Аналітичне згладжування часового ряду. Рівняння тренду
Пряма лінія – трендові значення рентабельності (лінійний тренд, побудований за даними фактичних значень рентабельності).
Приклад 14.6. Збудуємо лінійний тренд відсоткових ставок за кредитами на основі статистичних даних, опублікованих у Бюлетені банківської статистики № 4 (47) за 1997р.
Другим етапом є пошук значень параметрів рівняння. Параметри трендових моделей визначаються за допомогою системи нормальних рівнянь. У разі застосування лінійного тренду використовують наступну систему рівнянь, яку вирішують способом найменших квадратів
Приклад 14.7. Припускаючи наявність циклічних коливань, проведемо гармонійний аналіз динаміки відхилень від лінійного тренду даних про ставки за кредитами (у, - у,).
Лінійний тренд добре відображає тенденцію змін при дії багатьох різноманітних факторів, що змінюються різним чином за різними закономірностями. Рівночинна цих факторів при взаємопогашенні особливостей окремих фак-
При b = 1 маємо лінійний тренд, b = 2 – параболічний тощо. Ступінна форма - гнучка, придатна для відображення змін із різним заходом пропорційності змін у часі. Жорсткою умовою є обов'язкове проходження через початок координат при t = 0, у = 0. Можна ускладнити форму тренду у = а + th або у = а + th, але ці рівняння не можна логарифмувати, важко обчислювати параметри і вони вкрай рідко застосовуються.
Для лінійного тренду нормальні рівняння МНК мають вигляд
У формулі (9.33) підсумовування від = -(л-1) 2до/ = (л-1) 2 загалом формула (9.33) аналогічна формулі для лінійного тренду (9.29).
Відповідно до формули (9.29) параметри лінійного тренду дорівнюють а = 1894/11 = 172,2 ц/га 2>Л= 486/110 = 4,418 ц/га. Рівняння лінійного тренду має вигляд у = 172,2 + 4,418/, де (= 0 1987 р. Це означає, що середній фактичний і вирівняний рівень, віднесений до середини періоду, тобто до 1991 р., дорівнює 172 ц с 1 га, а середньорічний приріст становить 4,418 ц/га на рік.
Оскільки, за даними табл. 9.4, вже було встановлено, що тренд має лінійну форму , проводимо розрахунок середньорічного абсолютного приросту , тобто параметра рівняння лінійного тренду кіль-
Коливання помірна, не сильна. Для порівняння наводимо показники (без розрахунку) коливань урожайності картоплі, дані таблиць 9.1 і 9.5 - відхилення від лінійного тренду s(t) = 14,38 ц з 1 га, v(t) = 8,35%.
Для отримання достатньо надійних меж прогнозу положення тренду, скажімо, з імовірністю 0,9 того, що помилка буде не більшою за вказану, слід середню помилкупомножити на величину /-критерію Стьюдента при зазначеній ймовірності (або значущості 1 - 0,9 = 0,1) і за числі ступенів свободи, рівному, для лінійного тренду, N-2, тобто 15. Ця величина дорівнює 1,753. Отримуємо граничну з цією ймовірністю помилку
Іншим прийомом вимірювання кореляції у рядах динаміки може бути кореляція між тими з ланцюгових показників рядів, які є константами їх трендів. При лінійних трендах – це ланцюгові абсолютні прирости. Обчисливши їх за вихідними рядами динаміки (axl, ayi), знаходимо коефіцієнт кореляції між абсолютними змінами за формулою (9.52) або, що точніше, за формулою (9.51), оскільки середні зміни не дорівнюють нулю на відміну від середніх відхилень від трендів. Допустимість даного способу заснована на тому, що різниця між сусідніми рівнями в основному складається з коливань, а частка тренду в них невелика, отже, спотворення кореляції від тренду дуже велике при кумулятивному ефекті протягом тривалого періоду, дуже мало - за кожний рік окремо. Однак треба пам'ятати, що це справедливо лише для рядів із показником, суттєво меншим одиниці. У нашому прикладі для ряду врожайності з-показник дорівнює 0,144, для собівартості він дорівнює 0,350. Коефіцієнт кореляції абсолютних ланцюгових змін склав 0,928, що дуже близько до коефіцієнта кореляції відхилень від трендів.
В одному з попередніх прикладів ми розглянули прогноз щодо обсягу виробництва за два місяці певної компанії з Дубліна. Були отримані оцінки на 1997 рік, при цьому використовувався лінійний тренд та метод складання. Прогнозні значення наведені в тоннах
Значення k для оцінки довірчих інтервалів прогнозу щодо лінійного тренду з ймовірністю 0,8
Адаптивне моделювання лінійного тренду за допомогою експоненційних ковзних середніх.
Алгоритм обчислення параметрів лінійного тренду
Обчислити у першому наближенні параметри лінійного тренду
Визначити остаточні значення параметрів лінійного тренду
ЕМА помилок може погіршити якість прогнозу. У цьому випадку при розрахунку параметрів лінійного тренда необхідно зупинитися на кроці 2 цього алгоритму.
LN - лінійний тренд, сезонність не враховується
Якщо вважати, що зміни цін, всупереч міркувань ефективності на тривалих відрізках часу, визначаються численними і часто нелінійними зворотними зв'язками, то на основі теорії хаосу можна побудувати покращені моделі, що описують вплив минулого на сьогодення (див. -). Драматичні обвали ринку за відсутності істотних змінінформації, різкі зміни умов доступу та термінів при перетині компанією якогось невидимого порога в кредитній сфері – це прояви нелінійності. Реальна поведінка фінансових ринків швидше суперечить правилам обігу лінійних трендів, ніж підтверджує їх.
