Довірчий інтервал для мат очікування в excel. Методи кількісного аналізу: Оцінка довірчих інтервалів
У статистиці існує два види оцінок: точкові та інтервальні. Точкова оцінкає окремою вибірковою статистикою, яка використовується для оцінки параметра генеральної сукупності. Наприклад, вибіркове середнє - це точкова оцінка математичного очікуваннягенеральної сукупності, а вибіркова дисперсія S 2- точкова оцінка дисперсії генеральної сукупності σ 2. було показано, що середнє вибіркове є незміщеною оцінкою математичного очікування генеральної сукупності. Вибіркове середнє називається незміщеним, оскільки середнє значення всіх вибіркових середніх (при тому самому обсязі вибірки n) дорівнює математичному очікуванню генеральної сукупності.
Для того щоб вибіркова дисперсія S 2стала незміщеною оцінкою дисперсії генеральної сукупності σ 2, знаменник вибіркової дисперсії слід покласти рівним n – 1 , а не n. Інакше висловлюючись, дисперсія генеральної сукупності є середнім значенням різноманітних вибіркових дисперсій.
Оцінюючи параметрів генеральної сукупності слід пам'ятати, що вибіркові статистики, такі як , залежить від конкретних вибірок. Щоб врахувати цей факт, для отримання інтервальної оцінкиматематичного очікування генеральної сукупності аналізують розподіл вибіркових середніх (детальніше див.). Побудований інтервал характеризується певним довірчим рівнем, який є ймовірністю того, що справжній параметр генеральної сукупності оцінений правильно. Аналогічні довірчі інтервали можна застосовувати для оцінки частки ознаки рта основної розподіленої маси генеральної сукупності.
Завантажити нотатку у форматі або , приклади у форматі
Побудова довірчого інтервалу для математичного очікування генеральної сукупності за відомого стандартного відхилення
Побудова довірчого інтервалу для частки ознаки у генеральній сукупності
У цьому розділі поняття довірчого інтервалу поширюється на дані категорій. Це дозволяє оцінити частку ознаки у генеральній сукупності рза допомогою вибіркової частки рS= Х/n. Як вказувалося, якщо величини nрі n(1 – р)перевищують число 5, біномний розподілможна апроксимувати нормальним. Отже, для оцінки частки ознаки у генеральній сукупності рможна побудувати інтервал, довірчий рівень якого дорівнює (1 – α)х100%.

де pS- вибіркова частка ознаки, рівна Х/n, тобто. кількості успіхів, поділеному на обсяг вибірки, р- частка ознаки у генеральній сукупності, Z- критичне значення стандартизованого нормального розподілу, n- Обсяг вибірки.
приклад 3.Припустимо, що з інформаційної системивилучено вибірку, що складається зі 100 накладних, заповнених протягом останнього місяця. Припустимо, що 10 із цих накладних складено з помилками. Таким чином, р= 10/100 = 0,1. Довірчого рівня 95% відповідає критичне значення Z = 1,96.
Таким чином, ймовірність того, що від 4,12% до 15,88% накладних містять помилки, дорівнює 95%.
Для заданого обсягу вибірки довірчий інтервал, Що містить частку ознаки в генеральній сукупності, здається ширшим, ніж для безперервної випадкової величини. Це тим, що вимірювання безперервної випадкової величини містять більше інформації, ніж вимірювання категорійних даних. Інакше висловлюючись, категорійні дані, які набувають лише два значення, містять недостатньо інформації з метою оцінки параметрів їх розподілу.
Уобчислення оцінок, вилучених із кінцевої генеральної сукупності
Оцінка математичного очікування.Поправочний коефіцієнт кінцевої генеральної сукупності ( fpc) використовувався зменшення стандартної помилки в раз. При обчисленні довірчих інтервалів для оцінок параметрів генеральної сукупності поправний коефіцієнт застосовується у ситуаціях, коли вибірки отримують без повернення. Таким чином, довірчий інтервал для математичного очікування, що має довірчий рівень, рівний (1 – α)х100%, обчислюється за такою формулою:

приклад 4.Щоб проілюструвати застосування поправочного коефіцієнта для кінцевої генеральної сукупності, повернемося до завдання про обчислення довірчого інтервалу для середньої суми накладних, розглянутої вище в прикладі 3. Припустимо, що за місяць у компанії виписуються 5000 накладних, причому X̅= 110,27 дол., S= 28,95 дол., N = 5000, n = 100, α = 0,05, t 99 = 1,9842. За формулою (6) отримуємо:
Оцінка частки ознаки.При виборі без повернення довірчий інтервал для частки ознаки, що має довірчий рівень, рівний (1 – α)х100%, обчислюється за такою формулою:

Довірчі інтервали та етичні проблеми
При вибірковому дослідженні генеральної сукупності та формулюванні статистичних висновків часто виникають етичні проблеми. Основна з них - як узгоджуються довірчі інтервали та точкові оцінки вибіркових статистик. Публікація точкових оцінок без вказівки відповідних довірчих інтервалів (як правило, що мають 95% довірчий рівень) та обсягу вибірки, на основі яких вони отримані, може породити непорозуміння. Це може створити в користувача враження, що точкова оцінка - саме те, що йому необхідно, щоб передбачити властивості всієї генеральної сукупності. Таким чином, необхідно розуміти, що в будь-яких дослідженнях в основу повинні бути поставлені не точкові, а інтервальні оцінки. Крім того, особливу увагу слід приділяти правильному виборуобсягів вибірки
Найчастіше об'єктами статистичних маніпуляцій стають результати соціологічних опитувань населення з тих чи інших політичних проблем. При цьому результати опитування виносять на перші сторінки газет, а помилку вибіркового дослідження та методологію статистичного аналізу друкують десь у середині. Щоб довести обґрунтованість одержаних точкових оцінок, необхідно вказувати обсяг вибірки, на основі якої вони отримані, межі довірчого інтервалу та його рівень значущості.
Наступна замітка
Використовуються матеріали книги Левін та ін. Статистика менеджерів. - М.: Вільямс, 2004. - с. 448–462
Центральна гранична теоремастверджує, що з досить великому обсязі вибірок вибірковий розподіл середніх можна апроксимувати нормальним розподілом. Це властивість залежить від виду розподілу генеральної сукупності.
Оцінка довірчих інтервалів
Цілі навчання
Статистика розглядає такі два основні завдання:
У нас є деяка оцінка, побудована на вибіркових даних, і ми хочемо зробити деяке ймовірнісне твердження щодо того, де знаходиться справжнє значення параметра, що оцінюється.
Ми маємо конкретну гіпотезу, яку необхідно перевірити на основі вибіркових даних.
