रैखिक प्रतिगमन परिणामों का मूल्यांकन। एकाधिक सहसंबंध गुणांक और निर्धारण के एकाधिक गुणांक
तीन चरों का बहु सहसंबंध गुणांक किसी एक विशेषता (डैश से पहले सूचकांक पत्र) और दो अन्य विशेषताओं (डैश के बाद सूचकांक अक्षर) के संयोजन के बीच एक रैखिक संबंध की निकटता का संकेतक है:
 ; (12.7)
; (12.7)
 (12.8)
(12.8)
ये फ़ार्मुलों के लिए एकाधिक सहसंबंध गुणांकों की गणना करना आसान बनाते हैं ज्ञात मूल्यजोड़ी सहसंबंध गुणांक r xy , r xz और r yz.
गुणक आरनकारात्मक नहीं है और हमेशा 0 और 1 के बीच होता है। पास आने पर आरएकता के लिए, तीन विशेषताओं के रैखिक संबंध की डिग्री बढ़ जाती है। अनुपात के बीच एकाधिक सहसंबंध, उदाहरण के लिए आर y-xz, और दो जोड़ी सहसंबंध गुणांक आर वाईएक्सतथा आर yzनिम्नलिखित संबंध हैं: प्रत्येक युग्म गुणांक निरपेक्ष मान से अधिक नहीं हो सकता आर y-xz.
बहु सहसंबंध गुणांक का वर्ग R2बहु निर्धारण का गुणांक कहलाता है। यह अध्ययन किए गए कारकों के प्रभाव में आश्रित चर में भिन्नता के अनुपात को दर्शाता है।
बहु सहसंबंध के महत्व का अनुमान लगाया जाता है
एफ- मानदंड:
 , (12.9)
, (12.9)
एननमूना आकार है,
क- सुविधाओं की संख्या; हमारे मामले में क = 3.
सैद्धांतिक मूल्य एफ- मानदंड आवेदन तालिका से लिए गए हैं 1 = के-1 और ν 2 \u003d n–kस्वतंत्रता की डिग्री और महत्व के स्वीकृत स्तर। जनसंख्या में शून्य से बहु सहसंबंध गुणांक की समानता के बारे में शून्य परिकल्पना ( एच0: आर= 0) स्वीकार किया जाता है यदि एफ तथ्य।< F табл . और खारिज कर दिया अगर एफ तथ्य। ≥ एफ टेबल.
काम का अंत -
यह विषय संबंधित है:
गणित के आँकड़े
शैक्षणिक संस्थान .. गोमेली स्टेट यूनिवर्सिटी.. फ्रांसिस स्केरीना यू एम ज़ुचेंको के नाम पर ..
अगर आपको चाहिये अतिरिक्त सामग्रीइस विषय पर, या आपको वह नहीं मिला जिसकी आप तलाश कर रहे थे, हम अपने काम के डेटाबेस में खोज का उपयोग करने की सलाह देते हैं:
प्राप्त सामग्री का हम क्या करेंगे:
यदि यह सामग्री आपके लिए उपयोगी साबित हुई, तो आप इसे सामाजिक नेटवर्क पर अपने पेज पर सहेज सकते हैं:
| कलरव |
इस खंड के सभी विषय:
ट्यूटोरियल
विशेषता 1-31 01 01 "जीव विज्ञान" गोमेल 2010 . में अध्ययन कर रहे विश्वविद्यालय के छात्रों के लिए
गणितीय आँकड़ों का विषय और विधि
गणितीय आँकड़ों का विषय जीव विज्ञान, अर्थशास्त्र, प्रौद्योगिकी और अन्य क्षेत्रों में सामूहिक घटनाओं के गुणों का अध्ययन है। विविधता के कारण ये घटनाएं आमतौर पर जटिल होती हैं (भिन्नता
एक यादृच्छिक घटना की अवधारणा
मुख्य के रूप में सांख्यिकीय प्रेरण या सांख्यिकीय अनुमान अवयवसामूहिक परिघटनाओं का अध्ययन करने का तरीका, उनका अपना है विशिष्ट सुविधाएं. सांख्यिकीय निष्कर्ष संख्यात्मक . के साथ किए जाते हैं
यादृच्छिक घटना की प्रायिकता
संख्यात्मक विशेषतायादृच्छिक घटना, जिसमें यह गुण होता है कि परीक्षणों की किसी भी पर्याप्त बड़ी श्रृंखला के लिए, घटना की आवृत्ति इस विशेषता से केवल थोड़ी भिन्न होती है, कहलाती है
संभावनाओं की गणना
अक्सर संभावनाओं को एक साथ जोड़ने और गुणा करने की आवश्यकता होती है। उदाहरण के लिए, आप एक ही समय में 2 पासे फेंकने पर 5 अंक प्राप्त करने की संभावना निर्धारित करना चाहते हैं। आवश्यक राशि होने की संभावना है
एक यादृच्छिक चर की अवधारणा
संभाव्यता की अवधारणा को परिभाषित करने और इसके मुख्य गुणों को स्पष्ट करने के बाद, आइए संभाव्यता सिद्धांत की सबसे महत्वपूर्ण अवधारणाओं में से एक पर विचार करें - एक यादृच्छिक चर की अवधारणा। आइए मान लें कि परिणामस्वरूप
असतत यादृच्छिक चर
एक यादृच्छिक चर असतत है यदि इसके संभावित मूल्यों का सेट परिमित है, या, के अनुसार कम से कम, गणनीय है। मान लें कि एक यादृच्छिक चर X मान x1 . ले सकता है
सतत यादृच्छिक चर
पिछले उपखंड में चर्चा किए गए असतत यादृच्छिक चर के विपरीत, एक सतत यादृच्छिक चर के लिए संभावित मूल्यों का सेट न केवल परिमित है, बल्कि इसके लिए उत्तरदायी भी नहीं है
गणितीय अपेक्षा और विचरण
अक्सर एक या दो संख्यात्मक संकेतकों का उपयोग करके एक यादृच्छिक चर के वितरण को चिह्नित करने की आवश्यकता होती है जो इस वितरण के सबसे महत्वपूर्ण गुणों को व्यक्त करते हैं। ऐसा करने के लिए
लम्हें
गणितीय आँकड़ों में एक यादृच्छिक चर के वितरण के तथाकथित क्षण बहुत महत्वपूर्ण हैं। पर गणितीय अपेक्षाएक यादृच्छिक चर के बड़े मूल्यों को अपर्याप्त रूप से ध्यान में रखा जाता है।
द्विपद वितरण और संभावनाओं की माप
इस विषय में, हम असतत यादृच्छिक चर के वितरण के मुख्य प्रकारों पर विचार करेंगे। आइए मान लें कि किसी एकल परीक्षण में किसी यादृच्छिक घटना A के घटित होने की प्रायिकता के बराबर है
आयताकार (समान) वितरण
एक आयताकार (समान) वितरण निरंतर वितरण का सबसे सरल प्रकार है। यदि एक यादृच्छिक चर एक्स अंतराल (ए, बी) में कोई वास्तविक मान ले सकता है, जहां ए और बी वास्तविक हैं
सामान्य वितरण
सामान्य वितरण गणितीय आँकड़ों में एक प्रमुख भूमिका निभाता है। यह कम से कम यादृच्छिक नहीं है: वस्तुनिष्ठ वास्तविकता में, विभिन्न संकेत बहुत बार सामने आते हैं।
लॉग-सामान्य वितरण
यादृच्छिक चर Y का लघुगणक है सामान्य वितरणपैरामीटर μ और σ के साथ यदि यादृच्छिक चर X = lnY का समान पैरामीटर μ और & के साथ एक सामान्य वितरण है
औसत मान
सभी समूह गुणों में, औसत स्तर, विशेषता के औसत मूल्य से मापा जाता है, का सबसे बड़ा सैद्धांतिक और व्यावहारिक महत्व है। किसी विशेषता का औसत मान एक बहुत गहरी अवधारणा है,
औसत के सामान्य गुण
औसत मूल्यों के सही उपयोग के लिए, इन संकेतकों के गुणों को जानना आवश्यक है: औसत स्थान, अमूर्तता और कुल क्रिया की एकता। इसके संख्यात्मक मान से
अंकगणित औसत
अंकगणित माध्य, होना सामान्य गुणऔसत मूल्यों की अपनी विशेषताएं होती हैं, जिन्हें निम्नलिखित सूत्रों द्वारा व्यक्त किया जा सकता है:
औसत रैंक (गैर-पैरामीट्रिक माध्य)
औसत रैंक ऐसी विशेषताओं के लिए निर्धारित की जाती है जिनके लिए मात्रात्मक माप के तरीके अभी तक नहीं मिले हैं। ऐसी विशेषताओं के प्रकट होने की डिग्री के अनुसार, वस्तुओं को स्थान दिया जा सकता है, अर्थात, स्थित
भारित अंकगणित माध्य
आमतौर पर, अंकगणितीय माध्य की गणना करने के लिए, सभी जोड़ें विशेषता मानऔर परिणामी राशि को विकल्पों की संख्या से विभाजित किया जाता है। इस मामले में, प्रत्येक मान, योग में प्रवेश करने पर, इसे पूर्ण से बढ़ा देता है
