Оцінка значущості рівняння регресії та її параметрів. Оцінка статистичної значущості параметрів рівняння регресії
Після того як рівняння регресії побудовано та за допомогою коефіцієнта детермінації оцінено його точність, залишається відкритим питанняза рахунок чого досягнуто цієї точності і відповідно чи можна цьому рівнянню довіряти. Справа в тому, що рівняння регресії будувалося не за генеральної сукупності, яка невідома, а щодо вибірки з неї. Крапки з генеральної сукупності потрапляють у вибірку випадковим чином, тому відповідно до теорії ймовірності серед інших випадків можливий варіант, коли вибірка з “широкої” генеральної сукупності виявиться “вузькою” (рис. 15).
Мал. 15. Можливий варіантвлучення точок у вибірку з генеральної сукупності.
В цьому випадку:
а) рівняння регресії, побудоване на вибірку, може значно відрізнятися від рівняння регресії для генеральної сукупності, що призведе до помилок прогнозу;
б) коефіцієнт детермінації та інші характеристики точності виявляться невиправдано високими і вводитимуть в оману про прогнозні якості рівняння.
У граничному випадку не виключений варіант, коли з генеральної сукупності хмара з головною віссю паралельної горизонтальної осі (відсутня зв'язок між змінними) за рахунок випадкового відбору буде отримана вибірка, головна вісь якої виявиться нахиленою до осі. Таким чином, спроби прогнозувати чергові значення генеральної сукупності спираючись на дані вибірки з неї загрожують не тільки помилками в оцінці сили та напряму зв'язку між залежною та незалежною змінними, але й небезпекою знайти зв'язок між змінними там, де насправді її немає.
В умовах відсутності інформації про всі точки генеральної сукупності єдиний спосіб зменшити помилки в першому випадку полягає у використанні при оцінці коефіцієнтів рівняння регресії методу, що забезпечує їх незміщеність та ефективність. А ймовірність настання другого випадку може бути значно знижена завдяки тому, що апріорі відома одна властивість генеральної сукупності з двома незалежними один від одного змінними – в ній відсутня саме цей зв'язок. Досягається це зниження за рахунок перевірки статистичної значимостіотриманого рівняння регресії
Один з варіантів перевірки, що найчастіше використовуються, полягає в наступному. Для отриманого рівняння регресії визначається -статистика - характеристика точності рівняння регресії, що є відношенням тієї частини дисперсії залежною змінною яка пояснена рівнянням регресії до непоясненої (залишкової) частини дисперсії. Рівняння для визначення статистики у разі багатовимірної регресії має вигляд:

де: - Пояснена дисперсія - частина дисперсії залежною змінною Y яка пояснена рівнянням регресії;
Залишкова дисперсія - частина дисперсії залежною змінною Y яка не пояснена рівнянням регресії, її наявність є наслідком дії випадкової складової;
Число точок у вибірці;
Число змінних у рівнянні регресії.
Як видно з наведеної формули, дисперсії визначаються як окреме від поділу відповідної суми квадратів на число ступенів свободи. Число ступенів свободи це мінімально необхідне число значень залежної змінної, яких достатньо для отримання шуканої характеристики вибірки і які можуть вільно змінюватись з урахуванням того, що для цієї вибірки відомі всі інші величини, що використовуються для розрахунку потрібної характеристики.
Для отримання залишкової дисперсії потрібні коефіцієнти рівняння регресії. У разі парної лінійної регресії коефіцієнтів два, тому відповідно до формули (беручи ) число ступенів свободи дорівнює . Мається на увазі, що для визначення залишкової дисперсії достатньо знати коефіцієнти рівняння регресії і лише значень залежної змінної вибірки. Два значення, що залишилися, можуть бути обчислені на підставі цих даних, а значить, не є вільно варіюються.
Для обчислення поясненої дисперсії значень залежної змінної взагалі не потрібні, оскільки її можна обчислити, знаючи коефіцієнти регресії при незалежних змінних та дисперсію незалежної змінної. Для того щоб переконатися в цьому, достатньо згадати вираз, що наводився раніше. ![]() . Тому число ступенів свободи для залишкової дисперсії дорівнює числу незалежних змінних у рівнянні регресії (для парної лінійної регресії).
. Тому число ступенів свободи для залишкової дисперсії дорівнює числу незалежних змінних у рівнянні регресії (для парної лінійної регресії).
В результаті критерій для рівняння парної лінійної регресії визначається за формулою:
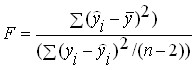 .
.
Теоретично ймовірності доведено, що критерій рівняння регресії, отриманого для вибірки з генеральної сукупності, у якої відсутній зв'язок між залежною і незалежною змінною має розподіл Фішера, досить добре вивчений. Завдяки цьому для будь-якого значення критерію можна розрахувати ймовірність його появи і навпаки, визначити те значення критерію яке він не зможе перевищити із заданою ймовірністю.
Для здійснення статистичної перевіркиЗначення рівняння регресії формулюється нульова гіпотеза про відсутність зв'язку між змінними (всі коефіцієнти при змінних дорівнюють нулю) і вибирається рівень значущості .
Рівень значущості – це припустима можливість зробити помилку першого роду – відкинути внаслідок перевірки правильну нульову гіпотезу. У даному випадку зробити помилку першого роду означає визнати за вибіркою наявність зв'язку між змінними в генеральній сукупності, коли насправді її там немає.
Зазвичай рівень значущості приймається рівним 5% чи 1%. Що рівень значимості (що менше ), то вище рівень надійності тесту, рівний , тобто. Тим більше шанс уникнути помилки визнання щодо вибірки наявності зв'язку у генеральної сукупності насправді незв'язаних між собою змінних. Але зі зростанням рівня значущості зростає небезпека скоєння помилки другого роду – відкинути правильну нульову гіпотезу, тобто. не помітити за вибіркою наявний насправді зв'язок змінних у генеральній сукупності. Тому залежно від того, яка помилка має великі негативні наслідки, Вибирають той чи інший рівень значущості.
Для обраного рівня значущості за розподілом Фішера визначається табличне значення ймовірність перевищення, якого у вибірці потужністю, отриманої з генеральної сукупності без зв'язку між змінними, не перевищує рівня значущості. порівнюється з фактичним значенням критерію для регресійного рівняння.
Якщо виконується умова, то помилкове виявлення зв'язку зі значенням -критерію рівним або більшим за вибіркою з генеральної сукупності з незв'язаними між собою змінними відбуватиметься з ймовірністю меншою за рівень значущості. Відповідно до правила "дуже рідкісних подій не буває", приходимо до висновку, що встановлений за вибіркою зв'язок між змінними є і в генеральній сукупності, з якої вона отримана.
Якщо виявляється , то рівняння регресії статистично не значимо. Іншими словами існує реальна ймовірністьтого, що за вибіркою встановлено не існує в реальності зв'язок між змінними. До рівняння, що не витримало перевірку на статистичну значущість, ставляться так само, як і до ліків з терміном, що минув термін придатності.
