Варіаційний ряд визначення. Варіація та варіаційний ряд, розмах варіації
Сукупність значень вивченого в даному експериментіабо спостереженні параметра, проранжованих за величиною (зростання чи спадання) називається варіаційним рядом.
Припустимо, що ми виміряли артеріальний тиск у десяти пацієнтів із єдиною метою отримати верхній поріг АТ: систолічний тиск, тобто. лише одне число.
Припустимо, що серія спостережень (статистична сукупність) артеріального систолічного тиску в 10-ти спостереженнях має такий вигляд (табл. 1):
Таблиця 1
складники варіаційного рядуназиваються варіантами. Варіанти є числове значення досліджуваної ознаки.
Побудова зі статистичної сукупності спостережень варіаційного ряду – лише перший крок до осмислення особливостей усієї сукупності. Далі необхідно визначити середній рівень кількісної ознаки, що вивчається (середній рівень білка крові, середня вага пацієнтів, середній час наступу наркозу і т.д.)
Середній рівень вимірюють за допомогою критеріїв, які звуться середніх величин. Середня величина – узагальнююча числова характеристикаякісно однорідних величин, що характеризує одним числом усю статистичну сукупність за однією ознакою. Середня величина виражає те загальне, що притаманно ознаки у цій сукупності спостережень.
Загальновживаними є три види середніх величин: мода (), медіана () та середньоарифметична величина ().
Для визначення будь-якої середньої величининеобхідно використовувати результати індивідуальних спостережень, записавши їх як варіаційного ряду (табл. 2).
Мода- значення, що найчастіше зустрічається в серії спостережень. У нашому прикладі мода = 120. Якщо в варіаційному ряду немає значень, що повторюються, то кажуть, що мода відсутня. Якщо кілька значень повторюються однакова кількість разів, то як мода беруть найменшу з них.
Медіана- значення, що поділяє розподіл на дві рівні частини, центральне або серединне значення серії спостережень, упорядкованих за зростанням або зменшенням. Так, якщо в варіаційному ряду 5 значень, його медіана дорівнює третьому члену варіаційного ряду, якщо в ряду парна кількістьчленів, то медіана є середнє арифметичне двох його центральних спостережень, тобто. якщо у ряді 10 спостережень, то медіана дорівнює середньому арифметичному 5 та 6 спостереження. У прикладі.
Зауважимо важливу особливість моди та медіани: на їх величини не впливають числові значення крайніх варіантів.
Середня арифметична величинарозраховується за формулою:
де - спостережена величина в тому спостереженні, а - число спостережень. Для нашої нагоди.
Середня арифметична величина має три властивості:
Середня займає серединне положення у варіаційному ряду. У строго симетричному ряду.
Середня є узагальнюючою величиною і за середньою не видно випадкових коливань, відмінностей у індивідуальних даних. Вона відбиває те своєрідне, що притаманно всієї сукупності.
Сума відхилень всіх варіантів від середньої дорівнює нулю: . Відхилення варіант від середньої позначається.
Варіаційний ряд складається з варіантів і відповідних їм частот. З десяти отриманих значень цифра 120 зустрілася 6 разів, 115 – 3 рази, 125 – 1 раз. Частота () - абсолютна чисельність окремих варіантів у сукупності, що вказує, скільки разів зустрічається дана варіантау варіаційному ряду.
Варіаційний ряд може бути простим (частоти = 1) або згрупованим укороченим по 3-5 варіант. Простий ряд використовується при малій кількості спостережень (), згрупований - при великій кількості спостережень ().
Особливе місце у статистичному аналізі належить визначенню середнього рівня ознаки, що вивчається, або явища. Середній рівень ознаки вимірюють середніми величинами.
Середня величина характеризує загальний кількісний рівень ознаки, що вивчається, і є груповою властивістю статистичної сукупності. Вона нівелює, послаблює випадкові відхиленняіндивідуальних спостережень у той чи інший бік і висуває першому плані основне, типове властивість досліджуваного ознаки.
Середні величини широко використовуються:
1. Для оцінки стану здоров'я населення: показники фізичного розвитку(Зростання, вага, окружність грудної клітки та ін.), Виявлення поширеності та тривалості різних захворювань, аналізу демографічних показників (природного руху населення, середньої тривалості майбутнього життя, відтворення населення, середньої чисельності населення та ін).
2. Для вивчення діяльності лікувально-профілактичних установ, медичних кадрів та оцінки якості їх роботи, планування та визначення потреб населення в різних видахмедичної допомоги (середня кількість звернень або відвідувань на одного мешканця на рік, середня тривалість перебування хворого у стаціонарі, середня тривалість обстеження хворого, середня забезпеченість лікарями, ліжками та ін.).
3. Для характеристики санітарно-епідеміологічного стану (середня запиленість повітря в цеху, середня площа на одну особу, середні норми споживання білків, жирів та вуглеводів тощо).
4. Для визначення медико-фізіологічних показників у нормі та патології, при обробці лабораторних даних, для встановлення достовірності результатів вибіркового дослідження у соціально-гігієнічних, клінічних, експериментальних дослідженнях.
Обчислення середніх величин виконується з урахуванням варіаційних рядів. Варіаційний ряд– це однорідна у якісному відношенні статистична сукупність, окремі одиниці якої характеризують кількісні відмінності досліджуваної ознаки чи явища.
