Біномінальний розподіл. Розподіл біномний: визначення, формула, приклади
Звичайно, при обчисленні кумулятивної функції розподілу слід скористатися згаданим зв'язком біномного та бета-розподілу. Цей спосіб наперед краще безпосереднього підсумовування, коли n > 10.
У класичних підручниках зі статистики для отримання значень біномного розподілу часто рекомендують використовувати формули, що базуються на граничних теоремах (типу формули Муавра-Лапласа). Необхідно відмітити, що з суто обчислювальної точки зоруЦінність цих теорем близька до нуля, особливо зараз, коли практично на кожному столі стоїть потужний комп'ютер. Основний недолік наведених апроксимацій – їх зовсім недостатня точність при значеннях n, характерних більшості додатків. Не меншим недоліком є і відсутність скільки-небудь чітких рекомендацій щодо застосування тієї чи іншої апроксимації (у стандартних текстах наводяться лише асимптотичні формулювання, вони не супроводжуються оцінками точності і, отже, мало корисні). Я б сказав, що обидві формули придатні лише за n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Не розглядаю тут завдання пошуку квантилей: для дискретних розподілів вона тривіальна, а тих завданнях, де такі розподіли виникають, вона, зазвичай, і актуальна. Якщо ж кванти все-таки знадобляться, рекомендую так переформулювати завдання, щоб працювати з p-значеннями (спостереженими значущістю). Ось приклад: при реалізації деяких перебірних алгоритмів на кожному кроці потрібно перевіряти статистичну гіпотезупро біноміальну випадкову величину. Згідно з класичним підходом на кожному кроці потрібно обчислити статистику критерію та порівняти її значення з межею критичної множини. Оскільки, однак, алгоритм перебірний, доводиться визначати межу критичної множини щоразу заново (адже від кроку до кроку обсяг вибірки змінюється), що непродуктивно збільшує тимчасові витрати. Сучасний підхід рекомендує обчислювати спостережене значення і порівнювати її з довірчою ймовірністюекономити на пошуку квантилей.
Тому в наведених нижче кодах відсутнє обчислення зворотної функції, натомість наведена функція rev_binomialDF , яка обчислює ймовірність p успіху в окремому випробуванні за заданою кількістю n випробувань, числу m успіхів в них і значення y ймовірності отримати ці m успіхів. При цьому використовується вищезгаданий зв'язок між біноміальним та бета-розподілом.
Фактично ця функція дозволяє отримувати межі довірчих інтервалів. Справді, припустимо, що у n біноміальних випробуваннях ми здобули m успіхів. Як відомо, ліва межа двостороннього довірчого інтервалудля параметра p з довірчим рівнем дорівнює 0, якщо m = 0, а є рішенням рівняння  . Аналогічно, права межа дорівнює 1, якщо m = n, а є рішенням рівняння
. Аналогічно, права межа дорівнює 1, якщо m = n, а є рішенням рівняння  . Звідси випливає, що для пошуку лівого кордону ми маємо вирішувати щодо рівняння
. Звідси випливає, що для пошуку лівого кордону ми маємо вирішувати щодо рівняння  , а для пошуку правої – рівняння
, а для пошуку правої – рівняння  . Вони і вирішуються у функціях binom_leftCI та binom_rightCI , що повертають верхню та нижню межі двостороннього довірчого інтервалу відповідно.
. Вони і вирішуються у функціях binom_leftCI та binom_rightCI , що повертають верхню та нижню межі двостороннього довірчого інтервалу відповідно.
Хочу зауважити, що якщо не потрібна зовсім неймовірна точність, то при досить великих n можна скористатися наступною апроксимацією [Б.Л. ван дер Варден, математична статистика. М: ІЛ, 1960, гол. 2, розд. 7]:  де g – квантиль нормального розподілу. Цінність цієї апроксимації в тому, що є дуже прості наближення, що дозволяють обчислювати квантил нормального розподілу (див. текст про обчислення нормального розподілу та відповідний розділ даного довідника). У моїй практиці (в основному, при n > 100) ця апроксимація давала приблизно 3-4 знаки, чого, як правило, цілком достатньо.
де g – квантиль нормального розподілу. Цінність цієї апроксимації в тому, що є дуже прості наближення, що дозволяють обчислювати квантил нормального розподілу (див. текст про обчислення нормального розподілу та відповідний розділ даного довідника). У моїй практиці (в основному, при n > 100) ця апроксимація давала приблизно 3-4 знаки, чого, як правило, цілком достатньо.
Для обчислень за допомогою нижченаведених кодів будуть потрібні файли betaDF.h , betaDF.cpp (див. розділ про бета-розподіл), а також logGamma.h , logGamma.cpp (див. додаток А). Ви також можете подивитися приклад використання функцій.
Файл binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double successes, double p); /* * Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному. * Обчислюється ймовірність B(successes|trials,p) те, що число * успіхів укладено між 0 і "successes" (включно). */ double rev_binomialDF(double trials, double successes, double y); /* * Нехай відома ймовірність y настання не менше m успіхів * у trials випробуваннях схеми Бернуллі. Функція знаходить можливість p * успіху в окремому випробуванні. * * У обчисленнях використовується наступне співвідношення * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI(double trials, double successes, double level); /* Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному * і кількість успіхів дорівнює "successes". * Обчислюється ліва межа двостороннього довірчого інтервалу * з рівнем значущості level. */ double binom_rightCI(double n, double successes, double level); /* Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному * і кількість успіхів дорівнює "successes". * Обчислюється правий кордон двостороннього довірчого інтервалу * з рівнем значущості level. */ #endif /* Ends #ifndef __BINOMIAL_H__ */ |
Файл binomialDF.cpp
| /************************************************* **********/ /* Біноміальний розподіл */ /************************************* ***************************/ #include |
Розподіл ймовірностей дискретних випадкових величин. Біноміальний розподіл. Розподіл Пуассон. Геометричний розподіл. Виробляюча функція.
6. Розподіл ймовірностей дискретних випадкових величин
6.1. Біноміальний розподіл
Нехай проводиться nнезалежних випробувань, у кожному з яких подія Aможе або з'явиться, або з'явиться. Ймовірність pпояви події Aу всіх випробуваннях постійна та не змінюється від випробування до випробування. Розглянемо як випадкову величину X число появи події Aу цих випробуваннях. Формула, що дозволяє знайти ймовірність появи події Aрівно kраз на nвипробуваннях, як відомо, описується формулою Бернуллі
Розподіл ймовірностей, що визначається формулою Бернуллі, називається біномним .
Цей закон названий "біноміальним" тому, що праву частину можна розглядати як спільний член розкладання бінома Ньютона
Запишемо біномний закон у вигляді таблиці
|
p n |
np n –1 q |
|
q n |