Ті – такі ліки не обов'язково зіпсовані, але якщо немає впевненості у їхній якості, то їх вважають за краще не використовувати. Це правило не вберігає від усіх помилок, але дозволяє уникнути найбільш грубих, що також досить важливо.
Другий варіант перевірки, зручніший у разі використання електронних таблиць, це зіставлення ймовірності появи отриманого значення -критерію з рівнем значущості. Якщо ця можливість виявляється нижче рівня значимості , отже рівняння статистично значуще, інакше немає.
Після того, як виконано перевірку статистичної значущості регресійного рівняння в цілому корисно, особливо для багатовимірних залежностей здійснити перевірку на статистичну значущість отриманих коефіцієнтів регресії. Ідеологія перевірки така ж як і при перевірці рівняння в цілому але як критерій використовується - критерій Стьюдента, що визначається за формулами:
 і
і 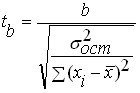
де: - значення критерію Стьюдента для коефіцієнтів і відповідно;
 - Залишкова дисперсія рівняння регресії;
- Залишкова дисперсія рівняння регресії;
Число точок у вибірці;
Число змінних у вибірці, для парної лінійної регресії.
Отримані фактичні значення критерію Стьюдента порівнюються з табличними значеннями ![]() отриманими з розподілу Стьюдента. Якщо виявляється, що , то відповідний коефіцієнт статистично значущий, інакше немає. Другий варіант перевірки статистичної значущості коефіцієнтів - визначити ймовірність появи критерію Стьюдента і порівняти з рівнем значущості.
отриманими з розподілу Стьюдента. Якщо виявляється, що , то відповідний коефіцієнт статистично значущий, інакше немає. Другий варіант перевірки статистичної значущості коефіцієнтів - визначити ймовірність появи критерію Стьюдента і порівняти з рівнем значущості.
Для змінних, чиї коефіцієнти виявилися статистично не значущими, велика ймовірність того, що їх вплив на залежну змінну в генеральній сукупності взагалі відсутній. Тому або необхідно збільшити кількість точок у вибірці, тоді можливо коефіцієнт стане статистично значущим і заодно уточниться його значення, або як незалежні змінні знайти інші, більш тісно пов'язані з залежною змінною. Точність прогнозування у разі обох випадках зросте.
Як експресний метод оцінки значущості коефіцієнтів рівняння регресії можна застосовувати наступне правило- Якщо критерій Стьюдента більше 3, то такий коефіцієнт, як правило, виявляється статистично значущим. А взагалі вважається, що для отримання статистично значимих рівнянь регресії необхідно, щоб виконувалася умова.
Стандартна помилка прогнозування отриманого рівняння регресії невідомого значення при відомому оцінюють за формулою:

Таким чином, прогноз з довірчою ймовірністю 68% може бути представлений у вигляді:
Якщо потрібна інша довірча ймовірність, то рівня значимості необхідно визначити критерій Стьюдента і довірчий інтервалдля прогнозу з рівнем надійності дорівнюватиме ![]() .
.
Прогнозування багатовимірних та нелінійних залежностей
Якщо прогнозована величина залежить від кількох незалежних змінних, то цьому випадку є багатовимірна регресія виду:
де: - Коефіцієнти регресії, що описують вплив змінних на прогнозовану величину.
Методика визначення коефіцієнтів регресії не відрізняється від парної лінійної регресії, особливо при використанні електронної таблиці, так як там застосовується та сама функція і для парної і для багатовимірної лінійної регресії. У цьому бажано щоб між незалежними змінними були відсутні взаємозв'язки, тобто. зміна однієї змінної не позначалося на значення інших змінних. Але ця вимога не є обов'язковою, важливо щоб між змінними були відсутні функціональні лінійні залежності. Описані вище процедури перевірки статистичної значущості отриманого рівняння регресії та її окремих коефіцієнтів, оцінка точності прогнозування залишається як і для випадку парної лінійної регресії. У той же час застосування багатомірних регресій замість парної зазвичай дозволяє при належному виборі змінних суттєво підвищити точність опису поведінки залежної змінної, а отже, і точність прогнозування.
Крім цього, рівняння багатовимірної лінійної регресії дозволяють описати і нелінійну залежність прогнозованої величини від незалежних змінних. Процедура наведення не лінійного рівняннядо лінійного виду називається лінеаризацією. Зокрема, якщо ця залежність описується поліномом ступеня відмінного від 1, то, здійснивши заміну змінних зі ступенями відмінними від одиниці на нові змінні в першому ступені, отримуємо завдання багатовимірної лінійної регресії замість нелінійної. Так, наприклад, якщо вплив незалежної змінної описується параболою виду
![]()
то заміна дозволяє перетворити нелінійне завдання до багатовимірного лінійного вигляду
![]()
Так само легко можуть бути перетворені нелінійні завдання, у яких нелінійність виникає внаслідок того, що прогнозована величина залежить від твору незалежних змінних. Для обліку такого впливу необхідно запровадити нову змінну, що дорівнює цьому твору.
У тих випадках, коли нелінійність описується складнішими залежностями, лінеаризація можлива за рахунок перетворення координат. Для цього розраховуються значення ![]() та будуються графіки залежності вихідних точок у різних комбінаціях перетворених змінних. Та комбінація перетворених координат або перетворених і не перетворених координат, в якій залежність найближче до прямої лінії підказує заміну змінних, яка призведе до перетворення нелінійної залежності до лінійного вигляду. Наприклад, нелінійна залежність виду
та будуються графіки залежності вихідних точок у різних комбінаціях перетворених змінних. Та комбінація перетворених координат або перетворених і не перетворених координат, в якій залежність найближче до прямої лінії підказує заміну змінних, яка призведе до перетворення нелінійної залежності до лінійного вигляду. Наприклад, нелінійна залежність виду
перетворюється на лінійну вигляду
Отримані коефіцієнти регресії для перетвореного рівняння залишаються незміщеними та ефективними, але перевірка статистичної значущості рівняння та коефіцієнтів неможлива
Перевірка обґрунтованості застосування методу найменших квадратів
Застосування методу найменших квадратів забезпечує ефективність та несмещенность оцінок коефіцієнтів рівняння регресії за дотримання наступних умов (умов Гауса-Маркова):
3. значення не залежать один від одного
4. значення не залежать від незалежних змінних
Найбільш просто можна перевірити дотримання цих умов шляхом побудови графіків залишків залежно від , Потім від незалежної (незалежних) змінних. Якщо точки на цих графіках розташовані в коридорі розташованому симетрично осі абсцис і розташування точок не проглядаються закономірності, то умови Гауса-Маркова виконані і можливості підвищити точність рівняння регресії відсутні. Якщо це не так, то існує можливість суттєво підвищити точність рівняння і для цього необхідно звернутись до спеціальної літератури.