Кількісна варіація може бути двох типів: перервна (дискретна) та безперервна.
Перервна (дискретна) ознака виражається тільки цілим числом і не може мати жодних проміжних значень(наприклад, кількість відвідувань, чисельність населення ділянки, кількість дітей у сім'ї, ступінь тяжкості хвороби в балах та ін.).
Безперервна ознака може набувати будь-яких значень у певних межах, у тому числі й дробових, і виражається лише приблизно (наприклад, вага – для дорослих можна обмежитися кілограмами, а для новонароджених – грамами; ріст, артеріальний тиск, час, витрачений на прийом хворого, та т. д.).
Цифрове значення кожної окремої ознаки або явища, що входить до варіаційного ряду, називається варіантом і позначається буквою V . У математичній літературі трапляються й інші позначення, наприклад x або y.
Варіаційний ряд, де кожен варіант вказано один раз, називається простим.Такі ряди використовуються в більшості статистичних завданьу разі комп'ютерної обробки даних.
При збільшенні числа спостережень, як правило, зустрічаються варіанти, що повторюються. У цьому випадку створюється згрупований варіаційний ряд, де вказується число повторень (частота, що позначається буквою « р »).
Ранжований варіаційний рядскладається з варіантів, розташованих у порядку зростання або спадання. Як простий, і згрупований ряди можуть бути складені з ранжированием.
Інтервальний варіаційний рядскладають з метою спрощення наступних обчислень, що виконуються без використання комп'ютера, при дуже великій кількості одиниць спостереження (понад 1000).
Безперервний варіаційний рядвключає значення варіант, які можуть виражатися будь-якими значеннями.
Якщо у варіаційному ряді значення ознаки (варіанти) задані у вигляді окремих конкретних чисел, такий ряд називають дискретним.
Загальними характеристикамизначень ознаки, що відображається у варіаційному ряду, є середні величини. Серед них найбільш застосовувані: середня арифметична величина М,мода Мота медіана Me.Кожна з цих характеристик є своєрідною. Вони не можуть підмінити один одного і лише в сукупності досить повно і в стиснутій формі є особливості варіаційного ряду.
Модою (Мо) називають значення найчастіше зустрічається варіанти.
Медіана (Me) - Це значення варіанти, що розділяє ранжований варіаційний ряд навпіл (з кожного боку медіани знаходиться половина варіант). В окремих випадках, коли є симетричний варіаційний ряд, мода і медіана рівні між собою і збігаються зі значенням середньої арифметичної.
Найбільш типовою характеристикою значень варіант є середня арифметичнавеличина ( М ). У математичній літературі вона позначається .
Середня арифметична величина (M, ) – це загальна кількісна характеристика певної ознаки досліджуваних явищ, що становлять якісно однорідну статистичну сукупність. Розрізняють середню арифметичну просту та зважену. Середня арифметична проста обчислюється для простого варіаційного ряду шляхом підсумовування всіх варіантів і поділом цієї суми на загальну кількість варіантів, що входять до цього варіаційного ряду. Обчислення проводяться за такою формулою:
 ,
,
де: М - Середня арифметична проста;
Σ V - сума варіант;
n- Число спостережень.
У згрупованому варіаційному ряду визначають зважену середню арифметичну. Формула її обчислення:
 ,
,
де: М - Середня арифметична зважена;
Σ Vp - сума творів – варіант на їх частоти;
n- Число спостережень.
При велику кількість спостережень у разі ручних обчислень може застосовуватися спосіб моментів.
Середня арифметична має такі властивості:
· Сума відхилень варіант від середньої ( Σ d ) дорівнює нулю (див. табл. 15);
· при множенні (розподілі) всіх варіант на той самий множник (ділитель) середня арифметична множиться (ділиться) на той самий множник (ділитель);
· Якщо додати (відняти) до всіх варіантів одне і те ж число, середня арифметична збільшується (зменшується) на це число.
Середні арифметичні величини, взяті власними силами, не враховуючи варіабельності рядів, у тому числі вони обчислені, можуть повною мірою відбивати властивості варіаційного ряду, особливо коли необхідно зіставлення коїться з іншими середніми. Близькі за значенням середні можуть бути отримані з рядів різним ступенемрозсіювання. Чим ближче один до одного окремі варіанти за своєю кількісною характеристикою, тим менше розсіювання (хитність, варіабельність)ряду, тим типовіша його середня.
Основними параметрами, які дозволяють оцінити варіабельність ознаки, є:
· Розмах;
· Амплітуда;
· Середнє квадратичне відхилення;
· Коефіцієнт варіації.
Приблизно про коливання ознаки можна судити по розмаху та амплітуді варіаційного ряду. Розмах вказує на максимальну (V max) та мінімальну (V min) варіанти у ряду. Амплітуда (A m) є різницею цих варіантів: A m = V max - V min .
Основним, загальноприйнятим заходом коливання варіаційного ряду є дисперсія (D ). Але найчастіше застосовується більш зручний параметр, обчислюваний з урахуванням дисперсії - середнє квадратичне відхилення ( σ ). Воно враховує величину відхилення ( d ) кожної варіанти варіаційного ряду від його середньої арифметичної ( d=V - M ).
Оскільки відхилення варіант від середньої можуть бути позитивними та негативними, то при підсумовуванні вони дають значення "0" (S d=0). Щоб уникнути цього, величини відхилення ( d) зводяться на другий ступінь і усереднюються. Таким чином, дисперсія варіаційного ряду є середнім квадратом відхилень варіант від середньої арифметичної та обчислюється за формулою:
 .
