هموارسازی نمایی و مدل های پیش بینی سری های زمانی متحرک میانگین نمایی روش هموارسازی در اکسل
شناسایی و تجزیه و تحلیل روند یک سری زمانی اغلب با کمک تراز یا هموارسازی آن انجام می شود. هموارسازی نمایی یکی از ساده ترین و رایج ترین تکنیک های هم ترازی سری است. هموارسازی نمایی را می توان به عنوان یک فیلتر نشان داد که ورودی آن به ترتیب توسط اعضای سری اصلی دریافت می شود و مقادیر فعلی میانگین نمایی در خروجی تشکیل می شود.
بگذارید یک سری زمانی باشد.
هموارسازی نمایی سری طبق فرمول تکرارشونده انجام می شود: , .
هرچه α کوچکتر باشد، نوسانات سری اصلی و نویز فیلتر شده و سرکوب شده است.
اگر از این رابطه بازگشتی به طور مداوم استفاده شود، میانگین نمایی را می توان بر حسب مقادیر سری زمانی X بیان کرد.
اگر داده های قبلی تا زمان شروع هموارسازی وجود داشته باشد، می توان از میانگین حسابی همه یا برخی از داده های موجود به عنوان مقدار اولیه استفاده کرد.
پس از ظهور آثار R. Brown، اغلب از هموارسازی نمایی برای حل مشکل پیش بینی کوتاه مدت سری های زمانی استفاده می شود.
فرمول بندی مسئله
بگذارید سری زمانی داده شود: .
حل مشکل پیش بینی سری های زمانی ضروری است، یعنی. پیدا کردن
افق پیش بینی، ضروری است که
به منظور در نظر گرفتن منسوخ بودن داده ها، یک توالی غیر افزایشی از وزن ها را معرفی می کنیم، سپس
مدل قهوه ای
فرض کنید D کوچک است (پیش بینی کوتاه مدت)، سپس برای حل چنین مشکلی از آن استفاده کنید مدل قهوه ای.
اگر پیش بینی را یک گام جلوتر در نظر بگیریم، پس - خطای این پیش بینی، و پیش بینی جدید در نتیجه تعدیل پیش بینی قبلی با در نظر گرفتن خطای آن به دست می آید - جوهر انطباق.
در پیشبینی کوتاهمدت، مطلوب است که تغییرات جدید در اسرع وقت منعکس شود و در عین حال سریها را از نوسانات تصادفی به بهترین شکل ممکن "پاک کنید". که افزایش وزن مشاهدات اخیر: .
از سوی دیگر، برای صاف کردن انحرافات تصادفی، α باید کاهش یابد: .
که این دو الزام با هم تضاد دارند. جستجو برای مقدار مصالحهای α، مسئله بهینهسازی مدل است. معمولا α از بازه (0.1/3) گرفته می شود.
مثال ها

کار کنید هموارسازی نماییبا α=0.2 بر اساس داده های گزارش های ماهانه فروش یک برند خودروی خارجی در روسیه برای دوره ژانویه 2007 تا اکتبر 2008. بیایید به افت شدید در ژانویه و فوریه توجه کنیم، زمانی که فروش به طور سنتی در ابتدای تابستان کاهش و افزایش می یابد. .
چالش ها و مسائل
این مدل فقط با یک افق پیشبینی کوچک کار میکند. روند و تغییرات فصلی در نظر گرفته نشده است. برای در نظر گرفتن تأثیر آنها، پیشنهاد می شود از مدل های زیر استفاده شود: Holt (روند خطی در نظر گرفته می شود)، Holt-Winters (روند نمایی ضربی و فصلی)، Theil-Wage (روند خطی افزودنی و فصلی).
یک مدل سری زمانی ساده و منطقی به شکل زیر است:
Y t = b + e t
y، = b + rn (11.5)
جایی که b ثابت است، e یک خطای تصادفی است. ثابت b در هر بازه زمانی نسبتاً پایدار است، اما ممکن است در طول زمان به آرامی تغییر کند. یکی از راه های شهودی برای استخراج مقدار b از داده ها استفاده از هموارسازی میانگین متحرک است که در آن به آخرین مشاهدات وزن های بالاتری نسبت به مشاهدات ماقبل آخر داده می شود، مشاهدات ماقبل آخر وزن بیشتری نسبت به مشاهدات ماقبل آخر دارند و غیره. هموارسازی نمایی ساده فقط همین است. در اینجا، وزنهایی که به صورت تصاعدی کاهش مییابند به مشاهدات قدیمیتر اختصاص داده میشوند، در حالی که، برخلاف میانگین متحرک، همه مشاهدات قبلی سری در نظر گرفته میشوند، و نه فقط آنهایی که در یک پنجره خاص قرار میگیرند. فرمول دقیق هموارسازی نمایی ساده به صورت زیر است:
S t = a y t + (1 - a) S t -1
هنگامی که این فرمول به صورت بازگشتی اعمال می شود، هر مقدار هموار شده جدید (که یک پیش بینی نیز است) به عنوان میانگین وزنی مشاهده جاری و سری هموار محاسبه می شود. بدیهی است که نتیجه هموارسازی به پارامتر a بستگی دارد . اگر a 1 باشد، مشاهدات قبلی کاملاً نادیده گرفته می شوند. اگر a 0 باشد، مشاهدات فعلی نادیده گرفته می شوند. مقادیر بین 0 و 1 نتایج متوسطی را ارائه می دهد. مطالعات تجربی نشان داده اند که یک هموارسازی نمایی ساده اغلب پیش بینی نسبتاً دقیقی را ارائه می دهد.
در عمل معمولا توصیه می شود کمتر از 0.30 بگیرید. با این حال، انتخاب بیشتر از 0.30 گاهی اوقات پیش بینی دقیق تری می دهد. این بدان معناست که بهتر است ارزیابی شود مقدار بهینهبر روی داده های واقعی به جای استفاده از دستورالعمل های کلی.
در عمل، پارامتر هموارسازی بهینه اغلب با استفاده از روش جستجوی شبکه ای جستجو می شود. محدوده احتمالی مقادیر پارامتر توسط یک شبکه با یک مرحله خاص تقسیم می شود. به عنوان مثال، شبکه ای از مقادیر a = 0.1 تا a = 0.9 را با گام 0.1 در نظر بگیرید. سپس مقدار a انتخاب می شود که مجموع مربعات (یا میانگین مربعات) باقیمانده ها (مقادیر مشاهده شده منهای پیش بینی های یک قدم جلوتر) حداقل باشد.
مایکروسافت اکسلدارای تابع هموارسازی نمایی است که معمولاً برای هموارسازی سطوح یک سری زمانی تجربی بر اساس روش هموارسازی نمایی ساده استفاده میشود. برای فراخوانی این تابع، Tools Þ Data Analysis را از نوار منو انتخاب کنید. پنجره Analysis Data بر روی صفحه باز می شود که در آن باید مقدار Exponential Smoothing (Exponential smoothing) را انتخاب کنید. در نتیجه کادر محاوره ای هموارسازی نمایی ظاهر می شود.
در کادر محاورهای هموارسازی نمایی، تقریباً همان پارامترهایی که در کادر محاورهای که در بالا بحث شد تنظیم میشوند. میانگین متحرک.
1. Input Range (Input Range) - در این قسمت محدوده ای از سلول ها حاوی مقادیر پارامتر مورد مطالعه وارد می شود.
2. برچسب ها - این چک باکس اگر علامت زده شود
اولین سطر (ستون) در محدوده ورودی حاوی یک هدر است. اگر سرصفحه وجود ندارد، کادر انتخاب باید پاک شود. در این حالت، نام های استاندارد به طور خودکار برای داده های محدوده خروجی تولید می شود.
3. ضریب میرایی - مقدار ضریب هموارسازی نمایی انتخاب شده a را در این قسمت وارد کنید. مقدار پیش فرض a = 0.3 است.
4. گزینه های خروجی - در این گروه، علاوه بر تعیین محدوده ای از سلول ها برای داده های خروجی در قسمت Output Range، می توانید نیاز به ترسیم خودکار نمودار نیز داشته باشید که برای این کار باید گزینه Chart Output را تیک بزنید و استاندارد را محاسبه کنید. خطاها، که برای آنها باید گزینه Standard Errog (Errors Standard) را تیک بزنید.
وظیفه 2.با استفاده از برنامه مایکروسافت اکسل، با استفاده از تابع هموارسازی نمایی، بر اساس داده های مربوط به حجم خروجی Task 1، سطوح خروجی صاف شده و خطاهای استاندارد را محاسبه کنید. سپس داده های واقعی و پیش بینی شده را با استفاده از نمودار ارائه دهید. نکته: شما باید یک جدول و نمودار مشابه آنچه در کار 1 انجام شده است، اما با سطوح هموار متفاوت و خطاهای استاندارد دریافت کنید.
روش هم ترازی تحلیلی
که در آن مقادیر نظری سری های زمانی مطابق با مربوطه محاسبه می شود معادله تحلیلیدر زمان t.
تعیین مقادیر نظری (محاسبه شده) بر اساس به اصطلاح کافی انجام می شود. مدل ریاضی، که بهترین راهروند اصلی توسعه سری های زمانی را نشان می دهد.
سادهترین مدلها (فرمولها) که روند توسعه را بیان میکنند به شرح زیر هستند:
تابع خطی که نمودار آن یک خط مستقیم است:
تابع نمایی:
Y t = a 0 * a 1 t
تابع توان مرتبه دوم که نمودار آن سهمی است:
Y t = a 0 + a 1 * t + a 2 * t 2
تابع لگاریتمی:
Y t = a 0 + a 1 * ln تی
محاسبه پارامترهای تابع معمولاً با روش انجام می شود کمترین مربعاتکه در آن حداقل نقطه از مجموع مجذور انحرافات بین سطوح نظری و تجربی به عنوان راه حل در نظر گرفته شده است:
![]()
که در آن - سطوح تراز شده (محاسبه شده)، و Yt - سطوح واقعی.
پارامترهای معادله a i که این شرط را برآورده می کنند را می توان با حل سیستم پیدا کرد معادلات عادی. بر اساس معادله روند یافت شده، سطوح تراز شده محاسبه می شوند.
تراز خط مستقیمدر مواردی استفاده می شود که سود مطلق عملاً ثابت است، یعنی. هنگامی که سطوح در یک پیشرفت حسابی (یا نزدیک به آن) تغییر می کنند.
تراز توسط تابع نمایی زمانی اعمال می شود که این مجموعه منعکس کننده پیشرفت در حرفه هندسی باشد، یعنی. عوامل رشد زنجیره ای عملا ثابت هستند.
تراز توسط تابع توان (پارابولای مرتبه دوم) زمانی استفاده می شود که سری دینامیک با ثابت تغییر کند سرعت زنجیره ایرشد
تراز توسط تابع لگاریتمی زمانی استفاده میشود که سری توسعه با رشد آهستهتر را در پایان دوره منعکس کند، یعنی. زمانی که افزایش سطوح نهایی سری زمانی به صفر میل می کند.
با توجه به پارامترهای محاسبه شده، مدل روند تابع سنتز می شود، یعنی. به دست آوردن مقادیر a 0 , a 1 , a ,2 و جایگزینی آنها در معادله مورد نظر.
صحت محاسبات سطوح تحلیلی را می توان با شرایط زیر بررسی کرد: مجموع مقادیر سری تجربی باید با مجموع سطوح محاسبه شده سری تراز شده مطابقت داشته باشد. در این مورد، ممکن است یک خطای کوچک در محاسبات به دلیل گرد کردن مقادیر محاسبه شده رخ دهد:
برای ارزیابی دقت مدل روند، از ضریب تعیین استفاده می شود:

که در آن واریانس داده های نظری به دست آمده از مدل روند، و واریانس داده های تجربی است.
مدل روند برای فرآیند مورد مطالعه کافی است و روند توسعه آن را در مقادیر R2 نزدیک به 1 منعکس می کند.
پس از انتخاب مناسب ترین مدل، می توانید برای هر یک از دوره ها پیش بینی کنید. هنگام انجام پیش بینی ها، آنها نه با یک نقطه، بلکه با تخمین فاصله ای عمل می کنند و به اصطلاح فاصله های اطمینان پیش بینی را تعیین می کنند. مقدار فاصله اطمینان در تعیین می شود نمای کلیبه روش زیر:

میانگین کجاست انحراف معیاراز روند تا-مقدار جدولی آزمون t Student در سطح معناداری آ، که به سطح معنی داری بستگی دارد آ(%) و تعداد درجات آزادی k = n- تیمقدار - با فرمول تعیین می شود:

مقادیر واقعی و محاسبه شده سطوح سری پویا کجا و هستند. پ -تعداد سطوح ردیف؛ تی- تعداد پارامترهای معادله روند (برای معادله خط مستقیم تی - 2، برای معادله سهمی مرتبه 2 t = 3).
بعد از محاسبات لازمبازه زمانی که مقدار پیش بینی شده با احتمال معینی در آن قرار می گیرد تعیین می شود.
استفاده از مایکروسافت اکسل برای ساخت مدل های روند بسیار ساده است. ابتدا سری زمانی تجربی باید به صورت نمودار یکی از انواع زیر ارائه شود: هیستوگرام، نمودار میله ای، نمودار، نمودار پراکندگی، نمودار مساحتی، و سپس روی یکی از نشانگرهای داده روی نمودار کلیک راست کنید. در نتیجه، خود سری زمانی روی نمودار برجسته می شود و منوی زمینه روی صفحه باز می شود. از این منو دستور Add Trendline را انتخاب کنید. کادر محاوره ای Add Trendline نمایش داده می شود.
در تب Type این کادر محاوره ای، نوع روند مورد نیاز انتخاب شده است:
1. خطی (خطی);
2. لگاریتمی (Logarithmic);
3. چند جمله ای، از درجه 2 تا 6 شامل (Polinomial);
4. قدرت (قدرت);
5. نمایی (نمای);
6. میانگین متحرک، با نشانگر دوره هموارسازی از 2 تا 15 (میانگین متحرک).
در تب گزینههای این کادر محاورهای، گزینههای روند اضافی تنظیم میشوند.
1. Trendline Name (Name of the smoothed curve) - در این گروه نامی انتخاب می شود که برای نشان دادن تابعی که برای هموارسازی سری های زمانی استفاده می شود، روی نمودار نمایش داده می شود. گزینه های زیر ممکن است:
♦ خودکار - هنگامی که دکمه رادیویی روی این موقعیت تنظیم می شود، مایکروسافت اکسل به طور خودکار نام تابع هموارسازی روند را بر اساس نوع روند انتخابی، مانند Linear (تابع خطی) تولید می کند.
♦ سفارشی - وقتی دکمه رادیویی روی این موقعیت تنظیم می شود، می توانید نام خود را برای تابع روند در کادر سمت راست، حداکثر تا 256 کاراکتر وارد کنید.
2. Forecast (Forecast) - در این گروه می توانید تعیین کنید که چند دوره قبل (فیلد Forward) می خواهید یک خط روند را به آینده طرح کنید و چند دوره به عقب (فیلد Backward) می خواهید یک خط روند را به گذشته ارائه دهید. (این فیلدها در حالت میانگین متحرک موجود نیستند).
3. تنظیم فاصله (قطع منحنی با محور Y در یک نقطه) - این چک باکس و فیلد ورودی واقع در سمت راست به شما امکان می دهد مستقیماً نقطه ای را که خط روند باید محور Y را قطع کند مشخص کنید (این فیلدها در دسترس نیستند. برای همه حالت ها).
4. نمایش معادله روی نمودار - وقتی این گزینه تیک خورده باشد، معادله ای که خط روند هموارسازی را توصیف می کند روی نمودار نمایش داده می شود.
5. مقدار R-squared را روی نمودار نمایش دهید R2)-وقتی این چک باکس علامت زده شود، نمودار مقدار ضریب تعیین را نشان می دهد.
نوارهای خطا همچنین می توانند همراه با یک خط روند در نمودار سری زمانی نمایش داده شوند. برای درج نوارهای خطا، یک سری داده را انتخاب کنید، روی آن کلیک راست کنید و دستور Format Data Series را از منوی زمینه باز شده انتخاب کنید. گفتگوی Format Series Data Series روی صفحه باز می شود که در آن باید به تب Y Error Bars (Y-errors) بروید.
در این تب با استفاده از سوییچ مقدار Error نوع میله ها و گزینه محاسبه آنها را بسته به نوع خطا انتخاب می کنید.
1. مقدار ثابت (مقدار ثابت) - هنگامی که سوئیچ در این موقعیت قرار می گیرد، مقدار ثابت مشخص شده در قسمت شمارنده در سمت راست به عنوان مقدار خطای مجاز در نظر گرفته می شود.
2. درصد (مقدار نسبی) - هنگامی که سوئیچ در این موقعیت قرار می گیرد، انحراف مجاز برای هر نقطه داده بر اساس مقدار درصد مشخص شده در قسمت شمارنده در سمت راست محاسبه می شود.
3. انحراف(های) استاندارد - هنگامی که سوئیچ در این موقعیت قرار می گیرد، انحراف استاندارد برای هر نقطه داده محاسبه می شود، که سپس در عدد مشخص شده در قسمت شمارنده در سمت راست ضرب می شود.
4. خطای استاندارد - هنگامی که سوئیچ در این موقعیت قرار می گیرد، مقدار خطای استاندارد در نظر گرفته می شود که برای همه موارد داده ثابت است.
5. سفارشی (سفارشی) - هنگامی که سوئیچ در این موقعیت تنظیم می شود، یک آرایه دلخواه از مقادیر انحراف در جهت مثبت و / یا منفی وارد می شود (شما می توانید پیوندهایی را به طیف وسیعی از سلول ها وارد کنید).
نوارهای خطا را نیز می توان قالب بندی کرد. برای انجام این کار، آنها را با کلیک بر روی دکمه سمت راست ماوس انتخاب کنید و دستور Format Error Bars را از منوی زمینه باز شده انتخاب کنید.
وظیفه 3.با استفاده از برنامه مایکروسافت اکسل، بر اساس داده های مربوط به حجم موضوع 1، باید:
یک سری زمانی را به صورت نموداری که با استفاده از Chart Wizard ساخته شده است، ارائه دهید. سپس یک خط روند اضافه کنید و مناسب ترین نسخه معادله را انتخاب کنید.
نتایج را در قالب جدول "انتخاب معادله روند" ارائه دهید:
جدول "انتخاب معادله روند"
معادله انتخاب شده را به صورت گرافیکی، رسم داده ها بر روی نام تابع به دست آمده و مقدار قابلیت اطمینان تقریبی (R 2) ارائه دهید.
تکلیف 4. به سوالات زیر پاسخ دهید:
1. هنگام تجزیه و تحلیل روند برای یک مجموعه داده خاص، ضریب تعیین برای مدل خطی 0.95، برای مدل لگاریتمی - 0.8، و برای چند جمله ای درجه سوم - 0.9636 است. کدام مدل روند برای فرآیند مورد مطالعه مناسبتر است:
الف) خطی؛
ب) لگاریتمی؛
ج) چند جمله ای درجه 3.
2. با توجه به داده های ارائه شده در کار 1، حجم خروجی را در سال 2003 پیش بینی کنید. چه روند کلی در رفتار کمیت مورد مطالعه از نتایج پیشبینی شما تبعیت میکند:
الف) کاهش تولید وجود دارد.
ب) تولید در همان سطح باقی می ماند.
ج) افزایش تولید وجود دارد.
در این ماده، ویژگی های اصلی سری های زمانی، مدل های تجزیه سری های زمانی و همچنین روش های اصلی هموارسازی سری - روش میانگین متحرک، هموارسازی نمایی و تراز تحلیلی در نظر گرفته شد. برای حل این مشکلات، مایکروسافت اکسل ابزارهایی مانند میانگین متحرک (میانگین متحرک) و هموارسازی نمایی (هموارسازی نمایی) را ارائه می دهد که به شما امکان می دهد سطوح یک سری زمانی تجربی و همچنین دستور Add Trendiine (افزودن خط روند) را هموار کنید. ) که به شما امکان می دهد مدل های روند بسازید و بر اساس مقادیر موجود سری های زمانی پیش بینی کنید.
P.S. برای فعال کردن بسته تجزیه و تحلیل داده ها، دستور Tools → Data Analysis را انتخاب کنید (Tools → Data Analysis).
اگر تجزیه و تحلیل داده وجود ندارد، باید مراحل زیر را انجام دهید:
1. دستور Tools → Add-ins (Add-ins) را انتخاب کنید.
2. Analysis ToolPak را از لیست تنظیمات پیشنهادی انتخاب کرده و روی OK کلیک کنید. پس از آن بسته سفارشی سازی Data Analysis دانلود و به اکسل متصل می شود. دستور مربوطه در منوی Tools ظاهر می شود.
©2015-2019 سایت
تمامی حقوق متعلق به نویسندگان آنها می باشد. این سایت ادعای نویسندگی ندارد، اما استفاده رایگان را فراهم می کند.
تاریخ ایجاد صفحه: 27/04/2016
مبحث 3. هموارسازی و پیش بینی سری های زمانی بر اساس مدل های روند
|
هدفبررسی این مبحث ایجاد بستری اساسی برای آموزش مدیران در تخصص 080507 در زمینه ساخت مدلهای وظایف مختلف در حوزه اقتصاد، شکلگیری رویکردی سیستماتیک برای تنظیم و حل مشکلات پیشبینی در بین دانشجویان است. . دوره پیشنهادی به متخصصان این امکان را می دهد که به سرعت با آن سازگار شوند کار عملی، بهتر است در اطلاعات و ادبیات علمی و فنی در تخصص حرکت کنید تا تصمیمات مطمئن تری که در کار ایجاد می شود اتخاذ کنید. اصلی وظایفمطالعه موضوع عبارتند از: کسب دانش نظری عمیق در مورد کاربرد مدلهای پیشبینی، کسب مهارتهای پایدار در انجام کارهای تحقیقاتی، توانایی حل مسائل علمی پیچیده مرتبط با مدلهای ساختمان، از جمله مدلهای چند بعدی، توانایی تحلیل منطقی نتایج به دست آمده و تعیین راه های یافتن راه حل های قابل قبول. |
|
|
کافی روش سادهشناسایی روندهای توسعه، هموارسازی سری های زمانی است، به عنوان مثال، جایگزینی سطوح واقعی با سطوح محاسبه شده که تغییرات کمتری نسبت به داده های اصلی دارند. تبدیل مربوطه نامیده می شود فیلتر کردن. بیایید چندین روش صاف کردن را در نظر بگیریم.
3.1. میانگین های ساده
هدف هموارسازی ایجاد یک مدل پیشبینی برای دورههای آینده بر اساس مشاهدات گذشته است. در روش میانگین های ساده، مقادیر متغیر به عنوان داده های اولیه در نظر گرفته می شود Yدر مقاطع زمانی تی، و مقدار پیش بینی به عنوان یک میانگین ساده برای دوره زمانی بعدی تعیین می شود. فرمول محاسبه دارای فرم است

