Оцінка результатів лінійної регресії. Множинний коефіцієнт кореляції та множинний коефіцієнт детермінації
Множинний коефіцієнт кореляції трьох змінних – це показник тісноти лінійного зв'язку між однією з ознак (літера індексу перед тире) та сукупністю двох інших ознак (літери індексу після тире):
 ; (12.7)
; (12.7)
 (12.8)
(12.8)
Ці формули дозволяють легко обчислити численні коефіцієнти кореляції при відомих значенняхкоефіцієнтів парної кореляції r xy , r xz та r yz.
Коефіцієнт Rне від'ємний і завжди знаходиться в межах від 0 до 1. При наближенні Rдо одиниці ступінь лінійного зв'язку трьох ознак збільшується. між коефіцієнтом множинної кореляції, наприклад R y-xz, та двома коефіцієнтами парної кореляції r yxі r yzіснує таке співвідношення: кожен із парних коефіцієнтів не може перевищувати за абсолютною величиною R y-xz.
Квадрат коефіцієнта множинної кореляції R 2називається коефіцієнтом множинної детермінації. Він показує частку варіації залежної змінної під впливом факторів, що вивчаються.
Значимість множинної кореляції оцінюється за
F-Критерію:
 , (12.9)
, (12.9)
n- Обсяг вибірки,
k- Число ознак; у нашому випадку k = 3.
Теоретичне значення F-Крітерію беруть з таблиці додатків для ν 1 = k-1 і ν 2 = n-kступенів свободи та прийнятого рівня значущості. Нульова гіпотеза про рівність множинного коефіцієнта кореляції в сукупності нулю ( H 0:R= 0) приймається, якщо F факт.< F табл . і відкидається, якщо F факт. ≥ F табл.
Кінець роботи -
Ця тема належить розділу:
Математична статистика
Установа освіти.. гомельська державний університет.. імені франциска скорини юм жученко..
Якщо вам потрібно додатковий матеріална цю тему, або Ви не знайшли те, що шукали, рекомендуємо скористатися пошуком по нашій базі робіт:
Що робитимемо з отриманим матеріалом:
Якщо цей матеріал виявився корисним для Вас, Ви можете зберегти його на свою сторінку в соціальних мережах:
| Твітнути |
Всі теми цього розділу:
Навчальний посібник
для студентів вузів, які навчаються за спеціальністю 1-31 01 01 «Біологія» Гомель 2010
Предмет та метод математичної статистики
Предмет математичної статистики – вивчення властивостей масових явищ у біології, економіці, техніці та інших галузях. Ці явища зазвичай видаються складними, внаслідок різноманітності (варієрів
Поняття випадкової події
Статистична індукція чи статистичні висновки як головна складова частинаметоду дослідження масових явищ, які мають свої відмінні риси. Статистичні висновки роблять із чисельно
Імовірність випадкової події
Числова характеристикавипадкової події, що володіє тим властивістю, що для будь-якої досить великої серії випробувань частота події лише трохи відрізняється від цієї характеристики, називає
Обчислення ймовірностей
Часто виникає необхідність одночасно складати та множити ймовірності. Наприклад, потрібно визначити можливість випадання 5 очок при одночасному киданні 2 кубиків. Шукана сума віроят
Поняття випадкової змінної
Визначивши поняття ймовірності та з'ясувавши її основні властивості, перейдемо до розгляду одного з найважливіших понять теорії ймовірностей – поняття випадкової змінної. Припустимо, що в результаті
Дискретні випадкові змінні
Випадкова змінна дискретна, якщо сукупність можливих її значень кінцева, або, Крайній мірі, Піддається числення. Припустимо, що випадкова змінна X може набувати значення x1
Безперервні випадкові змінні
На противагу дискретним випадковим змінним, розглянутим у попередньому підрозділі, сукупність можливих значень безперервної випадкової змінної не тільки не кінцева, а й не піддається
Математичне очікування та дисперсія
Часто виникає необхідність охарактеризувати розподіл випадкової змінної за допомогою одного-двох числових показників, що виражають найістотніші властивості цього розподілу. До таких
Моменти
Велике значення у математичній статистиці мають звані моменти розподілу випадкової змінної. У математичному очікуванніВеликі значення випадкової величини враховуються недостатньо.
Біноміальний розподіл та вимір ймовірностей
У цьому темі розглянемо основні типи розподілу дискретних випадкових змінних. Припустимо, що ймовірність настання деякої випадкової події А при одиничному випробуванні дорівнює
Прямокутний (рівномірний) розподіл
Прямокутний (рівномірний) розподіл - найпростіший тип безперервних розподілів. Якщо випадкова змінна X може набувати будь-яке дійсне значення в інтервалі (а, b), де а і b – дейст
Нормальний розподіл
Нормальний розподіл грає основну роль математичної статистики. Це ні в якому разі не є випадковим: в об'єктивній дійсності дуже часто зустрічаються різні ознаки
Логарифмічно нормальний розподіл
Випадкова змінна Y має логарифмічний характер. нормальний розподілз параметрами μ та σ, якщо випадкова змінна X = lnY має нормальний розподіл з тими самими параметрами μ та &
Середні величини
З усіх групових властивостей найбільше теоретичне та практичне значення має середній рівень, що вимірюється середньою величиною ознаки. Середня величина ознаки - поняття дуже глибоке,
Загальні властивості середніх величин
Для правильного використання середніх величин необхідно знати властивості цих показників: серединне розташування, абстрактність та єдність сумарної дії. За своїм чисельним значенням
Середня арифметична
Середня арифметична, володіючи загальними властивостямисередніх величин, має свої особливості, які можна виразити такими формулами:
Середній ранг (непараметрична середня)
Середній ранг визначається таких ознак, котрим ще знайдено способи кількісного виміру. За ступенем прояву таких ознак об'єкти можуть бути ранжовані, тобто розташовані
Зважена середня арифметична
Зазвичай, щоб розрахувати середню арифметичну, складають усі значення ознакита отриману суму ділять на число варіантів. У цьому випадку кожне значення, входячи в суму, збільшує її на повну
Середня квадратична
Середня квадратична обчислюється за формулою: , (6.5) Вона дорівнює кореню квадратному із суми
Медіана
Медіаною називають таке значення ознаки, яке поділяє всю групу на дві рівні частини: одна частина має значення ознаки менше, ніж медіана, а інша більша. Наприклад, якщо має
Середня геометрична
Щоб отримати середню геометричну для групи з n даними, потрібно всі варіанти перемножити і з отриманого твору витягти корінь n-йступеня:
Середня гармонійна
Середня гармонійна розраховується за такою формулою. (6.14) Для п'яти варіантів: 1, 4, 5, 5 сер.