.
Вона є найважливішою характеристикою варіабельності та застосовується для обчислення багатьох статистичних критеріїв.
Оскільки дисперсія виражається квадратом відхилень, її величина не може використовуватися в порівнянні з середньою арифметичною. Для цих цілей застосовується середнє квадратичне відхилення, що позначається знаком "Сігма" ( σ ). Воно характеризує середнє відхилення всіх варіант варіаційного ряду від середньої арифметичної величини в тих самих одиницях, що і сама середня величина, тому вони можуть використовуватися спільно.
Середнє квадратичне відхилення визначають за такою формулою:

Зазначена формула застосовується при числі спостережень ( n ) більше 30. При меншій кількості n значення середнього квадратичного відхилення матиме похибку, пов'язану з математичним зміщенням ( n - 1). У зв'язку з цим, більш точний результат може бути отриманий за допомогою обліку такого усунення у формулі розрахунку стандартного відхилення:
стандартне відхилення (s ) – це оцінка середньоквадратичного відхилення випадкової величини Хщодо її математичного очікуванняна основі незміщеної оцінки її дисперсії.
При значеннях n > 30 середнє квадратичне відхилення ( σ ) та стандартне відхилення ( s ) будуть однаковими ( σ =s ). Тому у більшості практичних посібників ці критерії розглядаються як різнозначні.В програмі Excel обчисленнястандартного відхилення може бути виконано функцією = СТАНДОТКЛОН (діапазон). А для розрахунку середнього квадратичного відхилення потрібно створити відповідну формулу.
Середнє квадратичне або стандартне відхилення дозволяє визначити, наскільки значення ознаки можуть відрізнятись від середнього значення. Припустимо, існують два міста з однаковою середньою денною температурою літній період. Одне з цих міст розташоване на узбережжі, а інше на континенті. Відомо, що в містах, розташованих на узбережжі, різниця денних температур менша, ніж у міст, розташованих усередині континенту. Тому середнє квадратичне відхилення денних температур у прибережного міста буде меншим, ніж у другого міста. Насправді це означає, що середня температура повітря кожного конкретного дня у місті, розташованого на континенті, буде сильніше відрізнятися від середнього значення, ніж у місті на узбережжі. Крім того, стандартне відхилення дозволяє оцінити можливі відхилення температури від середньої з необхідним рівнем ймовірності.
Відповідно до теорії ймовірності, в явищах, що підкоряються нормальному закону розподілу, між значеннями середньої арифметичної, середнього квадратичного відхилення та варіантами існує строга залежність ( правило трьох сигм). Наприклад, 68,3% значень варіює ознаки знаходяться в межах М ± 1 σ , 95,5% - у межах М ± 2 σ та 99,7% - у межах М ± 3 σ .
Величина середнього квадратичного відхилення дозволяє будувати висновки про характер однорідності варіаційного низки і досліджуваної групи. Якщо величина середнього квадратичного відхилення невелика, це свідчить про досить високої однорідності досліджуваного явища. Середню арифметичну у разі слід визнати цілком характерною для даного варіаційного ряду. Проте надто мала величина сигми змушує думати про штучний підбір спостережень. При дуже великій сигмі середня арифметична меншою мірою характеризує варіаційний ряд, що говорить про значну варіабельність ознаки або явища, що вивчається, або про неоднорідність досліджуваної групи. Проте зіставлення величини середнього квадратичного відхилення можливе лише ознак однакової розмірності. Справді, якщо порівнювати різноманітність ваги новонароджених дітей та дорослих, ми завжди матимемо вищі значення сигми у дорослих.
Порівняння варіабельності ознак різної розмірності може бути виконано за допомогою коефіцієнта варіації. Він висловлює різноманітність у відсотках від середньої величини, що дозволяє порівняти різні ознаки. Коефіцієнт варіації в медичної літературипозначається знаком « З », а в математичній « v» та обчислюваного за формулою:
 .
.
Значення коефіцієнта варіації менше 10% свідчить про мале розсіювання, від 10 до 20% – про середнє, більше 20% – про сильне розсіювання варіант навколо середньої арифметичної.
Середня арифметична величина, як правило, обчислюється на основі даних вибіркової сукупності. При повторних дослідженнях під впливом випадкових явищ середня арифметична може змінюватись. Це пов'язано з тим, що досліджується, зазвичай, лише частина можливих одиниць спостереження, тобто вибіркова сукупність. Інформація про всі можливі одиниці, що представляють явище, що вивчається, може бути отримана при вивченні всієї генеральної сукупностіщо не завжди можливо. У той самий час із метою узагальнення даних експерименту цікавий величина середньої у генеральній сукупності. Тому для формулювання загального висновку про явище, що вивчається, результати, отримані на основі вибіркової сукупності, повинні бути, перенесені на генеральну сукупність статистичними методами.
Щоб визначити ступінь збігу вибіркового дослідження та генеральної сукупності, необхідно оцінити величину помилки, яка неминуче виникає при вибірковому спостереженні. Така помилка називається « Помилка репрезентативності» або «Середньою помилкою середньої арифметичної». Вона фактично є різницею між середніми, отриманими при вибірковому статистичному спостереженні, і аналогічними величинами, які б отримані при суцільному дослідженні тієї самої об'єкта, тобто. щодо генеральної сукупності. Оскільки середня вибіркова є випадковою величиною, такий прогноз виконується з прийнятним для дослідника рівнем ймовірності. У медичних дослідженнях він становить щонайменше 95%.