Метод послідовних різниць полягає в наступному, якщо ряд містить лінійний тренд, тоді вихідні дані замінюються першими різницями
Значення Лу немає чітко вираженої тенденції, вони варіюють навколо середнього рівня, що означає наявність у ряді динаміки лінійного тренду (лінійної тенденції). Аналогічний висновок можна зробити і з ряду х абсолютні прирости немає систематичної спрямованості, вони приблизно стабільні, отже, ряд характеризується лінійної тенденцією.
Це призвело до ідеї виміру кореляції не самих рівнів х, а перших різниць Дх, = х, - , 6у, - у, - у,.., (при лінійних трендах). У загальному випадкубуло визнано за необхідне корелювати відхилення від трендів (за вирахуванням циклічної компоненти) Еу -у, - %, Ех = х, - %, (у, % - тренди часових рядів).
На графіку рис. 5.3 наочно видно наявність зростання тенденції. Можливе існування лінійного тренду.
Параметри лінійного тренду можна інтерпретувати так: а - початковий рівень часового ряду в момент часу t = 0 b - середній за період абсолютний приріст рівнів ряду. Стосовно даного тимчасового ряду можна сказати, що темпи зростання номінальної місячної заробітної плати за 10 місяців 1999 р. змінювалися від рівня 82,66% із середнім протягом місяця абсолютним приростом , рівним 4,72 відс. пункту. Розрахункові за лінійним трендом значення рівнів часового ряду визначаються двома способами. По-перше, можна послідовно підставляти у знайдене рівняння тренда значення / = 1, 2,..., л, тобто.
По-друге, відповідно до інтерпретації параметрів лінійного тренду кожен наступний рівень ряду є сума попереднього рівня та середнього ланцюгового абсолютного приросту, тобто.
Таким чином, початковий рівень ряду відповідно до рівняння експоненційного тренду становить 83,96 (порівняйте з початковим рівнем 82,66 у лінійному тренді), а середній ланцюговий коефіцієнт зростання - 1,046. Отже, можна сказати, що
Лінійне рівняння тренду має вигляд y = at + b.
Параметри рівнянь функції тренда знаходять з допомогою теорії кореляції шляхом найменших квадратів.
1.Метод найменших квадратів.
Метод найменших квадратів МНК), є одним із способів протистояти помилкам вимірів. (Як у Фізиці похибка відхилень)
Цей метод зазвичай використовують для знаходження параметрів рівнянь (ліній, гіпербол парабол і т.д.)
Цей спосіб полягає у мінімізації суми квадратів відхилень.
Сенс МНК можна виразити через цей графік
2. Аналіз точності визначення оцінок параметрів рівняння тренда (по таблиці студента знаходимо ТТабл і робимо інтервальний прогноз, тобто виявляємо реднеквадратичну помилку)
3.Перевірка гіпотез щодо коефіцієнтів лінійного рівняннятренда (статистика критерій студента, фішера)
Перевірка на наявність автокореляції залишків.
Важливою передумовою побудови якісної регресійної моделі МНК є незалежність значень випадкових відхиленьвід значень відхилень у всіх інших спостереженнях. Це гарантує відсутність корелювання між будь-якими відхиленнями і, зокрема, між сусідніми відхиленнями.
Автокореляція (послідовна кореляція)
Автокореляція залишків (відхилень) зазвичай трапляється у регресійному аналізі під час використання даних часових рядів і дуже рідко під час використання перехресних даних.
Перевірка наявності гетероскедастичності.
1) Методом графічного аналізу залишків.
У цьому випадку осі абсцис відкладаються значення пояснюючої змінної X, а осі ординат або відхилення e i , або їх квадрати e 2 i .
Якщо є певний зв'язок між відхиленнями, то гетероскедастичність має місце. Відсутність залежності швидше за все свідчить про відсутність гетероскедастичності.
2) За допомогою тесту рангової кореляціїСпірмена.
Коефіцієнт рангової кореляції Спірмена.
36. Методи виміру стійкості тенденцій динаміки (коефіцієнт рангів Спірмена).
Поняття «стійкість» використовується у різних сенсах. По відношенню до статистичного вивчення динаміки ми розглянемо два аспекти цього поняття: 1) стійкість як категорія, протилежна коливання; 2) стійкість спрямованості змін, тобто. стійкість тенденції.
Стійкість у другому сенсі характеризує не власними силами рівні, а процес їх спрямованої зміни. Можна дізнатися, наприклад, наскільки стійкий процес скорочення питомих витрат ресурсів виробництва одиниці виробленої продукції, чи є стійкою тенденція зниження дитячої смертності тощо. буд. попередніх (стійке зростання), або нижче всіх попередніх (стійке зниження). Будь-яке порушення строгоранжированной послідовності рівнів свідчить про неповну стійкість змін.
З визначення поняття стійкості тенденції випливає і метод побудови її показателя. Як показник стійкості можна використовувати коефіцієнт кореляції рангів Ч.Спірмена (Spearman) - rx.
де п – число рівнів;
I - різниця рангів рівнів та номерів періодів часу.
При повному збігу рангів рівнів, починаючи з найменшого, та номерів періодів (моментів) часу за їх хронологічному порядкуКоефіцієнт кореляції рангів дорівнює +1. Це значення відповідає нагоди повної стійкості зростання рівнів. При повної протилежності рангів рівнів рангам років коефіцієнт Спірмена дорівнює -1, що означає повну стійкість процесу скорочення рівнів. При хаотичному чергуванні рангорівнів коефіцієнт близький до нуля, це означає нестійкість будь-якої тенденції.
