Експоненциално изглаждане и модели за прогнозиране на времеви редове. Метод на експоненциално изглаждане на подвижна средна в Excel
Идентифицирането и анализирането на тенденцията на времевия ред често се извършва с помощта на неговото подравняване или изглаждане. Експоненциалното изглаждане е една от най-простите и често срещани техники за подравняване на серии. Експоненциалното изглаждане може да бъде представено като филтър, чийто вход се получава последователно от членовете на оригиналната серия, а на изхода се формират текущите стойности на експоненциалната средна стойност.
Нека е времева серия.
Експоненциалното изглаждане на серията се извършва по рекурентната формула: , .
Колкото по-малък е α, толкова по-филтрирани, потиснати са флуктуациите на оригиналната серия и шума.
Ако тази рекурсивна връзка се използва последователно, тогава експоненциалната средна стойност може да бъде изразена по отношение на стойностите на времевия ред X.
Ако до момента на започване на изглаждането съществуват по-ранни данни, тогава средноаритметичната стойност на всички или някои от наличните данни може да се използва като първоначална стойност.
След появата на трудовете на Р. Браун експоненциалното изглаждане често се използва за решаване на проблема с краткосрочното прогнозиране на времеви редове.
Формулиране на проблема
Нека времевият ред е даден: .
Необходимо е да се реши проблемът с прогнозирането на времеви редове, т.е. намирам
Прогнозен хоризонт, необходимо е, че
За да вземем предвид остаряването на данните, въвеждаме ненарастваща последователност от тегла, след което
Кафяв модел
Да предположим, че D е малък (краткосрочна прогноза), тогава за решаване на такъв проблем използвайте кафяв модел.
Ако разгледаме прогнозата една стъпка напред, тогава - грешката на тази прогноза, а новата прогноза се получава в резултат на коригиране на предишната прогноза, като се вземе предвид нейната грешка - същността на адаптацията.
При краткосрочното прогнозиране е желателно да се отразят новите промени възможно най-бързо и в същото време да се „почисти“ серията от случайни колебания възможно най-добре. Че. увеличаване на тежестта на по-скорошни наблюдения: .
От друга страна, за да се изгладят случайните отклонения, α трябва да се намали: .
Че. тези две изисквания са в конфликт. Търсенето на компромисна стойност на α е проблемът на оптимизацията на модела. Обикновено α се взема от интервала (0,1/3).
Примери

работа експоненциално изглажданес α=0,2 въз основа на данните от месечните отчети за продажбите на чужда марка автомобили в Русия за периода от януари 2007 г. до октомври 2008 г. Нека да отбележим резки спадове през януари и февруари, когато продажбите традиционно намаляват и се увеличават в началото на лятото .
проблеми
Моделът работи само с малък прогнозен хоризонт. Тенденциите и сезонните промени не се вземат предвид. За да се вземе предвид тяхното влияние, се предлага да се използват следните модели: Holt (взема се предвид линейната тенденция), Holt-Winters (мултипликативна експоненциална тенденция и сезонност), Theil-Wage (адитивен линеен тренд и сезонност).
Прост и логически ясен модел на времеви редове има следната форма:
Y t = b + e t
y, = b + rn (11.5)
където b е константа, e е случайна грешка. Константата b е относително стабилна за всеки интервал от време, но може също така да се променя бавно с течение на времето. Един интуитивен начин за извличане на стойността на b от данните е да се използва изглаждане на пълзяща средна, при което на последните наблюдения се дават по-високи тегла от предпоследните, предпоследните са с по-голяма тежест от предпоследните и т.н. Простото експоненциално изглаждане е точно това. Тук експоненциално намаляващи тегла се присвояват на по-стари наблюдения, докато, за разлика от подвижната средна, се вземат предвид всички предишни наблюдения от серията, а не само тези, които са попаднали в определен прозорец. Точната формула за просто експоненциално изглаждане е:
S t = a y t + (1 - a) S t -1
Когато тази формула се прилага рекурсивно, всяка нова изгладена стойност (която също е прогноза) се изчислява като среднопретеглена стойност на текущото наблюдение и изгладената серия. Очевидно резултатът от изглаждането зависи от параметъра a . Ако a е 1, тогава предишните наблюдения се игнорират напълно. Ако a е 0, тогава текущите наблюдения се игнорират. Стойности на a между 0 и 1 дават междинни резултати. Емпиричните изследвания показват, че простото експоненциално изглаждане често дава доста точна прогноза.
На практика обикновено се препоръчва да се приема по-малко от 0,30. Въпреки това, изборът на по-голямо от 0,30 понякога дава по-точна прогноза. Това означава, че е по-добре да се оцени оптимална стойност a върху реални данни, отколкото да използвате общи насоки.
На практика оптималният параметър за изглаждане често се търси с помощта на процедура за търсене в мрежа. Възможният диапазон от стойности на параметрите е разделен от решетка с определена стъпка. Например, помислете за мрежа от стойности от a = 0,1 до a = 0,9 със стъпка от 0,1. След това се избира стойността на a, за която сумата от квадрати (или средни квадрати) на остатъците (наблюдавани стойности минус прогнози една стъпка напред) е минимална.
Microsoft Excelима функцията за експоненциално изглаждане, която обикновено се използва за изглаждане на нивата на емпиричен времеви ред въз основа на простия метод на експоненциално изглаждане. За да извикате тази функция, изберете Инструменти Þ Анализ на данни от лентата с менюта. На екрана ще се отвори прозорецът за анализ на данни, в който трябва да изберете стойността Експоненциално изглаждане (Експоненциално изглаждане). В резултат на това ще се появи диалоговият прозорец Експоненциално изглаждане.
В диалоговия прозорец Експоненциално изглаждане се задават почти същите параметри като в диалоговия прозорец, обсъден по-горе. пълзяща средна.
1. Входен диапазон (Входни данни) - в това поле се въвежда диапазон от клетки, съдържащи стойностите на изследвания параметър.
2. Етикети - това поле за отметка е отметнато, ако
първият ред (колона) във входния диапазон съдържа заглавка. Ако заглавката липсва, отметката трябва да бъде изчистена. В този случай стандартните имена ще бъдат автоматично генерирани за данните от изходния диапазон.
3. Фактор на затихване - в това поле се въвежда стойността на избрания експоненциален коефициент на изглаждане a. Стойността по подразбиране е a = 0,3.
4. Изходни опции - в тази група, освен че можете да зададете диапазон от клетки за изходни данни в полето Изходен диапазон, можете също да изисквате автоматично изчертаване на графика, за което трябва да поставите отметка на опцията Извеждане на диаграма и да изчислите стандартно грешки, за които трябва да поставите отметка на опцията Standard Errog (Стандартни грешки).
Задача 2.С помощта на програмата Microsoft Excel, използвайки функцията Exponential Smoothing, на базата на данните за обема на изхода от Задача 1, изчислете изгладените изходни нива и стандартните грешки. След това представете действителните и предвидените данни с помощта на диаграма. Подсказка: трябва да получите таблица и графика, подобни на тези в задача 1, но с различни изгладени нива и стандартни грешки.
Метод аналитично подравняване
където са теоретичните стойности на времевия ред, изчислени според съответните аналитично уравнениев момент t.
Определянето на теоретичните (изчислените) стойности се извършва въз основа на така наречените адекватни математически модел, който по най-добрия начинпоказва основната тенденция в развитието на динамичния ред.
Най-простите модели (формули), изразяващи тенденцията на развитие, са следните:
Линейна функция, чиято графика е права линия:
Експоненциална функция:
Y t = a 0 * a 1 t
Степенна функция от втори ред, чиято графика е парабола:
Y t = a 0 + a 1 * t + a 2 * t 2
Логаритмична функция:
Y t = a 0 + a 1 * ln T
Изчисляването на параметрите на функцията обикновено се извършва по метода най-малки квадрати, в която минималната точка от сумата на квадратите на отклоненията между теоретичното и емпиричното ниво се приема като решение:
![]()
където - подравнени (изчислени) нива, а Yt - действителни нива.
Параметрите на уравнение a i, удовлетворяващи това условие, могат да бъдат намерени чрез решаване на системата нормални уравнения. Въз основа на намереното уравнение на тенденцията се изчисляват подравнените нива.
подравняване по права линиясе използва в случаите, когато абсолютните печалби са практически постоянни, т.е. когато нивата се променят в аритметична прогресия (или близка до нея).
Подравняване по експоненциална функция се прилага, когато серията отразява развитието в геометричната професия, т.е. факторите на растеж на веригата са практически постоянни.
Подравняване по степенна функция (парабола от втори ред) се използва, когато динамичните редове се променят с константа верижно темпорастеж.
Подравняване по логаритмична функция се използва, когато серията отразява развитие с по-бавен растеж в края на периода, т.е. когато нарастването на крайните нива на динамичния ред клони към нула.
Според изчислените параметри се синтезира трендовият модел на функцията, т.е. получаване на стойности a 0 , a 1 , a ,2 и заместването им в желаното уравнение.
Правилността на изчисленията на аналитичните нива може да се провери чрез следното условие: сумата от стойностите на емпиричните серии трябва да съвпада със сумата на изчислените нива на подравнените серии. В този случай може да възникне малка грешка в изчисленията поради закръгляване на изчислените стойности:
За да се оцени точността на модела на тенденцията, се използва коефициентът на определяне:

където е дисперсията на теоретичните данни, получени от тренд модела, и е дисперсията на емпиричните данни.
Моделът на тенденцията е адекватен на изследвания процес и отразява тенденцията на неговото развитие при стойности на R 2, близки до 1.
След като изберете най-адекватния модел, можете да направите прогноза за всеки от периодите. При правенето на прогнози те оперират не с точкова, а с интервална оценка, определяща т. нар. доверителни интервали на прогнозата. Стойността на доверителния интервал се определя в общ изгледпо следния начин:

къде е средната стойност стандартно отклонениеот тенденцията та-таблична стойност на t-теста на Student на ниво на значимост а, което зависи от нивото на значимост а(%) и брой степени на свобода k = n- T.Стойността - се определя по формулата:

където и са действителните и изчислените стойности на нивата на динамичната серия; П -брой нива на редове; T- броя на параметрите в уравнението на тенденцията (за уравнението на правата линия T - 2, за уравнение на парабола от 2-ри ред t = 3).
След необходими изчисленияопределя се интервалът, в който прогнозираната стойност ще се намира с определена вероятност.
Използването на Microsoft Excel за изграждане на модели на тенденции е доста просто. Първо, емпиричните времеви редове трябва да бъдат представени като диаграма от един от следните типове: хистограма, стълбовидна диаграма, графика, точкова диаграма, диаграма с площи и след това щракнете с десния бутон върху един от маркерите за данни на диаграмата. В резултат на това самата времева серия ще бъде маркирана на диаграмата и контекстното меню ще се отвори на екрана. От това меню изберете командата Add Trendline. Ще се покаже диалоговият прозорец Добавяне на линия на тенденция.
В раздела Тип на този диалогов прозорец е избран желаният тип тенденция:
1. линеен (Линеен);
2. логаритмичен (Логаритмичен);
3. полином, от 2-ра до 6-та степен включително (Полином);
4. мощност (Power);
5. експоненциален (Exponential);
6. пълзяща средна, с индикация за периода на изглаждане от 2 до 15 (Moving Average).
В раздела Опции на този диалогов прозорец се задават допълнителни опции за тенденция.
1. Име на линията на тренда (Име на изгладената крива) - в тази група се избира името, което ще се показва на графиката, за да посочи функцията, използвана за изглаждане на времевия ред. Възможни са следните опции:
♦ Автоматично – Когато радиобутонът е зададен на тази позиция, Microsoft Excel автоматично генерира името на функцията за изглаждане на тренда въз основа на избрания тип тренд, като Линеен (Линейна функция).
♦ По избор - Когато радиобутонът е настроен на тази позиция, можете да въведете свое собствено име за функцията на тенденцията в полето вдясно, с дължина до 256 знака.
2. Прогноза (Forecast) - в тази група можете да посочите колко периода напред (поле Forward) искате да проектирате тренд линия в бъдещето и колко периода назад (поле Backward) искате да проектирате тренд линия в миналото (тези полета не са налични в режим на подвижна средна).
3. Задаване на пресечна точка (пресечна крива с Y-ос в точка) - това квадратче за отметка и полето за въвеждане, разположено вдясно, ви позволяват директно да посочите точката, в която тренд линията трябва да пресича Y-оста (тези полета не са налични за всички режими).
4. Показване на уравнението на диаграмата - когато тази опция е отметната, уравнение, описващо изглаждащата тренд линия, ще бъде показано на диаграмата.
5. Покажете стойността R-квадрат на диаграмата R2)-когато това квадратче е отметнато, диаграмата ще показва стойността на коефициента на детерминация.
Лентите за грешки също могат да бъдат показани заедно с линия на тенденция върху графика на времеви серии. За да вмъкнете ленти за грешки, изберете серия от данни, щракнете с десния бутон върху нея и изберете командата Форматиране на серия от данни от изскачащото контекстно меню. На екрана ще се отвори диалоговият прозорец Форматиране на серия от данни, в който трябва да отидете в раздела Y ленти за грешки (Y-грешки).
В този раздел, с помощта на превключвателя Количество на грешката, вие избирате вида на баровете и опцията за тяхното изчисляване в зависимост от вида на грешката.
1. Фиксирана стойност (Fixed value) - когато превключвателят е поставен в тази позиция, постоянната стойност, посочена в полето на брояча вдясно, се приема като стойност на допустимата грешка;
2. Процент (относителна стойност) - когато превключвателят е настроен на тази позиция, допустимото отклонение се изчислява за всяка точка от данни, въз основа на процентната стойност, посочена в полето на брояча вдясно;
3. Стандартно отклонение(я) - когато превключвателят е настроен на тази позиция, стандартното отклонение се изчислява за всяка точка от данни, което след това се умножава по числото, посочено в полето на брояча вдясно (множител);
4. Стандартна грешка - когато превключвателят е поставен в тази позиция, се приема стойността на стандартната грешка, която е постоянна за всички данни;
5. По избор (По избор) - когато превключвателят е настроен на тази позиция, произволен масив от стойности на отклонение се въвежда в положителна и / или отрицателна посока (можете да въведете връзки към диапазон от клетки).
Лентите за грешки също могат да бъдат форматирани. За да направите това, изберете ги, като щракнете с десния бутон на мишката и изберете командата Format Error Bars от изскачащото контекстно меню.
Задача 3.С помощта на програмата Microsoft Excel, въз основа на данните за обема на изданието на Задача 1, трябва:
Представете времева серия като графика, изградена с помощта на съветника за диаграми. След това добавете линия на тенденция, като изберете най-подходящата версия на уравнението.
Представете резултатите под формата на таблица "Избор на уравнението на тренда":
Таблица "Избор на уравнението на тренда"
Представете избраното уравнение графично, като нанесете данните за името на получената функция и стойността на достоверността на апроксимацията (R 2).
Задача 4. Отговорете на следните въпроси:
1. При анализ на тенденцията за определен набор от данни коефициентът на детерминация за линейния модел се оказа 0,95, за логаритмичния модел - 0,8, а за полинома от трета степен - 0,9636. Кой трендов модел е най-адекватен за изследвания процес:
а) линейни;
б) логаритмичен;
в) полином от 3-та степен.
2. Според данните, представени в задача 1, прогнозирайте обема на продукцията през 2003 г. Каква обща тенденция в поведението на изследваното количество следва от резултатите от вашата прогноза:
а) има спад в производството;
б) производството остава на същото ниво;
в) има увеличение на производството.
В този материал бяха разгледани основните характеристики на времевия ред, моделите на разлагане на времевия ред, както и основните методи за изглаждане на серията - методът на плъзгащата се средна, експоненциалното изглаждане и аналитичното подравняване. За да разреши тези проблеми, Microsoft Excel предлага инструменти като Moving Average (Moving Average) и Exponential Smoothing (Exponential Smoothing), които ви позволяват да изгладите нивата на емпиричен времеви ред, както и командата Add Trendiine (Добавяне на тренд линия ), което ви позволява да изграждате модели на тенденции и да правите прогноза въз основа на наличните стойности на времевия ред.
P.S. За да активирате пакета за анализ на данни, изберете командата Инструменти → Анализ на данни (Инструменти → Анализ на данни).
Ако липсва анализ на данни, трябва да изпълните следните стъпки:
1. Изберете командата Инструменти → Добавки (Добавки).
2. Изберете Analysis ToolPak от предложения списък с настройки и след това щракнете върху OK. След това пакетът за персонализиране на Data Analysis ще бъде изтеглен и свързан с Excel. Съответната команда ще се появи в менюто Инструменти.
©2015-2019 сайт
Всички права принадлежат на техните автори. Този сайт не претендира за авторство, но предоставя безплатно използване.
Дата на създаване на страницата: 2016-04-27
Тема 3. Изглаждане и прогнозиране на времеви редове на база тренд модели
|
целизучаването на тази тема е създаването на основна основа за обучение на мениджъри по специалността 080507 в областта на изграждането на модели на различни задачи в областта на икономиката, формирането на систематичен подход към поставянето и решаването на проблеми с прогнозирането сред студентите . Предложеният курс ще позволи на специалистите бързо да се адаптират практическа работа, по-добре е да се ориентирате в научната и техническа информация и литература по специалността, да вземете по-уверени решения, които възникват в работата. Основен задачиизучаването на темата са: студентите придобиват задълбочени теоретични знания за прилагането на прогнозни модели, придобиват стабилни умения за извършване на изследователска работа, способността за решаване на сложни научни проблеми, свързани с изграждането на модели, включително многомерни, способността за логически анализ на получените резултати и определяне на начини за намиране на приемливи решения. |
|
|
Достатъчно прост методидентифицирането на тенденциите на развитие е изглаждането на времевия ред, т.е. замяната на действителните нива с изчислени, които имат по-малки вариации от оригиналните данни. Съответната трансформация се нарича филтриране. Нека разгледаме няколко метода за изглаждане.
3.1. прости средни стойности
Целта на изглаждането е да се изгради прогнозен модел за бъдещи периоди въз основа на минали наблюдения. При метода на простите средни стойностите на променливата се приемат като първоначални данни Yв точки от времето T, а прогнозната стойност се определя като проста средна стойност за следващия период от време. Формулата за изчисление има формата