ТЕМА 4. СТАТИСТИЧНІ МЕТОДИ ВИВЧЕННЯ ЗВ'ЯЗКІВ
Рівняння регресії -це аналітичне уявлення кореляційної залежності. Рівняння регресії визначає гіпотетичну функціональну залежність між умовним середнім значенням результативного ознаки і значенням ознаки – чинника (чинників), тобто. основну тенденцію залежності.
Парна кореляційна залежність описується рівнянням парної регресії, множинна кореляційна залежність – рівнянням множинної регресії.
Ознака-результат у рівнянні регресії – це залежна змінна (відгук, яка пояснюється змінна), а ознака-фактор – незалежна змінна (аргумент, що пояснює змінна).
Найпростішим видом рівняння регресії є рівняння парної лінійної залежності:
де y – залежна змінна (ознака-результат); x - незалежна змінна (ознака-фактор); та – параметри рівняння регресії; - Помилка оцінювання.
Як рівняння регресії можна використовувати різні математичні функції. Часте практичне застосуваннязнаходять рівняння лінійної залежності, параболи, гіперболи, степової функції та ін.
Як правило, аналіз починається з оцінки лінійної залежності, оскільки результати легко піддаються змістовній інтерпретації. Вибір типу рівняння зв'язку досить відповідальний етап аналізу. У «докомп'ютерну» епоху ця процедура була з певними труднощами і вимагала від аналітика знання властивостей математичних функцій. В даний час на базі спеціалізованих програм можна оперативно побудувати безліч рівнянь зв'язку та на основі формальних критеріїв здійснити вибір кращої моделі (проте математична грамотність аналітика не втратила своєї актуальності).
Гіпотезу про тип кореляційної залежності можна висунути за наслідками побудови поля кореляції (див. лекцію 6). Виходячи з характеру розташування точок на графіку (координати точок відповідають значенням залежної та незалежної змінних), виявляється тенденція зв'язку між ознаками (показниками). Якщо лінія регресії проходить через усі точки поля кореляції, це свідчить про функціональної зв'язку. У практиці соціально-економічних досліджень таку картину спостерігати не доводиться, оскільки є статистична (кореляційна) залежність. В умовах кореляційної залежності при нанесенні лінії регресії на діаграму розсіювання спостерігається відхилення точок поля кореляції від лінії регресії, що демонструє так звані залишки або помилки оцінювання (див. рис. 7.1).
Наявність помилки рівняння пов'язана з тим, що:
§ не всі фактори, що впливають на результат, враховуються в рівнянні регресії;
§ може бути невірно обрана форма зв'язку - рівняння регресії;
§ не всі фактори включені до рівняння.
Побудувати рівняння регресії означає розрахувати значення його параметрів. Рівняння регресії будується з урахуванням фактичних значень аналізованих ознак. Розрахунок параметрів зазвичай виконується з використанням методу найменших квадратів (МНК)
Суть МНКполягає в тому, що вдається отримати такі значення параметрів рівняння, при яких мінімізується сума квадратів відхилень теоретичних значень ознаки-результату (розрахованих на основі рівняння регресії) від фактичних його значень:
 ,
,
 де - фактичне значення ознаки-результату у i-ї одиницісукупності; - Значення ознаки-результату у i-ї одиниці сукупності, отримане за рівнянням регресії ().
де - фактичне значення ознаки-результату у i-ї одиницісукупності; - Значення ознаки-результату у i-ї одиниці сукупності, отримане за рівнянням регресії ().
Тобто вирішується завдання на екстремум, тобто необхідно знайти, при яких значеннях параметрів, функція S досягає мінімуму.
Проводячи диференціювання, прирівнюючи приватні похідні нулю:




 , (7.3)
, (7.3)
 , (7.4)
, (7.4)
де - середній добуток значень фактора та результату; - Середнє значення ознаки – фактора; - Середнє значення ознаки-результату; - Дисперсія ознаки-фактора.
Параметр у рівнянні регресії характеризує кут нахилу лінії регресії графіку. Цей параметр називають коефіцієнтом регресіїта його величина характеризує, наскільки одиниць свого виміру зміниться ознака-результат при зміні ознаки-фактора на одиницю свого виміру. Знак при коефіцієнті регресії відбиває спрямованість залежності (пряма чи зворотна) і збігається зі знаком коефіцієнта кореляції (за умов парної залежності).
У рамках аналізованого прикладу, у програмі STATISTICA розраховані параметри рівняння регресії, що описує залежність між рівнем середньодушових грошових доходів населення і величиною валового регіонального продукту душу населення регіонах Росії, див. таблицю 7.1.
Таблиця 7.1 - Розрахунок та оцінка параметрів рівняння, що описує залежністьміж рівнем середньодушових грошових доходів населення та величиною валового регіонального продукту на душу населення в регіонах Росії, 2013 р.

У графі "В" таблиці містяться значення параметрів рівняння парної регресії, отже можна записати: = 13406,89 + 22,82 x. Дане рівняння описує тенденцію зв'язку між аналізованими характеристиками. Параметр – це коефіцієнт регресії. У разі він дорівнює 22,82 і характеризує таке: зі збільшенням ВРП душу населення на 1 тыс.рублей середньодушові грошові доходи загалом зростають (на що вказує знак " + " ) на 22,28 крб.
Параметр рівняння регресії у соціально-економічних дослідженнях, як правило, змістовно не інтерпретується. Формально він відображає величину ознаки - результату за умови, що ознака - фактор дорівнює нулю. Параметр характеризує розташування лінії регресії на графіку, див. рисунок 7.1.

Рисунок 7.1 - Поле кореляції та лінія регресії, що відображають залежність рівня середньодушових грошових доходів населення в регіонах Росії та величини ВРП на душу населення
Значення параметра відповідає точці перетину лінії регресії з віссю Y, X=0.
Побудова рівняння регресії супроводжується оцінкою статистичної значущості рівняння загалом та її параметрів. Необхідність таких процедур пов'язана з обмеженим обсягом даних, що може перешкоджати дії закону великих чиселі, отже, виявлення справжньої тенденції у взаємозв'язку аналізованих показників. З іншого боку, будь-яку досліджувану сукупність можна як вибірку з генеральної сукупності, а характеристики, отримані під час аналізу, як оцінку генеральних параметрів.
Оцінка статистичної значущості параметрів та рівняння в цілому – це обґрунтування можливості використання побудованої моделі зв'язку для прийняття управлінських рішень та прогнозування (моделювання).
Статистична значущість рівняння регресіїзагалом оцінюється з використанням F-критерія Фішера, який являє собою відношення факторної та залишкових дисперсій, розрахованих на один ступінь свободи:
де  - факторна дисперсія ознаки – результату; k – число ступенів свободи факторної дисперсії (кількість факторів у рівнянні регресії); - Середнє значення залежної змінної; - теоретичне (отриманої за рівнянням регресії) значення залежної змінної у i - й одиниці сукупності;
- факторна дисперсія ознаки – результату; k – число ступенів свободи факторної дисперсії (кількість факторів у рівнянні регресії); - Середнє значення залежної змінної; - теоретичне (отриманої за рівнянням регресії) значення залежної змінної у i - й одиниці сукупності;  - залишкова дисперсіяознаки – результату; n – обсяг сукупності; n-k-1 – число ступенів свободи залишкової дисперсії.
