Повторні незалежні випробування схема та формула бернуллі. Схема повторних незалежних випробувань
Формула Бернуллі- Формула в теорії ймовірностей, що дозволяє знаходити ймовірність появи події A (\displaystyle A)при незалежних випробуваннях. Формула Бернуллі дозволяє позбавитися від великої кількостіобчислень - складання та множення ймовірностей - за досить великої кількості випробувань. Названа на честь видатного швейцарського математика Якоба Бернуллі, який вивів цю формулу.
Енциклопедичний YouTube
1 / 3
✪ Теорія ймовірностей. 22. Формула Бернуллі. Розв'язання задач
✪ Формула Бернуллі
✪ 20 Повторення випробувань Формула Бернуллі
Субтитри
Формулювання
Теорема.Якщо ймовірність p (\displaystyle p)настання події A (\displaystyle A)у кожному випробуванні постійна, то ймовірність P k , n (\displaystyle P_(k,n))того, що подія A (\displaystyle A)настане рівно k (\displaystyle k)раз на n (\displaystyle n)незалежних випробуваннях, дорівнює: P k , n = C n k ⋅ p k ⋅ q n − k (\displaystyle P_(k,n)=C_(n)^(k)\cdot p^(k)\cdot q^(n-k)), де q = 1 − p (\displaystyle q=1-p).
Доведення
Нехай проводиться n (\displaystyle n)незалежних випробувань, причому відомо, що внаслідок кожного випробування подія A (\displaystyle A)настає з ймовірністю P (A) = p (\displaystyle P\left(A\right)=p)і, отже, не настає з ймовірністю P (A ¯) = 1 − p = q (\displaystyle P\left((\bar(A))\right)=1-p=q). Нехай, так само, під час випробувань ймовірності p (\displaystyle p)і q (\displaystyle q)залишаються незмінними. Яка ймовірність того, що в результаті n (\displaystyle n)незалежних випробувань, подія A (\displaystyle A)настане рівно k (\displaystyle k)разів?
Виявляється, можна точно підрахувати кількість "вдалих" комбінацій результатів випробувань, для яких подія A (\displaystyle A)настає k (\displaystyle k)раз на n (\displaystyle n)незалежних випробуваннях, - точно ця кількість, поєднань з n (\displaystyle n)по k (\displaystyle k) :
C n (k) = n! k! (n - k)! (\displaystyle C_(n)(k)=(\frac (n){k!\left(n-k\right)!}}} !}.
У той самий час, оскільки всі випробування незалежні та його результати несумісні (подія A (\displaystyle A)або настає, або ні), то ймовірність отримання "вдалої" комбінації точно дорівнює: .
Звичайно, для того щоб знайти ймовірність того, що в n (\displaystyle n)незалежних випробуваннях подія A (\displaystyle A)настане рівно k (\displaystyle k)раз, потрібно скласти ймовірність отримання всіх "вдалих" комбінацій. Імовірності отримання всіх "вдалих" комбінацій однакові та рівні p k ⋅ q n − k (\displaystyle p^(k)\cdot q^(n-k)), кількість "вдалих" комбінацій дорівнює C n (k) (\displaystyle C_(n)(k))тому остаточно отримуємо:
P k , n = C n k ⋅ p k ⋅ q n − k = C n k ⋅ p k ⋅ (1 − p) n − k (\displaystyle P_(k,n)=C_(n)^(k)\cdot p^( k)\cdot q^(n-k)=C_(n)^(k)\cdot p^(k)\cdot (1-p)^(n-k)).
Останній вислів не що інше, як Формула Бернуллі. Корисно також зауважити, що через повноту групи подій буде справедливо:
∑ k = 0 n (P k , n) = 1 (\displaystyle \sum _(k=0)^(n)(P_(k,n))=1).
Статистика приходить до нас на допомогу при вирішенні багатьох завдань, наприклад: коли немає можливості побудувати детерміновану модель, коли занадто багато факторів або коли нам необхідно оцінити правдоподібність побудованої моделі з урахуванням наявних даних. Ставлення до статистики неоднозначне. Є думка, що існує три види брехні: брехня, Нагла брехнята статистика. З іншого боку, багато «користувачів» статистики надто їй вірять, не розуміючи до кінця, як вона працює: застосовуючи, наприклад, тест до будь-яких даних без перевірки їх нормальності. Така недбалість здатна породжувати серйозні помилки і перетворювати «шанувальників» тесту на ненависників статистики. Спробуємо поставити струми над і розібратися, які моделі випадкових величин повинні використовуватися для опису тих чи інших явищ і яка між ними існує генетичний зв'язок.