वर्गमूल औसत का वर्ग
मूल माध्य वर्ग की गणना सूत्र द्वारा की जाती है: , (6.5) यह योग के वर्गमूल के बराबर होता है
मंझला
माध्यिका एक ऐसा विशेषता मान है जो पूरे समूह को दो समान भागों में विभाजित करता है: एक भाग का विशेषता मान माध्यिका से कम होता है, और दूसरे का मान अधिक होता है। उदाहरण के लिए, यदि मेरे पास
जियोमेट्रिक माध्य
n डेटा वाले समूह के लिए ज्यामितीय माध्य प्राप्त करने के लिए, आपको सभी विकल्पों को गुणा करना होगा और परिणामी उत्पाद से निकालना होगा nth रूटडिग्री:
औसत हार्मोनिक
हार्मोनिक माध्य की गणना सूत्र द्वारा की जाती है। (6.14) पांच विकल्पों के लिए: 1, 4, 5, 5 माध्यम
स्वतंत्रता की डिग्री की संख्या
स्वतंत्रता की डिग्री की संख्या समूह में मुक्त विविधता तत्वों की संख्या के बराबर है। यह विविधता बाधाओं की संख्या के बिना सभी उपलब्ध अध्ययन मदों की संख्या के बराबर है। उदाहरण के लिए, अनुसंधान के लिए
भिन्नता का गुणांक
मानक विचलन एक नामित मान है, जिसे अंकगणित माध्य के समान इकाइयों में व्यक्त किया जाता है। इसलिए, विभिन्न इकाइयों में व्यक्त विभिन्न विशेषताओं की तुलना करने के लिए
सीमाएं और दायरा
विविधता की डिग्री के त्वरित और अनुमानित आकलन के लिए, सबसे सरल संकेतकों का अक्सर उपयोग किया जाता है: लिम = (न्यूनतम अधिकतम) - सीमाएं, यानी सबसे छोटी और सबसे बड़ा मूल्यफ़ीचर, पी =
सामान्यीकृत विचलन
आमतौर पर, एक विशेषता के विकास की डिग्री इसे मापकर निर्धारित की जाती है और एक निश्चित नामित संख्या द्वारा व्यक्त की जाती है: 3 किलो वजन, 15 सेमी लंबाई, मधुमक्खियों के पंख पर 20 हुक, दूध में 4% वसा, 15 किलो वजन कतरन
सारांश समूह का माध्य और सिग्मा
कभी-कभी कई वितरणों से बने योग वितरण के लिए माध्य और सिग्मा निर्धारित करना आवश्यक होता है। इस मामले में, वितरण स्वयं ज्ञात नहीं हैं, बल्कि केवल उनके साधन और सिग्मा हैं।
वितरण वक्र का तिरछापन (तिरछापन) और खड़ीपन (कुर्टोसिस)
बड़े नमूनों (n > 100) के लिए, दो और आँकड़ों की गणना की जाती है। वक्र की विषमता को विषमता कहते हैं:
विविधता श्रृंखला
जैसे-जैसे अध्ययन किए गए समूहों का आकार बढ़ता है, विविधता में नियमितता अधिक से अधिक स्पष्ट होती जाती है, जो छोटे समूहों में इसके प्रकट होने के यादृच्छिक रूप से छिपी हुई थी।
हिस्टोग्राम और भिन्नता वक्र
हिस्टोग्राम है विविधता श्रृंखला, एक आरेख के रूप में प्रस्तुत किया जाता है जिसमें एक भिन्न बारंबारता मान को अलग-अलग बार ऊँचाइयों द्वारा दर्शाया जाता है। डेटा वितरण हिस्टोग्राम p . में दिखाया गया है
वितरण अंतर का महत्व
एक सांख्यिकीय परिकल्पना डेटा के देखे गए नमूने के अंतर्निहित संभाव्यता वितरण के बारे में एक विशिष्ट धारणा है। इंतिहान सांख्यिकीय परिकल्पनास्वीकृति की एक प्रक्रिया है
तिरछापन और कुर्टोसिस के लिए मानदंड
पौधों, जानवरों और सूक्ष्मजीवों के कुछ लक्षण, जब वस्तुओं को समूहों में जोड़ा जाता है, तो वे वितरण देते हैं जो सामान्य से काफी भिन्न होते हैं। ऐसे मामलों में जहां कोई
सामान्य जनसंख्या और नमूना
एक निश्चित श्रेणी के व्यक्तियों के पूरे समूह को सामान्य जनसंख्या कहा जाता है। मात्रा आबादीअध्ययन के उद्देश्यों से निर्धारित होता है। यदि जंगली जानवरों की किसी प्रजाति का अध्ययन किया जाता है
प्रातिनिधिकता
चयनित वस्तुओं के समूह का प्रत्यक्ष अध्ययन सबसे पहले देता है, प्राथमिक सामग्रीऔर नमूने की विशेषताएं। सभी नमूना डेटा और सारांश आंकड़े प्रासंगिक हैं:
प्रतिनिधित्व त्रुटियाँ और अन्य शोध त्रुटियाँ
चयनात्मक संकेतकों के आधार पर सामान्य मापदंडों के मूल्यांकन की अपनी विशेषताएं हैं। एक हिस्सा कभी भी पूरी तरह से पूरी तरह से विशेषता नहीं हो सकता है, इसलिए सामान्य आबादी की विशेषता
आत्मविश्वास की सीमा
सामान्य मापदंडों के संभावित मूल्यों को खोजने के लिए नमूना संकेतकों का उपयोग करने के लिए भी प्रतिनिधित्व त्रुटियों के मूल्य को निर्धारित करना आवश्यक है। इस प्रक्रिया को o . कहा जाता है
सामान्य मूल्यांकन प्रक्रिया
सामान्य पैरामीटर का आकलन करने के लिए आवश्यक तीन मान - नमूना संकेतक (), विश्वसनीयता मानदंड
अंकगणित माध्य का अनुमान
श्रेणी मध्यम आकारवस्तुओं की अध्ययन की गई श्रेणी के लिए सामान्य औसत के मूल्य को स्थापित करना है। इस उद्देश्य के लिए आवश्यक प्रतिनिधित्व त्रुटि सूत्र द्वारा निर्धारित की जाती है:
माध्य अंतर अनुमान
कुछ अध्ययनों में, दो मापों के बीच के अंतर को प्राथमिक डेटा के रूप में लिया जाता है। यह तब हो सकता है जब नमूने के प्रत्येक व्यक्ति का दो राज्यों में अध्ययन किया जाता है - या में अलग अलग उम्र, या पी
औसत अंतर का अविश्वसनीय और विश्वसनीय अनुमान
चयनात्मक अध्ययनों के ऐसे परिणाम, जिनके अनुसार सामान्य पैरामीटर का कोई निश्चित अनुमान प्राप्त करना असंभव है (या तो यह शून्य से अधिक है, या शून्य से कम या बराबर है), अविश्वसनीय कहा जाता है।
सामान्य साधनों के अंतर का अनुमान
जैविक अनुसंधान में दो मात्राओं के बीच के अंतर का विशेष महत्व है। अंतर से, विभिन्न आबादी, नस्लों, नस्लों, किस्मों, रेखाओं, परिवारों, प्रयोगात्मक और नियंत्रण समूहों की तुलना की जाती है (विधि जीआर
अंतर विश्वसनीयता मानदंड
एक ही समय पर बहुत महत्व, जिसमें शोधकर्ताओं के लिए विश्वसनीय मतभेदों की प्राप्ति है, यह निर्धारित करने के लिए कि क्या प्राप्त विश्वसनीय है, वास्तविक रूप से मास्टर तरीकों की आवश्यकता है
गुणात्मक विशेषताओं के अध्ययन में प्रतिनिधित्व
गुणात्मक लक्षणों में आमतौर पर अभिव्यक्ति के क्रम नहीं हो सकते हैं: वे या तो मौजूद हैं या प्रत्येक व्यक्ति में मौजूद नहीं हैं, उदाहरण के लिए, लिंग, परागण, किसी भी विशेषता की उपस्थिति या अनुपस्थिति, कुरूपता
शेयरों में अंतर की विश्वसनीयता
नमूना शेयरों के अंतर की विश्वसनीयता उसी तरह निर्धारित की जाती है जैसे साधनों के अंतर के लिए: (10.34)
सहसंबंध गुणांक
कई अध्ययनों में, उनके आपसी संबंधों में कई संकेतों का अध्ययन करना आवश्यक है। यदि हम दो लक्षणों के संबंध में ऐसा अध्ययन करते हैं, तो हम देख सकते हैं कि एक विशेषता की परिवर्तनशीलता नहीं है
सहसंबंध गुणांक त्रुटि
किसी भी नमूना मान की तरह, सहसंबंध गुणांक की अपनी प्रतिनिधित्व त्रुटि होती है, जिसकी गणना सूत्र का उपयोग करके बड़े नमूनों के लिए की जाती है:
नमूना सहसंबंध गुणांक का विश्वास
नमूना सहसंबंध गुणांक की कसौटी सूत्र द्वारा निर्धारित की जाती है: (11.9) जहां:
सहसंबंध गुणांक की विश्वास सीमा
सहसंबंध गुणांक के सामान्य मूल्य की विश्वास सीमाएँ पाई जाती हैं सामान्य तरीके सेसूत्र के अनुसार:
दो सहसंबंध गुणांकों के बीच अंतर की विश्वसनीयता
सहसंबंध गुणांक में अंतर की विश्वसनीयता उसी तरह निर्धारित की जाती है जैसे कि सामान्य सूत्र के अनुसार, साधनों में अंतर की विश्वसनीयता।
सीधी रेखा प्रतिगमन समीकरण
रेक्टिलिनियर सहसंबंध इस मायने में भिन्न है कि कनेक्शन के इस रूप के साथ, पहली विशेषता में समान परिवर्तनों में से प्रत्येक एक अच्छी तरह से परिभाषित और अन्य पीआर में समान औसत परिवर्तन से मेल खाता है।
रेक्टिलिनियर रिग्रेशन समीकरण के तत्वों की त्रुटियां
समीकरण में एक साधारण सीधा रेखीय प्रतिगमन: y = a + bx तीन प्रतिनिधित्व त्रुटियाँ हैं। 1 प्रतिगमन गुणांक त्रुटि:
आंशिक सहसंबंध गुणांक
आंशिक सहसंबंध गुणांक एक संकेतक है जो दो विशेषताओं के संयुग्मन की डिग्री को मापता है जब नियत मानतीसरा। गणितीय आँकड़े आपको एक सहसंबंध स्थापित करने की अनुमति देते हैं
रेखीय बहु समाश्रयण समीकरण
तीन चरों के बीच एक सीधी रेखा संबंध के गणितीय समीकरण को समाश्रयण तल का बहु रेखीय समीकरण कहा जाता है। इसका निम्नलिखित सामान्य रूप है:
सहसंबंध संबंध
यदि अध्ययन के तहत परिघटनाओं के बीच संबंध एक रेखीय से महत्वपूर्ण रूप से विचलित होता है, जिसे ग्राफ से स्थापित करना आसान है, तो संबंध के माप के रूप में सहसंबंध गुणांक अनुपयुक्त है। यह अनुपस्थिति का संकेत दे सकता है
सहसंबंध संबंध गुण
सहसंबंध अनुपात इसके किसी भी रूप में सहसंबंध की डिग्री को मापता है। इसके अलावा, सहसंबंध अनुपात में कई अन्य गुण हैं जो सांख्यिकीय में बहुत रुचि रखते हैं
सहसंबंध अनुपात प्रतिनिधित्व त्रुटि
प्रतिनिधित्व त्रुटि के लिए एक सटीक सूत्र अभी तक विकसित नहीं किया गया है। सहसंबंध संबंध. आमतौर पर पाठ्यपुस्तकों में दिए गए फॉर्मूले में कमियां होती हैं जिन्हें हमेशा नजरअंदाज नहीं किया जा सकता है। यह सूत्र नहीं
सहसंबंध रैखिकता मानदंड
एक रेक्टिलिनियर के लिए एक वक्रतापूर्ण निर्भरता के सन्निकटन की डिग्री निर्धारित करने के लिए, मानदंड F का उपयोग किया जाता है, जिसकी गणना सूत्र द्वारा की जाती है:
फैलाव परिसर
फैलाव परिसर अध्ययन के लिए शामिल डेटा और प्रत्येक ग्रेडेशन (निजी औसत) और संपूर्ण परिसर (सामान्य औसत) के लिए डेटा के औसत के साथ ग्रेडेशन का एक सेट है।
सांख्यिकीय प्रभाव
सांख्यिकीय प्रभाव कारक की विविधता (इसके उन्नयन) की परिणामी विशेषता की विविधता में एक प्रतिबिंब है, जो अध्ययन में आयोजित किया जाता है। नव के प्रभाव का आकलन करने के लिए
तथ्यात्मक प्रभाव
तथ्यात्मक प्रभाव अध्ययन किए गए कारकों का एक सरल या संयुक्त सांख्यिकीय प्रभाव है। एक-कारक परिसरों में, कुछ संगठनात्मक स्तरों पर एक कारक के सरल प्रभाव का अध्ययन किया जाता है।
एक-कारक फैलाव परिसर
विचरण का विश्लेषण अंग्रेजी वैज्ञानिक आर ए फिशर द्वारा कृषि और जैविक अनुसंधान के अभ्यास में विकसित और पेश किया गया था, जिन्होंने माध्य वर्गों के अनुपात के वितरण कानून की खोज की थी।
बहुकारक फैलाव परिसर
का स्पष्ट विचार गणित का मॉडलविचरण का विश्लेषण आवश्यक कम्प्यूटेशनल संचालन को समझना आसान बनाता है, खासकर जब बहुभिन्नरूपी प्रयोगों से डेटा संसाधित करते हैं, जिसमें अधिक होते हैं
परिवर्तनों
प्रायोगिक सामग्री के प्रसंस्करण के लिए विचरण के विश्लेषण का सही उपयोग वेरिएंट (नमूने) के लिए भिन्नता की समरूपता को मानता है, एक सामान्य या इसके करीब वितरण
प्रभावों की ताकत के संकेतक
उनके परिणामों द्वारा प्रभावों की ताकत का निर्धारण जीव विज्ञान में आवश्यक है, कृषि, सबसे अधिक चुनने के लिए दवा प्रभावी साधनएक्सपोजर, भौतिक और रासायनिक एजेंटों की खुराक के लिए - एसटी
प्रभाव की शक्ति के मुख्य संकेतक के प्रतिनिधित्व की त्रुटि
प्रभाव की ताकत के मुख्य संकेतक की त्रुटि का सटीक सूत्र अभी तक नहीं मिला है। एक-कारक परिसरों में, जब प्रतिनिधित्व त्रुटि केवल भाज्य के एक संकेतक के लिए निर्धारित की जाती है
प्रभाव की शक्ति के संकेतकों के मूल्यों को सीमित करें
प्रभाव की शक्ति का मुख्य संकेतक शर्तों के कुल योग से एक पद के हिस्से के बराबर है। इसके अलावा, यह सूचक वर्ग के बराबर हैसहसंबंध संबंध। इन दो कारणों से पावर इंडिकेटर
प्रभावों की विश्वसनीयता
एक चयनात्मक अध्ययन में प्राप्त प्रभाव की शक्ति का मुख्य संकेतक, सबसे पहले, प्रभाव की डिग्री की विशेषता है, जो वास्तव में, अध्ययन की गई वस्तुओं के समूह में खुद को प्रकट करता है।
विभेदक विश्लेषण
विभेदक विश्लेषण बहुभिन्नरूपी सांख्यिकीय विश्लेषण के तरीकों में से एक है। विभेदक विश्लेषण का उद्देश्य विभिन्न विशेषताओं (विशेषताओं, जोड़े .) के मापन के आधार पर है
समस्या कथन, समाधान के तरीके, प्रतिबंध
मान लीजिए कि m विशेषताओं वाली n वस्तुएं हैं। माप के परिणामस्वरूप, प्रत्येक वस्तु को सदिश x1 ... xm, m >1 द्वारा अभिलक्षित किया जाता है। कार्य यह है कि
धारणाएं और प्रतिबंध
विभेदक विश्लेषण कई मान्यताओं के तहत "काम करता है"। यह धारणा कि प्रेक्षित मात्राएँ - वस्तु की मापी गई विशेषताएँ - का सामान्य वितरण होता है। यह
विभेदक विश्लेषण एल्गोरिथम
भेदभाव की समस्याओं (विभेदक विश्लेषण) के समाधान में संपूर्ण नमूना स्थान (सभी बहुआयामी मानी जाने वाली प्राप्तियों का सेट) को विभाजित करना शामिल है। यादृच्छिक चर) कुछ संख्या के लिए
क्लस्टर विश्लेषण
क्लस्टर विश्लेषण वर्गीकरण करने के लिए उपयोग की जाने वाली विभिन्न प्रक्रियाओं को जोड़ता है। इन प्रक्रियाओं को लागू करने के परिणामस्वरूप, वस्तुओं के प्रारंभिक सेट को समूहों या समूहों में विभाजित किया जाता है
क्लस्टर विश्लेषण के तरीके
व्यवहार में, सामूहिक क्लस्टरिंग विधियों को आमतौर पर लागू किया जाता है। आमतौर पर, वर्गीकरण शुरू करने से पहले, डेटा को मानकीकृत किया जाता है (माध्य घटाया जाता है और वर्गमूल को विभाजित किया जाता है)।
क्लस्टर विश्लेषण एल्गोरिथ्म
क्लस्टर विश्लेषण वस्तुओं के बीच की दूरी की अवधारणा की परिभाषा के आधार पर बहुआयामी प्रेक्षणों या वस्तुओं को वर्गीकृत करने के तरीकों का एक समूह है, जिसके बाद उनसे समूहों का चयन किया जाता है, और
बहु सहसंबंध गुणांक की गणना का विशेष महत्व है गुणनखंड x 1 , x 2 ,…, x m , के साथ परिणामी विशेषता yयह निर्धारित करने के लिए सूत्र सामान्य मामलारूप है