Число ступенів свободи
Число ступенів свободи дорівнює числу елементів вільного розмаїття групи. Воно дорівнює числу всіх наявних елементів вивчення без обмежень різноманітності. Наприклад, для дослідження
Коефіцієнт варіації
Стандартне відхилення – величина іменована, виражена у тих самих одиницях виміру, як і середня арифметична. Тому для порівняння різних ознак, виражених у різних одиницях з
Ліміти та розмах
Для швидкої та приблизної оцінки ступеня різноманітності часто застосовуються найпростіші показники: lim = (min max) – ліміти, тобто найменше і найбільше значенняознаки, p =
Нормоване відхилення
Зазвичай ступінь розвитку ознаки визначається шляхом його вимірювання і виражається певним іменованим числом: 3 кг ваги, 15 см довжини, 20 зачіпок на крилі бджіл, 4% жиру в молоці, 15 кг настригу
Середня та сигма сумарної групи
Іноді буває необхідно визначити середню та сигму для сумарного розподілу, складеного з кількох розподілів. При цьому відомі не самі розподіли, а лише їхні середні та сигми.
Скошеність (асиметрія) та крутість (ексцес) кривої розподілу
Для більших вибірок (n > 100) обчислюють ще два статистичні показники. Скошеність кривої називається асиметрією:
Варіаційний ряд
Принаймні збільшення чисельності досліджуваних груп дедалі більше проявляється та закономірність у різноманітності, що у нечисленних групах була прихована випадкової формою свого прояви.
Гістограма та варіаційна крива
Гістограма – це варіаційний рядпредставлений у вигляді діаграми, в якій різна величина частот зображується різною висотою стовпчиків. Гістограма розподілу даних представлена на р
Достовірність розходження розподілів
Статистична гіпотеза - це певне припущення про розподіл ймовірностей, що лежить в основі вибірки даних, що спостерігається. Перевірка статистичної гіпотези- Це процес прийняття
Критерій по асиметрії та ексцесу
Деякі ознаки рослин, тварин та мікроорганізмів при об'єднанні об'єктів у групи дають розподіли, що значно відрізняються від нормального. У тих випадках, коли якісь при
Генеральна сукупність та вибірка
Весь масив особин певної категорії називається генеральною сукупністю. Об `єм генеральної сукупностівизначається завданнями дослідження. Якщо вивчається якийсь вид диких живий
Репрезентативність
Безпосереднє вивчення групи відібраних об'єктів дає передусім первинний матеріалта характеристику самої вибірки. Усі вибіркові дані та зведені показники мають значення як
Помилки репрезентативності та інші помилки досліджень
Оцінка генеральних параметрів за вибірковими показниками має особливості. Частина ніколи не може повністю охарактеризувати все ціле, тому характеристика генеральної сукупності
Довірчі кордони
Визначати величину помилок репрезентативності необхідно у тому, щоб вибіркові показники використовувати ще й знаходження можливих значень генеральних параметрів. Цей процес називається про
Загальний порядок оцінки
Три величини, необхідні оцінки генерального параметра, – вибірковий показник (), критерій надійності
Оцінка середньої арифметичної
Оцінка середньої величинимає на меті встановити величину генеральної середньої для вивченої категорії об'єктів. Потрібна для цієї мети помилка репрезентативності визначається за формулою:
Оцінка середньої різниці
У деяких дослідженнях як первинні дані береться різниця двох вимірювань. Це може бути у випадку, коли кожна особина вибірки вивчається у двох станах – або у різному віці, або п
Недостовірна та достовірна оцінка середньої різниці
Такі результати вибіркових досліджень, за якими не можна отримати жодної певної оцінки генерального параметра (або він більший за нуль, або менше, або дорівнює нулю), називаються недостовірними.
Оцінка різниці генеральних середніх
У біологічних дослідженнях особливе значення має різницю двох величин. По різниці ведеться порівняння різних популяцій, рас, порід, сортів, ліній, сімейств, дослідних та контрольних груп (метод гр
Критерій достовірності різниці
При тому великому значенні, яке має для дослідників отримання достовірних різниць, з'являється необхідність оволодіти методами, що дозволяють визначити – чи отримана достовірна, реально з
Репрезентативність щодо якісних ознак
Якісні ознаки зазвичай не можуть мати градацій прояву: вони або є, або не є у кожної з особин, наприклад, підлога, комолость, наявність або відсутність яких-небудь особливостей, уродс
Достовірність різниці часток
Достовірність різниці вибіркових часток визначається як і, як й у різниці середніх: (10.34)
Коефіцієнт кореляції
Багато дослідженнях потрібно вивчити кілька ознак у тому взаємної зв'язку. Якщо вести таке дослідження стосовно двох ознак, можна помітити, що мінливість однієї ознаки н
Помилка коефіцієнта кореляції
Як і будь-яка вибіркова величина, коефіцієнт кореляції має свою помилку репрезентативності, що обчислюється для великих вибірок за формулою:
Достовірність вибіркового коефіцієнта кореляції
Критерій вибіркового коефіцієнта кореляції визначається за такою формулою: (11.9) де:
Довірчі межі коефіцієнта кореляції
Довірчі межі генерального значення коефіцієнта кореляції знаходяться загальним способомза формулою:
Достовірність різниці двох коефіцієнтів кореляції
Достовірність різниці коефіцієнтів кореляції визначається так само, як і достовірність різниці середніх, за звичайною формулою
Рівняння прямолінійної регресії
Прямолінійна кореляція відрізняється тим, що при цій формі зв'язку кожному з однакових змін першої ознаки відповідає цілком певна і теж однакова в середньому зміна іншого
Помилки елементів рівняння прямолінійної регресії
У рівнянні простий прямо лінійної регресії: у = а + bх виникають три помилки репрезентативності. 1 Помилка коефіцієнта регресії:
Приватний коефіцієнт кореляції
Приватний коефіцієнт кореляції - це показник, що вимірює ступінь сполученості двох ознак при постійному значеннітретього. Математична статистика дозволяє встановити кореляцію
Лінійне рівняння множинної регресії
Математичне рівняння для прямолінійної залежності між трьома змінними називається множинним лінійним рівнянням площини регресії. Воно має такий загальний вигляд:
Кореляційне ставлення
Якщо зв'язок між явищами, що вивчаються, істотно відхиляється від лінійної, що легко встановити за графіком, то коефіцієнт кореляції непридатний як міра зв'язку. Він може вказати на відсутність
Властивості кореляційного відношення
Кореляційне відношення вимірює ступінь кореляції за будь-якої її форми. Крім того, кореляційне відношення має низку інших властивостей, що становлять великий інтерес у статистичному
Помилка репрезентативності кореляційного відношення
Ще не розроблено точної формули помилки репрезентативності кореляційного відношення. Зазвичай формула, що наводиться в підручниках, має недоліки, якими не завжди можна знехтувати. Ця формула не уч
Критерій лінійності кореляції
Для визначення ступеня наближення криволінійної залежності до прямолінійної використовується критерій F, який обчислюється за формулою:
Дисперсійний комплекс
Дисперсійний комплекс - це сукупність градацій із залученими для дослідження даними та середніми з даних щодо кожної градації (приватні середні) та по всьому комплексу (загальна середня).