Помилку репрезентативності не можна змішувати з помилками реєстрації або помилками уваги (описки, прорахунки, друкарські помилки та ін.), які повинні бути зведені до мінімуму адекватною методикою та інструментами, що застосовуються при проведенні експерименту.
Величина помилки репрезентативності залежить як від обсягу вибірки, і від варіабельності ознаки. Чим більше числоспостережень, тим ближча вибірка до генеральної сукупності і тим менша помилка. Чим більш мінливий ознака, тим більше величина статистичної помилки.
На практиці для визначення помилки репрезентативності у варіаційних рядах користуються такою формулою:
 ,
,
де: m – помилка репрезентативності;
σ - Середнє квадратичне відхилення;
n- Число спостережень у вибірці.
З формули видно, що розмір середньої помилкипрямо пропорційний середньому квадратичному відхилення, т. е. варіабельності досліджуваного ознаки, і обернено пропорційний кореню квадратному з числа спостережень.
За виконання статистичного аналізу з урахуванням обчислення відносних величин побудова варіаційного низки перестав бути обов'язковим. При цьому визначення середньої помилки для відносних показників може виконуватися за спрощеною формулою:
 ,
,
де: Р- Величина відносного показника, Вираженого у відсотках, проміле і т.д.;
q- величина, зворотна Р і виражена як (1-Р), (100-Р), (1000-Р) і т. д., залежно від підстави, на яку розрахований показник;
n- Число спостережень у вибірковій сукупності.
Однак, зазначена формула обчислення помилки репрезентативності для відносних величин може застосовуватися тільки в тому випадку, коли значення показника менше за його підставу. У ряді випадків розрахунку інтенсивних показників така умова не дотримується, і показник може виражатися числом більше 100% або 1000%. У такій ситуації виконується побудова варіаційного ряду та обчислення помилки репрезентативності за формулою середніх величин на основі середнього квадратичного відхилення.
Прогнозування величини середньої арифметичної у генеральній сукупності виконується із зазначенням двох значень – мінімального та максимального. Ці крайні значення можливих відхилень, у яких може коливатися шукана середня величина генеральної сукупності, називаються « Довірчі кордони».
Постулатами теорії ймовірностей доведено, що при нормальному розподілі ознаки з ймовірністю 99,7%, крайні значення середньої відхилень будуть не більше величинипотрійної помилки репрезентативності ( М ± 3 m ); у 95,5% - не більше величини подвоєної середньої помилки середньої величини ( М ± 2 m ); у 68,3% – не більше величини однієї середньої помилки ( М ± 1 m ) (рис. 9).

| P% |
Рис. 9. Щільність ймовірностей нормального розподілу.
Зазначимо, що наведене вище твердження є справедливим лише для ознаки, яка підпорядковується нормальному закону розподілу Гауса.
Більшість експериментальних досліджень, зокрема й у галузі медицини, пов'язані з вимірами, результати яких можуть набувати практично будь-які значення заданому інтервалі, тому, зазвичай, описуються моделлю безперервних випадкових величин. У зв'язку з цим у більшості статистичних методів розглядаються безперервні розподіли. Одним з таких розподілів, що мають основну роль у математичної статистики, є нормальний, або гаусовий, розподіл.
Це пояснюється цілою низкою причин.
1. Насамперед, багато експериментальних спостережень можна успішно описати з допомогою нормального розподілу. Слід відразу ж зазначити, що не існує розподілів емпіричних даних, які були б точно нормальними, оскільки нормально розподілена випадкова величина знаходиться в межах від до , чого ніколи не зустрічається на практиці. Проте нормальний розподіл часто добре підходить як наближення.
Чи проводяться виміри ваги, зростання та інших фізіологічних параметрів організму людини - скрізь на результати впливає дуже велике числовипадкових факторів (природні причини та помилки вимірювання). Причому, як правило, дія кожного з цих факторів є незначною. Досвід показує, що результати саме у таких випадках будуть розподілені приблизно нормально.
2. Багато розподілів, пов'язані з випадковою вибіркою, зі збільшенням обсягу останньої перетворюються на нормальне.
3. Нормальний розподіл добре підходить як наближений опис інших безперервних розподілів(Наприклад, асиметричних).
4. Нормальний розподіл має низку сприятливих математичних властивостей, багато в чому забезпечили його широке застосування у статистиці.
У той самий час слід зазначити, що у медичних даних зустрічається багато експериментальних розподілів, опис яких моделлю нормального розподілу неможливо. Для цього у статистці розроблено методи, які прийнято називати «Непараметричними».
Вибір статистичного методу, який підходить для обробки даних конкретного експерименту, повинен проводитись в залежності від належності даних до нормального закону розподілу. Перевірка гіпотези підпорядкування ознаки нормальному закону розподілу виконується з допомогою гістограми розподілу частот (графіка), і навіть низки статистичних критеріїв. Серед них:
Критерій асиметрії ( b );
Критерій перевірки на ексцес ( g );
Критерій Шапіро - Вілкса ( W ) .
