فاصله اطمینان برای تشک انتظار در اکسل. روش های تحلیل کمی: تخمین فواصل اطمینان
در آمار، دو نوع تخمین وجود دارد: نقطه ای و فاصله ای. تخمین نقطه اییک آماره نمونه است که برای تخمین پارامتر استفاده می شود جمعیت. به عنوان مثال، میانگین نمونه تخمین نقطه ای است انتظارات ریاضیجامعه عمومی و واریانس نمونه S2- برآورد نقطه ای واریانس جمعیت σ2. نشان داده شد که میانگین نمونه برآوردی بی طرفانه از انتظارات جامعه است. میانگین نمونه بی طرف نامیده می شود زیرا میانگین تمام نمونه ها به معنای (با حجم نمونه یکسان است n) برابر با انتظارات ریاضی عموم مردم است.
به منظور واریانس نمونه S2به یک برآوردگر بی طرفانه واریانس جمعیت تبدیل شد σ2، مخرج واریانس نمونه باید برابر باشد n – 1 ، اما نه n. به عبارت دیگر، واریانس جامعه، میانگین تمام واریانس های نمونه ممکن است.
هنگام تخمین پارامترهای جمعیت باید در نظر داشت که آمارهای نمونه مانند ، به نمونه های خاصی بستگی دارد. برای در نظر گرفتن این واقعیت، به دست آوردن تخمین فاصلهانتظارات ریاضی جمعیت عمومی توزیع میانگین های نمونه را تجزیه و تحلیل می کند (برای جزئیات بیشتر، نگاه کنید به). فاصله ساخته شده با یک سطح اطمینان مشخص مشخص می شود، که احتمال برآورد صحیح پارامتر واقعی جمعیت عمومی است. از فواصل اطمینان مشابهی می توان برای تخمین نسبت یک ویژگی استفاده کرد آرو توده اصلی توزیع شده از جمعیت عمومی.
دانلود یادداشت در قالب یا فرمت، نمونه ها در قالب
ساخت یک فاصله اطمینان برای انتظارات ریاضی جمعیت عمومی با یک انحراف معیار شناخته شده
ایجاد فاصله اطمینان برای نسبت یک صفت در جمعیت عمومی
در این بخش مفهوم فاصله اطمینان به داده های طبقه بندی شده تعمیم داده شده است. این به شما امکان می دهد سهم این صفت را در جمعیت عمومی تخمین بزنید آربا سهم نمونه آراس= X/n. همانطور که گفته شد، اگر مقادیر nآرو n(1 - p)از عدد 5 فراتر رفته، توزیع دو جمله ایرا می توان به صورت عادی تقریب زد. بنابراین، برای تخمین سهم یک صفت در جمعیت عمومی آرمی توان بازه ای ساخت که سطح اطمینان آن برابر است (1 - α)x100%.

جایی که پاس- سهم نمونه از ویژگی، برابر با ایکس/n، یعنی تعداد موفقیت ها تقسیم بر حجم نمونه، آر- سهم این صفت در جمعیت عمومی، زمقدار بحرانی توزیع نرمال استاندارد شده است، n- اندازهی نمونه.
مثال 3بیایید فرض کنیم که از سیستم اطلاعاتنمونه ای از 100 فاکتور تکمیل شده در ماه گذشته را بازیابی کرد. فرض کنید 10 مورد از این فاکتورها نادرست است. به این ترتیب، آر= 10/100 = 0.1. سطح اطمینان 95% مربوط به مقدار بحرانی Z = 1.96 است.
بنابراین، 95 درصد احتمال دارد که بین 4.12 تا 15.88 درصد فاکتورها دارای خطا باشند.
برای حجم نمونه معین فاصله اطمینانبه نظر می رسد که سهم این صفت در جمعیت عمومی را شامل می شود، نسبت به حالت مداوم گسترده تر است متغیر تصادفی. این به این دلیل است که اندازه گیری یک متغیر تصادفی پیوسته حاوی اطلاعات بیشتری نسبت به اندازه گیری داده های طبقه بندی است. به عبارت دیگر، دادههای طبقهبندی که فقط دو مقدار میگیرند، حاوی اطلاعات کافی برای تخمین پارامترهای توزیع آنها نیستند.
ATمحاسبه برآوردهای حاصل از یک جمعیت محدود
برآورد انتظارات ریاضی.ضریب تصحیح برای جمعیت نهایی ( fpc) برای کاهش خطای استاندارد با ضریب استفاده شد. هنگام محاسبه فواصل اطمینان برای برآورد پارامترهای جمعیت، یک ضریب تصحیح در شرایطی که نمونهها بدون جایگزینی کشیده میشوند، اعمال میشود. بنابراین، فاصله اطمینان برای انتظارات ریاضی، با داشتن سطح اطمینان برابر است (1 - α)x100%، با فرمول محاسبه می شود:

مثال 4برای نشان دادن کاربرد یک ضریب تصحیح برای یک جمعیت محدود، اجازه دهید به مسئله محاسبه فاصله اطمینان برای میانگین مقدار فاکتورهایی که در مثال 3 در بالا بحث شد، برگردیم. فرض کنید یک شرکت 5000 فاکتور در ماه صادر می کند، ایکس= 110.27 دلار، اس= 28.95 دلار ن = 5000, n = 100, α = 0.05، t99 = 1.9842. با توجه به فرمول (6) بدست می آوریم:
تخمین سهم ویژگیهنگام انتخاب بدون بازگشت، فاصله اطمینان برای نسبت ویژگی که دارای سطح اطمینان برابر است (1 - α)x100%، با فرمول محاسبه می شود:

فواصل اطمینان و مسائل اخلاقی
هنگام نمونهگیری از یک جامعه و فرمولبندی استنباطهای آماری، اغلب مشکلات اخلاقی به وجود میآیند. نکته اصلی این است که فواصل اطمینان و تخمین های نقطه با هم توافق دارند. نمونه آمار. تخمین های نقطه انتشار بدون تعیین فواصل اطمینان مناسب (معمولاً در سطح اطمینان 95٪) و حجم نمونه که از آن استخراج می شود، می تواند گمراه کننده باشد. این ممکن است به کاربر این تصور را بدهد که تخمین نقطه ای دقیقاً همان چیزی است که او برای پیش بینی ویژگی های کل جمعیت به آن نیاز دارد. بنابراین، درک این نکته ضروری است که در هر تحقیقی، تخمین های نه نقطه ای، بلکه فاصله ای باید در اولویت قرار گیرد. علاوه بر این، باید توجه ویژه ای شود انتخاب صحیحاندازه های نمونه
بیشتر اوقات، اهداف دستکاری های آماری نتایج بررسی های جامعه شناختی از جمعیت در مورد موضوعات مختلف سیاسی است. در همان زمان، نتایج نظرسنجی در صفحه اول روزنامه ها قرار می گیرد و خطای نمونه گیری و روش تجزیه و تحلیل آماری در جایی در وسط چاپ می شود. برای اثبات اعتبار برآوردهای نقطهای بهدستآمده، باید حجم نمونه بر اساس آن، مرزهای فاصله اطمینان و سطح معنیداری آن مشخص شود.
یادداشت بعدی
از مطالب کتاب لوین و همکاران آمار برای مدیران استفاده شده است. - م.: ویلیامز، 2004. - ص. 448-462
تئوری حد مرکزیبیان می کند که با توجه به حجم نمونه به اندازه کافی بزرگ، توزیع نمونه میانگین ها را می توان با یک توزیع نرمال تقریب زد. این ویژگی به نوع توزیع جمعیت بستگی ندارد.
برآورد فواصل اطمینان
اهداف یادگیری
آمار موارد زیر را در نظر می گیرد دو وظیفه اصلی:
ما بر اساس دادههای نمونه تخمینی داریم و میخواهیم یک گزاره احتمالی در مورد اینکه مقدار واقعی پارامتر تخمین زده شده کجاست بیان کنیم.
ما یک فرضیه خاص داریم که باید بر اساس داده های نمونه آزمایش شود.