جایی که nتعداد مشاهدات
در صورتی که مشاهده جدیدی در دسترس باشد، پیش بینی دریافتی جدید نیز باید برای پیش بینی دوره بعدی در نظر گرفته شود. هنگام استفاده از این روش، پیشبینی با میانگینگیری تمام دادههای قبلی انجام میشود، با این حال، نقطه ضعف چنین پیشبینی دشواری استفاده از آن در مدلهای روند است.
3.2. روش میانگین متحرک
این روش مبتنی بر نمایش سری به عنوان مجموع یک روند نسبتاً هموار و یک جزء تصادفی است. این روش مبتنی بر ایده محاسبه مقدار نظری بر اساس یک تقریب محلی است. برای ایجاد یک برآورد روند در یک نقطه تیتوسط مقادیر سری از بازه زمانی مقدار نظری سری را محاسبه کنید. رایج ترین در تمرین سری های هموارسازی موردی است که تمام وزن ها برای عناصر فاصله با یکدیگر برابر هستند. به همین دلیل این روش نامیده می شود روش میانگین متحرک،از زمانی که رویه اجرا می شود، پنجره ای با عرض (2 متر + 1)در سراسر ردیف عرض پنجره معمولاً فرد در نظر گرفته می شود، زیرا مقدار نظری برای مقدار مرکزی محاسبه می شود: تعداد عبارت ها k = 2 متر + 1با همان تعداد سطوح در سمت چپ و راست لحظه تی
فرمول محاسبه میانگین متحرک در این مورد به شکل زیر است:

پراکندگی میانگین متحرک به صورت تعریف شده است σ 2 /k،از کجا σ2واریانس عبارت های اصلی سری را نشان می دهد و کبازه هموارسازی، بنابراین هر چه فاصله هموارسازی بیشتر باشد، میانگین گیری داده ها قوی تر و روند تغییرپذیری کمتری دارد. اغلب، صاف کردن روی سه، پنج و هفت عضو سری اصلی انجام می شود. در این مورد، ویژگیهای میانگین متحرک زیر را باید در نظر گرفت: اگر یک سری با نوسانات دورهای با طول ثابت در نظر بگیریم، در هنگام هموارسازی بر اساس میانگین متحرک با فاصله هموارسازی برابر یا مضربی از دوره ، نوسانات به طور کامل برطرف خواهد شد. اغلب، هموارسازی بر اساس میانگین متحرک، این سری را چنان به شدت متحول می کند که روند توسعه شناسایی شده تنها در بیشتر موارد آشکار می شود. به طور کلی، و کوچکتر، اما برای جزئیات تجزیه و تحلیل مهم (امواج، خم ها، و غیره) ناپدید می شوند. پس از صاف شدن، امواج کوچک گاهی اوقات می توانند جهت را تغییر دهند و به جای "قله ها"، "گودال" مخالف ظاهر شوند و بالعکس. همه اینها نیاز به احتیاط در استفاده از میانگین متحرک ساده دارد و فرد را مجبور می کند به دنبال روش های ظریف تری برای توصیف باشد.
روش میانگین متحرک مقادیر روند را برای اولین و آخرین ارائه نمی دهد متراعضای ردیف این کاستی به ویژه در مواردی که طول ردیف کوچک است قابل توجه است.
3.3. هموارسازی نمایی
میانگین نمایی y tنمونه ای از میانگین متحرک وزنی نامتقارن است که درجه پیر شدن داده ها را در نظر می گیرد: اطلاعات "قدیمی تر" با وزن کمتر وارد فرمول محاسبه مقدار هموار سطح سری می شود.
اینجا میانگین نمایی جایگزین مقدار مشاهده شده سری y t(هموارسازی شامل تمام داده های دریافت شده تا لحظه فعلی می شود تی), α پارامتر هموارسازی که وزن مشاهده فعلی (جدیدترین) را مشخص می کند. 0< α <1.
این روش برای پیش بینی سری های زمانی غیر ثابت با تغییرات تصادفی در سطح و شیب استفاده می شود. با دور شدن از لحظه کنونی زمان به گذشته، وزن عبارت متناظر سری به سرعت (به صورت تصاعدی) کاهش می یابد و عملاً هیچ تأثیری بر مقدار .
به راحتی می توان فهمید که آخرین رابطه به ما امکان می دهد تفسیر زیر را از میانگین نمایی ارائه دهیم: if پیش بینی مقدار سری y t، سپس تفاوت خطای پیش بینی است. بنابراین پیش بینی برای نقطه بعدی در زمان t+1آنچه را که در حال حاضر شناخته شده است در نظر می گیرد تیخطای پیش بینی
گزینه صاف کردن α یک عامل وزنی است اگر α نزدیک به وحدت، سپس پیش بینی به طور قابل توجهی بزرگی خطای آخرین پیش بینی را در نظر می گیرد. برای مقادیر کوچک α مقدار پیش بینی شده نزدیک به پیش بینی قبلی است. انتخاب پارامتر هموارسازی یک مشکل نسبتاً پیچیده است. ملاحظات کلی به شرح زیر است: روش برای پیش بینی سری های به اندازه کافی صاف است. در این حالت، میتوان با به حداقل رساندن خطای پیشبینی یک مرحلهای پیشبینی شده از یک سوم آخر سری، یک ثابت هموارسازی را انتخاب کرد. برخی از کارشناسان استفاده از مقادیر زیاد پارامتر هموارسازی را توصیه نمی کنند. روی انجیر 3.1 نمونه ای از یک سری هموار را با استفاده از روش هموارسازی نمایی نشان می دهد α= 0,1.