където нброй наблюдения.
В случай, че стане налично ново наблюдение, новополучената прогноза също трябва да се вземе предвид за прогнозиране за следващия период. Когато се използва този метод, прогнозата се извършва чрез осредняване на всички предишни данни, но недостатъкът на такова прогнозиране е трудността при използването му в модели на тенденции.
3.2. Метод на подвижната средна
Този метод се основава на представяне на серията като сума от сравнително плавен тренд и случаен компонент. Методът се основава на идеята за изчисляване на теоретичната стойност въз основа на локално приближение. За да изградите оценка на тенденцията в точка Tпо стойностите на серията от времевия интервал изчислете теоретичната стойност на серията. Най-широко разпространен в практиката на изглаждащите серии е случаят, когато всички тегла за елементите на интервала са равни помежду си. Поради тази причина този метод се нарича метод на пълзяща средна,тъй като при изпълнение на процедурата се появява прозорец с ширина от (2 м + 1)в целия ред. Ширината на прозореца обикновено се приема нечетна, тъй като теоретичната стойност се изчислява за централната стойност: броя на термините k = 2m + 1с еднакъв брой нива отляво и отдясно на момента T.
Формулата за изчисляване на подвижната средна в този случай приема формата:

Дисперсията на подвижната средна се определя като σ 2 /k,къде през σ2обозначава дисперсията на оригиналните условия на серията, и кинтервал на изглаждане, така че колкото по-голям е интервалът на изглаждане, толкова по-силно е осредняването на данните и толкова по-малко променлива е тенденцията. Най-често изглаждането се извършва върху три, пет и седем члена на оригиналната серия. В този случай трябва да се вземат предвид следните характеристики на плъзгащата се средна: ако разглеждаме серия с периодични колебания с постоянна дължина, тогава при изглаждане на базата на пълзяща средна с интервал на изглаждане, равен или кратен на периода , колебанията ще бъдат напълно елиминирани. Често изглаждането на базата на подвижна средна трансформира серията толкова силно, че идентифицираната тенденция на развитие се проявява само в най- в общи линии, а по-малките, но важни за анализа детайли (вълни, завои и др.) изчезват; след изглаждане, малките вълни понякога могат да променят посоката си към противоположните „ями“ да се появят на мястото на „върхове“ и обратно. Всичко това изисква предпазливост при използването на проста подвижна средна и принуждава да се търсят по-фини методи за описание.
Методът на пълзящата средна не дава стойности на тренда за първата и последната мчленове на ред. Този недостатък е особено забележим в случаите, когато дължината на реда е малка.
3.3. Експоненциално изглаждане
Експоненциално средно y tе пример за асиметрична претеглена подвижна средна, която отчита степента на стареене на данните: „по-стара“ информация с по-малко тегло влиза във формулата за изчисляване на изгладената стойност на нивото на серията
Тук експоненциална средна, заместваща наблюдаваната стойност на серията y t(изглаждането включва всички данни, получени до текущия момент T), α изглаждащ параметър, характеризиращ тежестта на текущото (най-новото) наблюдение; 0< α <1.
Методът се използва за прогнозиране на нестационарни времеви редове със случайни промени в нивото и наклона. Докато се отдалечаваме от текущия момент от времето в миналото, теглото на съответния член от серията бързо (експоненциално) намалява и практически престава да оказва влияние върху стойността на .
Лесно е да се види, че последната връзка ни позволява да дадем следната интерпретация на експоненциалната средна: ако прогнозиране на серийната стойност y t, тогава разликата е грешката на прогнозата. Така че прогнозата за следващия момент във времето t+1взема предвид станалото известно в момента Tгрешка в прогнозата.
Опция за изглаждане α е тегловен фактор. Ако α близо до единица, тогава прогнозата значително отчита големината на грешката на последната прогноза. За малки стойности α прогнозираната стойност е близка до предишната прогноза. Изборът на параметър за изглаждане е доста сложен проблем. Общите съображения са следните: методът е добър за прогнозиране на достатъчно гладки серии. В този случай човек може да избере изглаждаща константа чрез минимизиране на грешката при прогнозиране с една стъпка напред, оценена от последната трета от серията. Някои експерти не препоръчват използването на големи стойности на параметъра за изглаждане. На фиг. 3.1 показва пример на изгладена серия, използваща метода на експоненциално изглаждане за α= 0,1.

