Оценка на резултатите от линейната регресия. Множествен коефициент на корелация и множествен коефициент на детерминация
Коефициентът на множествена корелация на три променливи е индикатор за близостта на линейна връзка между един от признаците (индексна буква преди тирето) и комбинация от два други признака (индексни букви след тирето):
 ; (12.7)
; (12.7)
 (12.8)
(12.8)
Тези формули улесняват изчисляването на множество корелационни коефициенти за известни стойностидвойни коефициенти на корелация r xy, r xz и r yz.
Коефициент Рне е отрицателна и винаги е между 0 и 1. При приближаване Рдо единство се увеличава степента на линейна връзка на трите признака. Между съотношение множествена корелация, например R y-xzи две двойки корелационни коефициенти r yxи r yzима следната връзка: всеки от коефициентите на двойката не може да надвишава по абсолютна стойност R y-xz.
Квадратът на коефициента на множествена корелация R2се нарича коефициент на множествена детерминация. Той показва съотношението на вариация в зависимата променлива под влиянието на изследваните фактори.
Значимостта на множествената корелация се оценява от
Е– критерий:
 , (12.9)
, (12.9)
не размерът на извадката,
к– брой знаци; в нашия случай к = 3.
теоретична стойност Е– критериите са взети от таблицата за кандидатстване за ν 1 = k-1 и ν 2 \u003d n–kстепените на свобода и приетото ниво на значимост. Нулева хипотеза за равенството на коефициента на множествена корелация в популацията на нула ( H0:R= 0) се приема, ако F факт.< F табл . и отхвърлен, ако F факт. ≥ F таблица.
Край на работата -
Тази тема принадлежи на:
Математическа статистика
Учебно заведение.. Гомел Държавен университет.. кръстен на Франциск Скарина Ю М Жученко ..
Ако се нуждаеш допълнителен материалпо тази тема или не сте намерили това, което търсите, препоръчваме да използвате търсенето в нашата база данни с произведения:
Какво ще правим с получения материал:
Ако този материал се оказа полезен за вас, можете да го запазите на страницата си в социалните мрежи:
| туит |
Всички теми в този раздел:
Урок
за студенти, обучаващи се по специалността 1-31 01 01 "Биология" Гомел 2010 г.
Предмет и метод на математическата статистика
Предмет на математическата статистика е изучаването на свойствата на масовите явления в биологията, икономиката, технологиите и други области. Тези явления обикновено са сложни, поради разнообразието (вариация
Концепцията за случайно събитие
Статистическа индукция или статистическо заключение като основно компонентметод за изучаване на масови явления, имат свои собствени отличителни черти. Статистическите заключения са направени с числени
Вероятност за случайно събитие
Числена характеристикаслучайно събитие, което има свойството, че за всяка достатъчно голяма серия от тестове, честотата на събитието се различава само малко от тази характеристика, се нарича
Изчисляване на вероятности
Често има нужда от едновременно добавяне и умножаване на вероятности. Например, искате да определите вероятността да получите 5 точки, когато хвърлите 2 зара едновременно. Необходимата сума е вероятно
Концепцията за случайна променлива
След като дефинирахме понятието вероятност и изяснихме основните му свойства, нека преминем към разглеждането на едно от най-важните понятия на теорията на вероятностите - понятието за случайна променлива. Нека приемем, че като резултат
Дискретни случайни променливи
Случайната променлива е дискретна, ако наборът от нейните възможни стойности е краен, или според поне, е изброимо. Да приемем, че случайна променлива X може да приеме стойностите x1
Непрекъснати случайни променливи
За разлика от дискретните случайни променливи, обсъдени в предишния подраздел, наборът от възможни стойности за непрекъсната случайна променлива не само не е краен, но също така не се поддава на
Математическо очакване и дисперсия
Често има нужда да се характеризира разпределението на случайна променлива с помощта на един или два числови показателя, които изразяват най-значимите свойства на това разпределение. На такива
Моменти
От голямо значение в математическата статистика са така наречените моменти на разпределение на случайна величина. AT математическо очакванеголеми стойности на случайна променлива се вземат предвид недостатъчно.
Биномиално разпределение и измерване на вероятности
В тази тема ще разгледаме основните видове разпределение на дискретни случайни променливи. Нека приемем, че вероятността за възникване на някакво случайно събитие А в едно изпитание е равна на
Правоъгълно (равномерно) разпределение
Правоъгълното (равномерно) разпределение е най-простият тип непрекъснати разпределения. Ако случайна променлива X може да приеме всяка реална стойност в интервала (a, b), където a и b са реални
Нормална дистрибуция
Нормалното разпределение играе важна роля в математическата статистика. Това съвсем не е случайно: в обективната реалност много често се срещат различни признаци.