Від'ємне значення rx вказує на наявність тенденції зниження рівнів, причому стійкість цієї тенденції нижче середньої.
У цьому слід пам'ятати, що за 100%-ной стійкості тенденції у ряду динаміки то, можливо коливність рівнів, і коефіцієнт їх стійкості буде ниже100%. При слабкої коливання, але ще більш слабкої тенденції, навпаки, можливий високий коефіцієнт стійкості рівнів, але близький до нуля коефіцієнт стійкості тренду. У цілому ж обидва показники пов'язані, звичайно, прямою залежністю: найчастіше більша стійкість рівнів спостерігається одночасно з більшою стійкістю тренду.
37. Моделювання тенденції низки динаміки за наявності структурних змін.
Від сезонних і циклічних коливань слід відрізняти одноразові зміни характеру тенденції часового ряду, спричинені структурними змінами економіки чи іншими чинниками. У цьому випадку, починаючи з деякого моменту часу t, відбувається зміна характеру динаміки показника, що вивчається, що призводить до зміни параметрів тренду, що описує цю динаміку.
Момент t супроводжується значними змінами ряду факторів, що надають сильний вплив на показник Моделювання тенденції тимчасового ряду за наявності структурних змін. Найчастіше ці зміни викликані змінами в загальноекономічній ситуації або подіями глобального характеру, що призвели до зміни структури економіки. Якщо досліджуваний тимчасовий ряд включає відповідний момент часу, то одним із завдань його вивчення стає з'ясування питання про те, чи значно вплинули загальні структурні зміни на характер цієї тенденції.
Якщо цей вплив значимо, то моделювання тенденції даного тимчасового низки слід використовувати кусочно-линейные моделі регресії, тобто. розділити вихідну сукупність на 2 підсукупності (до моменту часу t і після) і будувати окремо з кожної підсукупності рівняння лінійної регресії.
Якщо структурні зміни незначно вплинули на характер тенденції ряду Моделювання тенденції часового ряду за наявності структурних змін, то її можна писати за допомогою єдиного для всієї сукупності даних рівняння тренду.
Кожен із описаних вище підходів має свої позитивні та негативні сторони. При побудові шматково-лінійної моделі знижується залишкова сума квадратів у порівнянні з єдиним для всієї сукупності рівнянням тренду. Але поділ сукупності частини веде до втрати числа спостережень, і до зниження кількості ступенів свободи у кожному рівнянні кусочно-линейной моделі. Побудова єдиного рівняння тренду дозволяє зберегти число спостережень вихідної сукупності, але залишкова сума квадратів за цим рівнянням буде вищою порівняно з кусково-лінійною моделлю. Очевидно, що вибір моделі залежить від співвідношення між зниженням залишкової дисперсіїі втратою числа ступенів свободи під час переходу від єдиного рівняння регресії до шматково-лінійної моделі.
38. Регресійний аналіз зв'язкових динамічних рядів.
Багатовимірні часові ряди, що показують залежність результативної ознаки від одного або кількох факторних, називають зв'язковими рядами динаміки. Застосування методів найменших квадратів для обробки рядів динаміки не вимагає висування жодних припущень щодо законів розподілу вихідних даних. Однак при використанні методу найменших квадратів для обробки зв'язкових рядів слід враховувати наявність автокореляції (авторегресії), яка не враховувалася при обробці одномірних рядів динаміки, оскільки її наявність сприяла більш щільному та чіткому виявленню тенденції розвитку соціально-економічного явища, що розглядається в часі.
Виявлення автокореляції у рівнях низки динаміки
У рядах динаміки економічних процесів між рівнями, особливо близько розташованими, існує взаємозв'язок. Її зручно уявити як кореляційної залежності між рядами y1,y2,y3,…..yn h y1+h, y2+h,…, yn+h. Тимчасове зміщення L називається зрушенням, саме явище взаємозв'язку – автокореляцією.
Автокореляційна залежність особливо суттєва між наступними та попередніми рівнями низки динаміки.
Розрізняють два види автокореляції:
Автокореляція у спостереженнях за однією або більше змінними;
Автокореляція помилок або автокореляція у відхиленнях від тренду.
Наявність останньої призводить до спотворення середніх величин. квадратичних помилоккоефіцієнтів регресії, що ускладнює побудову довірчих інтервалів для коефіцієнтів регресії, а як і перевірку їх значимості.
Автокореляцію вимірюють з допомогою циклічного коефіцієнта автокореляції, що може розраховуватися як між сусідніми рівнями, тобто. зрушеними на один період, але і між зрушеними на будь-яку кількість одиниць часу (L). Цей зсув, що називається тимчасовим лагом, визначає і порядок коефіцієнтів автокореляції: першого порядку (при L = 1), другого порядку (при L = 2) і т.д. Однак найбільший інтерес для дослідження представляє обчислення нециклічного коефіцієнта (першого порядку), тому що найбільш сильні спотворення результатів аналізу виникають при кореляції між вихідними рівнями ряду і тими ж рівнями, зрушеними на одну одиницю часу.
Для судження про наявність чи відсутність автокореляції у досліджуваному ряду фактичне значення коефіцієнтів автокореляції зіставляється з табличним (критичним) для 5%-го чи 1%-го рівня значимості.
Якщо фактичне значення коефіцієнта автокореляції менше табличного, то гіпотеза про відсутність автокореляції у ряді можна прийняти. Коли ж фактичне значення більше табличного, можна дійти невтішного висновку про наявність автокореляції у низці динаміки.
