پراکندگی سری های زمانی با فرمول محاسبه می شود. پراکندگی یک متغیر تصادفی گسسته
شاخص های تعمیم دهنده اصلی تنوع در آمار، واریانس ها و میانگین ها هستند انحراف معیار.
پراکندگی آن میانگین حسابی مجذور انحرافات هر ویژگی از میانگین کل. واریانس معمولاً مربع میانگین انحرافات نامیده می شود و 2 نشان داده می شود. بسته به داده های اولیه، واریانس را می توان از میانگین حسابی، ساده یا وزنی محاسبه کرد:
پراکندگی بدون وزن (ساده).
 واریانس وزنی.
واریانس وزنی.
انحراف معیار مشخصه تعمیم دهنده ابعاد مطلق است تغییرات صفت در مجموع در واحدهای مشابه علامت (به متر، تن، درصد، هکتار و غیره) بیان می شود.
انحراف معیار جذر واریانس است و با نشان داده می شود:
 انحراف معیار بدون وزن؛
انحراف معیار بدون وزن؛
 انحراف معیار وزنی.
انحراف معیار وزنی.
انحراف معیار معیاری برای پایایی میانگین است. هرچه انحراف معیار کوچکتر باشد، میانگین حسابی کل جامعه نمایش داده شده را بهتر نشان می دهد.
قبل از محاسبه انحراف معیار محاسبه واریانس انجام می شود.
روش محاسبه واریانس وزنی به شرح زیر است:
1) میانگین موزون حسابی را تعیین کنید:
2) محاسبه انحراف گزینه ها از میانگین:
3) مربع انحراف هر گزینه از میانگین:
4) ضرب انحرافات مجذور در وزن ها (فرکانس ها):
5) خلاصه آثار دریافتی:
![]()
6) مقدار حاصل بر مجموع اوزان تقسیم می شود:

مثال 2.1

میانگین موزون حسابی را محاسبه کنید:

مقادیر انحراف از میانگین و مربع آنها در جدول ارائه شده است. بیایید واریانس را تعریف کنیم:

انحراف معیار برابر خواهد بود با:

اگر داده منبع به صورت بازه ای ارائه شود سری توزیع ، سپس ابتدا باید مقدار گسسته ویژگی را تعیین کنید و سپس روش توضیح داده شده را اعمال کنید.
مثال 2.2
اجازه دهید محاسبه واریانس سری بازهای را روی دادههای توزیع سطح کاشت مزرعه جمعی بر اساس عملکرد گندم نشان دهیم.

میانگین حسابی عبارت است از:

بیایید واریانس را محاسبه کنیم:

6.3. محاسبه پراکندگی با توجه به فرمول برای داده های فردی
تکنیک محاسبه پراکندگی پیچیده است و برای مقادیر زیاد گزینه ها و فرکانس ها می تواند دست و پا گیر باشد. محاسبات را می توان با استفاده از خواص پراکندگی ساده کرد.
پراکندگی دارای خواص زیر است.
1. کاهش یا افزایش وزن (فرکانس) یک ویژگی متغیر به تعداد معینی، پراکندگی را تغییر نمی دهد.
2. کاهش یا افزایش هر مقدار ویژگی با همان مقدار ثابت ولیپراکندگی تغییر نمی کند
3. کاهش یا افزایش مقدار هر ویژگی به تعداد معینی بار کبه ترتیب واریانس در را کاهش یا افزایش می دهد ک 2 بار انحراف معیار در کیک بار.
4. واریانس یک ویژگی نسبت به مقدار دلخواه همیشه از واریانس نسبت به میانگین حسابی با مجذور اختلاف بین مقادیر متوسط و دلخواه بیشتر است:
![]()
اگر یک ولی 0، سپس به تساوی زیر می رسیم:
یعنی واریانس یک ویژگی برابر است با تفاوت بین میانگین مربع مقادیر مشخصه و مربع میانگین.
هر ویژگی را می توان به تنهایی یا در ترکیب با دیگران در هنگام محاسبه واریانس استفاده کرد.
روش محاسبه واریانس ساده است:
1) تعیین کنید میانگین حسابی :
2) مجذور میانگین حسابی:

3) مربع انحراف هر یک از انواع سری:
ایکس من 2 .
4) مجموع مربع گزینه ها را پیدا کنید:
5) مجموع مربع های گزینه ها را بر تعداد آنها تقسیم کنید، یعنی مربع میانگین را تعیین کنید:
6) تفاوت بین میانگین مربع مشخصه و مربع میانگین را تعیین کنید:
مثال 3.1ما داده های زیر را در مورد بهره وری کارگران داریم:

بیایید محاسبات زیر را انجام دهیم:
![]()
انواع پراکندگی:
واریانس کلتنوع صفت کل جمعیت را تحت تأثیر همه عواملی که باعث این تنوع شده اند مشخص می کند. این مقدار با فرمول تعیین می شود
میانگین حسابی کل جامعه مورد مطالعه کجاست.
میانگین واریانس درون گروهینشاندهنده یک تغییر تصادفی است که ممکن است تحت تأثیر هر عامل نامشخصی ایجاد شود و به عامل مشخصه زیربنای گروهبندی بستگی ندارد. این واریانس به صورت زیر محاسبه می شود: ابتدا واریانس برای گروه های فردی محاسبه می شود () سپس میانگین واریانس درون گروهی محاسبه می شود:
 که در آن n i تعداد واحدهای گروه است
که در آن n i تعداد واحدهای گروه است
واریانس بین گروهی(پراکندگی میانگین های گروهی) تنوع سیستماتیک را مشخص می کند، به عنوان مثال. تفاوت در ارزش صفت مورد مطالعه که تحت تأثیر عامل صفت که اساس گروه بندی است به وجود می آید.