Статистичні впливи
Статистичне вплив – це відбиток у розмаїтті результативного ознаки того розмаїття чинника (його градацій), що у дослідженні. Для оцінки впливу фактора нео
Факторіальний вплив
Факторіальний вплив – це простий або комбінований статистичний вплив факторів, що вивчаються. В однофакторних комплексах вивчається простий вплив одного фактора при певних органах.
Однофакторний дисперсійний комплекс
Дисперсійний аналіз розроблено та введено в практику сільськогосподарських та біологічних досліджень англійським ученим Р. А. Фішером, який відкрив закон розподілу відносин середніх квадратів
Багатофакторний дисперсійний комплекс
Ясне уявлення про математичної моделідисперсійного аналізу полегшує розуміння необхідних обчислювальних операцій, особливо при обробці даних багатофакторних дослідів, у яких більше
Перетворення
Правильне використання дисперсійного аналізу для обробки експериментального матеріалу передбачає однорідність дисперсій за варіантами (вибірками), нормальний або близький до нього розподіл у
Показники сили впливу
Визначення сили впливів за їх результатами потрібно в біології, сільському господарстві, медицині для вибору найбільш ефективних засобіввпливу, для дозування фізичних та хімічних агентів – ст.
Помилка репрезентативності основного показника сили впливу
Точну формулу помилки основного показника сили впливу ще не знайдено. В однофакторних комплексах, коли помилка репрезентативності визначається лише для одного факторіального показника
Граничні значення показників сили впливу
Основний показник сили впливу дорівнює частці одного доданку від усієї суми доданків. Крім того, цей показник дорівнює квадратукореляційного відношення. З цих двох причин показник сили вл
Достовірність впливів
Основний показник сили впливу, отриманий у вибірковому дослідженні, характеризує, перш за все, той ступінь впливу, який реально, насправді, виявився у групі досліджених об'єктів.
Дискримінантний аналіз
Дискримінантний аналіз є одним із методів багатовимірного статистичного аналізу. Мета дискримінантного аналізу полягає в тому, щоб на основі вимірювання різних характеристик (ознак, пар
Постановка задачі, методи розв'язання, обмеження
Припустимо, є n об'єктів з m характеристиками. Через війну вимірів кожен об'єкт характеризується вектором x1 ... xm, m >1. Завдання полягає в тому, що
Припущення та обмеження
Дискримінантний аналіз «працює» у виконанні низки припущень. Припущення про те, що величини, що спостерігаються - вимірювані характеристики об'єкта - мають нормальний розподіл. Це
Алгоритм дискримінантного аналізу
Розв'язання задач дискримінації (дискримінантний аналіз) полягає у розбиття всього вибіркового простору (множини реалізації всіх аналізованих багатовимірних) випадкових величин) на деяке число
Кластерний аналіз
Кластерний аналіз поєднує різні процедури, що використовуються щодо класифікації. В результаті застосування цих процедур вихідна сукупність об'єктів поділяється на кластери чи групи
Методи кластерного аналізу
У практиці зазвичай реалізуються агломеративні методи кластеризації. Зазвичай перед початком класифікації дані стандартизуються (віднімається середнє і проводиться поділ на корінь квадратний)
Алгоритм кластерного аналізу
Кластерний аналіз – це сукупність методів класифікації багатовимірних спостережень чи об'єктів, заснованих на визначенні поняття відстані між об'єктами з наступним виділенням їх груп, &
Особливе значення має розрахунок множинного коефіцієнта кореляції результативної ознаки y з факторними x 1 x 2 ... x mформула для визначення якого в загальному випадкумає вигляд
де ∆ r – визначник кореляційної матриці; ∆ 11 – додаток алгебри елемента r yy кореляційної матриці.
Якщо розглядаються лише дві факторні ознаки, то для обчислення множинного коефіцієнта кореляції можна використовувати таку формулу: 
Побудова множинного коефіцієнта кореляції є доцільною лише в тому випадку, коли приватні коефіцієнти кореляції виявилися значущими, і зв'язок між результативною ознакою та факторами, включеними в модель, дійсно існує.
Коефіцієнт детермінації
Загальна формула: R 2 = RSS/TSS=1-ESS/TSSде RSS - пояснена сума квадратів відхилень, ESS - непояснена (залишкова) сума квадратів відхилень, TSS - Загальна сумаквадратів відхилень (TSS=RSS+ESS)
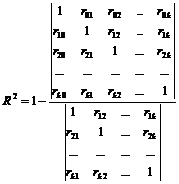 ,
,
де r ij - парні коефіцієнти кореляції між регресорами x i і x j, a r i 0 - парні коефіцієнти кореляції між регресором x i і y;
- скоригований (нормований) коефіцієнт детермінації.