При використанні поліномів різних ступенів оцінка параметрів рівняння тренду проводиться методом найменших квадратів (МНК) так само, як оцінки параметрів рівняння регресії на основі просторових даних. Як залежна змінна розглядаються рівні динамічного ряду, а як незалежна змінна – фактор часу t,який зазвичай виражається поруч натуральних чисел 1, 2, ..., п.
Оцінка властивостей нелінійних функцій проводиться МНК після лінеаризації, тобто. приведення їх до лінійного вигляду. Розглянемо застосування МНК деяких нелінійних функцій, які докладно викладалися у розділі, присвяченої регресії.
Для оцінки параметрів показової кривої у = ab 1 або експоненти у = еа+и (або у = аеы ) шляхом логарифмування функції наводяться до лінійного вигляду lny = ln a + t ln b або експоненти: lny = a + bt.Далі будується система нормальних рівнянь
Приклад 5.1
Число зареєстрованих ДТП (на 100 000 осіб населення) по Новгородській області за 2000-2008 рр. характеризується даними:
Виходячи з графіка було обрано показову криву / Для побудови системи нормальних рівнянь були розраховані допоміжні величини

Система нормальних рівнянь склала ![]()
Вирішуючи її, отримаємо значення
![]()
Відповідно маємо експоненту чи показову криву
За період з 2000 до 2008 р. кількість дорожньо-транспортних пригод зростала в середньому щорічно на 13,5%. Експонента досить добре описує тенденцію вихідного часового ряду: коефіцієнт детермінації становив 0,9202. Отже, даний тренд пояснює 92% коливань рівнів ряду і лише 8% її пов'язані з випадковими факторами.
Деяку специфіку має оцінка параметрів кривих із насиченням: модифікаційної експоненти, логістичної кривої, кривої Гомперця, гіперболи виду. За цими функціями має бути спочатку визначена асимптота. Якщо вона може бути задана дослідником на основі аналізу часового ряду, інші параметри можуть бути оцінені за МНК. У цих випадках ці функції призводять до лінійного вигляду. Розглянемо оцінку параметрів цих кривих окремих прикладах, починаючи з модифікованої експоненти.
Приклад 5.2
Рівень механізації праці (у%) характеризується динамічним рядом(Табл. 5.2)
Таблиця 5.2.Розрахунок параметрів модифікованої експоненти у = с ab" t
|
У = з-у |
|||||||
Так як рівень механізації праці не може перевищувати 100%, є об'єктивно задана верхня асимптота с = 100. Для оцінки параметрів аі bнаведемо розглянуту функцію до лінійного вигляду; позначимо (з-у) через Yта прологарифмуємо:
![]()
Для нашого прикладу, виходячи із даних підсумкового рядка табл. 3, маємо систему рівнянь
![]()
Вирішивши її, отримаємо ln а= 3,06311; ln b= -0,19744. Відповідно потенціюючи, отримаємо: тобто. рівняння.
Якщо перейти від Yдо вихідних рівнів ряду, рівняння модифікованої експоненти становитиме , де параметр показує середній коефіцієнт зниження рівня використання ручної праці за 1998–2005 роки. Розрахункові значення у, тобто. можуть бути знайдені шляхом підстановки рівняння 0,8208" відповідних значень t. Або на основі рівняння In 7 = 3,06311 - 0,19744 г при комп'ютерній обробці визначається In У і далі 100 - е 1пу. Так, за t = 8 In Y= = 1,48363 і 100 – e1"48363 = 100 – 4,40892 = 95,59108 = 95,6 (див. останню графу таблиці). Через деяку зміщеність оцінок (оскільки МНК застосовується до логарифмів) Ху, ФХу, хоча у прикладі ці величини досить близькі одна одній.
Якщо асимптота не задана, то оцінка параметрів модифікованої експоненти ускладнюється. У цих випадках можуть використовуватися різні методи оцінювання: метод трьох сум, метод трьох точок, за допомогою регресії, метод Бріанта. Розглянемо застосування методу регресії з метою оцінки параметрів модифікованої експоненти виду у = с – ab c.
Приклад 5.3
У таблиці представлені дані про витрати підприємства реклами за 10 міс. року.
Таблиця 5.3.Дані про витрати підприємства реклами за 10 міс. року (у тис. руб.)
Знайдемо по нашому ряду абсолютні ланцюгові приростиг і представимо їх через параметри нашої функції, T.e.z = c-ab"- З + ab"~ l = ab" 1 (1 – b). Відомо, що модифікованої експоненти логарифм абсолютних приростів лінійно залежить від часу t. Отже, можна записати, що lnz = Ιηα + (f - 1) lnb + ln (l - b). Позначимо Ιηα + ln(l – b) через d.Тоді lnz = d +(t-1) lnb, тобто. лінійне рівняння в логарифмах. Застосовуючи МНК, отримаємо оцінки параметрів d, lnb, відповідно і параметра Ь.У цьому прикладі виходячи з граф табл. 5.3 lnz та (t – 1) було виявлено рівняння регресії: lnz = 4,519641 – 0,20882 (t – 1). Виходячи з нього одержуємо lnb = -0,20882; b = 0,811538. 4,519641 = In a + In (1 - b) = In [α (1 - b)]. Тоді α (1 – b) = e4,519641, звідки параметра =91,80264/(1-0,811538) = 487,1145.
Далі можна знайти оцінку параметра як середнє значення з величин з = у+ ab", знайдених для кожного місяця (див. останню графу табл. 5.3). Гранична величина витрат на рекламу складе 516,4 тис. руб. Шукане рівняння тренду набуде вигляду
Розглянутий метод можна застосувати, якщо абсолютні прирости – величини позитивні. Якщо ж деякі прирости виявляться меншими за нуль, то потрібно проводити згладжування рівнів часового ряду методом ковзної середньої.