Насамперед, цей матеріал буде цікавий студентам, які вивчають теорію ймовірностей та статистику, хоча й «зрілі» фахівці зможуть його використовувати як довідник. В одній із наступних робіт я покажу приклад використання статистики для побудови тесту оцінки значущості показників біржових торгових стратегій.
У роботі будуть розглянуті:
Наприкінці статті буде поставлено для роздумів. Свої роздуми щодо цього я викладу в наступній статті.
Деякі з наведених безперервних розподілів є окремими випадками.
Дискретні розподіли
Дискретні розподіли використовуються для опису подій з характеристиками, що не диференціюються, визначеними в ізольованих точках. Простіше кажучи, для подій, результат яких може бути віднесений до деякої дискретної категорії: успіх чи невдача, ціле число (наприклад, гра в рулетку, кістки), орел або решка тощо.Описується дискретний розподіл ймовірністю настання кожного з можливих наслідків події. Як і будь-якого розподілу (зокрема безперервного) для дискретних подій визначено поняття матожидания і дисперсії. Однак, слід розуміти, що матожидання для дискретної випадкової події - величина в загальному випадкунереалізована як результат одиночної випадкової події, а скоріше як величина, якої буде прагнути середнє арифметичне результатів подій зі збільшенням їх кількості.
У моделюванні дискретних випадкових подій важливу роль відіграє комбінаторика, тому що ймовірність результату події можна визначити як відношення кількості комбінацій, що дають необхідний результат загальної кількості комбінацій. Наприклад: у кошику лежать 3 білих м'ячі та 7 чорних. Коли ми вибираємо з кошика 1 м'яч, ми можемо зробити це 10-м різними способами(загальна кількість комбінацій), але лише 3 варіанти, за яких буде обрано білий м'яч(3 комбінації, що дають необхідний результат). Таким чином, можливість вибрати білий м'яч: ().
Слід також відрізняти вибірки з поверненням та без повернення. Наприклад, для опису ймовірності вибору двох білих м'ячів важливо визначити, чи перший м'яч буде повернуто до кошика. Якщо ні, то ми маємо справу з вибіркою без повернення () і ймовірність буде така: - ймовірність вибрати білий м'яч з початкової вибірки помножена на ймовірність знову вибрати білий м'яч із решти кошика. Якщо перший м'яч повертається у кошик, це вибірка з поверненням (). І тут ймовірність вибору двох білих м'ячів складе .
Якщо кілька формалізувати приклад з кошиком наступним чином: нехай результат події може приймати одне з двох значень 0 або 1 з ймовірностями і відповідно, тоді розподіл ймовірності отримання кожного із запропонованих результатів буде називатися розподіл Бернуллі:
За традицією, що склалася, результат зі значенням 1 називається «успіх», а результат зі значенням 0 - «невдача». Очевидно, що отримання результату «успіх чи невдача» настає з ймовірністю.
Матерікування та дисперсія розподілу Бернуллі:
Кількість успіхів у випробуваннях, результат яких розподілений з ймовірністю успіху (приклад з поверненням м'ячів у кошик), описується біномним розподілом:
Інакше можна сказати, що биномиальное розподіл визначає суму з незалежних випадкових величин, які вміють розподіл із ймовірністю успіху .
Мотовидання та дисперсія:
Біноміальний розподілсправедливо лише вибірки з поверненням, тобто, коли ймовірність успіху залишається постійної для всієї серії випробувань.
Якщо величини і мають біномні розподіли з параметрами і відповідно, їх сума також буде розподілена біномно з параметрами .
Уявимо ситуацію, що ми витягуємо м'ячі з кошика і повертаємо назад доти, доки не буде витягнута біла куля. Кількість таких операцій описується геометричним розподілом. Іншими словами: геометричний розподіл визначає кількість випробувань до першого успіху при ймовірності настання успіху в кожному випробуванні. Якщо мається на увазі номер випробування, в якому настав успіх, то геометричний розподіл описуватиметься такою формулою:
Маточування та дисперсія геометричного розподілу:
Геометричний розподілгенетично пов'язане з розподілом, який описує безперервну випадкову величину: час до настання події, за постійної інтенсивності подій. Геометричний розподіл також є окремим випадком.
Розподіл Паскаля є узагальненням розподілу: описує розподіл кількості невдач у незалежних випробуваннях, результат яких розподілений з ймовірністю успіху до настання успіхів у сумі. При, ми отримаємо розподіл для величини.