лог-нормално разпределение
Случайната променлива Y има логаритмично нормална дистрибуцияс параметри μ и σ, ако случайната променлива X = lnY има нормално разпределение със същите параметри μ и &
Средни стойности
От всички групови свойства най-голямо теоретично и практическо значение има средното ниво, измерено чрез средната стойност на признака. Средната стойност на характеристика е много дълбока концепция,
Общи свойства на средните
За правилното използване на средните стойности е необходимо да се познават свойствата на тези показатели: медианното местоположение, абстрактността и единството на общото действие. По числената си стойност
Средноаритметично
Средно аритметично, като общи имотисредни стойности, има свои собствени характеристики, които могат да бъдат изразени със следните формули:
Среден ранг (средно непараметрично)
Средният ранг се определя за такива характеристики, за които все още не са открити методи за количествено измерване. Според степента на проявление на такива характеристики обектите могат да бъдат класирани, т.е. локализирани
Среднопретеглена аритметична
Обикновено, за да изчислите средната аритметична стойност, добавете всички стойности на характеристикитеи получената сума се разделя на броя на опциите. В този случай всяка стойност, влизаща в сумата, я увеличава докрай
корен квадратен
Средноквадратичният корен се изчислява по формулата: , (6.5) Равен е на корен квадратен от сумата
Медиана
Медианата е такава стойност на характеристиката, която разделя цялата група на две равни части: едната част има стойност на характеристиката, по-малка от медианата, а другата има по-голяма стойност. Например, ако имам
Средна геометрична
За да получите средната геометрична стойност за група с n данни, трябва да умножите всички опции и да извлечете от получения продукт n-ти коренстепени:
Средно хармонично
Средната хармонична стойност се изчислява по формулата. (6.14) За пет опции: 1, 4, 5, 5 средно
Брой степени на свобода
Броят на степените на свобода е равен на броя на свободните многообразни елементи в групата. Той е равен на броя на всички налични учебни елементи без броя на ограниченията на разнообразието. Например за изследване
Коефициентът на вариация
Стандартното отклонение е наименована стойност, изразена в същите единици като средната аритметична стойност. Следователно, за да сравните различни характеристики, изразени в различни единици от
Граници и обхват
За бърза и приблизителна оценка на степента на разнообразие често се използват най-простите показатели: lim = (min ¸ max) - граници, т.е. най-голяма стойностфункция, p =
Нормализирано отклонение
Обикновено степента на развитие на даден признак се определя чрез измерването му и се изразява с определено наименувано число: 3 кг тегло, 15 см дължина, 20 кукички на крилото на пчелите, 4% масленост на млякото, 15 кг. изрязване
Средна стойност и сигма на сумарната група
Понякога е необходимо да се определи средната стойност и сигма за сумарно разпределение, съставено от няколко разпределения. В този случай не са известни самите разпределения, а само техните средни стойности и сигми.
Наклон (асимметричност) и стръмност (ексцет) на кривата на разпределение
За големи проби (n > 100) се изчисляват още две статистики. Изкривяването на кривата се нарича асиметрия:
Вариационни серии
С увеличаването на размера на изследваните групи все повече се проявява закономерността в разнообразието, което в малките групи беше скрито от случайната форма на проявление.
Хистограма и вариационна крива
Хистограмата е вариационна серия, представен под формата на диаграма, в която различна стойност на честотата е изобразена с различна височина на лентата. Хистограмата на разпределението на данните е показана на стр
Значение на разликите в разпределението
Статистическата хипотеза е конкретно предположение за вероятностното разпределение, което е в основата на наблюдаваната извадка от данни. Преглед статистическа хипотезае процес на приемане
Критерии за изкривяване и ексцес
Някои признаци на растения, животни и микроорганизми, когато обектите се комбинират в групи, дават разпределения, които се различават значително от нормалното. В случаите, когато има
Генерална съвкупност и извадка
Целият набор от индивиди от определена категория се нарича генерална съвкупност. Сила на звука населениеопределени от целите на изследването. Ако се изследва някакъв вид диви животни
Представителност
Директното изследване на група избрани обекти дава, на първо място, първичен материали характеристики на самата проба. Всички примерни данни и обобщени цифри са уместни като
Грешки в представителността и други грешки в изследването
Оценката на общите параметри въз основа на селективни показатели има свои собствени характеристики. Една част никога не може напълно да характеризира цялото, следователно характеристиката на общата съвкупност
Граници на доверието
Необходимо е да се определи стойността на грешките на представителност, за да се използват примерни показатели и за намиране на възможни стойности на общи параметри. Този процес се нарича o
Процедура за обща оценка
Три стойности, необходими за оценка на общия параметър - примерен индикатор (), критерий за надеждност
Оценка на средноаритметичната стойност
Степен среден размерима за цел да установи стойността на общата авария за изследваната категория обекти. Грешката на представителност, необходима за тази цел, се определя по формулата:
Оценка на средната разлика
В някои проучвания разликата между две измервания се приема като първична информация. Това може да е случаят, когато всеки индивид от пробата се изследва в две състояния - или в различни възрасти, или стр
Ненадеждна и надеждна оценка на средната разлика
Такива резултати от селективни изследвания, според които е невъзможно да се получи определена оценка на общия параметър (или той да е по-голям от нула, или по-малък или равен на нула), се наричат ненадеждни.
Оценка на разликата на общите средни
При биологичните изследвания разликата между две количества е от особено значение. По разлика се сравняват различни популации, раси, породи, сортове, линии, семейства, експериментални и контролни групи (метод gr
Критерий за надеждност на разликата
По същото време голямо значение, което има за изследователите получаването на надеждни разлики, има нужда от овладяване на методи, които позволяват да се определи дали полученото е надеждно, реалистично
Представителност при изследване на качествени признаци
Качествените черти обикновено не могат да имат градации на проявление: те или съществуват, или не съществуват във всеки от индивидите, например пол, пол, наличие или отсъствие на някакви черти, грозота
Достоверност на разликата в дяловете
Надеждността на разликата в извадковите дялове се определя по същия начин, както за разликата в средните: (10.34)
Коефициент на корелация
В много изследвания се изисква да се изследват няколко признака във взаимната им връзка. Ако проведем такова изследване по отношение на две черти, тогава можем да видим, че променливостта на една черта не е
Грешка на коефициента на корелация
Както всяка стойност на извадката, коефициентът на корелация има собствена грешка на представителност, изчислена за големи извадки по формулата:
Доверие на коефициента на корелация на извадката
Критерият за извадковия коефициент на корелация се определя по формулата: (11.9) където:
Доверителни граници на корелационния коефициент
Намерени са доверителните граници на общата стойност на корелационния коефициент по общ начинпо формулата:
Достоверност на разликата между два корелационни коефициента
Надеждността на разликата в коефициентите на корелация се определя по същия начин, както надеждността на разликата в средните стойности, съгласно обичайната формула
Регресионно уравнение на права линия
Праволинейната корелация е различна по това, че при тази форма на връзка всяка една и съща промяна в първия атрибут съответства на добре дефинирана и също същата средна промяна в другия pr
Грешки на елементите на уравнението на праволинейната регресия
В уравнението проста права линейна регресия: y = a + bx има три грешки в представителността. 1 Грешка на регресионния коефициент:
Частичен коефициент на корелация
Коефициентът на частична корелация е показател, който измерва степента на конюгиране на два признака, когато постоянна стойносттрети. Математическата статистика ви позволява да установите корелация
Уравнение на линейна множествена регресия
Математическото уравнение за връзка по права линия между три променливи се нарича множествено линейно уравнение на регресионната равнина. Има следната обща форма:
корелационна връзка
Ако връзката между изследваните явления значително се отклонява от линейната, която лесно се установява от графиката, тогава коефициентът на корелация е неподходящ като мярка за връзката. Може да показва липсата
Свойства на корелационна връзка
Коефициентът на корелация измерва степента на корелация във всяка от нейните форми. В допълнение, съотношението на корелация има редица други свойства, които са от голям интерес в статистиката
Грешка в представителността на коефициента на корелация
Все още не е разработена точна формула за грешката на представителността. корелационна връзка. Формулата, която обикновено се дава в учебниците, има недостатъци, които не винаги могат да бъдат пренебрегнати. Тази формула не го прави
Критерий за корелационна линейност
За да се определи степента на сближаване на криволинейна зависимост с праволинейна, се използва критерият F, изчислен по формулата:
Дисперсионен комплекс
Дисперсионният комплекс е набор от градации с данните, включени за изследването и средната стойност на данните за всяка градация (частни средни стойности) и за целия комплекс (обща средна стойност).