जहां r सहसंबंध मैट्रिक्स का निर्धारक है; 11 सहसंबंध मैट्रिक्स के तत्व r yy का बीजगणितीय पूरक है।
यदि केवल दो कारक चिह्नों पर विचार किया जाता है, तो बहु सहसंबंध गुणांक की गणना के लिए निम्न सूत्र का उपयोग किया जा सकता है: 
एक बहु सहसंबंध गुणांक का निर्माण केवल तभी उचित होता है जब आंशिक सहसंबंध गुणांक महत्वपूर्ण हो, और परिणामी विशेषता और मॉडल में शामिल कारकों के बीच संबंध वास्तव में मौजूद हो।
निर्धारण गुणांक
सामान्य सूत्र: R 2 = RSS/TSS=1-ESS/TSSजहां आरएसएस वर्ग विचलन का समझाया गया योग है, ईएसएस वर्ग विचलन का अस्पष्टीकृत (अवशिष्ट) योग है, टीएसएस है कुल राशिवर्ग विचलन (TSS=RSS+ESS)
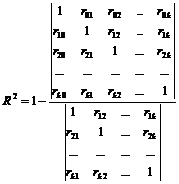 ,
,
जहाँ r ij - प्रतिगामी x i और x j के बीच युग्म सहसंबंध गुणांक, a r i 0 - प्रतिगामी x i और y के बीच युग्म सहसंबंध गुणांक;
- निर्धारण का सही (सामान्यीकृत) गुणांक।
बहु सहसंबंध गुणांक का वर्ग ![]() बुलाया निर्धारण के कई गुणांक; यह दर्शाता है कि परिणामी विशेषता के विचरण का अनुपात क्या है आपकारक चिह्नों x 1, x 2, …, x m के प्रभाव से समझाया गया है। ध्यान दें कि अवशिष्ट और . के अनुपात के माध्यम से निर्धारण के गुणांक की गणना के लिए सूत्र कुल विचरणपरिणामी सुविधा एक ही परिणाम देगी।
बुलाया निर्धारण के कई गुणांक; यह दर्शाता है कि परिणामी विशेषता के विचरण का अनुपात क्या है आपकारक चिह्नों x 1, x 2, …, x m के प्रभाव से समझाया गया है। ध्यान दें कि अवशिष्ट और . के अनुपात के माध्यम से निर्धारण के गुणांक की गणना के लिए सूत्र कुल विचरणपरिणामी सुविधा एक ही परिणाम देगी।
बहु सहसंबंध गुणांक और निर्धारण का गुणांक 0 से 1 तक भिन्न होता है। 1 के करीब, संबंध जितना मजबूत होगा और, तदनुसार, उतना ही सटीक रूप से नीचे निर्मित प्रतिगमन समीकरण निर्भरता का वर्णन करेगा। आप x 1 , x 2 , …, x m से। यदि बहु सहसंबंध गुणांक का मान छोटा है (0.3 से कम), तो इसका मतलब है कि कारक विशेषताओं का चयनित सेट परिणामी विशेषता की भिन्नता का पर्याप्त रूप से वर्णन नहीं करता है, या कारक और परिणाम चर के बीच संबंध गैर-रैखिक है।
एकाधिक सहसंबंध गुणांक की गणना कैलकुलेटर का उपयोग करके की जाती है। एकाधिक सहसंबंध गुणांक और निर्धारण के गुणांक का महत्वफिशर के परीक्षण का उपयोग करके जाँच की गई।
निम्नलिखित में से कौन सी संख्या बहु निर्धारण के गुणांक का मान हो सकती है:
ए) 0.4;
बी) -1;
ग) -2.7;
घ) 2.7।
विभिन्न रैखिक गुणांकसहसंबंध 0.75 है। मॉडल में आश्रित चर y की भिन्नता का कितना प्रतिशत ध्यान में रखा जाता है और यह कारकों x 1 और x 2 के प्रभाव के कारण होता है।
ए) 56.2 (आर 2 = 0.75 2 = 0.5625);
निर्मित मॉडल की गुणवत्ता का मूल्यांकन करें। क्या एक-कारक मॉडल की तुलना में मॉडल की गुणवत्ता में सुधार हुआ है? लोच गुणांक, - और -गुणांक का उपयोग करके परिणाम पर महत्वपूर्ण कारकों के प्रभाव का आकलन करें।
निर्धारण गुणांक आर- हम "रिग्रेशन" (तालिका ") के परिणामों से वर्ग लेते हैं प्रतिगमन आँकड़े» मॉडल (6) के लिए)।
इसलिए, एक अपार्टमेंट की कीमत में भिन्नता (परिवर्तन) यू 76.77% इस समीकरण द्वारा क्षेत्र के शहर की भिन्नता द्वारा समझाया गया है एक्स 1 , अपार्टमेंट में कमरों की संख्या एक्स 2 और रहने की जगह एक्स 4 .
हम मूल डेटा का उपयोग करते हैं यू मैंऔर रिग्रेशन टूल द्वारा पाए गए अवशेष  (मॉडल (6) के लिए तालिका "शेष का निष्कर्ष")। सापेक्ष त्रुटियों की गणना करें और औसत मान ज्ञात करें
(मॉडल (6) के लिए तालिका "शेष का निष्कर्ष")। सापेक्ष त्रुटियों की गणना करें और औसत मान ज्ञात करें  .
.
शेष आहरण
| अवलोकन | भविष्यवाणी Y | खंडहर | रिले. गलती |
| 1 | 45,95089273 | -7,95089273 | 20,92340192 |
| 2 | 86,10296493 | -23,90296493 | 38,42920407 |
| 3 | 94,84442678 | 30,15557322 | 24,12445858 |
| 4 | 84,17648426 | -23,07648426 | 37,76838667 |
| 5 | 40,2537216 | 26,7462784 | 39,91981851 |
| 6 | 68,70572376 | 24,29427624 | 26,12287768 |
| 7 | 143,7464899 | -25,7464899 | 21,81905923 |
| 8 | 106,0907598 | 25,90924022 | 19,62821228 |
| 9 | 135,357993 | -42,85799303 | 46,33296544 |
| 10 | 114,4792566 | -9,47925665 | 9,027863476 |
| 11 | 41,48765602 | 0,512343975 | 1,219866607 |
| 12 | 103,2329236 | 21,76707636 | 17,41366109 |
| 13 | 130,3567798 | 39,64322022 | 23,3195413 |
| 14 | 35,41901876 | 2,580981242 | 6,7920559 |
| 15 | 155,4129693 | -24,91296925 | 19,0903979 |
| 16 | 84,32108188 | 0,678918123 | 0,798727204 |
| 17 | 98,0552279 | -0,055227902 | 0,056355002 |
| 18 | 144,2104618 | -16,21046182 | 12,66442329 |
| 19 | 122,8677535 | -37,86775351 | 44,55029825 |
| 20 | 100,0221225 | 59,97787748 | 37,48617343 |
| 21 | 53,27196558 | 6,728034423 | 11,21339071 |
| 22 | 35,06605378 | 5,933946225 | 14,47303957 |
| 23 | 114,4792566 | -24,47925665 | 27,19917406 |
| 24 | 113,1343153 | -30,13431529 | 36,30640396 |
| 25 | 40,43190991 | 4,568090093 | 10,15131132 |
| 26 | 39,34427892 | -0,344278918 | 0,882766457 |
| 27 | 144,4794501 | -57,57945009 | 66,25943623 |
| 28 | 56,4827667 | -16,4827667 | 41,20691675 |
| 29 | 95,38240332 | -15,38240332 | 19,22800415 |
| 30 | 228,6988826 | -1,698882564 | 0,748406416 |
| 31 | 222,8067278 | 12,19327221 | 5,188626473 |
| 32 | 38,81483144 | 1,185168555 | 2,962921389 |
| 33 | 48,36325811 | 18,63674189 | 27,81603267 |
| 34 | 126,6080021 | -3,608002113 | 2,933335051 |
| 35 | 84,85052935 | 15,14947065 | 15,14947065 |
| 36 | 116,7991162 | -11,79911625 | 11,23725357 |
| 37 | 84,17648426 | -13,87648426 | 19,73895342 |
| 38 | 113,9412801 | -31,94128011 | 38,95278062 |
| 39 | 215,494184 | 64,50581599 | 23,03779142 |
| 40 | 141,7795953 | 58,22040472 | 29,11020236 |
| औसत | 101,2375 | 22,51770962 |
कॉलम के अनुसार सापेक्ष त्रुटियांऔसत मूल्य पाएं =22.51% (औसत फ़ंक्शन का उपयोग करके)।
तुलना से पता चलता है कि 22.51%>7%। इसलिए, मॉडल की सटीकता असंतोषजनक है।
का उपयोग करके एफ - फिशर मानदंड आइए समग्र रूप से मॉडल के महत्व की जांच करें। ऐसा करने के लिए, हम "रिग्रेशन" टूल (तालिका " भिन्नता का विश्लेषण» मॉडल के लिए (6)) एफ= 39,6702.