У цій темі ми розглядаємо перше завдання. Введемо також визначення довірчого інтервалу.
Довірчий інтервал - це інтервал, який будується навколо оцінного значення параметра і показує, де знаходиться справжнє значення параметра, що оцінюється, з апріорі заданою ймовірністю.
Вивчивши матеріал цієї теми, Ви:
дізнаєтесь, що таке довірчий інтервал оцінки;
навчіться класифікувати статистичні завдання;
освоїте техніку побудови довірчих інтервалів як за статистичними формулами, так і за допомогою програмного інструментарію;
навчитеся визначати необхідні розміри вибірок для досягнення певних параметрів точності статистичних оцінок.
Розподіл вибіркових характеристик
Т-розподіл
Як обговорювали вище розподіл випадкової величини, близький до стандартизованого нормального розподілу з параметрами 0 і 1. Оскільки нам не відома величина σ, ми замінюємо її на деяку оцінку s . Величина вже має інший розподіл, а саме чи Розподіл Стьюдента, Яке визначається параметром n -1 (кількість ступенів свободи). Цей розподіл близький до нормального розподілу (що більше n, тим розподіл ближче).
На рис. 95  представлено розподіл Стьюдента з 30 ступенями свободи. Як видно, воно дуже близьке до нормального розподілу.
представлено розподіл Стьюдента з 30 ступенями свободи. Як видно, воно дуже близьке до нормального розподілу.
Аналогічно до функцій для роботи з нормальним розподілом НОРМРАСП і НОРМОБР є функції для роботи з t-розподілом - СТЬЮДРАСП (TDIST) і Стьюдрозбір (TINV). Приклад використання цих функцій можна переглянути у файлі СТЬЮДРАСП.XLS (шаблон і рішення) та на рис. 96  .
.
Розподіл інших характеристик
Як ми вже знаємо, для визначення точності оцінювання математичного очікування нам необхідний t-розподіл. Для оцінювання інших параметрів, наприклад дисперсії, потрібні інші розподіли. Два з них - це F-розподіл та x 2 -розподіл.
Довірчий інтервал для середнього значення
Довірчий інтервал- це інтервал, який будується навколо оцінного значення параметра і показує, де знаходиться справжнє значення параметра, що оцінюється з апріорі заданою ймовірністю.
Побудова довірчого інтервалу для середнього значення відбувається наступним чином:
приклад
У ресторані швидкого обслуговування планується розширити асортимент нового вигляду сендвіча. Для того щоб оцінити попит на нього, менеджер випадковим чином планує вибрати 40 відвідувачів з тих, хто вже спробував його і запропонувати їм оцінити їхнє ставлення до нового продукту в балах від 1 до 10. Менеджер хоче оцінити очікувану кількість балів, яку отримає новий продукт побудувати 95% довірчий інтервал цієї оцінки. Як це здійснити? (Див. файл СЕНДВІЧ1.XLS (шаблон і рішення).
Рішення
Для вирішення цього завдання можна скористатися. Результати подано на рис. 97  .
.
Довірчий інтервал для сумарного значення
Іноді за вибірковими даними потрібно оцінити не математичне очікування, а загальну сумузначень. Наприклад, у ситуації з аудитором інтерес може представляти оцінка не середньої величинирахунки, а суми всіх рахунків.
Нехай N – загальна кількість елементів, n – розмір вибірки, T 3 – сума значень у вибірці, T” – оцінка для суми по всій сукупності, тоді ![]() а довірчий інтервал обчислюється за формулою , де s - оцінка стандартного відхилення для вибірки, - оцінка середнього для вибірки.
а довірчий інтервал обчислюється за формулою , де s - оцінка стандартного відхилення для вибірки, - оцінка середнього для вибірки.
приклад
Допустимо, деяка податкова службахоче оцінити розмір сумарних податкових повернень для 10 000 платників податків. Платник податку отримує повернення, або доплачує податки. Знайдіть 95%-й довірчий інтервал для суми повернення за умови, що розмір вибірки становить 500 осіб (див. файл СУМА ПОВЕРНЕНЬ.XLS (шаблон і рішення ).
Рішення
У StatPro немає спеціальної процедури для цього випадку, проте можна помітити, що кордони можна отримати з кордонів для середнього виходячи з наведених вище формул (рис. 98).  ).
).
Довірчий інтервал для пропорції
Нехай p - математичне очікування частки клієнтів, а р - оцінка цієї частки, отримана за вибіркою розміру n. Можна показати, що для чималих  розподіл оцінки буде близьким до нормального з математичним очікуванням p і стандартним відхиленням
розподіл оцінки буде близьким до нормального з математичним очікуванням p і стандартним відхиленням ![]() . Стандартна помилка оцінки в даному випадку виражається як
. Стандартна помилка оцінки в даному випадку виражається як  , а довірчий інтервал як
, а довірчий інтервал як  .
.
приклад
У ресторані швидкого обслуговування планується розширити асортимент нового вигляду сендвіча. Для того щоб оцінити попит на нього, менеджер випадково вибрав 40 відвідувачів з тих, хто вже спробував його і запропонував їм оцінити їхнє ставлення до нового продукту в балах від 1 до 10. Менеджер хоче оцінити очікувану частку клієнтів, які оцінюють новий продукт не менше ніж у 6 балів (він очікує, що саме ці клієнти будуть споживачами нового продукту).
Рішення
Спочатку створюємо новий стовпець за ознакою 1, якщо оцінка клієнта була більше 6 балів і 0 інакше (див. файл СЕНДВІЧ2.XLS (шаблон та рішення)).
Спосіб 1
Підраховуючи кількість 1 оцінюємо частку, а далі використовуємо формули.
Значення z кр береться зі спеціальних таблиць нормального розподілу (наприклад, 1,96 для 95% довірчого інтервалу).
Використовуючи даний підхід і конкретні дані для побудови 95% інтервалу, отримаємо наступні результати (рис. 99  ). Критичне значення параметра z кр дорівнює 1,96. Стандартна помилка оцінки – 0,077. Нижня межа довірчого інтервалу – 0,475. Верхня межа довірчого інтервалу – 0,775. Таким чином, менеджер вправі вважати з 95% впевненістю, що відсоток клієнтів, які оцінили новий продукт на 6 балів і вище, буде між 47,5 і 77,5.
). Критичне значення параметра z кр дорівнює 1,96. Стандартна помилка оцінки – 0,077. Нижня межа довірчого інтервалу – 0,475. Верхня межа довірчого інтервалу – 0,775. Таким чином, менеджер вправі вважати з 95% впевненістю, що відсоток клієнтів, які оцінили новий продукт на 6 балів і вище, буде між 47,5 і 77,5.