Статистически влияния
Статистическото влияние е отражение в разнообразието на получената характеристика на разнообразието на фактора (неговите градации), което е организирано в изследването. За оценка на влиянието на нео
Факторно влияние
Факторното влияние е просто или комбинирано статистическо влияние на изследваните фактори. При еднофакторните комплекси се изучава простото влияние на един фактор на определени организационни нива.
Еднофакторен дисперсионен комплекс
Дисперсионният анализ е разработен и въведен в практиката на селскостопанските и биологичните изследвания от английския учен Р. А. Фишър, който открива закона за разпределение на съотношението на средните квадрати
Многофакторен дисперсионен комплекс
ясна представа за математически моделанализът на дисперсията улеснява разбирането на необходимите изчислителни операции, особено при обработка на данни от многовариантни експерименти, в които има повече
Трансформации
Правилното използване на дисперсионния анализ за обработка на експериментален материал предполага хомогенност на дисперсии за варианти (извадки), нормално или близко до него разпределение в
Индикатори за силата на въздействията
Определянето на силата на влиянията по техните резултати се изисква в биологията, селско стопанство, лекарство за избор на най ефективни средстваекспозиция, за дозировката на физични и химични агенти - ст
Грешката на представителност на основния показател за силата на влияние
Точната формула за грешката на основния показател за силата на влияние все още не е намерена. В еднофакторни комплекси, когато грешката на представителност се определя само за един факторен показател
Гранични стойности на показателите за сила на влияние
Основният показател за силата на влияние е равен на дела на един термин от общата сума на термините. Освен това този показател е равно на квадратакорелационна връзка. Поради тези две причини индикаторът за мощност
Надеждност на въздействията
Основният показател за силата на въздействие, получен при селективно изследване, характеризира на първо място степента на влияние, която наистина се е проявила в групата от изследвани обекти.
Дискриминантен анализ
Дискриминантният анализ е един от методите на многовариантния статистически анализ. Целта на дискриминантния анализ е въз основа на измерването на различни характеристики (характеристики, двойки
Постановка на проблема, методи за решаване, ограничения
Да предположим, че има n обекта с m характеристики. В резултат на измерванията всеки обект се характеризира с вектора x1 ... xm, m>1. Задачата е това
Предпоставки и ограничения
Дискриминантният анализ "работи" при редица предположения. Предположението, че наблюдаваните величини - измерените характеристики на обекта - имат нормално разпределение. то
Алгоритъм за дискриминантен анализ
Решаването на проблемите с дискриминацията (дискриминантен анализ) се състои в разделянето на цялото пространство на извадката (наборът от реализации на всички разглеждани многомерни случайни променливи) за някакво число
клъстерен анализ
Клъстерният анализ съчетава различни процедури, използвани за извършване на класификация. В резултат на прилагането на тези процедури първоначалният набор от обекти се разделя на клъстери или групи
Методи за клъстерен анализ
На практика обикновено се прилагат агломеративни клъстерни методи. Обикновено, преди да започне класификацията, данните се стандартизират (средната се изважда и квадратният корен се разделя).
Алгоритъм за клъстерен анализ
Клъстерният анализ е набор от методи за класифициране на многоизмерни наблюдения или обекти въз основа на дефиницията на концепцията за разстояние между обекти, последвано от избор на групи от тях, &
От особено значение е изчисляването на коефициента на множествена корелация резултатна характеристика y с фактор x 1 , x 2 ,…, x m ,формула за определяне кои в общ случайима формата
където ∆ r е детерминантата на корелационната матрица; ∆ 11 е алгебричното допълнение на елемента r yy от корелационната матрица.
Ако се вземат предвид само два факторни знака, тогава може да се използва следната формула за изчисляване на коефициента на множествена корелация: 
Изграждането на коефициент на множествена корелация е препоръчително само в случай, че частичните коефициенти на корелация се оказаха значими и връзката между получената характеристика и факторите, включени в модела, наистина съществува.
Коефициент на определяне
Обща формула: R 2 = RSS/TSS=1-ESS/TSSкъдето RSS е обяснената сума от квадратни отклонения, ESS е необяснената (остатъчна) сума от квадратни отклонения, TSS е обща сумаквадратни отклонения (TSS=RSS+ESS)
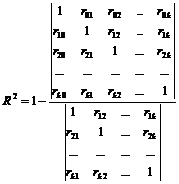 ,
,
където r ij - двойки корелационни коефициенти между регресори x i и x j , a r i 0 - двойки корелационни коефициенти между регресори x i и y ;
- коригиран (нормализиран) коефициент на детерминация.
