ارزیابی نتایج رگرسیون خطی. ضریب همبستگی چندگانه و ضریب تعیین چندگانه
ضریب همبستگی چندگانه سه متغیر نشانگر نزدیکی رابطه خطی بین یکی از ویژگی ها (حرف نمایه قبل از خط تیره) و ترکیبی از دو ویژگی دیگر (حروف نمایه بعد از خط تیره) است:
 ; (12.7)
; (12.7)
 (12.8)
(12.8)
این فرمول ها محاسبه ضرایب همبستگی چندگانه را آسان می کند ارزش های شناخته شدهضرایب همبستگی جفتی r xy، r xz و r yz.
ضریب آرمنفی نیست و همیشه بین 0 و 1 است. هنگام نزدیک شدن آرتا وحدت، درجه رابطه خطی سه ویژگی افزایش می یابد. بین نسبت همبستگی چندگانه، مثلا R y-xzو دو جفت ضریب همبستگی r yxو r yzرابطه زیر وجود دارد: هر یک از ضرایب جفت نمی تواند از مقدار مطلق تجاوز کند R y-xz.
مجذور ضریب همبستگی چندگانه R2ضریب تعیین چندگانه نامیده می شود. نسبت تغییرات متغیر وابسته را تحت تأثیر عوامل مورد مطالعه نشان می دهد.
اهمیت همبستگی چندگانه توسط برآورد می شود
اف– معیار:
 , (12.9)
, (12.9)
nحجم نمونه است،
ک- تعداد ویژگی ها؛ در مورد ما ک = 3.
ارزش نظری اف- معیارها از جدول درخواست برای ν 1 = k-1 و ν 2 \u003d n–kدرجات آزادی و سطح قابل قبول اهمیت. فرضیه صفر در مورد برابری ضریب همبستگی چندگانه در جمعیت به صفر ( H0: R= 0) پذیرفته می شود اگر F واقعیت.< F табл . و رد شد اگر F واقعیت. ≥ جدول F.
پایان کار -
این موضوع متعلق به:
آمار ریاضی
موسسه آموزشی.. گومل دانشگاه دولتی.. به نام فرانسیس اسکارینا یو ام ژوچنکو ..
اگر احتیاج داری مواد اضافیدر مورد این موضوع، یا آنچه را که به دنبال آن بودید پیدا نکردید، توصیه می کنیم از جستجو در پایگاه داده آثار ما استفاده کنید:
با مطالب دریافتی چه خواهیم کرد:
اگر این مطالب برای شما مفید بود، می توانید آن را در صفحه خود در شبکه های اجتماعی ذخیره کنید:
| توییت |
تمامی موضوعات این بخش:
آموزش
برای دانشجویانی که در رشته تخصصی 1-31 01 01 "زیست شناسی" گومل 2010 تحصیل می کنند
موضوع و روش آمار ریاضی
موضوع آمار ریاضی مطالعه خواص پدیده های توده ای در زیست شناسی، اقتصاد، فناوری و سایر زمینه ها است. این پدیده ها معمولاً به دلیل تنوع (تنوع) پیچیده هستند
مفهوم یک رویداد تصادفی
استقراء آماری یا استنتاج آماری به عنوان اصلی ترین جزءروش مطالعه پدیده های توده ای خاص خود را دارد ویژگی های متمایز کننده. نتیجه گیری های آماری با عددی انجام می شود
احتمال وقوع یک رویداد تصادفی
مشخصه عددیرویداد تصادفی، که این ویژگی را دارد که برای هر سری آزمایش های به اندازه کافی بزرگ، فرکانس رویداد فقط اندکی با این مشخصه متفاوت است، نامیده می شود.
محاسبه احتمالات
اغلب نیاز به جمع و ضرب همزمان احتمالات وجود دارد. به عنوان مثال، شما می خواهید با انداختن همزمان 2 تاس، احتمال کسب 5 امتیاز را تعیین کنید. مقدار مورد نیاز محتمل است
مفهوم متغیر تصادفی
پس از تعریف مفهوم احتمال و روشن شدن ویژگی های اصلی آن، اجازه دهید به بررسی یکی از مهمترین مفاهیم نظریه احتمال - مفهوم متغیر تصادفی - بپردازیم. اجازه دهید در نتیجه آن را فرض کنیم
متغیرهای تصادفی گسسته
یک متغیر تصادفی گسسته است اگر مجموعه مقادیر ممکن آن متناهی باشد یا با توجه به حداقل، قابل شمارش است. فرض کنید یک متغیر تصادفی X می تواند مقادیر x1 را بگیرد
متغیرهای تصادفی پیوسته
در مقایسه با متغیرهای تصادفی گسسته که در بخش فرعی قبلی مورد بحث قرار گرفت، مجموعه مقادیر ممکن برای یک متغیر تصادفی پیوسته نه تنها محدود نیست، بلکه قابل قبول نیست.
انتظارات و واریانس ریاضی
اغلب نیاز به توصیف توزیع یک متغیر تصادفی با استفاده از یک یا دو شاخص عددی وجود دارد که مهمترین ویژگی های این توزیع را بیان می کند. به چنین
لحظات
در آمار ریاضی به اصطلاح لحظه های توزیع یک متغیر تصادفی اهمیت زیادی دارد. AT انتظارات ریاضیمقادیر بزرگ یک متغیر تصادفی به اندازه کافی در نظر گرفته نمی شود.
توزیع دو جمله ای و اندازه گیری احتمالات
در این مبحث انواع اصلی توزیع متغیرهای تصادفی گسسته را در نظر خواهیم گرفت. فرض کنید احتمال وقوع یک رویداد تصادفی A در یک آزمایش منفرد برابر است با
توزیع مستطیلی (یکنواخت).
توزیع مستطیلی (یکنواخت) ساده ترین نوع توزیع پیوسته است. اگر یک متغیر تصادفی X بتواند هر مقدار واقعی را در بازه (a, b) بگیرد، جایی که a و b واقعی هستند.
توزیع نرمال
توزیع نرمال نقش عمده ای در آمار ریاضی ایفا می کند. این به هیچ وجه تصادفی نیست: در واقعیت عینی، اغلب با علائم مختلفی مواجه می شود.
توزیع log-normal
متغیر تصادفی Y دارای لگاریتمی است توزیع نرمالبا پارامترهای μ و σ اگر متغیر تصادفی X = lnY دارای توزیع نرمال با پارامترهای مشابه μ و & باشد.