Спосіб 2
Це завдання допускає рішення стандартними засобами StatPro. Для цього достатньо помітити, що частка в даному випадку збігається із середнім значенням стовпця Тип . Далі застосуємо StatPro/Statistical Inference/One-Sample Analysisдля побудови довірчого інтервалу середнього значення (оцінки математичного очікування) стовпця Тип . Отримані у разі результат, будуть дуже близький до результату 1-го способу (рис. 99).
Довірчий інтервал для стандартного відхилення
Як оцінка стандартного відхилення використовується s (формула наведена у розділі 1). Функцією щільності розподілу оцінки s є функція хі-квадрат, яка, як і t-розподіл, має n-1 ступінь свободи. Є спеціальні функції для роботи з цим розподілом ХІ2РАСП (CHIDIST) та ХІ2ОБР (CHIINV).
Довірчий інтервал у разі вже буде не симетричним. Умовна схема меж представлена на рис. 100 .
приклад
Верстат повинен робити деталі діаметром 10 см. Однак через різні обставини відбуваються помилки. Контролера за якістю хвилюють дві обставини: по-перше, середнє значення має дорівнювати 10 см; по-друге, навіть у разі, якщо відхилення будуть великі, багато деталі будуть забраковані. Щодня він робить вибірку з 50 деталей (див. файл КОНТРОЛЬ ЯКОСТІ.XLS (шаблон та рішення)) Які висновки може дати така вибірка?
Рішення
Побудуємо 95% довірчі інтервали для середнього і для стандартного відхилення за допомогою StatPro/Statistical Inference/ One-Sample Analysis(Мал. 101  ).
).
Далі, використовуючи припущення про нормальному розподілідіаметрів, розрахуємо частку бракованих виробів, задавшись граничним відхиленням 0,065. Використовуючи можливості таблиці підстановки (випадок двох параметрів), побудуємо залежність частки шлюбу від середнього значення та стандартного відхилення (рис. 102)  ).
).
Довірчий інтервал для різниці двох середніх значень
Це одне з найважливіших застосувань статистичних методів. Приклади ситуацій.
Менеджер магазину одягу хотів би знати, на скільки більше чи менше витрачає у магазині середня жінка-покупець, ніж чоловік.
Дві авіакомпанії літають аналогічними маршрутами. Організація-споживач хотіла б порівняти різницю між середньоочікуваними часом затримок рейсів по обох авіакомпаніях.
Компанія розсилає купони на окремі види товарів в одному місті та не розсилає в іншому. Менеджери хочуть порівняти середні обсяги купівлі цих товарів у найближчі два місяці.
Автомобільний дилер часто має справу на презентаціях із заміжніми парами. Щоб зрозуміти їхню персональну реакцію на презентацію, пари часто опитують окремо. Менеджер хоче оцінити різницю в рейтингах, які вказують чоловіки і жінки.
Випадок незалежних вибірок
Різниця середніх значень матиме t-розподіл із n 1 + n 2 - 2 ступенями свободи. Довірчий інтервал для μ 1 - μ 2 виражається співвідношенням:

Дане завдання допускає рішення не тільки за наведеними вище формулами, але і стандартними засобами StatPro. Для цього достатньо застосувати
Довірчий інтервал для різниці між пропорціями
Нехай – математичне очікування часток. Нехай їх вибіркові оцінки, побудовані за вибірками розміру n 1 і n 2 відповідно. Тоді є оцінкою для різниці. Отже, довірчий інтервал цієї різниці виражається як:
Тут z кр є значенням, отриманим з нормального розподілу за спеціальними таблицями (наприклад, 1,96 для 95% довірчого інтервалу).
Стандартна помилка оцінки виражається у разі співвідношенням:
 .
.
приклад
Магазин, готуючись до великого розпродажу, зробив наступні маркетингові дослідження. Було обрано 300 найкращих покупців, які у свою чергу були випадково поділені на дві групи по 150 членів у кожній. Усім з відібраних покупців було розіслано запрошення для участі у розпродажі, але тільки для членів першої групи було додано купон, що дає право на знижку 5%. Під час розпродажу купівлі всіх 300 відібраних покупців фіксувалися. Як менеджер може інтерпретувати отримані результати і зробити висновок про ефективність надання купонів? (Див. файл КУПОНИ.XLS (шаблон і рішення)).
Рішення
Для нашого конкретного випадку зі 150 покупців, які отримали купон на знижку, 55 зробили покупку на розпродажі, а серед 150 купон, що не отримали, купівлю зробили тільки 35 (рис. 103  ). Тоді значення вибіркових пропорцій відповідно 0,3667 та 0,2333. А вибіркова різниця між ними дорівнює відповідно 0,1333. Вважаючи довірчий інтервал 95%, знаходимо по таблиці нормального розподілу z кр = 1,96. Обчислення стандартної помилки вибіркової різниці дорівнює 0,0524. Остаточно отримуємо, що нижня межа 95% довірчого інтервалу дорівнює 0,0307, а верхня межа 0,2359 відповідно. Отримані результати можна інтерпретувати таким чином, що на кожних 100 покупців, які отримали купон зі знижкою, очікується від 3 до 23 нових покупців. Однак треба мати на увазі, що цей висновок сам по собі ще не означає ефективності застосування купонів (оскільки надаючи знижку ми втрачаємо в прибутку!). Продемонструємо це на конкретних даних. Припустимо, що середній обсяг купівлі дорівнює 400 крб., у тому числі 50 крб. є прибуток магазину. Тоді очікуваний прибуток на 100 покупцях, які не отримали купон, дорівнює:
). Тоді значення вибіркових пропорцій відповідно 0,3667 та 0,2333. А вибіркова різниця між ними дорівнює відповідно 0,1333. Вважаючи довірчий інтервал 95%, знаходимо по таблиці нормального розподілу z кр = 1,96. Обчислення стандартної помилки вибіркової різниці дорівнює 0,0524. Остаточно отримуємо, що нижня межа 95% довірчого інтервалу дорівнює 0,0307, а верхня межа 0,2359 відповідно. Отримані результати можна інтерпретувати таким чином, що на кожних 100 покупців, які отримали купон зі знижкою, очікується від 3 до 23 нових покупців. Однак треба мати на увазі, що цей висновок сам по собі ще не означає ефективності застосування купонів (оскільки надаючи знижку ми втрачаємо в прибутку!). Продемонструємо це на конкретних даних. Припустимо, що середній обсяг купівлі дорівнює 400 крб., у тому числі 50 крб. є прибуток магазину. Тоді очікуваний прибуток на 100 покупцях, які не отримали купон, дорівнює:
50 0,2333 100 = 1166,50 руб.
