Біноміальний закон розподілу. Біноміальний розподіл
На відміну від нормального та рівномірного розподілу, Які описують поведінка змінної в досліджуваній вибірці піддослідних, біноміальний розподіл використовується для інших цілей. Воно служить для прогнозування ймовірності двох взаємовиключних подій у деяких незалежних один від одного випробувань. Класичний приклад біномного розподілу – підкидання монети, що падає на тверду поверхню. Рівноймовірні два результати (події): 1) монета падає «орлом» (імовірність дорівнює р) або 2) монета падає «решкою» (імовірність дорівнює q). Якщо третього результату не дано, то p = q= 0,5 та p + q= 1. Використовуючи формулу біномного розподілу, можна визначити, наприклад, яка ймовірність того, що у 50 випробуваннях (число підкидань монети) остання випаде «орлом», припустимо, 25 разів.
Для подальших міркувань введемо загальноприйняті позначення:
n – загальне числоспостережень;
i- Число цікавлять нас подій (виходів);
n – i- Число альтернативних подій;
p– емпірично визначена (іноді – передбачувана) ймовірність цікавої для нас події;
q- Можливість альтернативної події;
P n ( i) – прогнозована ймовірність цікавої для нас події iза певною кількістю спостережень n.
Формула біномного розподілу:
У разі рівноймовірного результату подій ( p = q) можна використовувати спрощену формулу:
![]() (6.8)
(6.8)
Розглянемо три приклади, що ілюструють використання формул біномного розподілу у психологічних дослідженнях.
Приклад 1
Припустимо, що 3 студенти вирішують завдання підвищеної складності. Для кожного з них рівноймовірні 2 результати: (+) – розв'язання та (-) – нерозв'язання задачі. Усього можливе 8 різних результатів (2 3 = 8).
Імовірність того, що жоден студент не впорається із завданням, дорівнює 1/8 (варіант 8); 1 студент впорається із завданням: P= 3/8 (варіанти 4, 6, 7); 2 студенти – P= 3/8 (варіанти 2, 3, 5) та 3 студенти – P= 1/8 (варіант 1).
Необхідно визначити ймовірність того, що троє з 5 студентів успішно впораються з цим завданням.
Рішення
Усього можливих результатів: 2 5 = 32.
Загальна кількість варіантів 3(+) та 2(-) становить