Знайдемо числові показники цього розподілу.
За визначенням математичного очікуваннядля ДСВ маємо
 .
.
Запишемо рівність, що є біном Ньютона
 .
.
і продиференціюємо його з p. В результаті отримаємо
 .
.
Помножимо ліву та праву частинуна p:
 .
.
Враховуючи що p+ q=1, маємо
 (6.2)
(6.2)
Отже, математичне очікування числа події вn незалежних випробуванняхдорівнює добутку числа випробуваньnна ймовірністьpпояви події у кожному випробуванні.
Дисперсію обчислимо за формулою
 .
.
Для цього знайдемо
 .
.
Попередньо продиференціюємо формулу бінома Ньютона двічі по p:

і помножимо обидві частини рівності на p 2:

Отже,
Отже, дисперсія біномного розподілу дорівнює
 .
(6.3)
.
(6.3)
Ці результати можна отримати і з суто якісних міркувань. Загальне число X події A у всіх випробуваннях складаються з числа події в окремих випробуваннях. Тому якщо X 1 – число появи події у першому випробуванні, X 2 – у другому тощо, то загальне числопояви події A у всіх випробуваннях дорівнює X=X 1 +X 2 +…+X n. За якістю математичного очікування:
Кожна з доданків правої частини рівності є математичне очікування числа подій в одному випробуванні, яке дорівнює ймовірності події. Таким чином,
За якістю дисперсії:
Оскільки математичне очікування випадкової величини  , яке може набувати лише двох значень, а саме 1 2 з ймовірністю pта 0 2 з ймовірністю q, то
, яке може набувати лише двох значень, а саме 1 2 з ймовірністю pта 0 2 з ймовірністю q, то  . Таким чином,
. Таким чином,  В результаті, отримуємо
В результаті, отримуємо
Скориставшись поняттям початкових та центральних моментів, можна отримати формули для асиметрії та ексцесу:
 .
(6.4)
.
(6.4)