Аналогічні обчислення для 100 покупців, які отримали купон, дають:
30 0,3667 100 = 1100,10 руб.
Зменшення середньої прибутку до 30 пояснюється лише тим, що, використовуючи знижку, покупці, які отримали купон, загалом робитимуть покупку на 380 крб.
Таким чином, підсумковий висновок говорить про неефективність використання таких купонів у цій конкретній ситуації.
Зауваження. Це завдання допускає рішення стандартними засобами StatPro. Для цього достатньо звести це завдання до завдання оцінки різниці двох середніх способом, а далі застосувати StatPro/Statistical Inference/Two-Sample Analysisдля побудови довірчого інтервалу різниці двох середніх значень.
Управління довжиною довірчого інтервалу
Довжина довірчого інтервалу залежить від наступних умов:
безпосередньо даних (стандартне відхилення);
рівня значимості;
розміру вибірки.
Розмір вибірки для оцінки середнього значення
Спочатку розглянемо завдання у загальному випадку. Позначимо дане нам значення половини довжини довірчого інтервалу за (рис. 104  ). Нам відомо, що довірчий інтервал для середнього значення деякої випадкової величини X виражається як
). Нам відомо, що довірчий інтервал для середнього значення деякої випадкової величини X виражається як ![]() , де
, де ![]() . Вважаючи:
. Вважаючи:
![]() і висловлюючи n, отримаємо.
і висловлюючи n, отримаємо.
На жаль, точне значеннядисперсії випадкової величини X нам відомо. Крім цього, нам невідомо і значення t кр, оскільки воно залежить від n через кількість ступенів свободи. У цій ситуації ми можемо вчинити так. Замість дисперсії s використовуємо будь-яку оцінку дисперсії, за якими є реалізація досліджуваної випадкової величини. Замість значення t кр використовуємо значення z кр нормального розподілу. Це цілком припустимо, оскільки функції щільності розподілів для нормального та t-розподілу дуже близькі (за винятком випадку малих n). Таким чином, шукана формула набуває вигляду:
 .
.
Оскільки формула дає, взагалі кажучи, нецілочисленний результат, як шуканий розмір вибірки береться округлення з надлишком результату.
приклад
У ресторані швидкого обслуговування планується розширити асортимент нового вигляду сендвіча. Для того щоб оцінити попит на нього, менеджер випадково планує вибрати деяку кількість відвідувачів з тих, хто вже спробував його, і запропонувати їм оцінити їхнє ставлення до нового продукту в балах від 1 до 10. Менеджер хоче оцінити очікувану кількість балів, яку отримає новий продукт і побудувати 95% довірчий інтервал цієї оцінки. При цьому він хоче, щоб половина ширини довірчого інтервалу не перевищувала 0,3. Яку кількість відвідувачів йому потрібно опитати?
виглядає наступним чином:

Тут р оц- оцінка частки p , а є задана половина довжини довірчого інтервалу. Завищене значення для n можна отримати, використовуючи значення р оц= 0,5. У цьому випадку довжина довірчого інтервалу не перевищуватиме заданого значення при будь-якому істинному значенні p .
приклад
Нехай менеджер із попереднього прикладу планує оцінити частку клієнтів, які віддали перевагу новому виду продукції. Він хоче побудувати 90% довірчий інтервал, половина довжини якого не перевищувала б 0,05. Скільки клієнтів має увійти до випадкової вибірки?
Рішення
У разі значення z кр = 1,645. Тому шукана кількість обчислюється як  .
.
Якби менеджер мав підстави вважати, що шукане значення p становить, наприклад, приблизно 0,3, то, підставляючи це значення у наведену вище формулу, ми отримали б менше значення величини випадкової вибірки, а саме 228.
Формула для визначення розмірів випадкової вибірки у разі різниці між двома середніми значеннямизаписується як:
 .
.
приклад
Деяка комп'ютерна компанія має сервісний центр обслуговування клієнтів. У Останнім часомзбільшилась кількість скарг клієнтів на погана якістьобслуговування. У сервісному центрі переважно працюють співробітники двох типів: які мають великого досвіду, але які закінчили спеціальні підготовчі курси, і мають великий практичний досвід, але з закінчили спеціальних курсів. Компанія хоче проаналізувати нарікання клієнтів за останні півроку та порівняти їх середні кількості, що припадають на кожну з двох груп співробітників. Передбачається, що кількості у вибірках з обох груп будуть однакові. Яку кількість співробітників необхідно включити у вибірку, щоб отримати 95% інтервал з половиною довжини не більше 2?
Рішення
Тут σ оц є оцінка стандартного відхилення обох випадкових змінних у припущенні, що вони близькі. Таким чином, у нашому завданні нам необхідно якимось чином одержати цю оцінку. Це можна зробити, наприклад, в такий спосіб. Переглянувши дані щодо нарікань клієнтів за останні півроку, менеджер може помітити, що на кожного співробітника в основному припадає від 6 до 36 нарікань. Знаючи, що для нормального розподілу практично всі значення віддалені від середнього значення не більше ніж на три стандартні відхилення, він може з певною підставою вважати, що:
![]() , Звідки σ оц = 5.
, Звідки σ оц = 5.
Підставляючи це значення у формулу, отримуємо  .
.
Формула для визначення розміру випадкової вибірки у разі оцінки різниці між часткамимає вигляд:

приклад
Деяка компанія має дві заводи з виробництва аналогічної продукції. Менеджер компанії хоче порівняти частки бракованої продукції обох фабриках. За наявною інформацією відсоток шлюбу обох фабриках становить від 3 до 5%. Передбачається побудувати 99% довірчий інтервал з половиною довжини не більше 0,005 (або 0,5%). Яку кількість виробів необхідно вибрати з кожної фабрики?
Рішення
Тут р 1оц і р 2оц є оцінками двох невідомих часток шлюбу на 1-й та 2-й фабриці. Якщо покласти р 1оц = р 2оц = 0,5, ми отримаємо підвищене значення для n . Але оскільки в нашому випадку ми маємо деяку апріорну інформацію про ці частки, то беремо верхню оцінку цих часток, а саме 0,05. Отримуємо
Коли оцінюється деякі параметри сукупності за вибірковими даними, корисно дати не тільки точкову оцінкупараметра, але й вказати довірчий інтервал, який показує, де може знаходитися точне значення параметра, що оцінюється.
У цьому розділі ми також познайомилися з кількісними співвідношеннями, що дозволяють будувати такі інтервали для різних параметрів; дізналися методи управління довжиною довірчого інтервалу.
