Биномен закон на разпределение. Биномиално разпределение
За разлика от нормалните и равномерни разпределенияописвайки поведението на променлива в извадката от изследвани субекти, биномното разпределение се използва за други цели. Той служи за прогнозиране на вероятността от две взаимно изключващи се събития в определен брой независими опити. Класически пример за биномно разпределение е хвърлянето на монета, която пада върху твърда повърхност. Два изхода (събития) са еднакво вероятни: 1) монетата пада „орел“ (вероятността е равна на Р) или 2) монетата пада „опашки“ (вероятността е равна на р). Ако не е даден трети резултат, тогава стр = р= 0,5 и стр + р= 1. Използвайки формулата за биномно разпределение, можете да определите например каква е вероятността при 50 опита (броя хвърляния на монети) последният да падне глави, да речем, 25 пъти.
За по-нататъшни разсъждения въвеждаме общоприетата нотация:
н – общ бройнаблюдения;
аз- броя на събитията (резултатите), които ни интересуват;
н – аз– брой алтернативни събития;
стр- емпирично определена (понякога - предполагаема) вероятност за събитие, което ни интересува;
ре вероятността от алтернативно събитие;
Пн ( аз) е предвидената вероятност за събитието, което ни интересува азза определен брой наблюдения н.
Формула за биномно разпределение:
В случай на равновероятен изход от събития ( p = q) можете да използвате опростената формула:
![]() (6.8)
(6.8)
Нека разгледаме три примера, илюстриращи използването на формули за биномно разпределение в психологически изследвания.
Пример 1
Да приемем, че 3 ученика решават задача с повишена сложност. За всяка от тях са еднакво вероятни 2 изхода: (+) - решение и (-) - нерешение на задачата. Възможни са общо 8 различни изхода (2 3 = 8).
Вероятността нито един ученик да не се справи със задачата е 1/8 (вариант 8); 1 ученик ще изпълни задачата: П= 3/8 (варианти 4, 6, 7); 2 ученика - П= 3/8 (варианти 2, 3, 5) и 3 ученика – П=1/8 (вариант 1).
Необходимо е да се определи вероятността трима от 5 ученици да се справят успешно с тази задача.
Решение
Общо възможни резултати: 2 5 = 32.
Общият брой опции 3(+) и 2(-) е