مقادیر متوسط
از بین تمام ویژگیهای گروه، سطح متوسط که با میانگین مقدار صفت اندازهگیری میشود، بیشترین اهمیت نظری و عملی را دارد. مقدار متوسط یک ویژگی یک مفهوم بسیار عمیق است،
خصوصیات عمومی میانگین ها
برای استفاده صحیح از مقادیر متوسط، لازم است ویژگی های این شاخص ها را بدانید: مکان میانه، انتزاع و وحدت عمل کل. با مقدار عددی آن
میانگین حسابی
میانگین حسابی، داشتن خواص مشترکمقادیر متوسط، ویژگی های خاص خود را دارد که می توان آن را با فرمول های زیر بیان کرد:
رتبه متوسط (میانگین ناپارامتریک)
رتبه متوسط برای چنین ویژگی هایی تعیین می شود که هنوز روش های اندازه گیری کمی برای آنها یافت نشده است. با توجه به درجه تجلی چنین ویژگی هایی، اشیاء را می توان رتبه بندی کرد، به عنوان مثال، واقع شده است
میانگین وزنی حسابی
معمولاً برای محاسبه میانگین حسابی همه را جمع کنید مقادیر ویژگیو مقدار حاصل بر تعداد گزینه ها تقسیم می شود. در این حالت، هر مقدار با وارد کردن مجموع، آن را به میزان کامل افزایش می دهد
ریشه میانگین مربع
ریشه میانگین مربع با فرمول محاسبه می شود: , (6.5) برابر است با جذر مجموع
میانه
میانه مقدار مشخصه ای است که کل گروه را به دو قسمت مساوی تقسیم می کند: یک قسمت دارای مقدار ویژگی کمتر از میانه است و قسمت دیگر دارای مقدار بیشتری است. مثلاً اگر دارم
میانگین هندسی
برای به دست آوردن میانگین هندسی برای یک گروه با n داده، باید همه گزینه ها را ضرب کنید و از حاصل ضرب استخراج کنید. ریشه n امدرجه:
هارمونیک متوسط
میانگین هارمونیک با فرمول محاسبه می شود. (6.14) برای پنج گزینه: 1، 4، 5، 5 متوسط
تعداد درجات آزادی
تعداد درجات آزادی برابر با تعداد عناصر تنوع آزاد در گروه است. برابر است با تعداد تمام آیتم های مطالعه موجود بدون تعداد محدودیت های تنوع. مثلا برای تحقیق
ضریب تغییرات
انحراف استاندارد یک مقدار نامگذاری شده است که با واحدهای مشابه میانگین حسابی بیان می شود. بنابراین، برای مقایسه ویژگی های مختلف بیان شده در واحدهای مختلف از
محدودیت ها و دامنه
برای ارزیابی سریع و تقریبی درجه تنوع، اغلب از ساده ترین شاخص ها استفاده می شود: lim = (min ¸ max) - محدودیت ها، یعنی کوچکترین و بزرگترین ارزشویژگی، p =
انحراف نرمال شده
معمولاً درجه رشد یک صفت با اندازه گیری آن مشخص می شود و با عدد مشخصی بیان می شود: وزن 3 کیلوگرم، طول 15 سانتی متر، 20 قلاب در بال زنبور، 4 درصد چربی در شیر، 15 کیلوگرم بریدن
میانگین و سیگمای گروه خلاصه
گاهی لازم است میانگین و سیگما برای توزیع مجموعی که از چندین توزیع تشکیل شده است تعیین شود. در این مورد، نه خود توزیع ها، بلکه فقط ابزار و سیگماهای آنها شناخته می شوند.
چولگی (چولگی) و شیب (کورتوز) منحنی توزیع
برای نمونه های بزرگ (n> 100)، دو آمار دیگر محاسبه می شود. چولگی منحنی نامتقارن نامیده می شود:
سری واریاسیون
با افزایش اندازه گروه های مورد مطالعه، نظم در تنوع بیشتر و بیشتر آشکار می شود که در گروه های کوچک با شکل تصادفی تجلی آن پنهان می شد.
هیستوگرام و منحنی تغییرات
هیستوگرام است سری تغییرات، به صورت نموداری ارائه می شود که در آن مقدار فرکانس متفاوتی با ارتفاع میله های مختلف نشان داده می شود. هیستوگرام توزیع داده ها در صفحه نشان داده شده است
اهمیت تفاوت های توزیع
یک فرضیه آماری یک فرض خاص در مورد توزیع احتمال زیربنای نمونه مشاهده شده داده است. معاینه فرضیه آماریفرآیند پذیرش است
معیارهای چولگی و کشیدگی
برخی از نشانه های گیاهان، حیوانات و میکروارگانیسم ها، هنگامی که اشیاء در گروه ها ترکیب می شوند، توزیع هایی را به وجود می آورند که به طور قابل توجهی با نرمال متفاوت است. در مواردی که هر
جامعه عمومی و نمونه
کل آرایه افراد یک دسته خاص، جمعیت عمومی نامیده می شود. جلد جمعیتتوسط اهداف مطالعه تعیین می شود. اگر گونه ای از حیوانات وحشی مورد مطالعه قرار گیرد
نمایندگی
مطالعه مستقیم گروهی از اشیاء انتخاب شده، اول از همه، مواد اولیهو ویژگی های خود نمونه تمام داده های نمونه و ارقام خلاصه به عنوان مرتبط هستند
خطاهای نمایندگی و سایر خطاهای تحقیق
ارزیابی پارامترهای کلی بر اساس شاخص های انتخابی ویژگی های خاص خود را دارد. یک جزء هرگز نمی تواند به طور کامل کل را مشخص کند، بنابراین ویژگی جمعیت عمومی است
مرزهای اعتماد به نفس
برای استفاده از شاخص های نمونه برای یافتن مقادیر احتمالی پارامترهای عمومی، لازم است مقدار خطاهای نمایندگی تعیین شود. این فرآیند o نامیده می شود
روش ارزیابی عمومی
سه مقدار مورد نیاز برای ارزیابی پارامتر کلی - شاخص نمونه ()، معیار قابلیت اطمینان
تخمین میانگین حسابی
مقطع تحصیلی سایز متوسطهدف آن تعیین مقدار میانگین کلی برای دسته مورد مطالعه از اشیاء است. خطای نمایندگی مورد نیاز برای این منظور با فرمول تعیین می شود:
تخمین اختلاف میانگین
در برخی از مطالعات، تفاوت بین دو اندازه گیری به عنوان داده اولیه در نظر گرفته می شود. این ممکن است زمانی اتفاق بیفتد که هر فرد از نمونه در دو حالت - یا در مورد مطالعه قرار گیرد سنین مختلف، یا p
برآورد غیر قابل اعتماد و قابل اعتماد از تفاوت میانگین
چنین نتایجی از مطالعات انتخابی که بر اساس آنها نمیتوان تخمین قطعی از پارامتر کلی را به دست آورد (یا بزرگتر از صفر یا کمتر یا مساوی صفر باشد)، غیر قابل اعتماد نامیده میشوند.
تخمین تفاوت میانگین های کلی
در تحقیقات بیولوژیکی، تفاوت بین دو کمیت از اهمیت ویژه ای برخوردار است. با تفاوت، جمعیتها، نژادها، نژادها، واریتهها، لاینها، خانوادهها، گروههای آزمایش و کنترل با هم مقایسه میشوند.
معیار پایایی تفاوت
همزمان پراهمیت، که برای محققان تفاوت های قابل اعتماد را دریافت می کند ، نیاز به تسلط بر روش هایی وجود دارد که امکان تعیین قابل اعتماد بودن نتایج بدست آمده را به طور واقع بینانه فراهم می کند.
نمایندگی در مطالعه ویژگی های کیفی
صفات کیفی معمولاً نمی توانند درجاتی از تجلی داشته باشند: آنها یا در هر یک از افراد وجود دارند یا وجود ندارند، مثلاً جنسیت، نظرسنجی، وجود یا عدم وجود هر ویژگی، زشتی.
قابلیت اطمینان تفاوت در سهام
پایایی تفاوت سهام نمونه به همان روشی که برای تفاوت میانگین ها تعیین می شود: (10.34)
ضریب همبستگی
در بسیاری از مطالعات، بررسی چندین نشانه در رابطه متقابل آنها الزامی است. اگر چنین مطالعه ای را در رابطه با دو صفت انجام دهیم، می بینیم که تغییرپذیری یک صفت نیست.