Для логістичної кривої Перла – Ріда аналогічно параметри а і b може бути знайдено МНК, якщо асимптота з задана. Тоді дана функціяперетворюється на лінійну з логарифмів ![]() позначимо через Yі прологарифмуємо, тобто. ). Далі параметри а та bвизначаються МНК, як у прикладі по табл. 5.3.
позначимо через Yі прологарифмуємо, тобто. ). Далі параметри а та bвизначаються МНК, як у прикладі по табл. 5.3.
Для логістичної кривої виду параметри а і b можуть бути оцінені МНК, якщо асимптота із заданою, так як у цьому випадку функція лінеаризується: ; позначимо через Yвеличину та прологарифмуємо: Далі, застосовуючи МНК, оцінюємо параметри аі b.
При практичних розрахунках значення верхньої асимптоти логістичної кривої може бути визначено виходячи з суті розвитку явища, різного родуобмежень щодо його зростання (нормативи споживання, законодавчі акти), і навіть графічно.
Якщо верхня асимптота не задана, то оцінки параметрів можуть використовуватися різні методи: Фішера, Юла, Родса, Нейра та інших. Порівняльна оцінка та огляд цих методів викладено у роботі E. М. Четыркина .
Покажемо з прикладу розрахунок параметрів логістичної кривою методом Фішера.
Приклад 5.4
Виробництво продукції характеризується даними, поданими у табл. 5.4.
Таблиця 5.4.Розрахунок параметрів логістичної кривої
Метод Фішера ґрунтується на визначенні похідної для логістичної кривої. Диференціюючи цю функцію по t, отримаємо рівняння
Позначимо темп приросту логістичної кривої через. Тоді, тобто. для z,маємо лінійну функціюз параметрами ата . Щоб знайти рішення, необхідно оцінити z. Припускаючи, що інтервали між рівнями у ряді динаміки рівні, Фішер запропонував приблизно оцінювати у вигляді рівняння , де п- 1. Для нашого прикладу значення z представлені у графі 3 табл. 5.4. Далі застосовуємо МНК до рівняння: , тобто. будуємо регресію z(оту(, беручи дані від t = 2 до f = 8.). а = 0,806. Це рівняння статистично значуще: F-критерій дорівнює 689,6; R 2 = 0,996. Відповідно для нього значущі й параметри: f-критерій для параметра адорівнює 47,2 і параметра – дорівнює -26,2. Так як , то і ![]() тобто. верхня асимптота виробництва продукції складає 403 од.
тобто. верхня асимптота виробництва продукції складає 403 од.
Після того, як знайдено параметри а і с, знаходимо параметр b. Для цього функціюпредставимо як Позначимо через Yвираз у лівій частині рівності, тобто..-Тоді маємо рівняння Прологарифмуємо його:. У цьому рівнянні вільний член є In Ь. Його можна визначити з першого рівняння системи нормальних рівнянь, а саме Для нашого прикладу маємо рівняння. Відповідно Таким чином, логістична крива запишеться у вигляді
![]()
Теоретичні значення цієї функції представлені у графі 6 табл. 5.4 (знайдені шляхом підстановки відповідних значень t). Вони досить близько підходять до вихідних даних: коефіцієнт кореляції з-поміж них дорівнює 0,999; через те, що у розрахунках використовувалися логарифми. Якщо припустити, що граничне значення обсягу виробництва дорівнює 400 од., тобто. застосувати МНК до рівняння, то отримаємо і b ==67,5; параметр апри комп'ютерній обробці визначається як -а =-0,8. Відповідно рівняння тренду запишеться як . Результати двох рівнянь досить близькі.
Параметри кривої Гомперца також можуть бути оцінені МНК, якщо асимптота з заданою, так як в цьому випадку дана функція зводиться до лінійного вигляду Прологарифмувавши її, отримаємо рівняння .
Вдруге прологарифмувавши, отримаємо рівняння ![]() , Позначивши через у*, lgb через Уі Ig(lga) через А, запишемо криву Гомперца в лінійному вигляді, для оцінки параметрів якої можна застосувати МНК.
, Позначивши через у*, lgb через Уі Ig(lga) через А, запишемо криву Гомперца в лінійному вигляді, для оцінки параметрів якої можна застосувати МНК.
При практичному застосуваннікривою Гомперца можуть виникнути деякі складності по динамічному ряду з тенденцією, що підвищується. У цьому випадку задається верхня асимптота с і логарифми. При повторному логарифмуванні в розрахунках використовуються лише позитивні значенняПродемонструємо можливість оцінки параметрів кривої Гомперца з верхньою асимптотою з прикладу динаміки по підприємству товарних запасів початку кожного місяця (тис. дол.).