Аналіз характеру розподілу даних (його називають перевіркою на нормальність розподілу) здійснюється за кожним параметром. Щоб впевнено судити про відповідність розподілу параметра нормальному закону, необхідно досить багато одиниць спостереження (щонайменше 30 значень).
Для нормального розподілу критерії асиметрії та ексцесу набувають значення 0. Якщо розподіл зміщено вправо b > 0 (позитивна асиметрія), при b < 0 - график распределения смещен влево (отрицательная асимметрия). Критерий асимметрии проверяет форму кривой распределения. В случае нормального закону g =0. При g > 0 крива розподілу гостріша, якщо g < 0 пик более сглаженный, чем функция нормального распределения.
Для перевірки на нормальність за критерієм Шапіро – Вілкса потрібно визначити значення цього критерію за статистичними таблицями за необхідного рівня значущості та залежно від кількості одиниць спостереження (ступенів свободи). Додаток 1. Гіпотеза про нормальність відкидається при малих значеннях цього критерію, як правило, при w <0,8.
Різні вибіркові значення назвемо варіантамиряду значень та позначимо: х 1 , х 2, …. Насамперед зробимо ранжуванняваріантів, тобто. розташування їх у порядку зростання чи спадання. До кожного варіанта вказується свою вагу, тобто. число, яке характеризує внесок цього варіанта у загальну сукупність. Як ваги виступають частоти або частоти.
Частотою n i варіанти х iназивається число, що показує скільки разів зустрічається даний варіант у аналізованій вибірковій сукупності.
Частотою чи відносною частотою w i варіанти х iназивається число, що дорівнює відношенню частоти варіанта до суми частот усіх варіантів. Частина показує, яка частина одиниць вибіркової сукупності має цей варіант.
Послідовність варіантів з відповідними їм вагами (частотами або частотами), записана в порядку зростання (або спадання), називається варіаційним рядом.
Варіаційні ряди бувають дискретними та інтервальними.
Для дискретного варіаційного ряду задаються точкові значення ознаки, для інтервального значення ознаки задаються у вигляді інтервалів. Варіаційні ряди можуть показувати розподіл частот чи відносних частот (частин), залежно від цього, яка величина вказується кожному за варіанта – частота чи частота.
Дискретний варіаційний ряд розподілу частотмає вигляд:
Частини знаходяться за формулою , i = 1, 2, …, m.
w 1 +w 2 + … + w m = 1.
приклад 4.1. Для цієї сукупності чисел
4, 6, 6, 3, 4, 9, 6, 4, 6, 6
побудувати дискретні варіаційні ряди розподілу частот та частот.
Рішення . Обсяг сукупності дорівнює n= 10. Дискретний ряд розподілу частот має вигляд
Аналогічну форму запису мають інтервальні ряди.
Інтервальний варіаційний ряд розподілу частотзаписується у вигляді:
Сума всіх частот дорівнює загальній кількості спостережень, тобто. обсягу сукупності: n = n 1 +n 2 + … + n m.
Інтервальний варіаційний ряд розподілу відносних частот (частин)має вигляд:
Частина знаходиться за формулою , i = 1, 2, …, m.
Сума всіх частостей дорівнює одиниці: w 1 +w 2 + … + w m = 1.
Найчастіше практично застосовуються інтервальні ряди. Якщо статистичних вибіркових даних дуже багато і їх значення відрізняються один від одного на скільки завгодно малу величину, дискретний ряд для цих даних буде досить громіздким і незручним для подальшого дослідження. І тут застосовують угруповання даних, тобто. проміжок, що містить всі значення ознаки, розбивають на кілька часткових інтервалів і, підрахувавши частоту кожного інтервалу, отримують інтервальний ряд. Запишемо докладніше схему побудови інтервального ряду, припустивши, що довжини часткових інтервалів будуть однаковими.
2.2 Побудова інтервального ряду
Для побудови інтервального ряду необхідно:
Визначити кількість інтервалів;
Визначити довжину інтервалів;
Визначити розташування інтервалів на осі.
Для визначення числа інтервалів k існує формула Стерджеса, за якою
 ,
,
де n- Обсяг всієї сукупності.
Наприклад, якщо є 100 значень ознаки (варіант), рекомендується для побудови інтервального ряду взяти кількість інтервалів рівним інтервалам.
Однак дуже часто на практиці кількість інтервалів вибирає сам дослідник, враховуючи, що це число не повинно бути дуже великим, щоб ряд не був громіздким, але й не дуже маленьким, щоб не втратити деяких властивостей розподілу.
Довжина інтервалу h визначається за такою формулою:
 ,
,
де x max та x min - це відповідно найбільше і найменше значення варіантів.
Величину  називають розмахомряду.
називають розмахомряду.
Для побудови самих інтервалів надходять по-різному. Один із найпростіших способів полягає в наступному. За початок першого інтервалу приймають величину  . Тоді інші межі інтервалів перебувають за такою формулою . Очевидно, що кінець останнього інтервалу a m+1 повинен задовольняти умову
. Тоді інші межі інтервалів перебувають за такою формулою . Очевидно, що кінець останнього інтервалу a m+1 повинен задовольняти умову
Після того, як знайдено всі межі інтервалів, визначають частоти (або частоти) цих інтервалів. Для вирішення цього завдання переглядають всі варіанти і визначають число варіантів, що потрапили в той чи інший інтервал. Повну побудову інтервального ряду розглянемо з прикладу.