Ориз. 3.1. Резултатът от експоненциалното изглаждане при α
=0,1
(1 оригинална серия; 2 изгладени серии; 3 остатъци)
3.4. Експоненциално изглаждане
базиран на тенденции (метод на Холт)
Този метод отчита местната линейна тенденция, която съществува във времевия ред. Ако има възходяща тенденция във времевия ред, тогава наред с оценката на текущото ниво е необходима и оценка на наклона. В техниката на Holt стойностите на нивото и наклона се изглаждат директно чрез използване на различни константи за всеки от параметрите. Изглаждащите константи ви позволяват да оцените текущото ниво и наклон, като ги прецизирате всеки път, когато се правят нови наблюдения.
Методът на Holt използва три формули за изчисление:
- Експоненциално изгладени серии (оценка на текущото ниво)
(3.2) |
- Оценка на тенденцията
(3.3) |
- Прогноза за Рпериоди напред
|
(3.4) |
където α, β изглаждащи константи от интервала .
Уравнение (3.2) е подобно на уравнение (3.1) за просто експоненциално изглаждане, с изключение на трендовия член. Константа β необходими за изглаждане на оценката на тенденцията. В прогнозното уравнение (3.3) прогнозната тенденция се умножава по броя на периодите Р, на който се основава прогнозата, след което този продукт се добавя към текущото ниво на изгладени данни.
Постоянно α и β се избират субективно или чрез минимизиране на грешката при прогнозиране. Колкото по-големи са стойностите на теглата, толкова по-бързо ще се реагира на текущите промени и данните ще бъдат по-изгладени. По-малките тегла правят структурата на изгладените стойности по-малко плоска.
На фиг. 3.2 показва пример за изглаждане на серия с помощта на метода на Холт за стойности α и β равно на 0,1.

Ориз. 3.2. Резултат от изглаждане на Холт
при α
= 0,1
и β
= 0,1
3.5. Експоненциално изглаждане с тенденция и сезонни вариации (метод на Winters)
Ако има сезонни колебания в структурата на данните, трипараметърният експоненциален изглаждащ модел, предложен от Winters, се използва за намаляване на грешките в прогнозата. Този подход е разширение на предишния модел на Holt. За да се отчетат сезонните вариации, тук се използва допълнително уравнение и този метод е напълно описан от четири уравнения:
- Експоненциално изгладени серии
|
(3.5) |

- Оценка на тенденцията
(3.6) |
- Оценка на сезонността
|
(3.7) |
 .
.
- Прогноза за Рпериоди напред
(3.8) |
където α, β, γ постоянно изглаждане за ниво, тенденция и сезонност, съответно; с- продължителността на периода на сезонни колебания.
Уравнение (3.5) коригира изгладената серия. В това уравнение терминът взема предвид сезонността в оригиналните данни. След като сезонността и тенденцията са взети предвид в уравнения (3.6), (3.7), оценките се изглаждат и се прави прогноза в уравнение (3.8).
Точно както в предишния метод, тежестите α, β, γ могат да бъдат избрани субективно или чрез минимизиране на грешката при прогнозиране. Преди да приложите уравнение (3.5), е необходимо да определите началните стойности за изгладената серия L t, тенденция T t, коефициенти на сезонност S t. Обикновено първоначалната стойност на изгладената серия се приема равна на първото наблюдение, тогава тенденцията е нула, а сезонните коефициенти се определят равни на единица.
На фиг. 3.3 показва пример за изглаждане на серия с помощта на метода Winters.

Ориз. 3.3. Резултат от изглаждане по метода Winters
при α
= 0,1
;β
= 0,1; γ = 0,1(1- оригинален ред; 2 изгладен ред; 3 остатъци)
3.6. Прогнозиране на база трендови модели
Доста често времевите редове имат линеен тренд (тренд). Приемайки линеен тренд, трябва да изградите права линия, която най-точно да отразява промяната в динамиката през разглеждания период. Има няколко метода за конструиране на права линия, но най-обективната от формална гледна точка ще бъде конструкция, основана на минимизиране на сумата от отрицателни и положителни отклонения на първоначалните стойности на серията от права линия.
Права линия в двукоординатна система (x, y)може да се определи като пресечна точка на една от координатите прии ъгъла на наклон спрямо оста Х.Уравнението за такава права линия ще изглежда така ![]() където а-пресечна точка; bъгъл на наклон.
където а-пресечна точка; bъгъл на наклон.
За да може правата линия да отразява хода на динамиката, е необходимо да се сведе до минимум сумата от вертикални отклонения. Когато се използва като критерий за оценка на минимизирането на проста сума от отклонения, резултатът няма да бъде много добър, тъй като отрицателните и положителните отклонения взаимно се компенсират. Минимизирането на сумата от абсолютни стойности също не води до задоволителни резултати, тъй като оценките на параметрите в този случай са нестабилни, има и изчислителни трудности при прилагането на такава процедура за оценка. Следователно най-често използваната процедура е да се минимизира сумата на квадратните отклонения, или метод на най-малките квадрати(MNK).
Тъй като серията от начални стойности има колебания, моделът на серията ще съдържа грешки, чиито квадрати трябва да бъдат сведени до минимум

където y i наблюдавана стойност; y i * теоретични стойности на модела; номер на наблюдение.
Когато моделираме тренда на оригиналния времеви ред с помощта на линеен тренд, ще приемем, че
Разделяйки първото уравнение на н, стигаме до следващия
![]()
Заместване на получения израз във второто уравнение на системата (3.10), за коефициента б*получаваме:

3.7. Проверка на годността на модела
Като пример, на фиг. 3.4 показва графика на линейна регресия между мощността на автомобила хи цената му при.

Ориз. 3.4. График на линейна регресия
Уравнението за този случай е: при=1455,3 + 13,4 х. Визуалният анализ на тази фигура показва, че за редица наблюдения има значителни отклонения от теоретичната крива. Остатъчната графика е показана на фиг. 3.5.