Квадратът на коефициента на множествена корелация ![]() Наречен множествен коефициент на детерминация; показва каква част от дисперсията на резултантния атрибут гсе обяснява с влиянието на факторните знаци x 1 , x 2 , …, x m . Обърнете внимание, че формулата за изчисляване на коефициента на детерминация чрез отношението на остатъка и обща дисперсиярезултатната функция ще даде същия резултат.
Наречен множествен коефициент на детерминация; показва каква част от дисперсията на резултантния атрибут гсе обяснява с влиянието на факторните знаци x 1 , x 2 , …, x m . Обърнете внимание, че формулата за изчисляване на коефициента на детерминация чрез отношението на остатъка и обща дисперсиярезултатната функция ще даде същия резултат.
Коефициентът на множествена корелация и коефициентът на детерминация варират от 0 до 1. Колкото по-близо до 1, толкова по-силна е връзката и съответно толкова по-точно построеното по-долу регресионно уравнение ще опише зависимостта гот x 1 , x 2 , …,x m . Ако стойността на коефициента на множествена корелация е малка (по-малка от 0,3), това означава, че избраният набор от факторни характеристики не описва адекватно вариацията на резултантната характеристика или връзката между факторните и резултатните променливи е нелинейна.
Коефициентът на множествена корелация се изчислява с помощта на калкулатор. Значението на коефициента на множествена корелация и коефициента на детерминацияпроверени с помощта на теста на Фишер.
Кое от следните числа може да бъде стойността на коефициента на множествена детерминация:
а) 0,4;
б) -1;
в) -2,7;
г) 2.7.
Многократни линеен коефициенткорелацията е 0,75. Какъв процент от вариацията на зависимата променлива y се взема предвид в модела и се дължи на влиянието на факторите x 1 и x 2.
а) 56.2 (R2 =0.75 2 =0.5625);
Оценете качеството на изградения модел. Подобри ли се качеството на модела в сравнение с еднофакторния модел? Дайте оценка на влиянието на значимите фактори върху резултата, като използвате коефициенти на еластичност, - и -коефициенти.
Коефициент на определяне Р- вземаме квадрата от резултатите от "Регресията" (таблица " Регресионна статистика» за модел (6)).
Следователно варирането (промяната) в цената на апартамента Y 76,77% се обяснява с това уравнение с вариацията на града на региона х 1 , броя на стаите в апартамента х 2 и жилищна площ х 4 .
Използваме оригиналните данни Y ази остатъците, открити от инструмента за регресия  (таблица "Извод на остатъка" за модел (6)). Изчислете относителните грешки и намерете средната стойност
(таблица "Извод на остатъка" за модел (6)). Изчислете относителните грешки и намерете средната стойност  .
.
ОСТАТЪЧНО ТЕГЛЕНЕ
| Наблюдение | Предсказаният Y | останки | отн. грешка |
| 1 | 45,95089273 | -7,95089273 | 20,92340192 |
| 2 | 86,10296493 | -23,90296493 | 38,42920407 |
| 3 | 94,84442678 | 30,15557322 | 24,12445858 |
| 4 | 84,17648426 | -23,07648426 | 37,76838667 |
| 5 | 40,2537216 | 26,7462784 | 39,91981851 |
| 6 | 68,70572376 | 24,29427624 | 26,12287768 |
| 7 | 143,7464899 | -25,7464899 | 21,81905923 |
| 8 | 106,0907598 | 25,90924022 | 19,62821228 |
| 9 | 135,357993 | -42,85799303 | 46,33296544 |
| 10 | 114,4792566 | -9,47925665 | 9,027863476 |
| 11 | 41,48765602 | 0,512343975 | 1,219866607 |
| 12 | 103,2329236 | 21,76707636 | 17,41366109 |
| 13 | 130,3567798 | 39,64322022 | 23,3195413 |
| 14 | 35,41901876 | 2,580981242 | 6,7920559 |
| 15 | 155,4129693 | -24,91296925 | 19,0903979 |
| 16 | 84,32108188 | 0,678918123 | 0,798727204 |
| 17 | 98,0552279 | -0,055227902 | 0,056355002 |
| 18 | 144,2104618 | -16,21046182 | 12,66442329 |
| 19 | 122,8677535 | -37,86775351 | 44,55029825 |
| 20 | 100,0221225 | 59,97787748 | 37,48617343 |
| 21 | 53,27196558 | 6,728034423 | 11,21339071 |
| 22 | 35,06605378 | 5,933946225 | 14,47303957 |
| 23 | 114,4792566 | -24,47925665 | 27,19917406 |
| 24 | 113,1343153 | -30,13431529 | 36,30640396 |
| 25 | 40,43190991 | 4,568090093 | 10,15131132 |
| 26 | 39,34427892 | -0,344278918 | 0,882766457 |
| 27 | 144,4794501 | -57,57945009 | 66,25943623 |
| 28 | 56,4827667 | -16,4827667 | 41,20691675 |
| 29 | 95,38240332 | -15,38240332 | 19,22800415 |
| 30 | 228,6988826 | -1,698882564 | 0,748406416 |
| 31 | 222,8067278 | 12,19327221 | 5,188626473 |
| 32 | 38,81483144 | 1,185168555 | 2,962921389 |
| 33 | 48,36325811 | 18,63674189 | 27,81603267 |
| 34 | 126,6080021 | -3,608002113 | 2,933335051 |
| 35 | 84,85052935 | 15,14947065 | 15,14947065 |
| 36 | 116,7991162 | -11,79911625 | 11,23725357 |
| 37 | 84,17648426 | -13,87648426 | 19,73895342 |
| 38 | 113,9412801 | -31,94128011 | 38,95278062 |
| 39 | 215,494184 | 64,50581599 | 23,03779142 |
| 40 | 141,7795953 | 58,22040472 | 29,11020236 |
| Средно аритметично | 101,2375 | 22,51770962 |
По колона относителни грешкинамерете средната стойност =22.51% (с помощта на функцията AVERAGE).
Сравнението показва, че 22,51%>7%. Следователно точността на модела е незадоволителна.