- залишкова дисперсіяознаки – результату; n – обсяг сукупності; n-k-1 – число ступенів свободи залишкової дисперсії.
Величина F-критерію Фішера, згідно з формулою, характеризує співвідношення між факторною та залишковою дисперсіями залежною змінною, демонструючи, по суті, у скільки разів величина поясненої частини варіації перевищує непояснену.
F-критерій Фішера табульований, входом до таблиці є число ступенів свободи факторної та залишкової дисперсій. Порівняння розрахункового значення критерію з табличним (критичним) дозволяє відповісти на питання: чи статистично значуща та частина варіації ознаки-результату, яку вдається пояснити факторами, включеними до рівняння цього виду. Якщо  , то рівняння регресії визнається статистично значущим і, відповідно, статистично значущим і коефіцієнтом детермінації. В іншому випадку (
, то рівняння регресії визнається статистично значущим і, відповідно, статистично значущим і коефіцієнтом детермінації. В іншому випадку (  ), рівняння – статистично незначимо, тобто. Варіація врахованих у рівнянні чинників не пояснює статистично значимої частини варіації ознаки-результату, або правильно обрано рівняння зв'язку.
), рівняння – статистично незначимо, тобто. Варіація врахованих у рівнянні чинників не пояснює статистично значимої частини варіації ознаки-результату, або правильно обрано рівняння зв'язку.
Оцінка статистичної значущості параметрів рівнянняздійснюється на основі t-статистикияка розраховується як відношення модуля параметрів рівняння регресії до їх стандартних помилок (  ):
):
 , де
, де  ; (7.6)
; (7.6)
 , де
, де  ; (7.7)
; (7.7)
де  - стандартні відхиленняознаки - фактора та ознаки - результату; - Коефіцієнт детермінації.
- стандартні відхиленняознаки - фактора та ознаки - результату; - Коефіцієнт детермінації.
 У спеціалізованих статистичних програмах розрахунок параметрів завжди супроводжується розрахунком значень їх стандартних (середньоквадратичних) помилок та t-статистики (див. таблицю 7.1). Розрахункове значення t-статистики порівнюється з табличним, якщо обсяг сукупності, що вивчається, менше 30 одиниць (безумовно мала вибірка), слід звернутися до таблиці t-розподілу Стьюдента, якщо обсяг сукупності великий, слід скористатися таблицею нормального розподілу (інтеграла ймовірностей Лапласа). Параметр рівняння визнається статистично значущим, якщо.
У спеціалізованих статистичних програмах розрахунок параметрів завжди супроводжується розрахунком значень їх стандартних (середньоквадратичних) помилок та t-статистики (див. таблицю 7.1). Розрахункове значення t-статистики порівнюється з табличним, якщо обсяг сукупності, що вивчається, менше 30 одиниць (безумовно мала вибірка), слід звернутися до таблиці t-розподілу Стьюдента, якщо обсяг сукупності великий, слід скористатися таблицею нормального розподілу (інтеграла ймовірностей Лапласа). Параметр рівняння визнається статистично значущим, якщо.
Оцінка параметрів на основі t-статистики, по суті, є перевіркою нульової гіпотези про рівність генеральних параметрів нулю (H 0: =0; H 0: = 0;), тобто про статистично не значущу величину параметрів рівняння регресії. Рівень значущості гіпотези, зазвичай, приймається: = 0,05. Якщо розрахунковий рівень значимості менше 0,05, то нульова гіпотеза відкидається і приймається альтернативна - статистичної значущості параметра.
 Продовжимо розгляд прикладу. У таблиці 7.1 у графі «B» наведено значення параметрів, у графі Std.Err.ofB – величини стандартних помилок параметрів ( ), у графі t(77 – число ступенів свободи) розраховані значення t – статистики з урахуванням числа ступенів свободи. Для оцінки статистичної значущості параметрів розрахункові значення t – статистик необхідно порівняти з табличним значенням. Заданого рівня значущості (0,05) у таблиці нормального розподілу відповідає t = 1,96. Бо 18,02, 10,84, тобто. , Слід визнати статистичну значимість отриманих значень параметрів, тобто. ці значення сформовані під впливом невипадкових факторів і відображають тенденцію зв'язку між аналізованими показниками.
Продовжимо розгляд прикладу. У таблиці 7.1 у графі «B» наведено значення параметрів, у графі Std.Err.ofB – величини стандартних помилок параметрів ( ), у графі t(77 – число ступенів свободи) розраховані значення t – статистики з урахуванням числа ступенів свободи. Для оцінки статистичної значущості параметрів розрахункові значення t – статистик необхідно порівняти з табличним значенням. Заданого рівня значущості (0,05) у таблиці нормального розподілу відповідає t = 1,96. Бо 18,02, 10,84, тобто. , Слід визнати статистичну значимість отриманих значень параметрів, тобто. ці значення сформовані під впливом невипадкових факторів і відображають тенденцію зв'язку між аналізованими показниками.
Для оцінки статистичної значущості рівняння загалом звернемося до значення F-критерію Фішера (див. таблицю 7.1). Розрахункове значення F-критерію = 117,51, табличне значення критерію, виходячи з відповідного числа ступенів свободи (для факторної дисперсії d.f. =1, для залишкової дисперсії d.f. =77), дорівнює 4,00 (див. додаток.... .). Таким чином,  Отже, рівняння регресії загалом статистично значуще. У разі можна говорити про статистичної значимості величини коефіцієнта детермінації, тобто. Варіація середньодушових доходів населення регіонах Росії на 60 відсотків можна пояснити варіацією обсягів валового регіонального продукту душу населення.
Отже, рівняння регресії загалом статистично значуще. У разі можна говорити про статистичної значимості величини коефіцієнта детермінації, тобто. Варіація середньодушових доходів населення регіонах Росії на 60 відсотків можна пояснити варіацією обсягів валового регіонального продукту душу населення.
Проводячи оцінку статистичної значимості рівняння регресії та її параметрів, можемо отримати різне поєднання результатів.
· Рівняння за F-критерієм статистично значуще і всі параметри рівняння з t-статистики теж статистично значущі. Це рівняння може бути використане як для прийняття управлінських рішень (на які фактори слід впливати, щоб отримати бажаний результат), так і для прогнозування поведінки ознаки-результату при тих чи інших значеннях факторів.
· За F-критерієм рівняння статистично значуще, але незначні параметри (параметр) рівняння. Рівняння може бути використане для прийняття управлінських рішень (що стосуються тих факторів, якими отримано підтвердження статистичної значущості їх впливу), але рівняння не може бути використане для прогнозування.