Рис. 6.1
Багатокутник біномного розподілу має такий вигляд (див. рис. 6.1). Імовірність n (k) спочатку зростає при збільшенні k, досягає найбільшого значенняі далі починає зменшуватися. Біноміальний розподіл асиметричний, за винятком випадку p=0,5. Зазначимо, що за великому числівипробувань nБіноміальний розподіл дуже близький до нормального. (Обґрунтування цієї пропозиції пов'язане з локальною теоремою Муавра-Лапласа.)Числоm 0 настання події називаєтьсянайімовірнішим якщо ймовірність настання події дана кількість разів у цій серії випробувань найбільша (максимум у багатокутнику розподілу). Для біномного розподілу
Зауваження. Цю нерівність можна довести, використовуючи рекурентну формулу для біномних ймовірностей:
 (6.6)
(6.6)
Приклад 6.1.Частка виробів вищого гатунку цьому підприємстві становить 31%. Чому дорівнює математичного очікування і дисперсія, а також найімовірніше число виробів вищого гатунку у випадково відібраної партії з 75 виробів?
Рішення. Оскільки p=0,31, q=0,69, n=75, то
M[ X] = np= 750,31 = 23,25; D[ X] = npq = 750,310,69 = 16,04.
Для знаходження найімовірнішого числа m 0 , складемо подвійну нерівність
Звідси слідує що m 0 = 23.
Розділ 7.
Конкретні закони розподілу випадкових величин
Види законів розподілу дискретних випадкових величин
Нехай дискретна випадкова величинаможе приймати значення х 1 , х 2 , …, х n, …. Імовірності цих значень можуть бути обчислені за різними формулами, наприклад, за допомогою основних теорем теорії ймовірностей, формули Бернуллі або інших формул. Для деяких із цих формул закон розподілу має свою назву.
Найбільш поширеними законами розподілу дискретної випадкової величини є біноміальний, геометричний, гіпергеометричний, закон розподілу Пуассона.
Біноміальний закон розподілу
Нехай проводиться nнезалежних випробувань, у кожному з яких може з'явитися чи не з'явитися подія А. Імовірність появи цієї події в кожному одиничному випробуванні постійна, не залежить від номера випробування і дорівнює р=Р(А). Звідси ймовірність не появи події Ау кожному випробуванні також постійна і рівна q=1–р. Розглянемо випадкову величину Хрівну числу події Ав nвипробуваннях. Очевидно, що значення цієї величини дорівнюють
х 1 = 0 - подія Ав nвипробуваннях не з'явилося;
х 2 = 1 - подія Ав nвипробування з'явилося один раз;
х 3 = 2 - подія Ав nвипробування з'явилося двічі;
…………………………………………………………..
х n +1 = n– подія Ав nвипробуваннях з'явилося все nразів.
Імовірності цих значень можуть бути обчислені за формулою Бернуллі (4.1):
де до=0, 1, 2, …,n .
Біноміальним законом розподілу Х, що дорівнює кількості успіхів у nвипробуваннях Бернуллі, з ймовірністю успіху р.
Отже, дискретна випадкова величина має біномний розподіл (або розподілена по біноміальному закону), якщо її можливі значення 0, 1, 2, …, n, А відповідні ймовірності обчислюються за формулою (7.1).
Біноміальний розподіл залежить від двох параметрів рі n.
Ряд розподілу випадкової величини, розподіленої за біноміальним законом, має вигляд:
| Х | … | k | … | n | ||
| Р | | … | … | |
приклад 7.1 . Здійснюється три незалежні постріли по мішені. Імовірність влучення при кожному пострілі дорівнює 0,4. Випадкова величина Х- Число попадань в ціль. Побудувати її низку розподілу.
Рішення. Можливими значеннями випадкової величини Хє х 1 =0; х 2 =1; х 3 =2; х 4 =3. Знайдемо відповідні можливості, використовуючи формулу Бернуллі. Неважко показати, що застосування цієї формули тут цілком виправдане. Зазначимо, що ймовірність не влучення в ціль при одному пострілі дорівнюватиме 1-0,4 = 0,6. Отримаємо