Квадрат множинного коефіцієнта кореляції ![]() називається множинним коефіцієнтом детермінації; він показує, яка частка дисперсії результативної ознаки yпояснюється впливом факторних ознак x1, x2, …, xm. Зауважимо, що формула для обчислення коефіцієнта детермінації через співвідношення залишкової та загальної дисперсіїрезультативної ознаки дасть той самий результат.
називається множинним коефіцієнтом детермінації; він показує, яка частка дисперсії результативної ознаки yпояснюється впливом факторних ознак x1, x2, …, xm. Зауважимо, що формула для обчислення коефіцієнта детермінації через співвідношення залишкової та загальної дисперсіїрезультативної ознаки дасть той самий результат.
Множинний коефіцієнт кореляції та коефіцієнт детермінації змінюються в межах від 0 до 1. Чим ближче до 1, тим зв'язок сильніший і, відповідно, тим точніше рівняння регресії, побудоване надалі, описуватиме залежність yвід x 1, x 2, …, x m. Якщо значення множинного коефіцієнта кореляції невелике (менше 0,3), це означає, що обраний набір факторних ознак недостатньо описує варіацію результативної ознаки або зв'язок між факторними і результативною змінними є нелінійним.
Розраховується множинний коефіцієнт кореляції за допомогою калькулятора. Значимість множинного коефіцієнта кореляції та коефіцієнта детермінаціїперевіряється за допомогою критерію Фішера.
Яке з наведених чисел може бути значенням коефіцієнта множинної детермінації:
а) 0,4;
б) -1;
в) -2,7;
г) 2,7.
Множинний лінійний коефіцієнткореляції дорівнює 0.75. Який відсоток варіації залежної змінної враховано в моделі і обумовлений впливом факторів х 1 і х 2 .
а) 56,2 (R 2 = 0.75 2 = 0.5625);
Оцініть якість збудованої моделі. Чи покращилася якість моделі порівняно з однофакторною моделлю? Дайте оцінку впливу значимих факторів на результат за допомогою коефіцієнтів еластичності, - та -коефіцієнтів.
Коефіцієнт детермінації R-квадрат візьмемо із підсумків «Регресії» (таблиця « Регресійна статистика» для моделі (6).
Отже, варіація (зміна) ціни квартири Yна 76,77% пояснюється за цим рівнянням варіацією міста області Х 1 , числа кімнат у квартирі Х 2 та житлової площі Х 4 .
Використовуємо вихідні дані Y iта знайдені інструментом «Регресія» залишки  (Таблиця «Виведення залишку» для моделі (6)). Розрахуємо відносні похибки та знайдемо середнє значення
(Таблиця «Виведення залишку» для моделі (6)). Розрахуємо відносні похибки та знайдемо середнє значення  .
.
ВИСНОВОК ЗАЛИШКУ
| Спостереження | Передбачене Y | Залишки | Отн. похибка |
| 1 | 45,95089273 | -7,95089273 | 20,92340192 |
| 2 | 86,10296493 | -23,90296493 | 38,42920407 |
| 3 | 94,84442678 | 30,15557322 | 24,12445858 |
| 4 | 84,17648426 | -23,07648426 | 37,76838667 |
| 5 | 40,2537216 | 26,7462784 | 39,91981851 |
| 6 | 68,70572376 | 24,29427624 | 26,12287768 |
| 7 | 143,7464899 | -25,7464899 | 21,81905923 |
| 8 | 106,0907598 | 25,90924022 | 19,62821228 |
| 9 | 135,357993 | -42,85799303 | 46,33296544 |
| 10 | 114,4792566 | -9,47925665 | 9,027863476 |
| 11 | 41,48765602 | 0,512343975 | 1,219866607 |
| 12 | 103,2329236 | 21,76707636 | 17,41366109 |
| 13 | 130,3567798 | 39,64322022 | 23,3195413 |
| 14 | 35,41901876 | 2,580981242 | 6,7920559 |
| 15 | 155,4129693 | -24,91296925 | 19,0903979 |
| 16 | 84,32108188 | 0,678918123 | 0,798727204 |
| 17 | 98,0552279 | -0,055227902 | 0,056355002 |
| 18 | 144,2104618 | -16,21046182 | 12,66442329 |
| 19 | 122,8677535 | -37,86775351 | 44,55029825 |
| 20 | 100,0221225 | 59,97787748 | 37,48617343 |
| 21 | 53,27196558 | 6,728034423 | 11,21339071 |
| 22 | 35,06605378 | 5,933946225 | 14,47303957 |
| 23 | 114,4792566 | -24,47925665 | 27,19917406 |
| 24 | 113,1343153 | -30,13431529 | 36,30640396 |
| 25 | 40,43190991 | 4,568090093 | 10,15131132 |
| 26 | 39,34427892 | -0,344278918 | 0,882766457 |
| 27 | 144,4794501 | -57,57945009 | 66,25943623 |
| 28 | 56,4827667 | -16,4827667 | 41,20691675 |
| 29 | 95,38240332 | -15,38240332 | 19,22800415 |
| 30 | 228,6988826 | -1,698882564 | 0,748406416 |
| 31 | 222,8067278 | 12,19327221 | 5,188626473 |
| 32 | 38,81483144 | 1,185168555 | 2,962921389 |
| 33 | 48,36325811 | 18,63674189 | 27,81603267 |
| 34 | 126,6080021 | -3,608002113 | 2,933335051 |
| 35 | 84,85052935 | 15,14947065 | 15,14947065 |
| 36 | 116,7991162 | -11,79911625 | 11,23725357 |
| 37 | 84,17648426 | -13,87648426 | 19,73895342 |
| 38 | 113,9412801 | -31,94128011 | 38,95278062 |
| 39 | 215,494184 | 64,50581599 | 23,03779142 |
| 40 | 141,7795953 | 58,22040472 | 29,11020236 |
| Середнє | 101,2375 | 22,51770962 |
Стовпцем відносних похибокзнайдемо середнє значення =22.51% (за допомогою функції СРЗНАЧ).
Порівняння показує, що 22.51%>7%. Отже, точність моделі є незадовільною.