Ориз. 3.5. Таблица на остатъците
Анализът на остатъците от регресионната линия може да осигури полезна мярка за това колко добре изчислената регресия отразява реалните данни. Добрата регресия е тази, която обяснява значително количество дисперсия и, обратно, лошата регресия не проследява голямо количество колебания в оригиналните данни. Интуитивно е ясно, че всяка допълнителна информация ще подобри модела, т.е. ще намали необяснимата част от вариацията на променливата при. За да анализираме регресията, ще разложим дисперсията на компоненти. Очевидно е, че
Последният член ще бъде равен на нула, тъй като е сбор от остатъците, така че стигаме до следния резултат
където SS0, SS1, SS2определяне на общата, регресионната и остатъчната сума на квадратите, съответно.
Регресионната сума на квадратите измерва частта от дисперсията, обяснена с линейна връзка; остатъчна част от дисперсията, необяснена с линейна зависимост.
Всяка от тези суми се характеризира със съответния брой степени на свобода (HR), което определя броя на единиците данни, които са независими една от друга. С други думи, сърдечната честота е свързана с броя на наблюденията ни броя на параметрите, изчислен от съвкупността от тези параметри. В разглеждания случай да се изчисли SS0 се определя само една константа (средна стойност), следователно сърдечната честота за SS0 ще бъде (н– 1), пулс за SS 2 - (n - 2)и сърдечната честота за SS 1ще бъде n - (n - 1)=1, тъй като има n - 1 постоянни точки в регресионното уравнение. Точно като сумата на квадратите, сърдечната честота е свързана с
![]()
Сумите на квадратите, свързани с разлагането на дисперсията, заедно със съответните сърдечни честоти, могат да бъдат поставени в така наречената таблица за анализ на дисперсията (ANOVA ANalysis Of VAriance table) (Таблица 3.1).
Таблица 3.1
ANOVA таблица
Източник |
Сбор на квадрати |
Среден квадрат |
|
Регресия |
SS2/ (n-2) |
Използвайки въведеното съкращение за суми от квадрати, определяме коефициент на детерминациякато съотношението на регресионната сума на квадратите към общата сума на квадратите като
|
(3.13) |
Коефициентът на детерминация измерва дела на променливостта в дадена променлива Y, което може да се обясни с помощта на информация за променливостта на независимата променлива х.Коефициентът на определяне се променя от нула, когато хне влияе Y,до един, когато промяната Yнапълно обяснено от промяната х.
3.8. Регресионен прогнозен модел
Най-добрата прогноза е тази с най-малка дисперсия. В нашия случай конвенционалните най-малки квадрати дават най-добрата прогноза от всички методи, които дават безпристрастни оценки, базирани на линейни уравнения. Прогнозната грешка, свързана с процедурата за прогнозиране, може да дойде от четири източника.
Първо, случайният характер на адитивните грешки, обработвани от линейна регресия, гарантира, че прогнозата ще се отклонява от истинските стойности, дори ако моделът е правилно зададен и неговите параметри са точно известни.
Второ, самият процес на оценка въвежда грешка в оценката на параметрите, тъй като те рядко могат да бъдат равни на истинските стойности, въпреки че средно са равни на тях.
Трето, в случай на условна прогноза (в случай на неизвестни точни стойности на независимите променливи), грешката се въвежда с прогнозата на обяснителните променливи.
Четвърто, грешката може да се появи, защото спецификацията на модела е неточна.
В резултат на това източниците на грешки могат да бъдат класифицирани, както следва:
- естеството на променливата;
- естеството на модела;
- грешката, въведена от прогнозата на независими случайни променливи;
- грешка в спецификацията.
Ще разгледаме безусловна прогноза, когато независимите променливи се прогнозират лесно и точно. Започваме разглеждането на проблема с качеството на прогнозата с двойното регресионно уравнение.
![]()
Постановката на проблема в този случай може да се формулира по следния начин: каква ще бъде най-добрата прогноза y T+1, при условие че в модела y = a + bxнастроики аи bпреценено точно и стойността xT+1известен.
Тогава прогнозираната стойност може да се определи като
Тогава грешката в прогнозата ще бъде
![]() .
.
Грешката на прогнозата има две свойства:
Получената дисперсия е минимална сред всички възможни оценки, базирани на линейни уравнения.
Макар че аи b са известни, грешката в прогнозата се появява поради факта, че при Т+1може да не лежи на линията на регресия поради грешка ε T+1, подчинявайки се на нормално разпределение с нулева средна стойност и дисперсия σ2. За да проверим качеството на прогнозата, въвеждаме нормализирана стойност

След това 95% доверителен интервал може да се дефинира, както следва:

където β 0,05квантили на нормалното разпределение.
Границите на интервала от 95% могат да бъдат определени като
Имайте предвид, че в този случай ширината доверителен интервалне зависи от размера Х,а границите на интервала са прави линии, успоредни на регресионните линии.
По-често, когато се конструира регресионна линия и се проверява качеството на прогнозата, е необходимо да се оценят не само регресионните параметри, но и дисперсията на прогнозната грешка. Може да се покаже, че в този случай дисперсията на грешката зависи от стойността (), където е средната стойност на независимата променлива. Освен това, колкото по-дълъг е сериалът, толкова по-точна е прогнозата. Грешката на прогнозата намалява, ако стойността на X T+1 е близо до средната стойност на независимата променлива и, обратно, когато се отдалечава от средната стойност, прогнозата става по-малко точна. На фиг. 3.6 показва резултатите от прогнозата, използвайки уравнението на линейната регресия за 6 интервала от време напред, заедно с доверителните интервали.

Ориз. 3.6. Прогноза с линейна регресия
Както се вижда от фиг. 3.6, тази линия на регресия не описва добре оригиналните данни: има голяма вариация спрямо линията на напасване. За качеството на модела може да се съди и по остатъците, които при задоволителен модел трябва да се разпределят приблизително по нормалния закон. На фиг. 3.7 показва графика на остатъците, изградена с помощта на вероятностна скала.

Фиг.3.7. Таблица на остатъците
Когато се използва такава скала, данните, които се подчиняват на нормалния закон, трябва да лежат на права линия. Както следва от фигурата, точките в началото и края на периода на наблюдение се отклоняват донякъде от правата линия, което показва недостатъчно високо качество на избрания модел под формата на уравнение на линейна регресия.
В табл. Таблица 3.2 показва прогнозните резултати (втора колона) заедно с 95% доверителни интервали (съответно долна трета и горна четвърта колона).
Таблица 3.2
Прогнозни резултати

3.9. Многовариантен регресионен модел
При многовариантна регресия данните за всеки случай включват стойностите на зависимата променлива и всяка независима променлива. Зависима променлива ге случайна променлива, свързана с независимите променливи чрез следната връзка:
където трябва да се определят коефициентите на регресия; ε компонент на грешката, съответстващ на отклонението на стойностите на зависимата променлива от истинското съотношение (приема се, че грешките са независими и имат нормално разпределение с нулева средна стойност и неизвестна дисперсия σ ).
За даден набор от данни оценките на регресионните коефициенти могат да бъдат намерени чрез метода на най-малките квадрати. Ако оценките на OLS са означени с , тогава съответната регресионна функция ще изглежда така:
Остатъците са оценки на компонента на грешката и са подобни на остатъците в случай на проста линейна регресия.
Статистическият анализ на многовариантен регресионен модел се извършва подобно на анализа на проста линейна регресия. Стандартните пакети от статистически програми позволяват да се получат оценки чрез най-малки квадрати за параметрите на модела, оценки на техните стандартни грешки. Освен това можете да получите стойността T-статистика за проверка на значимостта на отделните членове на регресионния модел и стойността Е-статистика за проверка на значимостта на регресионната зависимост.
Формата на разделяне на сумите на квадратите в случай на многовариантна регресия е подобна на израза (3.13), но съотношението за сърдечната честота ще бъде както следва
Отново подчертаваме, че не обемът на наблюденията и кброй променливи в модела. Общата вариация на зависимата променлива се състои от два компонента: вариацията, обяснена от независимите променливи чрез регресионната функция, и необяснимата вариация.
Таблица ANOVA за случая на многовариантна регресия ще има формата, показана в табл. 3.3.
Таблица 3.3
ANOVA таблица
Източник |
Сбор на квадрати |
Среден квадрат |
|
Регресия |
SS2/ (n-k-1) |
Като пример за многовариантна регресия ще използваме данни от пакета Statistica (файл с данни Бедност.Sta)Представените данни са базирани на съпоставка на резултатите от преброяванията от 1960 г. и 1970 г. за произволна извадка от 30 страни. Имената на държавите са въведени като имена на низове и имената на всички променливи в този файл са изброени по-долу:
POP_CHNG изменение на населението за 1960-1970 г.;
N_EMPLD броят на заетите в селското стопанство;
PT_POOR процент на семействата, живеещи под прага на бедността;
TAX_RATE данъчна ставка;
PT_PHONE процент апартаменти с телефон;
PT_RURAL процент от селското население;
ВЪЗРАСТ средна възраст.
Като зависима променлива избираме функцията Pt_Poor, а като независими - всички останали. Изчислените коефициенти на регресия между избраните променливи са дадени в табл. 3.4
Таблица 3.4
Коефициенти на регресия