приклад 4.2. Для наступних статистичних даних, записаних у порядку зростання, побудувати інтервальний ряд із числом інтервалів, що дорівнює 5:
11, 12, 12, 14, 14, 15, 21, 21, 22, 23, 25, 38, 38, 39, 42, 42, 44, 45, 50, 50, 55, 56, 58, 60, 62, 63, 65, 68, 68, 68, 70, 75, 78, 78, 78, 78, 80, 80, 86, 88, 90, 91, 91, 91, 91, 91, 93, 93, 95, 96.
Рішення. Усього n=50 значень варіантів.
Число інтервалів поставлено за умови завдання, тобто. k=5.
Довжина інтервалів дорівнює  .
.
Визначимо межі інтервалів:
a 1 = 11 − 8,5 = 2,5; a 2 = 2,5 + 17 = 19,5; a 3 = 19,5 + 17 = 36,5;
a 4 = 36,5 + 17 = 53,5; a 5 = 53,5 + 17 = 70,5; a 6 = 70,5 + 17 = 87,5;
a 7 = 87,5 +17 = 104,5.
Для визначення частоти інтервалів зважаємо на кількість варіантів, що потрапили в даний інтервал. Наприклад, перший інтервал від 2,5 до 19,5 потрапляють варіанти 11, 12, 12, 14, 14, 15. Їх число дорівнює 6, отже, частота першого інтервалу дорівнює n 1 =6. Частина першого інтервалу дорівнює  . У другий інтервал від 19,5 до 36,5 потрапляють варіанти 21, 21, 22, 23, 25, число яких дорівнює 5. Отже, частота другого інтервалу дорівнює n 2 = 5, а частота
. У другий інтервал від 19,5 до 36,5 потрапляють варіанти 21, 21, 22, 23, 25, число яких дорівнює 5. Отже, частота другого інтервалу дорівнює n 2 = 5, а частота  . Знайшовши аналогічним чином частоти і частоти всім інтервалів, отримаємо такі інтервальні ряди.
. Знайшовши аналогічним чином частоти і частоти всім інтервалів, отримаємо такі інтервальні ряди.
Інтервальний ряд розподілу частот має вигляд:
Сума частот дорівнює 6+5+9+11+8+11=50.
Інтервальний ряд розподілу частостей має вигляд:
Сума частостей дорівнює 0,12+0,1+0,18+0,22+0,16+0,22=1. ■
При побудові інтервальних рядів, залежно від конкретних умов завдання, можуть застосовуватися й інші правила, а саме
1. Інтервальні варіаційні ряди можуть складатися з часткових інтервалів різної довжини. Нерівні довжини інтервалів дозволяють виділити властивості статистичної сукупності з нерівномірним розподілом ознаки. Наприклад, якщо межі інтервалів визначають чисельність мешканців у містах, то доцільно у цій задачі використовувати нерівні за довжиною інтервали. Очевидно, що для невеликих міст має значення і невелика різниця у числі жителів, а для великих міст різниця в десятки та сотні жителів не має суттєвого значення. Інтервальні ряди з нерівними довжинами часткових інтервалів досліджуються, переважно, у загальній теорії статистики та його розгляд виходить поза рамки даного посібника.
2. У математичній статистиці іноді розглядають інтервальні ряди, котрим ліву межу першого інтервалу вважають рівною –∞, а праву межу останнього інтервалу +∞. Це робиться для того, щоб наблизити статистичний розподіл до теоретичного.
3. При побудові інтервальних рядів може виявитися, що значення якогось варіанта збігається точно з межею інтервалу. Найкраще в цьому випадку вчинити так. Якщо такий збіг лише одне, то вважати, що аналізований варіант зі своєю частотою потрапив в інтервал, що знаходиться ближче до середини інтервального ряду, якщо таких варіантів кілька, то всі їх віднести до правих від цих варіант інтервалів, або всі - до лівих.
4. Після визначення числа інтервалів та їх довжини, розташування інтервалів можна робити і за іншим способом. Знаходять середнє арифметичне всіх розглянутих значень варіантів хпор. і будують перший інтервал таким чином, щоб це середнє вибіркове було б усередині якогось інтервалу. Таким чином, отримуємо інтервал від хпор. - 0,5 hдо хпор. + 0,5 h. Потім вліво і вправо, додаючи довжину інтервалу, будуємо інші інтервали доти, доки x min та x max не потраплять відповідно у перший та останній інтервали.
5. Інтервальні ряди за великої кількості інтервалів зручно записувати вертикально, тобто. інтервали записувати над першому рядку, а першому стовпці, а частоти (чи частоти) у другому стовпці.
Вибіркові дані можуть розглядатися як значення деякої випадкової величини Х. Випадкова величина має власний закон розподілу. З теорії ймовірностей відомо, що закон розподілу дискретної випадкової величини можна задати у вигляді ряду розподілу, а безперервної – за допомогою густини розподілу. Однак існує універсальний закон розподілу, який має місце і для дискретної і безперервної випадкових величин. Цей закон розподілу задається як функції розподілу F(x) = P(X<x). Для вибіркових даних можна зазначити аналог функції розподілу – емпіричну функцію розподілу.
Подібна інформація.
Варіаційний ряд- Це ряд числових значень ознаки.
Основні характеристики варіаційного ряду: v - варіанти, р - частота її народження.