FDISP फ़ंक्शन का उपयोग करके, हम मान पाते हैं एफ कृ =3.252 महत्व स्तर के लिए α = 5%, और स्वतंत्रता की डिग्री की संख्या क 1 = 2 , क 2 = 37 .
एफ> एफ कृ, इसलिए, मॉडल समीकरण (6) महत्वपूर्ण है, इसका उपयोग समीचीन है, आश्रित चर यूमॉडल (6) में शामिल कारक चर द्वारा काफी अच्छी तरह से वर्णित किया गया है एक्स 1 , एक्स 2. तथा एक्स 4 .
इसके अतिरिक्त उपयोग करना टी -छात्र की कसौटी आइए हम मॉडल के व्यक्तिगत गुणांकों के महत्व की जाँच करें।
टी-प्रतिगमन समीकरण के गुणांकों के लिए आंकड़े "प्रतिगमन" उपकरण के परिणामों में दिए गए हैं। प्राप्त हुआ निम्नलिखित मानचयनित मॉडल (6) के लिए:
| कठिनाइयाँ | मानक त्रुटि | टी आंकड़ा | पी-वैल्यू | नीचे 95% | शीर्ष 95% | कम 95.0% | शीर्ष 95.0% |
|
| वाई-चौराहा | -5,643572321 | 12,07285417 | -0,46745966 | 0,642988 | -30,1285 | 18,84131 | -30,1285 | 18,84131 |
| X4 | 2,591405557 | 0,461440597 | 5,61590284 | 2.27ई-06 | 1,655561 | 3,52725 | 1,655561 | 3,52725 |
| X1 | 6,85963077 | 9,185748512 | 0,74676884 | 0,460053 | -11,7699 | 25,48919 | -11,7699 | 25,48919 |
| X2 | -1,985156991 | 7,795346067 | -0,25465925 | 0,800435 | -17,7949 | 13,82454 | -17,7949 | 13,82454 |
महत्वपूर्ण मान टी कृमहत्व स्तर के लिए पाया गया α=5%और स्वतंत्रता की डिग्री की संख्या क=40–2–1=37 . टी कृ =2.026 (फ़ंक्शन स्टूड्रेस्पो)।
मुक्त गुणांक के लिए α
=–5.643
परिभाषित आंकड़े  ,
,  टी कृ, इसलिए, मुक्त गुणांक महत्वपूर्ण नहीं है, इसे मॉडल से बाहर रखा जा सकता है।
टी कृ, इसलिए, मुक्त गुणांक महत्वपूर्ण नहीं है, इसे मॉडल से बाहर रखा जा सकता है।
प्रतिगमन गुणांक के लिए β
1
=6.859
परिभाषित आंकड़े  ,
,  β
1
महत्वपूर्ण नहीं है, इसे और क्षेत्र के शहर के कारक को मॉडल से हटाया जा सकता है।
β
1
महत्वपूर्ण नहीं है, इसे और क्षेत्र के शहर के कारक को मॉडल से हटाया जा सकता है।
प्रतिगमन गुणांक के लिए β
2
=-1,985
परिभाषित आंकड़े  ,
,  टी कृ, इसलिए प्रतिगमन गुणांक β
2
महत्वपूर्ण नहीं है, यह और अपार्टमेंट में कमरों की संख्या के कारक को मॉडल से बाहर रखा जा सकता है।
टी कृ, इसलिए प्रतिगमन गुणांक β
2
महत्वपूर्ण नहीं है, यह और अपार्टमेंट में कमरों की संख्या के कारक को मॉडल से बाहर रखा जा सकता है।
प्रतिगमन गुणांक के लिए β
4
=2.591
परिभाषित आंकड़े  ,
,  >t करोड़, इसलिए, प्रतीपगमन गुणांक β
4
महत्वपूर्ण है, यह और अपार्टमेंट के रहने वाले क्षेत्र का कारक मॉडल में संग्रहीत किया जा सकता है।
>t करोड़, इसलिए, प्रतीपगमन गुणांक β
4
महत्वपूर्ण है, यह और अपार्टमेंट के रहने वाले क्षेत्र का कारक मॉडल में संग्रहीत किया जा सकता है।
मॉडल के गुणांकों के महत्व के बारे में निष्कर्ष महत्व के स्तर पर किए जाते हैं α=5%. "पी-वैल्यू" कॉलम को ध्यान में रखते हुए, ध्यान दें कि मुक्त गुणांक α 0.64 = 64% के स्तर पर महत्वपूर्ण माना जा सकता है; प्रतिगमन गुणांक β 1 - 0.46 = 46% के स्तर पर; प्रतिगमन गुणांक β 2 - 0.8 = 80% के स्तर पर; और प्रतिगमन गुणांक β 4 - 2.27ई-06 = 2.26691790951854 ई-06 = 0.0000002% के स्तर पर।
समीकरण में नए कारक चर जोड़ने पर, निर्धारण का गुणांक स्वतः बढ़ जाता है आर 2
और घटता है मतलब त्रुटिसन्निकटन, हालांकि यह हमेशा मॉडल की गुणवत्ता में सुधार नहीं करता है। इसलिए, मॉडल (3) और चयनित एकाधिक मॉडल (6) की गुणवत्ता की तुलना करने के लिए, हम सामान्यीकृत निर्धारण गुणांक का उपयोग करते हैं।
इस प्रकार, प्रतिगमन समीकरण में कारक "क्षेत्र का शहर" जोड़ते समय एक्स 1 और कारक "अपार्टमेंट में कमरों की संख्या" एक्स 2, मॉडल की गुणवत्ता खराब हो गई है, जो कारकों को हटाने के पक्ष में बोलती है एक्स 1 और एक्समॉडल से 2.
आइए आगे की गणना करें।
लोच के औसत गुणांक
एक रैखिक मॉडल के मामले में सूत्रों द्वारा निर्धारित किया जाता है  .
.
AVERAGE फ़ंक्शन का उपयोग करते हुए, हम पाते हैं: S यू, केवल कारक में वृद्धि के साथ एक्स 4 उसके एक के लिए मानक विचलन- 0.914 . की वृद्धि एस यू
डेल्टा गुणांक
सूत्रों द्वारा परिभाषित किया गया है  .
.
आइए एक्सेल में "डेटा विश्लेषण" पैकेज के "सहसंबंध" टूल का उपयोग करके जोड़ी सहसंबंध गुणांक खोजें।
| यू | X1 | X2 | X4 |
|
| यू | 1 | |||
| X1 | -0,01126 | 1 | ||
| X2 | 0,751061 | -0,0341 | 1 | |
| X4 | 0,874012 | -0,0798 | 0,868524 | 1 |
निर्धारण का गुणांक पहले निर्धारित किया गया था और 0.7677 के बराबर है।
आइए डेल्टा गुणांक की गणना करें:
 ;
; 

1 . के बाद से 1
तथा एक्स 2
खराब तरीके से चुना गया है, और उन्हें मॉडल से निकालने की आवश्यकता है। इसलिए, प्राप्त रैखिक तीन-कारक मॉडल के समीकरण के अनुसार, परिणामी कारक में परिवर्तन यू(अपार्टमेंट की कीमत) कारक के प्रभाव के कारण 104% है एक्स 4
(अपार्टमेंट का रहने का क्षेत्र), कारक के प्रभाव से 4% तक एक्स 2
(कमरों की संख्या), कारक के प्रभाव से 0.0859% तक एक्स 1
(क्षेत्र का शहर)।
जटिल घटनाओं का अध्ययन करते समय, दो से अधिक यादृच्छिक कारकों को ध्यान में रखा जाना चाहिए। इन कारकों के बीच संबंध की प्रकृति का एक सही विचार तभी प्राप्त किया जा सकता है जब सभी माने गए यादृच्छिक कारकों की एक ही बार में जांच की जाए। तीन या अधिक यादृच्छिक कारकों का एक संयुक्त अध्ययन शोधकर्ता को अध्ययन की गई घटनाओं के बीच कारण संबंधों के बारे में कम या ज्यादा उचित मान्यताओं को स्थापित करने की अनुमति देगा। एकाधिक संबंधों का एक सरल रूप तीन विशेषताओं के बीच एक रैखिक संबंध है। यादृच्छिक कारकों को के रूप में दर्शाया गया है एक्स 1 , एक्स 2 और एक्स 3. के बीच जोड़ीवार सहसंबंध गुणांक एक्स 1 और एक्स 2 को के रूप में दर्शाया गया है आर 12 , क्रमशः . के बीच एक्स 1 और एक्स 3 - आर 12, बीच एक्स 2 और एक्स 3 - आर 23. तीन विशेषताओं के रैखिक संबंध की जकड़न के माप के रूप में, कई सहसंबंध गुणांक का उपयोग किया जाता है, निरूपित आर 1-23, आर 2 13, आर 3 ּ 12 और आंशिक सहसंबंध गुणांक निरूपित आर 12.3 , आर 13.2 , आर 23.1 .