Тази таблица показва регресионните коефициенти ( AT) и стандартизирани регресионни коефициенти ( бета). С помощта на коеф ATзадава се формата на регресионното уравнение, което в този случай има формата:
Включването в дясната страна само на тези променливи се дължи на факта, че само тези характеристики имат вероятностна стойност Рпо-малко от 0,05 (вижте четвъртата колона на таблица 3.4).
Библиография
- Басовски Л. Е.Прогнозиране и планиране в пазарни условия. - М .: Инфра - М, 2003.
- Бокс Дж., Дженкинс Г.Анализ на времеви редове. Брой 1. Прогноза и управление. – М.: Мир, 1974.
- Боровиков В. П., Ивченко Г. И.Прогнозиране в системата Statistica в Windows среда. - М.: Финанси и статистика, 1999.
- херцог В.Обработка на данни на компютър в примери. - Санкт Петербург: Питър, 1997.
- Ивченко Б. П., Мартищенко Л. А., Иванцов И. Б.Информационна микроикономика. Част 1. Методи за анализ и прогнозиране. - Санкт Петербург: Нордмед-Издат, 1997.
- Кричевски М. Л.Въведение в изкуствените невронни мрежи: Proc. надбавка. - Санкт Петербург: Санкт Петербург. състояние морска техника. ун-т, 1999г.
- Сошникова Л. А., Тамашевич В. Н., Уебе Г. и др.Многомерен статистически анализ в икономиката. – М.: Единство-Дана, 1999.
Очевидно в метода на претеглената пълзяща средна има много начини да се зададат теглата, така че тяхната сума да е равна на 1. Един от тези методи се нарича експоненциално изглаждане. В тази схема на метода на среднопретеглената стойност, за всяко t > 1, прогнозната стойност във време t+1 е претеглената сума на действителните продажби, , за период от време t, и прогнозираните продажби, , за период от време t В други думи,
Експоненциалното изглаждане има изчислителни предимства пред подвижните средни. Тук, за да се изчисли , е необходимо само да се знаят стойностите на , и , (заедно със стойността на α). Например, ако една компания трябва да прогнозира търсенето на 5000 артикула за всеки период от време, тогава ще трябва да съхранява 10 001 стойности на данни (5000 стойности на , 5000 стойности на и стойност α), докато направете прогноза въз основа на пълзяща средна стойност от 8 възела, необходими 40 000 стойности на данни. В зависимост от поведението на данните може да е необходимо да се съхраняват различни стойности на α за всеки продукт, но дори и в този случай количеството съхранявана информация е много по-малко, отколкото при използване на пълзяща средна. Хубавото на експоненциалното изглаждане е, че чрез запазване на α и последната прогноза всички предишни прогнози също се запазват имплицитно.
Нека разгледаме някои свойства на модела на експоненциално изглаждане. Като начало отбелязваме, че ако t > 2, тогава във формула (1) t може да се замени с t–1, т.е. Замествайки този израз в оригиналната формула (1), получаваме
Извършвайки последователно подобни замествания, получаваме следния израз за
Тъй като от неравенството 0< α < 1 следует, что 0 < 1 – α < 1, то Другими словами, наблюдение , имеет больший вес, чем наблюдение , которое, в свою очередь, имеет больший вес, чем . Это иллюстрирует основное свойство модели экспоненциального сглаживания - коэффициенты при убывают при уменьшении номера k. Также можно показать, что сумма всех коэффициентов (включая коэффициент при ), равна 1.
От формула (2) може да се види, че стойността е претеглената сума от всички предишни наблюдения (включително последното наблюдение). Последният член на сумата (2) не е статистическо наблюдение, но чрез "предположение" (можем да приемем, например, че ). Очевидно с увеличаване на t влиянието върху прогнозата намалява и в даден момент може да бъде пренебрегнато. Дори ако стойността на α е достатъчно малка (така че (1 - α) е приблизително равна на 1), стойността ще намалее бързо.
Стойността на параметъра α силно влияе на ефективността на модела за прогнозиране, тъй като α е теглото на най-скорошното наблюдение. Това означава, че трябва да се присвои по-голяма стойност на α в случая, когато последното наблюдение в модела е най-предсказуемо. Ако α е близо до 0, това означава почти пълна увереност в предишната прогноза и игнориране на последното наблюдение.
Виктор имаше проблем: как най-добре да избере стойността на α. Отново инструментът Solver ще ви помогне с това. За да намерите оптималната стойност на α (т.е. тази, при която прогнозната крива ще се отклонява най-малко от кривата на стойността на времевия ред), направете следното.
- Изберете командата Инструменти -> Търсене на решение.
- В диалоговия прозорец Намиране на решение, който се отваря, задайте целевата клетка на G16 (вижте Expo sheet) и укажете, че нейната стойност трябва да бъде минималната.
- Посочете, че клетката, която трябва да се модифицира, е клетка B1.
- Въведете ограничения B1 > 0 и B1< 1
- Като щракнете върху бутона Run, ще получите резултата, показан на Фиг. осем.

Отново, както при метода на претеглената пълзяща средна, най-добрата прогноза ще бъде получена чрез присвояване на пълното тегло на последното наблюдение. Следователно оптималната стойност на α е равна на 1, докато средната абсолютни отклоненияе равно на 6,82 (клетка G16). Виктор получи прогноза, която вече беше виждал.
Методът на експоненциалното изглаждане работи добре в ситуации, в които променливата, която ни интересува, се държи стационарно и нейните отклонения от постоянна стойностса причинени от случайни фактори и не са регулярни. Но: независимо от стойността на параметъра α, методът на експоненциално изглаждане няма да може да предвиди монотонно нарастващи или монотонно намаляващи данни (прогнозираните стойности винаги ще бъдат съответно по-малки или повече от наблюдаваните). Може също така да се покаже, че в модел със сезонни вариации няма да е възможно да се получат задоволителни прогнози с този метод.
Ако статистиката се променя монотонно или е подложена на сезонни промени, са необходими специални методи за прогнозиране, които ще бъдат разгледани по-долу.
Метод на Holt (експоненциално изглаждане с тенденция)
![]() ,
,
Методът на Холт позволява прогнозиране за k времеви периода напред. Методът, както можете да видите, използва два параметъра α и β. Стойностите на тези параметри варират от 0 до 1. Променливата L показва дългосрочното ниво на стойностите или основната стойност на данните от времевия ред. Променливата T показва възможното увеличение или намаляване на стойностите за един период.
Нека разгледаме работата на този метод на нов пример. Светлана работи като анализатор в голяма брокерска фирма. Въз основа на тримесечните отчети, които има за Startup Airlines, тя иска да прогнозира приходите на тази компания за следващото тримесечие. Наличните данни и изградената на тяхна база диаграма се намират в работната книга Startup.xls (фиг. 9). Вижда се, че данните имат ясен тренд (почти монотонно нарастващ). Светлана иска да използва метода на Холт, за да прогнозира печалбата на акция за тринадесетото тримесечие. За да направите това, трябва да зададете първоначалните стойности за L и T. Има няколко възможности за избор: 1) L е равно на стойността на печалбата на акция за първото тримесечие и T = 0; 2) L е равно на средната стойност на печалбата на акция за 12 тримесечия, а T е равно на средната промяна за всичките 12 тримесечия. Има и други опции за първоначалните стойности за L и T, но Светлана избра първата опция.
Тя реши да използва инструмента Find Solution, за да намери оптималната стойност на параметрите α и β, при която стойността на средната абсолютни грешкипроцентът ще бъде минимален. За да направите това, трябва да следвате тези стъпки.
Изберете командата Услуга -> Търсене на решение.
В диалоговия прозорец Търсене на решение, който се отваря, задайте клетка F18 като целева клетка и посочете, че нейната стойност трябва да бъде минимизирана.
В полето Промяна на клетки въведете диапазона от клетки B1:B2. Добавете ограничения B1:B2 > 0 и B1:B2< 1.
Кликнете върху бутона Изпълнение.
Получената прогноза е показана на фиг. десет.
Както се вижда, оптималните стойности се оказаха α = 0,59 и β = 0,42, докато средната абсолютна грешка в проценти е 38%.