در این مبحث به بررسی مشکل اول می پردازیم. ما همچنین تعریف فاصله اطمینان را معرفی می کنیم.
فاصله اطمینان فاصله ای است که حول مقدار تخمینی یک پارامتر ساخته می شود و نشان می دهد که مقدار واقعی پارامتر تخمین زده شده با یک احتمال پیشینی در کجا قرار دارد.
پس از مطالعه مطالب در مورد این موضوع، شما:
بیاموزید که فاصله اطمینان برآورد چقدر است.
طبقه بندی را یاد بگیرید مشکلات آماری;
تسلط بر تکنیک ساخت فواصل اطمینان، هم با استفاده از فرمول های آماری و هم با استفاده از ابزارهای نرم افزاری.
یاد بگیرید که اندازه نمونه مورد نیاز را برای دستیابی به پارامترهای خاصی از دقت برآوردهای آماری تعیین کنید.
توزیع ویژگی های نمونه
توزیع T
همانطور که در بالا بحث شد، توزیع متغیر تصادفی نزدیک به توزیع نرمال استاندارد شده با پارامترهای 0 و 1 است. از آنجایی که ما مقدار σ را نمی دانیم، آن را با مقداری تخمین s جایگزین می کنیم. مقدار قبلاً توزیع متفاوتی دارد، یعنی یا توزیع دانش آموزی، که با پارامتر n -1 (تعداد درجات آزادی) تعیین می شود. این توزیع نزدیک به توزیع نرمال است (هرچه n بزرگتر باشد، توزیع ها نزدیکتر است).
روی انجیر 95  توزیع دانش آموز با 30 درجه آزادی ارائه شده است. همانطور که می بینید، به توزیع نرمال بسیار نزدیک است.
توزیع دانش آموز با 30 درجه آزادی ارائه شده است. همانطور که می بینید، به توزیع نرمال بسیار نزدیک است.
مشابه توابع کار با توزیع عادی NORMDIST و NORMINV، توابعی برای کار با توزیع t وجود دارد - STUDIST (TDIST) و STUDRASPBR (TINV). نمونه ای از استفاده از این توابع را می توان در فایل STUDRIST.XLS (قالب و راه حل) و در شکل. 96  .
.
توزیع سایر خصوصیات
همانطور که می دانیم، برای تعیین دقت برآورد انتظار، به توزیع t نیاز داریم. برای تخمین سایر پارامترها، مانند واریانس، توزیع های دیگری مورد نیاز است. دو مورد از آنها توزیع F و x 2 - توزیع.
فاصله اطمینان برای میانگین
فاصله اطمینانفاصله ای است که حول مقدار تخمینی پارامتر ساخته می شود و نشان می دهد که مقدار واقعی پارامتر برآورد شده با احتمال پیشینی در کجا قرار دارد.
ایجاد یک فاصله اطمینان برای مقدار میانگین رخ می دهد به روش زیر:
مثال
این فست فود قصد دارد مجموعه خود را با نوع جدیدی از ساندویچ گسترش دهد. به منظور تخمین تقاضا برای آن، مدیر قصد دارد به طور تصادفی 40 بازدید کننده را از بین کسانی که قبلا آن را امتحان کرده اند انتخاب کند و از آنها بخواهد که نگرش خود را نسبت به محصول جدید در مقیاسی از 1 تا 10 ارزیابی کنند. تعداد امتیازات مورد انتظاری که محصول جدید دریافت می کند و یک فاصله اطمینان 95% برای این برآورد ایجاد می کند. چگونه انجامش بدهیم؟ (به فایل SANDWICH1.XLS (الگو و راه حل) مراجعه کنید.
راه حل
برای حل این مشکل می توانید از . نتایج در شکل ارائه شده است. 97  .
.
فاصله اطمینان برای ارزش کل
گاهی بر اساس داده های نمونه، لازم است نه انتظارات ریاضی، بلکه برآورد شود مبلغ کلارزش های. به عنوان مثال، در شرایطی که حسابرس وجود دارد، ممکن است ارزیابی نشود سایز متوسطحساب ها، اما مجموع همه حساب ها.
اجازه دهید N تعداد کل عناصر، n اندازه نمونه، T 3 مجموع مقادیر در نمونه، T" تخمینی برای مجموع کل جامعه باشد، سپس ![]() ، و فاصله اطمینان با فرمول محاسبه می شود، که در آن s تخمین انحراف استاندارد برای نمونه است، تخمین میانگین برای نمونه است.
، و فاصله اطمینان با فرمول محاسبه می شود، که در آن s تخمین انحراف استاندارد برای نمونه است، تخمین میانگین برای نمونه است.
مثال
بیایید بگوییم اداره مالیاتمی خواهد مبلغ کل بازپرداخت مالیات را برای 10000 مالیات دهندگان تخمین بزند. مالیات دهنده یا بازپرداخت دریافت می کند یا مالیات اضافی می پردازد. فاصله اطمینان 95% را برای مبلغ بازپرداخت، با فرض حجم نمونه 500 نفر پیدا کنید (به فایل REFUND AMOUNT.XLS (الگو و راه حل) مراجعه کنید.
راه حل
هیچ رویه خاصی در StatPro برای این مورد وجود ندارد، با این حال، می توانید ببینید که با استفاده از فرمول های بالا، کران ها را می توان از کران های میانگین به دست آورد (شکل 98).  ).
).
فاصله اطمینان برای نسبت
فرض کنید p انتظار سهمی از مشتریان باشد و pv تخمینی از این سهم باشد که از نمونه ای به اندازه n به دست می آید. می توان نشان داد که برای به اندازه کافی بزرگ است  توزیع تخمین نزدیک به نرمال با میانگین p و انحراف معیار خواهد بود
توزیع تخمین نزدیک به نرمال با میانگین p و انحراف معیار خواهد بود ![]() . خطای استاندارد برآورد در این مورد به صورت بیان می شود
. خطای استاندارد برآورد در این مورد به صورت بیان می شود  ، و فاصله اطمینان به عنوان
، و فاصله اطمینان به عنوان  .
.
مثال
این فست فود قصد دارد مجموعه خود را با نوع جدیدی از ساندویچ گسترش دهد. به منظور برآورد تقاضا برای آن، مدیر به طور تصادفی 40 بازدیدکننده را از بین کسانی که قبلا آن را امتحان کرده بودند انتخاب کرد و از آنها خواست تا نگرش خود را نسبت به محصول جدید در مقیاس 1 تا 10 ارزیابی کنند. مدیر می خواهد نسبت مورد انتظار را تخمین بزند. از مشتریانی که به محصول جدید حداقل 6 امتیاز می دهند (او انتظار دارد این مشتریان مصرف کنندگان محصول جدید باشند).
راه حل
در ابتدا، اگر امتیاز مشتری بیش از 6 امتیاز بود، یک ستون جدید بر اساس 1 و در غیر این صورت 0 ایجاد می کنیم (به فایل SANDWICH2.XLS (الگو و راه حل) مراجعه کنید.
روش 1
با شمارش مقدار 1 سهم را تخمین زده و سپس از فرمول ها استفاده می کنیم.
مقدار z cr از جداول توزیع نرمال ویژه (مثلاً 1.96 برای بازه اطمینان 95٪) گرفته شده است.
با استفاده از این رویکرد و داده های خاص برای ایجاد یک بازه 95٪، نتایج زیر را به دست می آوریم (شکل 99).  ). مقدار بحرانی پارامتر z cr 1.96 است. خطای استاندارد برآورد 0.077 است. حد پایینی فاصله اطمینان 0.475 است. حد بالایی فاصله اطمینان 0.775 است. بنابراین، یک مدیر می تواند با اطمینان 95٪ فرض کند که درصد مشتریانی که به یک محصول جدید 6 امتیاز یا بیشتر امتیاز می دهند، بین 47.5 تا 77.5 خواهد بود.