Следователно вероятността за очаквания резултат е 10/32 » 0,31.
Пример 3
Упражнение
Определете вероятността 5 екстроверта да бъдат намерени в група от 10 произволни субекта.
Решение
1. Въведете обозначението: p=q= 0,5; н= 10; i = 5; P 10 (5) = ?
2. Използваме опростена формула (вижте по-горе):
Заключение
Вероятността 5 екстроверта да бъдат намерени сред 10 произволни субекта е 0,246.
Бележки
1. Изчисляване по формула за достатъчно големи числатестовете са доста трудоемки, така че в тези случаи се препоръчва използването на биномиални таблици за разпределение.
2. В някои случаи стойностите стри рможе да се зададе първоначално, но не винаги. По правило те се изчисляват въз основа на резултатите от предварителните тестове (пилотни проучвания).
3. В графично изображение(в координати P n(аз) = f(аз)) биномното разпределение може да има различен вид: кога p = qразпределението е симетрично и наподобява нормалното разпределение на Гаус; неравномерността на разпределението е по-голяма от повече разликамежду вероятностите стри р.
Поасоново разпределение
Разпределението на Поасон е специален случай на биномното разпределение, използвано, когато вероятността от интересни събития е много ниска. С други думи, това разпределение описва вероятността от редки събития. Формулата на Поасон може да се използва за стр < 0,01 и р ≥ 0,99.
Уравнението на Поасон е приблизително и се описва със следната формула:
![]() (6.9)
(6.9)
където μ е произведението средна вероятностсъбития и брой наблюдения.
Като пример разгледайте алгоритъма за решаване на следния проблем.
Задачата
В продължение на няколко години в 21 големи клиники в Русия се провежда масово изследване на новородени за заболяването на бебета с болестта на Даун (пробата е средно 1000 новородени във всяка клиника). Получени са следните данни:
Упражнение
1. Определете средната вероятност от заболяването (по отношение на броя на новородените).
2. Определете средния брой новородени с едно заболяване.
3. Определете вероятността сред 100 произволно избрани новородени да има 2 бебета с болестта на Даун.
Решение
1. Определете средната вероятност от заболяването. При това трябва да се ръководим от следното разсъждение. От 21 клиники болестта на Даун е регистрирана само в 10. В 11 клиники няма открити заболявания, в 6 клиники е регистриран 1 случай, в 2 клиники 2 случая, в 1-ва клиника - 3 и в 1-ва клиника - 4 случая. 5 случая не са открити в нито една клиника. За да се определи средната вероятност от заболяването, е необходимо общият брой на случаите (6 1 + 2 2 + 1 3 + 1 4 = 17) да се раздели на общия брой новородени (21 000):
![]()
2. Броят на новородените за едно заболяване е реципрочната стойност на средната вероятност, т.е. равен на общия брой новородени, разделен на броя на регистрираните случаи:
![]()
3. Заменете стойностите стр = 0,00081, н= 100 и аз= 2 във формулата на Поасон:
Отговор
Вероятността сред 100 произволно избрани новородени да бъдат открити 2 бебета с болест на Даун е 0,003 (0,3%).
Свързани задачи
Задача 6.1
Упражнение
Използвайки данните от задача 5.1 за времето на сензомоторната реакция, изчислете асиметрията и ексцеса на разпределението на VR.
Задача 6. 2
200 дипломирани студенти бяха тествани за нивото на интелигентност ( IQ). След нормализиране на полученото разпределение IQспоред стандартното отклонение са получени следните резултати:
Упражнение
Използвайки тестовете на Колмогоров и хи-квадрат, определете дали полученото разпределение на индикаторите съответства на IQнормално.
Задача 6. 3
При възрастен субект (25-годишен мъж) е изследвано времето на проста сензомоторна реакция (SR) в отговор на звуков стимул с постоянна честота 1 kHz и интензитет 40 dB. Стимулът беше представен сто пъти на интервали от 3–5 секунди. Индивидуалните VR стойности за 100 повторения бяха разпределени както следва:
Упражнение
1. Построяване на честотна хистограма на разпределението на VR; определяне на средната стойност на VR и стойността на стандартното отклонение.
2. Изчислете коефициента на асиметрия и ексцеса на разпределението на BP; въз основа на получените стойности Катои Прнаправете заключение за съответствието или несъответствието на това разпределение с нормалното.
Задача 6.4
През 1998 г. 14 души (5 момчета и 9 момичета) завършват училища в Нижни Тагил със златни медали, 26 души (8 момчета и 18 момичета) със сребърни медали.
Въпрос
Може ли да се каже, че момичетата получават медали по-често от момчетата?
Забележка
Съотношението на броя на момчетата и момичетата в населениесмятат за равни.
Задача 6.5
Смята се, че броят на екстровертите и интровертите в хомогенна група субекти е приблизително еднакъв.
Упражнение
Определете вероятността в група от 10 произволно избрани субекта да се намерят 0, 1, 2, ..., 10 екстроверти. Конструирайте графичен израз за разпределението на вероятността за намиране на 0, 1, 2, ..., 10 екстроверти в дадена група.
Задача 6.6
Упражнение
Изчислете вероятността P n(i) функции на биномно разпределение за стр= 0,3 и р= 0,7 за стойности н= 5 и аз= 0, 1, 2, ..., 5. Постройте графичен израз на зависимостта P n(i) = f(i) .
Задача 6.7
AT последните годинисред определена част от населението се утвърждава вярата в астрологичните прогнози. Според резултатите от предварителните проучвания е установено, че около 15% от населението вярва в астрологията.
Упражнение
Определете вероятността сред 10 произволно избрани респонденти да има 1, 2 или 3 души, които вярват в астрологичните прогнози.
Задача 6.8
Задачата
На 42 общообразователни училищаЕкатеринбург и Свердловска област (общ брой студенти 12260 души) в продължение на няколко години следващото числослучаи на психични заболявания сред ученици:
Упражнение
Нека да се прегледат 1000 ученици на случаен принцип. Изчислете каква е вероятността сред тези хиляда ученици да се открият 1, 2 или 3 психично болни деца?
РАЗДЕЛ 7. МЕРКИ ЗА РАЗЛИКА
Формулиране на проблема
Да предположим, че имаме две независими извадки от субекти хи при. Независимпробите се броят, когато един и същ субект (субект) се появява само в една проба. Задачата е да се сравнят тези проби (два набора от променливи) една с друга за техните разлики. Естествено, колкото и близки да са стойностите на променливите в първата и втората извадка, някои, макар и незначителни, разлики между тях ще бъдат открити. От същата гледна точка математическа статистикаинтересуваме се от въпроса дали разликите между тези извадки са статистически значими (статистически значими) или незначими (случайни).
Най-често срещаните критерии за значимостта на разликите между извадките са параметричните мерки на разликите - Критерий на ученикаи Критерий на Фишер. В някои случаи се използват непараметрични критерии - Q тест на Розенбаум, U-тест Мана Уитни и други. Ъглова трансформация на Фишер φ*, които ви позволяват да сравнявате стойности, изразени като проценти (проценти) една с друга. И накрая, като специален случай, за сравняване на проби могат да се използват критерии, които характеризират формата на разпределенията на извадката - критерий χ 2 Pearsonи критерий λ Колмогоров – Смирнов.
За да разберем по-добре тази тема, ще продължим по следния начин. Ще решим един и същ проблем с четири метода, като използваме четири различни критерия - Розенбаум, Ман-Уитни, Стюдънт и Фишер.
Задачата
30 ученици (14 момчета и 16 момичета) по време на изпитната сесия бяха тествани съгласно теста на Спилбъргер за нивото на реактивна тревожност. Бяха получени следните резултати (Таблица 7.1):
Таблица 7.1
| Предмети | Ниво на реактивна тревожност | |||||||||||||||
| Младежи | ||||||||||||||||
| момичета |
Упражнение
Да се установи дали разликите в нивото на реактивна тревожност при момчета и момичета са статистически значими.
Задачата изглежда доста типична за психолог, специализиран в областта на образователна психология: кой изпитва по-остро стреса от изпитите - момчетата или момичетата? Ако разликите между извадките са статистически значими, то в този аспект има значителни различия между половете; ако разликите са случайни (не са статистически значими), това предположение трябва да се отхвърли.
7. 2. Непараметричен тест QРозенбаум
Q-Критерият на Розенбаум се основава на сравнението на "насложени" един върху друг класирани серии от стойности на две независими променливи. В същото време не се анализира характерът на разпределението на признака във всеки ред - в този случай има значение само ширината на неприпокриващите се участъци на двата класирани реда. Когато сравнявате две класирани серии от променливи една с друга, са възможни 3 опции:
1. Класирани рангове хи гнямат област на припокриване, т.е. всички стойности на първата класирана серия ( х) е по-голямо от всички стойности на втората класирана серия ( г):
В този случай разликите между извадките, определени от който и да е статистически критерий, със сигурност са значителни и не се изисква използването на критерия на Розенбаум. На практика обаче тази опция е изключително рядка.
2. Класираните редове се припокриват напълно (по правило единият ред е вътре в другия), няма незастъпващи се зони. В този случай критерият на Розенбаум не е приложим.

3. Има припокриваща се област на редовете, както и две неприпокриващи се области ( N 1и N 2) свързан с различнокласирани серии (означаваме х- ред, изместен към голям, г- в посока на по-ниски стойности):