де - Число поєднань з .
Маточування та дисперсія негативного біномного розподілу:
Сума незалежних випадкових величин, розподілених за Паскалем, також розподілена за Паскалем: нехай має розподіл , а - . Нехай також і незалежні, тоді їхня сума матиме розподіл
Досі ми розглядали приклади вибірок із поверненням, тобто, ймовірність результату не змінювалася від випробування до випробування.
Тепер розглянемо ситуацію без повернення та опишемо ймовірність кількості успішних вибірок із сукупності із заздалегідь відомою кількістю успіхів та невдач (заздалегідь відома кількість білих та чорних м'ячів у кошику, козирних карт у колоді, бракованих деталей у партії тощо).
Нехай загальна сукупність містить об'єктів, їх позначені як «1», бо як «0». Вважатимемо вибір об'єкта з міткою «1», як успіх, а з міткою «0» як невдачу. Проведемо n випробувань, причому обрані об'єкти більше не братимуть участь у подальших випробуваннях. Імовірність настання успіхів підпорядковуватиметься гіпергеометричному розподілу:
де - Число поєднань з .
Мотовидання та дисперсія:
Розподіл Пуассона

(взято звідси)
Розподіл Пуассона значно відрізняється від розглянутих вище розподілів своєю «предметною» областю: тепер розглядається не ймовірність настання того чи іншого результату випробування, а інтенсивність подій, тобто середня кількість подій за одиницю часу.
Розподіл Пуассона описує ймовірність настання незалежних подій за час при середній інтенсивності подій:
Маточування та дисперсія розподілу Пуассона:
Дисперсія та маточіння розподілу Пуассона тотожно рівні.
Розподіл Пуассона у поєднанні з , що описує інтервали часу між настаннями незалежних подій, становлять математичну основу теорії надійності.
Щільність ймовірності добутку випадкових величин x і y () з розподілами і може бути обчислена наступним чином:
Деякі з наведених нижче розподілів є окремими випадками розподілу Пірсона, який, у свою чергу, є рішенням рівняння:
де - параметри розподілу. Відомі 12 типів розподілу Пірсона залежно від значень параметрів.
Розподіли, які будуть розглянуті у цьому розділі, мають тісні взаємозв'язки між собою. Ці зв'язки виражаються в тому, що деякі розподіли є окремими випадками інших розподілів, або описують перетворення випадкових величин, що мають інші розподіли.
На наведеній нижче схемі відбито взаємозв'язки між деякими з безперервних розподілів, які будуть розглянуті в цій роботі. На схемі суцільними стрілками показано перетворення випадкових величин (початок стрілки вказує на початковий розподіл, кінець стрілки - на результуюче), а пунктирними - відношення узагальнення (початок стрілки вказує на розподіл, що є окремим випадком того, на яке вказує кінець стрілки). Для окремих випадків розподілу Пірсона над пунктирними стрілками вказано відповідний тип розподілу Пірсона.

Запропонований нижче огляд розподілів охоплює багато випадків, які трапляються в аналізі даних та моделюванні процесів, хоча, звичайно, і не містить абсолютно всі відомі науці розподілу.
Нормальний розподіл (розподіл Гауса)

(взято звідси)
Щільність ймовірності нормального розподілу з параметрами та описується функцією Гауса:
Якщо і , то такий розподіл називається стандартним.
Маточування та дисперсія нормального розподілу:
Область визначення нормального розподілу – безліч дійсних чисел.
Нормальним розподілом є розподіл типу VI.
Сума квадратів незалежних нормальних величин має, а відношення незалежних гаусових величин розподілено по.
Нормальний розподіл є нескінченно ділимим: сума нормально розподілених величин і з параметрами і відповідно також має нормальний розподілз параметрами , де та .
Нормальний розподіл добре моделює величини, що описують природні явища, шуми термодинамічної природи та похибки вимірювань
Крім того, згідно з центральною граничною теоремою, сума великої кількості незалежних доданків одного порядку сходить до нормального розподілу, незалежно від розподілів доданків. Завдяки цій властивості, нормальний розподіл популярний у статистичному аналізі, багато статистичних тестів розраховані на нормально розподілені дані.
На нескінченній ділимості нормального розподілу заснований z-тест. Цей тест використовується для перевірки рівності маточіння вибірки нормально розподілених величин деякого значення. Значення дисперсії має бути відомо. Якщо значення дисперсії невідоме і розраховується на підставі аналізованої вибірки, застосовується t-тест, заснований на .