خطای ضریب همبستگی
مانند هر مقدار نمونه، ضریب همبستگی دارای خطای نمایندگی خاص خود است که برای نمونه های بزرگ با استفاده از فرمول محاسبه می شود:
اطمینان از ضریب همبستگی نمونه
معیار ضریب همبستگی نمونه با فرمول: (11.9) تعیین می شود که در آن:
حدود اطمینان ضریب همبستگی
حدود اطمینان مقدار کلی ضریب همبستگی پیدا شده است به صورت کلیطبق فرمول:
پایایی تفاوت بین دو ضریب همبستگی
پایایی تفاوت در ضرایب همبستگی به همان روشی که پایایی اختلاف میانگین ها طبق فرمول معمول تعیین می شود.
معادله رگرسیون خط مستقیم
همبستگی مستقیم از این جهت متفاوت است که با این شکل از اتصال، هر یک از تغییرات یکسان در اولین ویژگی مربوط به یک تغییر کاملاً تعریف شده و همچنین میانگین یکسان در pr دیگر است.
خطاهای عناصر معادله رگرسیون یکطرفه
در معادله یک مستقیم ساده رگرسیون خطی: y = a + bx سه خطای نمایندگی وجود دارد. 1 خطای ضریب رگرسیون:
ضریب همبستگی جزئی
ضریب همبستگی جزئی شاخصی است که درجه همگرایی دو ویژگی را می سنجد مقدار ثابتسوم. آمار ریاضی به شما امکان می دهد یک همبستگی ایجاد کنید
معادله رگرسیون چندگانه خطی
معادله ریاضی برای رابطه خط مستقیم بین سه متغیر، معادله خطی چندگانه صفحه رگرسیون نامیده می شود. شکل کلی زیر را دارد:
رابطه همبستگی
اگر رابطه بین پدیده های مورد مطالعه به طور قابل توجهی از یک رابطه خطی انحراف داشته باشد، که به راحتی از نمودار مشخص می شود، ضریب همبستگی به عنوان معیاری برای رابطه نامناسب است. می تواند نشان دهنده غیبت باشد
ویژگی های رابطه همبستگی
نسبت همبستگی درجه همبستگی را در هر یک از اشکال آن اندازه گیری می کند. علاوه بر این، نسبت همبستگی دارای تعدادی ویژگی دیگر است که در آماری بسیار جالب است
خطای نمایندگی نسبت همبستگی
فرمول دقیقی برای خطای نمایندگی هنوز ایجاد نشده است. رابطه همبستگی. فرمولی که معمولاً در کتاب های درسی ارائه می شود دارای اشکالاتی است که همیشه نمی توان آنها را نادیده گرفت. این فرمول اینطور نیست
معیار خطی همبستگی
برای تعیین درجه تقریب یک وابستگی منحنی به یک مستطیل، از معیار F استفاده می شود که با فرمول محاسبه می شود:
مجتمع پراکندگی
مجموعه پراکندگی مجموعه ای از درجه بندی ها با داده های مربوط به مطالعه و میانگین داده ها برای هر درجه بندی (میانگین خصوصی) و برای کل مجموعه (میانگین عمومی) است.
تأثیرات آماری
تأثیر آماری بازتابی در تنوع ویژگی حاصل از تنوع عامل (درجه بندی آن) است که در مطالعه سازماندهی شده است. برای ارزیابی تأثیر نئو
تأثیر عاملی
تأثیر عاملی، تأثیر آماری ساده یا ترکیبی عوامل مورد مطالعه است. در مجتمع های تک عاملی، تأثیر ساده یک عامل در سطوح سازمانی مشخصی بررسی می شود.
مجتمع پراکندگی یک عاملی
تجزیه و تحلیل واریانس توسط دانشمند انگلیسی R. A. Fisher، که قانون توزیع نسبت مربعات میانگین را کشف کرد، توسعه داده شد و در تحقیقات کشاورزی و بیولوژیکی معرفی شد.
کمپلکس پراکندگی چند عاملی
ایده روشن از مدل ریاضیتجزیه و تحلیل واریانس درک عملیات محاسباتی لازم را آسان تر می کند، به ویژه در هنگام پردازش داده های آزمایش های چند متغیره، که در آنها موارد بیشتری وجود دارد.
تحولات
استفاده صحیح از تحلیل واریانس برای پردازش مواد آزمایشی، همگنی واریانس ها را برای انواع (نمونه ها)، یک توزیع نرمال یا نزدیک به آن در
شاخص های قدرت تأثیرات
تعیین قدرت تأثیرات توسط نتایج آنها در زیست شناسی مورد نیاز است. کشاورزی، پزشکی را انتخاب کنید وسیله موثرقرار گرفتن در معرض، برای دوز عوامل فیزیکی و شیمیایی - خیابان
خطای نمایندگی شاخص اصلی قدرت نفوذ
فرمول دقیقی برای خطای شاخص اصلی قدرت نفوذ هنوز پیدا نشده است. در مجتمع های یک عاملی، زمانی که خطای نمایندگی فقط برای یک شاخص فاکتوریل تعیین می شود
مقادیر حدی شاخص های قدرت نفوذ
شاخص اصلی قدرت نفوذ برابر است با سهم یک جمله از مجموع مجموع اصطلاحات. علاوه بر این، این شاخص برابر مربع استرابطه همبستگی به این دو دلیل، نشانگر قدرت
قابلیت اطمینان تأثیرات
شاخص اصلی قدرت تأثیر، که در یک مطالعه انتخابی به دست آمده است، اول از همه، درجه تأثیرگذاری را مشخص می کند که واقعاً در واقع در گروه اشیاء مورد مطالعه ظاهر می شود.
تجزیه و تحلیل تشخیصی
یکی از روش های تجزیه و تحلیل آماری چند متغیره، تحلیل تفکیکی است. هدف از تجزیه و تحلیل متمایز این است که بر اساس اندازه گیری ویژگی های مختلف (ویژگی ها، جفت ها).
بیان مسئله، روش های راه حل، محدودیت ها
فرض کنید n شی با ویژگی m وجود دارد. در نتیجه اندازه گیری ها، هر جسم با بردار x1 ... xm، m >1 مشخص می شود. وظیفه این است که
مفروضات و محدودیت ها
تجزیه و تحلیل تمایز تحت تعدادی از مفروضات "کار" می کند. این فرض که کمیت های مشاهده شده - ویژگی های اندازه گیری شده جسم - دارای توزیع نرمال هستند. آی تی
الگوریتم تجزیه و تحلیل متمایز
راه حل مسائل تمایز (تحلیل تفکیک کننده) شامل تقسیم بندی کل فضای نمونه (مجموعه ای از تحقق های همه چند بعدی در نظر گرفته شده است). متغیرهای تصادفی) برای یک عدد
آنالیز خوشه ای
تجزیه و تحلیل خوشه ای روش های مختلف مورد استفاده برای انجام طبقه بندی را ترکیب می کند. در نتیجه اعمال این رویه ها، مجموعه اولیه اشیاء به خوشه ها یا گروه ها تقسیم می شوند
روش های تحلیل خوشه ای
در عمل، روشهای خوشهبندی تجمعی معمولاً اجرا میشوند. معمولاً قبل از شروع طبقهبندی، دادهها استاندارد میشوند (میانگین کم و جذر تقسیم میشود).
الگوریتم تحلیل خوشه ای
تجزیه و تحلیل خوشه ای مجموعه ای از روش ها برای طبقه بندی مشاهدات یا اشیاء چند بعدی بر اساس تعریف مفهوم فاصله بین اشیاء و به دنبال آن انتخاب گروه ها از آنها است.
محاسبه ضریب همبستگی چندگانه از اهمیت ویژه ای برخوردار است ویژگی حاصل y با عامل x 1 , x 2 ,…, x m ,فرمول برای تعیین اینکه در کدام مورد کلیفرم را دارد
جایی که Δ r تعیین کننده ماتریس همبستگی است. ∆ 11 متمم جبری عنصر r yy ماتریس همبستگی است.