Този случай е типичен за използването на критерия на Розенбаум, при който трябва да се спазват следните условия:
1. Обемът на всяка проба трябва да бъде най-малко 11.
2. Размерите на пробите не трябва да се различават значително един от друг.
Критерий Q Rosenbaum съответства на броя на неприпокриващите се стойности: Q = н 1 +н 2 . Заключението за надеждността на разликите между пробите се прави, ако Q > Qкр . В същото време ценностите Q cr са в специални таблици (виж Приложение, Таблица VIII).
Да се върнем към нашата задача. Нека въведем обозначението: х- селекция от момичета, г- Избор на момчета. За всяка проба изграждаме класирана серия:
х: 28 30 34 34 35 36 37 39 40 41 42 42 43 44 45 46
г: 26 28 32 32 33 34 35 38 39 40 41 42 43 44
Преброяваме броя на стойностите в неприпокриващи се области на класираната серия. В един ред хстойностите 45 и 46 не се припокриват, т.е. н 1 = 2; в ред гсамо 1 стойност без припокриване 26 т.е. н 2 = 1. Следователно, Q = н 1 +н 2 = 1 + 2 = 3.
В табл. VIII Приложение откриваме, че Qкр . = 7 (за ниво на значимост 0,95) и Q cr = 9 (за ниво на значимост 0,99).
Заключение
Тъй като Q<Q cr, тогава според критерия на Розенбаум разликите между пробите не са статистически значими.
Забележка
Тестът на Розенбаум може да се използва независимо от естеството на разпределението на променливите, т.е. в този случай не е необходимо да се използват χ 2 на Пиърсън и λ тестовете на Колмогоров, за да се определи типа на разпределението в двете проби.
7. 3. U- Тест на Ман-Уитни
За разлика от критерия на Розенбаум, UТестът на Ман-Уитни се основава на определяне на зоната на припокриване между два класирани реда, т.е. колкото по-малка е зоната на припокриване, толкова по-значими са разликите между пробите. За целта се използва специална процедура за преобразуване на интервални скали в рангови скали.
Нека разгледаме алгоритъма за изчисление за U-критерий по примера на предходната задача.
Таблица 7.2
| x, y | Р xy | Р xy * | Рх | Рг |
| 26 28 32 32 33 34 35 38 39 40 41 42 43 44 | 2,5 2,5 5,5 5,5 11,5 11,5 16,5 16,5 18,5 18,5 20,5 20,5 25,5 25,5 27,5 27,5 | 2,5 11,5 16,5 18,5 20,5 25,5 27,5 | 1 2,5 5,5 5,5 7 9 11,5 15 16,5 18,5 20,5 23 25,5 27,5 | |
| Σ | 276,5 | 188,5 |
1. Създаваме една класирана серия от две независими проби. В този случай стойностите за двете проби се смесват, колона 1 ( х, г). За да се опрости по-нататъшната работа (включително в компютърната версия), стойностите за различните проби трябва да бъдат маркирани с различни шрифтове (или различни цветове), като се има предвид фактът, че в бъдеще ще ги публикуваме в различни колони.
2. Преобразувайте интервалната скала на стойностите в порядъчна (за да направите това, преозначаваме всички стойности с номера на ранг от 1 до 30, колона 2 ( Р xy)).
3. Въвеждаме корекции за свързани рангове (същите стойности на променливата се обозначават със същия ранг, при условие че сумата от ранговете не се променя, колона 3 ( Р xy *). На този етап се препоръчва да се изчислят сумите на ранговете във 2-ра и 3-та колона (ако всички корекции са правилни, тогава тези суми трябва да са равни).
4. Разпределяме номерата на ранга в съответствие с принадлежността им към определена проба (колони 4 и 5 ( Р x и Р y)).
5. Извършваме изчисления по формулата:
![]() (7.1)
(7.1)
където T x е най-голямата от ранговите суми ; н x и н y , съответно размерите на извадката. В този случай имайте предвид, че ако Tх< T y , след това нотацията хи гтрябва да се обърне.
6. Сравнете получената стойност с табличната (вижте приложенията, таблица IX) Заключението за достоверността на разликите между двете проби се прави, ако Uексп.< Uкр. .
В нашия пример ![]() Uексп. = 83,5 > U кр. = 71.
Uексп. = 83,5 > U кр. = 71.
Заключение
Разликите между двете проби според теста на Ман-Уитни не са статистически значими.
Бележки
1. Тестът на Ман-Уитни практически няма ограничения; минималните размери на сравняваните извадки са 2 и 5 души (виж таблица IX от приложението).
2. Подобно на теста на Розенбаум, тестът на Ман-Уитни може да се използва за всякакви проби, независимо от естеството на разпределението.
Критерий на ученика
За разлика от критериите на Розенбаум и Ман-Уитни, критерият TМетодът на Студент е параметричен, т.е. въз основа на определянето на основните статистически показатели - средните стойности във всяка извадка ( и ) и техните дисперсии (s 2 x и s 2 y), изчислени по стандартни формули (виж Раздел 5).
Използването на критерия на Стюдънт предполага следните условия:
1. Разпределението на стойностите за двете проби трябва да е в съответствие със закона нормална дистрибуция(вижте раздел 6).
2. Общият обем на пробите трябва да бъде най-малко 30 (за β 1 = 0,95) и поне 100 (за β 2 = 0,99).
3. Обемите на две проби не трябва да се различават значително един от друг (не повече от 1,5 ÷ 2 пъти).
Идеята на критерия на Студент е доста проста. Да предположим, че стойностите на променливите във всяка от пробите са разпределени според нормален закон, т.е. имаме работа с две нормални разпределения, които се различават едно от друго по средни стойности и дисперсия (съответно и , и , виж фиг. 7.1).

с хс г
Ориз. 7.1. Оценка на разликите между две независими проби: и - средни стойности на пробите хи г; s x и s y - стандартни отклонения
Лесно е да се разбере, че разликите между две проби ще бъдат толкова по-големи, колкото по-голяма е разликата между средните стойности и колкото по-малки са техните дисперсии (или стандартни отклонения).
При независими извадки коефициентът на Стюдънт се определя по формулата:
 (7.2)
(7.2)
където н x и н y - съответно броят на пробите хи г.
След изчисляване на коефициента на Студент в таблицата със стандартни (критични) стойности T(вижте Приложение, Таблица X) намерете стойността, съответстваща на броя на степените на свобода n = n x + н y - 2 и го сравнете с изчисленото по формулата. Ако Tексп. £ Tкр. , тогава хипотезата за надеждността на разликите между извадките се отхвърля, ако Tексп. > Tкр. , тогава се приема. С други думи, извадките се различават значително една от друга, ако изчисленият по формулата коефициент на Стюдънт е по-голям от табличната стойност за съответното ниво на значимост.
В проблема, който разгледахме по-рано, изчисляването на средните стойности и дисперсии дава следните стойности: хвж. = 38,5; σ x 2 = 28,40; привж. = 36,2; σ y 2 = 31,72.
Вижда се, че средната стойност на тревожност в групата на момичетата е по-висока, отколкото в групата на момчетата. Тези разлики обаче са толкова малки, че е малко вероятно да бъдат статистически значими. Разсейването на стойностите при момчетата, напротив, е малко по-високо, отколкото при момичетата, но разликите между дисперсиите също са малки.