Нехай у нас є вибірка обсягом n незалежних нормально розподілених величин з генеральної сукупностізі стандартним відхиленням висунемо гіпотезу, що . Тоді величина матиме стандартний нормальний розподіл. Порівнюючи отримане значення z з квантилами стандартного розподілу, можна приймати або відхиляти гіпотезу з необхідним рівнем значущості.
Завдяки широкій поширеності розподілу Гаусса, багато дослідників, які не дуже добре знають статистику, забувають перевіряти дані на нормальність, або оцінюють графік щільності розподілу «на вічко», сліпо вважаючи, що мають справу з Гаусовими даними. Відповідно, сміливо застосовуючи тести, призначені для нормального розподілу та отримуючи зовсім некоректні результати. Напевно, звідси й пішла чутка про статистику як найстрашніший вид брехні.
Розглянемо приклад: нам треба виміряти опір набору резистрів певного номіналу. Опір має фізичну природу, логічно припустити, що розподіл відхилень опору від номіналу буде нормальним. Вимірюємо, отримуємо дзвонову функцію щільності ймовірності для виміряних значень з модою в околиці номіналу резистрів. Це нормальний розподіл? Якщо так, то шукатимемо браковані резистри використовуючи , або z-тест, якщо нам заздалегідь відома дисперсія розподілу. Думаю, що багато хто саме так і вчинить.
Але давайте уважніше подивимося на технологію вимірювання опору: опір визначається як відношення прикладеної напруги до струму, що протікає. Струм і напруга ми вимірювали приладами, які, своєю чергою, мають нормально розподілені похибки. Тобто, виміряні значення струму та напруги - це нормально розподілені випадкові величиниз маточуваннями, що відповідають істинним значенням вимірюваних величин. І це означає, що отримані значення опору розподілені по , а чи не по Гауссу.
Розподіл описує суму квадратів випадкових величин, кожна з яких розподілена за стандартним нормальному закону :
Де - Число ступенів свободи, .
Маточування та дисперсія розподілу:
Область визначення - безліч невід'ємних натуральних чисел. є нескінченно поділеним розподілом. Якщо і - розподілені за і мають і ступенів свободи відповідно, то їх сума також буде розподілена і мати ступенів свободи.
Є окремим випадком (а отже, розподілом типу III) та узагальненням. Відношення величин, розподілених за розподілено по .
На розподілі засновано критерій згоди Пірсона. з допомогою цього критерію можна перевіряти достовірність належності вибірки випадкової величини деякому теоретичному розподілу.
Припустимо, що ми маємо вибірка деякої випадкової величини . На підставі цієї вибірки розрахуємо ймовірність потрапляння значень до інтервалів (). Нехай також є припущення про аналітичний вираз розподілу, відповідно до якого, ймовірності попадання у вибрані інтервали повинні становити . Тоді величини будуть розподілені за нормальним законом.
Наведемо до стандартного нормального розподілу: ,
де і .
Отримані величини мають нормальний розподіл з параметрами (0, 1), а отже, сума їх квадратів розподілена зі ступенем свободи. Зниження ступеня свободи пов'язане з додатковим обмеженням на суму ймовірностей потрапляння значень в інтервали: вона повинна дорівнювати 1.
Порівнюючи значення з квантилями розподілу, можна прийняти або відхилити гіпотезу про теоретичний розподіл даних з необхідним рівнем значущості.
Розподіл Стьюдента використовується для проведення t-тесту: тесту на рівність маточіння вибірки розподілених випадкових величин деякому значенню, або рівності маточінь двох вибірок з однаковою дисперсією (рівність дисперсій необхідно перевіряти). Розподіл Стьюдента описує відношення розподіленої випадкової величини до величини, розподіленої на .
Нехай і незалежні випадкові величини, що мають ступеня свободи і відповідно. Тоді величина матиме розподіл Фішера зі ступенями свободи, а величина - розподіл Фішера зі ступенями свободи.
Розподіл Фішера визначено для дійсних невід'ємних аргументів і має густину ймовірності:
Маточування та дисперсія розподілу Фішера:
Маточкування визначено для , а диспересія - для .
На розподілі Фішера засновано ряд статистичних тестів, таких як оцінка значущості параметрів регресії, тест на гетероскедастичність та тест на рівність дисперсій вибірок (f-тест слід відрізняти від точноготіста Фішера).