Като се използва Е – Критерий на Фишер Нека проверим значението на модела като цяло. За да направите това, изписваме от резултатите от използването на инструмента "Регресия" (таблица " дисперсионен анализ» за модел (6)) Е= 39,6702.
Използвайки функцията FDISP, намираме стойността Е кр =3.252 за ниво на значимост α = 5%и броя на степените на свобода к 1 = 2 , к 2 = 37 .
Е> Е кр, следователно уравнението на модела (6) е значимо, използването му е целесъобразно, зависима променлива Yе сравнително добре описан от факторните променливи, включени в модела (6) х 1 , х 2. и х 4 .
Допълнително използвайки T – Критерий на ученика Нека проверим значимостта на отделните коефициенти на модела.
T– статистиките за коефициентите на регресионното уравнение са дадени в резултатите от инструмента "Регресия". получено следните стойностиза избран модел (6) :
| Коефициенти | стандартна грешка | t-статистика | P-стойност | дъно 95% | Топ 95% | По-ниски 95,0% | Топ 95,0% |
|
| Y-пресечка | -5,643572321 | 12,07285417 | -0,46745966 | 0,642988 | -30,1285 | 18,84131 | -30,1285 | 18,84131 |
| X4 | 2,591405557 | 0,461440597 | 5,61590284 | 2.27E-06 | 1,655561 | 3,52725 | 1,655561 | 3,52725 |
| X1 | 6,85963077 | 9,185748512 | 0,74676884 | 0,460053 | -11,7699 | 25,48919 | -11,7699 | 25,48919 |
| X2 | -1,985156991 | 7,795346067 | -0,25465925 | 0,800435 | -17,7949 | 13,82454 | -17,7949 | 13,82454 |
критична стойност T крнамерено за ниво на значимост α=5%и брой степени на свобода к=40–2–1=37 . T кр =2.026 (функция STEUDRESPO).
За безплатен коеф α
=–5.643
дефинирани статистики  ,
,  T кр, следователно свободният коефициент не е значим, той може да бъде изключен от модела.
T кр, следователно свободният коефициент не е значим, той може да бъде изключен от модела.
За коефициента на регресия β
1
=6.859
дефинирани статистики  ,
,  β
1
не е значим, той и факторът град град могат да бъдат премахнати от модела.
β
1
не е значим, той и факторът град град могат да бъдат премахнати от модела.
За коефициента на регресия β
2
=-1,985
дефинирани статистики  ,
,  T кр, следователно коефициентът на регресия β
2
не е значим, той и факторът брой стаи в апартамента могат да бъдат изключени от модела.
T кр, следователно коефициентът на регресия β
2
не е значим, той и факторът брой стаи в апартамента могат да бъдат изключени от модела.
За коефициента на регресия β
4
=2.591
дефинирани статистики  ,
,  >t cr, следователно коефициентът на регресия β
4
е значителен, той и факторът жилищна площ на апартамента могат да бъдат съхранени в модела.
>t cr, следователно коефициентът на регресия β
4
е значителен, той и факторът жилищна площ на апартамента могат да бъдат съхранени в модела.
Изводите за значимостта на коефициентите на модела се правят на ниво значимост α=5%. Имайки предвид колоната "P-стойност", имайте предвид, че свободният коефициент α може да се счита за значимо на ниво 0,64 = 64%; регресионен коефициент β 1 – на ниво 0,46 = 46%; регресионен коефициент β 2 – на ниво 0,8 = 80%; и коефициента на регресия β 4 – на ниво 2.27E-06= 2.26691790951854E-06 = 0.0000002%.
При добавяне на нови факторни променливи към уравнението коефициентът на детерминация автоматично се увеличава Р 2
и намалява средна грешкаприближения, въпреки че това не винаги подобрява качеството на модела. Следователно, за да сравним качеството на модела (3) и избрания множествен модел (6), използваме нормализираните коефициенти на определяне.
Така при добавяне на фактора „град от региона“ към уравнението на регресията х 1 и коефициента "брой стаи в апартамента" х 2 качеството на модела е влошено, което говори в полза на премахване на факторите х 1 и х 2 от модела.
Нека направим допълнителни изчисления.
Средни коефициенти на еластичност
в случай на линеен модел се определят по формулите  .
.
Използвайки функцията AVERAGE, намираме: S Y, с увеличение само на фактора х 4 за един от неговите стандартно отклонение– нараства с 0,914 С Y
Делта коефициенти
се определят с формули  .
.
Нека намерим двойните коефициенти на корелация с помощта на инструмента "Корелация" на пакета "Анализ на данни" в Excel.
| Y | X1 | X2 | X4 |
|
| Y | 1 | |||
| X1 | -0,01126 | 1 | ||
| X2 | 0,751061 | -0,0341 | 1 | |
| X4 | 0,874012 | -0,0798 | 0,868524 | 1 |
Коефициентът на детерминация е определен по-рано и е равен на 0,7677.
Нека изчислим делта коефициентите:
 ;
; 

Тъй като Δ 1 1
и х 2
избрани лошо и те трябва да бъдат премахнати от модела. Следователно, според уравнението на получения линеен трифакторен модел, промяната в резултатния фактор Y(цена на апартамент) е 104% поради влиянието на фактора х 4
(жилищна площ на апартамента), с 4% от въздействието на фактора х 2
(брой стаи), с 0.0859% от влиянието на фактора х 1
(град от обл.).
Когато се изучават сложни явления, трябва да се вземат предвид повече от два случайни фактора. Правилна представа за естеството на връзката между тези фактори може да се получи само ако всички разглеждани случайни фактори се изследват наведнъж. Съвместното изследване на три или повече случайни фактора ще позволи на изследователя да установи повече или по-малко разумни предположения за причинно-следствените връзки между изследваните явления. Проста форма на множествена връзка е линейна връзка между три характеристики. Случайните фактори се означават като х 1 , х 2 и х 3 . Коефициенти на двойна корелация между х 1 и х 2 се обозначава като r 12 , съответно между х 1 и х 3 - r 12, между х 2 и х 3 - r 23. Като мярка за плътността на линейната връзка на три признака се използват множество коефициенти на корелация, означени Р 1-23, Р 2 ּ 13, Р 3 ּ 12 и означени частични коефициенти на корелация r 12.3 , r 13.2 , r 23.1 .