). مقدار بحرانی پارامتر z cr 1.96 است. خطای استاندارد برآورد 0.077 است. حد پایینی فاصله اطمینان 0.475 است. حد بالایی فاصله اطمینان 0.775 است. بنابراین، یک مدیر می تواند با اطمینان 95٪ فرض کند که درصد مشتریانی که به یک محصول جدید 6 امتیاز یا بیشتر امتیاز می دهند، بین 47.5 تا 77.5 خواهد بود.
روش 2
این مشکل با استفاده از ابزارهای استاندارد StatPro قابل حل است. برای انجام این کار، توجه به این نکته کافی است که سهم در این مورد با مقدار میانگین ستون Type مطابقت دارد. بعد درخواست کنید StatPro/استنتاج آماری/تحلیل تک نمونهبرای ایجاد فاصله اطمینان برای مقدار میانگین (تخمین انتظارات) برای ستون Type. نتایج به دست آمده در این مورد بسیار نزدیک به نتیجه روش 1 خواهد بود (شکل 99).
فاصله اطمینان برای انحراف معیار
s به عنوان تخمینی از انحراف استاندارد استفاده می شود (فرمول در بخش 1 آورده شده است). تابع چگالی تخمین s تابع خی دو است که مانند توزیع t دارای n-1 درجه آزادی است. عملکردهای ویژه ای برای کار با این توزیع CHI2DIST (CHIDIST) و CHI2OBR (CHIINV) وجود دارد.
فاصله اطمینان در این حالت دیگر متقارن نخواهد بود. طرح شرطی مرزها در شکل نشان داده شده است. 100 .
مثال
دستگاه باید قطعاتی با قطر 10 سانتی متر تولید کند اما به دلیل شرایط مختلف خطاهایی رخ می دهد. کنترل کننده کیفیت نگران دو چیز است: اول، مقدار متوسط باید 10 سانتی متر باشد. ثانیاً، حتی در این مورد، اگر انحرافات زیاد باشد، بسیاری از جزئیات مردود خواهد بود. او هر روز یک نمونه از 50 قسمت می سازد (به فایل QUALITY CONTROL.XLS (الگو و راه حل) مراجعه کنید. چنین نمونه ای چه نتیجه ای می تواند بدهد؟
راه حل
ما 95% فواصل اطمینان را برای میانگین و برای انحراف استاندارد با استفاده میسازیم StatPro/استنتاج آماری/تحلیل تک نمونه(شکل 101  ).
).
بعد، با استفاده از فرضیه توزیع نرمالقطر، نسبت محصولات معیوب را محاسبه می کنیم و حداکثر انحراف را 0.065 تنظیم می کنیم. با استفاده از قابلیت های جدول جستجو (مورد دو پارامتر)، وابستگی درصد ردها را به مقدار میانگین و انحراف استاندارد می سازیم (شکل 102).  ).
).
فاصله اطمینان برای تفاوت دو میانگین
این یکی از مهمترین برنامه های کاربردی است روش های آماری. نمونه های موقعیت
یک مدیر فروشگاه پوشاک دوست دارد بداند که یک خریدار زن متوسط در فروشگاه چقدر بیشتر یا کمتر از یک مرد خرج می کند.
این دو شرکت هواپیمایی مسیرهای مشابهی را انجام می دهند. یک سازمان مصرف کننده مایل است تفاوت بین میانگین زمان های تاخیر پرواز مورد انتظار برای هر دو شرکت هواپیمایی را مقایسه کند.
این شرکت برای انواع خاصی از کالاها در یک شهر کوپن ارسال می کند و در شهر دیگر ارسال نمی کند. مدیران می خواهند میانگین خرید این اقلام را طی دو ماه آینده مقایسه کنند.
یک فروشنده خودرو اغلب در سخنرانی ها با زوج های متاهل سروکار دارد. برای درک واکنش های شخصی آنها به ارائه، اغلب زوج ها به طور جداگانه مصاحبه می شوند. مدیر می خواهد تفاوت در رتبه بندی های داده شده توسط مردان و زنان را ارزیابی کند.
مورد نمونه های مستقل
اختلاف میانگین یک توزیع t با n 1 + n 2 - 2 درجه آزادی خواهد داشت. فاصله اطمینان برای μ 1 - μ 2 با نسبت بیان می شود:

این مشکل نه تنها با فرمول های فوق، بلکه با ابزارهای استاندارد StatPro نیز قابل حل است. برای این کار کافی است درخواست بدهید
فاصله اطمینان برای تفاوت بین نسبت ها
اجازه دهید انتظار ریاضی از سهام باشد. فرض کنید تخمین نمونه آنها به ترتیب بر روی نمونه هایی با اندازه n 1 و n 2 ساخته شده است. سپس یک تخمین برای تفاوت است. بنابراین، فاصله اطمینان برای این تفاوت به صورت زیر بیان می شود:
در اینجا z cr مقداری است که از توزیع نرمال جداول خاص به دست می آید (مثلاً 1.96 برای فاصله اطمینان 95٪).
خطای استاندارد برآورد در این مورد با رابطه زیر بیان می شود:
 .
.
مثال
فروشگاه، در آماده سازی برای فروش بزرگ، تحقیقات بازاریابی زیر را انجام داد. 300 خریدار برتر انتخاب و به طور تصادفی به دو گروه 150 نفره تقسیم شدند. برای همه خریداران منتخب دعوتنامه برای شرکت در فروش ارسال شد، اما فقط برای اعضای گروه اول یک کوپن ضمیمه شده بود که حق 5% تخفیف را دارد. در حین فروش، خرید هر 300 خریدار منتخب ثبت شد. چگونه یک مدیر می تواند نتایج را تفسیر کند و در مورد اثربخشی کوپن قضاوت کند؟ (به فایل COUPONS.XLS (الگو و راه حل) مراجعه کنید).
راه حل
برای مورد خاص ما، از 150 مشتری که کوپن تخفیف دریافت کردند، 55 نفر خرید فروش انجام دادند و از بین 150 مشتری که کوپن دریافت نکردند، فقط 35 نفر خرید کردند (شکل 103).  ). سپس مقادیر نسبت های نمونه به ترتیب 0.3667 و 0.2333 است. و اختلاف نمونه بین آنها به ترتیب برابر با 0.1333 است. با فرض فاصله اطمینان 95٪، از جدول توزیع نرمال z cr = 1.96 را دریافت می کنیم. محاسبه خطای استاندارد اختلاف نمونه 0.0524 است. در نهایت، دریافتیم که حد پایین بازه اطمینان 95% به ترتیب 0.0307 و حد بالایی 0.2359 است. نتایج بهدستآمده را میتوان به گونهای تفسیر کرد که به ازای هر 100 مشتری که کوپن تخفیف دریافت کردند، میتوان از 3 تا 23 مشتری جدید انتظار داشت. اما باید در نظر داشت که این نتیجه گیری به خودی خود به معنای کارایی استفاده از کوپن نیست (زیرا با ارائه تخفیف ضرر می کنیم!). بیایید این را روی داده های خاص نشان دهیم. فرض کنید که مقدار متوسط خرید 400 روبل است که 50 روبل آن است. سود فروشگاهی وجود دارد سپس سود مورد انتظار به ازای هر 100 مشتری که کوپن دریافت نکرده اند برابر است با:
). سپس مقادیر نسبت های نمونه به ترتیب 0.3667 و 0.2333 است. و اختلاف نمونه بین آنها به ترتیب برابر با 0.1333 است. با فرض فاصله اطمینان 95٪، از جدول توزیع نرمال z cr = 1.96 را دریافت می کنیم. محاسبه خطای استاندارد اختلاف نمونه 0.0524 است. در نهایت، دریافتیم که حد پایین بازه اطمینان 95% به ترتیب 0.0307 و حد بالایی 0.2359 است. نتایج بهدستآمده را میتوان به گونهای تفسیر کرد که به ازای هر 100 مشتری که کوپن تخفیف دریافت کردند، میتوان از 3 تا 23 مشتری جدید انتظار داشت. اما باید در نظر داشت که این نتیجه گیری به خودی خود به معنای کارایی استفاده از کوپن نیست (زیرا با ارائه تخفیف ضرر می کنیم!). بیایید این را روی داده های خاص نشان دهیم. فرض کنید که مقدار متوسط خرید 400 روبل است که 50 روبل آن است. سود فروشگاهی وجود دارد سپس سود مورد انتظار به ازای هر 100 مشتری که کوپن دریافت نکرده اند برابر است با:
50 0.2333 100 \u003d 1166.50 روبل.