برنج. 3.1. نتیجه هموارسازی نمایی در α
=0,1
(1 سری اصلی؛ 2 سری صاف شده؛ 3 مورد باقیمانده)
3.4. هموارسازی نمایی
مبتنی بر روند (روش Holt)
این روش روند خطی محلی را که در سری های زمانی وجود دارد در نظر می گیرد. در صورت وجود روند صعودی در سری زمانی، در کنار برآورد سطح فعلی، برآورد شیب نیز ضروری است. در تکنیک Holt، مقادیر سطح و شیب مستقیماً با استفاده از ثابتهای مختلف برای هر یک از پارامترها هموار میشوند. ثابتهای هموار به شما امکان میدهند سطح و شیب فعلی را تخمین بزنید و هر بار که مشاهدات جدید انجام میشوند، آنها را اصلاح کنید.
روش Holt از سه فرمول محاسبه استفاده می کند:
- سری هموار نمایی (تخمین سطح فعلی)
(3.2) |
- ارزیابی روند
(3.3) |
- پیش بینی برای آردوره های پیش رو
|
(3.4) |
جایی که α, β هموارسازی ثابت ها از بازه .
معادله (3.2) مشابه معادله (3.1) برای هموارسازی نمایی ساده به جز عبارت روند است. مقدار ثابت β برای هموارسازی برآورد روند مورد نیاز است. در معادله پیش بینی (3.3)، برآورد روند در تعداد دوره ها ضرب می شود آر، که پیش بینی بر اساس آن است و سپس این محصول به سطح فعلی داده های هموار اضافه می شود.
دائمی α و β به صورت ذهنی یا با به حداقل رساندن خطای پیشبینی انتخاب میشوند. هرچه مقادیر بزرگتر وزنها گرفته شود، پاسخ به تغییرات مداوم سریعتر انجام میشود و دادهها هموارتر میشوند. وزن های کوچکتر باعث می شود که ساختار مقادیر هموار کمتر صاف شود.
روی انجیر 3.2 نمونه ای از هموارسازی یک سری با استفاده از روش Holt برای مقادیر را نشان می دهد α و β برابر با 0.1.

برنج. 3.2. نتیجه صاف کردن Holt
در α
= 0,1
و β
= 0,1
3.5. هموارسازی نمایی با تغییرات روند و فصلی (روش زمستانی)
اگر نوسانات فصلی در ساختار داده وجود داشته باشد، از مدل هموارسازی نمایی سه پارامتری پیشنهاد شده توسط Winters برای کاهش خطاهای پیش بینی استفاده می شود. این رویکرد توسعه ای از مدل قبلی Holt است. برای محاسبه تغییرات فصلی، در اینجا از یک معادله اضافی استفاده شده است و این روش به طور کامل توسط چهار معادله توضیح داده شده است:
- سری صاف شده نمایی
|
(3.5) |

- ارزیابی روند
(3.6) |
- ارزیابی فصلی
|
(3.7) |
 .
.
- پیش بینی برای آردوره های پیش رو
(3.8) |
جایی که α, β, γ هموارسازی ثابت برای سطح، روند و فصلی به ترتیب. س- مدت دوره نوسانات فصلی.
معادله (3.5) سری هموار شده را تصحیح می کند. در این معادله، این اصطلاح فصلی بودن داده های اصلی را در نظر می گیرد. پس از در نظر گرفتن فصلی و روند در معادلات (3.6)، (3.7)، تخمین ها هموار شده و پیش بینی در معادله (3.8) انجام می شود.
درست مانند روش قبلی، وزنه ها α, β, γ را می توان به صورت ذهنی یا با به حداقل رساندن خطای پیش بینی انتخاب کرد. قبل از اعمال معادله (3.5)، لازم است مقادیر اولیه برای سری هموار شده تعیین شود آن، روند تی تی، ضرایب فصلی اس تی. معمولاً مقدار اولیه سری هموار شده برابر با اولین مشاهده در نظر گرفته می شود، سپس روند صفر می شود و ضرایب فصلی برابر با یک تعیین می شود.
روی انجیر 3.3 نمونه ای از هموارسازی یک سری با استفاده از روش Winters را نشان می دهد.

برنج. 3.3. نتیجه صاف کردن به روش Winters
در α
= 0,1
;β
= 0.1; γ = 0.1(1- ردیف اصلی؛ 2 ردیف صاف شده؛ 3 عدد باقیمانده)
3.6. پیش بینی بر اساس مدل های روند
اغلب سری های زمانی روند (روند) خطی دارند. با فرض یک روند خطی، باید یک خط مستقیم بسازید که با دقت بیشتری تغییر در دینامیک را در دوره مورد بررسی نشان دهد. روش های مختلفی برای ساخت یک خط مستقیم وجود دارد، اما هدفمندترین آنها از دیدگاه رسمی، ساخت و ساز مبتنی بر به حداقل رساندن مجموع انحرافات منفی و مثبت مقادیر اولیه سری از یک خط مستقیم خواهد بود.
یک خط مستقیم در یک سیستم دو مختصات (x، y)را می توان به عنوان نقطه تقاطع یکی از مختصات تعریف کرد درو زاویه تمایل به محور ایکس.معادله چنین خط مستقیمی به نظر می رسد ![]() جایی که آ-نقطه تقاطع؛ بزاویه شیب.
جایی که آ-نقطه تقاطع؛ بزاویه شیب.
برای اینکه خط مستقیم سیر دینامیک را منعکس کند، لازم است مجموع انحرافات عمودی را به حداقل برسانیم. هنگامی که به عنوان معیاری برای تخمین به حداقل رساندن یک مجموع ساده انحراف استفاده می شود، نتیجه خیلی خوب نخواهد بود، زیرا انحرافات منفی و مثبت یکدیگر را خنثی می کنند. به حداقل رساندن مجموع مقادیر مطلق نیز به نتایج رضایت بخشی منجر نمی شود، زیرا تخمین های پارامتر در این مورد ناپایدار هستند، همچنین در اجرای چنین روش تخمینی مشکلات محاسباتی وجود دارد. بنابراین، متداول ترین روشی که استفاده می شود، به حداقل رساندن مجموع انحرافات مربع یا روش حداقل مربع(MNK).
از آنجایی که سری مقادیر اولیه دارای نوساناتی است، مدل سری حاوی خطاهایی است که مربع های آن باید به حداقل برسد.

جایی که y مقدار را مشاهده کردم. y i * مقادیر نظری مدل؛ شماره مشاهده
هنگام مدلسازی روند سری زمانی اصلی با استفاده از روند خطی، آن را فرض میکنیم
تقسیم معادله اول بر n، به بعدی می رسیم
![]()
جایگزینی عبارت حاصل در معادله دوم سیستم (3.10)، برای ضریب ب*ما گرفتیم:

3.7. بررسی تناسب مدل
به عنوان مثال، در شکل. 3.4 نمودار رگرسیون خطی بین قدرت خودرو را نشان می دهد ایکسو هزینه آن در.

برنج. 3.4. نمودار رگرسیون خطی
معادله این مورد این است: در=1455,3 + 13,4 ایکس. تجزیه و تحلیل بصری این شکل نشان می دهد که برای تعدادی از مشاهدات انحرافات قابل توجهی از منحنی نظری وجود دارد. نمودار باقیمانده در شکل نشان داده شده است. 3.5.