За допомогою F - Критерія Фішера перевіримо значущість моделі загалом. Для цього випишемо з результатів застосування інструменту «Регресія» (таблиця « дисперсійний аналіз» для моделі (6)) F= 39,6702.
За допомогою функції FРАСПОБР знайдемо значення F кр =3.252 для рівня значимості α = 5%, і чисел ступенів свободи k 1 = 2 , k 2 = 37 .
F> F кр, отже, рівняння моделі (6) є значущим, його використання доцільно, залежна змінна Yдосить добре описується включеними в модель (6) факторними змінними Х 1 , Х 2 . і Х 4 .
Додатково за допомогою t -Крітерія Стьюдента перевіримо значимість окремих коефіцієнтів моделі.
t-Статистики для коефіцієнтів рівняння регресії наведені в підсумках інструменту «Регресія». Отримано наступні значеннядля обраної моделі (6) :
| Коефіцієнти | Стандартна помилка | t-статистика | P-Значення | Нижні 95% | Верхні 95% | Нижні 95,0% | Верхні 95,0% |
|
| Y-перетин | -5,643572321 | 12,07285417 | -0,46745966 | 0,642988 | -30,1285 | 18,84131 | -30,1285 | 18,84131 |
| X4 | 2,591405557 | 0,461440597 | 5,61590284 | 2,27E-06 | 1,655561 | 3,52725 | 1,655561 | 3,52725 |
| X1 | 6,85963077 | 9,185748512 | 0,74676884 | 0,460053 | -11,7699 | 25,48919 | -11,7699 | 25,48919 |
| X2 | -1,985156991 | 7,795346067 | -0,25465925 | 0,800435 | -17,7949 | 13,82454 | -17,7949 | 13,82454 |
Критичне значення t крзнайдено для рівня значимості α=5%та числа ступенів свободи k=40–2–1=37 . t кр =2.026 (функція СТЬЮДРАСПОБР).
Для вільного коефіцієнта α
=–5.643
визначено статистику  ,
,  t крОтже, вільний коефіцієнт не є значущим, його можна виключити з моделі.
t крОтже, вільний коефіцієнт не є значущим, його можна виключити з моделі.
Для коефіцієнта регресії β
1
=6.859
визначено статистику  ,
,  β
1
не є значним, його та фактор міста області можна видалити з моделі.
β
1
не є значним, його та фактор міста області можна видалити з моделі.
Для коефіцієнта регресії β
2
=-1,985
визначено статистику  ,
,  t кр, отже, коефіцієнт регресії β
2
Не є значним, його і фактор числа кімнат у квартирі можна виключити з моделі.
t кр, отже, коефіцієнт регресії β
2
Не є значним, його і фактор числа кімнат у квартирі можна виключити з моделі.
Для коефіцієнта регресії β
4
=2.591
визначено статистику  ,
,  >t кр, отже, коефіцієнт регресії β
4
є значним, його і фактор житлової площі квартири можна зберегти в моделі.
>t кр, отже, коефіцієнт регресії β
4
є значним, його і фактор житлової площі квартири можна зберегти в моделі.
Висновки про значимість коефіцієнтів моделі зроблено лише на рівні значимості α=5%. Розглядаючи стовпець «P-значення», зазначимо, що вільний коефіцієнт α вважатимуться значним лише на рівні 0.64 = 64%; коефіцієнт регресії β 1 - На рівні 0,46 = 46%; коефіцієнт регресії β 2 - На рівні 0,8 = 80%; а коефіцієнт регресії β 4 - На рівні 2,27 E-06 = 2,26691790951854E-06 = 0,0000002%.
При додаванні до рівняння нових факторних змінних автоматично збільшується коефіцієнт детермінації R 2
і зменшується середня помилкаапроксимації, хоча при цьому не завжди покращується якість моделі. Тому для порівняння якості моделі (3) та обраної множинної моделі (6) використовуємо нормовані коефіцієнти детермінації.
Таким чином, при додаванні до рівняння регресії фактора «місто області» Х 1 та фактора «число кімнат у квартирі» Х 2 якість моделі погіршилося, що говорить на користь видалення факторів Х 1 і Х 2 із моделі.
Проведемо подальші розрахунки.
Середні коефіцієнти еластичності
у разі лінійної моделі визначаються формулами  .
.
За допомогою функції СРЗНАЧ знайдемо: S Y, при збільшенні лише фактора Х 4 на одне його стандартне відхилення- Збільшується на 0,914 S Y
Дельта-коефіцієнти
визначаються формулами  .
.
Знайдемо коефіцієнти парної кореляції за допомогою інструмента «Кореляція» пакета «Аналіз даних» в Excel.
| Y | X1 | X2 | X4 |
|
| Y | 1 | |||
| X1 | -0,01126 | 1 | ||
| X2 | 0,751061 | -0,0341 | 1 | |
| X4 | 0,874012 | -0,0798 | 0,868524 | 1 |
Коефіцієнт детермінації було визначено раніше і дорівнює 0.7677.
Обчислимо дельта-коефіцієнти:
 ;
; 

Оскільки Δ 1 1
і Х 2
вибрано невдало, і їх потрібно видалити з моделі. Отже, за рівнянням отриманої лінійної трифакторної моделі зміна результуючого фактора Y(ціни квартири) на 104% пояснюється впливом фактора Х 4
(житловою площею квартири), на 4% впливом фактора Х 2
(кількість кімнат), на 0,0859% впливом фактора Х 1
(Місто області).
При вивченні складних явищ необхідно враховувати понад два випадкові фактори. Правильне уявлення про природу зв'язку між цими факторами можна отримати тільки в тому випадку, якщо дослідити відразу всі аналізовані випадкові фактори. Спільне вивчення трьох і більше випадкових факторів дозволить досліднику встановити більш менш обґрунтовані припущення про причинні залежності між явищами, що вивчаються. Простою формою множинного зв'язку є лінійна залежність між трьома ознаками. Випадкові фактори позначаються як X 1 , X 2 та X 3 . Парний коефіцієнти кореляції між X 1 і X 2 позначається як r 12 , відповідно між X 1 і X 3 - r 12 , між X 2 та X 3 - r 23 . Як міра тісноти лінійного зв'язку трьох ознак використовують множинні коефіцієнти кореляції, що позначаються R 1 ּ 23 , R 2 ּ 13 , R 3 ּ 12 та приватні коефіцієнти кореляції, що позначаються r 12.3 , r 13.2 , r 23.1 .