Таблиця 5.5.Розрахунок параметрів кривої Гомперця
Відповідно до формули (9.29) параметри лінійного тренду дорівнюють а = 1894/11 = 172,2 ц/га; b= 486/110 = 4,418 ц/га. Рівняння лінійного тренду має вигляд:
у̂ = 172,2 + 4,418t, де t = 0 1987 р. Це означає, що середній фактичний і вирівняний рівень, віднесений до середини періоду, тобто. до 1991 р., дорівнює 172 ц з 1 ra a середньорічний приріст становить 4,418 ц/га на рік
Параметри параболічного тренду згідно (9.23) рівні- b = 4,418; a = 177,75; з =-0,5571. Рівняння параболічного тренду має вигляд у̃ = 177,75 + 4,418t - 0.5571t 2; t= 0 1991 р. Це означає, що абсолютний приріст врожайності уповільнюється загалом на 2·0,56 ц/га на рік протягом року. А сам абсолютний приріст не є константою параболічного тренду, а є середньої величиною у період. на рік, прийнятий початок відліку тобто. 1991, тренд проходить через точку з ординатою 77,75 ц/га; Вільний член параболічного тренду не є середнім рівнем у період. Параметри експоненційного тренду обчислюються за формулами (9.32) та (9.33) ln а= 56,5658/11 = 5,1423; потенціюючи, отримуємо а= 171,1; ln k= 2,853: 110 = 0,025936; потенціюючи, отримуємо k = 1,02628.
Рівняння експоненційного тренду має вигляд: y̅ = 171,1 · 1,02628 t.
Це означає, що середньорічний темп посту врожайності за період становив 102,63%. У точці прийнятий початок відліку, тренд проходить точку з ординатою 171,1 ц/га.
Розраховані за рівняннями трендів рівні записані трьох останніх графах табл. 9.5. Як видно за цими даними. Розрахункові значення рівнів за всіма трьома видами трендів різняться ненабагато, оскільки і прискорення параболи, і темпи зростання експоненти невеликі. Істотна відмінність має парабола - зростання рівнів з 1995 р. припиняється, у той час як при лінійному тренді рівні зростають і далі, а при експоненті їх ост прискорюється. Тому для прогнозів на майбутнє ці три тренди нерівноправні: при екстраполяції параболи на майбутні роки рівні різко розійдуться з прямою та експонентою, що видно з табл. 9.6. У цій таблиці представлено роздрук рішення на ПЕОМ за програмою «Statgraphics» тих же трьох трендів. Відмінність їх вільних членів від наведених вище пояснюється тим, що програма нумерує року не від середини, а від початку, тому вільні члени трендів відносяться до 1986 р., для якого t = 0. Рівняння експоненти на роздруківці залишено в логарифмованому вигляді. Прогноз зроблено п'ять років уперед, тобто. до 2001 р. При зміні початку координат (відліку часу) у рівнянні параболи змінюється і середній абсолютний приріст, параметр b.оскільки внаслідок негативного прискорення приріст постійно скорочується, яке максимум - на початку періоду. Константою параболи є лише прискорення.

У рядку Data наводяться рівні вихідного ряду; "Forecast summary" означає зведені дані для прогнозу. У наступних рядках – рівняння прямої, параболи, експоненти – у логарифмічному вигляді. Графа ME означає середню розбіжність між рівнями вихідного ряду та рівнями тренду (вирівняними). Для прямої і параболи ця розбіжність завжди дорівнює нулю. Рівні експоненти в середньому на 0,48852 нижче за рівні вихідного ряду. Точний збіг можливий, якщо справжній тренд - експонента; у разі збігу немає, але відмінність, мало. Графа ТРАВНІ - це дисперсія s 2 -міра коливання фактичних рівнів щодо тренду, про що сказано у п. 9.7. Графа МАЕ – середнє лінійне відхилення рівнів від тренда за модулем (див. параграф 5.8); графа МАРЕ – відносне лінійне відхилення у відсотках. Тут вони наведені як показники придатності обраного тренду. Найменшу дисперсію та модуль відхилення має парабола: вона за період 1986 – 1996 рр. . ближче до фактичних рівнів. Але вибір типу тренду не можна зводити лише до цього критерію. Насправді уповільнення приросту є результатом великого негативного відхилення, тобто неврожаю в 1996 р.
Друга половина таблиці - це прогноз рівнів урожайності за трьома видами трендів на роки; t = 12, 13, 14, 15 та 16 від початку відліку (1986 р.). Прогнозовані рівні по експоненті аж до 16-го року не набагато вище, ніж по прямій. Рівні тренда-параболи – знижуються, дедалі більше розходячись з іншими трендами.
Як бачимо в табл. 9.4 при обчисленні параметрів тренду рівні вихідного ряду входять з різними вагами - значеннями t pта їх квадратів. Тому вплив коливань рівнів на параметри тренду залежить від цього, який номер року припадає врожайний чи неврожайний рік. Якщо різке відхилення посідає рік із нульовим номером ( t i = 0), то воно ніякого впливу на параметри тренду не вплине, а якщо потрапить на початок і кінець ряду, то вплине сильно. Отже, одноразове аналітичне вирівнюваннянеповно звільняє параметри тренда від впливу коливання, і при сильних коливаннях можуть бути сильно спотворені, що в нашому прикладі трапилося з параболою. Для подальшого виключення впливу коливань, що спотворює, на параметри тренда слід застосувати метод багаторазового ковзного вирівнювання.
Цей прийом полягає в тому, що параметри тренду обчислюються не відразу по всьому ряду, а ковзним методом, спочатку за перші тперіодів часу або моментів, потім за період від 2-го до т + 1, від 3-го до (т + 2)-го рівня тощо. Якщо число вихідних рівнів ряду дорівнює п,а довжина кожної ковзної бази розрахунку параметрів дорівнює т,то число таких ковзних баз t або окремих значень параметрів, які будуть визначені, складе:
L = п + 1 - т.
Застосування методики ковзного багаторазового вирівнювання розглядати, як видно з наведених розрахунків, можливе лише за досить великому числірівнів ряду, як правило, 15 і більше. Розглянемо цю методику з прикладу даних табл. 9.4 -динаміки цін на непаливні товари країн, що розвиваються, що знову ж дає можливість читачеві брати участь у невеликому науковому дослідженні. На цьому прикладі продовжимо і методику прогнозування в розділі 9.10.