F-тест: нехай є дві незалежні вибірки та розподілені дані обсягами і відповідно. Висунемо гіпотезу про рівність дисперсій вибірок та перевіримо її статистично.
Розрахуємо величину. Вона матиме розподіл Фішера зі ступенями свободи.
Порівнюючи значення з квантилями відповідного розподілу Фішера, ми можемо прийняти або відхилити гіпотезу про рівність дисперсій вибірок із потрібним рівнем значущості.
Експоненційний (показовий) розподіл та розподіл Лапласу (подвійний експоненціальний, подвійний показовий)

(взято звідси)
Експонентний розподіл описує інтервали часу між незалежними подіями, що відбуваються із середньою інтенсивністю. Кількість настання такої події за деякий відрізок часу описується дискретним. Експоненційний розподіл разом з складають математичну основу теорії надійності.
Крім теорії надійності, експоненціальний розподіл застосовується в описі соціальних явищ, в економіці, теорії масового обслуговування, у транспортній логістиці – скрізь, де необхідно моделювати потік подій.
Експоненційний розподіл є окремим випадком (для n=2), а отже, і . Так як експоненційно розподілена величина є величиною хі-квадрат з 2-ма ступенями свободи, то вона може бути інтерпретована як сума квадратів двох незалежних нормально розподілених величин.
Крім того, експоненційний розподіл є чесним випадком
Коротка теорія
Теорія ймовірностей має справу з такими експериментами, які можна повторювати. Крайній мірітеоретично) необмежену кількість разів. Нехай деякий експеримент повторюється в один раз, причому результати кожного повторення не залежать від результатів попередніх повторень. Такі серії повторень називають незалежними випробуваннями. Окремим випадком таких випробувань є незалежні випробування Бернуллі, які характеризуються двома умовами:
1) результатом кожного випробування є один із двох можливих результатів, званих відповідно «успіхом» або «невдачею».
2) ймовірність «успіху», у кожному наступному випробуванні не залежить від результатів попередніх випробувань та залишається постійною.
Теорема Бернуллі
Якщо проводиться серія з незалежних випробувань Бернуллі, у кожному з яких «успіх» з'являється з ймовірністю, то ймовірність того, що «успіх» у випробуваннях з'явиться рівно раз, виражається формулою:
де – ймовірність «невдачі».
- Число поєднань елементів по (див. основні формули комбінаторики)
Ця формула називається формулою Бернуллі.
Формула Бернуллі дозволяє позбавитися великої кількості обчислень - складання та множення ймовірностей - при досить великій кількості випробувань.
Схему випробувань Бернуллі називають також біномною схемою, а відповідні ймовірності – біноміальними, що пов'язано з використанням біномних коефіцієнтів.
Розподіл за схемою Бернуллі дозволяє, зокрема, знайти найімовірніше число настання події.
Якщо кількість випробувань nвелике, то користуються:
Приклад розв'язання задачі
Умова задачі
Схожість насіння деякої рослини становить 70%. Яка ймовірність того, що з 10 посіяних насіння зійдуть: 8, принаймні 8; не менше 8?
Рішення задачі
Скористаємося формулою Бернуллі:
У нашому випадку
Нехай подія – з 10 насінин зійдуть 8:
Нехай подія зійде принаймні 8 (це означає 8, 9 або 10)
Нехай подія зійде не менше 8 (це означає 8,9 або 10)
Відповідь
Середнявартість рішення контрольної роботи 700 - 1200 рублів (але не менше 300 руб. за все замовлення). На ціну сильно впливає терміновість рішення (від доби до кількох годин). Вартість онлайн-допомоги на іспиті/заліку – від 1000 руб. за рішення квитка.
Заявку можна залишити прямо в чаті, попередньо скинувши умову завдань та повідомивши необхідні вам терміни вирішення. Час відповіді – кілька хвилин.
На цьому уроці знаходимо ймовірність настання події у незалежних випробуваннях при повторенні випробувань . Випробування називаються незалежними, якщо ймовірність того чи іншого результату кожного випробування не залежить від того, які результати мали інші випробування . Незалежні випробування можуть проводитися як у однакових умовах, і у різних. У першому випадку ймовірність появи деякої події у всіх випробуваннях одна й та сама, у другому випадку вона змінюється від випробування до випробування.