برنج. 3.5. نمودار باقیمانده
تجزیه و تحلیل باقیماندههای خط رگرسیون میتواند معیار مفیدی از میزان انعکاس رگرسیون تخمینی دادههای واقعی ارائه دهد. رگرسیون خوب رگرسیونی است که مقدار قابل توجهی از واریانس را توضیح می دهد و برعکس، رگرسیون بد مقدار زیادی از نوسانات را در داده های اصلی ردیابی نمی کند. به طور مستقیم واضح است که هر گونه اطلاعات اضافی مدل را بهبود می بخشد، به عنوان مثال، کسر غیرقابل توضیح از تغییرات متغیر را کاهش می دهد. در. برای تجزیه و تحلیل رگرسیون، واریانس را به اجزاء تجزیه می کنیم. بدیهی است که
جمله آخر برابر با صفر خواهد بود، زیرا حاصل جمع باقی مانده ها است، بنابراین به نتیجه زیر می رسیم.
جایی که SS0، SS1، SS2مجموع مجموع، رگرسیون و مجموع باقیمانده مربع ها را به ترتیب تعیین کنید.
مجموع رگرسیون مربع ها بخشی از واریانس توضیح داده شده توسط یک رابطه خطی را اندازه می گیرد. بخش باقی مانده از پراکندگی، که با یک وابستگی خطی توضیح داده نمی شود.
هر یک از این مجموع با تعداد متناظری از درجات آزادی (HR) مشخص می شود که تعداد واحدهای داده مستقل از یکدیگر را تعیین می کند. به عبارت دیگر ضربان قلب با تعداد مشاهدات مرتبط است nو تعداد پارامترهای محاسبه شده از مجموع این پارامترها. در مورد مورد بررسی برای محاسبه SS0 تنها یک ثابت (مقدار متوسط) تعیین می شود، بنابراین ضربان قلب برای SS0 خواهد بود (ن– 1), ضربان قلب برای SS 2 - (n - 2)و ضربان قلب برای SS 1خواهد بود n - (n - 1) = 1، از آنجایی که n - 1 نقطه ثابت در معادله رگرسیون وجود دارد. درست مانند مجموع مربع ها، ضربان قلب با هم مرتبط است
![]()
مجموع مربع های مربوط به تجزیه واریانس، همراه با ضربان قلب متناظر، را می توان در جدول تحلیل واریانس به اصطلاح (جدول ANOVA ANAlysis Of VAriance) قرار داد (جدول 3.1).
جدول 3.1
جدول ANOVA
منبع |
مجموع مربعات |
مربع متوسط |
|
پسرفت |
SS2/ (n-2) |
با استفاده از مخفف معرفی شده برای مجموع مربع ها، تعریف می کنیم ضریب تعیینبه عنوان نسبت مجموع رگرسیون مربع ها به مجموع مجموع مجذورات به عنوان
|
(3.13) |
ضریب تعیین نسبت متغیر بودن یک متغیر را اندازه گیری می کند Y، که با استفاده از اطلاعات مربوط به تغییرپذیری متغیر مستقل قابل توضیح است ایکس.ضریب تعیین زمانی که از صفر تغییر می کند ایکستاثیر نمی گذارد Y،به یکی در هنگام تغییر Yبه طور کامل با تغییر توضیح داده شده است ایکس.
3.8. مدل پیش بینی رگرسیون
بهترین پیشبینی پیشبینی است که کمترین واریانس را داشته باشد. در مورد ما، حداقل مربعات معمولی بهترین پیشبینی را از همه روشهایی که تخمینهای بیطرفانه بر اساس معادلات خطی ارائه میدهند، ایجاد میکند. خطای پیشبینی مرتبط با روش پیشبینی میتواند از چهار منبع باشد.
ابتدا، ماهیت تصادفی خطاهای افزایشی که توسط رگرسیون خطی کنترل میشوند، تضمین میکند که پیشبینی از مقادیر واقعی منحرف میشود، حتی اگر مدل به درستی مشخص شده باشد و پارامترهای آن دقیقاً شناخته شده باشند.
ثانیاً، فرآیند تخمین خود خطا در تخمین پارامترهایی ایجاد می کند که به ندرت می توانند با مقادیر واقعی برابر باشند، اگرچه به طور متوسط با آنها برابر هستند.
ثالثاً در مورد پیشبینی شرطی (در مورد مقادیر دقیق ناشناخته متغیرهای مستقل)، خطا با پیشبینی متغیرهای توضیحی معرفی میشود.
چهارم، ممکن است خطا ظاهر شود زیرا مشخصات مدل نادرست است.
در نتیجه، منابع خطا را می توان به صورت زیر طبقه بندی کرد:
- ماهیت متغیر؛
- ماهیت مدل؛
- خطای معرفی شده توسط پیش بینی متغیرهای تصادفی مستقل؛
- خطای مشخصات
زمانی که متغیرهای مستقل به راحتی و با دقت پیش بینی شوند، یک پیش بینی بدون قید و شرط را در نظر خواهیم گرفت. ما بررسی مسئله کیفیت پیشبینی را با معادله رگرسیون زوجی آغاز میکنیم.
![]()
بیان مسئله در این مورد را می توان به صورت زیر فرموله کرد: بهترین پیش بینی y T+1 چه خواهد بود، مشروط بر اینکه در مدل y = a + bxگزینه ها آو بدقیقاً برآورد شده و ارزش xT+1شناخته شده.
سپس مقدار پیش بینی شده را می توان به صورت تعریف کرد
سپس خطای پیشبینی خواهد بود
![]() .
.
خطای پیش بینی دو ویژگی دارد:
واریانس حاصل در بین تمام تخمین های ممکن بر اساس معادلات خطی حداقل است.
با اينكه آو b شناخته شده اند، خطای پیش بینی به این دلیل ظاهر می شود که در T+1ممکن است به دلیل خطا روی خط رگرسیون قرار نگیرد ε T+1با رعایت یک توزیع نرمال با میانگین و واریانس صفر σ2. برای بررسی کیفیت پیش بینی، مقدار نرمال شده را معرفی می کنیم

سپس فاصله اطمینان 95% را می توان به صورت زیر تعریف کرد:

جایی که β 0.05چندک های توزیع نرمال
مرزهای بازه 95% را می توان به صورت تعریف کرد
توجه داشته باشید که در این مورد عرض فاصله اطمینانبه اندازه بستگی ندارد ایکس،و مرزهای فاصله خطوط مستقیم موازی با خطوط رگرسیون هستند.
اغلب، هنگام ساخت یک خط رگرسیون و بررسی کیفیت پیش بینی، لازم است نه تنها پارامترهای رگرسیون، بلکه واریانس خطای پیش بینی نیز ارزیابی شود. می توان نشان داد که در این مورد واریانس خطا به مقدار () بستگی دارد، که در آن مقدار میانگین متغیر مستقل است. علاوه بر این، هر چه این سری طولانی تر باشد، پیش بینی دقیق تر است. اگر مقدار X T+1 به مقدار میانگین متغیر مستقل نزدیک باشد، خطای پیشبینی کاهش مییابد، و برعکس، هنگام دور شدن از مقدار میانگین، پیشبینی دقیقتر میشود. روی انجیر 3.6 نتایج پیش بینی را با استفاده از معادله رگرسیون خطی برای 6 بازه زمانی پیش رو به همراه بازه های اطمینان نشان می دهد.

برنج. 3.6. پیش بینی رگرسیون خطی
همانطور که در شکل دیده میشود. 3.6، این خط رگرسیون داده های اصلی را به خوبی توصیف نمی کند: تغییرات زیادی نسبت به خط برازش وجود دارد. کیفیت مدل را می توان با باقیمانده ها نیز قضاوت کرد که با یک مدل رضایت بخش، باید تقریباً طبق قانون عادی توزیع شوند. روی انجیر 3.7 نموداری از باقیمانده ها را نشان می دهد که با استفاده از مقیاس احتمال ساخته شده است.

شکل 3.7. نمودار باقیمانده
هنگام استفاده از چنین مقیاسی، داده هایی که از قانون عادی پیروی می کنند باید روی یک خط مستقیم قرار گیرند. همانطور که از شکل نشان داده شده است، نقاط ابتدا و انتهای دوره مشاهده تا حدودی از یک خط مستقیم منحرف می شوند که نشان دهنده کیفیت ناکافی مدل انتخاب شده در قالب یک معادله رگرسیون خطی است.
روی میز. جدول 3.2 نتایج پیش بینی (ستون دوم) را به همراه 95% فواصل اطمینان (به ترتیب ستون سوم پایین و چهارم بالا) نشان می دهد.
جدول 3.2
نتایج پیش بینی

3.9. مدل رگرسیون چند متغیره
در رگرسیون چند متغیره، داده های هر مورد شامل مقادیر متغیر وابسته و هر متغیر مستقل است. متغیر وابسته yیک متغیر تصادفی است که با رابطه زیر با متغیرهای مستقل مرتبط است:
جایی که ضرایب رگرسیون تعیین می شود. ε جزء خطای مربوط به انحراف مقادیر متغیر وابسته از نسبت واقعی (فرض می شود که خطاها مستقل هستند و دارای توزیع نرمال با میانگین صفر و واریانس مجهول هستند. σ ).
برای یک مجموعه داده معین، برآورد ضرایب رگرسیون را می توان با استفاده از روش حداقل مربعات یافت. اگر تخمین OLS با نشان داده شود، تابع رگرسیون مربوطه به شکل زیر خواهد بود:
باقیمانده ها تخمینی از مولفه خطا هستند و مشابه باقی مانده ها در مورد رگرسیون خطی ساده هستند.
تجزیه و تحلیل آماری یک مدل رگرسیون چند متغیره مشابه تجزیه و تحلیل یک رگرسیون خطی ساده انجام می شود. بستههای استاندارد برنامههای آماری این امکان را فراهم میکنند که تخمینهایی را با حداقل مربعات برای پارامترهای مدل، تخمین خطاهای استاندارد آنها به دست آوریم. همچنین، می توانید ارزش را دریافت کنید تی-آمار برای بررسی اهمیت شرایط فردی مدل رگرسیون و مقدار اف-آمار برای آزمون اهمیت وابستگی رگرسیون.
شکل تقسیم مجموع مربعات در حالت رگرسیون چند متغیره شبیه بیان (3.13) است، اما نسبت ضربان قلب به صورت زیر خواهد بود.
باز هم تاکید می کنیم که nحجم مشاهدات است و کتعداد متغیرها در مدل واریانس کلی متغیر وابسته از دو جزء تشکیل شده است: واریانس توضیح داده شده توسط متغیرهای مستقل از طریق تابع رگرسیون و واریانس غیر قابل توضیح.
ANOVA جدول برای حالت رگرسیون چند متغیره به شکل نشان داده شده در جدول خواهد بود. 3.3.
جدول 3.3
جدول ANOVA
منبع |
مجموع مربعات |
مربع متوسط |
|
پسرفت |
SS2/ (n-k-1) |
به عنوان نمونه ای از رگرسیون چند متغیره، از داده های بسته Statistica (فایل داده ها) استفاده خواهیم کرد فقر.استا)داده های ارائه شده بر اساس مقایسه نتایج سرشماری های 1960 و 1970 است. برای یک نمونه تصادفی از 30 کشور. نام کشورها به عنوان نام رشته وارد شده است و نام همه متغیرهای این فایل در زیر آمده است:
POP_CHNG تغییر جمعیت برای 1960-1970;
N_EMPLD تعداد افراد شاغل در کشاورزی؛
PT_POOR درصد خانواده هایی که زیر خط فقر زندگی می کنند.
نرخ مالیات TAX_RATE؛
PT_PHONE درصد آپارتمان های دارای تلفن؛
PT_RURAL درصد جمعیت روستایی;
سن میانسالی.
به عنوان یک متغیر وابسته، ویژگی را انتخاب می کنیم Pt_Poor، و به عنوان مستقل - بقیه. ضرایب رگرسیون محاسبه شده بین متغیرهای انتخاب شده در جدول آورده شده است. 3.4
جدول 3.4
ضرایب رگرسیون

این جدول ضرایب رگرسیون ( AT) و ضرایب رگرسیون استاندارد شده ( بتا). با کمک ضرایب ATشکل معادله رگرسیون تنظیم شده است که در این حالت به شکل زیر است:
درج شدن فقط این متغیرها در سمت راست به این دلیل است که فقط این ویژگی ها دارای مقدار احتمال هستند. آرکمتر از 0.05 (به ستون چهارم جدول 3.4 مراجعه کنید).
کتابشناسی - فهرست کتب
- باسوفسکی ال. ای.پیش بینی و برنامه ریزی در شرایط بازار. - M .: Infra - M، 2003.
- باکس جی، جنکینز جی.تحلیل سری های زمانی مسئله 1. پیش بینی و مدیریت - م.: میر، 1974.
- Borovikov V. P.، Ivchenko G. I.پیش بینی در سیستم Statistica در محیط ویندوز. - م.: امور مالی و آمار، 1999.
- دوک V.پردازش داده ها در رایانه شخصی در نمونه ها - سن پترزبورگ: پیتر، 1997.
- ایوچنکو بی.پی.، مارتیشچنکو ال.آ.، ایوانتسوف آی.بی.اقتصاد خرد اطلاعات. بخش 1. روش های تجزیه و تحلیل و پیش بینی. - سن پترزبورگ: Nordmed-Izdat، 1997.
- کریچفسکی ام. ال.مقدمه ای بر شبکه های عصبی مصنوعی: Proc. کمک هزینه - سن پترزبورگ: سن پترزبورگ. حالت فناوری دریایی un-t، 1999.
- Soshnikova L. A.، Tamashevich V. N.، Uebe G. و همکاران.تحلیل آماری چند متغیره در اقتصاد - م.: وحدت-دانا، 1999.
بدیهی است که در روش میانگین متحرک وزنی راه های زیادی برای تنظیم وزن ها به گونه ای وجود دارد که مجموع آنها برابر با 1 باشد که یکی از این روش ها هموارسازی نمایی نام دارد. در این طرح از روش میانگین موزون، برای هر t> 1، مقدار پیشبینی شده در زمان t+1 مجموع وزنی فروش واقعی، در دوره زمانی t، و فروش پیشبینیشده، در دوره زمانی t در سایر موارد است. کلمات،
هموارسازی نمایی دارای مزایای محاسباتی نسبت به میانگین متحرک است. در اینجا، برای محاسبه، فقط لازم است مقادیر، و، (همراه با مقدار α) را بدانید. برای مثال، اگر یک شرکت نیاز به پیشبینی تقاضا برای 5000 مورد در هر دوره زمانی داشته باشد، باید 10001 مقدار داده (5000 مقدار، 5000 مقدار و یک مقدار α) را ذخیره کند. بر اساس میانگین متحرک 8 گره، 40000 مقدار داده مورد نیاز را پیش بینی کنید. بسته به رفتار داده ها، ممکن است لازم باشد مقادیر مختلف α برای هر محصول ذخیره شود، اما حتی در این مورد، مقدار اطلاعات ذخیره شده بسیار کمتر از زمانی است که از میانگین متحرک استفاده می شود. خوبی در مورد هموارسازی نمایی این است که با حفظ α و آخرین پیش بینی، تمام پیش بینی های قبلی نیز به طور ضمنی حفظ می شوند.
بیایید برخی از خواص مدل هموارسازی نمایی را در نظر بگیریم. برای شروع، توجه می کنیم که اگر t> 2 باشد، در فرمول (1) t را می توان با t–1 جایگزین کرد، یعنی. با جایگزینی این عبارت به فرمول اصلی (1)، به دست می آوریم
با انجام تعویض های متوالی مشابه، عبارت زیر را برای به دست می آوریم
از آنجایی که از نابرابری 0< α < 1 следует, что 0 < 1 – α < 1, то Другими словами, наблюдение , имеет больший вес, чем наблюдение , которое, в свою очередь, имеет больший вес, чем . Это иллюстрирует основное свойство модели экспоненциального сглаживания - коэффициенты при убывают при уменьшении номера k. Также можно показать, что сумма всех коэффициентов (включая коэффициент при ), равна 1.
از فرمول (2) می توان دریافت که مقدار حاصل جمع وزنی تمام مشاهدات قبلی (از جمله آخرین مشاهده) است. آخرین جمله از جمع (2) نیست مشاهده آماری، اما با "فرض" (برای مثال می توانیم فرض کنیم که ). بدیهی است که با افزایش t تأثیر بر پیش بینی کاهش می یابد و در یک لحظه می توان از آن غفلت کرد. حتی اگر مقدار α به اندازه کافی کوچک باشد (به طوری که (1 - α) تقریباً برابر با 1 باشد)، مقدار به سرعت کاهش می یابد.
مقدار پارامتر α تا حد زیادی بر عملکرد مدل پیشبینی تأثیر میگذارد، زیرا α وزن آخرین مشاهده است. این بدان معنی است که مقدار α بزرگتر باید در موردی که آخرین مشاهده در مدل پیش بینی کننده ترین باشد، اختصاص داده شود. اگر α نزدیک به 0 باشد، این به معنای اطمینان تقریباً کامل به پیش بینی قبلی و نادیده گرفتن آخرین مشاهده است.
ویکتور یک مشکل داشت: بهترین روش برای انتخاب مقدار α. باز هم ابزار Solver در این مورد به شما کمک می کند. برای یافتن مقدار بهینه α (یعنی مقداری که در آن منحنی پیش بینی کمترین انحراف را از منحنی مقدار سری زمانی دارد)، به صورت زیر عمل کنید.
- دستور Tools -> Search for a solution را انتخاب کنید.
- در کادر محاوره ای Find Solution که باز می شود، سلول هدف را روی G16 قرار دهید (به صفحه Expo مراجعه کنید) و مشخص کنید که مقدار آن باید حداقل باشد.
- مشخص کنید که سلولی که باید اصلاح شود سلول B1 باشد.
- محدودیت های B1 > 0 و B1 را وارد کنید< 1
- با کلیک بر روی دکمه Run نتیجه نشان داده شده در شکل را دریافت خواهید کرد. هشت

باز هم مانند روش میانگین متحرک وزنی، با اختصاص وزن کامل به آخرین مشاهده، بهترین پیش بینی به دست خواهد آمد. بنابراین، مقدار بهینه α برابر با 1 است، در حالی که میانگین انحرافات مطلقبرابر با 6.82 (سلول G16) است. ویکتور پیش بینی ای دریافت کرد که قبلاً دیده بود.
روش هموارسازی نمایی در شرایطی که متغیر مورد علاقه ما ثابت رفتار می کند و انحرافات آن از مقدار ثابتناشی از عوامل تصادفی هستند و منظم نیستند. اما: صرف نظر از مقدار پارامتر α، روش هموارسازی نمایی قادر به پیش بینی داده های یکنواخت افزایش یا کاهش یکنواخت نخواهد بود (مقادیر پیش بینی شده همیشه به ترتیب کمتر یا بیشتر از مقادیر مشاهده شده خواهند بود). همچنین می توان نشان داد که در مدلی با تغییرات فصلی نمی توان با این روش پیش بینی های رضایت بخشی را به دست آورد.
در صورتی که آمار به صورت یکنواخت تغییر کند یا در معرض تغییرات فصلی باشد، روش های پیش بینی خاصی مورد نیاز است که در ادامه به آن پرداخته می شود.
روش هالت (هموارسازی نمایی با روند)
![]() ,
,
روش هولت امکان پیشبینی k دورههای زمانی آینده را فراهم میکند. روش، همانطور که می بینید، از دو پارامتر α و β استفاده می کند. مقادیر این پارامترها از 0 تا 1 متغیر است. متغیر L، سطح بلندمدت مقادیر یا مقدار زیربنایی داده های سری زمانی را نشان می دهد. متغیر T نشان دهنده افزایش یا کاهش احتمالی مقادیر در یک دوره است.
بیایید کار این روش را روی یک مثال جدید در نظر بگیریم. سوتلانا به عنوان یک تحلیلگر در یک شرکت کارگزاری بزرگ کار می کند. بر اساس گزارش های سه ماهه ای که برای استارتاپ ایرلاینز دارد، او می خواهد درآمد آن شرکت را برای سه ماهه آینده پیش بینی کند. داده های موجود و نمودار ساخته شده بر اساس آنها در کتاب کار Startup.xls قرار دارند (شکل 9). مشاهده می شود که داده ها روند واضحی دارند (تقریباً یکنواخت افزایش می یابد). سوتلانا می خواهد از روش Holt برای پیش بینی سود هر سهم برای سه ماهه سیزدهم استفاده کند. برای انجام این کار، باید مقادیر اولیه L و T را تعیین کنید. چندین گزینه وجود دارد: 1) L برابر است با ارزش سود هر سهم برای سه ماهه اول و T = 0. 2) L برابر با میانگین ارزش سود هر سهم برای 12 فصل و T برابر با میانگین تغییر برای هر 12 فصل است. گزینه های دیگری برای مقادیر اولیه برای L و T وجود دارد، اما Svetlana گزینه اول را انتخاب کرد.
او تصمیم گرفت از ابزار Find Solution برای یافتن مقدار بهینه پارامترهای α و β استفاده کند که در آن مقدار میانگین خطاهای مطلقدرصد حداقل خواهد بود. برای این کار باید این مراحل را دنبال کنید.
دستور Service -> Search for a solution را انتخاب کنید.
در کادر گفتگوی Search for a solution که باز می شود، سلول F18 را به عنوان سلول هدف تنظیم کنید و نشان دهید که مقدار آن باید به حداقل برسد.
در قسمت Changingcell ها محدوده سلول های B1:B2 را وارد کنید. قیود B1:B2 > 0 و B1:B2 را اضافه کنید< 1.
بر روی دکمه Execute کلیک کنید.
پیش بینی حاصل در شکل نشان داده شده است. ده
همانطور که مشاهده می شود، مقادیر بهینه آلفا = 0.59 و β = 0.42 است، در حالی که میانگین خطاهای مطلق در درصد 38٪ است.