اگر فقط دو علامت عامل در نظر گرفته شود، می توان از فرمول زیر برای محاسبه ضریب همبستگی چندگانه استفاده کرد: 
ساخت یک ضریب همبستگی چندگانه فقط در مواردی توصیه می شود که ضرایب همبستگی جزئی معنی دار باشند و رابطه بین ویژگی حاصل و عوامل موجود در مدل واقعاً وجود داشته باشد.
ضریب تعیین
فرمول کلی: R2 = RSS/TSS=1-ESS/TSSکه در آن RSS مجموع مجذور انحرافات توضیح داده شده است، ESS مجموع مجذور انحرافات غیر قابل توضیح (باقیمانده) است، TSS برابر است با مبلغ کلانحرافات مربع (TSS=RSS+ESS)
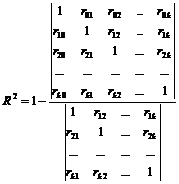 ,
,
که در آن r ij - ضرایب همبستگی جفت بین رگرسیور x i و x j , a r i 0 - ضرایب همبستگی جفت بین رگرسیور x i و y .
- ضریب تعیین تصحیح شده (نرمال شده).
مجذور ضریب همبستگی چندگانه ![]() تماس گرفت ضریب تعیین چندگانه; نشان می دهد که چه نسبتی از واریانس صفت حاصل را نشان می دهد yبا تأثیر علائم عامل x 1 , x 2 , …, x m توضیح داده می شود. توجه داشته باشید که فرمول محاسبه ضریب تعیین از طریق نسبت باقیمانده و واریانس کلویژگی حاصل همان نتیجه را خواهد داد.
تماس گرفت ضریب تعیین چندگانه; نشان می دهد که چه نسبتی از واریانس صفت حاصل را نشان می دهد yبا تأثیر علائم عامل x 1 , x 2 , …, x m توضیح داده می شود. توجه داشته باشید که فرمول محاسبه ضریب تعیین از طریق نسبت باقیمانده و واریانس کلویژگی حاصل همان نتیجه را خواهد داد.
ضریب همبستگی چندگانه و ضریب تعیین از 0 تا 1 متغیر است. yاز x 1، x 2، …، x m. اگر مقدار ضریب همبستگی چندگانه کوچک باشد (کمتر از 0.3)، به این معنی است که مجموعه انتخاب شده از ویژگی های عامل به اندازه کافی تغییرات ویژگی حاصل را توصیف نمی کند، یا رابطه بین متغیرهای عامل و نتیجه غیرخطی است.
ضریب همبستگی چندگانه با استفاده از ماشین حساب محاسبه می شود. اهمیت ضریب همبستگی چندگانه و ضریب تعیینبا استفاده از تست فیشر بررسی شد.
کدام یک از اعداد زیر می تواند مقدار ضریب تعیین چندگانه باشد:
الف) 0.4؛
ب) -1؛
ج) -2.7;
د) 2.7.
چندگانه ضریب خطیهمبستگی 0.75 است. چند درصد از تغییرات متغیر وابسته y در مدل لحاظ شده و ناشی از تأثیر عوامل x 1 و x 2 است.
الف) 56.2 (R 2 = 0.75 2 = 0.5625)؛
کیفیت مدل ساخته شده را ارزیابی کنید. آیا کیفیت مدل نسبت به مدل تک عاملی بهبود یافته است؟ با استفاده از ضرایب الاستیسیته، ضرایب - و ، تأثیر عوامل مهم بر نتیجه را ارزیابی کنید.
ضریب تعیین آر- ما مربع را از نتایج "رگرسیون" می گیریم (جدول " آمار رگرسیون» برای مدل (6)).
بنابراین، تغییر (تغییر) در قیمت یک آپارتمان Y 77/76 درصد با این معادله با تغییر شهر منطقه توضیح داده می شود ایکس 1 ، تعداد اتاق های آپارتمان ایکس 2 و فضای زندگی ایکس 4 .
ما از داده های اصلی استفاده می کنیم Y منو بقایای یافت شده توسط ابزار رگرسیون  (جدول "نتیجه گیری باقیمانده" برای مدل (6)). خطاهای نسبی را محاسبه کرده و مقدار متوسط را بیابید
(جدول "نتیجه گیری باقیمانده" برای مدل (6)). خطاهای نسبی را محاسبه کرده و مقدار متوسط را بیابید  .
.
انصراف باقی مانده
| مشاهده | Y را پیش بینی کرد | باقی | رابطه خطا |
| 1 | 45,95089273 | -7,95089273 | 20,92340192 |
| 2 | 86,10296493 | -23,90296493 | 38,42920407 |
| 3 | 94,84442678 | 30,15557322 | 24,12445858 |
| 4 | 84,17648426 | -23,07648426 | 37,76838667 |
| 5 | 40,2537216 | 26,7462784 | 39,91981851 |
| 6 | 68,70572376 | 24,29427624 | 26,12287768 |
| 7 | 143,7464899 | -25,7464899 | 21,81905923 |
| 8 | 106,0907598 | 25,90924022 | 19,62821228 |
| 9 | 135,357993 | -42,85799303 | 46,33296544 |
| 10 | 114,4792566 | -9,47925665 | 9,027863476 |
| 11 | 41,48765602 | 0,512343975 | 1,219866607 |
| 12 | 103,2329236 | 21,76707636 | 17,41366109 |
| 13 | 130,3567798 | 39,64322022 | 23,3195413 |
| 14 | 35,41901876 | 2,580981242 | 6,7920559 |
| 15 | 155,4129693 | -24,91296925 | 19,0903979 |
| 16 | 84,32108188 | 0,678918123 | 0,798727204 |
| 17 | 98,0552279 | -0,055227902 | 0,056355002 |
| 18 | 144,2104618 | -16,21046182 | 12,66442329 |
| 19 | 122,8677535 | -37,86775351 | 44,55029825 |
| 20 | 100,0221225 | 59,97787748 | 37,48617343 |
| 21 | 53,27196558 | 6,728034423 | 11,21339071 |
| 22 | 35,06605378 | 5,933946225 | 14,47303957 |
| 23 | 114,4792566 | -24,47925665 | 27,19917406 |
| 24 | 113,1343153 | -30,13431529 | 36,30640396 |
| 25 | 40,43190991 | 4,568090093 | 10,15131132 |
| 26 | 39,34427892 | -0,344278918 | 0,882766457 |
| 27 | 144,4794501 | -57,57945009 | 66,25943623 |
| 28 | 56,4827667 | -16,4827667 | 41,20691675 |
| 29 | 95,38240332 | -15,38240332 | 19,22800415 |
| 30 | 228,6988826 | -1,698882564 | 0,748406416 |
| 31 | 222,8067278 | 12,19327221 | 5,188626473 |
| 32 | 38,81483144 | 1,185168555 | 2,962921389 |
| 33 | 48,36325811 | 18,63674189 | 27,81603267 |
| 34 | 126,6080021 | -3,608002113 | 2,933335051 |
| 35 | 84,85052935 | 15,14947065 | 15,14947065 |
| 36 | 116,7991162 | -11,79911625 | 11,23725357 |
| 37 | 84,17648426 | -13,87648426 | 19,73895342 |
| 38 | 113,9412801 | -31,94128011 | 38,95278062 |
| 39 | 215,494184 | 64,50581599 | 23,03779142 |
| 40 | 141,7795953 | 58,22040472 | 29,11020236 |
| میانگین | 101,2375 | 22,51770962 |
بر اساس ستون خطاهای نسبیمقدار متوسط را پیدا کنید =22.51% (با استفاده از تابع AVERAGE).