Отже, ймовірність очікуваного результату дорівнює 10/32» 0,31.
Приклад 3
Завдання
Визначити ймовірність того, що у групі з 10 випадкових випробуваних виявиться 5 екстравертів.
Рішення
1. Вводимо позначення: p = q = 0,5; n= 10; i = 5; P 10 (5) = ?
2. Використовуємо спрощену формулу (див. вище):
Висновок
Імовірність того, що серед 10 випадкових випробуваних виявиться 5 екстравертів, становить 0,246.
Примітки
1. Обчислення за формулою за достатньо великому числівипробувань досить трудомісткий, тому у цих випадках рекомендується використовувати таблиці біномного розподілу.
2. У деяких випадках значення pі qможна поставити спочатку, але не завжди. Як правило, вони обчислюються за наслідками попередніх випробувань (пілотажних досліджень).
3. У графічне зображення(у координатах P n(i) = f(i)) біноміальний розподіл може мати різний вигляд: в разі p = qрозподіл симетрично та нагадує нормальний розподіл Гауса; асиметрія розподілу тим більша, чим більше різницяміж ймовірностями pі q.
Розподіл Пуассона
Розподіл Пуассона є окремим випадком біномного розподілу, що використовується при дуже низькій ймовірності цікавих для нас подій. Іншими словами, цей розподіл визначає можливість рідкісних подій. Формулою Пуассона можна користуватися при p < 0,01 и q ≥ 0,99.
Рівняння Пуассона є наближеним і описується такою формулою:
![]() (6.9)
(6.9)
де μ є твір середньої ймовірностіподії та числа спостережень.
Як приклад розглянемо алгоритм розв'язання наступного завдання.
Умова задачі
За кілька років у 21 великій клініці Росії було проведено масове обстеження новонароджених щодо захворювання немовлят хворобою Дауна (вибірка в середньому становила 1000 новонароджених у кожній клініці). Були отримані такі дані:
Завдання
1. Визначити середню ймовірність захворювання (у перерахунку число новонароджених).
2. Визначити, скільки новонароджених у середньому припадає одне захворювання.
3. Визначити ймовірність того, що серед 100 випадково обраних новонароджених виявиться 2 немовляти із хворобою Дауна.
Рішення
1. Визначаємо середню ймовірність захворювання. При цьому ми маємо керуватися такими міркуваннями. Хвороба Дауна зареєстрована лише в 10 клініках з 21. У 11 клініках захворювань не виявлено, у 6 клініках зареєстровано по 1 випадку, у 2 клініках – 2 випадки, у 1-й клініці – 3 та у 1-й клініці – 4 випадки хвороби. 5 випадків захворювання не було виявлено в жодній клініці. Для того щоб визначити середню ймовірність захворювання, необхідно загальну кількість випадків (6 · 1 + 2 · 2 + 1 · 3 + 1 · 4 = 17) розділити на загальну кількість новонароджених (21000):
![]()
2. Число новонароджених, на яке припадає одне захворювання, є величиною зворотної середньої ймовірності, тобто дорівнює загальному числу новонароджених, віднесеному до зареєстрованих випадків:
![]()
3. Підставляємо значення p = 0,00081, n= 100 та i= 2 у формулу Пуассона:
Відповідь
Імовірність того, що серед 100 випадково обраних новонароджених виявиться 2 немовляти із хворобою Дауна, становить 0,003 (0,3%).
Завдання на тему
Завдання 6. 1
Завдання
Користуючись даними задачі 5.1 за часом сенсомоторної реакції, обчислити асиметрію та ексцес розподілу ВР.
Завдання 6. 2
200 учнів випускних класів було протестовано на рівень інтелектуальності ( IQ). Після нормування отриманого розподілу IQза стандартним відхиленням були отримані такі результати:
Завдання
Користуючись критеріями Колмогорова та хі-квадрат, визначити, чи відповідає отриманий розподіл показників IQнормальному.
Завдання 6. 3
У дорослого випробуваного (чоловік 25 років) досліджувався час простої сенсомоторної реакції (ВР) у відповідь на звуковий стимул з постійною частотою 1 кГц та інтенсивністю 40 дБ. Стимул пред'являвся повністю з інтервалами 3 – 5 секунд. Окремі значення ВР за 100 повторностями розподілилося таким чином:
Завдання
1. Побудувати частотну гістограму розподілу ВР; визначити середнє значення ВР та величину стандартного відхилення.
2. Розрахувати коефіцієнт асиметрії та показник ексцесу розподілу ВР; на підставі отриманих значень Asі Exзробити висновок про відповідність чи невідповідність даного розподілу нормальному.
Завдання 6. 4
У 1998 році в Нижньому Тагілі закінчили школи із золотими медалями 14 осіб (5 юнаків та 9 дівчат), зі срібними – 26 осіб (8 юнаків та 18 дівчат).
Питання
Чи можна стверджувати, що дівчата отримують медалі частіше за юнаків?
Примітка
Співвідношення числа юнаків та дівчат у генеральної сукупностівважати рівним.
Завдання 6. 5
Вважається, що кількість екстравертів та інтровертів у однорідній групі піддослідних є приблизно однаковим.
Завдання
Визначити ймовірність того, що у групі з 10 випадково відібраних піддослідних виявиться 0, 1, 2, ..., 10 екстравертів. Побудувати графічний вираз розподілу ймовірностей виявлення 0, 1, 2, ..., 10 екстравертів у цій групі.
Завдання 6. 6
Завдання
Розрахувати ймовірність P n(i) функції біномного розподілу при p= 0,3 та q= 0,7 для значень n= 5 та i= 0, 1, 2, ..., 5. Побудувати графічний вираз залежності P n(i) = f(i) .
Завдання 6. 7
У Останніми рокамисеред певної частини населення утвердилася віра у астрологічні прогнози. За наслідками попередніх опитувань встановлено, що в астрологію вірять близько 15% населення.
Завдання
Визначити ймовірність того, що серед 10 випадково обраних респондентів виявиться 1, 2 чи 3 особи, які вірять в астрологічні прогнози.
Завдання 6. 8
Умова задачі
У 42 загальноосвітніх школахм. Єкатеринбурга та Свердловської області (загальна кількість учнів 12260 осіб) за кілька років було виявлено наступне числовипадків психічних захворювань серед школярів:
Завдання
Нехай буде вибірково обстежено 1000 школярів. Розрахувати, яка ймовірність того, що серед цієї тисячі школярів буде виявлено 1, 2 чи 3 психічно хворих дитини?
РОЗДІЛ 7. ЗАХОДИ ВІДМІН
Постановка проблеми
Припустимо, що маємо дві незалежні друг від друга вибірки піддослідних хі у. НезалежнимиВибірки вважаються тоді, коли один і той же суб'єкт (випробуваний) фігурує тільки в одній вибірці. Завдання полягає в тому, щоб порівняти між собою ці вибірки (два ряди змінних) щодо їх відмінностей. Природно, що як би не були близькі між собою значення змінних у першій та другій вибірці, якісь, хай навіть незначні, різницю між ними виявлятимуться. З погляду математичної статистикинас цікавить питання, чи є різницю між цими вибірками статистично достовірними (статистично значущими) чи недостовірними (випадковими).
Найбільш поширеними критеріями достовірності різниці між вибірками є параметричні заходи – критерій Стьюдентаі критерій Фішера. У ряді випадків використовуються непараметричні критерії. критерій Q Розенбаума, U-критерій Манна-Уітні та ін Особливе місце посідає кутове перетворення Фішера φ*, що дозволяють порівнювати одне з одним значення, виражені у відсотках (відсоткових частках). І, нарешті, як окремий випадок, для порівняння вибірок можуть бути використані критерії, що характеризують форму розподілів вибірок – критерій χ 2 Пірсонаі критерій λ Колмогорова – Смирнова.
З метою найкращого засвоєння цієї теми ми надійдемо так. Одне й те завдання ми вирішимо чотирма методами з використанням чотирьох різних критеріїв – Розенбаума, Манна-Уітні, Стьюдента і Фішера.
Умова задачі
30 студентів (14 юнаків та 16 дівчат) під час екзаменаційної сесії протестовано за тестом Спілбергера на рівень реактивної тривожності. Отримано такі результати (табл. 7.1):
Таблиця 7.1
| Випробувані | Рівень реактивної тривожності | |||||||||||||||
| Юнаки | ||||||||||||||||
| Дівчата |
Завдання
Визначити, чи статистично достовірними є відмінності рівня реактивної тривожності у юнаків та дівчат.
Завдання видається цілком типовим для психолога, що спеціалізується в області педагогічної психології: хто гостріше переживає екзаменаційний стрес – юнаки чи дівчата? Якщо різницю між вибірками статистично достовірні, то існують значні статеві різницю у цьому аспекті; якщо відмінності є випадковими (статистично недостовірними), від цього припущення слід відмовитися.
7. 2. Непараметричний критерій QРозенбаум
Q-Критерій Розенбаума заснований на порівнянні «накладених» один на одного ранжованих рядів значень двох незалежних змінних. При цьому не аналізується характер розподілу ознаки всередині кожного ряду – у цьому випадку має значення лише ширина ділянок двох ранжованих рядів, що не перекриваються. При порівнянні між собою двох ранжованих рядів змінних можливі 3 варіанти:
1. Ранжовані ряди xі yнемає області перекриття, т. е. всі значення першого ранжированного ряду ( x) Найбільше значень другого ранжованого ряду( y):
У цьому випадку відмінності між вибірками, що визначаються за будь-яким статистичним критерієм, безперечно достовірні, і використання критерію Розенбауму не потрібне. Проте на практиці такий варіант трапляється виключно рідко.
2. Ранжовані ряди повністю накладаються один на одного (як правило, один з рядів знаходиться всередині іншого), зони, що не перекриваються, відсутні. У разі критерій Розенбаума непридатний.

3. Є зона перекриття рядів, а також дві області, що не перекриваються ( N 1і N 2), що відносяться до різнимранжованим рядам (позначимо х– ряд, зрушений у бік великих, y– у бік менших значень):