· Рівняння за F-критерієм статистично незначне. Рівняння не можна використовувати. Слід продовжити пошук значимих ознак-факторів чи аналітичної форми зв'язку аргументу та відгуку.
Якщо доведено статистична значимість рівняння та її параметрів, може бути реалізований, про, точковий прогноз, тобто. отримано оцінку значення ознаки-результату (y) при тих чи інших значеннях фактора (x).
Цілком очевидно, що прогнозне значення залежної змінної, розраховане на основі рівняння зв'язку, не співпадатиме з фактичним її значенням (  ).Графічно ця ситуація підтверджується тим, що не всі точки поля кореляції лежать на лінії регресії,тільки при функціональному зв'язку лінія регресії пройде через усі точки діаграми розсіювання. Наявність розбіжностей між фактичними і теоретичними значеннями залежної змінної пов'язано, передусім, із суттю кореляційної залежності: одночасно на результат впливає безліч чинників, у тому числі лише частина може бути врахована у конкретному рівнянні зв'язку. Крім того, може бути неправильно обрана форма зв'язку результату та фактора (тип рівняння регресії). У зв'язку з цим постає питання, наскільки інформативно побудоване рівняння зв'язку. На це питання відповідають два показники: коефіцієнт детермінації (про нього вже говорилося вище) та стандартна помилка оцінювання.
).Графічно ця ситуація підтверджується тим, що не всі точки поля кореляції лежать на лінії регресії,тільки при функціональному зв'язку лінія регресії пройде через усі точки діаграми розсіювання. Наявність розбіжностей між фактичними і теоретичними значеннями залежної змінної пов'язано, передусім, із суттю кореляційної залежності: одночасно на результат впливає безліч чинників, у тому числі лише частина може бути врахована у конкретному рівнянні зв'язку. Крім того, може бути неправильно обрана форма зв'язку результату та фактора (тип рівняння регресії). У зв'язку з цим постає питання, наскільки інформативно побудоване рівняння зв'язку. На це питання відповідають два показники: коефіцієнт детермінації (про нього вже говорилося вище) та стандартна помилка оцінювання.
Різницю між фактичними та теоретичними значеннями залежної змінної називають відхиленнями чи помилками, чи залишками. За підсумками цих величин розраховується залишкова дисперсія. Квадратний коріньз залишкової дисперсії і є середньоквадратичною (стандартною) помилкою оцінювання:
 =
=  (7.8)
(7.8)
Стандартна помилка рівняння вимірюється у тих самих одиницях, як і прогнозований показник. Якщо помилки рівняння підкоряються нормальному розподілу (при великих обсягах даних), то 95 відсотків значень повинні знаходитися від лінії регресії на відстані, що не перевищує 2S (виходячи з якості нормального розподілу - правила трьох сигм). Розмір стандартної помилки оцінювання використовується при розрахунку довірчих інтервалів при прогнозуванні значення ознаки - результату конкретної одиниці сукупності.
У практичних дослідженнях часто виникає необхідність у прогнозі середнього значення ознаки – результату при тому чи іншому значенні ознаки – фактора. У цьому випадку з розрахунку довірчого інтервалу для середнього значення залежної змінної()
враховується величина середньої помилки:
 (7.9)
(7.9)
Використання різних величин помилок пояснюється тим, що мінливість рівнів показників у конкретних одиниць сукупності набагато вища, ніж мінливість середнього значення, отже помилка прогнозу середнього значення менше.
Довірчий інтервал прогнозу середнього значення залежної змінної:
 , (7.10)
, (7.10)
де  - гранична помилкаоцінки (див. теорію вибірки); t - коефіцієнт довіри, значення якого знаходиться у відповідній таблиці, виходячи з прийнятого дослідником рівня ймовірності (числа ступенів свободи) (див. теорію вибірки).
- гранична помилкаоцінки (див. теорію вибірки); t - коефіцієнт довіри, значення якого знаходиться у відповідній таблиці, виходячи з прийнятого дослідником рівня ймовірності (числа ступенів свободи) (див. теорію вибірки).
Довірчий інтервал для прогнозованого значення ознаки-результату може бути розрахований і з урахуванням поправки на зсув лінії лінії регресії. Величина поправочного коефіцієнта визначається:
 (7.11)
(7.11)
де - значення ознаки-фактора, виходячи з якого, прогнозується значення ознаки-результату.
 Звідси випливає, що більше значення відрізняється від середнього значення ознаки-фактора, тим більша величинакоригувального коефіцієнта, тим більша помилка прогнозу. З урахуванням даного коефіцієнта довірчий інтервал прогнозу розраховуватиметься:
Звідси випливає, що більше значення відрізняється від середнього значення ознаки-фактора, тим більша величинакоригувального коефіцієнта, тим більша помилка прогнозу. З урахуванням даного коефіцієнта довірчий інтервал прогнозу розраховуватиметься:
На точність прогнозу з урахуванням рівняння регресії можуть впливати різні причини. Насамперед, слід враховувати, що оцінка якості рівняння та його параметрів проводиться, виходячи з припущення про нормальному розподілівипадкових залишків. Порушення цього припущення може бути пов'язане з наявністю різко відмінних значень даних, з нерівномірною варіацією, з наявністю нелінійної залежності. І тут якість прогнозу знижується. Другий момент, про який слід пам'ятати, - значення факторів, що враховуються під час прогнозування результату, не повинні виходити за межі розмаху варіації даних, на основі яких побудовано рівняння.
©2015-2019 сайт
Усі права належати їх авторам. Цей сайт не претендує на авторства, а надає безкоштовне використання.
Дата створення сторінки: 2018-01-08
Оцінивши параметри aі b, ми отримали рівняння регресії, яким можна оцінити значення yза заданими значеннями x. Природно вважати, що розрахункові значення залежної змінної нічого очікувати збігатися з дійсними значеннями, оскільки лінія регресії визначає взаємозв'язок лише середньому, загалом. Окремі значення розпорошені навколо неї. Таким чином, надійність одержуваних за рівнянням регресії розрахункових значень багато в чому визначається розсіюванням значень, що спостерігаються навколо лінії регресії. На практиці, як правило, дисперсія помилок невідома та оцінюється за спостереженнями одночасно з параметрами регресії. aі b. Цілком логічно припустити, що оцінка пов'язана із сумою квадратів залишків регресії. Величина є вибірковою оцінкою дисперсії обурень, що містяться в теоретичної моделі ![]() . Можна показати, що для моделі парної регресії
. Можна показати, що для моделі парної регресії
де - Відхилення фактичного значення залежної змінної від її розрахункового значення.
Якщо ![]() , то всім спостережень фактичні значення залежної змінної збігаються з розрахунковими (теоретичними) значеннями .
Графічно це означає, що теоретична лінія регресії (лінія, побудована за функцією ) проходить через усі точки кореляційного поля, що можливе лише за строго функціонального зв'язку. Отже, результативна ознака уповністю зумовлений впливом фактора х.