محاسبات مشابه برای 100 خریدار که یک کوپن دریافت کرده اند نشان می دهد:
30 0.3667 100 \u003d 1100.10 روبل.
کاهش میانگین سود به 30 با این واقعیت توضیح داده می شود که با استفاده از تخفیف، خریدارانی که کوپن دریافت کرده اند به طور متوسط 380 روبل خرید می کنند.
بنابراین، نتیجه گیری نهایی نشان دهنده ناکارآمدی استفاده از چنین کوپن هایی در این شرایط خاص است.
اظهار نظر. این مشکل با استفاده از ابزارهای استاندارد StatPro قابل حل است. برای این کار کافی است این مشکل را به مسئله تخمین اختلاف دو میانگین با روش تقلیل دهیم و سپس اعمال کنیم. StatPro/استنتاج آماری/تحلیل دو نمونهبرای ایجاد فاصله اطمینان برای تفاوت بین دو مقدار میانگین.
کنترل فاصله اطمینان
طول فاصله اطمینان بستگی به شرایط زیر:
داده های مستقیم (انحراف استاندارد)؛
سطح اهمیت؛
اندازهی نمونه.
حجم نمونه برای تخمین میانگین
اجازه دهید ابتدا مشکل را در نظر بگیریم مورد کلی. اجازه دهید مقدار نصف طول فاصله اطمینان داده شده به ما را به صورت B نشان دهیم (شکل 104  ). می دانیم که فاصله اطمینان برای مقدار میانگین برخی از متغیرهای تصادفی X به صورت بیان شده است
). می دانیم که فاصله اطمینان برای مقدار میانگین برخی از متغیرهای تصادفی X به صورت بیان شده است ![]() ، جایی که
، جایی که ![]() . با فرض اینکه:
. با فرض اینکه:
![]() و با بیان n بدست می آوریم.
و با بیان n بدست می آوریم.
متاسفانه، ارزش دقیقما واریانس متغیر تصادفی X را نمی دانیم. علاوه بر این، ما مقدار t cr را نمی دانیم زیرا از طریق تعداد درجات آزادی به n بستگی دارد. در این شرایط می توانیم موارد زیر را انجام دهیم. به جای واریانس s، از برخی برآوردهای واریانس برای برخی از تحقق های موجود از متغیر تصادفی مورد مطالعه استفاده می کنیم. به جای مقدار t cr، از مقدار z cr برای توزیع نرمال استفاده می کنیم. این کاملاً قابل قبول است، زیرا توابع چگالی برای توزیع های معمولی و t بسیار نزدیک هستند (به جز مورد n کوچک). بنابراین، فرمول مورد نظر به شکل زیر در می آید:
 .
.
از آنجایی که فرمول، به طور کلی، نتایج غیرصحیح را ارائه می دهد، گرد کردن بیش از نتیجه به عنوان حجم نمونه مورد نظر در نظر گرفته می شود.
مثال
این فست فود قصد دارد مجموعه خود را با نوع جدیدی از ساندویچ گسترش دهد. به منظور تخمین تقاضا برای آن، مدیر به طور تصادفی قصد دارد تعدادی از بازدیدکنندگان را از بین کسانی که قبلاً آن را امتحان کرده اند انتخاب کند و از آنها بخواهد که نگرش خود را نسبت به محصول جدید در مقیاسی از 1 تا 10 رتبه بندی کنند. مدیر می خواهد برای تخمین تعداد امتیازات مورد انتظاری که محصول جدید دریافت خواهد کرد، محصول و فاصله اطمینان 95% آن برآورد را ترسیم کنید. با این حال، او می خواهد که نیمی از عرض فاصله اطمینان از 0.3 بیشتر نباشد. او برای نظرسنجی به چند بازدیدکننده نیاز دارد؟
به شرح زیر است:

اینجا r otsتخمینی از کسری p است و B نیمی از طول فاصله اطمینان است. با استفاده از مقدار می توان یک مقدار باد شده برای n بدست آورد r ots= 0.5. در این حالت، طول فاصله اطمینان از مقدار داده شده B برای هیچ مقدار واقعی p تجاوز نخواهد کرد.
مثال
اجازه دهید مدیر مثال قبلی برنامه ریزی کند تا نسبت مشتریانی را که نوع جدیدی از محصول را ترجیح می دهند تخمین بزند. او میخواهد یک فاصله اطمینان 90 درصدی بسازد که نصف طول آن کمتر یا مساوی 0.05 باشد. چند مشتری باید به صورت تصادفی نمونه برداری شوند؟
راه حل
در مورد ما، مقدار z cr = 1.645 است. بنابراین، مقدار مورد نیاز به عنوان محاسبه می شود  .
.
اگر مدیر دلیلی داشت که مقدار مورد نظر p مثلاً حدود 0.3 است، با جایگزینی این مقدار در فرمول فوق، مقدار کوچکتری از نمونه تصادفی یعنی 228 بدست می آمد.
فرمولی برای تعیین حجم نمونه تصادفی در صورت تفاوت بین دو میانگیننوشته شده به صورت:
 .
.
مثال
برخی از شرکت های کامپیوتری دارای مرکز خدمات مشتریان هستند. AT اخیراافزایش تعداد شکایات مشتریان کیفیت پایینسرویس. این مرکز خدمات عمدتاً از دو نوع کارمند استخدام می کند: کسانی که تجربه کمی دارند، اما دوره های آموزشی ویژه را گذرانده اند، و کسانی که تجربه عملی زیادی دارند، اما دوره های خاصی را گذرانده اند. این شرکت میخواهد شکایات مشتریان را در شش ماه گذشته تجزیه و تحلیل کند و میانگین تعداد آنها را برای هر یک از دو گروه از کارمندان مقایسه کند. فرض بر این است که اعداد در نمونه ها برای هر دو گروه یکسان باشد. چند کارمند باید در نمونه گنجانده شوند تا فاصله زمانی 95% با طول نیمی بیش از 2 بدست آید؟
راه حل
در اینجا σ ots تخمینی از انحراف استاندارد هر دو متغیر تصادفی با فرض نزدیک بودن آنها است. بنابراین، در وظیفه خود، باید به نحوی این برآورد را بدست آوریم. این کار را می توان به عنوان مثال به صورت زیر انجام داد. با نگاهی به اطلاعات شکایات مشتری در شش ماه گذشته، یک مدیر ممکن است متوجه شود که به طور کلی بین 6 تا 36 شکایت به ازای هر کارمند وجود دارد. با علم به اینکه برای یک توزیع نرمال تقریباً همه مقادیر بیش از سه انحراف استاندارد از میانگین نیستند، او می تواند به طور منطقی باور کند که:
![]() ، از آنجا σ ots = 5.
، از آنجا σ ots = 5.
با جایگزینی این مقدار در فرمول، دریافت می کنیم  .
.
فرمولی برای تعیین اندازه یک نمونه تصادفی در صورت تخمین تفاوت بین سهامبه نظر می رسد:

مثال
برخی از شرکت ها دو کارخانه برای تولید محصولات مشابه دارد. مدیر یک شرکت می خواهد میزان عیب هر دو کارخانه را با هم مقایسه کند. بر اساس اطلاعات موجود، میزان رد در هر دو کارخانه از 3 تا 5 درصد است. قرار است یک فاصله اطمینان 99٪ با نیم طول بیش از 0.005 (یا 0.5٪) ایجاد کند. از هر کارخانه چند محصول باید انتخاب شود؟
راه حل
در اینجا p 1ot و p 2ot تخمینی از دو کسر ناشناخته رد در کارخانه های 1 و 2 هستند. اگر p 1ots \u003d p 2ots \u003d 0.5 قرار دهیم ، یک مقدار بیش از حد تخمین زده شده برای n بدست می آوریم. اما از آنجایی که در مورد ما اطلاعات پیشینی در مورد این سهام داریم، تخمین بالایی از این سهام یعنی 0.05 را در نظر می گیریم. ما گرفتیم
هنگام تخمین برخی پارامترهای جمعیت از دادههای نمونه، ارائه نه تنها مفید است تخمین نقطه ایپارامتر، اما همچنین یک فاصله اطمینان را مشخص کنید که نشان می دهد مقدار دقیق پارامتر تخمین زده شده کجا می تواند باشد.