Даний випадок є типовим для використання критерію Розенбаума, при використанні якого слід дотримуватись таких умов:
1. Обсяг кожної вибірки має бути не менше ніж 11.
2. Обсяги вибірок не повинні суттєво відрізнятись один від одного.
Критерій QРозенбаума відповідає числу значень, що не перекриваються: Q = N 1 +N 2 . Висновок про достовірність відмінностей між вибірками робиться у разі, якщо Q > Qкр . При цьому значення Qкр перебувають у спеціальних таблицях (див. Додаток, табл. VIII).
Повернемося до нашого завдання. Введемо позначення: х- Вибірка дівчат, y- Вибірка юнаків. Для кожної вибірки будуємо ранжований ряд:
х: 28 30 34 34 35 36 37 39 40 41 42 42 43 44 45 46
y: 26 28 32 32 33 34 35 38 39 40 41 42 43 44
Підраховуємо число значень у областях, що не перекриваються, ранжованих рядів. У ряді хнеперекриваються значення 45 і 46, тобто. N 1 = 2; у ряді yтільки 1 неперекривається значення 26, тобто. N 2 = 1. Звідси, Q = N 1 +N 2 = 1 + 2 = 3.
У табл. VIII Додатки знаходимо, що Qкр . = 7 (для рівня значимості 0,95) та Qкр = 9 (для рівня значущості 0,99).
Висновок
Оскільки Q<Qкр, то за критерієм Розенбаума різницю між вибірками є статистично достовірними.
Примітка
Критерій Розенбаума може використовуватися незалежно від характеру розподілу змінних, тобто в даному випадку відпадає необхідність використання критеріїв 2 Пірсона і Колмогорова для визначення типу розподілів в обох вибірках.
7. 3. U-критерій Манна – Вітні
На відміну від критерію Розенбаума, U-Критерій Манна - Уітні заснований на визначенні зони перекриття між двома ранжованими рядами, тобто чим менше зона перекриття, тим вірогідніша різниця між вибірками. Для цього використовується спеціальна процедура перетворення інтервальних шкал на рангові.
Розглянемо алгоритм обчислень за U-Критерію на прикладі попередньої задачі.
Таблиця 7.2
| x, y | R xy | R xy * | R x | R y |
| 26 28 32 32 33 34 35 38 39 40 41 42 43 44 | 2,5 2,5 5,5 5,5 11,5 11,5 16,5 16,5 18,5 18,5 20,5 20,5 25,5 25,5 27,5 27,5 | 2,5 11,5 16,5 18,5 20,5 25,5 27,5 | 1 2,5 5,5 5,5 7 9 11,5 15 16,5 18,5 20,5 23 25,5 27,5 | |
| Σ | 276,5 | 188,5 |
1. З двох незалежних вибірок будуємо єдиний ранжований ряд. У цьому випадку значення для обох вибірок йдуть «упереміш», стовпець 1 ( x, y). З метою спрощення подальшої роботи (у тому числі і в комп'ютерному варіанті) слід значення для різних вибірок відзначати різним шрифтом (або різним кольором) з урахуванням того, що надалі ми розноситимемо їх по різних стовпцях.
2. Перетворимо інтервальну шкалу значень на порядкову (для цього перепозначаємо всі значення ранговими числами від 1 до 30, стовпець 2 ( R xy)).
3. Вводимо поправки на пов'язані ранги (однакові значення змінної позначаються тим самим рангом за умови, що сума рангів не змінюється, стовпець 3 ( R xy*). На цьому етапі рекомендується підрахувати суми рангів у 2-му та 3-му стовпці (якщо всі поправки введені правильно, то ці суми повинні бути рівні).
4. Розносимо рангові числа відповідно до їх приналежності до тієї чи іншої вибірки (стовпці 4 і 5 ( R x та R y)).
5. Проводимо обчислення за такою формулою:
![]() (7.1)
(7.1)
де Тх – найбільша з рангових сум ; n x та n y , відповідно, обсяги вибірок. В даному випадку слід мати на увазі, що якщо T x< T y , то позначення xі yслід змінити зворотні.
6. Порівнюємо отримане значення з табличним (див. Додатки, табл. IX). Висновок про достовірність відмінностей між двома вибірками робиться у разі, якщо Uексп.< Uкр. .
У нашому прикладі ![]() Uексп. = 83,5> U кр. = 71.
Uексп. = 83,5> U кр. = 71.
Висновок
Відмінності між двома вибірками за критерієм Манна – Уітні є статистично достовірними.
Примітки
1. Критерій Манна-Уітні немає ніяких обмежень; мінімальні обсяги порівнюваних вибірок – 2 та 5 осіб (див. табл. IX Додатка).
2. Аналогічно критерію Розенбаума критерій Манна-Уітні може бути використаний стосовно будь-яких вибірок незалежно від характеру розподілу.
Критерій Стьюдента
На відміну від критеріїв Розенбаума та Манна-Уітні критерій tСтьюдента є параметричним, тобто заснований на визначенні основних статистичних показників – середніх значень у кожній вибірці (і) та їх дисперсій (s 2 x і s 2 y), що розраховуються за стандартними формулами (див. розділ 5).
Використання критерію Стьюдента передбачає дотримання наступних умов:
1. Розподіл значень для обох вибірок повинен відповідати закону нормального розподілу(Див. розділ 6).
2. Сумарний обсяг вибірок повинен бути не менше 30 (для β 1 = 0,95) та не менше 100 (для β 2 = 0,99).
3. Обсяги двох вибірок не повинні суттєво відрізнятись один від одного (не більше ніж у 1,5 ÷ 2 рази).
Ідея критерію Стьюдента досить проста. Припустимо, що значення змінних у кожній з вибірок розподіляються за нормальному закону, тобто ми маємо справу з двома нормальними розподілами, що відрізняються один від одного за середніми значеннями та дисперсією (відповідно і, і, див. рис. 7.1).

s x s y
Рис. 7.1. Оцінка відмінностей між двома незалежними вибірками: - середні значення вибірок xі y; s x та s y - стандартні відхилення
Неважко зрозуміти, що відмінності між двома вибірками будуть тим більшими, чим більша різниця між середніми значеннями і чим менше їх дисперсії (або стандартні відхилення).
У разі незалежних вибірок коефіцієнт Стьюдента визначають за такою формулою:
 (7.2)
(7.2)
де n x та n y – відповідно чисельність вибірок xі y.
Після обчислення коефіцієнта Стьюдента у таблиці стандартних (критичних) значень t(див. Додаток, табл. Х) знаходять величину, що відповідає числу ступенів свободи n = n x + n y - 2, і порівнюють її з розрахованою за формулою. Якщо tексп. £ tкр. , то гіпотезу про достовірність відмінностей між вибірками відкидають, якщо ж tексп. > tкр. , То її приймають. Іншими словами, вибірки достовірно відрізняються один від одного, якщо обчислений за формулою коефіцієнт Стьюдента більше табличного значення відповідного рівня значимості.
У розглянутому нами раніше завданні обчислення середніх значень та дисперсій дає наступні значення: xпор. = 38,5; σ х 2 = 28,40; упор. = 36,2; σ у 2 = 31,72.
Можна бачити, що середнє значення тривожності групи дівчат вище, ніж у групі юнаків. Проте ці відмінності настільки незначні, що навряд чи є статистично значущими. Розкид значень у юнаків, навпаки, дещо вищий, ніж у дівчат, але різницю між дисперсіями також невеликі.