مقایسه نشان می دهد که 22.51٪> 7٪. بنابراین دقت مدل رضایت بخش نیست.
با استفاده از اف - معیار فیشر بیایید اهمیت مدل را به طور کلی بررسی کنیم. برای انجام این کار، ما از نتایج استفاده از ابزار "Regression" (جدول " تحلیل واریانس» برای مدل (6)) اف= 39,6702.
با استفاده از تابع FDISP، مقدار را پیدا می کنیم اف kr =3.252 برای سطح اهمیت α = 5%و تعداد درجات آزادی ک 1 = 2 , ک 2 = 37 .
اف> اف krبنابراین، معادله مدل (6) معنادار است، استفاده از آن مصلحت، متغیر وابسته است Yبه خوبی با متغیرهای عامل موجود در مدل (6) توضیح داده شده است. ایکس 1 , ایکس 2. و ایکس 4 .
علاوه بر این با استفاده از تی -معیار دانش آموزی اجازه دهید اهمیت ضرایب فردی مدل را بررسی کنیم.
تی-آمار ضرایب معادله رگرسیون در نتایج ابزار "رگرسیون" آورده شده است. اخذ شده مقادیر زیربرای مدل انتخابی (6):
| شانس | خطای استاندارد | آمار t | P-value | 95% پایین | 95% برتر | 95.0% کمتر | 95.0% برتر |
|
| تقاطع Y | -5,643572321 | 12,07285417 | -0,46745966 | 0,642988 | -30,1285 | 18,84131 | -30,1285 | 18,84131 |
| X4 | 2,591405557 | 0,461440597 | 5,61590284 | 2.27E-06 | 1,655561 | 3,52725 | 1,655561 | 3,52725 |
| X1 | 6,85963077 | 9,185748512 | 0,74676884 | 0,460053 | -11,7699 | 25,48919 | -11,7699 | 25,48919 |
| X2 | -1,985156991 | 7,795346067 | -0,25465925 | 0,800435 | -17,7949 | 13,82454 | -17,7949 | 13,82454 |
ارزش بحرانی تی krبرای سطح معنی داری یافت شد α=5%و تعداد درجات آزادی ک=40–2–1=37 . تی kr =2.026 (عملکرد STEUDRESPO).
برای ضریب آزاد α
=–5.643
آمار تعریف شده  ,
,  تی krبنابراین، ضریب آزاد معنی دار نیست، می توان آن را از مدل حذف کرد.
تی krبنابراین، ضریب آزاد معنی دار نیست، می توان آن را از مدل حذف کرد.
برای ضریب رگرسیون β
1
=6.859
آمار تعریف شده  ,
,  β
1
معنی دار نیست، می توان آن را و عامل منطقه شهر را از مدل حذف کرد.
β
1
معنی دار نیست، می توان آن را و عامل منطقه شهر را از مدل حذف کرد.
برای ضریب رگرسیون β
2
=-1,985
آمار تعریف شده  ,
,  تی kr، از این رو ضریب رگرسیون β
2
قابل توجه نیست، و فاکتور تعداد اتاق های آپارتمان را می توان از مدل حذف کرد.
تی kr، از این رو ضریب رگرسیون β
2
قابل توجه نیست، و فاکتور تعداد اتاق های آپارتمان را می توان از مدل حذف کرد.
برای ضریب رگرسیون β
4
=2.591
آمار تعریف شده  ,
,  > t cr، بنابراین، ضریب رگرسیون β
4
قابل توجه است، آن و ضریب مساحت آپارتمان را می توان در مدل ذخیره کرد.
> t cr، بنابراین، ضریب رگرسیون β
4
قابل توجه است، آن و ضریب مساحت آپارتمان را می توان در مدل ذخیره کرد.
نتیجه گیری در مورد معناداری ضرایب مدل در سطح معناداری انجام می شود α=5%. با توجه به ستون "P-value" توجه داشته باشید که ضریب آزاد α را می توان در سطح 0.64 = 64٪ در نظر گرفت. ضریب رگرسیون β 1 - در سطح 0.46 = 46٪؛ ضریب رگرسیون β 2 - در سطح 0.8 = 80٪؛ و ضریب رگرسیون β 4 – در سطح 2.27E-06= 2.26691790951854E-06 = 0.0000002%.
هنگام اضافه کردن متغیرهای عامل جدید به معادله، ضریب تعیین به طور خودکار افزایش می یابد آر 2
و کاهش می یابد خطای متوسطتقریب ها، اگرچه این همیشه کیفیت مدل را بهبود نمی بخشد. بنابراین برای مقایسه کیفیت مدل (3) و مدل چندگانه انتخابی (6) از ضرایب تعیین نرمال شده استفاده می کنیم.
بنابراین، هنگام اضافه کردن عامل "شهر منطقه" به معادله رگرسیون ایکس 1 و فاکتور "تعداد اتاق های آپارتمان" ایکس 2، کیفیت مدل بدتر شده است، که به نفع حذف عوامل صحبت می کند ایکس 1 و ایکس 2 از مدل.
بیایید محاسبات بیشتری را انجام دهیم.
میانگین ضرایب کشش
در مورد یک مدل خطی با فرمول تعیین می شود  .
.
با استفاده از تابع AVERAGE، متوجه می شویم: S Y، با افزایش تنها عامل ایکس 4 برای یکی از او انحراف معیار- 0.914 افزایش می یابد اس Y
ضرایب دلتا
با فرمول ها تعریف می شوند  .
.
بیایید ضرایب همبستگی جفت را با استفاده از ابزار "Correlation" بسته "تحلیل داده ها" در اکسل پیدا کنیم.
| Y | X1 | X2 | X4 |
|
| Y | 1 | |||
| X1 | -0,01126 | 1 | ||
| X2 | 0,751061 | -0,0341 | 1 | |
| X4 | 0,874012 | -0,0798 | 0,868524 | 1 |
ضریب تعیین زودتر تعیین شده و برابر با 0.7677 است.
بیایید ضرایب دلتا را محاسبه کنیم:
 ;
; 

از آنجایی که Δ 1 1
و ایکس 2
بد انتخاب شده اند و باید از مدل حذف شوند. از این رو، با توجه به معادله مدل خطی سه عاملی به دست آمده، تغییر در ضریب حاصل Y(قیمت آپارتمان) به دلیل تاثیر فاکتور 104% می باشد ایکس 4
(مساحت آپارتمان)، 4 درصد با تاثیر عامل ایکس 2
(تعداد اتاق)، 0.0859٪ تحت تأثیر عامل ایکس 1
(شهر منطقه).
هنگام مطالعه پدیده های پیچیده، بیش از دو عامل تصادفی باید در نظر گرفته شود. تصور درستی از ماهیت ارتباط بین این عوامل تنها در صورتی به دست میآید که همه عوامل تصادفی مورد بررسی به طور همزمان بررسی شوند. مطالعه مشترک سه یا چند عامل تصادفی به محقق این امکان را می دهد که فرضیات کم و بیش معقولی در مورد روابط علی بین پدیده های مورد مطالعه ایجاد کند. یک شکل ساده از رابطه چندگانه یک رابطه خطی بین سه ویژگی است. عوامل تصادفی به عنوان نشان داده می شوند ایکس 1 , ایکس 2 و ایکس 3 . ضرایب همبستگی زوجی بین ایکس 1 و ایکس 2 به عنوان نشان داده شده است r 12 به ترتیب بین ایکس 1 و ایکس 3 - r 12، بین ایکس 2 و ایکس 3 - r 23. به عنوان اندازه گیری تنگی رابطه خطی سه ویژگی، از ضرایب همبستگی چندگانه استفاده می شود. آر 1-23، آر 2 ¼ 13, آر 3 ּ 12 و ضرایب همبستگی جزئی نشان داده شده است r 12.3 , r 13.2 , r 23.1 .