Счетоводство сезонни промени
Сезонните промени трябва да се вземат предвид при прогнозиране от данни от времеви редове. Сезонните промени са колебания нагоре и надолу с постоянен период в стойностите на променливата.
Например, ако разгледате продажбите на сладолед по месеци, можете да видите, че през по-топлите месеци (юни до август в северното полукълбо) повече високо нивопродажби, отколкото през зимата, и така всяка година. Тук сезонните колебания са с период от 12 месеца. Ако се използват седмични данни, моделът на сезонните колебания ще се повтаря на всеки 52 седмици. Друг пример е анализиран от седмични отчети за броя на гостите, които са пренощували в хотел, разположен в бизнес център на града. Предполага се, че можем кажи това голямо числоклиенти се очакват във вторник, сряда и четвъртък вечерта, най-малко клиенти ще има в събота и неделя вечерта, а среден брой гости се очаква в петък и понеделник вечер. Тази структура от данни, показваща броя клиенти в различни дни от седмицата, ще се повтаря на всеки седем дни.
Процедурата за изготвяне на сезонно коригирана прогноза се състои от следните четири стъпки:
1) Въз основа на първоначалните данни се определя структурата на сезонните колебания и периодът на тези колебания.
3) Въз основа на данните, от които е изключен сезонният компонент, се прави най-добрата възможна прогноза.
4) Сезонният компонент се добавя към получената прогноза.
Нека илюстрираме този подход с данни за продажбите на въглища (измерени в хиляди тонове) в Съединените щати в продължение на девет години като мениджър в Gillette Coal Mine, Франк трябва да прогнозира търсенето на въглища за следващите две тримесечия. Той въведе данни за цялата въгледобивна индустрия в работната книга Coal.xls и начерта данните (Фигура 11). Графиката показва, че обемите на продажбите са над средното през първото и четвъртото тримесечие (зимен сезон) и под средното през второто и третото тримесечие (пролетно-летните месеци).

Изключване на сезонния компонент
Първо трябва да изчислите средната стойност на всички отклонения за един период на сезонни промени. За изключване на сезонния компонент в рамките на една година се използват данни за четири периода (тримесечия). И за да се изключи сезонният компонент от цялата времева серия, се изчислява последователност от пълзящи средни над възлите T, където T е продължителността на сезонните колебания.За да извърши необходимите изчисления, Франк използва колони C и D, както е показано на фиг. По-долу. Колона C съдържа подвижната средна с 4 възела въз основа на данните в колона B.
Сега трябва да присвоим получените пълзящи средни стойности на средните точки на последователността от данни, от които са изчислени тези стойности. Тази операция се нарича центриранестойности. Ако T е нечетно, тогава първата стойност на подвижната средна (средната стойност на стойностите от първата до Т-точка) трябва да се присвои (T + 1)/2 на точката (например, ако T = 7, тогава първата подвижна средна ще бъде присвоена на четвъртата точка). По същия начин средната стойност на стойностите от втората до (T + 1)-та точка е центрирана в точката (T + 3)/2 и т. н. Центърът на n-тия интервал е в точката (T+ (2n-1))/2.
 |  |
Ако T е четен, както в разглеждания случай, тогава проблемът става малко по-сложен, тъй като тук централните (средните) точки са разположени между точките, за които е изчислена подвижната средна стойност. Следователно центрираната стойност за третата точка се изчислява като средната стойност на първата и втората стойност на подвижната средна. Например, първото число в колона D на центрираните средства на фиг. 12, вляво е (1613 + 1594)/2 = 1603. На фиг. 13 показва графики на необработени данни и центрирани средни стойности.

След това намираме съотношенията на стойностите на точките от данни към съответните стойности на центрираните средни стойности. Тъй като точките в началото и края на последователността от данни нямат съответните центрирани средства (вижте първото и последни ценностив колона D), това действие не се прилага за тези точки. Тези съотношения показват степента, до която стойностите на данните се отклоняват от типичното ниво, определено от центрираните средства. Имайте предвид, че стойностите на съотношението за третите тримесечия са по-малки от 1, а тези за четвъртите тримесечия са по-големи от 1.
 |  |
Тези зависимости са в основата на създаването на сезонни индекси. За изчисляването им изчислените съотношения се групират по тримесечия, както е показано на фиг. 15 в колони G-O.
След това се намират средните стойности на съотношенията за всяко тримесечие (колона E на фиг. 15). Например средната стойност на всички коефициенти за първото тримесечие е 1,108. Тази стойност е сезонният индекс за първото тримесечие, от който може да се заключи, че обемът на продажбите на въглища за първото тримесечие е средно около 110.8% от относителните средногодишни продажби.
Сезонен индексе средното съотношение на данните, отнасящи се за един сезон (в този случай сезонът е една четвърт) към всички данни. Ако сезонният индекс е по-голям от 1, тогава представянето на този сезон е над средното за годината, по същия начин, ако сезонният индекс е под 1, тогава представянето на сезона е под средното за годината.
И накрая, за да изключите сезонния компонент от оригиналните данни, стойностите на оригиналните данни трябва да бъдат разделени на съответния сезонен индекс. Резултатите от тази операция са показани в колони F и G (фиг. 16). Диаграма от данни, която вече не съдържа сезонен компонент, е показана на фиг. 17.
 |  |

Прогнозиране
Въз основа на данните, от които е изключен сезонният компонент, се изгражда прогноза. За целта се използва подходящ метод, който отчита естеството на поведението на данните (например данните имат тенденция или са относително постоянни). В този пример прогнозата се прави с помощта на просто експоненциално изглаждане. Оптималната стойност на параметъра α се намира с помощта на инструмента Solver. Графиката на прогнозните и реални данни с изключен сезонен компонент е показана на фиг. осемнадесет.

Отчитане на сезонната структура
Сега трябва да вземем предвид сезонния компонент в прогнозата (1726.5). За да направите това, умножете 1726 по сезонния индекс на първото тримесечие от 1,108, което води до стойност от 1912. Подобна операция (умножаване на 1726 по сезонния индекс от 0,784) ще даде прогноза за второто тримесечие, равна на 1353. Резултатът от добавянето на сезонната структура към получената прогноза е показан на фиг. 19.