Висновок
tексп. = 1,14< tкр. = 2,05 (? 1 = 0,95). Відмінності між двома порівнюваними вибірками є статистично достовірними. Цей висновок цілком узгоджується з таким, отриманим під час використання критеріїв Розенбаума і Манна-Уітні.
Інший спосіб визначення відмінностей між двома вибірками за критерієм Стьюдента полягає у обчисленні довірчого інтервалу стандартних відхилень. Довірчим інтервалом називається середньоквадратичне (стандартне) відхилення, поділене на квадратний корінь з обсягу вибірки і помножене на стандартне значення коефіцієнта Стьюдента для n- 1 ступенів свободи (відповідно, і ).
Примітка
Величина = m xназивається середньоквадратичною помилкою (див. Розділ 5). Отже, довірчий інтервал є середньоквадратичною помилкою, помноженою на коефіцієнт Стьюдента для даного обсягу вибірки, де число ступенів свободи ν = n- 1, і за даного рівнязначимості.
Дві незалежні один від одного вибірки вважаються достовірно різними, якщо довірчі інтервалидля цих вибірок не перекриваються один з одним. У нашому випадку ми маємо для першої вибірки 38,5±2,84, для другої 36,2±3,38.
Отже, випадкові варіації x iлежать у діапазоні 35,66 41,34, а варіації y i– у діапазоні 32,82 39,58. На підставі цього можна констатувати, що різницю між вибірками xі yстатистично недостовірні (діапазони варіацій перекриваються один з одним). У цьому слід пам'ятати, що ширина зони перекриття у разі немає значення (важливий лише сам факт перекриття довірчих інтервалів).
Метод Стьюдента для залежних один від одного вибірок (наприклад, для порівняння результатів, отриманих при повторному тестуванні на одній і тій же вибірці піддослідних) використовують досить рідко, оскільки для цього існують інші, більш інформативні статистичні прийоми(Див. розділ 10). Тим не менш, для цієї мети в першому наближенні можна використовувати формулу Стьюдента такого виду:
 (7.3)
(7.3)
Отриманий результат порівнюють з табличним значенням для n– 1 ступенів свободи, де n- Число пар значень xі y. Результати порівняння інтерпретуються так само, як і у разі обчислення відмінностей між двома незалежними вибірками.
Критерій Фішера
Критерій Фішера ( F) заснований на тому ж принципі, що і критерій Стьюдента, тобто передбачає обчислення середніх значень та дисперсій у порівнюваних вибірках. Найчастіше використовують у порівнянні між собою нерівноцінних за обсягом (різних за чисельністю) вибірок. Критерій Фішера є дещо жорсткішим, ніж критерій Стьюдента, тому більш переважний у випадках, коли виникають сумніви щодо достовірності відмінностей (наприклад, якщо за критерієм Стьюдента відмінності достовірні при нульовому і недостовірні за першому рівні значимості).
Формула Фішера виглядає так:
 (7.4)
(7.4)
де і  (7.5, 7.6)
(7.5, 7.6)
У завданні нами d 2= 5,29; σ z 2 = 29,94.
Підставляємо значення у формулу: ![]()
У табл. ХI Додатків знаходимо, що для рівня значущості β 1 = 0,95 та ν = n x + n y - 2 = 28 критичне значення становить 4,20.
Висновок
F = 1,32 < F кр.= 4,20. Відмінності між вибірками статистично недостовірні.
Примітка
При використанні критерію Фішера повинні дотримуватися тих самих умов, що й для критерію Стьюдента (див. підрозділ 7.4). Проте допускається відмінність чисельності вибірок більш як удвічі.
Таким чином, при вирішенні одного і того ж завдання чотирма різними методамиз використанням двох непараметричних та двох параметричних критеріїв ми дійшли однозначного висновку про те, що відмінності між групою дівчат та групою юнаків за рівнем реактивної тривожності недостовірні (тобто перебувають у межах випадкових варіацій). Однак можуть зустрітися і такі випадки, коли зробити однозначний висновок неможливо: одні критерії дають достовірні, інші – недостовірні відмінності. У цих випадках пріоритет надається параметричним критеріям (за умови достатності обсягу вибірок та нормального розподілу досліджуваних величин).
7. 6. Критерій j* - кутове перетворення Фішера
Критерій j * Фішера призначений для зіставлення двох вибірок за частотою зустрічальності цікавого дослідника ефекту. Він оцінює достовірність відмінностей між відсотковими частками двох вибірок, в яких зареєстрований цікавий для нас ефект. Допускається також порівняння відсоткових співвідношень та в межах однієї вибірки.
Суть кутового перетворення Фішера полягає у переведенні відсоткових часток у величини центрального кута, що вимірюється в радіанах. Більшій відсотковій частці буде відповідати більший кут j, а меншій частці – менший кут, але відносини тут нелінійні:
![]()
де Р- Відсоткова частка, виражена в частках одиниці.
При збільшенні розбіжності між кутами j 1 і j 2 та збільшення чисельності вибірок значення критерію зростає.
Критерій Фішера обчислюється за такою формулою:
| |
де j 1 - Кут, відповідний більшій процентній частці; j 2 – кут, що відповідає меншій відсотковій частці; n 1 та n 2 – відповідно, обсяг першої та другої вибірок.
Обчислене за формулою значення порівнюється зі стандартним (j* ст = 1,64 для b 1 = 0,95 та j* ст = 2,31 для b 2 = 0,99. Відмінності між двома вибірками вважаються статистично достовірними, якщо j*> j* ст для цього рівня значимості.
приклад
Нас цікавить, чи різняться між собою дві групи студентів щодо успішності виконання досить складного завдання. У першій групі з 20 осіб із нею впоралося 12 студентів, у другій – 10 осіб із 25.
Рішення
1. Вводимо позначення: n 1 = 20, n 2 = 25.
2. Обчислюємо відсоткові частки Р 1 та Р 2: Р 1 = 12 / 20 = 0,6 (60%), Р 2 = 10 / 25 = 0,4 (40%).
3. У табл. XII Додатків знаходимо відповідні відсоткові частини значення φ: j 1 = 1,772, j 2 = 1,369.
| |
Звідси:
Висновок
Відмінності між групами є статистично достовірними, оскільки j*< j* ст для 1-го и тем более для 2-го уровня значимости.
7.7. Використання критерію χ2 Пірсона та критерію λ Колмогорова
Розподіл ймовірностей дискретних випадкових величин. Біноміальний розподіл. Розподіл Пуассон. Геометричний розподіл. Виробляюча функція.
6. Розподіл ймовірностей дискретних випадкових величин
6.1. Біноміальний розподіл
Нехай проводиться nнезалежних випробувань, у кожному з яких подія Aможе або з'явиться, або з'явиться. Ймовірність pпояви події Aу всіх випробуваннях постійна та не змінюється від випробування до випробування. Розглянемо як випадкову величину X число появи події Aу цих випробуваннях. Формула, що дозволяє знайти ймовірність появи події Aрівно kраз на nвипробуваннях, як відомо, описується формулою Бернуллі
Розподіл ймовірностей, що визначається формулою Бернуллі, називається біномним .
Цей закон названий "біноміальним" тому, що праву частину можна розглядати як спільний член розкладання бінома Ньютона
Запишемо біномний закон у вигляді таблиці
|
p n |
np n –1 q |
|
q n |

Знайдемо числові показники цього розподілу.
За визначенням математичного очікуваннядля ДСВ маємо
 .
.
Запишемо рівність, що є біном Ньютона
 .
.
і продиференціюємо його з p. В результаті отримаємо
 .
.
Помножимо ліву та праву частинуна p:
 .
.
Враховуючи що p+ q=1, маємо
 (6.2)
(6.2)
Отже, математичне очікування числа події вnнезалежних випробуваннях дорівнює добутку числа випробуваньnна ймовірністьpпояви події у кожному випробуванні.
Дисперсію обчислимо за формулою
 .
.
Для цього знайдемо
 .
.
Попередньо продиференціюємо формулу бінома Ньютона двічі по p:

і помножимо обидві частини рівності на p 2:

Отже,
Отже, дисперсія біномного розподілу дорівнює
 .
(6.3)
.
(6.3)
Ці результати можна отримати і з суто якісних міркувань. Загальне число X події A у всіх випробуваннях складаються з числа події в окремих випробуваннях. Тому якщо X 1 – число появи події у першому випробуванні, X 2 – у другому тощо, то загальна кількість появи події A у всіх випробуваннях дорівнює X=X 1 +X 2 +…+X n. За якістю математичного очікування:
Кожна з доданків правої частини рівності є математичне очікування числа подій в одному випробуванні, яке дорівнює ймовірності події. Таким чином,
За якістю дисперсії:
Оскільки математичне очікування випадкової величини  , яке може набувати лише двох значень, а саме 1 2 з ймовірністю pта 0 2 з ймовірністю q, то
, яке може набувати лише двох значень, а саме 1 2 з ймовірністю pта 0 2 з ймовірністю q, то  . Таким чином,
. Таким чином,  В результаті, отримуємо
В результаті, отримуємо
Скориставшись поняттям початкових та центральних моментів, можна отримати формули для асиметрії та ексцесу:
 .
(6.4)
.
(6.4)

Рис. 6.1
Багатокутник біномного розподілу має такий вигляд (див. рис. 6.1). Імовірність n (k) спочатку зростає при збільшенні k, досягає найбільшого значенняі далі починає зменшуватися. Біноміальний розподіл асиметричний, за винятком випадку p=0,5. Зазначимо, що за великої кількості випробувань nБіноміальний розподіл дуже близький до нормального. (Обґрунтування цієї пропозиції пов'язане з локальною теоремою Муавра-Лапласа.)Числоm 0 настання події називаєтьсянайімовірнішим якщо ймовірність настання події дана кількість разів у цій серії випробувань найбільша (максимум у багатокутнику розподілу). Для біномного розподілу
Зауваження. Цю нерівність можна довести, використовуючи рекурентну формулу для біномних ймовірностей:
 (6.6)
(6.6)
Приклад 6.1.Частка виробів вищого гатунку цьому підприємстві становить 31%. Чому дорівнює математичного очікування і дисперсія, а також найімовірніше число виробів вищого гатунку у випадково відібраної партії з 75 виробів?
Рішення. Оскільки p=0,31, q=0,69, n=75, то
M[ X] = np= 750,31 = 23,25; D[ X] = npq = 750,310,69 = 16,04.
Для знаходження найімовірнішого числа m 0 , складемо подвійну нерівність
Звідси слідує що m 0 = 23.
Біноміальний розподіл - один з найважливіших розподілів ймовірностей випадкової величини, що дискретно змінюється. Біноміальним розподілом називається розподіл ймовірностей числа mнастання події Ав nвзаємно незалежні спостереження. Часто подія Аназивають "успіхом" спостереження, а протилежна йому подія - "неуспіхом", але це позначення дуже умовне.
Умови біномного розподілу:
- загалом проведено nвипробувань, у яких подія Аможе наступити чи наступити;
- подія Ау кожному з випробувань може наступити з однією і тією самою ймовірністю p;
- випробування є взаємно незалежними.
Імовірність того, що в nвипробуваннях подія Анастане саме mраз, можна обчислити за формулою Бернуллі:
![]()
![]() ,
,
де p- ймовірність настання події А;
q = 1 - p- Імовірність настання протилежної події.
Розберемося, чому біномний розподіл описаним вище чином пов'язаний з формулою Бернуллі . Подія - кількість успіхів при nвипробуваннях розпадається на ряд варіантів, у кожному з яких успіх досягається в mвипробуваннях, а неуспіх - у n - mвипробуваннях. Розглянемо один із таких варіантів - B1 . За правилом складання ймовірностей примножуємо ймовірності протилежних подій:
![]() ,
,
а якщо позначимо q = 1 - p, то
![]() .
.
Таку ж ймовірність матиме будь-який інший варіант, у якому mуспіхів та n - mнеуспіхів. Число таких варіантів дорівнює - числу способів, якими можна з nвипробувань отримати mуспіхів.
Сума ймовірностей усіх mчисел настання події А(чисел від 0 до n) дорівнює одиниці:
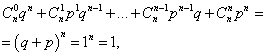
де кожен доданок являє собою доданок бінома Ньютона. Тому розподіл, що розглядається, і називається біноміальним розподілом.
Насправді часто необхідно обчислювати ймовірності " трохи більше mуспіхів у nвипробуваннях" або "не менше mуспіхів у nвипробуваннях". Для цього використовуються наступні формули.
Інтегральну функцію, тобто ймовірність F(m) того, що в nспостереженнях подія Анастане не більше mраз, Можна обчислити за формулою:
В свою чергу ймовірність F(≥m) того, що в nспостереженнях подія Анастане не менше mраз, обчислюється за такою формулою:
Іноді буває зручніше обчислювати ймовірність того, що в nспостереженнях подія Анастане не більше mраз, через ймовірність протилежної події:
![]() .
.
Який із формул користуватися, залежить від того, в якій із них сума містить менше доданків.
Характеристики біномного розподілу обчислюються за такими формулами .
Математичне очікування: .
Дисперсія: .
Середньоквадратичне відхилення: .
Біноміальний розподіл та розрахунки в MS Excel
Імовірність біномного розподілу P n ( m) та значення інтегральної функції F(m) можна обчислити за допомогою функції MS Excel БІНОМ.РАСП. Вікно для відповідного розрахунку показано нижче (для збільшення натиснути лівою кнопкою миші).

MS Excel вимагає ввести такі дані:
- кількість успіхів;
- кількість випробувань;
- ймовірність успіху;
- інтегральна – логічне значення: 0 – якщо потрібно обчислити ймовірність P n ( m) і 1 - якщо ймовірність F(m).
приклад 1.Менеджер фірми узагальнив інформацію про кількість проданих протягом останніх 100 днів фотокамер. У таблиці узагальнено інформацію та розраховано ймовірність того, що в день буде продано певна кількістьфотокамер.
День завершено із прибутком, якщо продано 13 або більше фотокамер. Імовірність, що день буде відпрацьовано із прибутком:
![]()
Імовірність того, що день буде відпрацьовано без прибутку:

Нехай ймовірність того, що день відпрацьований з прибутком, є постійною і дорівнює 0,61 і кількість проданих в день фотокамер не залежить від дня. Тоді можна використовувати біномний розподіл, де подія А- день буде відпрацьовано із прибутком, - без прибутку.
Імовірність того, що з 6 днів усі будуть відпрацьовані із прибутком:
![]() .
.
Той самий результат отримаємо, використовуючи функцію MS Excel БІНОМ.РАСП (значення інтегральної величини - 0):
P 6 (6 ) = БІНОМ.РАСП(6; 6; 0,61; 0) = 0,052.
Імовірність того, що з 6 днів 4 і більше днів будуть відпрацьовані із прибутком:
де ![]() ,
,
![]() ,
,
Використовуючи функцію MS Excel БІНОМ.РАСП, обчислимо ймовірність того, що з 6 днів не більше 3 днів буде завершено з прибутком (значення інтегральної величини - 1):
P 6 (≤3 ) = БІНОМ.РАСП(3; 6; 0,61; 1) = 0,435.
Імовірність того, що з 6 днів усі будуть відпрацьовані зі збитками:
![]() ,
,
Той самий показник обчислимо, використовуючи функцію MS Excel БІНОМ.РАСП:
P 6 (0 ) = БІНОМ.РАСП(0; 6; 0,61; 0) = 0,0035.
Вирішити завдання самостійно, а потім переглянути рішення
приклад 2.В урні 2 білі кулі та 3 чорні. З урни виймають кулю, встановлюють колір та кладуть назад. Спробу повторюють 5 разів. Число появи білих куль - дискретна випадкова величина X, Розподілена за біноміальним законом. Скласти закон розподілу випадкової величини. Визначити моду, математичне очікування та дисперсію.
Продовжуємо вирішувати завдання разом
приклад 3.З кур'єрської служби вирушили на об'єкти n= 5 кур'єрів. Кожен кур'єр з ймовірністю p= 0,3 незалежно від інших спізнюється об'єкт. Дискретна випадкова величина X- Кількість кур'єрів, що запізнилися. Побудувати низку розподілу це випадкової величини. Знайти її математичне очікування, дисперсію, середнє відхилення. Знайти ймовірність того, що на об'єкти запізняться щонайменше два кур'єри.
Розглянемо Біноміальний розподіл, обчислимо його математичне очікування, дисперсію, моду. За допомогою функції MS EXCEL БІНОМ.РАСП() побудуємо графіки функції розподілу та щільності ймовірності. Зробимо оцінку параметра розподілу p, математичного очікування розподілу та стандартного відхилення. Також розглянемо розподіл Бернуллі.
Визначення. Нехай проводяться nвипробувань, у кожному з яких може відбутися лише дві події: подія «успіх» з ймовірністю p або подія «невдача» з ймовірністю q =1-p (так звана Схема Бернуллі,Bernoullitrials).
Імовірність отримання рівно x успіхів у цих n випробуваннях дорівнює:
Кількість успіхів у вибірці x є випадковою величиною, яка має Біноміальний розподіл(англ. Binomialdistribution) pі n– є параметрами цього розподілу.
Нагадаємо, що для застосування схеми Бернулліі відповідно Біноміального розподілу,повинні бути виконані такі умови:
- кожне випробування повинно мати рівно два результати, що умовно називають «успіхом» і «невдачею».
- результат кожного випробування повинен залежати від результатів попередніх випробувань (незалежність випробувань).
- ймовірність успіху p має бути постійною для всіх випробувань.
Біноміальний розподіл у MS EXCEL
У MS EXCEL, починаючи з версії 2010, для Біноміального розподілує функція БІНОМ.РАСП() , англійська назва- BINOM.DIST(), яка дозволяє обчислити ймовірність того, що у вибірці буде рівно х"Успіхів" (тобто. функцію щільності ймовірності p(x), див. формулу вище), і інтегральну функцію розподілу(ймовірність того, що у вибірці буде xабо менше "успіхів", включаючи 0).
До MS EXCEL 2010 EXCEL була функція БІНОМРАСП() , яка також дозволяє обчислити функцію розподілуі щільність імовірності p(x). БІНОМРАСП() залишено в MS EXCEL 2010 для сумісності.
У файлі прикладу наведено графіки густини розподілу ймовірностіі .

Біноміальний розподілмає позначення B(n; p) .
Примітка: Для побудови інтегральної функції розподілуідеально підходить діаграма типу Графік, для густини розподілу – Гістограма з угрупуванням. Докладніше про побудову діаграм читайте статтю Основні типи діаграм.
Примітка: Для зручності написання формул у файлі прикладу створено Імена для параметрів Біноміального розподілу: n та p.

У прикладному файлі наведено різні розрахунки ймовірності за допомогою функцій MS EXCEL:

Як видно на картинці вище, передбачається, що:
- У нескінченній сукупності, з якої робиться вибірка, міститься 10% (або 0,1) придатних елементів (параметр p, Третій аргумент функції = БІНОМ.РАСП() )
- Щоб обчислити ймовірність того, що у вибірці з 10 елементів (параметр n, другий аргумент функції) буде рівно 5 придатних елементів (перший аргумент), потрібно записати формулу: =БІНОМ.РАСП(5; 10; 0,1; БРЕХНЯ)
- Останній, четвертий елемент, встановлений = БРЕХНЯ, тобто. повертається значення функції густини розподілу.
Якщо значення четвертого аргументу = ІСТИНА, то функція БІНОМ.РАСП() повертає значення інтегральної функції розподілуабо просто Функцію розподілу. У цьому випадку можна розрахувати ймовірність того, що у вибірці кількість придатних елементів буде з певного діапазону, наприклад, 2 або менше (включаючи 0).
Для цього потрібно записати формулу:
= БІНОМ.РАСП(2; 10; 0,1; ІСТИНА)
Примітка: При нецілому значенні х, . Наприклад, такі формули повернуть одне й теж значення:
=БІНОМ.РАСП( 2
; 10; 0,1; ІСТИНА)
=БІНОМ.РАСП( 2,9
; 10; 0,1; ІСТИНА)
Примітка: У файлі прикладу щільність імовірностіі функція розподілутакож обчислені з використанням визначення та функції ЧИСЛКОМБ() .
Показники розподілу
У файл прикладу на аркуші Прикладє формули для розрахунку деяких показників розподілу:
- =n * p;
- (квадрату стандартного відхилення) = n * p * (1-p);
- = (n + 1) * p;
- =(1-2*p)*КОРІНЬ(n*p*(1-p)).
Виведемо формулу математичного очікування Біноміального розподілу, використовуючи Схему Бернуллі.
За визначенням випадкова величина Х в схемою Бернуллі(Bernoulli random variable) має функцію розподілу:

Цей розподіл називається розподіл Бернуллі.
Примітка: розподіл Бернуллі- окремий випадок Біноміального розподілуіз параметром n=1.
Згенеруємо 3 масиви по 100 чисел з різними ймовірностями успіху: 0,1; 0,5 та 0,9. Для цього у вікні Генерація випадкових чисел встановимо такі параметри кожної ймовірності p:
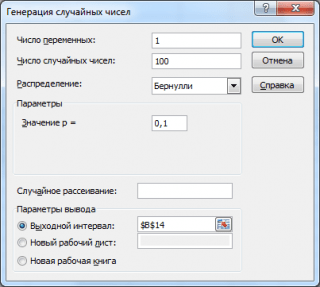
Примітка: Якщо встановити опцію Випадкове розсіювання (Random Seed), то можна вибрати певний випадковий набір згенерованих чисел. Наприклад, встановивши цю опцію =25 можна згенерувати різних комп'ютерах одні й самі набори випадкових чисел (якщо, звісно, інші параметри розподілу збігаються). Значення опції може приймати цілі значення від 1 до 32767. Назва опції Випадкове розсіюванняможе заплутати. Краще було б її перекласти як Номер набору з довільними числами.
У результаті матимемо 3 стовпці по 100 чисел, на підставі яких можна, наприклад, оцінити ймовірність успіху pза формулою: Число успіхів/100(Див. файл прикладу лист ГенераціяБернуллі).
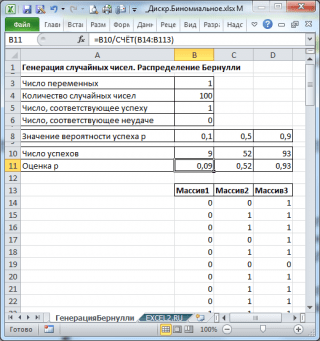
Примітка: Для розподілу Бернулліз p = 0,5 можна використовувати формулу = ВИПАД МІЖ (0; 1), яка відповідає .
Генерація випадкових чисел. Біноміальний розподіл
Припустимо, що у вибірці виявилося 7 дефектних виробів. Це означає, що «дуже ймовірна» ситуація, що змінилася частка дефектних виробів pяка є характеристикою нашого виробничого процесу. Хоча така ситуація «дуже ймовірна», але існує ймовірність (альфа-ризик, помилка 1-го роду, «хибна тривога»), що все ж таки pзалишилася без змін, а збільшена кількість дефектних виробів зумовлена випадковістю вибірки.
Як видно на малюнку нижче, 7 – кількість дефектних виробів, яка припустима для процесу з p=0,21 при тому ж значенні Альфа. Це є ілюстрацією, що з перевищенні порогового значення дефектних виробів у вибірці, p«швидше за все» збільшилося. Фраза «швидше за все» означає, що існує лише 10% ймовірність (100%-90%) того, що відхилення частки дефектних виробів вище порогового викликане лише сучайними причинами.

Таким чином, перевищення порогової кількості дефектних виробів у вибірці, може бути сигналом, що процес засмутився і став випускати б прольший відсоток бракованих виробів.
Примітка: До MS EXCEL 2010 у EXCEL була функція КРИТБІНОМ(), яка еквівалентна БІНОМ.ОБР(). КРИТБІНОМ залишена в MS EXCEL 2010 і вище для сумісності.
Зв'язок Біноміального розподілу з іншими розподілами
Якщо параметр n Біноміального розподілупрагне нескінченності, а pпрагне до 0, то в цьому випадку Біноміальний розподілможе бути апроксимовано.
Можна сформулювати умови, коли наближення розподілом Пуассонапрацює добре:
- p<0,1 (чим менше pі більше n, Тим наближення точніше);
- p>0,9 (враховуючи що q=1- p, обчислення в цьому випадку необхідно проводити через q(а хпотрібно замінити на n- x). Отже, чим менше qі більше n, Тим наближення точніше).
При 0,1<=p<=0,9 и n*p>10 Біноміальний розподілможна апроксимувати.
В свою чергу, Біноміальний розподілможе бути хорошим наближенням , коли розмір сукупності N Гіпергеометричного розподілунабагато більше розміру вибірки n (тобто N>>n або n/N<<1).
Докладніше про зв'язок вищезгаданих розподілів, можна прочитати у статті . Там же наведено приклади апроксимації, і пояснено умови, коли вона можлива і з якоюсь точністю.
ПОРАДА: Про інші розподіли MS EXCEL можна прочитати у статті .
У цій і кількох наступних нотатках ми розглянемо математичні моделі випадкових подій. Математична модель- це математичне вираз, що становить випадкову величину. Для дискретних випадкових величин цей математичний вираз відомий під назвою функція розподілу.
Якщо завдання дозволяє явно записати математичне вираз, що становить випадкову величину, можна обчислити точну ймовірність будь-якого її значення. У цьому випадку можна обчислити та перерахувати всі значення функції розподілу. У ділових, соціологічних та медичних додатках зустрічаються різноманітні розподіли випадкових величин. Одним із найкорисніших розподілів є біномне.
Біноміальний розподілвикористовується для моделювання ситуацій, що характеризуються такими особливостями.
- Вибірка складається з фіксованого числа елементів n, що є результатами якогось випробування.
- Кожен елемент вибірки належить одній із двох взаємовиключних категорій, які вичерпують весь вибірковий простір. Як правило, ці дві категорії називають успіх та невдача.
- Ймовірність успіху рє постійною. Отже, ймовірність невдачі дорівнює 1 – р.
- Вихід (тобто удача чи невдача) будь-якого випробування залежить від результату іншого випробування. Щоб гарантувати незалежність результатів, елементи вибірки зазвичай отримують за допомогою двох різних методів. Кожен елемент вибірки випадково витягується з нескінченної генеральної сукупності без повернення або з кінцевої генеральної сукупності з поверненням.
Завантажити нотатку у форматі або , приклади у форматі
Біноміальний розподіл використовується для оцінки кількості успіхів у вибірці, що складається з nспостережень. Розглянемо як приклад оформлення замовлень. Щоб зробити замовлення, клієнти компанії Saxon Company можуть скористатися інтерактивною електронною формою і надіслати її в компанію. Потім інформаційна система перевіряє, чи немає у замовленнях помилок, і навіть неповної чи недостовірної інформації. Будь-яке замовлення, що викликає сумніви, позначається та включається до щоденного звіту про виняткові ситуації. Дані, зібрані компанією, свідчать, що ймовірність помилок у замовленнях дорівнює 0,1. Компанія хотіла б знати, яка ймовірність виявити певну кількість помилкових замовлень у заданій вибірці. Наприклад, припустимо, що клієнти заповнили чотири електронні форми. Яка ймовірність, що всі замовлення виявляться безпомилковими? Як визначити цю можливість? Під успіхом розумітимемо помилку при заповненні форми, а всі інші результати вважатимемо невдачею. Нагадаємо, що нас цікавить кількість помилкових замовлень у заданій вибірці.
Які результати ми можемо спостерігати? Якщо вибірка складається з чотирьох замовлень, помилковими можуть бути одне, два, три чи всі чотири, крім того, всі вони можуть виявитися правильно заповненими. Чи може випадкова величина, що описує кількість неправильно заповнених форм, набувати будь-якого іншого значення? Це неможливо, оскільки кількість неправильно заповнених форм не може перевищувати обсяг вибірки nчи бути негативним. Таким чином, випадкова величина, що підпорядковується біноміальному закону розподілу, набуває значення від 0 до n.
Припустимо, що у вибірці із чотирьох замовлень спостерігаються такі результати:
Яка ймовірність виявити три помилкові замовлення у вибірці, що складається з чотирьох замовлень, причому у зазначеній послідовності? Оскільки попередні дослідження показали, що ймовірність помилки при заповненні форми дорівнює 0,10, ймовірності зазначених вище результатів обчислюються таким чином:
Оскільки результати не залежать один від одного, ймовірність зазначеної послідовності результатів дорівнює: р * р * (1-р) * р = 0,1 * 0,1 * 0,9 * 0,1 = 0,0009. Якщо необхідно обчислити кількість варіантів вибору X nелементів, слід скористатися формулою поєднань (1):