ضریب همبستگی چندگانه R 1.23 سه عامل نشانگر نزدیکی رابطه خطی بین یکی از عوامل (شاخص قبل از نقطه) و ترکیبی از دو عامل دیگر (شاخص های بعد از نقطه) است.
مقادیر ضریب R همیشه در محدوده 0 تا 1 است. با نزدیک شدن R به یک، درجه رابطه خطی سه ویژگی افزایش می یابد.
مثلاً بین ضریب همبستگی چندگانه آر 2 ּ 13 و ضریب همبستگی دو جفت r 12 و r 23 یک رابطه وجود دارد: هر یک از ضرایب جفت نمی تواند از مقدار مطلق تجاوز کند آر 2 ּ 13.
فرمول های محاسبه ضرایب همبستگی چندگانه با مقادیر شناخته شده ضرایب همبستگی جفتی r 12، r 13 و r 23 عبارتند از:
مجذور ضریب همبستگی چندگانه آر 2 تماس گرفت ضریب تعیین چندگانهنسبت تغییرات متغیر وابسته را تحت تأثیر عوامل مورد مطالعه نشان می دهد.
اهمیت همبستگی چندگانه توسط برآورد می شود اف- معیار:
![]()
n-اندازهی نمونه؛ k-تعداد عوامل در مورد ما ک = 3.
فرضیه صفر در مورد برابری ضریب همبستگی چندگانه در جامعه به صفر ( ساعت:r= 0) پذیرفته می شود اگر f f<f t، و رد می شود اگر
f f ³ fتی
ارزش نظری f-معیار برای تعریف شده است v 1 = ک- 1 و v 2 = n - کدرجات آزادی و سطح قابل قبول اهمیت a (پیوست 1).
مثالی از محاسبه ضریب همبستگی چندگانه. هنگام مطالعه رابطه بین عوامل، ضرایب همبستگی زوجی به دست آمد. n =15): r 12 ==0.6; r 13 = 0.3; r 23 = - 0,2.
لازم است وابستگی علامت را دریابید ایکس 2 علامت خاموش ایکس 1 و ایکس 3، یعنی ضریب همبستگی چندگانه را محاسبه کنید:

مقدار جدول اف- معیار در n 1 = 2 و n 2 = 15 - 3 = 12 درجه آزادی در a = 0.05 اف 0.05 = 3.89 و در a = 0.01 اف 0,01 = 6,93.
بنابراین، رابطه بین ویژگی ها آر 2.13 = 0.74 قابل توجه است
سطح معنی داری 1 درصد اف f > اف 0,01 .
قضاوت بر اساس ضریب تعیین چندگانه آر 2 = (0.74) 2 = 0.55، تنوع ویژگی ایکس 2 55% مربوط به اثر عوامل مورد مطالعه است و 45% از تغییرات (1-R 2) را نمی توان با تاثیر این متغیرها توضیح داد.
همبستگی خطی جزئی
ضریب همبستگی جزئیشاخصی است که میزان همگرایی دو ویژگی را اندازه گیری می کند.
آمار ریاضی به شما این امکان را می دهد که بدون انجام آزمایش خاصی، اما با استفاده از ضرایب همبستگی زوجی، بین دو ویژگی با مقدار ثابت سوم ارتباط برقرار کنید. r 12 , r 13 , r 23 .
ضرایب همبستگی جزئی با استفاده از فرمول های زیر محاسبه می شود:

اعداد قبل از نقطه نشان می دهد که وابستگی بین کدام ویژگی ها مورد مطالعه قرار می گیرد و اعداد بعد از نقطه نشان می دهد که تأثیر کدام ویژگی حذف شده است (حذف شده است). خطا و معیار اهمیت همبستگی جزئی با همان فرمولهای همبستگی زوجی تعیین می شود:
 .
.
ارزش نظری t-معیار برای تعیین شده است v = n– 2 درجه آزادی و سطح اهمیت پذیرفته شده a (پیوست 1).
فرضیه صفر در مورد برابری ضریب همبستگی جزئی در مجموع به صفر ( هو: r= 0) پذیرفته می شود اگر تی f< تی t، و رد می شود اگر
تی f ³ تیتی
ضرایب جزئی می توانند مقادیری بین -1 و +1 داشته باشند. خصوصی ضرایب تعیینبا مجذور ضرایب همبستگی جزئی بدست می آیند:
D 12.3 = r 2 12ּ3 ;د 13.2 = r 2 13ּ2 ;د 23¼1 = r 2 23ּ1.
تعیین میزان تأثیر خاص عوامل فردی بر ویژگی حاصل در حالی که ارتباط آن با سایر ویژگیهایی که این همبستگی را مخدوش میکنند حذف (حذف) میکند، اغلب مورد توجه است. گاهی پیش می آید که با مقدار ثابت صفت حذف شده، نمی توان به تأثیر آماری آن بر تغییرپذیری سایر صفات پی برد. برای درک تکنیک محاسبه ضریب همبستگی جزئی، یک مثال را در نظر بگیرید. سه گزینه وجود دارد ایکس, Yو ز. برای اندازه نمونه n= 180 ضرایب همبستگی زوجی تعیین شد
rxy = 0,799; rxz = 0,57; r yz = 0,507.
بیایید ضرایب همبستگی جزئی را تعریف کنیم:

ضریب همبستگی جزئی بین پارامتر ایکسو Y ز (r xyz = 0.720) نشان می دهد که تنها بخش کوچکی از رابطه این ویژگی ها در همبستگی کلی ( rxy= 0.799) به دلیل تأثیر ویژگی سوم ( ز). یک نتیجه مشابه باید با توجه به ضریب همبستگی جزئی بین پارامتر انجام شود ایکسو پارامتر زبا مقدار پارامتر ثابت Y (rایکس zּy = 0.318 و rxz= 0.57). در مقابل، ضریب همبستگی جزئی بین پارامترها Yو زبا مقدار پارامتر ثابت X r yz ּ ایکس 0.105 = به طور قابل توجهی با ضریب همبستگی کلی r متفاوت است z= 0.507. از اینجا می توان دریافت که اگر اشیایی را با مقدار پارامتر یکسان انتخاب کنید ایکس، سپس رابطه بین ویژگی ها Yو زآنها بسیار ضعیف خواهند بود، زیرا بخش مهمی از این رابطه به دلیل تغییر پارامتر است ایکس.
تحت برخی شرایط، ضریب همبستگی جزئی ممکن است با علامت زوجی مخالف باشد.
به عنوان مثال، هنگام مطالعه رابطه بین ویژگی ها X، Yو ز- ضرایب همبستگی زوجی به دست آمد (با n = 100): r xy = 0.6; rایکس z= 0,9;
r z = 0,4.
ضرایب همبستگی جزئی هنگام حذف تأثیر ویژگی سوم:

مثال نشان می دهد که مقادیر ضریب جفتو ضریب همبستگی جزئی در علامت متفاوت است.
روش همبستگی جزئی امکان محاسبه ضریب همبستگی جزئی مرتبه دوم را فراهم می کند. این ضریب ارتباط بین ویژگی اول و دوم را با مقدار ثابت سوم و چهارم نشان می دهد. ضریب جزئی مرتبه دوم بر اساس ضرایب جزئی مرتبه اول طبق فرمول تعیین می شود:

جایی که r 12 . 4 , r 13-4، r 23 ּ4 - ضرایب جزئی که مقدار آنها با فرمول ضریب جزئی با استفاده از ضرایب همبستگی جفت تعیین می شود. r 12 , r 13 , r 14 , r 23 , r 24 , r 34 .