Заключение
Tексп. = 1,14< Tкр. = 2,05 (β1 = 0,95). Разликите между двете сравнявани проби не са статистически значими. Това заключение е напълно съвместимо с това, получено с помощта на критериите на Розенбаум и Ман-Уитни.
Друг начин за определяне на разликите между две проби с помощта на t-теста на Student е да се изчисли доверителният интервал на стандартните отклонения. Доверителният интервал е средното квадратно (стандартно) отклонение, разделено на корен квадратен от размера на извадката и умножено по стандартната стойност на коефициента на Стюдънт за н– 1 степени на свобода (съответно и ).
Забележка
Стойност = m xсе нарича средна квадратична грешка (вижте раздел 5). Следователно доверителният интервал е стандартната грешка, умножена по коефициента на Стюдънт за даден размер на извадката, където броят на степените на свобода ν = н- 1 и за дадено нивозначимост.
Две проби, които са независими една от друга, се считат за значително различни, ако доверителни интервалитъй като тези проби не се припокриват една с друга. В нашия случай имаме 38,5 ± 2,84 за първата проба и 36,2 ± 3,38 за втората.
Следователно, случайни вариации x iлежат в диапазона 35,66 ¸ 41,34 и вариации y i- в диапазона 32.82 ¸ 39.58. Въз основа на това може да се каже, че разликите между пробите хи гстатистически ненадеждни (диапазони от вариации се припокриват един с друг). В този случай трябва да се има предвид, че ширината на зоната на припокриване в този случай няма значение (важен е само самият факт на припокриване на доверителните интервали).
Методът на Студент за взаимозависими проби (например за сравняване на резултатите, получени от многократно тестване на една и съща извадка от субекти) се използва доста рядко, тъй като има други, по-информативни методи за тези цели. статистически трикове(вижте раздел 10). За тази цел обаче, като първо приближение, можете да използвате формулата на Студент със следната форма:
 (7.3)
(7.3)
Полученият резултат се сравнява с табличната стойност за н– 1 степен на свобода, където н– брой двойки стойности хи г. Резултатите от сравнението се интерпретират точно по същия начин, както в случая на изчисляване на разликите между две независими проби.
Критерий на Фишер
Критерий на Фишер ( Е) се основава на същия принцип като t-теста на Стюдънт, т.е. включва изчисляване на средни стойности и дисперсии в сравняваните проби. Най-често се използва при сравняване на проби, които са различни по размер (различни по размер) една с друга. Тестът на Fisher е малко по-строг от теста на Student и следователно е по-предпочитан в случаите, когато има съмнения относно надеждността на разликите (например, ако според теста на Student разликите са значими при нула и не са значими при първата значимост ниво).
Формулата на Фишер изглежда така:
 (7.4)
(7.4)
където и  (7.5, 7.6)
(7.5, 7.6)
В нашия проблем d2= 5,29; σz 2 = 29,94.
Заменете стойностите във формулата: ![]()
В табл. XI Приложения установяваме, че за нивото на значимост β 1 = 0,95 и ν = н x + н y - 2 = 28 критичната стойност е 4,20.
Заключение
Е = 1,32 < F кр.= 4,20. Разликите между извадките не са статистически значими.
Забележка
Когато използвате теста на Фишер, трябва да бъдат изпълнени същите условия, както за теста на Стюдънт (вижте подраздел 7.4). Въпреки това се допуска разлика в броя на пробите повече от два пъти.
Така при решаване на същата задача с четири различни методиизползвайки два непараметрични и два параметрични критерия, стигнахме до недвусмислен извод, че разликите между групата момичета и групата момчета по отношение на нивото на реактивна тревожност са недостоверни (т.е. те са в диапазона на случайните вариации) ). Възможно е обаче да има случаи, когато не е възможно да се направи недвусмислено заключение: някои критерии дават надеждни, други - ненадеждни разлики. В тези случаи се дава приоритет на параметричните критерии (в зависимост от достатъчността на размера на извадката и нормалното разпределение на изследваните стойности).
7. 6. Критерий j* - Ъглова трансформация на Фишер
Критерият j*Fisher е предназначен за сравняване на две проби според честотата на възникване на ефекта, който представлява интерес за изследователя. Той оценява значимостта на разликите между процентите на две извадки, в които е регистриран интересният ефект. Допуска се също сравнение на проценти в една и съща извадка.
Същността на ъгловата трансформация на Фишер е превръщането на проценти в централни ъгли, които се измерват в радиани. По-голям процент ще съответства на по-голям ъгъл й, а по-малък дял - по-малък ъгъл, но връзката тук е нелинейна:
![]()
където Р– процент, изразен в части от единица.
С увеличаване на несъответствието между ъглите j 1 и j 2 и увеличаване на броя на пробите, стойността на критерия се увеличава.
Критерият на Фишер се изчислява по следната формула:
| |
където j 1 е ъгълът, съответстващ на по-големия процент; j 2 - ъгълът, съответстващ на по-малък процент; н 1 и н 2 - съответно обемът на първата и втората проба.
Изчислената по формулата стойност се сравнява със стандартната стойност (j* st = 1,64 за b 1 = 0,95 и j* st = 2,31 за b 2 = 0,99. Разликите между двете проби се считат за статистически значими, ако j*> j* st за дадено ниво на значимост.
Пример
Интересуваме се дали двете групи ученици се различават една от друга по отношение на успеха на изпълнението на доста сложна задача. В първата група от 20 души се справиха 12 ученици, във втората - 10 души от 25.
Решение
1. Въведете обозначението: н 1 = 20, н 2 = 25.
2. Изчислете проценти Р 1 и Р 2: Р 1 = 12 / 20 = 0,6 (60%), Р 2 = 10 / 25 = 0,4 (40%).
3. В табл. XII Приложения, намираме стойностите на φ, съответстващи на проценти: j 1 = 1.772, j 2 = 1.369.
| |
Оттук:
Заключение
Разликите между групите не са статистически значими, защото j*< j* ст для 1-го и тем более для 2-го уровня значимости.
7.7. Използване на χ2 теста на Пиърсън и λ теста на Колмогоров
Вероятностни разпределения на дискретни случайни променливи. Биномиално разпределение. Поасоново разпределение. Геометрично разпределение. генерираща функция.
6. Вероятностни разпределения на дискретни случайни променливи
6.1. Биномиално разпределение
Нека се произвежда ннезависими изпитания, във всяко от които събитие Аможе или не може да се появи. Вероятност стрнастъпване на събитие Авъв всички тестове е постоянен и не се променя от тест на тест. Разгледайте като случайна променлива X броя на случванията на събитието Ав тези тестове. Формула за намиране на вероятността за възникване на събитие Агладка кведнъж нтестове, както е известно, е описано Формула на Бернули
Разпределението на вероятностите, определено от формулата на Бернули, се нарича бином .
Този закон се нарича "бином", защото дясната страна може да се разглежда като общ термин в разширяването на бинома на Нютон
Записваме биномния закон под формата на таблица
|
стр н |
np н –1 р |
|
р н |