Приклади незалежних повторних випробувань :
- вийде з ладу один із вузлів приладу або два, три вузли, причому вихід з ладу кожного вузла не залежить від іншого вузла, а ймовірність виходу з ладу одного вузла постійна у всіх випробуваннях;
- вироблена в деяких постійних технологічних умовах деталь, або три, чотири, п'ять деталей, виявляться нестандартними, причому одна деталь може виявитися нестандартною незалежно від будь-якої іншої деталі і можливість того, що деталь виявиться нестандатною, постійна у всіх випробуваннях;
- з кількох пострілів по мішені один, три чи чотири постріли потрапляють у мету незалежно від наслідків інших пострілів і можливість попадання в ціль постійна у всіх випробуваннях;
- при опусканні монети автомат спрацює правильно один, два чи інше число разів незалежно від того, який результат мали інші опускання монети, і можливість того, що автомат спрацює правильно, постійна у всіх випробуваннях.
Ці події можна описати однією схемою. Кожна подія настає у кожному випробуванні з однією і тією ж ймовірністю, яка не змінюється, якщо стають відомими результати попередніх випробувань. Такі випробування називаються незалежними, а схема називається схемою Бернуллі . Передбачається, що такі випробування можуть бути повторені як завгодно багато разів.
Якщо ймовірність pнастання події Aу кожному випробуванні постійна, то ймовірність того, що в nнезалежних випробуваннях подія Aнастане mраз, знаходиться по формулі Бернуллі :
![]() (де q= 1 – p- ймовірність того, що подія не настане)
(де q= 1 – p- ймовірність того, що подія не настане)
![]()
Поставимо завдання – знайти ймовірність того, що подія такого типу nнезалежних випробуваннях настане mразів.
Формула Бернуллі: приклади розв'язання задач
приклад 1.Знайти ймовірність того, що серед взятих випадково п'яти деталей дві стандартні, якщо ймовірність того, що кожна деталь виявиться стандартною, дорівнює 0,9.
Рішення. Ймовірність події А, Що полягає в тому, що взята випадково деталь стандартна, є p=0,9 , а ймовірність того, що вона нестандартна, є q=1–p= 0,1. Позначена в умові завдання подія (позначимо її через У) настане, якщо, наприклад, перші дві деталі виявляться стандартними, а наступні три – нестандартними. Але подія Утакож настане, якщо перша та третя деталі виявляться стандартними, а решта – нестандартними, або якщо друга та п'ята деталі будуть стандартними, а решта – нестандартними. Є й інші можливості настання події У. Кожна з них характеризується тим, що з п'яти деталей дві, що займають будь-які місця з п'яти, виявляться стандартними. Отже, загальне числорізних можливостей настання події Удорівнює кількості можливостей розміщення на п'яти місцях двох стандартних деталей, тобто. дорівнює кількості поєднань з п'яти елементів по два, а .
Імовірність кожної з можливостей по теоремі множення ймовірностей дорівнює добутку п'яти множників, у тому числі два, відповідні появі стандартних деталей, рівні 0,9, інші три, відповідні появі нестандартних деталей, рівні 0,1, тобто. ця ймовірність становить. Так як зазначені десять можливостей є несумісними подіями, за теоремою складання ймовірність події У, яку позначимо
приклад 2.Імовірність того, що верстат протягом години вимагатиме уваги робітника, дорівнює 0,6. Припускаючи, що неполадки на верстатах незалежні, знайти ймовірність того, що протягом години уваги робітника вимагатиме якийсь один верстат із чотирьох обслуговуваних ним.
Рішення. Використовуючи формулу Бернулліпри n=4 , m=1 , p=0,6 та q=1–p=0,4 , отримаємо
приклад 3.Для нормальної роботиавтобази на лінії має бути не менше восьми автомашин, а їх є десять. Можливість невиходу кожної машини на лінію дорівнює 0,1. Знайти можливість нормальної роботи автобази в найближчий день.
Рішення. Автобаза працюватиме нормально (подія F), якщо на лінію вийдуть чи вісім (подія А), або дев'ять (подія У), або всі десять автомашин подія (подія C). За теоремою складання ймовірностей,
Кожен доданок знаходимо за формулою Бернуллі. Тут n=10 , m=8; 10 , а p=1-0,1=0,9, оскільки pмає означати можливість виходу автомашини на лінію; тоді q= 0,1. В результаті отримаємо

приклад 4.Нехай ймовірність того, що покупцю необхідне чоловіче взуття 41-го розміру, дорівнює 0,25. Знайти ймовірність того, що із шести покупців принаймні двом необхідне взуття 41-го розміру.