در این فصل، ما همچنین با روابط کمی آشنا شدیم که به ما اجازه میدهد چنین فاصلههایی را برای پارامترهای مختلف بسازیم. روش های کنترل طول فاصله اطمینان را یاد گرفت.
همچنین متذکر می شویم که مشکل تخمین حجم نمونه (مسئله برنامه ریزی آزمایش) را می توان با استفاده از ابزارهای استاندارد StatPro حل کرد. StatPro/استنتاج آماری/انتخاب اندازه نمونه.
فاصله اطمینان برای انتظارات ریاضی - این چنین فاصله ای است که از داده ها محاسبه می شود که با احتمال مشخصی انتظارات ریاضی جمعیت عمومی را در بر می گیرد. برآورد طبیعی برای انتظار ریاضی، میانگین حسابی مقادیر مشاهده شده آن است. بنابراین، بیشتر در طول درس از اصطلاحات "متوسط"، "مقدار متوسط" استفاده خواهیم کرد. در مسائل محاسبه فاصله اطمینان، پاسخ اغلب مورد نیاز این است که "فاصله اطمینان عدد متوسط [مقدار در یک مسئله خاص] از [مقدار پایین] به [مقدار بالاتر] است". با کمک فاصله اطمینان، می توان نه تنها مقادیر متوسط، بلکه سهم یک یا ویژگی دیگر از جمعیت عمومی را نیز ارزیابی کرد. مقادیر میانگین، واریانس، انحراف معیار و خطا که از طریق آنها به تعاریف و فرمول های جدید خواهیم رسید، در درس مورد تجزیه و تحلیل قرار می گیرند. نمونه و مشخصات جمعیت .
تخمین نقطه ای و بازه ای میانگین
اگر مقدار میانگین جمعیت عمومی با یک عدد (نقطه) تخمین زده شود، آنگاه یک میانگین خاص محاسبه شده از نمونه مشاهدات به عنوان تخمین میانگین مجهول جمعیت عمومی در نظر گرفته می شود. در این حالت، مقدار میانگین نمونه - یک متغیر تصادفی - با مقدار میانگین جامعه عمومی منطبق نیست. بنابراین هنگام نشان دادن مقدار میانگین نمونه، باید خطای نمونه را نیز به طور همزمان نشان داد. خطای استاندارد به عنوان معیار خطای نمونه گیری استفاده می شود که در واحدهای مشابه میانگین بیان می شود. بنابراین اغلب از نماد زیر استفاده می شود: .
اگر برآورد میانگین لازم است با احتمال خاصی مرتبط باشد، پارامتر جمعیت عمومی مورد علاقه باید نه با یک عدد، بلکه با یک بازه تخمین زده شود. فاصله اطمینان فاصله ای است که در آن با احتمال معینی پمقدار شاخص تخمینی جمعیت عمومی پیدا می شود. فاصله اطمینان که در آن با احتمال پ = 1 - α یک متغیر تصادفی است که به صورت زیر محاسبه می شود:
![]() ,
,
α = 1 - پ، که در پیوست تقریباً هر کتابی در مورد آمار یافت می شود.
در عمل، میانگین و واریانس جامعه مشخص نیست، بنابراین واریانس جامعه با واریانس نمونه جایگزین میشود و میانگین جامعه با میانگین نمونه جایگزین میشود. بنابراین، فاصله اطمینان در بیشتر موارد به صورت زیر محاسبه می شود:
![]() .
.
از فرمول فاصله اطمینان می توان برای تخمین میانگین جمعیت استفاده کرد
- انحراف معیار جمعیت عمومی شناخته شده است.
- یا انحراف معیار جامعه مشخص نیست، اما حجم نمونه بیشتر از 30 است.
میانگین نمونه یک برآورد بی طرفانه از میانگین جامعه است. به نوبه خود، واریانس نمونه  یک برآورد بی طرفانه از واریانس جمعیت نیست. برای به دست آوردن یک تخمین بی طرفانه از واریانس جامعه در فرمول واریانس نمونه، حجم نمونه است nباید جایگزین شود n-1.
یک برآورد بی طرفانه از واریانس جمعیت نیست. برای به دست آوردن یک تخمین بی طرفانه از واریانس جامعه در فرمول واریانس نمونه، حجم نمونه است nباید جایگزین شود n-1.
مثال 1اطلاعات از 100 کافه به طور تصادفی انتخاب شده در یک شهر خاص جمع آوری می شود که میانگین تعداد کارمندان در آنها 10.5 با انحراف معیار 4.6 است. فاصله اطمینان 95 درصد از تعداد کارکنان کافه را تعیین کنید.
مقدار بحرانی توزیع نرمال استاندارد برای سطح معناداری کجاست α = 0,05 .
بنابراین، فاصله اطمینان 95 درصد برای میانگین تعداد کارکنان کافه بین 9.6 تا 11.4 بود.
مثال 2برای یک نمونه تصادفی از یک جمعیت عمومی 64 مشاهده ای، مقادیر کل زیر محاسبه شد:
مجموع مقادیر در مشاهدات،
مجموع مجذور انحراف مقادیر از میانگین ![]() .
.
فاصله اطمینان 95% را برای مقدار مورد انتظار محاسبه کنید.
محاسبه انحراف معیار:
 ,
,
محاسبه مقدار متوسط:
![]() .
.
مقادیر موجود در عبارت را با فاصله اطمینان جایگزین کنید:
مقدار بحرانی توزیع نرمال استاندارد برای سطح معناداری کجاست α = 0,05 .
ما گرفتیم:
بنابراین، فاصله اطمینان 95% برای انتظارات ریاضی این نمونه از 7.484 تا 11.266 متغیر بود.
مثال 3برای یک نمونه تصادفی از یک جمعیت عمومی 100 مشاهداتی، مقدار میانگین 2/15 و انحراف معیار 2/3 محاسبه شد. فاصله اطمینان 95% را برای مقدار مورد انتظار و سپس فاصله اطمینان 99% را محاسبه کنید. اگر توان نمونه و تغییرات آن ثابت بماند، اما ضریب اطمینان افزایش یابد، آیا فاصله اطمینان باریک می شود یا افزایش می یابد؟
ما این مقادیر را با عبارت فاصله اطمینان جایگزین می کنیم:
مقدار بحرانی توزیع نرمال استاندارد برای سطح معناداری کجاست α = 0,05 .
ما گرفتیم:
![]() .
.
بنابراین، فاصله اطمینان 95 درصد برای میانگین این نمونه از 14.57 تا 15.82 بود.
مجدداً، ما این مقادیر را در عبارت فاصله اطمینان جایگزین می کنیم:
مقدار بحرانی توزیع نرمال استاندارد برای سطح معناداری کجاست α = 0,01 .
ما گرفتیم:
![]() .
.
بنابراین، فاصله اطمینان 99 درصد برای میانگین این نمونه از 14.37 تا 16.02 بود.
همانطور که می بینید، با افزایش ضریب اطمینان، مقدار بحرانی توزیع نرمال استاندارد نیز افزایش می یابد، و بنابراین، نقاط شروع و پایان بازه دورتر از میانگین قرار می گیرند، و بنابراین فاصله اطمینان برای انتظارات ریاضی. افزایش.
تخمین نقطه ای و فاصله ای وزن مخصوص
سهم برخی از ویژگی های نمونه را می توان به عنوان تخمین نقطه ای از سهم تفسیر کرد پهمین صفت در جمعیت عمومی اگر این مقدار باید با یک احتمال مرتبط شود، فاصله اطمینان وزن مخصوص باید محاسبه شود. پویژگی در جمعیت عمومی با احتمال پ = 1 - α :
 .