Множинний коефіцієнт кореляції R 1.23 трьох факторів - це показник тісноти лінійного зв'язку між одним із факторів (індекс перед точкою) та сукупністю двох інших факторів (індекси після точки).
Значення коефіцієнта R завжди в межах від 0 до 1. При наближенні R до одиниці ступінь лінійного зв'язку трьох ознак збільшується.
Між коефіцієнтом множинної кореляції, наприклад R 2 ּ 13 і двома коефіцієнтами парної кореляції r 12 і r 23 існує співвідношення: кожен з парних коефіцієнтів не може перевищувати абсолютної величини R 2 13 .
Формули для обчислення множинних коефіцієнтів кореляції при відомих значеннях коефіцієнтів парної кореляції r 12 r 13 і r 23 мають вигляд:
Квадрат коефіцієнта множинної кореляції R 2 називається коефіцієнтом множинної детермінації.Він показує частку варіації залежної змінної під впливом факторів, що вивчаються.
Значимість множинної кореляції оцінюється за F-критерію:
![]()
n –обсяг вибірки; k –кількість факторів. У нашому випадку k = 3.
нульова гіпотеза про рівність множинного коефіцієнта кореляції в сукупності нулю ( h o:r=0)приймається, якщо fф<f t, і відкидається, якщо
fф ³ fт.
теоретичне значення f-критерія визначається для v 1 = k- 1 та v 2 = n - kступенів свободи та прийнятого рівня значущості a (додаток 1).
Приклад обчислення коефіцієнта множинної кореляції. При вивченні взаємозв'язку між факторами було отримано коефіцієнти парної кореляції ( n =15): r 12 ==0,6; р 13 = 0,3; r 23 = - 0,2.
Необхідно з'ясувати залежність ознаки X 2 від ознаки X 1 і X 3, тобто розрахувати коефіцієнт множинної кореляції:

Табличне значення F-Критерію при n 1 = 2 і n 2 = 15 - 3 = 12 степенях свободи при a = 0,05 F 0,05 = 3,89 і за a = 0,01 F 0,01 = 6,93.
Таким чином, взаємозв'язок між ознаками R 2.13 = 0,74 значуща
1%-ном рівні значимості Fф > F 0,01 .
Судячи з коефіцієнта множинної детермінації R 2 = (0,74) 2 = 0,55, варіація ознаки X 2 на 55% пов'язана з дією факторів, що вивчаються, а 45% варіації (1-R 2) не може бути пояснено впливом цих змінних.
Приватна лінійна кореляція
Приватний коефіцієнт кореляції- Це показник, що вимірює ступінь сполученості двох ознак.
Математична статистика дозволяє встановити кореляцію між двома ознаками при постійному значенні третього, не ставлячи спеціального експерименту, а використовуючи парні коефіцієнти кореляції r 12 , r 13 , r 23 .
Приватні коефіцієнти кореляції розраховують за формулами:

Цифри перед точкою вказують, між якими ознаками вивчається залежність, а цифра після точки – вплив якої ознаки виключається (елімінується). Помилка та критерій значущості приватної кореляції визначають за тими ж формулами, що й парної кореляції:
 .
.
Теоретичне значення t-критерію визначається для v = n– 2 ступенів свободи та прийнятого рівня значущості a (додаток 1).
Нульова гіпотеза про рівність приватного коефіцієнта кореляції разом нулю ( H o: r= 0) приймається, якщо tф< tт, і відкидається, якщо
tф ³ tт.
Приватні коефіцієнти можуть набувати значень, укладених між -1 і +1. Приватні коефіцієнти детермінаціїзнаходять шляхом зведення у квадрат приватних коефіцієнтів кореляції:
D 12.3 = r 2 12ּ3 ; d 13.2 = r 2 13ּ2 ; d 23ּ1 = r 2 23ּ1 .
Визначення ступеня приватного впливу окремих факторів на результативну ознаку при виключенні (елімінуванні) зв'язку його з іншими ознаками, що спотворюють цю кореляцію, часто цікавий. Іноді буває, що при постійному значенні ознаки, що елімінується, не можна помітити його статистичного впливу на мінливість інших ознак. Щоб зрозуміти техніку розрахунку приватного коефіцієнта кореляції, розглянемо приклад. Є три параметри X, Yі Z. Для обсягу вибірки n= 180 визначено парні коефіцієнти кореляції
r xy = 0,799; r xz = 0,57; r yz = 0,507.
Визначимо окремі коефіцієнти кореляції:

Частковий коефіцієнт кореляції між параметром Xі Y Z (rхуּz = 0,720) показує, що лише незначна частина взаємозв'язку цих ознак у загальній кореляції ( r xy= 0,799) обумовлена впливом третьої ознаки ( Z). Аналогічний висновок необхідно зробити щодо приватного коефіцієнта кореляції між параметром Xта параметром Zз постійним значенням параметра Y (rх zּу = 0,318 і r xz= 0,57). Навпаки, окремий коефіцієнт кореляції між параметрами Yі Zз постійним значенням параметра X ryz ּ x= 0,105 значно відрізняється від загального коефіцієнта кореляції r у z = 0,507. З цього видно, що якщо підібрати об'єкти з однаковим значенням параметра X, то зв'язок між ознаками Yі Zу них буде дуже слабкою, оскільки значна частина у цьому взаємозв'язку зумовлена варіюванням параметра X.
За деяких обставин приватний коефіцієнт кореляції може бути протилежним за парним знаком.
Наприклад, щодо взаємозв'язку між ознаками X, Уі Z- були отримані парні коефіцієнти кореляції (при n = 100): rху = 0,6; rх z= 0,9;
r у z = 0,4.
Приватні коефіцієнти кореляції за винятком впливу третьої ознаки:

З прикладу видно, що значення парного коефіцієнтата приватного коефіцієнта кореляції різняться у знаку.