Ряд розподілу має такий вигляд:
| Х | ||||
| Р | 0,216 | 0,432 | 0,288 | 0,064 |
Неважко перевірити, що сума всіх ймовірностей дорівнює 1. Сама випадкова величина Хрозподілено за біноміальним законом. ■
Знайдемо математичне очікування та дисперсію випадкової величини, розподіленої за біноміальним законом.
При рішенні прикладу 6.5 було показано, що математичне очікування кількості події Ав nнезалежних випробувань, якщо ймовірність появи Ау кожному випробуванні постійна і рівна р, одно n· р
У цьому прикладі використовувалася випадкова величина, розподілена за біноміальним законом. Тому рішення прикладу 6.5 по суті є доказом наступної теореми.
Теорема 7.1.Математичне очікування дискретної випадкової величини, розподіленої за біноміальним законом, дорівнює добутку числа випробувань на можливість " успіху " , тобто. М(Х)=n· нар.
Теорема 7.2.Дисперсія дискретної випадкової величини, розподіленої по биномиальному закону, дорівнює добутку числа випробувань на ймовірність " успіху " і ймовірність " невдачі " , тобто. D(Х)=nрq.
Асиметрія та ексцес випадкової величини, розподіленої за біноміальним законом, визначаються за формулами
Ці формули можна отримати, скориставшись поняттям початкових та центральних моментів.
Біноміальний закон розподілу є основою багатьох реальних ситуацій. При великих значеннях nбіномний розподіл може бути апроксимований за допомогою інших розподілів, зокрема за допомогою розподілу Пуассона.
Розподіл Пуассона
Нехай є nвипробувань Бернуллі, при цьому кількість випробувань nдосить велике. Раніше було показано, що в цьому випадку (якщо до того ж ймовірність рподії Адуже мала) для знаходження ймовірності того, що подія Аз'явитися траз у випробуваннях можна скористатися формулою Пуассона (4.9). Якщо випадкова величина Хозначає кількість появи події Ав nвипробуваннях Бернуллі, то ймовірність того, що Хнабуде значення kможе бути обчислена за формулою
 , (7.2)
, (7.2)
де λ = nр.
Законом розподілу Пуассонаназивається розподіл дискретної випадкової величини Х, для якої можливими значеннями є цілі невід'ємні числа, а ймовірності р тцих значень перебувають за формулою (7.2).
Величина λ = nрназивається параметромрозподілу Пуассона.
Випадкова величина, розподілена за законом Пуассона, може набувати безліч значень. Так як для цього розподілу ймовірність рПоява події в кожному випробуванні мала, то цей розподіл іноді називають законом рідкісних явищ.
Ряд розподілу випадкової величини, розподіленої згідно із законом Пуассона, має вигляд
| Х | … | т | … | ||||
| Р | … | … |
Неважко переконатися, що сума ймовірностей другого рядка дорівнює 1. Для цього необхідно згадати, що функцію можна розкласти в рядок Маклорена, який сходиться для будь-якого х. В даному випадку маємо
 . (7.3)
. (7.3)
Як зазначалося, закон Пуассона у певних граничних випадках замінює биномиальный закон. Як приклад можна навести випадкову величину Хзначення якої рівні кількості збоїв за певний проміжок часу при багаторазовому застосуванні технічного пристрою. У цьому передбачається, що це пристрій високої надійності, тобто. ймовірність збою при одному застосуванні дуже мала.
Крім таких граничних випадків, на практиці трапляються випадкові величини, розподілені за законом Пуассона, не пов'язані з біномним розподілом. Наприклад, розподіл Пуассона часто використовується тоді, коли мають справу з кількістю подій, що з'являються в проміжку часу (кількість надходжень викликів на телефонну станцію протягом години, кількість машин, що прибули на автомийку протягом доби, кількість зупинок верстатів на тиждень і т.п. .). Всі ці події повинні утворювати так званий потік подій, який є одним з основних понять теорії масового обслуговування. Параметр λ характеризує середню інтенсивність потоку подій.