.
مثال 4در فلان شهر دو نامزد وجود دارد آو بنامزد شهرداری از 200 نفر از ساکنان شهر به صورت تصادفی نظرسنجی شد که از این تعداد 46 درصد پاسخ دادند که به نامزد رای می دهند. آ، 26٪ - برای نامزد بو 28 درصد نمی دانند به چه کسی رای خواهند داد. فاصله اطمینان 95٪ را برای نسبت ساکنان شهر که از نامزد حمایت می کنند، تعیین کنید آ.
هدف- آموزش الگوریتم هایی برای محاسبه فواصل اطمینان پارامترهای آماری به دانش آموزان.
در طول پردازش داده های آماری، میانگین حسابی محاسبه شده، ضریب تغییرات، ضریب همبستگی، معیارهای تفاوت و سایر آمارهای نقطه ای باید حد اطمینان کمی را دریافت کنند که نشان دهنده نوسانات احتمالی شاخص به بالا و پایین در فاصله اطمینان است.
مثال 3.1
.
توزیع کلسیم در سرم خون میمون ها، همانطور که قبلا مشخص شد، با شاخص های انتخابی زیر مشخص می شود: = 11.94 میلی گرم٪.  = 0.127 میلی گرم٪; n= 100. تعیین فاصله اطمینان برای میانگین عمومی (
= 0.127 میلی گرم٪; n= 100. تعیین فاصله اطمینان برای میانگین عمومی (  ) با احتمال اطمینان پ
= 0,95.
) با احتمال اطمینان پ
= 0,95.
میانگین کلی با احتمال معینی در بازه زیر است:
 ، جایی که
، جایی که  - میانگین حسابی نمونه؛ تی- معیار دانش آموز;
- میانگین حسابی نمونه؛ تی- معیار دانش آموز;  خطای میانگین حسابی است.
خطای میانگین حسابی است.
با توجه به جدول "مقادیر معیار دانش آموز" مقدار را پیدا می کنیم
 با سطح اطمینان 0.95 و تعداد درجات آزادی ک\u003d 100-1 \u003d 99. برابر است با 1.982. همراه با مقادیر میانگین حسابی و خطای آماری، آن را در فرمول جایگزین می کنیم:
با سطح اطمینان 0.95 و تعداد درجات آزادی ک\u003d 100-1 \u003d 99. برابر است با 1.982. همراه با مقادیر میانگین حسابی و خطای آماری، آن را در فرمول جایگزین می کنیم:
یا 11.69  12,19
12,19
بنابراین با احتمال 95 درصد می توان ادعا کرد که میانگین کلی این توزیع نرمال بین 11.69 تا 12.19 میلی گرم است.
مثال 3.2
. تعیین مرزهای فاصله اطمینان 95% برای واریانس عمومی (  ) توزیع کلسیم در خون میمون ها در صورتی که معلوم باشد
) توزیع کلسیم در خون میمون ها در صورتی که معلوم باشد  = 1.60، با n
= 100.
= 1.60، با n
= 100.
برای حل مشکل می توانید از فرمول زیر استفاده کنید:
جایی که  خطای آماری واریانس است.
خطای آماری واریانس است.
خطای واریانس نمونه را با استفاده از فرمول پیدا کنید:  . برابر با 0.11 است. معنی تی- معیار با احتمال اطمینان 0.95 و تعداد درجات آزادی ک= 100-1 = 99 از مثال قبلی شناخته شده است.
. برابر با 0.11 است. معنی تی- معیار با احتمال اطمینان 0.95 و تعداد درجات آزادی ک= 100-1 = 99 از مثال قبلی شناخته شده است.
بیایید از فرمول استفاده کنیم و دریافت کنیم:
یا 1.38  1,82
1,82
فاصله اطمینان دقیقتری برای واریانس عمومی میتواند با استفاده از آن ایجاد شود  (chi-square) - آزمون پیرسون. نکات مهم برای این معیار در یک جدول ویژه آورده شده است. هنگام استفاده از معیار
(chi-square) - آزمون پیرسون. نکات مهم برای این معیار در یک جدول ویژه آورده شده است. هنگام استفاده از معیار  برای ایجاد فاصله اطمینان از سطح اهمیت دو طرفه استفاده می شود. برای کران پایین، سطح معنی داری با فرمول محاسبه می شود
برای ایجاد فاصله اطمینان از سطح اهمیت دو طرفه استفاده می شود. برای کران پایین، سطح معنی داری با فرمول محاسبه می شود  ، برای قسمت بالایی
، برای قسمت بالایی  . به عنوان مثال، برای سطح اطمینان
. به عنوان مثال، برای سطح اطمینان  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. بر این اساس با توجه به جدول توزیع مقادیر بحرانی
= 0.990. بر این اساس با توجه به جدول توزیع مقادیر بحرانی  ، با سطوح اطمینان محاسبه شده و تعداد درجات آزادی ک= 100 – 1 = 99، مقادیر را پیدا کنید
، با سطوح اطمینان محاسبه شده و تعداد درجات آزادی ک= 100 – 1 = 99، مقادیر را پیدا کنید  و
و  . ما گرفتیم
. ما گرفتیم  برابر با 135.80 و
برابر با 135.80 و 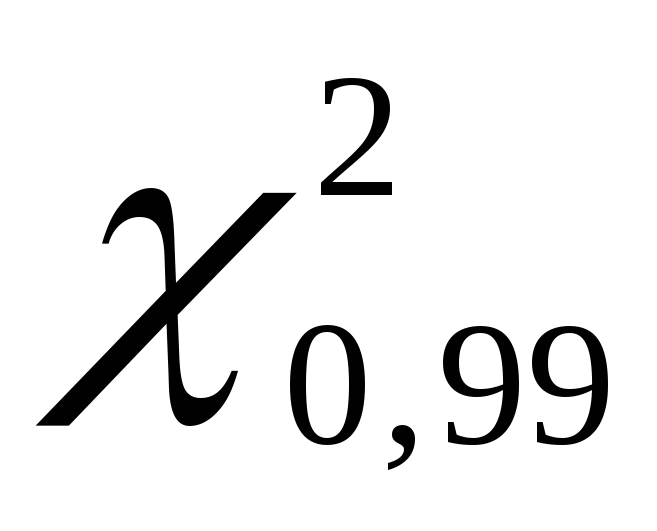 برابر با 70.06 است.
برابر با 70.06 است.
برای یافتن حدود اطمینان واریانس عمومی با استفاده از  ما از فرمول: برای کران پایین استفاده می کنیم
ما از فرمول: برای کران پایین استفاده می کنیم  ، برای کران بالا
، برای کران بالا  . داده های وظیفه را با مقادیر یافت شده جایگزین کنید
. داده های وظیفه را با مقادیر یافت شده جایگزین کنید  به فرمول ها:
به فرمول ها:  =
1,17;
=
1,17; = 2.26. بنابراین، با سطح اطمینان پ= 0.99 یا 99٪ واریانس عمومی در محدوده 1.17 تا 2.26 میلی گرم٪ شامل خواهد بود.
= 2.26. بنابراین، با سطح اطمینان پ= 0.99 یا 99٪ واریانس عمومی در محدوده 1.17 تا 2.26 میلی گرم٪ شامل خواهد بود.
مثال 3.3 . از بین 1000 بذر گندم از قسمتی که به آسانسور رسید، 120 بذر آلوده به ارگوت یافت شد. تعیین مرزهای احتمالی نسبت کل دانه های آلوده در یک دسته معین گندم ضروری است.
محدودیت های اطمینان برای سهم عمومی برای همه مقادیر ممکن آن باید با فرمول تعیین شود:
 ,
,
جایی که n تعداد مشاهدات است؛ مترعدد مطلق یکی از گروه ها است. تیانحراف نرمال شده است.