حسابداری تغییرات فصلی
تغییرات فصلی باید هنگام پیشبینی از دادههای سری زمانی در نظر گرفته شود. تغییرات فصلی دارای نوسانات بالا و پایین با دوره ثابت در مقادیر یک متغیر است.
به عنوان مثال، اگر به فروش بستنی به تفکیک ماه نگاه کنید، می بینید که در ماه های گرم تر (ژوئن تا آگوست در نیمکره شمالی) بیشتر سطح بالافروش نسبت به زمستان، و بنابراین هر سال. در اینجا نوسانات فصلی دوره ای 12 ماهه دارد. اگر از داده های هفتگی استفاده شود، الگوی نوسانات فصلی هر 52 هفته تکرار می شود. مثال دیگر با گزارش های هفتگی در مورد تعداد مهمانانی که یک شب در هتلی واقع در مرکز تجاری شهر اقامت داشته اند، تجزیه و تحلیل می شود. احتمالاً می توانیم آن را بگو عدد بزرگانتظار می رود مشتریان در شب های سه شنبه، چهارشنبه و پنج شنبه، کمترین تعداد مشتریان در شنبه و یکشنبه شب و میانگین تعداد مهمان در شب های جمعه و دوشنبه پیش بینی می شود. این ساختار داده، نمایش تعداد مشتریان در روزهای مختلف هفته، هر هفت روز یکبار تکرار خواهد شد.
روش انجام یک پیش بینی فصلی تعدیل شده شامل چهار مرحله زیر است:
1) بر اساس داده های اولیه، ساختار نوسانات فصلی و دوره این نوسانات مشخص می شود.
3) بر اساس داده هایی که جزء فصلی از آن حذف شده است، بهترین پیش بینی ممکن انجام می شود.
4) جزء فصلی به پیش بینی دریافتی اضافه می شود.
بیایید این رویکرد را با دادههای فروش زغال سنگ (اندازهگیری شده در هزاران تن) در ایالات متحده طی نه سال به عنوان مدیر معدن زغالسنگ ژیلت نشان دهیم، فرانک باید تقاضای زغال سنگ را برای دو سه ماهه آینده پیشبینی کند. او داده های کل صنعت زغال سنگ را در کتاب کار Coal.xls وارد کرد و داده ها را رسم کرد (شکل 11). نمودار نشان می دهد که حجم فروش در سه ماهه اول و چهارم (فصل زمستان) بالاتر از میانگین و در سه ماهه دوم و سوم (ماه های بهار و تابستان) کمتر از میانگین است.

حذف جزء فصلی
ابتدا باید میانگین تمام انحرافات را برای یک دوره تغییرات فصلی محاسبه کنید. برای حذف مؤلفه فصلی در یک سال، از دادههای چهار دوره (ربع) استفاده میشود. و برای حذف مولفه فصلی از کل سری زمانی، دنباله ای از میانگین های متحرک بر روی گره های T محاسبه می شود که در آن T مدت زمان نوسانات فصلی است.برای انجام محاسبات لازم، فرانک از ستون های C و D استفاده کرد، همانطور که در شکل نشان داده شده است. زیر ستون C شامل میانگین متحرک 4 گره بر اساس داده های ستون B است.
اکنون باید مقادیر میانگین متحرک حاصل را به نقاط میانی دنباله داده که این مقادیر از آن محاسبه شده اند، اختصاص دهیم. این عملیات نامیده می شود مرکز کردنارزش های. اگر T فرد باشد، اولین مقدار میانگین متحرک (میانگین مقادیر از اول تا نقطه T) باید به نقطه (T + 1)/2 اختصاص داده شود (به عنوان مثال، اگر T = 7، اولین میانگین متحرک به نقطه چهارم اختصاص داده می شود). به همین ترتیب، میانگین مقادیر از نقطه دوم تا (T + 1) ام در نقطه (T + 3)/2 و به همین ترتیب متمرکز می شود. مرکز فاصله n در نقطه (T+) است. (2n-1))/2.
 |  |
اگر T زوج باشد، همانطور که در مورد مورد بررسی، مشکل تا حدودی پیچیده تر می شود، زیرا در اینجا نقاط مرکزی (وسط) بین نقاطی قرار دارند که مقدار میانگین متحرک برای آنها محاسبه شده است. بنابراین، مقدار مرکزی برای نقطه سوم به عنوان میانگین مقادیر اول و دوم میانگین متحرک محاسبه می شود. به عنوان مثال، اولین عدد در ستون D به معنای مرکز در شکل 1. 12، در سمت چپ (1613 + 1594)/2 = 1603 است. در شکل. 13 نمودار داده های خام و میانگین های متمرکز را نشان می دهد.

در مرحله بعد، نسبت مقادیر نقاط داده را به مقادیر متناظر میانگین مرکزی پیدا می کنیم. از آنجایی که نقاط ابتدا و انتهای توالی داده ها دارای میانگین مرکزی متناظر نیستند (نگاه کنید به اول و آخرین ارزش هادر ستون D)، این عمل برای این نقاط اعمال نمی شود. این نسبت ها میزان انحراف مقادیر داده ها از سطح معمولی تعریف شده توسط میانگین های متمرکز را نشان می دهد. توجه داشته باشید که مقادیر نسبت برای سه ماهه سوم کمتر از 1 و نسبت های مربوط به سه ماهه چهارم بیشتر از 1 است.
 |  |
این روابط مبنای ایجاد شاخص های فصلی هستند. برای محاسبه آنها، نسبت های محاسبه شده بر اساس یک چهارم گروه بندی می شوند، همانطور که در شکل 1 نشان داده شده است. 15 در ستون های G-O.
سپس مقادیر متوسط نسبت ها برای هر سه ماهه پیدا می شود (ستون E در شکل 15). به عنوان مثال، میانگین تمام نسبت ها برای سه ماهه اول 1.108 است. این مقدار، شاخص فصلی سه ماهه اول است که از آن می توان نتیجه گرفت که حجم فروش زغال سنگ در سه ماهه اول به طور متوسط حدود 110.8 درصد از میانگین نسبی فروش سالانه است.
شاخص فصلیمیانگین نسبت داده های مربوط به یک فصل (در این مورد، فصل یک چهارم است) به همه داده ها است. اگر شاخص فصلی بیشتر از 1 باشد، عملکرد این فصل بالاتر از میانگین سال است، به طور مشابه، اگر شاخص فصلی زیر 1 باشد، عملکرد فصل کمتر از میانگین سال است.
در نهایت، برای حذف مولفه فصلی از داده های اصلی، مقادیر داده های اصلی باید بر شاخص فصلی مربوطه تقسیم شوند. نتایج این عملیات در ستون های F و G نشان داده شده است (شکل 16). نموداری از داده ها که دیگر شامل یک جزء فصلی نیست در شکل 1 نشان داده شده است. 17.
 |  |

پیش بینی
بر اساس داده هایی که جزء فصلی از آن مستثنی شده است، یک پیش بینی ساخته می شود. برای این کار از روش مناسبی استفاده می شود که ماهیت رفتار داده ها را در نظر می گیرد (مثلاً داده ها روند دارند یا نسبتاً ثابت هستند). در این مثال، پیش بینی با استفاده از هموارسازی نمایی ساده انجام شده است. مقدار بهینه پارامتر α با استفاده از ابزار Solver پیدا می شود. نمودار پیش بینی و داده های واقعی با جزء فصلی حذف شده در شکل نشان داده شده است. هجده.

حسابداری ساختار فصلی
اکنون باید مؤلفه فصلی را در پیش بینی در نظر بگیریم (1726.5). برای این کار عدد 1726 را در شاخص فصلی فصل اول 108/1 ضرب می کنیم که به عدد 1912 می رسد. با عملیات مشابه (ضرب 1726 در شاخص فصلی 784/0) پیش بینی سه ماهه دوم برابر با 1353 به دست می آید. نتیجه اضافه کردن ساختار فصلی به پیش بینی حاصل در شکل 1 نشان داده شده است. 19.