, то всім спостережень фактичні значення залежної змінної збігаються з розрахунковими (теоретичними) значеннями .
Графічно це означає, що теоретична лінія регресії (лінія, побудована за функцією ) проходить через усі точки кореляційного поля, що можливе лише за строго функціонального зв'язку. Отже, результативна ознака уповністю зумовлений впливом фактора х.
Зазвичай практично має місце деяке розсіювання точок кореляційного поля щодо теоретичної лінії регресії, т. е. відхилення емпіричних даних від теоретичних . Цей розкид обумовлений як впливом фактора х, тобто. регресією yпо х, (Таку дисперсію називають поясненою, так як вона пояснюється рівнянням регресії),так і дією інших причин (непояснена варіація, випадкова). Величина цих відхилень лежить в основі розрахунку показників якості рівняння.
Згідно з основним положенням дисперсійного аналізу загальна сума квадратів відхилень залежної змінної yвід середнього значення може бути розкладена на дві складові: пояснену рівнянням регресії та непояснену:
 ,
,
де - значення y, обчислені за рівнянням .
Знайдемо відношення суми квадратів відхилень, поясненої рівнянням регресії, до загальної суми квадратів:
 , звідки
, звідки
 . (7.6)
. (7.6)
Відношення частини дисперсії, поясненої рівнянням регресії до загальної дисперсіїрезультативної ознаки називається коефіцієнтом детермінації. Значення неспроможна перевершити одиниці і це максимальне значення буде досягнуто при , тобто. коли кожне відхилення дорівнює нулю і тому всі точки діаграми розсіювання точно лежать на прямій.
Коефіцієнт детермінації характеризує частку поясненої регресією дисперсії у загальній величині дисперсії залежною змінною . Відповідно величина характеризує частку варіації (дисперсії) у,непояснену рівнянням регресії, а отже, викликану впливом інших неврахованих у моделі факторів. Чим ближче до одиниці, тим вища якість моделі.
При парній лінійній регресії коефіцієнт детермінації дорівнює квадратупарного лінійного коефіцієнтакореляції: .
Корінь із цього коефіцієнта детермінації є коефіцієнт (індекс) множинної кореляції, або теоретичне кореляційне відношення.
Для того щоб дізнатися, чи дійсно отримане при оцінці регресії значення коефіцієнта детермінації відображає справжню залежність між yі xвиконують перевірку значимості побудованого рівняння загалом та окремих параметрів. Перевірка значущості рівняння регресії дозволяє дізнатися, чи придатне рівняння регресії для практичного використання, наприклад, для прогнозу чи ні.
При цьому висувають основну гіпотезу про незначущість рівняння в цілому, яка формально зводиться до гіпотези про рівність нулю параметрів регресії, або, що те саме, про рівність нуля коефіцієнта детермінації: . Альтернативна гіпотеза про значущість рівняння - гіпотеза про нерівність нулю параметрів регресії або про нерівність нулю коефіцієнта детермінації: .
Для перевірки значущості моделі регресії використовують F-критерій Фішера, що обчислюється як відношення суми квадратів (з розрахунку на одну незалежну змінну) до залишкової суми квадратів (з розрахунку на один ступінь свободи):
 , (7.7)
, (7.7)
де k- Число незалежних змінних.
Після поділу чисельника та знаменника співвідношення (7.7) на загальну сумуквадратів відхилень залежною змінною, F-критерій може бути еквівалентно виражений на основі коефіцієнта:
 .
.
Якщо нульова гіпотеза справедлива, то пояснена рівнянням регресії та непояснена (залишкова) дисперсії не відрізняються одна від одної.
Розрахункове значення F-критерій порівнюється з критичним значенням, яке залежить від кількості незалежних змінних k, та від числа ступенів свободи (n-k-1). Табличне (критичне) значення F-критерію – це максимальна величина відносин дисперсій, що може бути при випадковому розбіжності їх за заданого рівня ймовірності наявності нульової гіпотези. Якщо розрахункове значення F-критерій більше табличного при заданому рівні важливості, то нульова гіпотеза про відсутність зв'язку відхиляється і робиться висновок про суттєвість зв'язку, тобто. модель вважається значною.
Для моделі парної регресії
 .
.
У лінійній регресії зазвичай оцінюється значущість як рівняння загалом, а й окремих його коефіцієнтів. Для цього визначається стандартна помилка кожного параметра. Стандартні помилки коефіцієнтів регресії параметрів визначаються за формулами:
 , (7.8)
, (7.8)
 (7.9)
(7.9)
Стандартні помилки коефіцієнтів регресії або середньоквадратичні відхилення, розраховані за формулами (7.8,7.9), як правило, наводяться у результатах розрахунку моделі регресії у статистичних пакетах.
Маючи середньоквадратичні помилки коефіцієнтів регресії, перевіряють значимість цих коефіцієнтів використовуючи звичайну схему перевірки статистичних гіпотез.
Як основну гіпотезу висувають гіпотезу про незначну відмінність від нуля «справжнього» коефіцієнта регресії. Альтернативною гіпотезою у своїй є гіпотеза зворотна, т. е. про нерівність нулю «істинного» параметра регресії. Перевірка цієї гіпотези здійснюється за допомогою t-статистики, що має t-розподіл Стьюдента:
Потім розрахункові значення t-статистики порівнюються з критичними значеннями t-статистики, що визначаються за таблицями розподілу Стьюдента. Критичне значення визначається залежно від рівня значимості α та числа ступенів свободи, яке дорівнює (n-k-1), п -кількість спостережень, k- Число незалежних змінних. У разі лінійної парної регресії число ступенів свободи дорівнює (п- 2). Критичне значення також може бути обчислено на комп'ютері за допомогою вбудованої функції СТЮДРАСПОБР пакету Ехсеl.
Якщо розрахункове значення t-статистики більше критичного, то основну гіпотезу відкидають і вважають, що з ймовірністю (1-α)«Істинний» коефіцієнт регресії істотно відрізняється від нуля, що статистичним підтвердженням існування лінійної залежності відповідних змінних.
Якщо розрахункове значення t-статистики менше критичного, немає підстав відкидати основну гіпотезу, т. е. «справжній» коефіцієнт регресії незначно відрізняється від нуля за рівня значимості α . У цьому випадку фактор, що відповідає цьому коефіцієнту, повинен бути виключений з моделі.
Значимість коефіцієнта регресії можна встановити шляхом побудови довірчого інтервалу. Довірчий інтервал для параметрів регресії aі bвизначають наступним чином:
![]() ,
,
![]() ,
,
де визначається за таблицею розподілу Стьюдента рівня значимості α та числа ступенів свободи (п- 2) для парної регресії.