Варианти на задачите:
Задача 1
Даден е времеви ред
| T | ||||||||||
| х |
1. Начертайте зависимостта x = x(t).
- Използвайки проста подвижна средна над 4 възела, прогнозирайте търсенето в 11-та времева точка.
- Подходящ ли е този метод за прогнозиране за тези данни или не? Защо?
- Нагласете линейно напасване на най-малките квадрати към данните.
Задача 2
Използвайки модела за прогнозиране на приходите на Startup Airlines (Startup.xls), направете следното:
Задача 3
За времеви редове
| T | ||||||||||
| х |
тичам:
- Използвайки претеглена пълзяща средна над 4 възела и присвоявайки тегла 4/10, 3/10, 2/10, 1/10, прогнозирайте търсенето в 11-та времева точка. Трябва да се придаде по-голяма тежест на по-нови наблюдения.
- Това приближение по-добро ли е от проста подвижна средна над 4 възела? Защо?
- Намерете средната стойност на абсолютните отклонения.
- Използвайте инструмента Solver, за да намерите оптималните тегла на възлите. Колко е намаляла грешката на приближението?
- Използвайте експоненциално изглаждане за прогнозиране. Кой от използваните методи дава най-добри резултати?
Задача 4
Анализирайте времеви редове
| време | ||||||||||||
| Търсене |
- Използвайте претеглена подвижна средна с 4 възела с тегла 4/10, 3/10, 2/10, 1/10, за да получите прогноза в моменти 5-13. Трябва да се придаде по-голяма тежест на по-нови наблюдения.
- Намерете средната стойност на абсолютните отклонения.
- Мислите ли, че това приближение е по-добро от модела с 4-възлова проста подвижна средна? Защо?
- Използвайте инструмента Solver, за да намерите оптималните тегла на възлите. С колко успяхте да намалите стойността на грешката?
- Използвайте експоненциално изглаждане за прогнозиране. Кой от използваните методи дава най-добър резултат?
Задача 5
Даден е времеви ред
Задача 7
Маркетинг мениджърът на малка, развиваща се компания, която съдържа верига магазини за хранителни стоки, има информация за обемите на продажбите за цялото съществуване на най-печелившия магазин (вижте таблицата).
Използвайки проста пълзяща средна над 3 възела, прогнозирайте стойностите във възли от 4 до 11.
Използвайки претеглена пълзяща средна за 3 възела, предскажете стойностите във възлите от 4 до 11. Използвайте инструмента Solver, за да определите оптималните тегла.
Използвайте експоненциално изглаждане, за да предвидите стойностите във възли 2-11. Определете оптималната стойност на параметъра α с помощта на инструмента Solver.
Коя от получените прогнози е най-точна и защо?
Задача 8
Даден е времеви ред
- Начертайте този времеви ред. Свържете точките с прави линии.
- Използвайки проста подвижна средна над 4 възела, прогнозирайте търсенето за възли 5-13.
- Намерете средната стойност на абсолютните отклонения.
- Препоръчително ли е да се използва този методпрогноза за представените данни?
- Това приближение по-добро ли е от обикновена подвижна средна над 3 възела? Защо?
- Начертайте линейна и квадратична тенденция от данните.
- Използвайте експоненциално изглаждане за прогнозиране. Кой от използваните методи дава най-добри резултати?
Задача 10
Работната книга Business_Week.xls показва данни от Business Week за 43 месеца месечни продажби на автомобили.
- Премахнете сезонния компонент от тези данни.
- Определете най-добрия метод за прогнозиране за наличните данни.
- Каква е прогнозата за 44-ия период?
Задача 11
- проста схемапрогнозиране, когато стойността за последната седмица се приема като прогноза за следващата седмица.
- Метод на подвижната средна (с броя на възлите по ваш избор). Опитайте се да използвате няколко различни значениявъзли.
Задача 12
Работната книга Bank.xls показва ефективността на банката. Обмислете следните методи за прогнозиране на стойностите на този времеви ред.
Като прогноза се използва средната стойност на индикатора за всички предходни седмици.
Метод на претеглена пълзяща средна (с броя на възлите по ваш избор). Опитайте да използвате няколко различни стойности на възел. Използвайте инструмента Solver, за да определите оптималните тегла.
Метод на експоненциално изглаждане. Намерете оптималната стойност на параметъра α с помощта на инструмента Solver.
Кой от предложените по-горе методи за прогнозиране бихте препоръчали за прогнозиране на стойностите на този времеви ред?
Литература
Подобна информация.
Доктор по икономика, директор по наука и развитие на CJSC "KIS"
Метод на експоненциално изглаждане
Разработването на нови и анализът на добре познати технологии за управление, които подобряват ефективността на управлението на бизнеса, става особено актуално за руските предприятия в момента. Един от най-популярните инструменти е системата за бюджетиране, която се основава на формирането на бюджета на предприятието с последващ контрол върху изпълнението. Бюджетът е балансиран краткосрочен търговски, производствен, финансов и икономически план за развитие на организацията. Бюджетът на компанията съдържа цели, които се изчисляват на базата на прогнозни данни. Най-значимата бюджетна прогноза за всеки бизнес е прогнозата за продажбите. В предишни статии беше извършен анализ на адитивния и мултипликативния модел и беше изчислен прогнозният обем на продажбите за следващите периоди.
При анализа на динамичните редове е използван методът на пълзящата средна, при който всички данни, независимо от периода на тяхното възникване, са равни. Има и друг начин, по който се присвояват тегла на данните, на по-новите данни се дава по-голяма тежест от по-ранните данни.
Методът на експоненциалното изглаждане, за разлика от метода на пълзящата средна, може да се използва и за краткосрочни прогнози за бъдещата тенденция за един период напред и автоматично коригира всяка прогноза в светлината на разликите между действителния и прогнозирания резултат. Ето защо методът има ясно предимство пред разгледания по-рано.
Името на метода идва от факта, че той произвежда експоненциално претеглени пълзящи средни за целия времеви ред. При експоненциалното изглаждане се вземат предвид всички предишни наблюдения - предишното се взема предвид с максимална тежест, предишното - с малко по-ниска, най-ранното наблюдение влияе върху резултата с минимална статистическа тежест.
Алгоритъмът за изчисляване на експоненциално изгладени стойности във всяка точка от серията i се основава на три количества:
действителната стойност на Ai в дадена точка на ред i,
прогноза в точка от серията Fi
някакъв предварително определен коефициент на изглаждане W, постоянен в цялата серия.
Новата прогноза може да се запише като:
Изчисляване на експоненциално изгладени стойности
При практическото използване на метода на експоненциалното изглаждане възникват два проблема: изборът на коефициента на изглаждане (W), който до голяма степен влияе върху резултатите, и определянето на началното условие (Fi). От една страна, за да се изгладят случайните отклонения, стойността трябва да се намали. От друга страна, за да увеличите теглото на новите измервания, трябва да увеличите.
Въпреки че по принцип W може да приеме всяка стойност от диапазона 0< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Изборът на изглаждащ постоянен фактор е субективен. Анализаторите на повечето фирми използват традиционните си стойности W при обработката на сериите.Така, според публикуваните данни в аналитичния отдел на Kodak, традиционно се използва стойността от 0,38, а при Ford Motors е 0,28 или 0,3.
Ръчното изчисляване на експоненциалното изглаждане изисква изключително голямо количество монотонна работа. Например, нека изчислим прогнозния обем за 13-то тримесечие, ако има данни за продажбите за последните 12 тримесечия, като използваме простия метод на експоненциално изглаждане.
Да предположим, че за първото тримесечие прогнозата за продажби е 3. И нека изглаждащият фактор W = 0,8.
Попълнете третата колона в таблицата, като за всяко следващо тримесечие замествате стойността на предходното по формулата:
За 2 четвърти F2 = 0,8 * 4 (1-0,8) * 3 = 3,8
За 3-то тримесечие F3 =0.8*6 (1-0.8)*3.8 =5.6
По същия начин се изчислява изгладена стойност за коефициента 0,5 и 0,33.
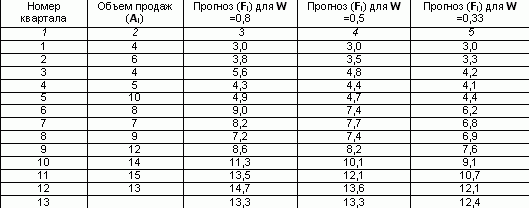
Изчисляване на прогноза за продажбите
Прогнозата за обема на продажбите при W = 0,8 за 13-то тримесечие беше 13,3 хиляди рубли.
Тези данни могат да бъдат представени в графична форма:
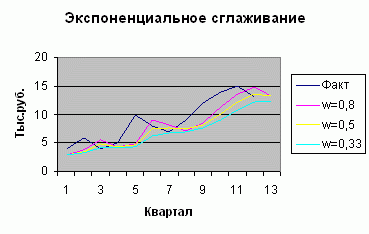
Експоненциално изглаждане