Коефициентът на множествена корелация R 1.23 на три фактора е индикатор за близостта на линейната връзка между един от факторите (индексът преди точката) и комбинацията от другите два фактора (индексите след точката).
Стойностите на коефициента R винаги са в диапазона от 0 до 1. Когато R се доближи до единица, степента на линейна връзка на трите характеристики се увеличава.
Между коефициента на множествена корелация, например Р 2 ּ 13 , и две двойки корелационни коефициенти r 12 и r 23 има връзка: всеки от коефициентите на двойката не може да надвишава по абсолютна стойност Р 2 ּ 13 .
Формулите за изчисляване на множество корелационни коефициенти с известни стойности на двойните корелационни коефициенти r 12, r 13 и r 23 са:
Квадратът на коефициента на множествена корелация Р 2 се обадиха коефициент на множествена детерминация.Той показва съотношението на вариация в зависимата променлива под влиянието на изследваните фактори.
Значимостта на множествената корелация се оценява от Е- критерий:
![]()
н-размер на извадката; к-редица фактори. В нашия случай к = 3.
нулева хипотеза за равенството на коефициента на множествена корелация в популацията на нула ( h o:r=0) се приема, ако f f<f t, и се отхвърля, ако
f f ³ f T.
теоретична стойност f-критериите са определени за v 1 = к- 1 и v 2 = н - кстепени на свобода и приетото ниво на значимост a (Приложение 1).
Пример за изчисляване на коефициента на множествена корелация. При изследване на връзката между факторите са получени двойните корелационни коефициенти ( н =15): r 12 ==0,6; r 13 = 0,3; r 23 = - 0,2.
Необходимо е да се установи зависимостта на знака х 2 знак за изключване х 1 и х 3, т.е. изчислете коефициента на множествена корелация:

Таблица стойност Е-критерий при n 1 = 2 и n 2 = 15 - 3 = 12 степени на свобода при a = 0,05 Е 0,05 = 3,89 и при a = 0,01 Е 0,01 = 6,93.
По този начин връзката между характеристиките Р 2,13 = 0,74 значимо на
1% ниво на значимост Е f > Е 0,01 .
Съдейки по коефициента на множествена детерминация Р 2 = (0,74) 2 = 0,55, вариация на характеристиката х 2 е 55% свързано с ефекта на изследваните фактори, а 45% от вариацията (1-R 2) не може да се обясни с влиянието на тези променливи.
Частична линейна корелация
Частичен коефициент на корелацияе индикатор, който измерва степента на конюгиране на две характеристики.
Математическата статистика ви позволява да установите корелация между две характеристики с постоянна стойност на третата, без да създавате специален експеримент, но с помощта на сдвоени коефициенти на корелация r 12 , r 13 , r 23 .
Частичните коефициенти на корелация се изчисляват по формулите:

Цифрите преди точката показват между кои признаци се изследва зависимостта, а числото след точката показва влиянието на кой признак се изключва (елиминира). Грешката и критерият за значимост на частичната корелация се определят по същите формули, както при двойната корелация:
 .
.
теоретична стойност T-се определя критерий за v = н– 2 степени на свобода и прието ниво на значимост a (Приложение 1).
Нулевата хипотеза за равенството на частичния корелационен коефициент в съвкупността на нула ( хо: r= 0) се приема, ако T f< T t и се отхвърля, ако
T f ³ T T.
Частичните коефициенти могат да приемат стойности между -1 и +1. Частно коефициенти на определянесе намират чрез повдигане на квадрат на частичните корелационни коефициенти:
д 12.3 = r 2 12ּ3 ;д 13.2 = r 2 13ּ2 ;д 23ּ1 = r 2 23ּ1 .
Определянето на степента на конкретно въздействие на отделните фактори върху резултатната характеристика, като същевременно се изключва (елиминира) връзката й с други характеристики, които изкривяват тази корелация, често е от голям интерес. Понякога се случва, че при постоянна стойност на елиминирания признак е невъзможно да се забележи статистическият му ефект върху променливостта на други признаци. За да разберете техниката за изчисляване на частичния коефициент на корелация, разгледайте пример. Вариантите са три х, Yи З. За размер на извадката н= 180 определени двойки коефициенти на корелация
rxy = 0,799; rxz = 0,57; r yz = 0,507.
Нека дефинираме коефициентите на частична корелация:

Частичен коефициент на корелация между параметъра хи Y З (r xyz = 0.720) показва, че само малка част от връзката на тези характеристики в общата корелация ( rxy= 0,799) се дължи на влиянието на третата характеристика ( З). Подобен извод трябва да се направи и по отношение на частичния коефициент на корелация между параметъра хи параметър Зс постоянна стойност на параметъра Y (rх zּy = 0,318 и rxz= 0,57). Напротив, частичният коефициент на корелация между параметрите Yи Зс постоянна стойност на параметъра X r yz ּ х= 0,105 се различава значително от общия коефициент на корелация r z= 0,507. От това се вижда, че ако изберете обекти с еднаква стойност на параметъра х, след това връзката между характеристиките Yи Зте ще бъдат много слаби, тъй като значителна част от тази връзка се дължи на вариацията на параметъра х.
При някои обстоятелства коефициентът на частична корелация може да бъде противоположен по знак на сдвоения.
Например, когато изучавате връзката между характеристиките X, Yи З- получени са сдвоени коефициенти на корелация (с н = 100): rху = 0,6; rх z= 0,9;
r z = 0,4.
Частични коефициенти на корелация при изключване на влиянието на третия признак:

Примерът показва, че стойностите двойка коефициенти частичният коефициент на корелация се различават по знак.