تجزیه و تحلیل رگرسیون- این یک روش تحقیق آماری است که به شما امکان می دهد وابستگی یک پارامتر را به یک یا چند متغیر مستقل نشان دهید. در دوران پیش از کامپیوتر، استفاده از آن بسیار دشوار بود، به خصوص زمانی که صحبت از حجم زیاد داده می شد. امروز، با یادگیری نحوه ساخت رگرسیون در اکسل، می توانید پیچیده را حل کنید وظایف آماریبه معنای واقعی کلمه در چند دقیقه در زیر نمونه های مشخصی از حوزه اقتصاد آورده شده است.
انواع رگرسیون
خود این مفهوم در سال 1886 وارد ریاضیات شد. رگرسیون اتفاق می افتد:
- خطی؛
- سهموی
- قدرت؛
- نمایی;
- هذلولی
- نمایشی؛
- لگاریتمی
مثال 1
مشکل تعیین وابستگی تعداد اعضای تیم بازنشسته را در نظر بگیرید میانگین درامددر 6 شرکت صنعتی
یک وظیفه. شش شرکت میانگین ماهانه را تجزیه و تحلیل کردند دستمزدو تعداد کارمندانی که ترک می کنند اراده خود. به شکل جدول داریم:
تعداد افرادی که رفتند | حقوق |
||
30000 روبل |
|||
35000 روبل |
|||
40000 روبل |
|||
45000 روبل |
|||
50000 روبل |
|||
55000 روبل |
|||
60000 روبل |
برای مسئله تعیین وابستگی تعداد کارگران بازنشسته به میانگین حقوق در 6 شرکت، مدل رگرسیون به شکل معادله Y = a 0 + a 1 x 1 +…+a k x k است که x i متغیرهای تأثیرگذار هستند. ، a i ضرایب رگرسیون، a k تعداد عوامل است.
برای این کار، Y نشانگر کارمندانی است که ترک کرده اند و عامل تأثیرگذار حقوق است که آن را با X نشان می دهیم.
استفاده از قابلیت های صفحه گسترده "اکسل"
تجزیه و تحلیل رگرسیون در اکسل باید قبل از اعمال توابع داخلی برای داده های جدولی موجود باشد. با این حال، برای این اهداف، بهتر است از افزونه بسیار مفید "Analysis Toolkit" استفاده کنید. برای فعال کردن آن نیاز دارید:
- از برگه "فایل" به بخش "گزینه ها" بروید.
- در پنجره ای که باز می شود، خط "افزونه ها" را انتخاب کنید.
- روی دکمه "Go" واقع در پایین، سمت راست خط "Management" کلیک کنید.
- کادر کنار نام «بسته تجزیه و تحلیل» را علامت بزنید و با کلیک روی «OK» اقدامات خود را تأیید کنید.
اگر همه چیز به درستی انجام شود، دکمه مورد نظر در سمت راست تب Data که در بالای کاربرگ اکسل قرار دارد ظاهر می شود.
در اکسل
اکنون که تمام ابزارهای مجازی لازم برای انجام محاسبات اقتصادسنجی را در اختیار داریم، می توانیم شروع به حل مشکل خود کنیم. برای این:
- بر روی دکمه "تجزیه و تحلیل داده ها" کلیک کنید؛
- در پنجره ای که باز می شود، روی دکمه "Regression" کلیک کنید.
- در برگه ای که ظاهر می شود، محدوده مقادیر Y (تعداد کارمندانی که ترک می کنند) و X (حقوق آنها) را وارد کنید.
- ما اقدامات خود را با فشار دادن دکمه "Ok" تأیید می کنیم.
در نتیجه، برنامه به طور خودکار یک صفحه جدید از صفحه گسترده را با داده های تحلیل رگرسیون پر می کند. توجه داشته باشید! اکسل این قابلیت را دارد که به صورت دستی مکان مورد نظر شما را برای این منظور تنظیم کند. به عنوان مثال، می تواند همان برگه ای باشد که مقادیر Y و X در آن هستند یا حتی یک کتاب جدید، به ویژه برای ذخیره چنین داده هایی طراحی شده است.
تجزیه و تحلیل نتایج رگرسیون برای R-square
در اکسل، داده های به دست آمده در هنگام پردازش داده های مثال در نظر گرفته شده به صورت زیر است:
اول از همه باید به مقدار R-square توجه کنید. ضریب تعیین است. در این مثال، R-square = 0.755 (75.5%)، یعنی پارامترهای محاسبه شده مدل، رابطه بین پارامترهای در نظر گرفته شده را 75.5٪ توضیح می دهد. هر چه مقدار ضریب تعیین بالاتر باشد، مدل انتخاب شده برای یک کار خاص کاربرد بیشتری دارد. اعتقاد بر این است که به درستی وضعیت واقعی را با مقدار مربع R بالای 0.8 توصیف می کند. اگر R مربع باشد<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
تجزیه و تحلیل نسبت
عدد 64.1428 نشان میدهد که اگر تمام متغیرهای xi در مدلی که در نظر میگیریم صفر شوند، مقدار Y چقدر خواهد بود. به عبارت دیگر، می توان استدلال کرد که مقدار پارامتر تحلیل شده نیز تحت تأثیر عوامل دیگری است که در یک مدل خاص توضیح داده نشده اند.
ضریب بعدی -0.16285 که در سلول B18 قرار دارد، وزن تأثیر متغیر X را بر Y نشان می دهد. این بدان معنی است که میانگین حقوق ماهانه کارکنان در مدل مورد بررسی بر تعداد افراد ترک با وزن 0.16285- تأثیر می گذارد. درجه نفوذ آن در همه کوچک است. علامت "-" نشان می دهد که ضریب دارای مقدار منفی است. این بدیهی است ، زیرا همه می دانند که هر چه حقوق در شرکت بالاتر باشد ، افراد کمتری تمایل به فسخ قرارداد کار یا ترک کار دارند.
رگرسیون چندگانه
این اصطلاح به یک معادله اتصال با چندین متغیر مستقل از شکل اشاره دارد:
y \u003d f (x 1 + x 2 + ... x m) + ε، که در آن y ویژگی مؤثر (متغیر وابسته) است، و x 1، x 2، ... x m عوامل عامل (متغیرهای مستقل) هستند.
تخمین پارامتر
برای رگرسیون چندگانه(MR) با استفاده از روش حداقل مربعات (LSM) انجام می شود. برای معادلات خطی به شکل Y = a + b 1 x 1 +…+b m x m + ε، ما سیستمی از معادلات عادی می سازیم (به زیر مراجعه کنید)

برای درک اصل روش، حالت دو عاملی را در نظر بگیرید. سپس وضعیتی داریم که با فرمول توصیف شده است

از اینجا دریافت می کنیم:

که در آن σ واریانس ویژگی مربوطه منعکس شده در شاخص است.
LSM برای معادله MP در مقیاس قابل استانداردسازی قابل اعمال است. در این حالت معادله را بدست می آوریم:

که در آن t y، t x 1، ... t xm متغیرهای استاندارد شده ای هستند که مقادیر میانگین آنها 0 است. β i ضرایب رگرسیون استاندارد شده است و انحراف استاندارد 1 است.