तीन कारकों में से कई सहसंबंध गुणांक आर 1.23 कारकों में से एक (बिंदु से पहले सूचकांक) और दो अन्य कारकों (बिंदु के बाद सूचकांक) के संयोजन के बीच एक रैखिक संबंध की निकटता का संकेतक है।
गुणांक R का मान हमेशा 0 से 1 की सीमा में होता है। जैसे ही R एक के करीब पहुंचता है, तीन विशेषताओं के रैखिक संबंध की डिग्री बढ़ जाती है।
एकाधिक सहसंबंध गुणांक के बीच, उदाहरण के लिए आर 2 ּ 13 , और दो जोड़ी सहसंबंध गुणांक आर 12 और आर 23 एक संबंध है: प्रत्येक युग्म गुणांक निरपेक्ष मान से अधिक नहीं हो सकता आर 2 13.
जोड़ी सहसंबंध गुणांक r 12 , r 13 और r 23 के ज्ञात मूल्यों के साथ कई सहसंबंध गुणांक की गणना के लिए सूत्र हैं:
बहु सहसंबंध गुणांक का वर्ग आर 2 कहा जाता है एकाधिक निर्धारण का गुणांक।यह अध्ययन किए गए कारकों के प्रभाव में आश्रित चर में भिन्नता के अनुपात को दर्शाता है।
बहु सहसंबंध के महत्व का अनुमान लगाया जाता है एफ- मानदंड:
![]()
एन-नमूने का आकार; क-कारकों की संख्या। हमारे मामले में क = 3.
जनसंख्या में शून्य से बहु सहसंबंध गुणांक की समानता के बारे में शून्य परिकल्पना ( एच ओ:आर= 0) स्वीकार किया जाता है यदि एफएफ<च तो, और अस्वीकार कर दिया जाता है यदि
एफच एफटी।
सैद्धांतिक मूल्य एफ-मानदंड परिभाषित किया गया है वी 1 = क- 1 और वी 2 = एन - कस्वतंत्रता की डिग्री और महत्व के स्वीकृत स्तर (परिशिष्ट 1)।
बहु सहसंबंध गुणांक की गणना का एक उदाहरण. कारकों के बीच संबंध का अध्ययन करते समय, युग्म सहसंबंध गुणांक प्राप्त किए गए थे ( एन =15): आर 12 ==0.6; आर 13 = 0.3; आर 23 = - 0,2.
संकेत की निर्भरता का पता लगाना आवश्यक है एक्स 2 ऑफ साइन एक्स 1 और एक्स 3 , यानी बहु सहसंबंध गुणांक की गणना करें:

तालिका मूल्य एफ n 1 = 2 और n 2 = 15 - 3 = 12 डिग्री पर स्वतंत्रता का मानदंड = 0.05 एफ 0.05 = 3.89 और a = 0.01 . पर एफ 0,01 = 6,93.
इस प्रकार, सुविधाओं के बीच संबंध आर 2.13 = 0.74 पर सार्थक
1% महत्व स्तर एफच > एफ 0,01 .
एकाधिक निर्धारण के गुणांक को देखते हुए आर 2 = (0.74) 2 = 0.55, विशेषता भिन्नता एक्स 2 अध्ययन किए गए कारकों के प्रभाव से संबंधित 55% है, और 45% भिन्नता (1-R 2) को इन चरों के प्रभाव से नहीं समझाया जा सकता है।
आंशिक रैखिक सहसंबंध
आंशिक सहसंबंध गुणांकएक संकेतक है जो दो विशेषताओं के संयुग्मन की डिग्री को मापता है।
गणितीय आंकड़े आपको एक विशेष प्रयोग स्थापित किए बिना, लेकिन युग्मित सहसंबंध गुणांक का उपयोग किए बिना, तीसरे के निरंतर मूल्य के साथ दो विशेषताओं के बीच संबंध स्थापित करने की अनुमति देते हैं। आर 12 , आर 13 , आर 23 .
आंशिक सहसंबंध गुणांक की गणना सूत्रों का उपयोग करके की जाती है:

डॉट से पहले की संख्याएं इंगित करती हैं कि किन विशेषताओं के बीच निर्भरता का अध्ययन किया जा रहा है, और डॉट के बाद की संख्या इंगित करती है कि किस सुविधा के प्रभाव को बाहर रखा गया है (समाप्त)। आंशिक सहसंबंध के महत्व की त्रुटि और मानदंड समान सूत्रों द्वारा निर्धारित किए जाते हैं जैसे कि जोड़ीदार सहसंबंध के लिए:
 .
.
सैद्धांतिक मूल्य टी-के लिए मानदंड निर्धारित किया गया है वी = एन- स्वतंत्रता की 2 डिग्री और स्वीकृत महत्व स्तर ए (परिशिष्ट 1)।
शून्य में कुल मिलाकर आंशिक सहसंबंध गुणांक की समानता के बारे में शून्य परिकल्पना ( हो: आर= 0) स्वीकार किया जाता है यदि टीएफ< टी t, और अस्वीकार कर दिया जाता है यदि
टीच टीटी।
आंशिक गुणांक -1 और +1 के बीच मान ले सकते हैं। निजी निर्धारण गुणांकआंशिक सहसंबंध गुणांकों को चुकता करके पाया जाता है:
डी 12.3 = आर 2 12ּ3 ;डी 13.2 = आर 2 13ּ2 ;डी 23ּ1 =आर 2 23ּ1।
परिणामी विशेषता पर अलग-अलग कारकों के विशेष प्रभाव की डिग्री निर्धारित करना, जबकि इस सहसंबंध को विकृत करने वाली अन्य विशेषताओं के साथ इसके संबंध को बाहर करना (समाप्त करना) अक्सर बहुत रुचि का होता है। कभी-कभी ऐसा होता है कि समाप्त विशेषता के निरंतर मूल्य के साथ, अन्य लक्षणों की परिवर्तनशीलता पर इसके सांख्यिकीय प्रभाव को नोटिस करना असंभव है। आंशिक सहसंबंध गुणांक की गणना के लिए तकनीक को समझने के लिए, एक उदाहरण पर विचार करें। तीन विकल्प हैं एक्स, यूतथा जेड. नमूना आकार के लिए एन= 180 युग्मित सहसंबंध गुणांक निर्धारित
आरएक्सवाई = 0,799; rxz = 0,57; आर yz = 0,507.
आइए आंशिक सहसंबंध गुणांक परिभाषित करें:

पैरामीटर के बीच आंशिक सहसंबंध गुणांक एक्सतथा यू जेड (आर xyz = 0.720) से पता चलता है कि समग्र सहसंबंध में इन विशेषताओं के संबंध का केवल एक छोटा सा हिस्सा ( आरएक्सवाई= 0.799) तीसरी विशेषता के प्रभाव के कारण है ( जेड) पैरामीटर के बीच आंशिक सहसंबंध गुणांक के संबंध में एक समान निष्कर्ष निकाला जाना चाहिए एक्सऔर पैरामीटर जेडनिरंतर पैरामीटर मान के साथ यू (आरएक्स जेड y = 0.318 और rxz= 0.57)। इसके विपरीत, मापदंडों के बीच आंशिक सहसंबंध गुणांक यूतथा जेडनिरंतर पैरामीटर मान के साथ एक्स आर yz ּ एक्स= 0.105 समग्र सहसंबंध गुणांक r . से काफी अलग है जेड = 0.507. इससे यह देखा जा सकता है कि यदि आप समान पैरामीटर मान वाली वस्तुओं का चयन करते हैं एक्स, फिर सुविधाओं के बीच संबंध यूतथा जेडवे बहुत कमजोर होंगे, क्योंकि इस संबंध का एक महत्वपूर्ण हिस्सा पैरामीटर की भिन्नता के कारण है एक्स.
कुछ परिस्थितियों में, आंशिक सहसंबंध गुणांक युग्मित एक के संकेत में विपरीत हो सकता है।
उदाहरण के लिए, सुविधाओं के बीच संबंध का अध्ययन करते समय एक्स, वाईतथा जेड- युग्मित सहसंबंध गुणांक प्राप्त किए गए (साथ .) एन = 100): आरएक्सवाई = 0.6; आरएक्स जेड= 0,9;
आर जेड = 0,4.
तीसरी विशेषता के प्रभाव को छोड़कर आंशिक सहसंबंध गुणांक:

उदाहरण से पता चलता है कि मान जोड़ी गुणांकऔर आंशिक सहसंबंध गुणांक संकेत में भिन्न होता है।
आंशिक सहसंबंध विधि दूसरे क्रम के आंशिक सहसंबंध गुणांक की गणना करना संभव बनाती है। यह गुणांक तीसरे और चौथे के स्थिर मान के साथ पहली और दूसरी विशेषता के बीच संबंध को इंगित करता है। दूसरा क्रम आंशिक गुणांक सूत्र के अनुसार पहले क्रम के आंशिक गुणांक के आधार पर निर्धारित किया जाता है:

कहाँ पे आर 12 . 4 , आर 13-4, आर 23 ּ4 - आंशिक गुणांक, जिसका मान आंशिक गुणांक सूत्र द्वारा निर्धारित किया जाता है, जोड़ी सहसंबंध गुणांक का उपयोग करके आर 12 , आर 13 , आर 14 , आर 23 , आर 24 , आर 34 .