Методът на частична корелация позволява да се изчисли коефициентът на частична корелация от втори ред. Този коефициент показва връзката между първия и втория признак с постоянна стойност на третия и четвъртия. Частичният коефициент от втори ред се определя въз основа на частичните коефициенти от първи ред по формулата:

където r 12 . 4 , r 13-4, r 23 ּ4 - частични коефициенти, чиято стойност се определя от формулата на частичния коефициент, като се използват двойните корелационни коефициенти r 12 , r 13 , r 14 , r 23 , r 24 , r 34 .
Регресионен анализ- Това е статистически метод за изследване, който ви позволява да покажете зависимостта на параметър от една или повече независими променливи. В предкомпютърната ера използването му е било доста трудно, особено когато става въпрос за големи количества данни. Днес, след като научихте как да изградите регресия в Excel, можете да решите сложно статистически задачибуквално след няколко минути. По-долу са конкретни примери от областта на икономиката.
Видове регресия
Самата концепция е въведена в математиката през 1886 г. Регресията се случва:
- линеен;
- параболичен;
- мощност;
- експоненциален;
- хиперболичен;
- демонстративен;
- логаритмичен.
Пример 1
Разгледайте проблема за определяне на зависимостта на броя на пенсионираните членове на екипа от средна работна заплатав 6 промишлени предприятия.
Задача. Шест предприятия са анализирали средномесечно заплатии броя на напусналите служители собствена воля. В табличен вид имаме:
Броят на напусналите хора | Заплата |
||
30 000 рубли |
|||
35 000 рубли |
|||
40 000 рубли |
|||
45 000 рубли |
|||
50 000 рубли |
|||
55 000 рубли |
|||
60 000 рубли |
За задачата за определяне на зависимостта на броя на пенсионираните работници от средната работна заплата в 6 предприятия регресионният модел има формата на уравнението Y = a 0 + a 1 x 1 +…+a k x k , където x i са влияещите променливи , a i са регресионните коефициенти, a k е броят на факторите.
За тази задача Y е индикаторът за напуснали служители, а влияещият фактор е заплатата, която означаваме с X.
Използване на възможностите на електронната таблица "Excel"
Регресионният анализ в Excel трябва да бъде предшестван от прилагане на вградени функции към наличните таблични данни. За тези цели обаче е по-добре да използвате много полезната добавка „Analysis Toolkit“. За да го активирате трябва:
- от раздела "Файл" отидете в секцията "Опции";
- в прозореца, който се отваря, изберете реда „Добавки“;
- кликнете върху бутона "Отиди", разположен в долната част, вдясно от реда "Управление";
- поставете отметка в квадратчето до името „Пакет за анализ“ и потвърдете действията си, като щракнете върху „OK“.
Ако всичко е направено правилно, желаният бутон ще се появи от дясната страна на раздела Данни, разположен над работния лист на Excel.
в Excel
Сега, когато имаме под ръка всички необходими виртуални инструменти за извършване на иконометрични изчисления, можем да започнем да решаваме нашия проблем. За това:
- кликнете върху бутона "Анализ на данни";
- в прозореца, който се отваря, кликнете върху бутона "Регресия";
- в раздела, който се появява, въведете диапазона от стойности за Y (броят служители, които са напуснали) и за X (техните заплати);
- Потвърждаваме действията си с натискане на бутона "Ok".
В резултат на това програмата автоматично ще попълни нов лист от електронната таблица с данни от регресионен анализ. Забележка! Excel има възможност ръчно да зададе местоположението, което предпочитате за тази цел. Например, може да е един и същ лист, където са стойностите Y и X, или дори нова книга, специално предназначени за съхранение на такива данни.
Анализ на резултатите от регресия за R-квадрат
В Excel данните, получени по време на обработката на данните от разглеждания пример, изглеждат така:
На първо място, трябва да обърнете внимание на стойността на R-квадрата. Това е коефициентът на детерминация. В този пример R-квадрат = 0,755 (75,5%), т.е. изчислените параметри на модела обясняват връзката между разглежданите параметри със 75,5%. Колкото по-висока е стойността на коефициента на детерминация, толкова по-приложим е избраният модел за конкретна задача. Смята се, че той правилно описва реалната ситуация със стойност на R-квадрат над 0,8. Ако R-квадрат<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Анализ на съотношението
Числото 64.1428 показва каква ще бъде стойността на Y, ако всички променливи xi в модела, който разглеждаме, са настроени на нула. С други думи, може да се твърди, че стойността на анализирания параметър се влияе и от други фактори, които не са описани в конкретен модел.
Следващият коефициент -0.16285, разположен в клетка B18, показва тежестта на влиянието на променливата X върху Y. Това означава, че средната месечна заплата на служителите в рамките на разглеждания модел влияе върху броя на напусналите с тежест -0.16285, т.е. степента на неговото влияние изобщо е малка. Знакът "-" показва, че коефициентът е с отрицателна стойност. Това е очевидно, тъй като всеки знае, че колкото по-висока е заплатата в предприятието, толкова по-малко хора изразяват желание да прекратят трудовия договор или да напуснат.
Множествена регресия
Този термин се отнася до уравнение на връзка с няколко независими променливи от формата:
y \u003d f (x 1 + x 2 + ... x m) + ε, където y е ефективната характеристика (зависима променлива), а x 1, x 2, ... x m са факторните фактори (независими променливи).
Оценка на параметъра
За множествена регресия(MR) се извършва по метода на най-малките квадрати (LSM). За линейни уравнения от формата Y = a + b 1 x 1 +…+b m x m + ε, ние конструираме система от нормални уравнения (вижте по-долу)

За да разберете принципа на метода, разгледайте двуфакторния случай. Тогава имаме ситуация, описана с формулата

От тук получаваме:

където σ е дисперсията на съответния признак, отразен в индекса.
LSM е приложим към уравнението MP в стандартизирана скала. В този случай получаваме уравнението:

където t y , t x 1, … t xm са стандартизирани променливи, за които средните стойности са 0; β i са стандартизираните регресионни коефициенти, а стандартното отклонение е 1.