لطفاً توجه داشته باشید که همه β i در این مورد به صورت عادی و متمرکز تنظیم می شوند، بنابراین مقایسه آنها با یکدیگر صحیح و قابل قبول است. علاوه بر این، مرسوم است که فاکتورها را فیلتر کرده و آنهایی را که دارای کمترین مقادیر βi هستند کنار بگذارند.
مسئله با استفاده از معادله رگرسیون خطی
فرض کنید جدولی از پویایی قیمت یک محصول خاص N در 8 ماه گذشته وجود دارد. لازم است در مورد توصیه خرید دسته آن با قیمت 1850 روبل در تن تصمیم گیری شود.
شماره ماه | نام ماه | قیمت کالای N |
|
1750 روبل در هر تن |
|||
1755 روبل در هر تن |
|||
1767 روبل در هر تن |
|||
1760 روبل در هر تن |
|||
1770 روبل در هر تن |
|||
1790 روبل در هر تن |
|||
1810 روبل در هر تن |
|||
1840 روبل در هر تن |
|||
برای حل این مشکل در صفحه گسترده اکسل، باید از ابزار تجزیه و تحلیل داده ها که قبلاً در مثال بالا شناخته شده است استفاده کنید. بعد، بخش "Regression" را انتخاب کنید و پارامترها را تنظیم کنید. لازم به یادآوری است که در قسمت "فاصله ورودی Y" باید محدوده ای از مقادیر برای متغیر وابسته (در این مورد قیمت یک محصول در ماه های خاص سال) و در "ورودی" وارد شود. فاصله X" - برای متغیر مستقل (تعداد ماه). با کلیک بر روی "Ok" اقدام را تأیید کنید. در یک برگه جدید (اگر چنین نشان داده شده بود)، ما داده هایی را برای رگرسیون دریافت می کنیم.
بر اساس آنها یک معادله خطی به شکل y=ax+b می سازیم که در آن پارامترهای a و b ضرایب سطر با نام شماره ماه و ضرایب و ردیف "تقاطع Y" از برگه با نتایج تحلیل رگرسیون. بنابراین، معادله رگرسیون خطی (LE) برای مسئله 3 به صورت زیر نوشته می شود:
قیمت محصول N = 11.714* شماره ماه + 1727.54.
یا در نماد جبری
y = 11.714 x + 1727.54
تجزیه و تحلیل نتایج
برای تصمیم گیری در مورد مناسب بودن معادله رگرسیون خطی حاصل، از ضرایب همبستگی چندگانه (MCC) و ضرایب تعیین و همچنین آزمون فیشر و آزمون دانشجو استفاده می شود. در جدول اکسل با نتایج رگرسیون، به ترتیب با نام های R متعدد، R-square، F-statistic و t-statistic ظاهر می شوند.
KMC R امکان ارزیابی تنگی رابطه احتمالی بین متغیرهای مستقل و وابسته را فراهم می کند. ارزش بالای آن نشان دهنده رابطه نسبتاً قوی بین متغیرهای "تعداد ماه" و "قیمت کالا N بر حسب روبل در هر 1 تن" است. با این حال، ماهیت این رابطه ناشناخته باقی مانده است.
مجذور ضریب تعیین R 2 (RI) یک مشخصه عددی از سهم پراکندگی کل است و پراکندگی کدام بخشی از داده های تجربی را نشان می دهد، یعنی. مقادیر متغیر وابسته با معادله رگرسیون خطی مطابقت دارد. در مسئله مورد بررسی، این مقدار برابر 84.8 درصد است، یعنی داده های آماری با دقت بالایی توسط SD به دست آمده توصیف می شوند.
آماره F که آزمون فیشر نیز نامیده می شود، برای ارزیابی اهمیت یک رابطه خطی، رد یا تایید فرضیه وجود آن استفاده می شود.
(معیار دانش آموز) به ارزیابی اهمیت ضریب با یک جمله مجهول یا آزاد یک رابطه خطی کمک می کند. اگر مقدار معیار t > t cr باشد، فرضیه بی اهمیت بودن عبارت آزاد است. معادله خطیرد شد.
در مسئله مورد بررسی برای عضو آزاد با استفاده از ابزار اکسل به دست آمد که t = 169.20903 و p = 2.89E-12، یعنی احتمال صفر داریم که فرضیه صحیح در مورد بی اهمیت بودن عضو آزاد باشد. رد شد. برای ضریب مجهول t=5.79405 و p=0.001158. به عبارت دیگر، احتمال رد فرضیه صحیح در مورد بی اهمیت بودن ضریب برای مجهول 0.12 درصد است.
بنابراین، می توان استدلال کرد که معادله رگرسیون خطی به دست آمده کافی است.
مشکل مصلحت خرید بلوک سهام
رگرسیون چندگانه در اکسل با استفاده از همان ابزار تحلیل داده انجام می شود. یک مشکل کاربردی خاص را در نظر بگیرید.
مدیریت NNN باید در مورد امکان خرید 20 درصد از سهام MMM SA تصمیم گیری کند. هزینه بسته (JV) 70 میلیون دلار آمریکا می باشد. متخصصان NNN داده های مربوط به تراکنش های مشابه را جمع آوری کردند. تصمیم بر این شد که ارزش بلوک سهام با توجه به پارامترهایی که به میلیون ها دلار آمریکا بیان می شود، ارزیابی شود:
- حساب های پرداختنی (VK)؛
- گردش مالی سالانه (VO)؛
- حساب های دریافتنی (VD)؛
- هزینه دارایی های ثابت (SOF).
علاوه بر این، پارامتر حقوق و دستمزد معوقه شرکت (V3 P) به هزار دلار آمریکا استفاده می شود.
راه حل با استفاده از صفحه گسترده اکسل
اول از همه، شما باید یک جدول از داده های اولیه ایجاد کنید. به نظر می رسد این است:

- با پنجره "تجزیه و تحلیل داده ها" تماس بگیرید.
- بخش "Regression" را انتخاب کنید؛
- در کادر "فاصله ورودی Y" محدوده مقادیر متغیرهای وابسته را از ستون G وارد کنید.
- روی نماد با یک فلش قرمز در سمت راست کادر "Input interval X" کلیک کنید و محدوده ای از تمام مقادیر را در برگه انتخاب کنید. ستون B,C، دی، اف.
«کاربرگ جدید» را انتخاب کرده و روی «تأیید» کلیک کنید.
تحلیل رگرسیون را برای مسئله داده شده دریافت کنید.

بررسی نتایج و نتیجه گیری
"ما" از داده های گرد ارائه شده در بالا در صفحه گسترده اکسل، معادله رگرسیون جمع آوری می کنیم:
SP \u003d 0.103 * SOF + 0.541 * VO - 0.031 * VK + 0.405 * VD + 0.691 * VZP - 265.844.
در یک شکل ریاضی آشناتر، می توان آن را به صورت زیر نوشت:
y = 0.103*x1 + 0.541*x2 - 0.031*x3 +0.405*x4 +0.691*x5 - 265.844
داده های JSC "MMM" در جدول ارائه شده است:
با جایگزینی آنها در معادله رگرسیون، رقمی معادل 64.72 میلیون دلار آمریکا بدست می آید. این به این معنی است که سهام JSC MMM نباید خریداری شود، زیرا ارزش 70 میلیون دلاری آنها بسیار زیاد است.
همانطور که می بینید، استفاده از صفحه گسترده اکسل و معادله رگرسیون امکان تصمیم گیری آگاهانه در مورد امکان سنجی یک تراکنش بسیار خاص را فراهم می کند.
اکنون می دانید که رگرسیون چیست. مثالهایی در اکسل که در بالا مورد بحث قرار گرفت به شما کمک میکند تصمیم بگیرید. وظایف عملیاز رشته اقتصاد سنجی