У цій і кількох наступних нотатках ми розглянемо математичні моделі випадкових подій. Математична модель- це математичний вираз, Що представляє випадкову величину Для дискретних випадкових величин цей математичний вираз відомий під назвою функція розподілу.
Якщо завдання дозволяє явно записати математичне вираз, що становить випадкову величину, можна обчислити точну ймовірність будь-якого її значення. У цьому випадку можна обчислити та перерахувати всі значення функції розподілу. У ділових, соціологічних та медичних додатках зустрічаються різноманітні розподіли випадкових величин. Одним із найкорисніших розподілів є біномне.
Біноміальний розподілвикористовується для моделювання ситуацій, що характеризуються такими особливостями.
- Вибірка складається з фіксованого числа елементів n, що є результатами якогось випробування.
- Кожен елемент вибірки належить одній із двох взаємовиключних категорій, які вичерпують весь вибірковий простір. Як правило, ці дві категорії називають успіх та невдача.
- Ймовірність успіху рє постійною. Отже, ймовірність невдачі дорівнює 1 – р.
- Вихід (тобто удача чи невдача) будь-якого випробування залежить від результату іншого випробування. Щоб гарантувати незалежність результатів, елементи вибірки зазвичай отримують за допомогою двох різних методів. Кожен елемент вибірки випадково витягується з нескінченної генеральної сукупностібез повернення або з кінцевої генеральної сукупності з поверненням.
Завантажити нотатку у форматі або , приклади у форматі
Біноміальний розподіл використовується для оцінки кількості успіхів у вибірці, що складається з nспостережень. Розглянемо як приклад оформлення замовлень. Щоб зробити замовлення, клієнти компанії Saxon Company можуть скористатися інтерактивною електронною формою і надіслати її в компанію. Потім інформаційна система перевіряє, чи немає у замовленнях помилок, і навіть неповної чи недостовірної інформації. Будь-яке замовлення, що викликає сумніви, позначається та включається до щоденного звіту про виняткові ситуації. Дані, зібрані компанією, свідчать, що ймовірність помилок у замовленнях дорівнює 0,1. Компанія хотіла б знати, яка ймовірність виявити певну кількість помилкових замовлень у заданій вибірці. Наприклад, припустимо, що клієнти заповнили чотири електронних форм. Яка ймовірність, що всі замовлення виявляться безпомилковими? Як визначити цю можливість? Під успіхом розумітимемо помилку при заповненні форми, а всі інші результати вважатимемо невдачею. Нагадаємо, що нас цікавить кількість помилкових замовлень у заданій вибірці.
Які результати ми можемо спостерігати? Якщо вибірка складається з чотирьох замовлень, помилковими можуть бути одне, два, три чи всі чотири, крім того, всі вони можуть виявитися правильно заповненими. Чи може випадкова величина, що описує кількість неправильно заповнених форм, набувати будь-якого іншого значення? Це неможливо, оскільки кількість неправильно заповнених форм не може перевищувати обсяг вибірки nчи бути негативним. Таким чином, випадкова величина, що підпорядковується біноміальному закону розподілу, набуває значення від 0 до n.
Припустимо, що у вибірці із чотирьох замовлень спостерігаються такі результати:
Яка ймовірність виявити три помилкові замовлення у вибірці, що складається з чотирьох замовлень, причому у зазначеній послідовності? Оскільки попередні дослідження показали, що ймовірність помилки при заповненні форми дорівнює 0,10, ймовірності зазначених вище результатів обчислюються таким чином:
Оскільки результати не залежать один від одного, ймовірність зазначеної послідовності результатів дорівнює: р * р * (1-р) * р = 0,1 * 0,1 * 0,9 * 0,1 = 0,0009. Якщо необхідно обчислити кількість варіантів вибору X nелементів, слід скористатися формулою поєднань (1):