Оскільки коефіцієнти регресії в економетричних дослідженнях мають чітку економічну інтерпретацію, довірчі інтервали повинні містити нуль. Справжнє значення коефіцієнта регресії неспроможна одночасно містити позитивні і негативні величини, зокрема й нуль, інакше ми отримуємо суперечливі результати за економічної інтерпретації коефіцієнтів, чого може бути. Таким чином, коефіцієнт значимий, якщо отриманий довірчий інтервал не накриває нуль.
Приклад 7.4.За даними прикладу 7.1:
а) Побудувати парну лінійну модель регресії залежності прибутку від від відпускної ціни з допомогою програмних засобів обробки даних.
б) Оцінити значимість рівняння регресії загалом, використовуючи F-критерій Фішера при α=0,05.
в) Оцінити значущість коефіцієнтів моделі регресії, використовуючи t-критерій Стьюдента при α=0,05і α=0,1.
Для проведення регресійного аналізувикористовуємо стандартну офісну програму EXCEL. Побудову регресійної моделі проведемо за допомогою інструмента РЕГРЕСІЯ налаштування ПАКЕТ АНАЛІЗУ (рис.7.5), запуск якого здійснюється наступним чином:
СервісАналіз данихРЕГРЕСІЯОК.

Рис.7.5. Використання інструменту РЕГРЕСІЯ
У діалоговому вікні РЕГРЕСІЯ в полі Вхідний інтервал Y необхідно ввести адресу діапазону осередків, що містять залежну змінну. У полі Вхідний інтервал Х потрібно ввести адреси одного або декількох діапазонів, що містять значення незалежних змінних Прапорець Мітки в першому рядку – встановлюється в активний стан, якщо виділені заголовки стовпців. На рис. 7.6. показано екранну форму обчислення моделі регресії за допомогою інструмента РЕГРЕСІЯ.

Мал. 7.6. Побудова моделі парної регресії за допомогою
інструменту РЕГРЕСІЯ
В результаті роботи інструменту РЕГРЕСІЯ формується наступний протокол регресійного аналізу (рис.7.7).

Мал. 7.7. Протокол регресійного аналізу
Рівняння залежності прибутку від відпускної ціни має вигляд:
Оцінку значущості рівняння регресії проведемо використовуючи F-критерій Фішера. Значення F-критерій Фішера візьмемо з таблиці Дисперсійний аналіз»Протоколу EXCEL (рис. 7.7.). Розрахункове значення F-критерію 53,372. Табличне значення F-критерію при рівні значимості α=0,05та числі ступенів свободи ![]() складає 4,964. Так як
складає 4,964. Так як ![]() , то рівняння вважається значним.
, то рівняння вважається значним.
Розрахункові значення t-критерія Стьюдента для коефіцієнтів рівняння регресії наведено у результативній таблиці (рис. 7.7). Табличне значення t-критерія Стьюдента за рівня значимості α=0,05та 10 степенях волі становить 2,228. Для коефіцієнта регресії a, отже коефіцієнт aне значущий. Для коефіцієнта регресії b, отже, коефіцієнт bзначущий.
Оцінка значущості параметрів рівняння регресії
Оцінка значущості параметрів рівняння лінійної регресії провадиться за допомогою критерію Стьюдента:
якщо tрозрах. > tкр, то приймається основна гіпотеза ( H o), що свідчить про статистичну значущість параметрів регресії;
якщо tрозрах.< tкр, то приймається альтернативна гіпотеза ( H 1), що свідчить про статистичну незначущість параметрів регресії.
де m a , m b– стандартні помилки параметрів aі b:
 (2.19)
(2.19)
 (2.20)
(2.20)
Критичне (табличне) значення критерію знаходиться за допомогою статистичних таблиць розподілу Стьюдента (додаток Б) або за таблицями Excel(Розділ майстра функцій «Статистичні»):
tкр = СТЬЮДРАСПОБР( α=1-P; k=n-2), (2.21)
де k=n-2також являє собою число ступенів свободи .
Оцінка статистичної значимості може бути застосована і до лінійного коефіцієнта кореляції
де m r– стандартна помилка визначення значень коефіцієнта кореляції r yx
 (2.23)
(2.23)
Нижче представлені варіанти завдань для практичних та лабораторних робітза тематикою другого розділу.
Запитання для самоперевірки по 2 розділу
1. Вкажіть основні складові економетричної моделі та їхню сутність.
2. Основний зміст етапів економетричного дослідження.
3. Сутність підходів щодо визначення параметрів лінійної регресії.
4. Сутність та особливість застосування методу найменших квадратів при визначенні параметрів рівняння регресії.
5. Які показники використовуються для оцінки тісноти взаємозв'язку досліджуваних факторів?
6. Сутність лінійного коефіцієнта кореляції.
7. Сутність коефіцієнта детермінації.
8. Сутність та основні особливості процедур оцінки адекватності (статистичної значущості) регресійних моделей.
9. Оцінка адекватності лінійних регресійних моделей за коефіцієнтом апроксимації.
10. Сутність підходу оцінки адекватності регресійних моделей за критерієм Фішера. Визначення емпіричних та критичних значень критерію.
11. Сутність поняття «дисперсійний аналіз» стосовно економетричним дослідженням.
12. Сутність та основні особливості процедури оцінки значущості параметрів лінійного рівняння регресії.
13. Особливості застосування розподілу Стьюдента в оцінці значущості параметрів лінійного рівняння регресії.
14. У чому завдання прогнозу поодиноких значень досліджуваного соціально-економічного явища?
1. Побудувати поле кореляції та сформулювати припущення про форму рівняння взаємозв'язку досліджуваних факторів;
2. Записати основні рівняння методу найменших квадратів, зробити необхідні перетворення, скласти таблицю для проміжних розрахунків та визначити параметри лінійного рівняння регресії;
3. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
4. Провести аналіз результатів, сформулювати висновки та рекомендації.
1. Розрахунок значення лінійного коефіцієнта кореляції;
2. Побудова таблиці дисперсійного аналізу;
3. Оцінка коефіцієнта детермінації;
4. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
5. Провести аналіз результатів, сформулювати висновки та рекомендації.
4. Провести загальну оцінкуадекватності обраного рівняння регресії;
1. Оцінка адекватності рівняння за значеннями коефіцієнта апроксимації;
2. Оцінка адекватності рівняння за значеннями коефіцієнта детермінації;
3. Оцінка адекватності рівняння за критерієм Фішера;
4. Провести загальну оцінку адекватності параметрів рівняння регресії;
5. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
6. Провести аналіз результатів, сформулювати висновки та рекомендації.
1. Використання стандартних процедур майстра функцій електронних таблиць Excel (з розділів «Математичні» та «Статистичні»);
2. Підготовка даних та особливості застосування функції «ЛІНЕЙН»;
3. Підготовка даних та особливості застосування функції «ПЕРЕДСКАЗ».