که در آن مقدار متوسط برای یک گروه جداگانه است.
هر سه نوع پراکندگی به هم مرتبط هستند: واریانس کلبرابر است با مجموع میانگین واریانس درون گروهی و واریانس بین گروهی:
![]()
خواص:
25 نرخ نسبی تغییرات
|
ضریب نوسان |
|
|
انحراف خطی نسبی |
|
|
ضریب تغییرات |
|
Coef. Osc. در بارهمنعکس کننده نوسان نسبی مقادیر شدید ویژگی در اطراف میانگین است. رابطه لین خاموش. سهم میانگین مقدار علامت انحراف مطلق از مقدار متوسط را مشخص می کند. Coef. تنوع رایج ترین معیار تغییر است که برای ارزیابی معمولی بودن میانگین ها استفاده می شود.
در آمار، جمعیت هایی با ضریب تغییرات بیشتر از 30-35٪ ناهمگن در نظر گرفته می شوند.
منظم بودن سری های توزیع لحظات توزیع شاخص های فرم توزیع
در سری های متغیر، بین فرکانس ها و مقادیر یک ویژگی متغیر رابطه وجود دارد: با افزایش صفت، مقدار فرکانس ابتدا تا حد معینی افزایش می یابد و سپس کاهش می یابد. چنین تغییراتی نامیده می شود الگوهای توزیع
شکل توزیع با استفاده از شاخصهای عدم تقارن و کشیدگی بررسی میشود. هنگام محاسبه این شاخص ها از گشتاورهای توزیع استفاده می شود.
لحظه k-امین مرتبه میانگین k-امین درجه انحراف انواع مقادیر ویژگی از مقداری ثابت است. ترتیب لحظه با مقدار k تعیین می شود. هنگام تجزیه و تحلیل سری های متغیر، آنها خود را به محاسبه لحظه های چهار مرتبه اول محدود می کنند. هنگام محاسبه ممان، فرکانس ها یا فرکانس ها را می توان به عنوان وزن استفاده کرد. بسته به انتخاب یک مقدار ثابت، لحظات اولیه، شرطی و مرکزی وجود دارد.
شاخص های فرم توزیع:
عدم تقارن(As) شاخصی که درجه عدم تقارن توزیع را مشخص می کند .

بنابراین، با چولگی منفی (چپ دست).  . با عدم تقارن مثبت (سمت راست).
. با عدم تقارن مثبت (سمت راست).  .
.
ممان مرکزی را می توان برای محاسبه عدم تقارن استفاده کرد. سپس:
 ,
,
جایی که μ 3 لحظه مرکزی مرتبه سوم است.
- کشیدگی (E به ) شیب نمودار تابع را در مقایسه با توزیع نرمالبا همان قدرت تغییر:
 ,
,
که در آن μ 4 لحظه مرکزی مرتبه چهارم است.
قانون توزیع عادی
برای توزیع نرمال (توزیع گاوسی)، تابع توزیع به شکل زیر است:


انتظار- انحراف معیار
توزیع نرمال متقارن است و با رابطه زیر مشخص می شود: Xav=Me=Mo
کشیدگی توزیع نرمال 3 و چولگی 0 است.
منحنی توزیع نرمال یک چند ضلعی است (خط مستقیم زنگولهای متقارن)
انواع پراکندگی. قانون اضافه کردن واریانس ماهیت ضریب تعیین تجربی.
اگر جمعیت اولیه بر اساس برخی ویژگی های اساسی به گروه ها تقسیم شود، انواع پراکندگی زیر محاسبه می شود:
واریانس کل جمعیت اصلی:
مقدار میانگین کل جمعیت اصلی کجاست؛ f فراوانی جمعیت اصلی است. واریانس کل انحراف مقادیر فردی ویژگی را از مقدار میانگین کل جمعیت اصلی مشخص می کند.
واریانس های درون گروهی:
که j تعداد گروه است؛ مقدار متوسط در هر گروه j است؛ فراوانی گروه j است. واریانس های درون گروهی انحراف ارزش فردی یک صفت در هر گروه از میانگین گروه را مشخص می کند. از تمام پراکندگیهای درون گروهی، میانگین با فرمول محاسبه میشود: تعداد واحدهای هر گروه j کجاست.
واریانس بین گروهی:
پراکندگی بین گروهی انحراف میانگین های گروهی از میانگین کل جمعیت اصلی را مشخص می کند.
قانون جمع واریانساین است که واریانس کل جمعیت اصلی باید برابر با مجموع واریانس های بین گروهی و میانگین واریانس های درون گروهی باشد:
ضریب تعیین تجربینسبت تغییرات صفت مورد مطالعه را با توجه به تنوع صفت گروه بندی نشان می دهد و با فرمول محاسبه می شود:
روش مرجع از صفر شرطی (روش گشتاورها) برای محاسبه میانگین و واریانس
محاسبه پراکندگی با روش گشتاورها بر اساس استفاده از فرمول و خواص 3 و 4 پراکندگی است.
(3. اگر تمام مقادیر صفت (گزینه ها) با مقداری ثابت A افزایش (کاهش) داشته باشند، واریانس جمعیت جدید تغییر نخواهد کرد.
4. اگر همه مقادیر صفت (گزینه ها) با K برابر افزایش (ضرب) شوند، که در آن K یک عدد ثابت است، آنگاه واریانس جمعیت جدید K2 برابر افزایش (کاهش) می شود.
فرمول محاسبه واریانس در سری های متغیر با فواصل مساوی را با روش ممان بدست می آوریم:

الف - صفر مشروط، برابر با گزینه با حداکثر فرکانس (وسط بازه با حداکثر فرکانس)
محاسبه میانگین با روش ممان نیز بر اساس استفاده از خواص میانگین است.
![]()
مفهومی از مشاهده انتخابی. مراحل بررسی پدیده های اقتصادی به روش انتخابی
نمونه مشاهده ای است که در آن همه واحدهای جمعیت اولیه مورد بررسی و مطالعه قرار نمی گیرند، بلکه تنها بخشی از واحدها مورد بررسی قرار می گیرند، در حالی که نتیجه بررسی بخشی از جامعه به کل جمعیت اصلی گسترش می یابد. مجموعه ای که از آن به انتخاب واحدها برای بررسی و مطالعه بیشتر گفته می شود عمومیو تمام شاخص های مشخص کننده این مجموعه نامیده می شوند عمومی.
حدود احتمالی انحراف میانگین نمونه از میانگین کلی نامیده می شود خطای نمونه گیری.
مجموعه واحدهای انتخاب شده نامیده می شود انتخابیو تمام شاخص های مشخص کننده این مجموعه نامیده می شوند انتخابی.
تحقیق انتخابی شامل مراحل زیر است:
ویژگی های موضوع مورد مطالعه (پدیده های اقتصادی انبوه). اگر جمعیت عمومی کم باشد، نمونه گیری توصیه نمی شود، مطالعه مستمر ضروری است.
محاسبه اندازه نمونه تعیین حجم بهینه ای که با کمترین هزینه امکان به دست آوردن خطای نمونه برداری در محدوده قابل قبول را فراهم می کند، مهم است.
انجام انتخاب واحدهای مشاهده با در نظر گرفتن الزامات تصادفی، تناسب.
شواهد نمایندگی بر اساس برآورد خطای نمونه گیری. برای نمونه تصادفی، خطا با استفاده از فرمول محاسبه می شود. برای نمونه هدف، نمایندگی با استفاده از روش های کیفی (مقایسه، آزمایش) ارزیابی می شود.
تحلیل و بررسی چارچوب نمونه. اگر نمونه تشکیل شده الزامات نمایندگی را برآورده کند، با استفاده از شاخص های تحلیلی (متوسط، نسبی و غیره) آنالیز می شود.
انتظارات و پراکندگی ریاضی - متداول ترین مشخصه های عددی مورد استفاده متغیر تصادفی. آنها بیشترین شخصیت را دارند ویژگی های مهمتوزیع: موقعیت و درجه پراکندگی آن. در بسیاری از مسائل عملی، توصیف کامل و جامع یک متغیر تصادفی - قانون توزیع - یا اصلاً به دست نمی آید یا اصلاً مورد نیاز نیست. در این موارد، آنها به توصیف تقریبی یک متغیر تصادفی با استفاده از ویژگیهای عددی محدود میشوند.
انتظارات ریاضی اغلب صرفاً به عنوان مقدار متوسط یک متغیر تصادفی نامیده می شود. پراکندگی یک متغیر تصادفی - مشخصه پراکندگی، پراکندگی یک متغیر تصادفی در اطراف آن انتظارات ریاضی.
انتظارات ریاضی از یک متغیر تصادفی گسسته
بیایید به مفهوم انتظار ریاضی نزدیک شویم و ابتدا از تفسیر مکانیکی توزیع یک متغیر تصادفی گسسته استفاده کنیم. اجازه دهید واحد جرم بین نقاط محور x توزیع شود ایکس1 , ایکس 2 , ..., ایکس n، و هر نقطه مادی دارای جرمی مربوط به آن است پ1 , پ 2 , ..., پ n. لازم است یک نقطه در محور x انتخاب شود که موقعیت کل سیستم نقاط مادی را با در نظر گرفتن جرم آنها مشخص می کند. طبیعی است که مرکز جرم سیستم نقاط مادی را چنین نقطه ای در نظر بگیریم. این میانگین وزنی متغیر تصادفی است ایکس، که در آن آبسیسه هر نقطه ایکسمنبا "وزن" برابر با احتمال مربوطه وارد می شود. به این ترتیب مقدار میانگین متغیر تصادفی به دست می آید ایکسانتظار ریاضی آن نامیده می شود.
انتظارات ریاضی از یک متغیر تصادفی گسسته، مجموع حاصل از تمام مقادیر ممکن آن و احتمالات این مقادیر است:
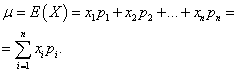
مثال 1یک قرعه کشی برد-برد ترتیب داد. 1000 برد وجود دارد که 400 مورد آن 10 روبل است. هر کدام 300-20 روبل هر کدام 200 تا 100 روبل. و هر کدام 100 - 200 روبل. میانگین برد برای شخصی که یک بلیط می خرد چقدر است؟
راه حل. ما میانگین بازده اگر مبلغ کلبرد، که برابر است با 10 * 400 + 20 * 300 + 100 * 200 + 200 * 100 = 50000 روبل، تقسیم بر 1000 (مبلغ کل برد). سپس 50000/1000 = 50 روبل می گیریم. اما عبارت برای محاسبه سود متوسط را می توان به شکل زیر نیز نشان داد:
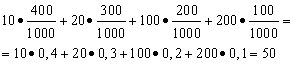