Моля, имайте предвид, че всички β i в този случай са зададени като нормализирани и централизирани, така че тяхното сравнение помежду си се счита за правилно и допустимо. Освен това е обичайно да се филтрират фактори, като се изхвърлят тези с най-малки стойности на βi.
Проблем с използване на уравнение на линейна регресия
Да предположим, че има таблица с динамиката на цените на определен продукт N през последните 8 месеца. Необходимо е да се вземе решение за целесъобразността на закупуването на неговата партида на цена от 1850 рубли/т.
номер на месеца | име на месеца | цена на артикул N |
|
1750 рубли на тон |
|||
1755 рубли на тон |
|||
1767 рубли на тон |
|||
1760 рубли на тон |
|||
1770 рубли на тон |
|||
1790 рубли на тон |
|||
1810 рубли на тон |
|||
1840 рубли на тон |
|||
За да разрешите този проблем в електронната таблица на Excel, трябва да използвате инструмента за анализ на данни, който вече е известен от горния пример. След това изберете секцията "Регресия" и задайте параметрите. Трябва да се помни, че в полето "Интервал на въвеждане Y" трябва да се въведе диапазон от стойности за зависимата променлива (в случая цената на даден продукт в определени месеци от годината), а в полето "Въвеждане интервал X" - за независимата променлива (номер на месец). Потвърдете действието, като щракнете върху „Ok“. На нов лист (ако е посочено така) получаваме данни за регресия.
Въз основа на тях изграждаме линейно уравнение от вида y=ax+b, където параметрите a и b са коефициентите на реда с името на номера на месеца и коефициентите и реда „Y-пресечна“ от лист с резултатите от регресионния анализ. Така уравнението на линейната регресия (LE) за проблем 3 е написано като:
Цена на продукта N = 11.714* номер на месеца + 1727.54.
или в алгебрична нотация
y = 11,714 x + 1727,54
Анализ на резултатите
За да се реши дали полученото уравнение на линейна регресия е адекватно, се използват коефициенти на множествена корелация (MCC) и коефициенти на определяне, както и тест на Fisher и тест на Student. В таблицата на Excel с регресионни резултати те се показват съответно под имената на множество R, R-квадрат, F-статистика и t-статистика.
KMC R дава възможност да се оцени плътността на вероятностната връзка между независимите и зависимите променливи. Високата му стойност показва доста силна връзка между променливите "Номер на месеца" и "Цена на стоки N в рубли за 1 тон". Естеството на тази връзка обаче остава неизвестно.
Квадратът на коефициента на детерминация R 2 (RI) е числена характеристика на дела на общото разсейване и показва разсейването на коя част от експерименталните данни, т.е. стойностите на зависимата променлива съответстват на уравнението на линейната регресия. В разглежданата задача тази стойност е равна на 84,8%, т.е. статистическите данни се описват с висока степен на точност от полученото SD.
F-статистиката, наричана още тест на Фишер, се използва за оценка на значимостта на линейна връзка, опровергавайки или потвърждавайки хипотезата за нейното съществуване.
(Критерий на Стюдънт) помага да се оцени значимостта на коефициента с неизвестен или свободен член на линейна връзка. Ако стойността на t-критерия > t cr, тогава хипотезата за незначимостта на свободния член линейно уравнениеотхвърлени.
В разглежданата задача за свободния член с помощта на инструментите на Excel се получи, че t = 169.20903, и p = 2.89E-12, т.е. имаме нулева вероятност правилната хипотеза за незначителността на свободния член да бъде отхвърлени. За коефициента при неизвестно t=5,79405 и p=0,001158. С други думи, вероятността правилната хипотеза за незначимостта на коефициента за неизвестното да бъде отхвърлена е 0,12%.
По този начин може да се твърди, че полученото уравнение на линейна регресия е адекватно.
Проблемът за целесъобразността от закупуване на пакет от акции
Множествената регресия в Excel се извършва с помощта на същия инструмент за анализ на данни. Помислете за конкретен приложен проблем.
Ръководството на NNN трябва да вземе решение относно целесъобразността на закупуването на 20% дял в MMM SA. Цената на пакета (JV) е 70 милиона щатски долара. Специалистите на NNN събраха данни за подобни транзакции. Беше решено да се оцени стойността на пакета акции според такива параметри, изразени в милиони щатски долари, като:
- дължими сметки (VK);
- годишен оборот (VO);
- вземания (VD);
- себестойност на дълготрайните активи (SOF).
Освен това се използва параметърът просрочени задължения на предприятието (V3 P) в хиляди щатски долари.
Решение с помощта на електронна таблица на Excel
На първо място, трябва да създадете таблица с първоначални данни. Изглежда така:

- извикайте прозореца "Анализ на данни";
- изберете секцията "Регресия";
- в полето "Интервал на въвеждане Y" въведете диапазона от стойности на зависимите променливи от колона G;
- кликнете върху иконата с червена стрелка вдясно от полето "Input interval X" и изберете в листа диапазон от всички стойности от колони B,C, Д, Е.
Изберете „Нов работен лист“ и щракнете върху „Ok“.
Вземете регресионния анализ за дадения проблем.

Разглеждане на резултатите и заключения
„Ние събираме“ от закръглените данни, представени по-горе в електронната таблица на Excel, регресионното уравнение:
SP \u003d 0,103 * SOF + 0,541 * VO - 0,031 * VK + 0,405 * VD + 0,691 * VZP - 265.844.
В по-позната математическа форма може да се запише като:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Данните за АД "МММ" са представени в таблицата:
Замествайки ги в регресионното уравнение, те получават цифра от 64,72 милиона щатски долара. Това означава, че акциите на АД МММ не трябва да се купуват, тъй като тяхната стойност от 70 милиона щатски долара е доста завишена.
Както можете да видите, използването на електронната таблица на Excel и регресионното уравнение направи възможно вземането на информирано решение относно осъществимостта на много специфична транзакция.
Сега знаете какво е регресия. Обсъдените по-горе примери в Excel ще ви помогнат да решите. практически задачиот областта на иконометрията.