Зазначимо також, що завдання оцінки розмірів вибірки (завдання планування експерименту) можна вирішити, використовуючи стандартні засоби StatPro, а саме StatPro/Statistical Inference/Sample Size Selection.
Довірчий інтервал для математичного очікування - це такий обчислений за даними інтервал, який з певною ймовірністю містить математичне очікування генеральної сукупності. Природною оцінкою для математичного очікування є середнє арифметичне її спостережених значень. Тому далі протягом уроку ми користуватимемося термінами "середнє", "середнє значення". У завданнях розрахунку довірчого інтервалу найчастіше потрібна відповідь типу "Довірчий інтервал середнього числа [величина у конкретній задачі] знаходиться від [менше значення] до [більше значення]". З допомогою довірчого інтервалу можна оцінювати як середні значення, а й питому вагу тієї чи іншої ознаки генеральної сукупності. Середні значення, дисперсія, стандартне відхилення та похибка, через які ми будемо приходити до нових визначень та формул, розібрані на уроці Характеристики вибірки та генеральної сукупності .
Точкова та інтервальна оцінки середнього значення
Якщо середнє значення генеральної сукупності оцінюється числом (точкою), то оцінку невідомої середньої величини генеральної сукупності приймається конкретне середнє, яке розраховано за вибіркою спостережень. У разі значення середнього вибірки - випадкової величини - не збігається із середнім значенням генеральної сукупності. Тому, вказуючи середнє значення вибірки, одночасно потрібно вказувати помилку вибірки. В якості міри помилки вибірки використовується стандартна помилка, яка виражена в тих самих одиницях виміру, що і середнє. Тому найчастіше використовується наступний запис: .
Якщо оцінку середнього потрібно пов'язати з певною ймовірністю, то параметр генеральної сукупності, що цікавить, потрібно оцінювати не одним числом, а інтервалом. Довірчим інтервалом називають інтервал, у якому з певною ймовірністю Pперебуває значення оцінюваного показника генеральної сукупності. Довірчий інтервал, у якому з ймовірністю P = 1 - α знаходиться випадкова величина , розраховується так:
![]() ,
,
α = 1 - P, яке можна знайти у додатку до практично будь-якої книги зі статистики.
Насправді середнє значення генеральної сукупності і дисперсія невідомі, тому дисперсія генеральної сукупності замінюється дисперсією вибірки , а середнє генеральної сукупності - середнім значенням вибірки . Таким чином, довірчий інтервал у більшості випадків розраховується так:
![]() .
.
Формулу довірчого інтервалу можна використовувати для оцінки середньої генеральної сукупності, якщо
- відоме стандартне відхилення генеральної сукупності;
- або стандартне відхилення генеральної сукупності невідоме, але обсяг вибірки – більше 30.
Середнє значення вибірки є незміщеною оцінкою середньої генеральної сукупності. У свою чергу, дисперсія вибірки  не є незміщеною оцінкою дисперсії генеральної сукупності. Для отримання незміщеної оцінки дисперсії генеральної сукупності у формулі дисперсії вибірки обсяг вибірки nслід замінити на n-1.
не є незміщеною оцінкою дисперсії генеральної сукупності. Для отримання незміщеної оцінки дисперсії генеральної сукупності у формулі дисперсії вибірки обсяг вибірки nслід замінити на n-1.
приклад 1.Зібрано інформацію зі 100 випадково обраних кафе в деякому місті про те, що середня кількість працівників у них становить 10,5 зі стандартним відхиленням 4,6. Визначити довірчий інтервал 95% від числа працівників кафе.
де - критичне значення стандартного нормального розподілу рівня значимості α = 0,05 .
Таким чином, довірчий інтервал 95% середньої кількості працівників кафе становив від 9,6 до 11,4.
приклад 2.Для випадкової вибірки з генеральної сукупності з 64 спостережень обчислено такі сумарні величини:
сума значень у спостереженнях,
сума квадратів відхилення значень від середнього ![]() .
.
Обчислити довірчий інтервал 95% для математичного очікування.
обчислимо стандартне відхилення:
 ,
,
обчислимо середнє значення:
![]() .
.
Підставляємо значення вираз для довірчого інтервалу:
де - критичне значення стандартного нормального розподілу рівня значимості α = 0,05 .
Отримуємо:
Таким чином, довірчий інтервал 95% для математичного очікування цієї вибірки становив від 7,484 до 11,266.
приклад 3.Для випадкової вибірки з генеральної сукупності зі 100 спостережень обчислено середнє значення 15,2 та стандартне відхилення 3,2. Обчислити довірчий інтервал 95% для математичного очікування, потім довірчий інтервал 99%. Якщо потужність вибірки та її варіація залишаються незмінними, а збільшується довірчий коефіцієнт, то довірчий інтервал звузиться чи розшириться?
Підставляємо дані значення вираз для довірчого інтервалу:
де - критичне значення стандартного нормального розподілу рівня значимості α = 0,05 .
Отримуємо:
![]() .
.
Таким чином, довірчий інтервал 95% для середньої даної вибірки становив від 14,57 до 15,82.
Знову підставляємо дані значення вираз для довірчого інтервалу:
де - критичне значення стандартного нормального розподілу рівня значимості α = 0,01 .
Отримуємо:
![]() .
.
Таким чином, довірчий інтервал 99% для середньої даної вибірки становив від 14,37 до 16,02.
Як бачимо, при збільшенні довірчого коефіцієнта збільшується також критичне значення стандартного нормального розподілу, а отже початкова і кінцева точки інтервалу розташовані далі від середнього, і таким чином довірчий інтервал для математичного очікування збільшується.
Точкова та інтервальна оцінки частки
Питому вагу деякої ознаки вибірки можна інтерпретувати як точкову оцінку частки pцієї ж ознаки у генеральній сукупності. Якщо ж цю величину потрібно пов'язати з ймовірністю, слід розрахувати довірчий інтервал частки pознаки у генеральній сукупності з ймовірністю P = 1 - α :
 .
.
приклад 4.У деякому місті два кандидати Aі Bпретендують на посаду мера Випадковим чином було опитано 200 жителів міста, з яких 46% відповіли, що голосуватимуть за кандидата. A, 26% - за кандидата Bта 28% не знають, за кого голосуватимуть. Визначити довірчий інтервал 95% для частки жителів міста, які підтримують кандидата A.
Ціль– навчити студентів алгоритмів обчислення довірчих інтервалів статистичних параметрів.
При статистичній обробці даних обчислені середня арифметична, коефіцієнт варіації, коефіцієнт кореляції, критерії відмінності та інші точкові статистики повинні отримати кількісні межі довіри, які позначають можливі коливання показника меншу і більшу сторону в межах довірчого інтервалу.