Метод приватної кореляції дозволяє обчислити приватний коефіцієнт кореляції другого порядку. Цей коефіцієнт вказує на взаємозв'язок між першою та другою ознакою при постійному значенні третього та четвертого. Визначення приватного коефіцієнта другого порядку ведуть основі приватних коефіцієнтів першого порядку за формулою:

де r 12 . 4 , r 13 ּ4 , r 23 4 - приватні коефіцієнти, значення яких визначають за формулою приватного коефіцієнта, використовуючи коефіцієнти парної кореляції r 12 , r 13 , r 14 , r 23 , r 24 , r 34 .
Регресійний аналіз- Це статистичний метод дослідження, що дозволяє показати залежність того чи іншого параметра від однієї або кількох незалежних змінних. У докомп'ютерну епоху його застосування було досить складно, особливо якщо йшлося про великі обсяги даних. Сьогодні, дізнавшись, як побудувати регресію в Excel, можна вирішувати складні статистичні завданнябуквально за кілька хвилин. Нижче представлені конкретні приклади галузі економіки.
Види регресії
Саме це поняття було введено в математику у 1886 році. Регресія буває:
- лінійної;
- параболічній;
- статечною;
- експоненційною;
- гіперболічній;
- показовою;
- логарифмічні.
Приклад 1
Розглянемо завдання визначення залежності кількості членів колективу, що звільнилися. середньої зарплатина 6 промислових підприємствах.
Завдання. На шести підприємствах проаналізували середньомісячну заробітну платута кількість співробітників, які звільнилися за власним бажанням. У табличній формі маємо:
Кількість звільнених | Зарплата |
||
30000 рублів |
|||
35000 рублів |
|||
40000 рублів |
|||
45000 рублів |
|||
50000 рублів |
|||
55000 рублів |
|||
60000 рублів |
Для завдання визначення залежності кількості працівників, що звільнилися, від середньої зарплати на 6 підприємствах модель регресії має вигляд рівняння Y = а 0 + а 1 x 1 +…+а k x k , де х i — що впливають змінні, a i — коефіцієнти регресії, a k — число факторів.
Для цього завдання Y — це показник співробітників, що звільнилися, а впливаючий фактор — зарплата, яку позначаємо X.
Використання можливостей табличного процесора «Ексель»
Аналізу регресії в Excel має передувати застосування наявних табличних даних вбудованих функцій. Однак для цього краще скористатися дуже корисною надбудовою «Пакет аналізу». Для його активації потрібно:
- з вкладки "Файл" перейти до розділу "Параметри";
- у вікні вибрати рядок «Надбудови»;
- клацнути на кнопці «Перейти», розташованої внизу, праворуч від рядка «Управління»;
- поставити галочку поруч із назвою «Пакет аналізу» та підтвердити свої дії, натиснувши «Ок».
Якщо все зроблено правильно, у правій частині вкладки "Дані", розташованому над робочим листом "Ексель", з'явиться потрібна кнопка.
в Excel
Тепер, коли під рукою є всі необхідні віртуальні інструменти для здійснення економетричних розрахунків, можемо розпочати вирішення нашого завдання. Для цього:
- клацаємо по кнопці «Аналіз даних»;
- у вікні натискаємо на кнопку «Регресія»;
- в вкладку, що з'явилася, вводимо діапазон значень для Y (кількість звільнених працівників) і для X (їх зарплати);
- підтверджуємо свої дії, натиснувши кнопку «Ok».
В результаті програма автоматично заповнить новий аркуш табличного процесора даними аналізу регресії. Зверніть увагу! В Excel є можливість самостійно задати місце, якому ви надаєте перевагу для цієї мети. Наприклад, це може бути той самий лист, де знаходяться значення Y і X, або навіть нова книгаспеціально призначена для зберігання подібних даних.
Аналіз результатів регресії для R-квадрату
В Excel дані отримані в ході обробки даних прикладу, що розглядається, мають вигляд:
Насамперед, слід звернути увагу до значення R-квадрата. Він є коефіцієнтом детермінації. У цьому прикладі R-квадрат = 0,755 (75,5%), тобто розрахункові параметри моделі пояснюють залежність між параметрами, що розглядаються, на 75,5 %. Чим вище значення коефіцієнта детермінації, тим вибрана модель вважається застосовнішою для конкретної задачі. Вважається, що вона коректно визначає реальну ситуацію за значення R-квадрату вище 0,8. Якщо R-квадрату<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Аналіз коефіцієнтів
Число 64,1428 показує, яким буде значення Y, якщо всі змінні xi в моделі, що розглядається, обнуляться. Іншими словами можна стверджувати, що на значення аналізованого параметра впливають інші фактори, не описані в конкретній моделі.
Наступний коефіцієнт -0,16285, розташований у осередку B18, показує вагомість впливу змінної Х на Y. Це означає, що середньомісячна зарплата співробітників у межах аналізованої моделі впливає кількість звільнених із вагою -0,16285, т. е. ступінь її впливу зовсім невелика. Знак «-» свідчить про те, що коефіцієнт має негативне значення. Це очевидно, оскільки всім відомо, що чим більша зарплата на підприємстві, тим менше людей висловлюють бажання розірвати трудовий договір чи звільняється.
Множинна регресія
Під таким терміном розуміється рівняння зв'язку з кількома незалежними змінними видами:
y=f(x 1 +x 2 +…x m) + ε, де y — це результативна ознака (залежна змінна), а x 1 , x 2 , …x m — ознаки-фактори (незалежні змінні).
Оцінка параметрів
Для множинної регресії(МР) її здійснюють, використовуючи метод найменших квадратів (МНК). Для лінійних рівнянь виду Y = a + b 1 x 1 +…+b m x m + ε будуємо систему нормальних рівнянь (див. нижче)

Щоб зрозуміти принцип методу, розглянемо двофакторний випадок. Тоді маємо ситуацію, що описується формулою

Звідси отримуємо:

де σ - це дисперсія відповідної ознаки, відображеної в індексі.
МНК застосуємо до рівняння МР в масштабі, що стандартизується. У такому разі отримуємо рівняння:

в якому t y , t x 1, ... t xm - Змінні, що стандартизуються, для яких середні значення рівні 0; β i – стандартизовані коефіцієнти регресії, а середньоквадратичне відхилення – 1.