Нека намерим числените характеристики на това разпределение.
По дефиниция математическо очакванеза DSW имаме
 .
.
Нека запишем равенството, което е Нютонов бин
 .
.
и го разграничете по отношение на p. В резултат на това получаваме
 .
.
Умножете левия и правилната странана стр:
 .
.
Като се има предвид това стр+ р=1, имаме
 (6.2)
(6.2)
Така, математическо очакване на броя на събитията вннезависими опити е равен на произведението от броя на опититенна вероятносттастрнастъпване на събитие във всеки опит.
Изчисляваме дисперсията по формулата
 .
.
За това намираме
 .
.
Първо, диференцираме биномната формула на Нютон два пъти по отношение на стр:

и умножете двете страни на уравнението по стр 2:

Следователно,
Така че дисперсията на биномното разпределение е
 .
(6.3)
.
(6.3)
Тези резултати могат да бъдат получени и чрез чисто качествено разсъждение. Общите X повторения на събитие А във всички опити се добавят към броя на появяванията на събитието в отделните опити. Следователно, ако X 1 е броят на появяванията на събитието в първия опит, X 2 във втория и т.н., тогава общият брой на случванията на събитие A във всички опити е X=X 1 +X 2 +…+ х н. Според свойството на математическото очакване:
Всеки от членовете от дясната страна на равенството е математическото очакване на броя на събитията в един тест, което е равно на вероятността на събитието. По този начин,
Според свойството на дисперсия:
Тъй като , и математическото очакване на случайна променлива  , което може да приема само две стойности, а именно 1 2 с вероятност стри 0 2 с вероятност р, тогава
, което може да приема само две стойности, а именно 1 2 с вероятност стри 0 2 с вероятност р, тогава  . По този начин,
. По този начин,  В резултат на това получаваме
В резултат на това получаваме
Използвайки концепцията за начален и централен момент, можете да получите формули за изкривяване и ексцес:
 .
(6.4)
.
(6.4)

Ориз. 6.1
Многоъгълникът на биномното разпределение има следната форма (виж фиг. 6.1). Вероятност П н (к) първо нараства с увеличаване к, достига най-голямата стойности след това започва да намалява. Биномиалното разпределение е изкривено с изключение на случая стр=0,5. Имайте предвид, че за голям брой тестове нбиномното разпределение е много близко до нормалното. (Обосновката за това предложение е свързана с местната теорема на Moivre-Laplace.)Номерм 0 настъпване на събитие се наричанай-вероятно , ако вероятността събитието да се случи определен брой пъти в тази поредица от опити е най-голямата (максимум в полигона на разпределение). За биномно разпределение
Коментирайте. Това неравенство може да се докаже с помощта на рекурентната формула за биномни вероятности:
 (6.6)
(6.6)
Пример 6.1.Делът на първокласните продукти в това предприятие е 31%. Каква е средната стойност и дисперсията, също и най-вероятният брой първокласни артикули в произволно избрана партида от 75 артикула?
Решение. Тъй като стр=0,31, р=0,69, н=75, тогава
М[ х] = np= 750,31 = 23,25; Д[ х] = npq = 750,310,69 = 16,04.
За да намерите най-вероятното число м 0 , съставяме двойно неравенство
Оттук следва, че м 0 = 23.
Биномиалното разпределение е едно от най-важните вероятностни разпределения за дискретно променяща се случайна променлива. Биномиалното разпределение е вероятностното разпределение на число мсъбитие НОв нвзаимно независими наблюдения. Често събитие НОсе нарича "успех" на наблюдението, а обратното събитие - "неуспех", но това обозначение е много условно.
Членове на биномното разпределение:
- извършено общо низпитания, при които събитието НОможе или не може да се случи;
- събитие НОвъв всяко от изпитанията може да се случи с еднаква вероятност стр;
- тестовете са взаимно независими.
Вероятността, че в нтестово събитие НОточно мпъти, може да се изчисли с помощта на формулата на Бернули:
![]()
![]() ,
,
където стр- вероятността за настъпване на събитието НО;
р = 1 - стре вероятността да се случи противоположното събитие.
Нека да го разберем защо биномното разпределение е свързано с формулата на Бернули по описания по-горе начин . Събитие - броят на успехите при нтестовете е разделен на няколко варианта, във всеки от които се постига успех мизпитания, а неуспех - в н - мтестове. Помислете за една от тези опции - б1 . Съгласно правилото за добавяне на вероятности, ние умножаваме вероятностите за противоположни събития:
![]() ,
,
и ако обозначим р = 1 - стр, тогава
![]() .
.
Същата вероятност ще има всяка друга опция, в която муспех и н - мнеуспехи. Броят на тези опции е равен на броя на начините, по които е възможно от нтест получите муспех.
Сумата от вероятностите за всички мномер на събитието НО(цифри от 0 до н) е равно на едно:
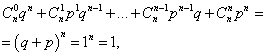
където всеки член е член на бинома на Нютон. Следователно разглежданото разпределение се нарича биномно разпределение.
На практика често е необходимо да се изчисляват вероятностите "най-много муспех в нтестове" или "поне муспех в нтестове". За това се използват следните формули.
Интегралната функция, т.е вероятност Е(м), че в нсъбитие за наблюдение НОняма да дойде повече мведнъж, може да се изчисли по формулата:
На свой ред вероятност Е(≥м), че в нсъбитие за наблюдение НОела поне мведнъж, се изчислява по формулата:
Понякога е по-удобно да се изчисли вероятността, че в нсъбитие за наблюдение НОняма да дойде повече мпъти, чрез вероятността от обратното събитие:
![]() .
.
Коя от формулите да се използва зависи от това коя от тях съдържа по-малко членове.
Характеристиките на биномното разпределение се изчисляват по следните формули .
Очаквана стойност: .
дисперсия: .
Стандартно отклонение: .
Биномно разпределение и изчисления в MS Excel
Вероятност на биномно разпределение Пн ( м) и стойността на интегралната функция Е(м) може да се изчисли с помощта на функцията на MS Excel BINOM.DIST. Прозорецът за съответното изчисление е показан по-долу (кликнете с левия бутон на мишката, за да го увеличите).