Види варіаційного ряду:
за частотою народження варіанти: простий - варіанти зустрічається один раз, зважений - варіанти зустрічається два і більше разів;
за розташуванням варіанти: ранжований – варіанти розташовані у порядку спадання та зростання, неранжований – варіанти записані без певного порядку;
по об'єднанню варіант групи: згрупований – варіанти об'єднані групи, несгрупированный – варіанти необ'єднані групи;
за величиною варіанти: безперервний - варіанти виражені цілим і дробовим числом, дискретний - варіанти виражені цілим числом, складний - варіанти представлені відносною або середньою величиною.
Варіаційний ряд складається та оформляється з метою розрахунку середніх величин.
Форма запису варіаційного ряду:
8. Середні величини, види, методика розрахунку, застосування у охороні здоров'я
Середні величини- Сукупна узагальнююча характеристика кількісних ознак. Застосування середніх величин:
1. Для характеристики організації роботи лікувально-профілактичних установ та оцінки їх діяльності:
а) у поліклініці: показники навантаження лікарів, середня кількість відвідувань, середня кількість мешканців на ділянці;
б) у стаціонарі: середня кількість днів роботи ліжка на рік; середня тривалість перебування у стаціонарі;
в) у центрі гігієни, епідеміології та громадського здоров'я: середня площа (або кубатура) на 1 особу, середні норми харчування (білки, жири, вуглеводи, вітаміни, мінеральні солі, калорії), санітарні норми та нормативи тощо;
2. Для характеристики фізичного розвитку (основних антропометричних ознак морфологічних та функціональних);
3. Для визначення медико-фізіологічних показників організму в нормі та патології у клінічних та експериментальних дослідженнях.
4. У спеціальних наукових дослідженнях.
Відмінність середніх величин від показників:
1. Коефіцієнти характеризують альтернативну ознаку, що зустрічається тільки в деякій частині статистичного колективу, який може мати місце або не мати місце.
Середні величини охоплюють ознаки, властиві всім членам колективу, але по-різному (вага, зростання, дні лікування лікарні).
2. Коефіцієнти застосовуються для вимірювання якісних ознак. Середні величини – для кількісних ознак, що варіюють.
Види середніх величин:
середня арифметична, її характеристики – середнє квадратичне відхилення та середня помилка
мода та медіана. Мода (Мо)– відповідає величині ознаки, що найчастіше зустрічається у цій сукупності. Медіана (Ме)– величина ознаки, що займає серединне значення у цій сукупності. Вона ділить ряд на 2 рівні частини за кількістю спостережень. Середня арифметична величина (М)- На відміну від моди та медіани спирається на всі зроблені спостереження, тому є важливою характеристикою для всього розподілу.
інші види середніх величин, що застосовуються у спеціальних дослідженнях: середня квадратична, кубічна, гармонійна, геометрична, прогресивна.
Середня арифметичнахарактеризує середній рівень статистичної сукупності.
Для простого ряду, де
∑v – сума варіант,
n – кількість спостережень.
 для виваженого ряду, де
для виваженого ряду, де
∑vр – сума творів кожної варіанти на частоту її народження
n – кількість спостережень.
Середнє квадратичне відхиленнясередньої арифметичної або сигма (σ) характеризує різноманітність ознаки
 - для простого ряду
- для простого ряду
Σd 2 – сума квадратів різниці середньої арифметичної та кожної варіанти (d = │M-V│)
n – кількість спостережень
 - для зваженого ряду
- для зваженого ряду
∑d 2 p – сума творів квадратів різниці середньої арифметичної та кожної варіанти на частоту її народження,
n – кількість спостережень.
Про рівень різноманітності можна судити за величиною коефіцієнта варіації  . Більше 20% – сильна різноманітність, 10-20% – середня різноманітність, менше 10% – слабка різноманітність.
. Більше 20% – сильна різноманітність, 10-20% – середня різноманітність, менше 10% – слабка різноманітність.
Якщо до середньої арифметичної величини додати і відібрати від неї одну сигму (М ± 1σ), то при нормальному розподілі в цих межах перебуватиме не менше 68,3% всіх варіантів (спостережень), що вважається нормою для явища, що вивчається. Якщо до 2 ± 2σ, то в цих межах буде перебувати 95,5% всіх спостережень, а якщо до М ± 3σ, то в цих межах буде 99,7% всіх спостережень. Таким чином, середнє квадратичне відхилення є стандартним відхиленням, що дозволяє передбачити ймовірність появи такого значення ознаки, що вивчається, яке знаходиться в межах заданих меж.
Середня помилка середньої арифметичноїабо помилка репрезентативності. Для простого, зваженого рядів та за правилом моментів:
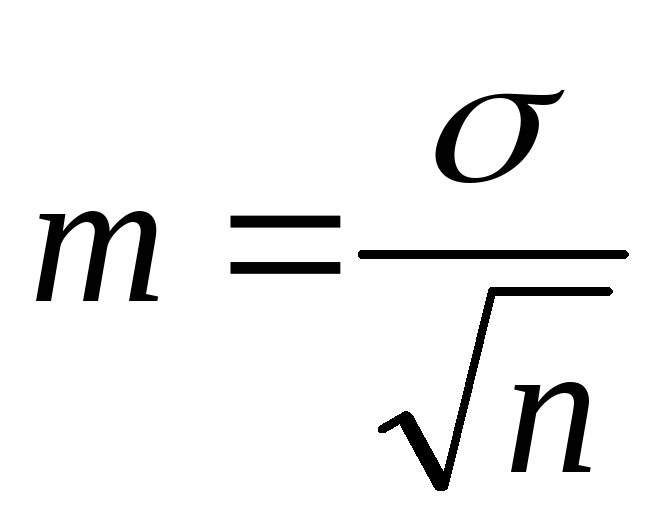 .