де n! = n * (n -1) * (n - 2) * ... * 2 * 1 - факторіал числа n, причому 0! = 1 та 1! = 1 за визначенням.
Цей вираз часто позначають як . Таким чином, якщо n = 4 і X = 3, кількість послідовностей, що складаються з трьох елементів, вилучених з вибірки, обсяг якої дорівнює 4, визначається за такою формулою:
Отже, ймовірність виявити три помилкові замовлення обчислюється так:
(Кількість можливих послідовностей) *
(ймовірність конкретної послідовності) = 4*0,0009 = 0,0036
Аналогічно можна обчислити ймовірність того, що серед чотирьох замовлень виявляться одне або два помилкові, а також ймовірність того, що всі замовлення помилкові або всі вірні. Однак при збільшенні обсягу вибірки nвизначити ймовірність конкретної послідовності результатів стає складніше. У цьому випадку слід застосувати відповідну математичну модель, яка описує біномний розподіл кількості варіантів вибору Xоб'єктів з вибірки, що містить nелементів.
Біномінальний розподіл

де Р(Х)- ймовірність Xуспіхів при заданих обсягах вибірки nта ймовірності успіху р, X = 0, 1, … n.
Зверніть увагу на те, що формула (2) є формалізацією інтуїтивних висновків. Випадкова величина X, що підпорядковується біномному розподілу, може приймати будь-яке ціле значення в діапазоні від 0 до n. твір рX(1 – р)n – Xє ймовірність конкретної послідовності, що складається з Xуспіхів у вибірці, обсяг якої дорівнює n. Величина визначає кількість можливих комбінацій, що складаються з Xуспіхів у nвипробуваннях. Отже, при заданій кількості випробувань nта ймовірності успіху рймовірність послідовності, що складається з Xуспіхів, дорівнює
Р(Х) = (кількість можливих послідовностей) * (ймовірність конкретної послідовності) = 
Розглянемо приклади, що ілюструють застосування формули (2).
1. Припустимо, що можливість невірно заповнити форму дорівнює 0,1. Яка ймовірність того, що серед чотирьох заповнених форм три виявляться хибними? Використовуючи формулу (2), отримуємо, що ймовірність виявити три помилкові замовлення у вибірці, що складається з чотирьох замовлень, дорівнює
2. Припустимо, що можливість невірно заповнити форму дорівнює 0,1. Яка ймовірність того, що серед чотирьох заповнених форм не менше трьох виявляться хибними? Як показано в попередньому прикладі, ймовірність того, що серед чотирьох заповнених форм три виявляться помилковими, дорівнює 0,0036. Щоб обчислити ймовірність того, що серед чотирьох заповнених форм не менше трьох будуть неправильно заповнені, необхідно скласти ймовірність того, що серед чотирьох заповнених форм три виявляться помилковими, і ймовірність того, що серед чотирьох заповнених форм виявляться помилковими. Імовірність другої події дорівнює
Таким чином, ймовірність того, що серед чотирьох заповнених форм не менше трьох виявляться помилковими, дорівнює
Р(Х> 3) = Р(Х = 3) + Р(Х = 4) = 0,0036 + 0,0001 = 0,0037
3. Припустимо, що можливість невірно заповнити форму дорівнює 0,1. Яка ймовірність того, що серед чотирьох заповнених форм менше трьох виявляться хибними? Імовірність цієї події
Р(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Використовуючи формулу (2), обчислимо кожну з цих ймовірностей:

Отже, Р(Х< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Імовірність Р(Х< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Тоді Р(Х< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
У міру збільшення обсягу вибірки nобчислення, аналогічні проведеним у прикладі 3, стають скрутними. Щоб уникати цих складнощів, багато біномних ймовірностей табулюють заздалегідь. Деякі з цих ймовірностей наведені на рис. 1. Наприклад, щоб отримати ймовірність, що Х= 2 при n= 4 та p= 0,1, слід витягти з таблиці число, яке стоїть на перетині рядка Х= 2 і стовпця р = 0,1.

Рис. 1. Біноміальна ймовірність при n = 4, Х= 2 і р = 0,1
Біноміальний розподіл можна обчислити за допомогою функції Excel=БІНОМ.РАСП() (рис. 2), що має 4 параметри: число успіхів - Х, Число випробувань (або обсяг вибірки) - n, ймовірність успіху – р, параметр інтегральна, Що приймає значення ІСТИНА (у цьому випадку обчислюється ймовірність не менше Хподій) або БРЕХНЯ (у цьому випадку обчислюється ймовірність точно Хподій).

Рис. 2. Параметри функції =БІНОМ.РАСП()
Для наведених вище трьох прикладів розрахунки наведені на рис. 3 (див. також файл Excel). У кожному стовпці наведено за однією формулою. Цифрами показано відповіді приклади відповідного номера).

Рис. 3. Розрахунок біномінального розподілув Excel для n= 4 та p = 0,1
Властивості біномного розподілу
Біноміальний розподіл залежить від параметрів nі р. Біноміальний розподіл може бути як симетричним, так і асиметричним. Якщо р = 0,05, біномний розподіл є симетричним незалежно від величини параметра n. Однак, якщо р ≠ 0,05, розподіл стає асиметричним. Чим ближче значення параметра рдо 0,05 і чим більший обсяг вибірки n, Тим слабше виражена асиметрія розподілу. Таким чином, розподіл кількості неправильно заповнених форм зміщено вправо, оскільки p= 0,1 (рис. 4).

Рис. 4. Гістограма біномного розподілу при n= 4 та p = 0,1
Математичне очікування біномного розподілудорівнює добутку обсягу вибірки nна ймовірність успіху р:
(3) Μ = Е(Х) =np
У середньому, при досить довгій серії випробувань у вибірці, що складається з чотирьох замовлень, може бути р = Е(Х) = 4 х 0,1 = 0,4 неправильно заповнених форм.
Стандартне відхилення біномного розподілу
Наприклад, стандартне відхиленнякількості невірно заповнених форм у бухгалтерській інформаційної системиодно:
Використовуються матеріали книги Левін та ін. Статистика менеджерів. - М.: Вільямс, 2004. - с. 307–313