از سوی دیگر، در این شرایط، مقدار برد یک متغیر تصادفی است که می تواند مقادیر 10، 20، 100 و 200 روبل را به خود اختصاص دهد. با احتمالات به ترتیب برابر با 0.4; 0.3; 0.2; 0.1. بنابراین، میانگین سود مورد انتظار برابر با مجموع استمحصولات اندازه برنده ها با احتمال به دست آوردن آنها.
مثال 2ناشر تصمیم به انتشار گرفت کتاب جدید. او قرار است کتاب را به قیمت 280 روبل بفروشد که 200 روبل به او، 50 روبل به کتابفروشی و 30 روبل به نویسنده داده می شود. این جدول اطلاعاتی در مورد هزینه چاپ کتاب و احتمال فروش ارائه می دهد. یک عدد مشخصنسخه هایی از کتاب
سود مورد انتظار ناشر را بیابید.
راه حل. متغیر تصادفی "سود" برابر است با تفاوت بین درآمد حاصل از فروش و بهای تمام شده هزینه ها. به عنوان مثال، اگر 500 نسخه از یک کتاب فروخته شود، درآمد حاصل از فروش 200 * 500 = 100000 و هزینه چاپ 225000 روبل است. بنابراین، ناشر با ضرر 125000 روبلی مواجه است. جدول زیر مقادیر مورد انتظار متغیر تصادفی - سود را خلاصه می کند:
| عدد | سود ایکسمن | احتمال پمن | ایکسمن پمن |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| جمع: | 1,00 | 25000 |
بنابراین، انتظار ریاضی سود ناشر را به دست می آوریم:
![]() .
.
مثال 3شانس زدن با یک ضربه پ= 0.2. میزان مصرف پوسته هایی را که انتظار ریاضی تعداد ضربه ها برابر با 5 را فراهم می کنند، تعیین کنید.
راه حل. از همان فرمول انتظاری که تاکنون استفاده کرده ایم بیان می کنیم ایکس- مصرف پوسته:
![]() .
.
مثال 4انتظارات ریاضی از یک متغیر تصادفی را تعیین کنید ایکستعداد ضربه با سه ضربه، در صورت احتمال ضربه زدن با هر شلیک پ = 0,4 .
نکته: احتمال مقادیر یک متغیر تصادفی را پیدا کنید فرمول برنولی .
ویژگی های انتظار
ویژگی های انتظار ریاضی را در نظر بگیرید.
ملک 1.انتظار ریاضی یک مقدار ثابت برابر با این ثابت است:
ملک 2.عامل ثابت را می توان از علامت انتظار خارج کرد:
![]()
ملک 3.انتظار ریاضی از مجموع (تفاوت) متغیرهای تصادفی برابر است با مجموع (تفاوت) انتظارات ریاضی آنها:
ملک 4.انتظارات ریاضی حاصل ضرب متغیرهای تصادفی برابر است با حاصل ضرب انتظارات ریاضی آنها:
ملک 5.اگر تمام مقادیر متغیر تصادفی ایکسکاهش (افزایش) به همان تعداد از جانب، سپس انتظارات ریاضی آن به همان مقدار کاهش می یابد (افزایش می یابد):
![]()
زمانی که نمی توان فقط به انتظارات ریاضی محدود شد
در بیشتر موارد، تنها انتظارات ریاضی نمی توانند به اندازه کافی متغیر تصادفی را مشخص کنند.
اجازه دهید متغیرهای تصادفی ایکسو Yتوسط قوانین توزیع زیر ارائه می شود:
| معنی ایکس | احتمال |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| معنی Y | احتمال |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
انتظارات ریاضی از این مقادیر یکسان است - برابر با صفر:
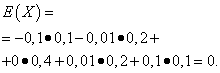
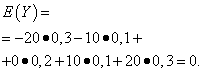
با این حال، توزیع آنها متفاوت است. مقدار تصادفی ایکسفقط می تواند مقادیری را بگیرد که با انتظارات ریاضی و متغیر تصادفی کمی متفاوت است Yمی تواند مقادیری را بگیرد که به طور قابل توجهی از انتظارات ریاضی منحرف می شود. مثال مشابه: دستمزد متوسط امکان قضاوت در مورد نسبت کارگران با دستمزد بالا و پایین را ممکن نمی سازد. به عبارت دیگر، با انتظارات ریاضی نمی توان قضاوت کرد که حداقل به طور متوسط چه انحرافی از آن ممکن است. برای این کار باید واریانس یک متغیر تصادفی را پیدا کنید.
پراکندگی یک متغیر تصادفی گسسته
پراکندگیمتغیر تصادفی گسسته ایکسانتظار ریاضی مربع انحراف آن از انتظار ریاضی نامیده می شود:
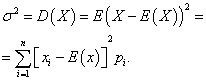
انحراف معیار یک متغیر تصادفی ایکستماس گرفت مقدار حسابیجذر واریانس آن:
![]() .
.
مثال 5واریانس و انحراف معیار متغیرهای تصادفی را محاسبه کنید ایکسو Y، که قوانین توزیع آن در جداول بالا آورده شده است.
راه حل. انتظارات ریاضی از متغیرهای تصادفی ایکسو Yهمانطور که در بالا مشاهده شد، برابر با صفر هستند. با توجه به فرمول پراکندگی برای E(ایکس)=E(y)=0 دریافت می کنیم:

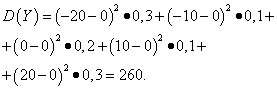
سپس انحراف معیار متغیرهای تصادفی ایکسو Yتشکیل می دهند
![]() .
.
بنابراین، با همان انتظارات ریاضی، واریانس متغیر تصادفی ایکسبسیار کوچک و تصادفی Y- قابل توجه. این نتیجه تفاوت در توزیع آنهاست.
مثال 6سرمایه گذار دارای 4 پروژه سرمایه گذاری جایگزین است. جدول داده های مربوط به سود مورد انتظار در این پروژه ها را با احتمال مربوطه خلاصه می کند.
| پروژه 1 | پروژه 2 | پروژه 3 | پروژه 4 |
| 500, پ=1 | 1000, پ=0,5 | 500, پ=0,5 | 500, پ=0,5 |
| 0, پ=0,5 | 1000, پ=0,25 | 10500, پ=0,25 | |
| 0, پ=0,25 | 9500, پ=0,25 |
برای هر جایگزین انتظارات ریاضی، واریانس و انحراف معیار را پیدا کنید.
راه حل. اجازه دهید نشان دهیم که چگونه این مقادیر برای جایگزین سوم محاسبه می شود:
جدول مقادیر یافت شده را برای همه گزینه ها خلاصه می کند.
همه جایگزین ها انتظارات ریاضی یکسانی دارند. این بدان معناست که در دراز مدت همه درآمد یکسانی دارند. انحراف استاندارد را می توان به عنوان معیاری از ریسک تفسیر کرد - هر چه بزرگتر باشد، ریسک سرمایه گذاری بیشتر است. سرمایهگذاری که ریسک زیادی نمیخواهد، پروژه 1 را انتخاب میکند زیرا دارای کمترین انحراف معیار (0) است. اگر سرمایه گذار ریسک و بازده بالا را در یک دوره کوتاه ترجیح دهد، پروژه با بیشترین انحراف معیار - پروژه 4 را انتخاب می کند.
خواص پراکندگی
اجازه دهید خواص پراکندگی را ارائه کنیم.
ملک 1.پراکندگی یک مقدار ثابت صفر است:
ملک 2.ضریب ثابت را می توان با مربع کردن آن از علامت پراکندگی خارج کرد:
![]() .
.
ملک 3.واریانس یک متغیر تصادفی برابر با انتظار ریاضی مربع این مقدار است که مجذور انتظارات ریاضی خود مقدار از آن کم می شود:
![]() ,
,
جایی که ![]() .
.
ملک 4.واریانس مجموع (تفاوت) متغیرهای تصادفی برابر است با مجموع (تفاوت) واریانس آنها:
مثال 7مشخص است که یک متغیر تصادفی گسسته ایکسفقط دو مقدار را می گیرد: -3 و 7. علاوه بر این، انتظارات ریاضی مشخص است: E(ایکس) = 4 . واریانس یک متغیر تصادفی گسسته را پیدا کنید.
راه حل. با نشان دادن پاحتمالی که با آن یک متغیر تصادفی یک مقدار می گیرد ایکس1 = −3 . سپس احتمال مقدار ایکس2 = 7 1 خواهد بود پ. بیایید معادله انتظارات ریاضی را استخراج کنیم:
E(ایکس) = ایکس 1 پ + ایکس 2 (1 − پ) = −3پ + 7(1 − پ) = 4 ,
جایی که احتمالات را بدست می آوریم: پ= 0.3 و 1 - پ = 0,7 .
قانون توزیع یک متغیر تصادفی:
| ایکس | −3 | 7 |
| پ | 0,3 | 0,7 |
ما واریانس این متغیر تصادفی را با استفاده از فرمول از ویژگی 3 واریانس محاسبه می کنیم:
D(ایکس) = 2,7 + 34,3 − 16 = 21 .
انتظارات ریاضی یک متغیر تصادفی را خودتان پیدا کنید و سپس راه حل را ببینید
مثال 8متغیر تصادفی گسسته ایکسفقط دو مقدار می گیرد. مقدار بزرگتر 3 را با احتمال 0.4 می گیرد. علاوه بر این، واریانس متغیر تصادفی مشخص است D(ایکس) = 6. انتظارات ریاضی یک متغیر تصادفی را پیدا کنید.
مثال 9یک کوزه شامل 6 توپ سفید و 4 توپ سیاه است. 3 توپ از کوزه گرفته می شود. تعداد توپ های سفید در بین توپ های کشیده شده یک متغیر تصادفی گسسته است ایکس. انتظارات ریاضی و واریانس این متغیر تصادفی را بیابید.
راه حل. مقدار تصادفی ایکسمی تواند مقادیر 0، 1، 2، 3 را بگیرد. احتمالات مربوطه را می توان از قانون ضرب احتمالات. قانون توزیع یک متغیر تصادفی:
| ایکس | 0 | 1 | 2 | 3 |
| پ | 1/30 | 3/10 | 1/2 | 1/6 |
بنابراین انتظار ریاضی از این متغیر تصادفی:
م(ایکس) = 3/10 + 1 + 1/2 = 1,8 .
واریانس یک متغیر تصادفی داده شده عبارت است از:
D(ایکس) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
انتظارات ریاضی و پراکندگی یک متغیر تصادفی پیوسته
برای یک متغیر تصادفی پیوسته، تفسیر مکانیکی انتظار ریاضی همان معنی را حفظ خواهد کرد: مرکز جرم برای یک واحد جرم که به طور پیوسته روی محور x با چگالی توزیع شده است. f(ایکس). در مقابل یک متغیر تصادفی گسسته، که برای آن آرگومان تابع ایکسمنبه طور ناگهانی تغییر می کند، برای یک متغیر تصادفی پیوسته، آرگومان به طور مداوم تغییر می کند. اما انتظارات ریاضی از یک متغیر تصادفی پیوسته با مقدار میانگین آن نیز مرتبط است.
برای یافتن انتظارات ریاضی و واریانس یک متغیر تصادفی پیوسته، باید انتگرال های معین را پیدا کنید. . اگر تابع چگالی یک متغیر تصادفی پیوسته داده شود، آنگاه مستقیماً وارد انتگرال می شود. اگر تابع توزیع احتمال داده شود، با تفکیک آن، باید تابع چگالی را پیدا کنید.
میانگین حسابی تمام مقادیر ممکن یک متغیر تصادفی پیوسته آن نامیده می شود انتظارات ریاضی، با یا نشان داده می شود.
بیایید محاسبه کنیماماسبرتری داشتنواریانس و انحراف معیار نمونه. ما همچنین واریانس یک متغیر تصادفی را در صورتی که توزیع آن مشخص باشد محاسبه می کنیم.
ابتدا در نظر بگیرید پراکندگی، سپس انحراف معیار.
واریانس نمونه
واریانس نمونه (واریانس نمونه،نمونهواریانس) گسترش مقادیر در آرایه را نسبت به .
هر 3 فرمول از نظر ریاضی معادل هستند.
از فرمول اول می توان دریافت که واریانس نمونهمجموع مجذور انحرافات هر مقدار در آرایه است از متوسطتقسیم بر حجم نمونه منهای 1.
پراکندگی نمونه هاتابع DISP() استفاده می شود، eng. نام VAR، یعنی. تنوع از MS EXCEL 2010، توصیه می شود از آنالوگ DISP.V() , eng. نام VARS، یعنی. واریانس نمونه علاوه بر این، با شروع از نسخه MS EXCEL 2010، یک تابع DISP.G () وجود دارد، eng. نام VARP، یعنی VARIance جمعیت که محاسبه می کند پراکندگیبرای جمعیت . کل تفاوت به مخرج برمی گردد: به جای n-1 مانند DISP.V() ، DISP.G() فقط n در مخرج دارد. قبل از MS EXCEL 2010، از تابع VARP() برای محاسبه واریانس جمعیت استفاده می شد.
واریانس نمونه
=SQUARE(نمونه)/(COUNT(نمونه)-1)
=(SUMSQ(نمونه)-COUNT(نمونه)*AVERAGE(نمونه)^2)/ (COUNT(نمونه)-1)- فرمول معمول
=SUM((Sample -AVERAGE(Sample))^2)/ (COUNT(Sample)-1) –
واریانس نمونهفقط در صورتی برابر 0 است که همه مقادیر با یکدیگر برابر باشند و بر این اساس برابر باشند مقدار میانگین. معمولا از ارزش بیشتر پراکندگی، گسترش مقادیر در آرایه بیشتر است.
واریانس نمونهاست تخمین نقطه ای پراکندگیتوزیع متغیر تصادفی که از آن نمونه. در مورد ساختمان فاصله اطمینان هنگام ارزیابی پراکندگیرا می توان در مقاله خواند.
واریانس یک متغیر تصادفی
برای محاسبه پراکندگیمتغیر تصادفی، شما باید آن را بدانید.
برای پراکندگیمتغیر تصادفی X اغلب از علامت Var(X) استفاده می کند. پراکندگیبرابر است با مربع انحراف از میانگین E(X): Var(X)=E[(X-E(X)) 2 ]
پراکندگیبا فرمول محاسبه می شود:

که در آن x i مقداری است که متغیر تصادفی می تواند بگیرد، و μ مقدار متوسط ()، p(x) احتمال این است که متغیر تصادفی مقدار x را بگیرد.
اگر متغیر تصادفی دارای پراکندگیبا فرمول محاسبه می شود:

بعد، ابعاد، اندازه پراکندگیمربوط به مربع واحد اندازه گیری مقادیر اصلی است. به عنوان مثال، اگر مقادیر در نمونه اندازه گیری وزن قطعه (به کیلوگرم) باشد، بعد واریانس کیلوگرم 2 خواهد بود. تفسیر این می تواند دشوار باشد، بنابراین، برای توصیف گسترش ارزش ها، مقداری برابر با ریشه دوم پراکندگی – انحراف معیار.
برخی از خواص پراکندگی:
Var(X+a)=Var(X)، که در آن X یک متغیر تصادفی و a یک ثابت است.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2=E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
این خاصیت پراکندگی در مقاله در مورد رگرسیون خطی.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y)، که در آن X و Y متغیرهای تصادفی هستند، Cov(X;Y) کوواریانس این متغیرهای تصادفی است.
اگر متغیرهای تصادفی مستقل باشند، آنها کوواریانس 0 است و از این رو Var(X+Y)=Var(X)+Var(Y) است. این ویژگی واریانس در خروجی استفاده می شود.
اجازه دهید نشان دهیم که برای مقادیر مستقل Var(X-Y)=Var(X+Y). در واقع، Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var(X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). این ویژگی واریانس برای رسم استفاده می شود.
انحراف استاندارد نمونه
انحراف استاندارد نمونهاندازه گیری میزان پراکندگی گسترده مقادیر در نمونه نسبت به آنها است.
طبق تعریف، انحراف معیاربرابر است با جذر پراکندگی:

انحراف معیاربزرگی مقادیر موجود در آن را در نظر نمی گیرد نمونه برداری، اما فقط میزان پراکندگی مقادیر در اطراف آنها است وسط. برای روشن شدن این موضوع مثالی می زنیم.
بیایید انحراف معیار را برای 2 نمونه محاسبه کنیم: (1؛ 5؛ 9) و (1001؛ 1005؛ 1009). در هر دو مورد s=4. بدیهی است که نسبت انحراف معیار به مقادیر آرایه برای نمونه ها به طور قابل توجهی متفاوت است. برای چنین مواردی استفاده کنید ضریب تغییرات(ضریب تغییرات، CV) - نسبت انحراف معیاربه میانگین حسابی، به صورت درصد بیان می شود.
در MS EXCEL 2007 و نسخه های قبلی برای محاسبه انحراف استاندارد نمونهتابع =STDEV() استفاده می شود، eng. نام STDEV، یعنی. انحراف معیار. از MS EXCEL 2010، توصیه می شود از آنالوگ آن استفاده کنید = STDEV.B () , eng. نام STDEV.S، یعنی. نمونه انحراف استاندارد.
علاوه بر این، با شروع از نسخه MS EXCEL 2010، یک تابع STDEV.G () , eng. نام STDEV.P، یعنی. انحراف استاندارد جمعیت که محاسبه می کند انحراف معیاربرای جمعیت. کل تفاوت به مخرج برمی گردد: به جای n-1 مانند STDEV.V() ، STDEV.G() فقط n در مخرج دارد.
انحراف معیارهمچنین می توان مستقیماً از فرمول های زیر محاسبه کرد (به فایل نمونه مراجعه کنید)
=SQRT(SQUADROTIV(نمونه)/(COUNT(نمونه)-1))
=SQRT((SUMSQ(نمونه)-COUNT(نمونه)*AVERAGE(نمونه)^2)/(COUNT(نمونه)-1))
سایر اقدامات پراکندگی
تابع SQUADRIVE() با محاسبه می شود ام ام مجذور انحراف مقادیر از آنها وسط. این تابع همان نتیجه را با فرمول =VAR.G( نمونه)*بررسی( نمونه) ، جایی که نمونه- ارجاع به محدوده ای حاوی آرایه ای از مقادیر نمونه (). محاسبات در تابع QUADROTIV() طبق فرمول انجام می شود:

تابع SROOT() نیز اندازه گیری پراکندگی مجموعه ای از داده ها است. تابع SIROTL() میانگین مقادیر مطلق انحراف مقادیر از وسط. این تابع همان نتیجه فرمول را برمی گرداند =SUMPRODUCT(ABS(Sample-AVERAGE(Sample)))/COUNT(Sample)، جایی که نمونه- ارجاع به یک محدوده حاوی آرایه ای از مقادیر نمونه.
محاسبات در تابع SROOTKL () طبق فرمول انجام می شود:

با این حال، این ویژگی به تنهایی برای مطالعه یک متغیر تصادفی کافی نیست. دو تیرانداز را تصور کنید که در حال شلیک به یک هدف هستند. یکی با دقت شلیک می کند و نزدیک به مرکز ضربه می زند و دیگری ... فقط سرگرم می شود و حتی هدف نمی گیرد. اما آنچه خنده دار است این است میانگیننتیجه دقیقاً مشابه تیرانداز اول خواهد بود! این وضعیت به صورت مشروط با متغیرهای تصادفی زیر نشان داده می شود:
انتظار ریاضی "تک تیرانداز" برابر است، با این حال، برای "فرد جالب": - آن نیز صفر است!
بنابراین، نیاز به تعیین کمیت تا کجا وجود دارد پراکنده شده استگلوله ها (مقادیر یک متغیر تصادفی) نسبت به مرکز هدف (انتظار). خوب و پراکندگیترجمه از لاتین فقط به عنوان پراکندگی .
بیایید ببینیم چگونه این تعریف شده است. مشخصه عددیدر یکی از نمونه های قسمت اول درس: 
در آنجا یک انتظار ریاضی ناامیدکننده از این بازی پیدا کردیم و اکنون باید واریانس آن را محاسبه کنیم که نشان داده شده استاز طریق .
بیایید دریابیم که بردها/باختها نسبت به مقدار متوسط چقدر "پراکنده" هستند. بدیهی است که برای این باید محاسبه کنیم تفاوتبین مقادیر یک متغیر تصادفیو او انتظارات ریاضی:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
اکنون به نظر می رسد لازم است نتایج را جمع بندی کنیم، اما این راه خوب نیست - به این دلیل که نوسانات به سمت چپ با نوسانات سمت راست یکدیگر را خنثی می کنند. بنابراین، برای مثال، تیرانداز "آماتور". (مثال بالا)تفاوت ها خواهد بود ![]() ، و وقتی اضافه شوند صفر می دهند، بنابراین ما هیچ تخمینی از پراکندگی تیراندازی او نخواهیم گرفت.
، و وقتی اضافه شوند صفر می دهند، بنابراین ما هیچ تخمینی از پراکندگی تیراندازی او نخواهیم گرفت.
برای دور زدن این ناراحتی، در نظر بگیرید ماژول هاتفاوتها، اما به دلایل فنی، این رویکرد زمانی ریشه دوانده است که آنها مربع شوند. راحت تر است که راه حل را در یک جدول مرتب کنید: 
و در اینجا التماس برای محاسبه است میانگین وزنیمقدار انحرافات مجذور چیست؟ مال آن هاست ارزش مورد انتظار، که معیار پراکندگی است:
![]() – تعریفپراکندگی بلافاصله از تعریف مشخص می شود که واریانس نمی تواند منفی باشد- برای تمرین توجه داشته باشید!
– تعریفپراکندگی بلافاصله از تعریف مشخص می شود که واریانس نمی تواند منفی باشد- برای تمرین توجه داشته باشید!
بیایید به یاد بیاوریم که چگونه انتظارات را پیدا کنیم. مجذور اختلافات را در احتمالات مربوطه ضرب کنید (ادامه جدول):
- به بیان مجازی، این "نیروی کشش" است،
و نتایج را خلاصه کنید:
آیا فکر نمی کنید که در پس زمینه بردها، نتیجه خیلی بزرگ بود؟ درست است - ما در حال مربع کردن بودیم و برای بازگشت به بعد بازی خود باید استخراج کنیم ریشه دوم. این مقدار نامیده می شود انحراف معیار
و نشان داد نامه یونانی"سیگما":
گاهی به این معنا گفته می شود انحراف معیار .
معنی آن چیست؟ اگر با انحراف معیار از انتظار ریاضی به چپ و راست منحرف شویم: ![]()
- سپس محتمل ترین مقادیر متغیر تصادفی روی این بازه متمرکز می شود. آنچه ما در واقع می بینیم:
با این حال، این اتفاق افتاد که در تجزیه و تحلیل پراکندگی تقریباً همیشه با مفهوم پراکندگی عمل می شود. بیایید ببینیم در رابطه با بازی ها چه معنایی دارد. اگر در مورد تیراندازان ما در مورد "دقت" ضربه ها نسبت به مرکز هدف صحبت می کنیم، در اینجا پراکندگی دو چیز را مشخص می کند:
اولاً بدیهی است که با افزایش نرخ ها، واریانس نیز افزایش می یابد. بنابراین، برای مثال، اگر 10 برابر افزایش دهیم، انتظار ریاضی 10 برابر و واریانس 100 برابر افزایش می یابد. (به محض اینکه یک مقدار درجه دوم باشد). اما توجه داشته باشید که قوانین بازی تغییر نکرده است! فقط نرخ ها تغییر کرده اند، به طور کلی، ما قبلاً 10 روبل شرط می کردیم، اکنون 100.
دومین نکته جالب تر این است که واریانس سبک بازی را مشخص می کند. به طور ذهنی نرخ بازی را اصلاح کنید در یک سطح معینو ببینید اینجا چیست:
یک بازی با واریانس کم یک بازی محتاطانه است. بازیکن تمایل دارد که قابل اعتمادترین طرح ها را انتخاب کند، جایی که در یک زمان زیاد از دست نمی دهد/برنده می شود. به عنوان مثال، سیستم قرمز/مشکی در رولت (به مثال 4 مقاله مراجعه کنید متغیرهای تصادفی) .
بازی با واریانس بالا او اغلب نامیده می شود پراکندگیبازی این یک سبک بازی ماجراجویانه یا تهاجمی است که در آن بازیکن طرح های "آدرنالین" را انتخاب می کند. حداقل یادمون باشه "مارتینگل"، که در آن مبالغ مورد نظر مرتبهای بزرگتر از بازی «آرام» پاراگراف قبلی است.
وضعیت در پوکر نشان دهنده است: به اصطلاح وجود دارد تنگبازیکنانی که تمایل دارند محتاط باشند و با سرمایه بازی خود "لرزند". (بانک). جای تعجب نیست که سرمایه آنها نوسان زیادی ندارد (واریانس کم). برعکس، اگر بازیکنی واریانس بالایی داشته باشد، مهاجم است. او اغلب ریسک می کند، شرط بندی های بزرگ می کند و هم می تواند یک بانک بزرگ را بشکند و هم تکه تکه شود.
همین اتفاق در فارکس و غیره رخ می دهد - نمونه های زیادی وجود دارد.
علاوه بر این، در همه موارد مهم نیست که بازی برای یک پنی باشد یا برای هزاران دلار. هر سطح دارای بازیکنان واریانس کم و زیاد خود است. خوب، برای برد متوسط، همانطور که به یاد داریم، "مسئول" ارزش مورد انتظار.
احتمالاً متوجه شده اید که یافتن واریانس یک فرآیند طولانی و پر زحمت است. اما ریاضیات سخاوتمندانه است:
فرمول برای یافتن واریانس
این فرمول مستقیماً از تعریف واریانس گرفته شده است و ما بلافاصله آن را در گردش قرار می دهیم. من پلاک را با بازی خودمان از بالا کپی می کنم: 
و انتظار پیدا شده .
واریانس را به روش دوم محاسبه می کنیم. ابتدا، بیایید انتظار ریاضی را پیدا کنیم - مربع متغیر تصادفی. توسط تعریف انتظارات ریاضی:
در این مورد:
بنابراین، طبق فرمول:
همانطور که می گویند، تفاوت را احساس کنید. و البته در عمل بهتر است از فرمول استفاده شود (مگر اینکه شرط اقتضا کند).
ما بر تکنیک حل و طراحی مسلط هستیم:
مثال 6