प्रतिगमन विश्लेषण- यह एक सांख्यिकीय शोध पद्धति है जो आपको एक या अधिक स्वतंत्र चर पर एक पैरामीटर की निर्भरता दिखाने की अनुमति देती है। प्री-कंप्यूटर युग में, इसका उपयोग काफी कठिन था, खासकर जब यह बड़ी मात्रा में डेटा की बात आती थी। आज, एक्सेल में रिग्रेशन बनाने का तरीका जानने के बाद, आप कॉम्प्लेक्स को हल कर सकते हैं सांख्यिकीय कार्यसचमुच कुछ ही मिनटों में। अर्थशास्त्र के क्षेत्र से विशिष्ट उदाहरण नीचे दिए गए हैं।
प्रतिगमन के प्रकार
इस अवधारणा को ही 1886 में गणित में पेश किया गया था। प्रतिगमन होता है:
- रैखिक;
- परवलयिक;
- शक्ति;
- घातीय;
- अतिपरवलिक;
- प्रदर्शनकारी;
- लघुगणक
उदाहरण 1
सेवानिवृत्त टीम के सदस्यों की संख्या की निर्भरता का निर्धारण करने की समस्या पर विचार करें औसत वेतन 6 औद्योगिक उद्यमों में।
एक कार्य। छह उद्यमों ने औसत मासिक का विश्लेषण किया वेतनऔर छोड़ने वाले कर्मचारियों की संख्या अपनी मर्जी. सारणीबद्ध रूप में हमारे पास है:
छोड़ने वालों की संख्या | वेतन |
||
30000 रूबल |
|||
35000 रूबल |
|||
40000 रूबल |
|||
45000 रूबल |
|||
50000 रूबल |
|||
55000 रूबल |
|||
60000 रूबल |
6 उद्यमों में औसत वेतन पर सेवानिवृत्त श्रमिकों की संख्या की निर्भरता निर्धारित करने की समस्या के लिए, प्रतिगमन मॉडल में समीकरण Y = a 0 + a 1 x 1 +…+a k x k का रूप होता है, जहां x i प्रभावित करने वाले चर हैं , a i प्रतिगमन गुणांक हैं, a k कारकों की संख्या है।
इस कार्य के लिए, Y छोड़ने वाले कर्मचारियों का संकेतक है, और प्रभावित करने वाला कारक वेतन है, जिसे हम X से दर्शाते हैं।
स्प्रेडशीट "एक्सेल" की क्षमताओं का उपयोग करना
एक्सेल में रिग्रेशन विश्लेषण उपलब्ध सारणीबद्ध डेटा के लिए अंतर्निहित कार्यों के आवेदन से पहले होना चाहिए। हालांकि, इन उद्देश्यों के लिए, बहुत उपयोगी ऐड-इन "विश्लेषण टूलकिट" का उपयोग करना बेहतर है। इसे सक्रिय करने के लिए आपको चाहिए:
- "फ़ाइल" टैब से, "विकल्प" अनुभाग पर जाएं;
- खुलने वाली विंडो में, "ऐड-ऑन" लाइन का चयन करें;
- "प्रबंधन" लाइन के दाईं ओर नीचे स्थित "गो" बटन पर क्लिक करें;
- "विश्लेषण पैकेज" नाम के बगल में स्थित बॉक्स को चेक करें और "ओके" पर क्लिक करके अपने कार्यों की पुष्टि करें।
यदि सब कुछ सही ढंग से किया जाता है, तो वांछित बटन एक्सेल वर्कशीट के ऊपर स्थित डेटा टैब के दाईं ओर दिखाई देगा।
एक्सेल में
अब जब हमारे पास अर्थमितीय गणना करने के लिए सभी आवश्यक आभासी उपकरण हैं, तो हम अपनी समस्या को हल करना शुरू कर सकते हैं। इसके लिए:
- "डेटा विश्लेषण" बटन पर क्लिक करें;
- खुलने वाली विंडो में, "रिग्रेशन" बटन पर क्लिक करें;
- दिखाई देने वाले टैब में, Y (छोड़ने वाले कर्मचारियों की संख्या) और X (उनका वेतन) के लिए मानों की श्रेणी दर्ज करें;
- हम "ओके" बटन दबाकर अपने कार्यों की पुष्टि करते हैं।
परिणामस्वरूप, प्रोग्राम स्वचालित रूप से प्रतिगमन विश्लेषण डेटा के साथ स्प्रेडशीट की एक नई शीट को पॉप्युलेट करेगा। टिप्पणी! एक्सेल में इस उद्देश्य के लिए आपके द्वारा पसंद किए जाने वाले स्थान को मैन्युअल रूप से सेट करने की क्षमता है। उदाहरण के लिए, यह वही शीट हो सकती है जहां वाई और एक्स मान हैं, या यहां तक कि एक नई किताब, विशेष रूप से ऐसे डेटा को संग्रहीत करने के लिए डिज़ाइन किया गया है।
आर-स्क्वायर के लिए प्रतिगमन परिणामों का विश्लेषण
एक्सेल में, माना उदाहरण के डेटा के प्रसंस्करण के दौरान प्राप्त डेटा इस तरह दिखता है:
सबसे पहले आपको आर-स्क्वायर की वैल्यू पर ध्यान देना चाहिए। यह निर्धारण का गुणांक है। इस उदाहरण में, आर-वर्ग = 0.755 (75.5%), यानी, मॉडल के परिकलित पैरामीटर 75.5% द्वारा माने गए मापदंडों के बीच संबंध की व्याख्या करते हैं। निर्धारण गुणांक का मान जितना अधिक होगा, किसी विशेष कार्य के लिए चुना गया मॉडल उतना ही अधिक लागू होगा। ऐसा माना जाता है कि यह 0.8 से ऊपर के आर-वर्ग मान के साथ वास्तविक स्थिति का सही वर्णन करता है। अगर R-वर्ग<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
अनुपात विश्लेषण
संख्या 64.1428 दर्शाती है कि Y का मान क्या होगा यदि हम जिस मॉडल पर विचार कर रहे हैं उसमें सभी चर xi शून्य पर सेट हैं। दूसरे शब्दों में, यह तर्क दिया जा सकता है कि विश्लेषण किए गए पैरामीटर का मूल्य अन्य कारकों से भी प्रभावित होता है जो किसी विशिष्ट मॉडल में वर्णित नहीं हैं।
सेल B18 में स्थित अगला गुणांक -0.16285, Y पर चर X के प्रभाव के भार को दर्शाता है। इसका मतलब है कि विचाराधीन मॉडल के भीतर कर्मचारियों का औसत मासिक वेतन -0.16285 के वजन के साथ छोड़ने वालों की संख्या को प्रभावित करता है, अर्थात। इसके प्रभाव की डिग्री बिल्कुल छोटी है। "-" चिह्न इंगित करता है कि गुणांक का ऋणात्मक मान है। यह स्पष्ट है, क्योंकि हर कोई जानता है कि उद्यम में वेतन जितना अधिक होता है, उतने ही कम लोग रोजगार अनुबंध को समाप्त करने या छोड़ने की इच्छा व्यक्त करते हैं।
एकाधिक प्रतिगमन
यह शब्द फॉर्म के कई स्वतंत्र चर के साथ एक कनेक्शन समीकरण को संदर्भित करता है:
y \u003d f (x 1 + x 2 + ... x m) + , जहां y प्रभावी विशेषता (आश्रित चर) है, और x 1 , x 2 , ... x m कारक कारक (स्वतंत्र चर) हैं।
पैरामीटर अनुमान
के लिये एकाधिक प्रतिगमन(MR) यह कम से कम वर्गों (LSM) की विधि का उपयोग करके किया जाता है। Y = a + b 1 x 1 +…+b m x m + के रूप के रैखिक समीकरणों के लिए, हम सामान्य समीकरणों की एक प्रणाली का निर्माण करते हैं (नीचे देखें)

विधि के सिद्धांत को समझने के लिए, दो-कारक मामले पर विचार करें। तब हमारे पास सूत्र द्वारा वर्णित स्थिति होती है

यहाँ से हमें मिलता है:

जहां सूचकांक में परिलक्षित संबंधित विशेषता का प्रसरण है।
एलएसएम एक मानक पैमाने पर एमपी समीकरण पर लागू होता है। इस मामले में, हमें समीकरण मिलता है:

जहाँ t y , t x 1,… t xm मानकीकृत चर हैं जिनके लिए माध्य मान 0 हैं; β मैं मानकीकृत प्रतिगमन गुणांक हैं, और मानक विचलन 1 है।
कृपया ध्यान दें कि इस मामले में सभी β i को सामान्यीकृत और केंद्रीकृत के रूप में सेट किया गया है, इसलिए एक दूसरे के साथ उनकी तुलना को सही और स्वीकार्य माना जाता है। इसके अलावा, यह βi के सबसे छोटे मूल्यों वाले कारकों को छोड़कर, कारकों को फ़िल्टर करने के लिए प्रथागत है।