Якщо обчислювати в ряді параметри по 11 -літнім періодам(по 11 рівням), то t= 17 + 1 - 11 = 7. Сенс багаторазового ковзного вирівнювання в тому, що при послідовних зрушеннях бази розрахунку параметрів на кінцях її і в середині виявляться різні рівніз різними за знаком і величиною відхиленнями від тренда. Тому при одних зрушеннях бази параметри завищуватимуться, при інших - занижуватимуться, а при подальшому усередненні значень параметрів по всіх зрушеннях бази розрахунку відбудеться подальше взаємопогашення спотворень параметрів тренду коливаннями рівнів.
Багаторазове ковзне вирівнювання не тільки дозволяє отримати більш точну та надійну оцінку параметрів тренду, а й здійснити контроль правильності вибору типу рівняння тренду. Якщо виявиться, що провідний параметр тренда, його константа при розрахунку по ковзних базах не безладно коливається, а систематично змінює свою величину істотно, значить, тип тренда був обраний неправильно, даний параметр константою не є.
Що стосується вільного члена при багаторазовому вирівнюванні, то немає необхідності і, більше того, просто неправильно обчислювати його величину як середню за всіма зрушеннями бази, бо при такому способі окремі рівні вихідного ряду входили б до розрахунку середньої з різними вагами, і сума вирівняних рівнів розійшлася б із сумою членів вихідного ряду. Вільний член тренду – це середня величинарівня за період за умови відліку часу від середини періоду. При відліку від початку, якщо перший рівень t i= 1, вільний член дорівнюватиме: a 0 = у̅ - b((N-1)/2). Рекомендується довжину ковзної бази розрахунку параметрів тренду вибирати не менше 9-11 рівнів, щоб достатньо погасити коливання рівнів. Якщо вихідний ряд дуже довгий, то база може становити до 0,7 - 0,8 його довжини. Для усунення впливу довго-періодичних (циклічних) коливань на параметри тренду число зрушень бази повинно бути одно або кратно довжині циклу коливань. Тоді початок і кінець бази послідовно «пробігатимуть» всі фази циклу і при усередненні параметра по всіх зрушеннях його спотворення від циклічних коливань взаємопогашуватимуться. Інший спосіб - взяти довжину ковзної бази, що дорівнює довжині циклу, щоб початок бази і кінець бази завжди припадали на ту саму фазу циклу коливань.
Оскільки, за даними табл. 9.4 вже було встановлено, що тренд має лінійну форму, проводимо розрахунок середньорічного абсолютного приросту, тобто параметра bрівняння лінійного тренду ковзним способом з 11-річним базам (див. табл. 9.7). У ній наведено розрахунок даних, необхідних для подальшого вивчення коливання в параграфі 9.7. Зупинимося докладніше на методиці багаторазового вирівнювання по ковзних базах. Розрахуємо параметр bпо всіх базах:

Покажемо приклад докладного розрахунку параметрів рівняння тренду з урахуванням наступних даних (див. таблицю) з допомогою калькулятора .
Лінійне рівняння тренду має вигляд y = at + b.
1. Знаходимо параметри рівняння методом найменших квадратів.
Система рівнянь МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших даних система рівнянь має вигляд:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
З першого рівняння виражаємо а 0 і підставимо на друге рівняння
Отримуємо a 0 = 6.37, a 1 = 5.88
Примітка: значення шпальти №6 y(t) розраховуються на основі отриманого рівняння тренду. Наприклад, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Рівняння тренду
y = 6.37 t + 5.88Оцінимо якість рівняння тренду за допомогою помилки абсолютної апроксимації.
![]()
Оскільки помилка більше 15%, то дане рівняння не бажано використовувати як тренд.
Середні значення: ![]()
![]()
![]()
Дисперсія ![]()
Середньоквадратичне відхилення
Коефіцієнт еластичності ![]()
p align="justify"> Коефіцієнт еластичності менше 1. Отже, при зміні Х на 1%, Y зміниться менш ніж на 1%. Іншими словами - вплив Х на Y не суттєво.
Коефіцієнт детермінації 
тобто. у 82.04% випадків впливає зміна даних. Іншими словами – точність підбору рівняння тренда – висока
2. Аналіз точності визначення оцінок параметрів рівняння тренду.
Дисперсія помилки рівняння.
де m = 1 - кількість факторів, що впливають у моделі тренду.
Стандартна помилка рівняння.
3. Перевірка гіпотез щодо коефіцієнтів лінійного рівняння тренду.
1) t-статистика. Критерій Стьюдента.
За таблицею Стьюдента знаходимо Tтабл
T табл (n-m-1; α/2) = (10; 0.025) = 2.228
>
Статистична значущість коефіцієнта a0 підтверджується. Оцінка параметра a 0 є значущою і тренд у часового ряду існує.
Статистична значимість коефіцієнта a 1 не підтверджується.
Довірчий інтервал для коефіцієнтів рівняння тренду.
Визначимо довірчі інтервали коефіцієнтів тренду, які з надійністю 95% будуть такими:
(a 1 - t набл S a 1; a 1 + t набл S a 1)
(6.375 - 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 - t набл S a 0; a 0 + t набл S a 0)
(5.88 - 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так як точка 0 (нуль) лежить усередині довірчого інтервалу, то інтервальна оцінкакоефіцієнта a 0 статистично незначна.
2) F-статистика. Критерій Фішера. 
Fkp = 4.84
Оскільки F > Fkp, то коефіцієнт детермінації статистично значимий
Перевірка на наявність автокореляції залишків.