کسر نمونه بذرهای آلوده برابر است  یا 12 درصد با سطح اطمینان آر= 95% انحراف نرمال شده ( تی-معیار دانش آموز برای ک
=
یا 12 درصد با سطح اطمینان آر= 95% انحراف نرمال شده ( تی-معیار دانش آموز برای ک
=
 )تی
= 1,960.
)تی
= 1,960.
داده های موجود را با فرمول جایگزین می کنیم:
از این رو، مرزهای فاصله اطمینان هستند 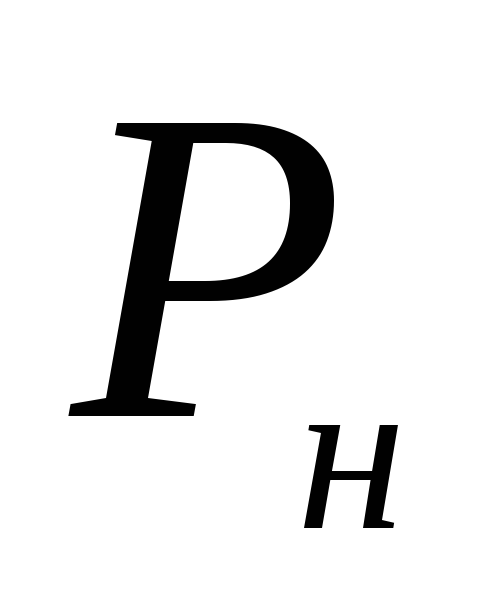 = 0.122-0.041 = 0.081، یا 8.1٪.
= 0.122-0.041 = 0.081، یا 8.1٪.  = 0.122 + 0.041 = 0.163 یا 16.3٪.
= 0.122 + 0.041 = 0.163 یا 16.3٪.
بنابراین با سطح اطمینان 95 درصد می توان گفت که نسبت کل بذرهای آلوده بین 8.1 تا 16.3 درصد است.
مثال 3.4 . ضریب تغییرات، که مشخص کننده تغییر کلسیم (mg%) در سرم خون میمون ها است، برابر با 10.6٪ بود. اندازهی نمونه n= 100. تعیین مرزهای فاصله اطمینان 95% برای پارامتر کلی ضروری است. رزومه.
محدودیت های اطمینان برای ضریب تغییرات کلی رزومه با فرمول های زیر تعیین می شوند:
 و
و  ، جایی که ک
مقدار میانی که با فرمول محاسبه می شود
، جایی که ک
مقدار میانی که با فرمول محاسبه می شود  .
.
دانستن آن با سطح اطمینان آر= 95% انحراف نرمال شده (آزمون t-Student برای ک
=
 )تی
= 1.960، مقدار را از قبل محاسبه کنید به:
)تی
= 1.960، مقدار را از قبل محاسبه کنید به:
 .
.
 یا 9.3٪
یا 9.3٪
 یا 12.3٪
یا 12.3٪
بنابراین، ضریب تغییرات کلی با احتمال اطمینان 95٪ در محدوده 9.3 تا 12.3٪ قرار دارد. با تکرار نمونه ها، ضریب تغییرات از 12.3 درصد بیشتر نخواهد شد و در 95 مورد از 100 مورد به زیر 9.3 درصد نمی رسد.
سوالاتی برای خودکنترلی:

وظایف برای راه حل مستقل.
1. میانگین درصد چربی شیر برای شیردهی گاوهای تلاقی خولموگوری به شرح زیر است: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. فواصل اطمینان را برای میانگین کلی در سطح اطمینان 95٪ (20 امتیاز) تنظیم کنید.
2. روی 400 بوته چاودار هیبرید، اولین گلها به طور متوسط 70.5 روز پس از کاشت ظاهر شدند. انحراف معیار 6.9 روز بود. تعیین خطای میانگین و فواصل اطمینان برای میانگین و واریانس جامعه در سطح معناداری دبلیو= 0.05 و دبلیو= 0.01 (25 امتیاز).
3. هنگام مطالعه طول برگ 502 نمونه توت فرنگی باغی، داده های زیر به دست آمد:
 = 7.86 سانتی متر؛ σ = 1.32 سانتی متر،
= 7.86 سانتی متر؛ σ = 1.32 سانتی متر،  \u003d 0.06 ± سانتی متر. فواصل اطمینان را برای میانگین حسابی جامعه با سطوح معنی داری 0.01 تعیین کنید. 0.02; 0.05. (25 امتیاز).
\u003d 0.06 ± سانتی متر. فواصل اطمینان را برای میانگین حسابی جامعه با سطوح معنی داری 0.01 تعیین کنید. 0.02; 0.05. (25 امتیاز).
4. در معاینه 150 مرد بالغ میانگین قد 167 سانتی متر بود و σ \u003d 6 سانتی متر. حدود میانگین کلی و واریانس عمومی با احتمال اطمینان 0.99 و 0.95 چیست؟ (25 امتیاز).
5. توزیع کلسیم در سرم خون میمون ها با شاخص های انتخابی زیر مشخص می شود:
 = 11.94 میلی گرم٪ σ
= 1,27, n
= 100. فاصله اطمینان 95% را برای میانگین جمعیت این توزیع ترسیم کنید. ضریب تغییرات (25 امتیاز) را محاسبه کنید.
= 11.94 میلی گرم٪ σ
= 1,27, n
= 100. فاصله اطمینان 95% را برای میانگین جمعیت این توزیع ترسیم کنید. ضریب تغییرات (25 امتیاز) را محاسبه کنید.
6. محتوای نیتروژن کل در پلاسمای خون موش های صحرایی آلبینو در سن 37 و 180 روز مطالعه شد. نتایج بر حسب گرم در 100 سانتی متر مکعب پلاسما بیان می شود. در سن 37 روزگی، 9 موش: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. در سن 180 روز، 8 موش: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. فواصل اطمینان را برای تفاوت با سطح اطمینان 0.95 (50 امتیاز) تنظیم کنید.
7. مرزهای فاصله اطمینان 95% برای واریانس کلی توزیع کلسیم (mg%) در سرم خون میمون ها را تعیین کنید، اگر برای این توزیع حجم نمونه 100=n، خطای آماری واریانس نمونه باشد. س σ 2 = 1.60 (40 امتیاز).
8. مرزهای فاصله اطمینان 95% را برای واریانس عمومی توزیع 40 سنبلچه گندم در طول (σ2 = 40.87 میلی متر مربع) تعیین کنید. (25 امتیاز).
9. سیگار عامل اصلی مستعد کننده بیماری انسدادی ریه در نظر گرفته می شود. سیگار کشیدن غیرفعال چنین عاملی در نظر گرفته نمی شود. دانشمندان ایمنی سیگار کشیدن غیرفعال را زیر سوال بردند و راه هوایی را در افراد غیرسیگاری، سیگاری های منفعل و فعال بررسی کردند. برای توصیف وضعیت دستگاه تنفسی، ما یکی از شاخص های عملکرد تنفس خارجی را انتخاب کردیم - حداکثر سرعت حجمی وسط بازدم. کاهش این شاخص نشانه ای از اختلال در باز بودن راه هوایی است. داده های نظرسنجی در جدول نشان داده شده است.
|
تعداد معاینه شده |
حداکثر سرعت جریان در اواسط بازدم، l/s |
||
|
انحراف معیار |
|||
|
غیر سیگاری ها |
|||
|
کار در منطقه غیر سیگاری | |||
|
در اتاقی پر از دود کار کنید | |||
|
سیگاری ها |
|||
|
سیگاری ها این کار را نمی کنند عدد بزرگسیگار | |||
|
میانگین تعداد سیگاری ها | |||
|
کشیدن تعداد زیادی سیگار | |||
از جدول، فاصله اطمینان 95% برای میانگین کلی و واریانس کلی برای هر یک از گروه ها را پیدا کنید. چه تفاوت هایی بین گروه ها وجود دارد؟ نتایج را به صورت گرافیکی (25 امتیاز) ارائه دهید.