Розглянемо Біноміальний розподіл, обчислимо його математичне очікування, дисперсію, моду. За допомогою функції MS EXCEL БІНОМ.РАСП() побудуємо графіки функції розподілу та щільності ймовірності. Зробимо оцінку параметра розподілу p, математичного очікуваннярозподілу та стандартного відхилення. Також розглянемо розподіл Бернуллі.
Визначення. Нехай проводяться nвипробувань, у кожному з яких може відбутися лише дві події: подія «успіх» з ймовірністю p або подія «невдача» з ймовірністю q =1-p (так звана Схема Бернуллі,Bernoullitrials).
Імовірність отримання рівно x успіхів у цих n випробуваннях дорівнює:
Кількість успіхів у вибірці x є випадковою величиною, яка має Біноміальний розподіл(англ. Binomialdistribution) pі n– є параметрами цього розподілу.
Нагадаємо, що для застосування схеми Бернулліі відповідно Біноміального розподілу,повинні бути виконані такі умови:
- кожне випробування повинно мати рівно два результати, що умовно називають «успіхом» і «невдачею».
- результат кожного випробування повинен залежати від результатів попередніх випробувань (незалежність випробувань).
- ймовірність успіху p має бути постійною для всіх випробувань.
Біноміальний розподіл у MS EXCEL
У MS EXCEL, починаючи з версії 2010, для Біноміального розподілує функція БІНОМ.РАСП() , англійська назва- BINOM.DIST(), яка дозволяє обчислити ймовірність того, що у вибірці буде рівно х"Успіхів" (тобто. функцію щільності ймовірності p(x), див. формулу вище), і інтегральну функцію розподілу(ймовірність того, що у вибірці буде xабо менше "успіхів", включаючи 0).
До MS EXCEL 2010 EXCEL була функція БІНОМРАСП() , яка також дозволяє обчислити функцію розподілуі щільність імовірності p(x). БІНОМРАСП() залишено в MS EXCEL 2010 для сумісності.
У файлі прикладу наведено графіки густини розподілу ймовірностіі .

Біноміальний розподілмає позначення B(n; p) .
Примітка: Для побудови інтегральної функції розподілуідеально підходить діаграма типу Графік, для густини розподілу – Гістограма з угрупуванням. Докладніше про побудову діаграм читайте статтю Основні типи діаграм.
Примітка: Для зручності написання формул у файлі прикладу створено Імена для параметрів Біноміального розподілу: n та p.

У прикладному файлі наведено різні розрахунки ймовірності за допомогою функцій MS EXCEL:
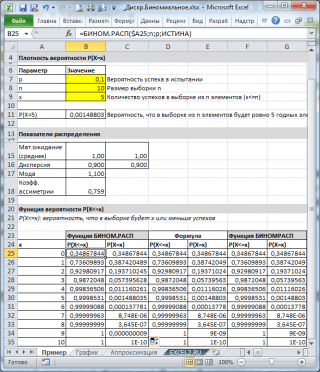
Як видно на картинці вище, передбачається, що:
- У нескінченній сукупності, з якої робиться вибірка, міститься 10% (або 0,1) придатних елементів (параметр p, Третій аргумент функції = БІНОМ.РАСП() )
- Щоб обчислити ймовірність того, що у вибірці з 10 елементів (параметр n, другий аргумент функції) буде рівно 5 придатних елементів (перший аргумент), потрібно записати формулу: =БІНОМ.РАСП(5; 10; 0,1; БРЕХНЯ)
- Останній, четвертий елемент, встановлений = БРЕХНЯ, тобто. повертається значення функції густини розподілу.
Якщо значення четвертого аргументу = ІСТИНА, то функція БІНОМ.РАСП() повертає значення інтегральної функції розподілуабо просто Функцію розподілу. У цьому випадку можна розрахувати ймовірність того, що у вибірці кількість придатних елементів буде з певного діапазону, наприклад, 2 або менше (включаючи 0).
Для цього потрібно записати формулу:
= БІНОМ.РАСП(2; 10; 0,1; ІСТИНА)
Примітка: При нецілому значенні х, . Наприклад, такі формули повернуть одне й теж значення:
=БІНОМ.РАСП( 2
; 10; 0,1; ІСТИНА)
=БІНОМ.РАСП( 2,9
; 10; 0,1; ІСТИНА)
Примітка: У файлі прикладу щільність імовірностіі функція розподілутакож обчислені з використанням визначення та функції ЧИСЛКОМБ() .