.
Для розрахунку середніх величин необхідно: однорідність матеріалу, достатньо спостережень. Якщо число спостережень менше 30, у формулах розрахунку і m використовують n-1.
При оцінці отриманого результату за розміром середньої помилки користуються довірчим коефіцієнтом, які дає можливість визначити вірогідність правильної відповіді, тобто він вказує на те, що отримана величина помилки вибірки буде не більшою за дійсну помилку, допущену внаслідок суцільного спостереження. Отже, зі збільшенням довірчої ймовірності збільшується ширина довірчого інтервалу, що, у свою чергу, підвищує довірливість судження, опорність отриманого результату.
(Визначення варіаційного ряду; складові варіаційного ряду; три форми варіаційного ряду; доцільність побудови інтервального ряду; висновки, які можна зробити по побудованому ряду)
Варіаційним рядом називається послідовність всіх елементів вибірки, розміщених у неубутньому порядку. Поодинокі елементи повторюються
Варіаційні – це лави, побудовані за кількісним ознакою.
Варіаційні ряди розподілу складаються з двох елементів: варіантів та частот:
Варіанти – це числові значення кількісної ознаки у варіаційному ряду розподілу. Вони можуть бути позитивними та негативними, абсолютними та відносними. При групуванні підприємств за результатами господарську діяльність варіанти позитивні – це прибуток, а негативні числа – це збиток.
Частоти – це чисельності окремих варіантів чи кожної групи варіаційного низки, тобто. це числа, що показують, як часто зустрічаються ті чи інші варіанти у розподілі. Сума всіх частот називається обсягом сукупності та визначається числом елементів усієї сукупності.
Частини – це частоти, виражені як відносних величин (частках одиниць чи відсотках). Сума частостей дорівнює одиниці або 100%. Заміна частот частостями дозволяє зіставляти варіаційні ряди з різним числом спостережень.
Виділяють три форми варіаційного ряду:ранжований ряд, дискретний ряд та інтервальний ряд.
Ранжований ряд - це розподіл окремих одиниць сукупності в порядку зростання або зменшення досліджуваної ознаки. Ранжування дозволяє легко розділити кількісні дані по групам, відразу виявити найменше та найбільше значення ознаки, виділити значення, які найчастіше повторюються.
Інші форми варіаційного ряду - групові таблиці, складені характером варіації значень досліджуваного ознаки. За характером варіації розрізняють дискретні (перервні) та безперервні ознаки.
Дискретний ряд - це такий варіаційний ряд, основою побудови якого покладено ознаки з перервним зміною (дискретні ознаки). До останніх можна віднести тарифний розряд, кількість дітей у сім'ї, кількість працівників для підприємства тощо. Ці ознаки можуть набувати лише кінцеве число певних значень.
Дискретний варіаційний ряд представляє таблицю, що складається із двох граф. У першій графі вказується конкретне значення ознаки, тоді як у другий - число одиниць сукупності з певним значенням ознаки.
Якщо ознака має безперервну зміну (розмір доходу, стаж роботи, вартість основних фондів підприємства тощо., які у певних межах можуть приймати будь-які значення), для цього ознаки потрібно будувати інтервальний варіаційний ряд.
Групова таблиця також має дві графи. У першій вказується значення ознаки в інтервалі від - до (варіанти), у другій - число одиниць, що входять в інтервал (частота).
Частота (частота повторення) - число повторень окремого варіанта значень ознаки, що позначається fi , а сума частот, що дорівнює обсягу досліджуваної сукупності, позначається
Де k – число варіантів значень ознаки
Дуже часто таблиця доповнюється графою, в якій підраховуються накопичені частоти S, які показують, скільки одиниць сукупності має значення ознаки не більше, ніж дане значення.
Дискретний варіаційний ряд розподілу - це ряд, в якому групи складені за ознакою, що змінюється дискретно і приймає лише цілі значення.
Інтервальний варіаційний ряд розподілу – це ряд, у якому групувальна ознака, що становить основу угруповання, може набувати певному інтервалі будь-які значення, зокрема і дробові.
Інтервальним варіаційним рядом називається впорядкована сукупність інтервалів варіювання значень випадкової величини з відповідними частотами або частотами влучень у кожен із них значень величини.
Інтервальний ряд розподілу доцільно будувати, передусім, при безперервній варіації ознаки, і навіть, якщо дискретна варіація проявляється у межах, тобто. Число варіантів дискретного ознаки досить велике.
Щодо цього ряду вже можна зробити кілька висновків. Наприклад, середній елемент варіаційного ряду (медіана) може бути оцінкою найімовірнішого результату виміру. Перший та останній елемент варіаційного ряду (тобто мінімальний та максимальний елемент вибірки) показують розкид елементів вибірки. Іноді якщо перший або останній елемент сильно відрізняються від інших елементів вибірки, їх виключають з результатів вимірювань, вважаючи, що ці значення отримані в результаті якогось грубого збою, наприклад, техніки.