Приклад 3.1
.
Розподіл кальцію у сироватці крові мавп, як було встановлено раніше, характеризується такими вибірковими показниками: = 11,94 мг%;  = 0,127 мг%; n= 100. Потрібно визначити довірчий інтервал для генеральної середньої (
= 0,127 мг%; n= 100. Потрібно визначити довірчий інтервал для генеральної середньої (  ) при довірчій ймовірності P
= 0,95.
) при довірчій ймовірності P
= 0,95.
Генеральна середня знаходиться з певною ймовірністю в інтервалі:
 , де
, де  - Вибіркова середня арифметична; t– критерій Стьюдента;
- Вибіркова середня арифметична; t– критерій Стьюдента;  - Помилка середньої арифметичної.
- Помилка середньої арифметичної.
За таблицею «Значення критерію Стьюдента» знаходимо значення
 при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99. Воно дорівнює 1,982. Разом із значеннями середньої арифметичної та статистичної помилки підставляємо його у формулу:
при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99. Воно дорівнює 1,982. Разом із значеннями середньої арифметичної та статистичної помилки підставляємо його у формулу:
або 11,69  12,19
12,19
Таким чином, з ймовірністю 95%, можна стверджувати, що генеральна середня цього нормального розподілу знаходиться між 11,69 і 12,19 мг%.
Приклад 3.2
. Визначте межі 95% довірчого інтервалу для генеральної дисперсії (  ) розподілу кальцію в крові мавп, якщо відомо, що
) розподілу кальцію в крові мавп, якщо відомо, що  = 1,60, при n
= 100.
= 1,60, при n
= 100.
Для вирішення задачі можна скористатися такою формулою:
Де  - Статистична помилка дисперсії.
- Статистична помилка дисперсії.
Знаходимо помилку вибіркової дисперсії за формулою:  . Вона дорівнює 0,11. Значення t- критерію при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99 відомо з попереднього прикладу.
. Вона дорівнює 0,11. Значення t- критерію при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99 відомо з попереднього прикладу.
Скористаємося формулою та отримаємо:
або 1,38  1,82
1,82
Більш точно довірчий інтервал генеральної дисперсії можна побудувати із застосуванням  (хі-квадрат) – критерію Пірсона. Критичні точки при цьому критерію наводяться у спеціальній таблиці. При використанні критерію
(хі-квадрат) – критерію Пірсона. Критичні точки при цьому критерію наводяться у спеціальній таблиці. При використанні критерію  для побудови довірчого інтервалу застосовують двосторонній рівень значущості. Для нижньої межі рівень значущості розраховується за формулою
для побудови довірчого інтервалу застосовують двосторонній рівень значущості. Для нижньої межі рівень значущості розраховується за формулою  , для верхньої –
, для верхньої –  . Наприклад, для довірчого рівня
. Наприклад, для довірчого рівня  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Відповідно до таблиці розподілу критичних значень
= 0,990. Відповідно до таблиці розподілу критичних значень  , при розрахованих довірчих рівнях та числі ступенів свободи k= 100 - 1 = 99, знайдемо значення
, при розрахованих довірчих рівнях та числі ступенів свободи k= 100 - 1 = 99, знайдемо значення  і
і  . Отримуємо
. Отримуємо  одно 135,80, а
одно 135,80, а 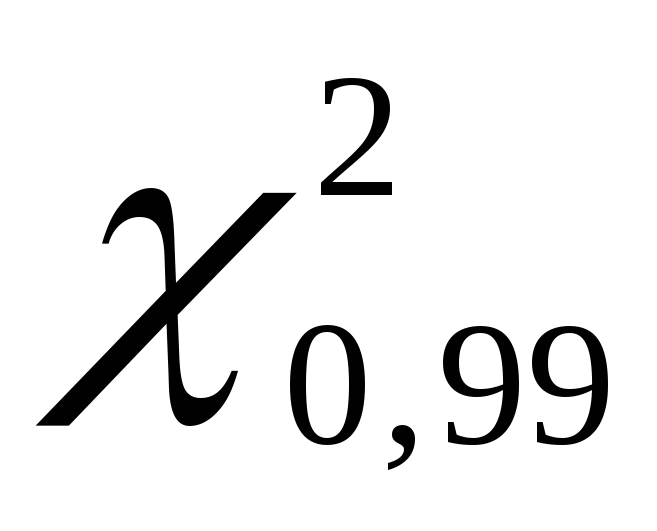 рівно70,06.
рівно70,06.
Щоб знайти довірчі межі генеральної дисперсії за допомогою  скористаємося формулами: для нижньої межі
скористаємося формулами: для нижньої межі  для верхнього кордону
для верхнього кордону  . Підставимо ці завдання знайдені значення
. Підставимо ці завдання знайдені значення  у формули:
у формули:  =
1,17;
=
1,17; = 2,26. Таким чином, за довірчої ймовірності P= 0,99 або 99% генеральна дисперсія лежатиме в інтервалі від 1,17 до 2,26 мг% включно.
= 2,26. Таким чином, за довірчої ймовірності P= 0,99 або 99% генеральна дисперсія лежатиме в інтервалі від 1,17 до 2,26 мг% включно.
Приклад 3.3 . Серед 1000 насіння пшениці з партії, що надійшла на елеватор, виявлено 120 насіння заражених ріжків. Необхідно визначити можливі межі генеральної частки зараженого насіння у цій партії пшениці.
Довірчі межі для генеральної частки за всіх можливих її значеннях доцільно визначати за формулою:
 ,
,
Де n - Число спостережень; m- Абсолютна чисельність однієї з груп; t– нормоване відхилення.
Вибіркова частка зараженого насіння дорівнює  чи 12%. За довірчої ймовірності Р= 95% нормоване відхилення ( t-критерій Стьюдента при k
=
чи 12%. За довірчої ймовірності Р= 95% нормоване відхилення ( t-критерій Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Підставляємо наявні дані у формулу:
Звідси межі довірчого інтервалу дорівнюють 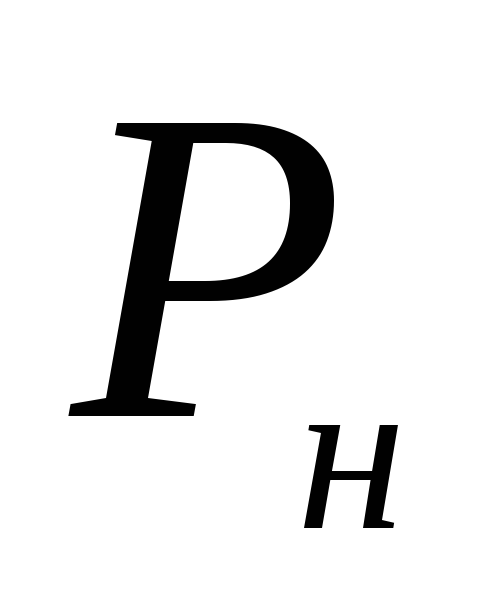 = 0,122-0,041 = 0,081, або 8,1%;
= 0,122-0,041 = 0,081, або 8,1%;  = 0,122 + 0,041 = 0,163, чи 16,3%.