Важливою причиною побудови якісної регресійної моделі МНК є незалежність значень випадкових відхилень від значень відхилень в інших спостереженнях. Це гарантує відсутність корелювання між будь-якими відхиленнями і, зокрема, між сусідніми відхиленнями.
Автокореляція (послідовна кореляція)визначається як кореляція між показниками, що спостерігаються, упорядкованими в часі (тимчасові ряди) або в просторі (перехресні ряди). Автокореляція залишків (відхилень) зазвичай трапляється у регресійному аналізі під час використання даних часових рядів і дуже рідко під час використання перехресних даних.
В економічних завданнях значно частіше зустрічається позитивна автокореляція, ніж негативна автокореляція. Найчастіше позитивна автокореляція викликається спрямованим постійним впливом деяких неврахованих у моделі чинників.
Негативна автокореляціяФактично означає, що з позитивним відхиленням слід негативне і навпаки. Така ситуація може мати місце, якщо ту саму залежність між попитом на прохолодні напої та доходами розглядати за сезонними даними (зима-літо).
Серед основних причин, що викликають автокореляцію, можна виділити такі:
1. Помилки специфікації. Необлік моделі будь-якої важливої пояснюючої змінної чи неправильний вибір форми залежності зазвичай призводять до системним відхиленням точок спостереження лінії регресії, що може зумовити автокореляцію.
2. Інерція. Багато економічні показники(інфляція, безробіття, ВНП і т.д.) мають певну циклічність, пов'язану з хвилеподібністю ділової активності. Тому зміна показників відбувається не миттєво, а має певну інертність.
3. Ефект павутиння. У багатьох виробничих та інших сферах економічні показники реагують зміну економічних умов із запізненням (тимчасовим лагом).
4. Згладжування даних. Найчастіше дані по деякому тривалому часовому періоду отримують усереднення даних по складових його інтервалах. Це може призвести до певного згладжування коливань, які були всередині періоду, що розглядається, що в свою чергу може бути причиною автокореляції.
Наслідки автокореляції схожі з наслідками гетероскедастичність: висновки з t- та F-статистиків, що визначають значущість коефіцієнта регресії та коефіцієнта детермінації, можливо, будуть невірними.
Виявлення автокореляції
1. Графічний метод
Є низка варіантів графічного визначення автокореляції. Один із них пов'язує відхилення e i з моментами їх отримання i. У цьому по осі абсцис відкладають або час отримання статистичних даних, або порядковий номер спостереження, а, по осі ординат – відхилення e i (або оцінки отклонений).
Природно припустити, що й є певна зв'язок між відхиленнями, то автокореляція має місце. Відсутність залежності швидше за все свідчить про відсутність автокореляції.
Автокореляція стає наочнішою, якщо побудувати графік залежності e i від e i-1
Критерій Дарбіна-Уотсона.
Цей критерій є найбільш відомим виявлення автокореляції.
При статистичному аналізірівняння регресії на початковому етапічасто перевіряють здійсненність однієї передумови: умови статистичної незалежності відхилень між собою. При цьому перевіряється некорельованість сусідніх величин e i.
| y | y(x) | e i = y-y(x) | e 2 | (e i - e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для аналізу корелюваності відхилень використовують статистику Дарбіна-Уотсона:
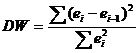
![]()
Критичні значення d 1 і d 2 визначаються на основі спеціальних таблиць для необхідного рівня значущості α, числа спостережень n = 12 та кількості змінних, що пояснюють m=1.
Автокореляція відсутня, якщо виконується така умова:
d 1< DW и d 2 < DW < 4 - d 2 .
Не звертаючись до таблиць, можна скористатися приблизним правилом і вважати, що автокореляція залишків відсутня, якщо 1.5< DW < 2.5. Поскольку 1.5 < 1.82 < 2.5, то автокорреляция остатков Відсутнє.
Для надійнішого висновку доцільно звертатися до табличних значень.
По таблиці Дарбіна-Уотсона для n=12 і k=1 (рівень значимості 5%) знаходимо: d 1 = 1.08; d2 = 1.36.
Оскільки 1.08< 1.82 и 1.36 < 1.82 < 4 - 1.36, то автокорреляция остатков Відсутнє.
Перевірка наявності гетероскедастичності.
1) Методом графічного аналізу залишків.
У цьому випадку осі абсцис відкладаються значення пояснюючої змінної X, а осі ординат або відхилення e i , або їх квадрати e 2 i .
Якщо є певний зв'язок між відхиленнями, то гетероскедастичність має місце. Відсутність залежності швидше за все свідчить про відсутність гетероскедастичності.
2) За допомогою тесту рангової кореляції Спірмена.
Коефіцієнт рангової кореляції Спірмена.
Надамо ранги ознакою Y і фактору X. Знайдемо суму різниці квадратів d 2 .
За формулою обчислимо коефіцієнт рангової кореляції Спірмена. ![]()
| t | e i | ранг X, d x | ранг e i , d y | (d x - d y) 2 |
| 1 | -5.14 | 1 | 4 | 9 |
| 2 | -8.27 | 2 | 2 | 0 |
| 3 | 2 | 3 | 7 | 16 |
| 4 | 7.68 | 4 | 9 | 25 |
| 5 | 10.55 | 5 | 11 | 36 |
| 6 | 9.63 | 6 | 10 | 16 |
| 7 | -0.2 | 7 | 6 | 1 |
| 8 | -4.52 | 8 | 5 | 9 | t табл (n-m-1;α/2) = (10; 0.05/2) = 2.228