MS Excel изисква да въведете следните данни:
- брой успехи;
- брой тестове;
- вероятност за успех;
- интеграл - логическа стойност: 0 - ако трябва да изчислите вероятността Пн ( м) и 1 - ако вероятността Е(м).
Пример 1Управителят на компанията обобщи информация за броя на продадените фотоапарати през последните 100 дни. Таблицата обобщава информацията и изчислява вероятностите за деня да бъде продаден определен бройкамери.
Денят завършва с печалба, ако се продадат 13 или повече камери. Вероятността денят да приключи с печалба:
![]()
Вероятността денят да бъде отработен без печалба:

Нека вероятността денят да бъде изработен с печалба да е постоянна и равна на 0,61, а броят на продадените камери на ден не зависи от деня. След това можете да използвате биномното разпределение, където събитието НО- денят ще бъде изработен с печалба, - без печалба.
Вероятността от 6 дни всички да бъдат изработени с печалба:
![]() .
.
Получаваме същия резултат с помощта на функцията на MS Excel BINOM.DIST (стойността на интегралната стойност е 0):
П 6 (6 ) = BINOM.DIST(6; 6; 0,61; 0) = 0,052.
Вероятността от 6 дни 4 или повече дни да бъдат отработени с печалба:
където ![]() ,
,
![]() ,
,
Използвайки функцията на MS Excel BINOM.DIST, изчисляваме вероятността от 6 дни не повече от 3 дни да бъдат завършени с печалба (стойността на интегралната стойност е 1):
П 6 (≤3 ) = BINOM.DIST(3; 6; 0,61; 1) = 0,435.
Вероятността от 6 дни всички да бъдат отработени със загуби:
![]() ,
,
Изчисляваме същия индикатор с помощта на функцията на MS Excel BINOM.DIST:
П 6 (0 ) = BINOM.DIST(0; 6; 0,61; 0) = 0,0035.
Решете проблема сами и след това вижте решението
Пример 2Една урна съдържа 2 бели топки и 3 черни. От урната се изважда топка, цветът се настройва и се връща обратно. Опитът се повтаря 5 пъти. Броят на появяванията на белите топки - дискретно произволна стойност х, разпределени по биномния закон. Съставете закона за разпределение на случайна променлива. Определете модата, математическото очакване и дисперсията.
Продължаваме да решаваме проблемите заедно
Пример 3От куриерската служба отиде до обектите н= 5 куриера. Всеки куриер с вероятност стр= 0.3 закъснява за обекта независимо от останалите. Дискретна случайна променлива х- броят на закъснелите куриери. Постройте серия на разпределение на тази случайна променлива. Намерете неговото математическо очакване, дисперсия, стандартно отклонение. Намерете вероятността поне двама куриери да закъснеят за предметите.
Разгледайте биномното разпределение, изчислете математическото му очакване, дисперсия, режим. Използвайки функцията на MS EXCEL BINOM.DIST(), ще начертаем графиките на функцията на разпределението и плътността на вероятността. Нека оценим параметъра на разпределението p, математическото очакване на разпределението и стандартното отклонение. Също така разгледайте разпределението на Бернули.
Определение. Нека се държат нтестове, във всеки от които могат да възникнат само 2 събития: събитието "успех" с вероятност стр или събитието "провал" с вероятността р =1-p (т.нар схема на Бернули,Бернулиизпитания).
Вероятност да получите точно х успех в тези н тестове е равно на:
Брой успехи в извадката х е случайна променлива, която има Биномиално разпределение(Английски) Биномразпространение) стри н– са параметри на това разпределение.
Спомнете си това, за да кандидатствате Схеми на Бернулии съответно биномно разпределение,трябва да бъдат изпълнени следните условия:
- всяко изпитание трябва да има точно два резултата, условно наречени „успех” и „неуспех”.
- резултатът от всеки тест не трябва да зависи от резултатите от предишни тестове (независимост на теста).
- успеваемост стр трябва да бъде постоянно за всички тестове.
Биномиално разпределение в MS EXCEL
В MS EXCEL, като се започне от версия 2010, за Биномиално разпределениеима функция BINOM.DIST() , английско име- BINOM.DIST(), което ви позволява да изчислите вероятността извадката да бъде точна х"успехи" (т.е. функция на плътността на вероятността p(x), вижте формулата по-горе), и интегрална функция на разпределение(вероятност пробата да има хили по-малко "успехи", включително 0).
Преди MS EXCEL 2010, EXCEL имаше функцията BINOMDIST(), която също ви позволява да изчислявате разпределителна функцияи плътност на вероятността p(x). BINOMDIST() е оставен в MS EXCEL 2010 за съвместимост.
Примерният файл съдържа графики плътност на разпределение на вероятноститеи .

Биномиално разпределениеима обозначението б(н; стр) .
Забележка: За застрояване интегрална функция на разпределениеперфектен тип диаграма График, за плътност на разпространение – Хистограма с групиране. За повече информация относно изграждането на диаграми прочетете статията Основните типове диаграми.
Забележка: За удобство при писане на формули в примерния файл са създадени имена за параметри Биномиално разпределение: n и p.

Примерният файл показва различни вероятностни изчисления с помощта на функции на MS EXCEL:

Както се вижда на снимката по-горе, се предполага, че:
- Безкрайната популация, от която е направена извадката, съдържа 10% (или 0,1) добри елементи (параметър стр, трети аргумент на функцията =BINOM.DIST() )
- За да се изчисли вероятността в извадка от 10 елемента (параметър н, вторият аргумент на функцията) ще има точно 5 валидни елемента (първият аргумент), трябва да напишете формулата: =BINOM.DIST(5; 10; 0,1; FALSE)
- Последният, четвърти елемент е зададен = FALSE, т.е. стойността на функцията се връща плътност на разпространение.
Ако стойността на четвъртия аргумент е TRUE, тогава функцията BINOM.DIST() връща стойността интегрална функция на разпределениеили просто разпределителна функция. В този случай можете да изчислите вероятността броят на добрите елементи в извадката да бъде от определен диапазон, например 2 или по-малко (включително 0).
За да направите това, трябва да напишете формулата:
= BINOM.DIST(2; 10; 0,1; TRUE)
Забележка: За стойност на x, която не е цяло число, . Например следните формули ще върнат същата стойност:
=BINOM.DIST( 2
; десет; 0,1; ВЯРНО)
=BINOM.DIST( 2,9
; десет; 0,1; ВЯРНО)
Забележка: В примерния файл плътност на вероятносттаи разпределителна функциясъщо се изчислява с помощта на дефиницията и функцията COMBIN().
Показатели за разпространение
AT примерен файл на лист Примерима формули за изчисляване на някои показатели за разпределение:
- =n*p;
- (стандартно отклонение на квадрат) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
Извеждаме формулата математическо очакване Биномиално разпределениеизползвайки Схема на Бернули.
По дефиниция, случайна променлива X в Схема на Бернули(случайна променлива на Бернули) има разпределителна функция:

Това разпределение се нарича Разпределение на Бернули.
Забележка: Разпределение на Бернули- специален случай Биномиално разпределениес параметър n=1.
Нека генерираме 3 масива от 100 числа с различни вероятности за успех: 0.1; 0,5 и 0,9. За да направите това, в прозореца Поколение произволни числа задайте следните параметри за всяка вероятност p:
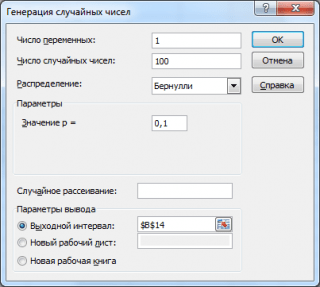
Забележка: Ако зададете опцията Случайно разпръскване (Случайно семе), тогава можете да изберете определен произволен набор от генерирани числа. Например, като зададете тази опция =25, можете да генерирате едни и същи набори от произволни числа на различни компютри (ако, разбира се, другите параметри на разпределение са еднакви). Стойността на опцията може да приема цели числа от 1 до 32 767. Име на опцията Случайно разпръскванеможе да обърка. Би било по-добре да го преведете като Задайте число със случайни числа.
В резултат на това ще имаме 3 колони от 100 числа, въз основа на които например можем да оценим вероятността за успех стрпо формулата: Брой успехи/100(см. примерен файлов лист Генериране на Bernoulli).
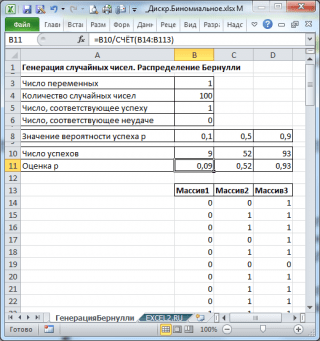
Забележка: За Разпределения на Бернулис p=0,5, можете да използвате формулата =RANDBETWEEN(0;1) , което съответства на .
Генериране на случайни числа. Биномиално разпределение
Да предположим, че в извадката има 7 дефектни артикула. Това означава, че е „много вероятно“ делът на дефектните продукти да се е променил. стр, което е характерно за нашия производствен процес. Въпреки че тази ситуация е „много вероятна“, има възможност (алфа риск, грешка тип 1, „фалшива аларма“), че стростава непроменена, а увеличеният брой дефектни продукти се дължи на случайна извадка.
Както може да се види на фигурата по-долу, 7 е броят на дефектните продукти, който е приемлив за процес с p=0,21 при същата стойност Алфа. Това илюстрира, че когато прагът на дефектни артикули в проба бъде надвишен, стр„вероятно“ се увеличи. Изразът „най-вероятно“ означава, че има само 10% шанс (100%-90%), че отклонението на процента дефектни продукти над прага се дължи само на случайни причини.

По този начин превишаването на праговия брой дефектни продукти в пробата може да служи като сигнал, че процесът е нарушен и е започнал да произвежда b относнопо-висок процент на дефектни продукти.
Забележка: Преди MS EXCEL 2010, EXCEL имаше функция CRITBINOM(), която е еквивалентна на BINOM.INV(). CRITBINOM() е оставен в MS EXCEL 2010 и по-нова версия за съвместимост.
Връзка на биномиалното разпределение с други разпределения
Ако параметърът н Биномиално разпределениеклони към безкрайност и стрклони към 0, тогава в този случай Биномиално разпределениеможе да бъде приблизително.
Възможно е да се формулират условия, когато апроксимацията Поасоново разпределениеработи добре:
- стр<0,1 (по-малкото стри още н, толкова по-точно е приближението);
- стр>0,9 (като се има предвид това р=1- стр, изчисленията в този случай трябва да се извършват с помощта на р(а хтрябва да се замени с н- х). Следователно, толкова по-малко ри още н, толкова по-точно е приближението).
На 0,1<=p<=0,9 и n*p>10 Биномиално разпределениеможе да бъде приблизително.
на свой ред Биномиално разпределениеможе да служи като добро приближение, когато размерът на популацията е N Хипергеометрично разпределениемного по-голям от размера на извадката n (т.е. N>>n или n/N<<1).
Можете да прочетете повече за връзката на горните разпределения в статията. Там са дадени и примери за приближение и са обяснени условията кога е възможно и с каква точност.
СЪВЕТ: Можете да прочетете за други дистрибуции на MS EXCEL в статията.
В тази и следващите няколко бележки ще разгледаме математически модели на случайни събития. Математически моделе математически израз, представляващ случайна променлива. За дискретни случайни променливи този математически израз е известен като функция на разпределение.
Ако проблемът ви позволява изрично да напишете математически израз, представляващ случайна променлива, можете да изчислите точната вероятност за всяка от нейните стойности. В този случай можете да изчислите и изброите всички стойности на функцията на разпределение. В бизнес, социологически и медицински приложения има различни разпределения на случайни променливи. Едно от най-полезните разпределения е биномното.
Биномиално разпределениесе използва за моделиране на ситуации, характеризиращи се със следните характеристики.
- Пробата се състои от фиксиран брой елементи нпредставляващ резултата от някакъв тест.
- Всеки примерен елемент принадлежи към една от двете взаимно изключващи се категории, които покриват цялото пространство на примера. Обикновено тези две категории се наричат успех и провал.
- Вероятност за успех Ре постоянен. Следователно вероятността от провал е 1 - стр.
- Резултатът (т.е. успех или неуспех) от всеки опит е независим от резултата от друг опит. За да се осигури независимост на резултатите, примерните елементи обикновено се получават с помощта на два различни метода. Всеки примерен елемент се изтегля на случаен принцип от безкрайна популация без заместване или от крайна популация със заместване.
Изтеглете бележка в или формат, примери във формат
Биномното разпределение се използва за оценка на броя на успехите в извадка, състояща се от ннаблюдения. Да вземем за пример поръчването. Клиентите на Saxon Company могат да използват интерактивен електронен формуляр, за да направят поръчка и да я изпратят до компанията. След това информационната система проверява дали има грешки в поръчките, както и непълна или неточна информация. Всяка съмнителна поръчка се маркира и се включва в ежедневния отчет за изключение. Данните, събрани от компанията, показват, че вероятността за грешки в поръчките е 0,1. Компанията би искала да знае каква е вероятността да открие определен брой грешни поръчки в дадена извадка. Да предположим например, че клиентите са попълнили четири електронни формуляра. Каква е вероятността всички поръчки да бъдат без грешки? Как да изчислим тази вероятност? Под успех имаме предвид грешка при попълване на формуляра и ще считаме всички останали резултати за неуспех. Спомнете си, че се интересуваме от броя на грешните поръчки в дадена извадка.
Какви резултати можем да наблюдаваме? Ако извадката се състои от четири поръчки, една, две, три или и четирите може да са грешни, освен това всички те могат да бъдат правилно попълнени. Може ли случайната променлива, описваща броя на неправилно попълнените формуляри, да приеме друга стойност? Това не е възможно, тъй като броят на неправилно попълнените формуляри не може да надвишава размера на извадката нили да бъде отрицателен. По този начин случайна променлива, която се подчинява на закона за биномно разпределение, приема стойности от 0 до н.
Да предположим, че в извадка от четири поръчки се наблюдават следните резултати:
Каква е вероятността да се намерят три грешни поръчки в извадка от четири поръчки и в посочения ред? Тъй като предварителните проучвания показват, че вероятността за грешка при попълване на формуляра е 0,10, вероятностите за горните резултати се изчисляват, както следва:
Тъй като резултатите са независими един от друг, вероятността за посочената последователност от резултати е равна на: p*p*(1–p)*p = 0,1*0,1*0,9*0,1 = 0,0009. Ако е необходимо да се изчисли броят на изборите х нелементи, трябва да използвате формулата за комбиниране (1):