= 0,122 + 0,041 = 0,163, чи 16,3%.
Таким чином, з довірчою ймовірністю 95% можна стверджувати, що генеральна частка зараженого насіння знаходиться між 8,1 та 16,3%.
Приклад 3.4 . Коефіцієнт варіації, що характеризує варіювання кальцію (мг%) у сироватці крові мавп, дорівнював 10,6%. Обсяг вибірки n= 100. Необхідно визначити межі 95% довірчого інтервалу для генерального параметра Cv.
Кордони довірчого інтервалу для генерального коефіцієнта варіації Cv визначаються за такими формулами:
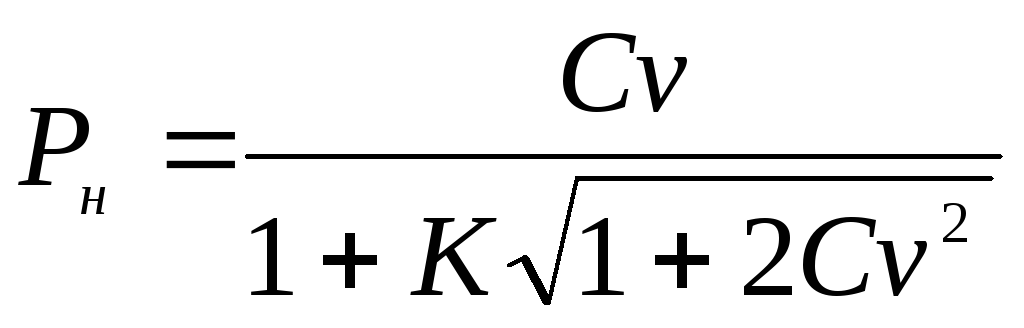 і
і  , де K
проміжна величина, що обчислюється за формулою
, де K
проміжна величина, що обчислюється за формулою  .
.
Знаючи, що за довірчої ймовірності Р= 95% нормоване відхилення (критерій Стьюдента при k
=
 )t
= 1,960, попередньо розрахуємо величину До:
)t
= 1,960, попередньо розрахуємо величину До:
 .
.
 або 9,3%
або 9,3%
 або 12,3%
або 12,3%
Таким чином, генеральний коефіцієнт варіації з довірчою ймовірністю 95% лежить в інтервалі від 93 до 123%. При повторних вибірках коефіцієнт варіації не перевищить 12,3% і не виявиться нижчим за 9,3% у 95 випадках зі 100.
Запитання для самоконтролю:

Завдання для самостійного вирішення.
1. Середній відсоток жиру у молоці за лактацію корів холмогорських помісей був таким: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Встановіть довірчі інтервали для середньої середньої при довірчій ймовірності 95% (20 балів).
2. На 400 рослинах гібридного жита перші квітки з'явилися в середньому на 70,5 день після посіву. Середнє відхилення було 6,9 дня. Визначте помилку середньої та довірчі інтервали для генеральної середньої та дисперсії при рівні значущості W= 0,05 та W= 0,01 (25 балів).
3. При вивченні довжини листя 502 екземплярів садової суниці були отримані такі дані:
 = 7,86 див; σ = 1,32 см,
= 7,86 див; σ = 1,32 см,  =± 0,06 см. Визначте довірчі інтервали для середньої арифметичної генеральної сукупності з рівнями значущості 0,01; 0,02; 0,05. (25 балів).
=± 0,06 см. Визначте довірчі інтервали для середньої арифметичної генеральної сукупності з рівнями значущості 0,01; 0,02; 0,05. (25 балів).
4. При обстеженні 150 дорослих чоловіків середній зріст дорівнював 167 см, а σ = 6 см. У яких межах знаходиться генеральна середня та генеральна дисперсія з довірчою ймовірністю 0,99 та 0,95? (25 балів).
5. Розподіл кальцію у сироватці крові мавп характеризується такими вибірковими показниками:
 = 11,94 мг%, σ
= 1,27, n
= 100. Побудуйте 95% довірчий інтервал для генеральної середньої цього розподілу. Розрахуйте коефіцієнт варіації (25 балів).
= 11,94 мг%, σ
= 1,27, n
= 100. Побудуйте 95% довірчий інтервал для генеральної середньої цього розподілу. Розрахуйте коефіцієнт варіації (25 балів).
6. Було вивчено загальний вміст азоту в плазмі крові щурів-альбіносів у віці 37 та 180 днів. Результати виражені у грамах на 100 см 3 плазми. У віці 37 днів 9 щурів мали: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. У віці 180 днів 8 щурів мали: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Встановіть довірчі інтервали для різниці з вірогідністю 0,95 (50 балів).
7. Визначте межі 95% довірчого інтервалу для генеральної дисперсії розподілу кальцію (мг%) у сироватці крові мавп, якщо для цього розподілу обсяг вибірки n = 100, статистична помилка вибіркової дисперсії s σ 2 = 1,60 (40 балів).
8. Визначте межі 95% довірчого інтервалу для генеральної дисперсії розподілу 40 колосків пшениці по довжині (σ 2 = 40, 87 мм 2). (25 балів).
9. Куріння вважають основним фактором, що привертає до обструктивних захворювань легень. Пасивне куріння таким фактором не вважається. Вчені засумнівалися в нешкідливості пасивного куріння та досліджували прохідність дихальних шляхів у курців, що не палять, пасивних та активних. Для характеристики стану дихальних шляхів взяли один із показників функції зовнішнього дихання – максимальну об'ємну швидкість середини видиху. Зменшення цього показника – ознака порушення прохідності дихальних шляхів. Дані обстеження наведено у таблиці.
|
Число обстежених |
Максимальна об'ємна швидкість середини видиху, л/с |
||
|
Стандартне відхилення |
|||
|
Некурці |
|||
|
працюють у приміщенні, де не курять | |||
|
працюють у накуреному приміщенні | |||
|
Курці |
|||
|
викурювальні не велике числоцигарок | |||
|
викурюють середню кількість сигарет | |||
|
викурюють велику кількість сигарет | |||
За даними таблиці знайдіть 95% довірчі інтервали для генеральної середньої та генеральної дисперсії для кожної групи. У чому різниця між групами? Результати подайте графічно (25 балів).