де n! = n * (n -1) * (n - 2) * ... * 2 * 1 - факторіал числа n, причому 0! = 1 та 1! = 1 за визначенням.
Цей вираз часто позначають як . Таким чином, якщо n = 4 і X = 3, кількість послідовностей, що складаються з трьох елементів, вилучених з вибірки, обсяг якої дорівнює 4, визначається за такою формулою:
Отже, ймовірність виявити три помилкові замовлення обчислюється так:
(Кількість можливих послідовностей) *
(ймовірність конкретної послідовності) = 4*0,0009 = 0,0036
Аналогічно можна обчислити ймовірність того, що серед чотирьох замовлень виявляться одне або два помилкові, а також ймовірність того, що всі замовлення помилкові або всі вірні. Однак при збільшенні обсягу вибірки nвизначити ймовірність конкретної послідовності результатів стає складніше. У цьому випадку слід застосувати відповідну математичну модель, що описує біномне розподіл кількості варіантів вибору Xоб'єктів з вибірки, що містить nелементів.
Біномінальний розподіл

де Р(Х)- ймовірність Xуспіхів при заданих обсягах вибірки nта ймовірності успіху р, X = 0, 1, … n.
Зверніть увагу на те, що формула (2) є формалізацією інтуїтивних висновків. Випадкова величина X, що підпорядковується біномному розподілу, може приймати будь-яке ціле значення в діапазоні від 0 до n. твір рX(1 – р)n – Xє ймовірність конкретної послідовності, що складається з Xуспіхів у вибірці, обсяг якої дорівнює n. Величина визначає кількість можливих комбінацій, що складаються з Xуспіхів у nвипробуваннях. Отже, при заданій кількості випробувань nта ймовірності успіху рймовірність послідовності, що складається з Xуспіхів, дорівнює
Р(Х) = (кількість можливих послідовностей) * (ймовірність конкретної послідовності) = 
Розглянемо приклади, що ілюструють застосування формули (2).
1. Припустимо, що можливість невірно заповнити форму дорівнює 0,1. Яка ймовірність того, що серед чотирьох заповнених форм три виявляться хибними? Використовуючи формулу (2), отримуємо, що ймовірність виявити три помилкові замовлення у вибірці, що складається з чотирьох замовлень, дорівнює
2. Припустимо, що можливість невірно заповнити форму дорівнює 0,1. Яка ймовірність того, що серед чотирьох заповнених форм не менше трьох виявляться хибними? Як показано в попередньому прикладі, ймовірність того, що серед чотирьох заповнених форм три виявляться помилковими, дорівнює 0,0036. Щоб обчислити ймовірність того, що серед чотирьох заповнених форм не менше трьох будуть неправильно заповнені, необхідно скласти ймовірність того, що серед чотирьох заповнених форм три виявляться помилковими, і ймовірність того, що серед чотирьох заповнених форм виявляться помилковими. Імовірність другої події дорівнює
Таким чином, ймовірність того, що серед чотирьох заповнених форм не менше трьох виявляться помилковими, дорівнює
Р(Х> 3) = Р(Х = 3) + Р(Х = 4) = 0,0036 + 0,0001 = 0,0037
3. Припустимо, що можливість невірно заповнити форму дорівнює 0,1. Яка ймовірність того, що серед чотирьох заповнених форм менше трьох виявляться хибними? Імовірність цієї події
Р(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Використовуючи формулу (2), обчислимо кожну з цих ймовірностей:

Отже, Р(Х< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Імовірність Р(Х< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Тоді Р(Х< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
У міру збільшення обсягу вибірки nобчислення, аналогічні проведеним у прикладі 3, стають скрутними. Щоб уникати цих складнощів, багато біномних ймовірностей табулюють заздалегідь. Деякі з цих ймовірностей наведені на рис. 1. Наприклад, щоб отримати ймовірність, що Х= 2 при n= 4 та p= 0,1, слід витягти з таблиці число, яке стоїть на перетині рядка Х= 2 і стовпця р = 0,1.

Рис. 1. Біноміальна ймовірність при n = 4, Х= 2 і р = 0,1
Біноміальний розподіл можна обчислити за допомогою функції Excel=БІНОМ.РАСП() (рис. 2), що має 4 параметри: число успіхів - Х, Число випробувань (або обсяг вибірки) - n, ймовірність успіху – р, параметр інтегральна, Що приймає значення ІСТИНА (у цьому випадку обчислюється ймовірність не менше Хподій) або БРЕХНЯ (у цьому випадку обчислюється ймовірність точно Хподій).

Рис. 2. Параметри функції =БІНОМ.РАСП()
Для наведених вище трьох прикладів розрахунки наведені на рис. 3 (див. також файл Excel). У кожному стовпці наведено за однією формулою. Цифрами показано відповіді приклади відповідного номера).

Рис. 3. Розрахунок біномінального розподілу в Excel для n= 4 та p = 0,1
Властивості біномного розподілу
Біноміальний розподіл залежить від параметрів nі р. Біноміальний розподіл може бути як симетричним, так і асиметричним. Якщо р = 0,05, біномний розподіл є симетричним незалежно від величини параметра n. Однак, якщо р ≠ 0,05, розподіл стає асиметричним. Чим ближче значення параметра рдо 0,05 і чим більший обсяг вибірки n, Тим слабше виражена асиметрія розподілу. Таким чином, розподіл кількості неправильно заповнених форм зміщено вправо, оскільки p= 0,1 (рис. 4).