10. در صورت خطای آماری واریانس نمونه، مرزهای فاصله اطمینان 95 و 99 درصد را برای واریانس کلی تعداد خوکچه در 64 تخم مرغ تعیین کنید. س σ 2 = 8.25 (30 امتیاز).
11. مشخص است که میانگین وزن خرگوش ها 2.1 کیلوگرم است. مرزهای فاصله اطمینان 95% و 99% را برای میانگین کلی و واریانس زمانی که n= 30، σ = 0.56 کیلوگرم (25 امتیاز).
12. در 100 خوشه، مقدار دانه بلال اندازه گیری شد ( ایکس، طول سنبله ( Y) و توده دانه در بلال ( ز). فواصل اطمینان را برای میانگین کلی و واریانس برای پیدا کنید پ 1
= 0,95, پ 2
= 0,99, پ 3
= 0.999 اگر
 = 19، = 6.766 سانتی متر، = 0.554 گرم؛ σ x 2 = 29.153، σ y 2 = 2.111، σ z 2 = 0.064. (25 امتیاز).
= 19، = 6.766 سانتی متر، = 0.554 گرم؛ σ x 2 = 29.153، σ y 2 = 2.111، σ z 2 = 0.064. (25 امتیاز).
13. در 100 خوشه گندم زمستانه که به طور تصادفی انتخاب شده بودند، تعداد سنبلچه ها شمارش شد. مجموعه نمونه با شاخص های زیر مشخص شد:
 = 15 سنبلچه و σ = 2.28 عدد. دقت به دست آوردن میانگین نتیجه را تعیین کنید (
= 15 سنبلچه و σ = 2.28 عدد. دقت به دست آوردن میانگین نتیجه را تعیین کنید (  ) و فاصله اطمینان را برای میانگین کلی و واریانس در سطوح معنی داری 95% و 99% (30 امتیاز) رسم کنید.
) و فاصله اطمینان را برای میانگین کلی و واریانس در سطوح معنی داری 95% و 99% (30 امتیاز) رسم کنید.
14. تعداد دنده های روی پوسته یک نرم تن فسیلی اورتامبونیت ها خط خطی:
مشخص است که n = 19, σ = 4.25. تعیین مرزهای فاصله اطمینان برای میانگین کلی و واریانس عمومی در سطح معناداری دبلیو = 0.01 (25 امتیاز).
15. برای تعیین میزان تولید شیر در یک مزرعه لبنی تجاری، بهره وری 15 گاو روزانه تعیین شد. بر اساس داده های سال، هر گاو به طور متوسط در روز (L) مقدار شیر می دهد: 22; 19; 25; بیست؛ 27; 17; سی 21; هجده؛ 24; 26; 23; 25; بیست؛ 24. فواصل اطمینان را برای واریانس عمومی و میانگین حسابی ترسیم کنید. آیا می توان انتظار داشت متوسط تولید شیر سالانه در هر گاو 10000 لیتر باشد؟ (50 امتیاز).
16. به منظور تعیین میانگین عملکرد گندم برای مزرعه، چمن زنی در کرت های نمونه 1، 3، 2، 5، 2، 6، 1، 3، 2، 11 و 2 هکتار انجام شد. عملکرد (c/ha) از کرت ها 39.4 بود. 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; 29 به ترتیب. فواصل اطمینان را برای واریانس عمومی و میانگین حسابی ترسیم کنید. آیا می توان انتظار داشت که متوسط عملکرد برای یک واحد کشاورزی 42 سی سی در هکتار باشد؟ (50 امتیاز).
فاصله اطمینان از حوزه آمار به ما رسید. این یک محدوده تعریف شده است که برای تخمین یک پارامتر ناشناخته به کار می رود درجه بالاقابلیت اطمینان. ساده ترین راه برای توضیح این موضوع با یک مثال است.
فرض کنید شما نیاز به بررسی یک متغیر تصادفی دارید، به عنوان مثال، سرعت پاسخ سرور به درخواست مشتری. هر بار که کاربر آدرس یک سایت خاص را تایپ می کند، سرور با سرعت متفاوتی پاسخ می دهد. بنابراین، زمان پاسخ بررسی شده دارای یک کاراکتر تصادفی است. بنابراین، فاصله اطمینان به شما این امکان را می دهد که مرزهای این پارامتر را تعیین کنید، و سپس می توان ادعا کرد که با احتمال 95٪ سرور در محدوده ای که ما محاسبه کردیم قرار خواهد گرفت.
یا باید دریابید که چند نفر از برند شرکت اطلاع دارند. هنگامی که فاصله اطمینان محاسبه می شود، می توان به عنوان مثال گفت که با احتمال 95٪ سهم مصرف کنندگانی که از این موضوع اطلاع دارند در محدوده 27٪ تا 34٪ است.
ارتباط نزدیکی با این اصطلاح دارد سطح اطمینان. این احتمال را نشان می دهد که پارامتر مورد نظر در فاصله اطمینان گنجانده شده است. این مقدار تعیین می کند که محدوده مورد نظر ما چقدر بزرگ خواهد بود. هر چه مقدار آن بزرگتر باشد، فاصله اطمینان باریکتر می شود و بالعکس. معمولاً روی 90٪، 95٪ یا 99٪ تنظیم می شود. ارزش 95٪ محبوب ترین است.
این شاخص نیز متاثر از واریانس مشاهدات است و تعریف آن بر این فرض است که ویژگی مورد مطالعه مطابقت دارد.این عبارت به قانون گاوس نیز معروف است. به گفته وی، به چنین توزیعی از همه احتمالات یک متغیر تصادفی پیوسته که می توان آن را با چگالی احتمال توصیف کرد، نرمال می گویند. اگر فرض توزیع نرمال اشتباه باشد، ممکن است تخمین اشتباه باشد.
ابتدا بیایید نحوه محاسبه فاصله اطمینان را برای اینجا بیابیم، دو مورد ممکن است. پراکندگی (درجه انتشار یک متغیر تصادفی) ممکن است شناخته شده باشد یا نباشد. اگر مشخص باشد، فاصله اطمینان ما با استفاده از فرمول زیر محاسبه می شود:
xsr - t*σ / (sqrt(n))<= α <= хср + t*σ / (sqrt(n)), где
علامت α -
t پارامتری از جدول توزیع لاپلاس است،
σ جذر پراکندگی است.
اگر واریانس ناشناخته باشد، در صورتی می توان آن را محاسبه کرد که همه مقادیر ویژگی مورد نظر را بدانیم. برای این کار از فرمول زیر استفاده می شود:
σ2 = х2ср - (хр)2، که در آن
х2ср - مقدار میانگین مربعات صفت مورد مطالعه،
(xsr)2 مربع این صفت است.
فرمولی که با آن فاصله اطمینان در این مورد محاسبه می شود کمی تغییر می کند:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n)), где
xsr - میانگین نمونه،
علامت α -
t پارامتری است که با استفاده از جدول توزیع Student t \u003d t (ɣ؛ n-1) پیدا می شود.
sqrt(n) جذر کل حجم نمونه است،
s جذر واریانس است.
این مثال را در نظر بگیرید. فرض کنید بر اساس نتایج 7 اندازه گیری، صفت مورد مطالعه 30 و واریانس نمونه برابر با 36 تعیین شد. پارامتر اندازه گیری شده
ابتدا، بیایید تعیین کنیم که t برابر است: t \u003d t (0.99؛ 7-1) \u003d 3.71. با استفاده از فرمول فوق به دست می آوریم:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7))<= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
فاصله اطمینان برای واریانس هم در مورد میانگین شناخته شده و هم زمانی که هیچ داده ای در مورد انتظارات ریاضی وجود ندارد محاسبه می شود و فقط مقدار تخمین نقطه ای بی طرفانه از واریانس مشخص است. ما در اینجا فرمول های محاسبه آن را ارائه نمی دهیم، زیرا آنها بسیار پیچیده هستند و در صورت تمایل، همیشه می توان آنها را در شبکه یافت.
ما فقط توجه می کنیم که تعیین فاصله اطمینان با استفاده از برنامه Excel یا یک سرویس شبکه که به این نام خوانده می شود راحت است.