10. Визначте межі 95% і 99% довірчого інтервалу для генеральної дисперсії чисельності поросят у 64 опоросах, якщо статистична помилка вибіркової дисперсії s σ 2 = 8, 25 (30 балів).
11. Відомо, що середня маса кролів становить 2,1 кг. Визначте межі 95%-ного та 99%-ного довірчого інтервалу для генеральної середньої та дисперсії при n= 30, σ = 0,56 кг (25 балів).
12. У 100 колосків вимірювали озерненість колосу ( Х), довжину колосу ( Y) та масу зерна в колосі ( Z). Знайти довірчі інтервали для генеральної середньої та дисперсії при P 1
= 0,95, P 2
= 0,99, P 3
= 0,999, якщо
 = 19, = 6,766 см, = 0,554 м; x 2 = 29, 153, y 2 = 2, 111, z 2 = 0, 064. (25 балів).
= 19, = 6,766 см, = 0,554 м; x 2 = 29, 153, y 2 = 2, 111, z 2 = 0, 064. (25 балів).
13. У відібраних випадковим чином 100 колосках пшениці озимої підраховувалося число колосків. Вибіркова сукупність характеризувалася такими показниками:
 = 15 колосків та σ = 2,28 шт. Визначте, з якою точністю отримано середній результат (
= 15 колосків та σ = 2,28 шт. Визначте, з якою точністю отримано середній результат (  ) та побудуйте довірчий інтервал для генеральної середньої та дисперсії при 95% та 99% рівнях значущості (30 балів).
) та побудуйте довірчий інтервал для генеральної середньої та дисперсії при 95% та 99% рівнях значущості (30 балів).
14. Число ребер на раковинах викопного молюска Orthambonites calligramma:
Відомо що n = 19, σ = 4,25. Визначте межі довірчого інтервалу для генеральної середньої та генеральної дисперсії при рівні значущості W = 0,01 (25 балів).
15. Для визначення надої молока на молочно-товарній фермі щодня визначалася продуктивність 15 корів. За даними протягом року кожна корова давала загалом на добу таку кількість молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Побудуйте довірчі інтервали для генеральної дисперсії та середньої арифметичної. Чи можна очікувати, що середньорічний надій на кожну корову складе 10000 літрів? (50 балів).
16. З метою визначення врожаю пшениці в середньому по агрогосподарству було проведено укоси на пробних ділянках площею 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 та 2 га. Врожайність (ц/га) з ділянок становила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 відповідно. Побудуйте довірчі інтервали для генеральних дисперсії та середньої арифметичної. Чи можна очікувати, що в середньому в агрогосподарстві врожай складе 42 ц/га? (50 балів).
Довірчий інтервал прийшов до нас із галузі статистики. Це певний діапазон, який служить для оцінки невідомого параметра з високим ступенемнадійність. Найпростіше це пояснити на прикладі.
Припустимо, слід досліджувати якусь випадкову величину, наприклад, швидкість відгуку сервера на запит клієнта. Щоразу, коли користувач набирає адресу конкретного сайту, сервер реагує з різною швидкістю. Таким чином, час відгуку, що досліджується, має випадковий характер. Так ось, довірчий інтервал дозволяє визначити межі цього параметра, і потім можна буде стверджувати, що з ймовірністю 95% сервера буде знаходитися в розрахованому нами діапазоні.
Або потрібно дізнатися, якій кількості людей відомо про торгову марку фірми. Коли буде підрахований довірчий інтервал, можна буде, наприклад, сказати що з 95% часткою ймовірності частка споживачів, знають про цю перебуває у діапазоні від 27% до 34%.
З цим терміном тісно пов'язана така величина, як довірча ймовірність. Вона є ймовірністю того, що шуканий параметр входить у довірчий інтервал. Від цієї величини залежить те, наскільки більшим виявиться наш пошуковий діапазон. Що більше значення вона набуває, то вже стає довірчий інтервал, і навпаки. Зазвичай її встановлюють 90%, 95% або 99%. Величина 95% найпопулярніша.
На цей показник також впливає дисперсія спостережень і Його визначення ґрунтується на тому припущенні, що досліджувана ознака підкоряється. Це твердження відоме також як Закон Гауса. Згідно з ним, нормальним називається такий розподіл усіх ймовірностей безперервної випадкової величини, який можна описати щільністю ймовірностей. Якщо припущення про нормальний розподіл виявилося помилковим, то оцінка може бути неправильною.
Спочатку розберемося з тим, як обчислити довірчий інтервал. Тут можливі два випадки. Дисперсія (ступінь розкиду випадкової величини) може бути відома чи ні. Якщо вона відома, то наш довірчий інтервал обчислюється за допомогою наступної формули:
хср - t*σ / (sqrt(n))<= α <= хср + t*σ / (sqrt(n)), где
α - ознака,
t - параметр таблиці розподілу Лапласа,
σ – квадратний корінь дисперсії.
Якщо дисперсія невідома, її можна розрахувати, якщо нам відомі всі значення шуканої ознаки. Для цього використовується така формула:
σ2 = х2ср - (хср)2 де
х2ср - середнє значення квадратів досліджуваної ознаки,
(ХСР)2 - квадрат даної ознаки.
Формула, за якою в цьому випадку розраховується довірчий інтервал, трохи змінюється:
хср - t * s / (sqrt (n))<= α <= хср + t*s / (sqrt(n)), где
хср - вибіркове середнє,
α - ознака,
t - параметр, який знаходять за допомогою таблиці розподілу Стьюдента t = t(?;n-1),
sqrt(n) - квадратний корінь загального обсягу вибірки,
s – квадратний корінь дисперсії.
Розглянь такий приклад. Припустимо, що за результатами 7 вимірів було визначено досліджуваного ознаки, що дорівнює 30 і дисперсія вибірки, що дорівнює 36. Потрібно знайти з ймовірністю 99% довірчий інтервал, який містить справжнє значення параметра, що вимірюється.
Спочатку визначимо чому t: t = t (0,99; 7-1) = 3.71. Використовуємо наведену вище формулу, отримуємо:
хср - t * s / (sqrt (n))<= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7))<= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
Довірчий інтервал для дисперсії розраховується як у випадку з відомим середнім, так і тоді, коли немає жодних даних про математичне очікування, а відомо лише значення точкової незміщеної оцінки дисперсії. Ми не наводитимемо тут формули його розрахунку, оскільки вони досить складні і за бажання їх завжди можна знайти в мережі.
Відзначимо лише, що довірчий інтервал зручно визначати за допомогою програми Excel або мережевого сервісу, що так і називається.