Зверніть увагу, що всі β i в даному випадку задані як нормовані та централізовані, тому їх порівняння між собою вважається коректним та допустимим. Крім того, прийнято здійснювати відсівання факторів, відкидаючи ті з них, які мають найменші значення βi.
Завдання з використанням рівняння лінійної регресії
Припустимо, є таблиця динаміки ціни конкретного товару протягом останніх 8 місяців. Необхідно ухвалити рішення про доцільність придбання його партії за ціною 1850 руб./т.
номер місяця | назва місяця | ціна товару N |
|
1750 рублів за тонну |
|||
1755 рублів за тонну |
|||
1767 рублів за тонну |
|||
1760 рублів за тонну |
|||
1770 рублів за тонну |
|||
1790 рублів за тонну |
|||
1810 рублів за тонну |
|||
1840 рублів за тонну |
|||
Для вирішення цього завдання в табличному процесорі «Ексель» потрібно задіяти вже відомий за наведеним вище прикладом інструмент «Аналіз даних». Далі вибирають розділ «Регресія» та задають параметри. Потрібно пам'ятати, що у полі «Вхідний інтервал Y» має вводитися діапазон значень для залежної змінної (у разі ціни на товар у конкретні місяці року), а «Вхідний інтервал X» — для незалежної (номер місяця). Підтверджуємо дії натисканням OK. На новому аркуші (якщо було зазначено) отримуємо дані для регресії.
Будуємо за ними лінійне рівняння виду y=ax+b, де як параметри a та b виступають коефіцієнти рядка з найменуванням номера місяця та коефіцієнти та рядки «Y-перетин» з аркуша з результатами регресійного аналізу. Таким чином, лінійне рівняння регресії (УР) для задачі 3 записується у вигляді:
Ціна товару N = 11,714* номер місяця + 1727,54.
або в позначеннях алгебри
y = 11,714 x + 1727,54
Аналіз результатів
Щоб вирішити, чи адекватно отримане рівняння лінійної регресії, використовуються коефіцієнти множинної кореляції (КМК) та детермінації, а також критерій Фішера та критерій Стьюдента. У таблиці «Ексель» з результатами регресії вони виступають під назвами множинний R, R-квадрат, F-статистика та t-статистика відповідно.
КМК R дає можливість оцінити тісноту ймовірнісного зв'язку між незалежною та залежною змінними. Її високе значення свідчить про досить сильний зв'язок між змінними «Номер місяця» та «Ціна товару N у рублях за 1 тонну». Проте характер цього зв'язку залишається невідомим.
Квадрат коефіцієнта детермінації R 2 (RI) є числову характеристику частки загального розкиду і показує, розкид якої частини експериментальних даних, тобто. значень залежної змінної відповідає рівнянню лінійної регресії У даній задачі ця величина дорівнює 84,8%, тобто статистичні дані з високим ступенем точності описуються отриманим УР.
F-статистика, яка називається також критерієм Фішера, використовується для оцінки значущості лінійної залежності, спростовуючи або підтверджуючи гіпотезу про її існування.
(Критерій Стьюдента) допомагає оцінювати значущість коефіцієнта при невідомій чи вільного члена лінійної залежності. Якщо значення t-критерію > t кр, то гіпотеза про незначущість вільного члена лінійного рівняннявідкидається.
У розглянутій задачі для вільного члена за допомогою інструментів «Ексель» було отримано, що t=169,20903, а p=2,89Е-12, тобто маємо нульову ймовірність того, що буде відкинута вірна гіпотеза про незначущість вільного члена. Для коефіцієнта за невідомої t=5,79405, а p=0,001158. Іншими словами ймовірність того, що буде відкинута вірна гіпотеза про незначущість коефіцієнта за невідомої, дорівнює 0,12%.
Отже, можна стверджувати, що отримане рівняння лінійної регресії адекватно.
Завдання про доцільність купівлі пакету акцій
Множинна регресія в Excel виконується з використанням того ж інструменту «Аналіз даних». Розглянемо конкретне прикладне завдання.
Керівництво компанія «NNN» має ухвалити рішення про доцільність купівлі 20% пакету акцій АТ «MMM». Вартість пакету (СП) складає 70 млн. американських доларів. Фахівцями NNN зібрані дані про аналогічні угоди. Було ухвалено рішення оцінювати вартість пакета акцій за такими параметрами, вираженими в мільйонах американських доларів, як:
- кредиторська заборгованість (VK);
- обсяг річного обороту (VO);
- дебіторська заборгованість (VD);
- вартість основних фондів (СОФ).
Крім того, використовується параметр заборгованості підприємства із зарплати (V3 П) у тисячах американських доларів.
Рішення засобами табличного процесора Excel
Насамперед, необхідно скласти таблицю вихідних даних. Вона має такий вигляд:

- викликають вікно "Аналіз даних";
- обирають розділ «Регресія»;
- у віконце «Вхідний інтервал Y» вводять діапазон значень залежних змінних зі стовпця G;
- клацають по іконці з червоною стрілкою праворуч від вікна «Вхідний інтервал X» і виділяють на аркуші діапазон всіх значень стовпців B,C, D, F.
Позначають пункт «Новий робочий лист» та натискають «Ok».
Отримують аналіз регресії для цього завдання.

Вивчення результатів та висновки
«Збираємо» із заокруглених даних, представлених вище на аркуші табличного процесора Excel, рівняння регресії:
СП = 0,103 * СОФ + 0,541 * VO - 0,031 * VK + 0,405 * VD +0,691 * VZP - 265,844.
У більш звичному математичному вигляді його можна записати як:
y = 0,103 * x1 + 0,541 * x2 - 0,031 * x3 +0,405 * x4 +0,691 * x5 - 265,844
Дані для АТ «MMM» представлені у таблиці:
Підставивши їх у рівняння регресії, одержують цифру в 64,72 млн американських доларів. Це означає, що акції АТ «MMM» не варто купувати, оскільки їхня вартість у 70 млн американських доларів досить завищена.
Як бачимо, використання табличного процесора «Ексель» та рівняння регресії дозволило ухвалити обґрунтоване рішення щодо доцільності цілком конкретної угоди.
Тепер ви знаєте, що таке регресія. Приклади в Excel, розглянуті вище, допоможуть вам вирішити практичних завданьз галузі економетрики.