Рис. 4. Гістограма біномного розподілу при n= 4 та p = 0,1
Математичне очікування біномного розподілудорівнює добутку обсягу вибірки nна ймовірність успіху р:
(3) Μ = Е(Х) =np
У середньому, при досить довгій серії випробувань у вибірці, що складається з чотирьох замовлень, може бути р = Е(Х) = 4 х 0,1 = 0,4 неправильно заповнених форм.
Стандартне відхилення біномного розподілу
Наприклад, стандартне відхилення кількості невірно заповнених форм у бухгалтерській інформаційної системиодно:
Використовуються матеріали книги Левін та ін. Статистика менеджерів. - М.: Вільямс, 2004. - с. 307–313
Розглянемо Біноміальний розподіл, обчислимо його математичне очікування, дисперсію, моду. За допомогою функції MS EXCEL БІНОМ.РАСП() побудуємо графіки функції розподілу та щільності ймовірності. Зробимо оцінку параметра розподілу p, математичного очікування розподілу та стандартного відхилення. Також розглянемо розподіл Бернуллі.
Визначення. Нехай проводяться nвипробувань, у кожному з яких може відбутися лише дві події: подія «успіх» з ймовірністю p або подія «невдача» з ймовірністю q =1-p (так звана Схема Бернуллі,Bernoullitrials).
Імовірність отримання рівно x успіхів у цих n випробуваннях дорівнює:
Кількість успіхів у вибірці x є випадковою величиною, яка має Біноміальний розподіл(англ. Binomialdistribution) pі n– є параметрами цього розподілу.
Нагадаємо, що для застосування схеми Бернулліі відповідно Біноміального розподілу,повинні бути виконані такі умови:
- кожне випробування повинно мати рівно два результати, що умовно називають «успіхом» і «невдачею».
- результат кожного випробування повинен залежати від результатів попередніх випробувань (незалежність випробувань).
- ймовірність успіху p має бути постійною для всіх випробувань.
Біноміальний розподіл у MS EXCEL
У MS EXCEL, починаючи з версії 2010, для Біноміального розподілує функція БІНОМ.РАСП() , англійська назва- BINOM.DIST(), яка дозволяє обчислити ймовірність того, що у вибірці буде рівно х"Успіхів" (тобто. функцію щільності ймовірності p(x), див. формулу вище), і інтегральну функцію розподілу(ймовірність того, що у вибірці буде xабо менше "успіхів", включаючи 0).
До MS EXCEL 2010 EXCEL була функція БІНОМРАСП() , яка також дозволяє обчислити функцію розподілуі щільність імовірності p(x). БІНОМРАСП() залишено в MS EXCEL 2010 для сумісності.
У файлі прикладу наведено графіки густини розподілу ймовірностіі .

Біноміальний розподілмає позначення B(n; p) .
Примітка: Для побудови інтегральної функції розподілуідеально підходить діаграма типу Графік, для щільності розподілу – Гістограма з угрупуванням. Докладніше про побудову діаграм читайте статтю Основні типи діаграм.
Примітка: Для зручності написання формул у файлі прикладу створено Імена для параметрів Біноміального розподілу: n та p.

У прикладному файлі наведено різні розрахунки ймовірності за допомогою функцій MS EXCEL:
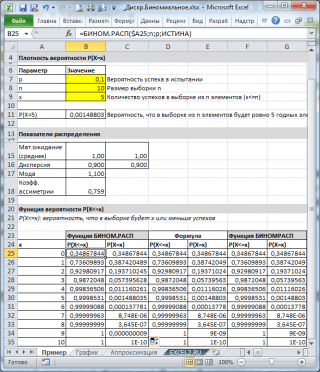
Як видно на картинці вище, передбачається, що:
- У нескінченній сукупності, з якої робиться вибірка, міститься 10% (або 0,1) придатних елементів (параметр p, Третій аргумент функції = БІНОМ.РАСП() )
- Щоб обчислити ймовірність того, що у вибірці з 10 елементів (параметр n, другий аргумент функції) буде рівно 5 придатних елементів (перший аргумент), потрібно записати формулу: =БІНОМ.РАСП(5; 10; 0,1; БРЕХНЯ)
- Останній, четвертий елемент, встановлений = БРЕХНЯ, тобто. повертається значення функції щільності розподілу.
Якщо значення четвертого аргументу = ІСТИНА, то функція БІНОМ.РАСП() повертає значення інтегральної функції розподілуабо просто Функцію розподілу. У цьому випадку можна розрахувати ймовірність того, що у вибірці кількість придатних елементів буде з певного діапазону, наприклад, 2 або менше (включаючи 0).
Для цього потрібно записати формулу:
= БІНОМ.РАСП(2; 10; 0,1; ІСТИНА)
Примітка: При нецілому значенні х, . Наприклад, такі формули повернуть одне й теж значення:
=БІНОМ.РАСП( 2
; 10; 0,1; ІСТИНА)
=БІНОМ.РАСП( 2,9
; 10; 0,1; ІСТИНА)
Примітка: У файлі прикладу щільність імовірностіі функція розподілутакож обчислені з використанням визначення та функції ЧИСЛКОМБ() .
Показники розподілу
У файл прикладу на аркуші Прикладє формули для розрахунку деяких показників розподілу:
- =n * p;
- (квадрату стандартного відхилення) = n * p * (1-p);
- = (n + 1) * p;
- =(1-2*p)*КОРІНЬ(n*p*(1-p)).
Виведемо формулу математичного очікування Біноміального розподілу, використовуючи Схему Бернуллі.
За визначенням випадкова величина Х в схемою Бернуллі(Bernoulli random variable) має функцію розподілу:

Цей розподіл називається розподіл Бернуллі.
Примітка: розподіл Бернуллі- окремий випадок Біноміального розподілуіз параметром n=1.
Згенеруємо 3 масиви по 100 чисел з різними ймовірностями успіху: 0,1; 0,5 та 0,9. Для цього у вікні Генерація випадкових чисел встановимо такі параметри кожної ймовірності p:

Примітка: Якщо встановити опцію Випадкове розсіювання (Random Seed), то можна вибрати певний випадковий набір згенерованих чисел. Наприклад, встановивши цю опцію =25 можна згенерувати різних комп'ютерах одні й самі набори випадкових чисел (якщо, звісно, інші параметри розподілу збігаються). Значення опції може приймати цілі значення від 1 до 32767. Назва опції Випадкове розсіюванняможе заплутати. Краще було б її перекласти як Номер набору з довільними числами.
У результаті матимемо 3 стовпці по 100 чисел, на підставі яких можна, наприклад, оцінити ймовірність успіху pза формулою: Число успіхів/100(Див. файл прикладу лист ГенераціяБернуллі).

Примітка: Для розподілу Бернулліз p = 0,5 можна використовувати формулу = ВИПАД МІЖ (0; 1), яка відповідає .
Генерація випадкових чисел. Біноміальний розподіл
Припустимо, що у вибірці виявилося 7 дефектних виробів. Це означає, що «дуже ймовірна» ситуація, що змінилася частка дефектних виробів pяка є характеристикою нашого виробничого процесу. Хоча така ситуація «дуже ймовірна», але існує ймовірність (альфа-ризик, помилка 1-го роду, «хибна тривога»), що все ж таки pзалишилася без змін, а збільшена кількість дефектних виробів зумовлена випадковістю вибірки.
Як видно на малюнку нижче, 7 – кількість дефектних виробів, яка припустима для процесу з p=0,21 при тому ж значенні Альфа. Це є ілюстрацією, що з перевищенні порогового значення дефектних виробів у вибірці, p«швидше за все» збільшилося. Фраза «швидше за все» означає, що існує лише 10% ймовірність (100%-90%) того, що відхилення частки дефектних виробів вище порогового викликане лише сучайними причинами.

Таким чином, перевищення порогової кількості дефектних виробів у вибірці, може бути сигналом, що процес засмутився і став випускати б ольший відсоток бракованих виробів.
Примітка: До MS EXCEL 2010 у EXCEL була функція КРИТБІНОМ(), яка еквівалентна БІНОМ.ОБР(). КРИТБІНОМ залишена в MS EXCEL 2010 і вище для сумісності.
Зв'язок Біноміального розподілу з іншими розподілами
Якщо параметр n Біноміального розподілупрагне нескінченності, а pпрагне до 0, то в цьому випадку Біноміальний розподілможе бути апроксимовано.
Можна сформулювати умови, коли наближення розподілом Пуассонапрацює добре:
- p<0,1 (чим менше pі більше n, Тим наближення точніше);
- p>0,9 (враховуючи що q=1- p, обчислення в цьому випадку необхідно проводити через q(а хпотрібно замінити на n- x). Отже, чим менше qі більше n, Тим наближення точніше).
При 0,1<=p<=0,9 и n*p>10 Біноміальний розподілможна апроксимувати.
В свою чергу, Біноміальний розподілможе бути хорошим наближенням , коли розмір сукупності N Гіпергеометричного розподілунабагато більше розміру вибірки n (тобто N>>n або n/N<<1).
Докладніше про зв'язок вищезгаданих розподілів, можна прочитати у статті . Там же наведено приклади апроксимації, і пояснено умови, коли вона можлива і з якоюсь точністю.
ПОРАДА: Про інші розподіли MS EXCEL можна прочитати у статті .