където n! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - факториел на числото н, и 0! = 1 и 1! = 1 по дефиниция.
Този израз често се нарича . Така, ако n = 4 и X = 3, броят на последователностите, състоящи се от три елемента, извлечени от проба с размер 4, се дава по следната формула:
Следователно вероятността за намиране на три грешни поръчки се изчислява, както следва:
(брой възможни последователности) *
(вероятност за определена последователност) = 4 * 0,0009 = 0,0036
По същия начин можем да изчислим вероятността сред четири поръчки една или две да са грешни, както и вероятността всички поръчки да са грешни или всички да са правилни. Въпреки това, тъй като размерът на извадката се увеличава нстава по-трудно да се определи вероятността за определена последователност от резултати. В този случай трябва да се приложи подходящ математически модел, който описва биномното разпределение на броя на изборите хобекти от проба, съдържаща нелементи.
Биномиално разпределение

където P(X)- вероятност хуспех за даден размер на извадката ни вероятност за успех Р, х = 0, 1, … н.
Обърнете внимание на факта, че формула (2) е формализация на интуитивни заключения. Случайна стойност х, подчинявайки се на биномното разпределение, може да приеме произволно цяло число в диапазона от 0 до н. работа Рх(1 - p)н – хе вероятността определена последователност да се състои от хуспехи в извадката, чийто размер е равен на н. Стойността определя броя на възможните комбинации, състоящи се от хуспех в нтестове. Следователно, за даден брой опити ни вероятност за успех Рвероятността последователност, състояща се от хуспехът е равен на
P(X) = (брой възможни последователности) * (вероятност за определена последователност) = 
Разгледайте примери, илюстриращи приложението на формула (2).
1. Да приемем, че вероятността за неправилно попълване на формуляра е 0,1. Каква е вероятността три от четирите попълнени формуляра да са грешни? Използвайки формула (2), получаваме, че вероятността за намиране на три грешни поръчки в извадка от четири поръчки е равна на
2. Да приемем, че вероятността за неправилно попълване на формуляра е 0,1. Каква е вероятността поне три от четири попълнени формуляра да са грешни? Както е показано в предишния пример, вероятността три от четирите попълнени формуляра да са грешни е 0,0036. За да изчислите вероятността поне три от четирите попълнени формуляра да бъдат неправилно попълнени, трябва да добавите вероятността сред четирите попълнени формуляра три да са грешни и вероятността сред четирите попълнени формуляра всички да са грешни. Вероятността за второто събитие е
По този начин вероятността от четирите попълнени формуляра поне три да са грешни е равна на
P(X > 3) = P(X = 3) + P(X = 4) = 0,0036 + 0,0001 = 0,0037
3. Да приемем, че вероятността за неправилно попълване на формуляра е 0,1. Каква е вероятността по-малко от три от четири попълнени формуляра да са грешни? Вероятността за това събитие
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Използвайки формула (2), изчисляваме всяка от тези вероятности:

Следователно, P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Вероятност P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Тогава P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
Тъй като размерът на извадката се увеличава низчисленията, подобни на тези, извършени в пример 3, стават трудни. За да се избегнат тези усложнения, много биномни вероятности се таблицират предварително. Някои от тези вероятности са показани на фиг. 1. Например, за да получите вероятността, че х= 2 at н= 4 и стр= 0,1, трябва да извлечете от таблицата числото в пресечната точка на линията х= 2 и колони Р = 0,1.

Ориз. 1. Биномна вероятност при н = 4, х= 2 и Р = 0,1
Биномиалното разпределение може да се изчисли с помощта на Функции на Excel=BINOM.DIST() (фиг. 2), който има 4 параметъра: броят на успехите - х, брой опити (или размер на извадката) – н, вероятността за успех е Р, параметър интегрална, който приема стойностите TRUE (в този случай се изчислява вероятността поне хсъбития) или FALSE (в този случай вероятността от точно хсъбития).

Ориз. 2. Параметри на функцията =BINOM.DIST()
За горните три примера изчисленията са показани на фиг. 3 (вижте също Excel файл). Всяка колона съдържа една формула. Числата показват отговорите на примерите на съответното число).

Ориз. 3. Изчисляване биномно разпределениев Excel за н= 4 и стр = 0,1
Свойства на биномното разпределение
Биномното разпределение зависи от параметрите ни Р. Биномното разпределение може да бъде симетрично или асиметрично. Ако p = 0,05, биномното разпределение е симетрично независимо от стойността на параметъра н. Въпреки това, ако p ≠ 0,05, разпределението става изкривено. Колкото по-близо е стойността на параметъра Рдо 0,05 и колкото по-голям е размерът на извадката н, толкова по-слаба е асиметрията на разпределението. По този начин разпределението на броя на неправилно попълнените формуляри се измества надясно, тъй като стр= 0,1 (фиг. 4).

Ориз. 4. Хистограма на биномното разпределение за н= 4 и стр = 0,1
Математическо очакване на биномното разпределениее равно на произведението от размера на извадката нвърху вероятността за успех Р:
(3) M = E(X) =np
Средно, при достатъчно дълга поредица от тестове в извадка от четири поръчки, може да има p \u003d E (X) \u003d 4 x 0,1 \u003d 0,4 неправилно попълнени форми.
Стандартно отклонение на биномно разпределение
Например, стандартно отклонениеброя на неправилно попълнените формуляри в счетоводството информационна системасе равнява:
Използвани са материали от книгата Левин и др.Статистика за мениджъри. - М.: Уилямс, 2004. - стр. 307–313