1. Використання стандартних процедур пакету аналізу даних електронних таблиць Excel;
2. Підготовка даних та особливості застосування процедури «РЕГРЕСІЯ»;
3. Інтерпретація та узагальнення даних таблиці регресійного аналізу;
4. Інтерпретація та узагальнення даних таблиці дисперсійного аналізу;
5. Інтерпретація та узагальнення даних таблиці оцінки значущості параметрів рівняння регресії;
При виконанні лабораторної роботи за даними одного з варіантів необхідно виконати такі окремі завдання:
1. Здійснити вибір форми рівняння взаємозв'язку досліджуваних чинників;
2. Визначити параметри рівняння регресії;
3. Провести оцінку тісноти взаємозв'язку досліджуваних чинників;
4. Провести оцінку адекватності обраного рівняння регресії;
5. Здійснити оцінку статистичної значущості параметрів рівняння регресії.
6. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
7. Провести аналіз результатів, сформулювати висновки та рекомендації.
Завдання для практичних та лабораторних робіт на тему «Парна лінійна регресіята кореляція в економетричних дослідженнях».
| Варіант 1 | Варіант 2 | Варіант 3 | Варіант 4 | Варіант 5 | |||||
| x | y | x | y | x | y | x | y | x | y |
| Варіант 6 | Варіант 7 | Варіант 8 | Варіант 9 | Варіант 10 | |||||
| x | y | x | y | x | y | x | y | x | y |
Для оцінки суттєвості, важливості коефіцієнта кореляції використовується t-критерій Стьюдента.
Знаходиться середня помилка коефіцієнта кореляції за такою формулою:
Н  а основі помилки розраховується t-критерій:
а основі помилки розраховується t-критерій:
Розраховане значення t-критерію порівнюють з табличним, знайденим у таблиці розподілу Стьюдента при рівні значущості 0,05 або 0,01 та числі ступенів свободи n-1. Якщо розрахункове значення t-критерію більше табличного, то коефіцієнт кореляції визнається значним.
При криволінійному зв'язку з метою оцінки значущості кореляційного відношення та рівняння регресії застосовується F-критерій. Він обчислюється за такою формулою:

або 
де - кореляційне відношення; n – кількість спостережень; m – кількість параметрів у рівнянні регресії.
Розраховане значення F порівнюється з табличним для прийнятого рівня значущості (0,05 або 0,01) і чисел ступенів свободи до 1 =m-1 і k 2 =n-m. Якщо розрахункове значення F перевищує табличне, зв'язок визнається суттєвим.
Значимість коефіцієнта регресії встановлюється за допомогою t-критерію Стьюдента, який обчислюється за такою формулою:

де ? 2 а i - Дисперсія коефіцієнта регресії.
Вона обчислюється за такою формулою:

де до - Число факторних ознак в рівнянні регресії.
Коефіцієнт регресії визнається значущим, якщо t a 1 t кр. t кр перебуває у таблиці критичних точок розподілу Стьюдента при прийнятому рівні значимості та числі ступенів свободи k=n-1.
4.3.Кореляційно-регресійний аналіз в Excel
Проведемо кореляційно-регресійний аналіз взаємозв'язку врожайності та витрат праці на 1 ц зерна. Для цього відкриваємо лист Excel, в комірки А1: А30 вводимо значення факторної ознаки – врожайності зернових культур, у комірки В1: В30 значення результативної ознаки - витрат праці на 1 ц зерна. У меню Сервіс оберемо опцію Аналіз даних. Натиснувши лівою кнопкою миші по цьому пункту, відкриємо інструмент Регресія. Клацаємо по кнопці OK, на екрані з'являється діалогове вікно Регресія. У полі Вхідний інтервал У вводимо значення результативної ознаки (виділяючи комірки В1: В30), у полі Вхідний інтервал Х вводимо значення факторної ознаки (виділяючи комірки А1: А30). Зазначаємо рівень ймовірності 95%, вибираємо Новий робочий лист. Клацаємо по кнопці OK. На робочому аркуші з'являється таблиця «ВИСНОВОК ПІДСУМКІВ», в якій дано результати обчислення параметрів рівняння регресії, коефіцієнта кореляції та інші показники, що дозволяють визначити значущість коефіцієнта кореляції та параметрів рівняння регресії.
|
ВИСНОВОК ПІДСУМКІВ | ||||||||
|
Регресійна статистика | ||||||||
|
Множинний R | ||||||||
|
R-квадрат | ||||||||
|
Нормований R-квадрат | ||||||||
|
Стандартна помилка | ||||||||
|
Спостереження | ||||||||
|
Дисперсійний аналіз | ||||||||
|
Значення F | ||||||||
|
Регресія | ||||||||
|
Коефіцієнти |
Стандартна помилка |
t-статистика |
P-Значення |
Нижні 95% |
Верхні 95% |
Нижні 95,0% |
Верхні 95,0% |
|
|
Y-перетин | ||||||||
|
Змінна X 1 | ||||||||
У цій таблиці «Множинний R» - це коефіцієнт кореляції, «R-квадрат» - коефіцієнт детермінації. "Коефіцієнти: Y-перетин" - вільний член рівняння регресії 2,836242; "Змінна Х1" - коефіцієнт регресії -0,06654. Тут є значення F-критерію Фішера 74,9876, t-критерію Стьюдента 14,18042, «Стандартна помилка 0,112121», які необхідні для оцінки значущості коефіцієнта кореляції, параметрів рівняння регресії і всього рівняння.
За підсумками даних таблиці побудуємо рівняння регресії: у x =2,836-0,067х. Коефіцієнт регресії а 1 =-0,067 означає, що з підвищенням урожайності зернових на 1 ц/га витрати на 1 ц зерна зменшуються на 0,067 чол.-ч.
Коефіцієнт кореляції r=0,85>0,7, отже, зв'язок між ознаками, що вивчаються, в даній сукупності тісний. p align="justify"> Коефіцієнт детермінації r 2 = 0,73 показує, що 73% варіації результативної ознаки (витрат праці на 1 ц зерна) викликано дією факторної ознаки (урожайності зернових).
В таблиці критичних точокрозподілу Фішера - Снедекора знайдемо критичне значення F-критерію при рівні значимості 0,05 і числі ступенів свободи до 1 = m-1 = 2-1 = 1 і k 2 = n-m = 30-2 = 28, воно дорівнює 4,21. Оскільки розраховане значення критерію більше табличного (F=74.9896>4,21), рівняння регресії визнається значним.
Для оцінки значущості коефіцієнта кореляції розрахуємо t-критерій Стьюдента:
У  таблиці критичних точок розподілу Стьюдента знайдемо критичне значення t-критерію при рівні значущості 0,05 та числі ступенів свободи n-1 = 30-1 = 29, воно дорівнює 2,0452. Оскільки розрахункове значення більше табличного, то коефіцієнт кореляції є значним.
таблиці критичних точок розподілу Стьюдента знайдемо критичне значення t-критерію при рівні значущості 0,05 та числі ступенів свободи n-1 = 30-1 = 29, воно дорівнює 2,0452. Оскільки розрахункове значення більше табличного, то коефіцієнт кореляції є значним.