Показники розподілу
У файл прикладу на аркуші Прикладє формули для розрахунку деяких показників розподілу:
- =n * p;
- (квадрату стандартного відхилення) = n * p * (1-p);
- = (n + 1) * p;
- =(1-2*p)*КОРІНЬ(n*p*(1-p)).
Виведемо формулу математичного очікування Біноміального розподілу, використовуючи Схему Бернуллі.
За визначенням випадкова величинаХ ст схемою Бернуллі(Bernoulli random variable) має функцію розподілу:

Цей розподіл називається розподіл Бернуллі.
Примітка: розподіл Бернуллі- окремий випадок Біноміального розподілуіз параметром n=1.
Згенеруємо 3 масиви по 100 чисел з різними ймовірностями успіху: 0,1; 0,5 та 0,9. Для цього у вікні Генерація випадкових чисел встановимо такі параметри кожної ймовірності p:
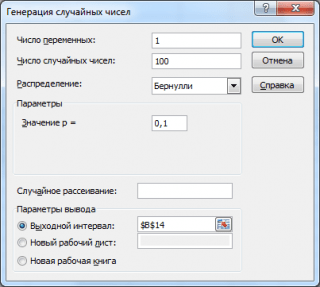
Примітка: Якщо встановити опцію Випадкове розсіювання (Random Seed), то можна вибрати певний випадковий набір згенерованих чисел. Наприклад, встановивши цю опцію =25 можна згенерувати різних комп'ютерах одні й самі набори випадкових чисел (якщо, звісно, інші параметри розподілу збігаються). Значення опції може приймати цілі значення від 1 до 32767. Назва опції Випадкове розсіюванняможе заплутати. Краще було б її перекласти як Номер набору з довільними числами.
У результаті матимемо 3 стовпці по 100 чисел, на підставі яких можна, наприклад, оцінити ймовірність успіху pза формулою: Число успіхів/100(Див. файл прикладу лист ГенераціяБернуллі).

Примітка: Для розподілу Бернулліз p = 0,5 можна використовувати формулу = ВИПАД МІЖ (0; 1), яка відповідає .
Генерація випадкових чисел. Біноміальний розподіл
Припустимо, що у вибірці виявилося 7 дефектних виробів. Це означає, що «дуже ймовірна» ситуація, що змінилася частка дефектних виробів pяка є характеристикою нашого виробничого процесу. Хоча така ситуація «дуже ймовірна», але існує ймовірність (альфа-ризик, помилка 1-го роду, «хибна тривога»), що все-таки pзалишилася без змін, а збільшена кількість дефектних виробів зумовлена випадковістю вибірки.
Як видно на малюнку нижче, 7 – кількість дефектних виробів, яка припустима для процесу з p=0,21 при тому ж значенні Альфа. Це є ілюстрацією, що з перевищенні порогового значення дефектних виробів у вибірці, p«швидше за все» збільшилося. Фраза «швидше за все» означає, що є лише 10% ймовірність (100%-90%) те, що відхилення частки дефектних виробів вище порогового викликано лише сучайними причинами.

Таким чином, перевищення порогової кількості дефектних виробів у вибірці може служити сигналом, що процес засмутився і став випускати б прольший відсоток бракованих виробів.
Примітка: До MS EXCEL 2010 у EXCEL була функція КРИТБІНОМ(), яка еквівалентна БІНОМ.ОБР(). КРИТБІНОМ залишена в MS EXCEL 2010 і вище для сумісності.
Зв'язок Біноміального розподілу з іншими розподілами
Якщо параметр n Біноміального розподілупрагне нескінченності, а pпрагне до 0, то в цьому випадку Біноміальний розподілможе бути апроксимовано.
Можна сформулювати умови, коли наближення розподілом Пуассонапрацює добре:
- p<0,1 (чим менше pі більше n, Тим наближення точніше);
- p>0,9 (враховуючи що q=1- p, обчислення в цьому випадку необхідно проводити через q(а хпотрібно замінити на n- x). Отже, чим менше qі більше n, Тим наближення точніше).
При 0,1<=p<=0,9 и n*p>10 Біноміальний розподілможна апроксимувати.
В свою чергу, Біноміальний розподілможе бути хорошим наближенням , коли розмір сукупності N Гіпергеометричного розподілунабагато більше розміру вибірки n (тобто N>>n або n/N<<1).
Докладніше про зв'язок вищезгаданих розподілів, можна прочитати у статті . Там же наведено приклади апроксимації, і пояснено умови, коли вона можлива і з якоюсь точністю.
ПОРАДА: Про інші розподіли MS EXCEL можна прочитати у статті .