گزینه های وظیفه:
وظیفه 1
با توجه به یک سری زمانی
| تی | ||||||||||
| ایکس |
1. وابستگی x = x(t) را رسم کنید.
- با استفاده از یک میانگین متحرک ساده روی 4 گره، تقاضا را در یازدهمین نقطه زمانی پیش بینی کنید.
- آیا این روش پیش بینی برای این داده ها مناسب است یا خیر؟ چرا؟
- برازش حداقل مربعات خطی برای داده ها.
وظیفه 2
با استفاده از مدل پیشبینی درآمد خطوط هوایی راهاندازی (Startup.xls)، موارد زیر را انجام دهید:
وظیفه 3
برای سری های زمانی
| تی | ||||||||||
| ایکس |
اجرا کن:
- با استفاده از میانگین متحرک وزنی بر روی 4 گره و تخصیص وزن های 4/10، 3/10، 2/10، 1/10، تقاضا را در نقطه زمانی یازدهم پیش بینی کنید. وزن بیشتری باید به مشاهدات اخیر اختصاص داده شود.
- آیا این تقریب بهتر از میانگین متحرک ساده بیش از 4 گره است؟ چرا؟
- میانگین انحرافات مطلق را بیابید.
- از ابزار Solver برای یافتن وزن بهینه گره استفاده کنید. خطای تقریب چقدر کاهش پیدا کرد؟
- از هموارسازی نمایی برای پیش بینی استفاده کنید. کدام یک از روش های مورد استفاده بهترین نتیجه را می دهد؟
وظیفه 4
تجزیه و تحلیل سری های زمانی
| زمان | ||||||||||||
| تقاضا |
- از میانگین متحرک وزنی 4 گرهی با وزن های 4/10، 3/10، 2/10، 1/10 برای پیش بینی در زمان های 5-13 استفاده کنید. وزن بیشتری باید به مشاهدات اخیر اختصاص داده شود.
- میانگین انحرافات مطلق را بیابید.
- به نظر شما این تقریب بهتر از مدل میانگین متحرک ساده 4 گره است؟ چرا؟
- از ابزار Solver برای یافتن وزن بهینه گره استفاده کنید. چقدر توانستید مقدار خطا را کاهش دهید؟
- از هموارسازی نمایی برای پیش بینی استفاده کنید. کدام یک از روش های مورد استفاده بهترین نتیجه را می دهد؟
وظیفه 5
با توجه به یک سری زمانی
وظیفه 7
مدیر بازاریابی یک شرکت کوچک و در حال رشد که شامل فروشگاه های زنجیره ای مواد غذایی است اطلاعاتی در مورد حجم فروش برای کل وجود سودآورترین فروشگاه دارد (جدول را ببینید).
با استفاده از یک میانگین متحرک ساده روی 3 گره، مقادیر را در گره های 4 تا 11 پیش بینی کنید.
با استفاده از میانگین متحرک وزنی بر روی 3 گره، مقادیر را در گره های 4 تا 11 پیش بینی کنید. برای تعیین وزن های بهینه از ابزار Solver استفاده کنید.
از هموارسازی نمایی برای پیش بینی مقادیر در گره های 2-11 استفاده کنید. مقدار بهینه پارامتر α را با استفاده از ابزار Solver تعیین کنید.
کدام یک از پیش بینی های به دست آمده دقیق ترین است و چرا؟
وظیفه 8
با توجه به یک سری زمانی
- طرح این سری زمانی نقاط را با خطوط مستقیم وصل کنید.
- با استفاده از یک میانگین متحرک ساده بیش از 4 گره، تقاضا برای گره های 5-13 را پیش بینی کنید.
- میانگین انحرافات مطلق را بیابید.
- آیا استفاده از آن توصیه می شود این روشپیش بینی برای داده های ارائه شده؟
- آیا این تقریب بهتر از میانگین متحرک ساده بیش از 3 گره است؟ چرا؟
- یک روند خطی و درجه دوم از داده ها ترسیم کنید.
- از هموارسازی نمایی برای پیش بینی استفاده کنید. کدام یک از روش های مورد استفاده بهترین نتیجه را می دهد؟
وظیفه 10
کتاب کار Business_Week.xls دادههای کسبوکار هفته را برای 43 ماه از فروش ماهانه خودرو نشان میدهد.
- مولفه فصلی را از این داده ها حذف کنید.
- بهترین روش پیشبینی برای دادههای موجود را تعیین کنید.
- پیش بینی دوره 44 چیست؟
وظیفه 11
- مدار سادهپیش بینی، زمانی که ارزش هفته گذشته به عنوان پیش بینی هفته بعد در نظر گرفته می شود.
- روش میانگین متحرک (با تعداد گره های انتخابی شما). سعی کنید از چندین مورد استفاده کنید معانی مختلفگره ها
وظیفه 12
کتاب کار Bank.xls عملکرد بانک را نشان می دهد. روش های زیر را برای پیش بینی مقادیر این سری زمانی در نظر بگیرید.
به عنوان یک پیش بینی، از مقدار میانگین شاخص برای تمام هفته های گذشته استفاده می شود.
روش میانگین متحرک وزنی (با تعداد گره های انتخابی شما). سعی کنید از چندین مقدار گره مختلف استفاده کنید. برای تعیین وزن بهینه از ابزار Solver استفاده کنید.
روش هموارسازی نمایی. با استفاده از ابزار Solver مقدار بهینه پارامتر α را پیدا کنید.
کدام یک از روش های پیش بینی ارائه شده در بالا را برای پیش بینی مقادیر این سری زمانی توصیه می کنید؟
ادبیات
اطلاعات مشابه
دکترای اقتصاد، مدیر علوم و توسعه CJSC "KIS"
روش هموارسازی نمایی
توسعه جدید و تجزیه و تحلیل فن آوری های مدیریت شناخته شده که کارایی مدیریت کسب و کار را بهبود می بخشد در حال حاضر به ویژه برای شرکت های روسی مهم شده است. یکی از محبوبترین ابزارها، سیستم بودجهبندی است که مبتنی بر تشکیل بودجه شرکت با کنترل بعدی بر اجرا است. بودجه یک برنامه کوتاه مدت تجاری، تولیدی، مالی و اقتصادی متوازن برای توسعه سازمان است. بودجه شرکت شامل اهدافی است که بر اساس داده های پیش بینی محاسبه می شوند. مهم ترین پیش بینی بودجه برای هر کسب و کار، پیش بینی فروش است. در مقالات قبلی، تجزیه و تحلیل مدل های افزایشی و ضربی انجام شد و حجم فروش پیش بینی شده برای دوره های بعدی محاسبه شد.
هنگام تجزیه و تحلیل سری های زمانی، از روش میانگین متحرک استفاده شد که در آن همه داده ها، صرف نظر از دوره وقوع آنها، برابر هستند. روش دیگری نیز وجود دارد که در آن وزنها به دادهها تخصیص داده میشود، به دادههای جدیدتر وزن بیشتری نسبت به دادههای قبلی داده میشود.
روش هموارسازی نمایی، برخلاف روش میانگین متحرک، میتواند برای پیشبینی کوتاهمدت روند آینده برای یک دوره پیشتر نیز استفاده شود و بهطور خودکار هر پیشبینی را با توجه به تفاوتهای بین نتیجه واقعی و پیشبینیشده تصحیح میکند. به همین دلیل است که روش مزیت آشکاری نسبت به روش های قبلی دارد.
نام این روش از این واقعیت ناشی می شود که میانگین متحرک وزنی نمایی را در کل سری زمانی تولید می کند. با هموارسازی نمایی، تمام مشاهدات قبلی در نظر گرفته می شود - قبلی با حداکثر وزن در نظر گرفته می شود، قبلی - با کمی پایین تر، اولین مشاهده بر روی نتیجه با حداقل وزن آماری تأثیر می گذارد.
الگوریتم برای محاسبه مقادیر هموار شده نمایی در هر نقطه از سری i بر اساس سه کمیت است.:
مقدار واقعی Ai در یک نقطه معین در ردیف i،
پیش بینی در نقطه ای از سری Fi
مقداری ضریب هموارسازی از پیش تعیین شده W، ثابت در سراسر سری.
پیش بینی جدید را می توان به صورت زیر نوشت:
محاسبه مقادیر هموار شده نمایی
در استفاده عملی از روش هموارسازی نمایی، دو مشکل پیش می آید: انتخاب ضریب هموارسازی (W) که تا حد زیادی بر نتایج تأثیر می گذارد و تعیین شرایط اولیه (Fi). از یک طرف، برای صاف کردن انحرافات تصادفی، مقدار باید کاهش یابد. از طرف دیگر، برای افزایش وزن اندازه گیری های جدید، باید افزایش دهید.
اگرچه، در اصل، W می تواند هر مقداری را از محدوده 0 بگیرد< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
انتخاب عامل ثابت هموارسازی ذهنی است. تحلیلگران در اکثر شرکت ها از مقادیر W سنتی خود هنگام پردازش سری استفاده می کنند.بنابراین، طبق داده های منتشر شده در بخش تحلیلی کداک، مقدار 0.38 به طور سنتی استفاده می شود و در Ford Motors 0.28 یا 0.3 است.
محاسبه دستی هموارسازی نمایی به مقدار بسیار زیادی کار یکنواخت نیاز دارد. برای مثال، بیایید حجم پیشبینیشده برای سه ماهه سیزدهم را در صورت وجود دادههای فروش برای 12 فصل گذشته، با استفاده از روش هموارسازی نمایی ساده محاسبه کنیم.
فرض کنید که برای سه ماهه اول پیش بینی فروش 3 بود. و اجازه دهید ضریب هموارسازی W = 0.8 باشد.
ستون سوم جدول را پر کنید و برای هر سه ماهه بعدی مقدار قبلی را مطابق فرمول جایگزین کنید:
برای 2 چهارم F2 = 0.8 * 4 (1-0.8) * 3 = 3.8
برای کوارتر سوم F3 =0.8*6 (1-0.8)*3.8 =5.6
به طور مشابه، یک مقدار هموار برای ضریب 0.5 و 0.33 محاسبه می شود.
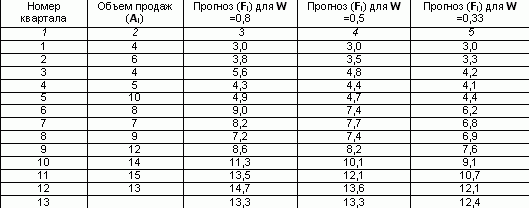
محاسبه پیش بینی فروش
پیش بینی حجم فروش در W = 0.8 برای سه ماهه سیزدهم 13.3 هزار روبل بود.
این داده ها را می توان به صورت گرافیکی ارائه کرد:
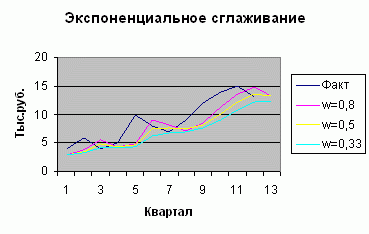
هموارسازی نمایی