रैखिक प्रतिगमन समीकरण का उपयोग करने में समस्या
मान लीजिए कि पिछले 8 महीनों के दौरान किसी विशेष उत्पाद एन की कीमत की गतिशीलता की एक तालिका है। 1850 रूबल / टी की कीमत पर इसके बैच को खरीदने की सलाह पर निर्णय लेना आवश्यक है।
माह संख्या | महीने का नाम | आइटम नंबर की कीमत |
|
1750 रूबल प्रति टन |
|||
1755 रूबल प्रति टन |
|||
1767 रूबल प्रति टन |
|||
1760 रूबल प्रति टन |
|||
1770 रूबल प्रति टन |
|||
1790 रूबल प्रति टन |
|||
1810 रूबल प्रति टन |
|||
1840 रूबल प्रति टन |
|||
एक्सेल स्प्रेडशीट में इस समस्या को हल करने के लिए, आपको उपरोक्त उदाहरण से पहले से ज्ञात डेटा विश्लेषण टूल का उपयोग करने की आवश्यकता है। अगला, "रिग्रेशन" अनुभाग चुनें और पैरामीटर सेट करें। यह याद रखना चाहिए कि "इनपुट अंतराल Y" फ़ील्ड में, आश्रित चर के लिए मानों की एक श्रेणी (इस मामले में, वर्ष के विशिष्ट महीनों में उत्पाद की कीमत) दर्ज की जानी चाहिए, और "इनपुट" में अंतराल X" - स्वतंत्र चर (माह संख्या) के लिए। "ओके" पर क्लिक करके कार्रवाई की पुष्टि करें। एक नई शीट पर (यदि ऐसा संकेत दिया गया था), हमें प्रतिगमन के लिए डेटा मिलता है।
उनके आधार पर, हम y=ax+b फॉर्म का एक रैखिक समीकरण बनाते हैं, जहां पैरामीटर ए और बी महीने की संख्या के नाम के साथ पंक्ति के गुणांक हैं और गुणांक और "वाई-चौराहे" पंक्ति से प्रतिगमन विश्लेषण के परिणामों के साथ शीट। इस प्रकार, समस्या 3 के लिए रैखिक समाश्रयण समीकरण (LE) को इस प्रकार लिखा जाता है:
उत्पाद की कीमत एन = 11.714* माह संख्या + 1727.54।
या बीजीय संकेतन में
वाई = 11.714 एक्स + 1727.54
परिणामों का विश्लेषण
यह तय करने के लिए कि परिणामी रैखिक प्रतिगमन समीकरण पर्याप्त है, एकाधिक सहसंबंध गुणांक (एमसीसी) और निर्धारण गुणांक का उपयोग किया जाता है, साथ ही फिशर का परीक्षण और छात्र का परीक्षण। प्रतिगमन परिणामों के साथ एक्सेल तालिका में, वे क्रमशः एकाधिक आर, आर-वर्ग, एफ-सांख्यिकी और टी-सांख्यिकी के नामों के तहत दिखाई देते हैं।
केएमसी आर स्वतंत्र और आश्रित चर के बीच संभाव्य संबंध की मजबूती का आकलन करना संभव बनाता है। इसका उच्च मूल्य चर "महीने की संख्या" और "माल की कीमत एन प्रति 1 टन रूबल में" के बीच काफी मजबूत संबंध को इंगित करता है। हालाँकि, इस रिश्ते की प्रकृति अज्ञात बनी हुई है।
निर्धारण गुणांक का वर्ग R 2 (RI) कुल प्रकीर्णन के हिस्से की एक संख्यात्मक विशेषता है और प्रयोगात्मक डेटा के किस भाग के बिखराव को दर्शाता है, अर्थात। आश्रित चर के मान रैखिक प्रतिगमन समीकरण से मेल खाते हैं। विचाराधीन समस्या में, यह मान 84.8% के बराबर है, अर्थात्, प्राप्त एसडी द्वारा सांख्यिकीय डेटा को उच्च स्तर की सटीकता के साथ वर्णित किया गया है।
एफ-सांख्यिकी, जिसे फिशर का परीक्षण भी कहा जाता है, का उपयोग एक रैखिक संबंध के महत्व का आकलन करने के लिए किया जाता है, इसके अस्तित्व की परिकल्पना का खंडन या पुष्टि करता है।
(छात्र की कसौटी) एक रैखिक संबंध के अज्ञात या मुक्त पद के साथ गुणांक के महत्व का मूल्यांकन करने में मदद करता है। यदि t-मानदंड का मान > t करोड़, तो मुक्त पद के महत्व की परिकल्पना रेखीय समीकरणअस्वीकृत।
मुक्त सदस्य के लिए विचाराधीन समस्या में, एक्सेल टूल्स का उपयोग करके, यह प्राप्त किया गया था कि t = 169.20903, और p = 2.89E-12, यानी, हमारे पास एक शून्य संभावना है कि स्वतंत्र सदस्य के महत्व के बारे में सही परिकल्पना होगी खारिज किया जाए। अज्ञात t=5.79405, और p=0.001158 पर गुणांक के लिए। दूसरे शब्दों में, अज्ञात के लिए गुणांक के महत्व के बारे में सही परिकल्पना के खारिज होने की संभावना 0.12% है।
इस प्रकार, यह तर्क दिया जा सकता है कि परिणामी रैखिक प्रतिगमन समीकरण पर्याप्त है।
शेयरों का एक ब्लॉक खरीदने की समीचीनता की समस्या
एक्सेल में मल्टीपल रिग्रेशन एक ही डेटा एनालिसिस टूल का उपयोग करके किया जाता है। एक विशिष्ट लागू समस्या पर विचार करें।
NNN के प्रबंधन को MMM SA में 20% हिस्सेदारी खरीदने की उपयुक्तता पर निर्णय लेना चाहिए। पैकेज की लागत (जेवी) 70 मिलियन अमेरिकी डॉलर है। एनएनएन विशेषज्ञों ने समान लेनदेन पर डेटा एकत्र किया। लाखों अमेरिकी डॉलर में व्यक्त किए गए ऐसे मापदंडों के अनुसार शेयरों के ब्लॉक के मूल्य का मूल्यांकन करने का निर्णय लिया गया, जैसे:
- देय खाते (वीके);
- वार्षिक कारोबार (वीओ);
- प्राप्य खाते (वीडी);
- अचल संपत्तियों की लागत (एसओएफ)।
इसके अलावा, हजारों अमेरिकी डॉलर में उद्यम (V3 P) के पैरामीटर पेरोल बकाया का उपयोग किया जाता है।
एक्सेल स्प्रेडशीट का उपयोग कर समाधान
सबसे पहले, आपको प्रारंभिक डेटा की एक तालिका बनाने की आवश्यकता है। यह इस तरह दिख रहा है:

- "डेटा विश्लेषण" विंडो को कॉल करें;
- "प्रतिगमन" अनुभाग का चयन करें;
- बॉक्स में "इनपुट अंतराल वाई" कॉलम जी से आश्रित चर के मूल्यों की श्रेणी दर्ज करें;
- "इनपुट अंतराल एक्स" बॉक्स के दाईं ओर एक लाल तीर के साथ आइकन पर क्लिक करें और शीट पर सभी मानों की एक श्रेणी का चयन करें कॉलम बी, सी, डी, एफ।
"नई वर्कशीट" चुनें और "ओके" पर क्लिक करें।
दी गई समस्या के लिए प्रतिगमन विश्लेषण प्राप्त करें।

परिणामों और निष्कर्षों की जांच
एक्सेल स्प्रेडशीट शीट पर ऊपर प्रस्तुत गोल डेटा से "हम एकत्र करते हैं", प्रतिगमन समीकरण:
एसपी \u003d 0.103 * एसओएफ + 0.541 * वीओ - 0.031 * वीके + 0.405 * वीडी + 0.691 * वीजेडपी - 265.844।
अधिक परिचित गणितीय रूप में, इसे इस प्रकार लिखा जा सकता है:
वाई = 0.103*x1 + 0.541*x2 - 0.031*x3 +0.405*x4 +0.691*x5 - 265.844
JSC "MMM" के लिए डेटा तालिका में प्रस्तुत किया गया है:
उन्हें प्रतिगमन समीकरण में प्रतिस्थापित करने पर, उन्हें 64.72 मिलियन अमेरिकी डॉलर का आंकड़ा मिलता है। इसका मतलब है कि जेएससी एमएमएम के शेयर नहीं खरीदे जाने चाहिए, क्योंकि उनका मूल्य 70 मिलियन अमेरिकी डॉलर अधिक है।
जैसा कि आप देख सकते हैं, एक्सेल स्प्रेडशीट और रिग्रेशन समीकरण के उपयोग ने एक बहुत ही विशिष्ट लेनदेन की व्यवहार्यता के बारे में एक सूचित निर्णय लेना संभव बना दिया है।
अब आप जानते हैं कि प्रतिगमन क्या है। एक्सेल में ऊपर चर्चा किए गए उदाहरण आपको निर्णय लेने में मदद करेंगे। व्यावहारिक कार्यअर्थमिति के क्षेत्र से।