انتظارات ریاضی، واریانس و انحراف معیار آن را بیابید.
این وظیفه در همه جا یافت می شود، و به عنوان یک قاعده، بدون معنای معنی دار است.
شما می توانید چندین لامپ با اعداد را تصور کنید که در یک دیوانه با احتمالات خاص روشن می شوند :)
راه حل: خلاصه کردن محاسبات اصلی در یک جدول راحت است. ابتدا داده های اولیه را در دو خط بالا می نویسیم. سپس محصولات را محاسبه می کنیم، سپس و در نهایت مجموع ستون سمت راست را محاسبه می کنیم: 
در واقع، تقریبا همه چیز آماده است. در خط سوم، یک انتظار ریاضی آماده ترسیم شد: ![]() .
.
پراکندگی با فرمول محاسبه می شود:
و در نهایت انحراف معیار:
- شخصاً من معمولاً 2 رقم اعشار گرد می کنم.
تمام محاسبات را می توان در یک ماشین حساب و حتی بهتر از آن - در اکسل انجام داد:
اینجا اشتباه کردن سخته :)
پاسخ:
آنهایی که آرزو دارند می توانند زندگی خود را بیشتر ساده کنند و از من استفاده کنند ماشین حساب (نسخه ی نمایشی)، که نه تنها به صورت آنی این مشکل را حل می کند، بلکه می سازد گرافیک موضوعی (زود بیا). برنامه می تواند دانلود در کتابخانه- اگر حداقل یکی را دانلود کرده اید مطالب آموزشییا دریافت کنید یک راه دیگر. با تشکر برای حمایت از پروژه!
چند کار برای راه حل مستقل:
مثال 7
واریانس متغیر تصادفی مثال قبلی را بر اساس تعریف محاسبه کنید.
و یک مثال مشابه:
مثال 8
یک متغیر تصادفی گسسته توسط قانون توزیع خودش داده می شود:

بله، مقادیر متغیر تصادفی می تواند بسیار بزرگ باشد (نمونه ای از کار واقعی)و در اینجا در صورت امکان از Excel استفاده کنید. همانطور که، به هر حال، در مثال 7 - سریعتر، قابل اعتمادتر و دلپذیرتر است.
راه حل ها و پاسخ ها در پایین صفحه.
در پایان بخش دوم درس، ما یک کار معمولی دیگر را تجزیه و تحلیل خواهیم کرد، حتی می توان گفت یک ریبوس کوچک:
مثال 9
یک متغیر تصادفی گسسته می تواند تنها دو مقدار بگیرد: و، و. احتمال، انتظارات ریاضی و واریانس مشخص است.
راه حل: بیایید با یک احتمال مجهول شروع کنیم. از آنجایی که یک متغیر تصادفی می تواند تنها دو مقدار بگیرد، پس مجموع احتمالات رویدادهای مربوطه:
و از آن پس .
باقی می ماند برای پیدا کردن ...، گفتن آسان :) اما اوه خوب، شروع شد. با تعریف انتظارات ریاضی: ![]() - مقادیر شناخته شده را جایگزین کنید:
- مقادیر شناخته شده را جایگزین کنید:
![]() - و هیچ چیز دیگری نمی توان از این معادله خارج کرد، به جز اینکه می توانید آن را در جهت معمول بازنویسی کنید:
- و هیچ چیز دیگری نمی توان از این معادله خارج کرد، به جز اینکه می توانید آن را در جهت معمول بازنویسی کنید: ![]()

یا: ![]()
در مورد اقدامات بعدی، فکر می کنم می توانید حدس بزنید. بیایید سیستم را ایجاد و حل کنیم: 
اعداد اعشاری- البته این مایه شرمساری کامل است. هر دو معادله را در 10 ضرب کنید: 
و تقسیم بر 2: 
این خیلی بهتر است. از معادله 1 بیان می کنیم: ![]() (این راه ساده تر است)- جایگزین در معادله 2:
(این راه ساده تر است)- جایگزین در معادله 2:
![]()
ما در حال ساختن هستیم مربعو ساده سازی ها را انجام دهید: 
ضرب می کنیم در: 
در نتیجه، معادله درجه دوم، متمایز آن را پیدا کنید:
- کامل!
و ما دو راه حل دریافت می کنیم:
1) اگر ![]() ، سپس
، سپس ![]() ;
;
2) اگر ![]() ، سپس .
، سپس .
اولین جفت مقادیر شرط را برآورده می کند. با احتمال زیاد، همه چیز درست است، اما، با این وجود، قانون توزیع را می نویسیم: 
و یک بررسی انجام دهید، یعنی انتظار را پیدا کنید:
