قانون توزیع دوجمله ای توزیع دو جمله ای
برخلاف معمولی و توزیع های یکنواختبرای توصیف رفتار یک متغیر در نمونه آزمودنی های مورد مطالعه، از توزیع دو جمله ای برای اهداف دیگر استفاده می شود. این برای پیش بینی احتمال دو رویداد متقابل منحصر به فرد در تعداد معینی از آزمایشات مستقل عمل می کند. یک مثال کلاسیک از توزیع دو جمله ای پرتاب سکه ای است که روی یک سطح سخت می افتد. دو نتیجه (رویداد) به یک اندازه محتمل هستند: 1) سقوط سکه "عقاب" (احتمال برابر است با آر) یا 2) سکه سقوط می کند "دم" (احتمال برابر است با q). اگر هیچ نتیجه سومی داده نشد، پس پ = q= 0.5 و پ + q= 1. با استفاده از فرمول توزیع دوجمله ای، می توانید تعیین کنید که مثلاً احتمال اینکه در 50 آزمایش (تعداد پرتاب سکه) آخرین سکه مثلاً 25 بار سرش بیفتد چقدر است.
برای استدلال بیشتر، نماد عمومی پذیرفته شده را معرفی می کنیم:
n – تعداد کلمشاهدات؛
من- تعداد رویدادها (نتایج) مورد علاقه ما؛
n – من- تعداد رویدادهای جایگزین؛
پ- احتمال وقوع یک رویداد مورد علاقه به طور تجربی تعیین شده (گاهی اوقات - فرضی)؛
qاحتمال یک رویداد جایگزین است.
پ n ( من) احتمال پیش بینی شده رویداد مورد علاقه ما است منبرای تعداد معینی از مشاهدات n.
فرمول توزیع دو جمله ای:
در صورت نتیجه غیرعادی رویدادها ( p = q) می توانید از فرمول ساده شده استفاده کنید:
![]() (6.8)
(6.8)
بیایید سه مثال را در نظر بگیریم که استفاده از فرمول های توزیع دو جمله ای را در تحقیقات روانشناختی نشان می دهد.
مثال 1
فرض کنید که 3 دانش آموز در حال حل مشکل افزایش پیچیدگی هستند. برای هر یک از آنها، 2 نتیجه به یک اندازه محتمل است: (+) - حل و (-) - عدم حل مسئله. در مجموع، 8 نتیجه مختلف ممکن است (2 3 = 8).
احتمال اینکه هیچ دانش آموزی با این کار کنار بیاید 1/8 است (گزینه 8). 1 دانش آموز این کار را انجام می دهد: پ= 3/8 (گزینه های 4، 6، 7)؛ 2 دانش آموز - پ= 3/8 (گزینه های 2، 3، 5) و 3 دانش آموزان - پ= 1/8 (گزینه 1).
لازم است احتمال اینکه از هر 5 دانش آموز سه نفر از عهده این کار با موفقیت برآیند، مشخص شود.
راه حل
مجموع نتایج ممکن: 2 5 = 32.
تعداد کل گزینه های 3(+) و 2(-) می باشد

بنابراین، احتمال نتیجه مورد انتظار 10/32 » 0.31 است.
مثال 3
ورزش
احتمال پیدا شدن 5 فرد برونگرا در یک گروه 10 نفره تصادفی را تعیین کنید.
راه حل
1. نماد را وارد کنید: p=q= 0,5; n= 10; i = 5; P 10 (5) = ?
2. ما از یک فرمول ساده شده استفاده می کنیم (به بالا مراجعه کنید):
نتیجه
احتمال یافتن 5 برونگرا از بین 10 آزمودنی تصادفی 0.246 است.
یادداشت
1. محاسبه با فرمول به اندازه کافی اعداد بزرگتست ها بسیار پر زحمت هستند، بنابراین در این موارد توصیه می شود از جداول توزیع دو جمله ای استفاده کنید.
2. در برخی موارد، مقادیر پو qمی توان در ابتدا تنظیم کرد، اما نه همیشه. به عنوان یک قاعده، آنها بر اساس نتایج آزمایشات اولیه (مطالعات آزمایشی) محاسبه می شوند.
3. در تصویر گرافیکی(در مختصات P n(من) = f(من)) توزیع دو جمله ای می تواند داشته باشد نوع متفاوت: چه زمانی p = qتوزیع متقارن و شبیه توزیع نرمال گاوسی است. چولگی توزیع بیشتر از تفاوت بیشتربین احتمالات پو q.
توزیع پواسون
توزیع پواسون یک مورد خاص از توزیع دوجمله ای است که زمانی استفاده می شود که احتمال رویدادهای مورد علاقه بسیار کم باشد. به عبارت دیگر، این توزیع احتمال رخدادهای نادر را توصیف می کند. می توان از فرمول پواسون برای پ < 0,01 и q ≥ 0,99.
معادله پواسون تقریبی است و با فرمول زیر توصیف می شود:
![]() (6.9)
(6.9)
جایی که μ محصول است احتمال متوسطرویدادها و تعداد مشاهدات
به عنوان مثال الگوریتم حل مسئله زیر را در نظر بگیرید.
وظیفه
برای چندین سال، 21 کلینیک بزرگ در روسیه معاینه انبوهی از نوزادان برای بیماری داون در نوزادان انجام دادند (متوسط نمونه 1000 نوزاد در هر کلینیک بود). داده های زیر دریافت شد:
ورزش
1. میانگین احتمال بیماری (از نظر تعداد نوزادان) را تعیین کنید.
2. میانگین تعداد نوزادان مبتلا به یک بیماری را تعیین کنید.
3. احتمال اینکه از بین 100 نوزاد به طور تصادفی انتخاب شده، 2 نوزاد مبتلا به بیماری داون را تعیین کنید.
راه حل
1. میانگین احتمال بیماری را تعیین کنید. در انجام این کار، ما باید با استدلال زیر هدایت شویم. بیماری داون از 21 درمانگاه تنها در 10 درمانگاه ثبت شده است. در 11 درمانگاه هیچ بیماری، 1 مورد در 6 درمانگاه، 2 مورد در 2 درمانگاه، 3 مورد در کلینیک یکم و 4 مورد در کلینیک یکم ثبت شده است. 5 مورد در هیچ کلینیک یافت نشد. برای تعیین میانگین احتمال بیماری، لازم است تعداد کل موارد (6 1 + 2 2 + 1 3 + 1 4 = 17) بر تعداد کل نوزادان (21000) تقسیم شود:
![]()
2. تعداد نوزادانی که عامل یک بیماری هستند، متقابل احتمال متوسط است، یعنی برابر با تعداد کل نوزادان تقسیم بر تعداد موارد ثبت شده:
![]()
3. مقادیر را جایگزین کنید پ = 0,00081, n= 100 و من= 2 در فرمول پواسون:
پاسخ
احتمال اینکه از بین 100 نوزاد انتخاب شده به طور تصادفی 2 نوزاد مبتلا به بیماری داون پیدا شود 003/0 (3/0 درصد) است.
وظایف مرتبط
وظیفه 6.1
ورزش
با استفاده از داده های مسئله 5.1 در مورد زمان واکنش حسی حرکتی، عدم تقارن و کشیدگی توزیع VR را محاسبه کنید.
وظیفه 6. 2
200 دانشجوی کارشناسی ارشد از نظر سطح هوش ( IQ). پس از نرمال کردن توزیع حاصل IQبا توجه به انحراف معیار، نتایج زیر به دست آمد:
ورزش
با استفاده از آزمون های کولموگروف و کای دو، تعیین کنید که آیا توزیع حاصل از شاخص ها مطابقت دارد یا خیر. IQطبیعی.
وظیفه 6. 3
در یک فرد بالغ (یک مرد 25 ساله)، زمان یک واکنش حسی حرکتی ساده (SR) در پاسخ به یک محرک صوتی با فرکانس ثابت 1 کیلوهرتز و شدت 40 دسی بل مورد مطالعه قرار گرفت. محرک صد بار در فواصل 3-5 ثانیه ارائه شد. مقادیر فردی VR برای 100 تکرار به صورت زیر توزیع شد:
ورزش
1. یک هیستوگرام فرکانس از توزیع VR بسازید. مقدار متوسط VR و مقدار انحراف استاندارد را تعیین کنید.
2. ضریب عدم تقارن و کشش توزیع VR را محاسبه کنید. بر اساس مقادیر دریافتی مانندو سابقدر مورد مطابقت یا عدم انطباق این توزیع با توزیع عادی نتیجه گیری کنید.
وظیفه 6.4
در سال 1998، 14 نفر (5 پسر و 9 دختر) با مدال طلا از مدارس نیژنی تاگیل، 26 نفر (8 پسر و 18 دختر) با مدال نقره فارغ التحصیل شدند.
سوال
آیا می توان گفت دختران بیشتر از پسران مدال می گیرند؟
توجه داشته باشید
نسبت تعداد پسر و دختر در جمعیتبرابر در نظر بگیرید
وظیفه 6.5
اعتقاد بر این است که تعداد افراد برونگرا و درونگرا در یک گروه همگن از افراد تقریباً یکسان است.
ورزش
این احتمال را تعیین کنید که در یک گروه 10 نفره که به طور تصادفی انتخاب شده اند، 0، 1، 2، ...، 10 نفر برونگرا پیدا شوند. یک عبارت گرافیکی برای توزیع احتمال یافتن 0، 1، 2، ...، 10 برونگرا در یک گروه معین بسازید.
وظیفه 6.6
ورزش
محاسبه احتمال P n(i) توابع توزیع دو جمله ای برای پ= 0.3 و q= 0.7 برای مقادیر n= 5 و من= 0، 1، 2، ...، 5. یک عبارت گرافیکی از وابستگی بسازید P n(من) = f(من) .
وظیفه 6.7
AT سال های گذشتهدر میان بخش خاصی از جمعیت، ایمان به پیش بینی های نجومی ایجاد شد. با توجه به نتایج بررسی های اولیه، مشخص شد که حدود 15 درصد از مردم به طالع بینی اعتقاد دارند.
ورزش
این احتمال را تعیین کنید که از بین 10 پاسخ دهنده به طور تصادفی انتخاب شده، 1، 2 یا 3 نفر وجود داشته باشند که به پیش بینی های نجومی اعتقاد دارند.
وظیفه 6.8
وظیفه
در 42 مدارس آموزش عمومیمنطقه یکاترینبورگ و سوردلوفسک (تعداد کل دانش آموزان 12260 نفر) برای چندین سال شماره بعدیموارد بیماری روانی در بین دانش آموزان:
ورزش
اجازه دهید 1000 دانش آموز به طور تصادفی معاینه شوند. حساب کنید احتمال شناسایی 1، 2 یا 3 کودک روانی در بین این هزار دانش آموز چقدر است؟
بخش 7. معیارهای تفاوت
فرمول بندی مسئله
فرض کنید دو نمونه مستقل از موضوعات داریم ایکسو در. مستقلنمونه ها زمانی شمارش می شوند که همان موضوع (موضوع) تنها در یک نمونه ظاهر شود. کار این است که این نمونه ها (دو مجموعه متغیر) را با یکدیگر برای تفاوت آنها مقایسه کنیم. طبیعتاً مهم نیست که مقادیر متغیرهای نمونه اول و دوم چقدر به هم نزدیک باشند، برخی تفاوتها، حتی اگر ناچیز باشند، بین آنها تشخیص داده میشود. از همین منظر آمار ریاضیما به این سوال علاقه مندیم که آیا تفاوت بین این نمونه ها از نظر آماری معنی دار است (از لحاظ آماری معنی دار) یا معنی دار نیست (تصادفی).
رایجترین معیار برای اهمیت تفاوتها بین نمونهها، معیارهای پارامتری تفاوتها هستند. معیار دانش آموزو معیار فیشر. در برخی موارد از معیارهای ناپارامتریک استفاده می شود - تست کیو روزنباوم، آزمون U مانا ویتنی و دیگران. تبدیل زاویه ای فیشر φ*، که به شما امکان می دهد مقادیر بیان شده به صورت درصد (درصد) را با یکدیگر مقایسه کنید. و در نهایت، به عنوان یک مورد خاص، برای مقایسه نمونه ها، می توان از معیارهایی استفاده کرد که شکل توزیع نمونه را مشخص می کند - معیار χ 2 پیرسونو معیار λ Kolmogorov – Smirnov.
برای درک بهتر این موضوع به صورت زیر عمل می کنیم. ما همان مشکل را با چهار روش با استفاده از چهار معیار مختلف حل خواهیم کرد - Rosenbaum، Mann-Whitney، Student و Fisher.
وظیفه
30 دانش آموز (14 پسر و 16 دختر) در جلسه امتحان بر اساس آزمون اسپیلبرگر از نظر سطح اضطراب واکنشی مورد آزمون قرار گرفتند. نتایج زیر به دست آمد (جدول 7.1):
جدول 7.1
| فاعل، موضوع | سطح اضطراب واکنشی | |||||||||||||||
| جوانان | ||||||||||||||||
| دختران |
ورزش
برای تعیین اینکه آیا تفاوت در سطح اضطراب واکنشی در پسران و دختران از نظر آماری معنادار است یا خیر.
این کار برای یک روانشناس متخصص در این زمینه کاملاً معمولی به نظر می رسد روانشناسی آموزشی: چه کسی استرس معاینه را شدیدتر تجربه می کند - پسران یا دختران؟ اگر تفاوت بین نمونه ها از نظر آماری معنی دار باشد، در این صورت تفاوت های جنسیتی قابل توجهی وجود دارد. اگر تفاوت ها تصادفی باشند (از نظر آماری معنی دار نیستند)، این فرض باید کنار گذاشته شود.
7. 2. آزمون ناپارامتریک سروزنباوم
س-معیار روزنبام مبتنی بر مقایسه مقادیر «فوقالعادهشده» بر روی یکدیگر سریهای رتبهبندی شده دو متغیر مستقل است. در عین حال، ماهیت توزیع صفت در هر ردیف تجزیه و تحلیل نمی شود - در این مورد، فقط عرض بخش های غیر همپوشانی دو ردیف رتبه بندی شده مهم است. هنگام مقایسه دو سری از متغیرهای رتبه بندی شده با یکدیگر، 3 گزینه ممکن است:
1. رتبه های رتبه بندی شده ایکسو yمنطقه همپوشانی ندارند، یعنی تمام مقادیر سری اول رتبه بندی شده ( ایکس) بزرگتر از تمام مقادیر سری دوم است( y):
در این مورد، تفاوت بین نمونه ها، که با هر معیار آماری تعیین می شود، قطعاً قابل توجه است و استفاده از معیار روزنبام مورد نیاز نیست. با این حال، در عمل این گزینه بسیار نادر است.
2. ردیف های رتبه بندی شده کاملاً با یکدیگر همپوشانی دارند (به عنوان یک قاعده، یکی از ردیف ها در داخل دیگری قرار دارد)، هیچ منطقه غیر همپوشانی وجود ندارد. در این مورد، معیار Rosenbaum قابل اجرا نیست.

3. یک ناحیه همپوشانی از ردیف ها و همچنین دو ناحیه غیر همپوشانی وجود دارد ( N 1و N 2) مربوط به ناهمسانسری های رتبه بندی شده (ما نشان می دهیم ایکس- یک ردیف به سمت بزرگ تغییر مکان داد، y- در جهت مقادیر کمتر):

این مورد برای استفاده از معیار Rosenbaum معمول است که هنگام استفاده از آن باید شرایط زیر رعایت شود:
1. حجم هر نمونه باید حداقل 11 باشد.
2. اندازه نمونه نباید تفاوت قابل توجهی با یکدیگر داشته باشد.
معیار س Rosenbaum با تعداد مقادیر غیر همپوشانی مطابقت دارد: س = ن 1 +ن 2 . نتیجه گیری در مورد پایایی تفاوت بین نمونه ها انجام می شود اگر س > س kr . در عین حال، ارزش ها س cr در جداول ویژه قرار دارند (به پیوست، جدول هشتم مراجعه کنید).
به وظیفه خود برگردیم. اجازه دهید نماد را معرفی کنیم: ایکس- منتخبی از دختران، y- منتخبی از پسران. برای هر نمونه، یک سری رتبه بندی می سازیم:
ایکس: 28 30 34 34 35 36 37 39 40 41 42 42 43 44 45 46
y: 26 28 32 32 33 34 35 38 39 40 41 42 43 44
ما تعداد مقادیر را در مناطق غیر همپوشانی سری رتبهبندی میشماریم. در یک ردیف ایکسمقادیر 45 و 46 با هم تداخل ندارند، یعنی. ن 1 = 2؛ در یک ردیف yفقط 1 مقدار غیر همپوشانی 26 یعنی. ن 2 = 1. بنابراین، س = ن 1 +ن 2 = 1 + 2 = 3.
روی میز. ضمیمه هشتم در می یابیم که س kr . = 7 (برای سطح معنی داری 0.95) و س cr = 9 (برای سطح معنی داری 0.99).
نتیجه
از آنجا که س<س cr، پس با توجه به معیار روزنبام، تفاوت بین نمونه ها از نظر آماری معنی دار نیست.
توجه داشته باشید
آزمون روزنبام بدون توجه به ماهیت توزیع متغیرها قابل استفاده است، یعنی در این مورد نیازی به استفاده از آزمون χ2 پیرسون و λ کلموگروف برای تعیین نوع توزیع در هر دو نمونه نیست.
7. 3. U-آزمون من ویتنی
برخلاف معیار روزنبام، Uآزمون من ویتنی بر اساس تعیین منطقه همپوشانی بین دو ردیف رتبه بندی شده است، یعنی هر چه منطقه همپوشانی کوچکتر باشد، تفاوت بین نمونه ها بیشتر است. برای این کار از روش خاصی برای تبدیل مقیاس های فاصله ای به مقیاس های رتبه ای استفاده می شود.
اجازه دهید الگوریتم محاسبه را در نظر بگیریم U-معیار در مثال کار قبلی.
جدول 7.2
| x، y | آر xy | آر xy * | آرایکس | آر y |
| 26 28 32 32 33 34 35 38 39 40 41 42 43 44 | 2,5 2,5 5,5 5,5 11,5 11,5 16,5 16,5 18,5 18,5 20,5 20,5 25,5 25,5 27,5 27,5 | 2,5 11,5 16,5 18,5 20,5 25,5 27,5 | 1 2,5 5,5 5,5 7 9 11,5 15 16,5 18,5 20,5 23 25,5 27,5 | |
| Σ | 276,5 | 188,5 |
1. ما یک سری رتبه بندی شده را از دو نمونه مستقل می سازیم. در این مورد، مقادیر برای هر دو نمونه مخلوط می شوند، ستون 1 ( ایکس, y). به منظور ساده سازی کار بیشتر (از جمله در نسخه رایانه ای)، مقادیر نمونه های مختلف باید با فونت های مختلف (یا رنگ های مختلف) علامت گذاری شوند، با در نظر گرفتن این واقعیت که در آینده آنها را در ستون های مختلف توزیع خواهیم کرد.
2. مقیاس فاصله مقادیر را به ترتیبی تبدیل کنید (برای این کار، همه مقادیر را با اعداد رتبه از 1 تا 30، ستون 2 دوباره طراحی می کنیم ( آر xy)).
3. اصلاحاتی را برای رتبه های مرتبط معرفی می کنیم (مقادیر یکسان متغیر با همان رتبه مشخص می شود، مشروط بر اینکه مجموع رتبه ها تغییر نکند، ستون 3 ( آر xy *). در این مرحله توصیه می شود مجموع رتبه های ستون های 2 و 3 را محاسبه کنید (در صورتی که تمام اصلاحات صحیح باشد، این مجموع باید برابر باشند).
4. اعداد رتبه ها را مطابق با تعلق آنها به یک نمونه خاص پخش می کنیم (ستون های 4 و 5 ( آر x و آر y)).
5. ما محاسبات را طبق فرمول انجام می دهیم:
![]() (7.1)
(7.1)
جایی که تی x بزرگترین مجموع رتبه است ; n x و n y، به ترتیب، اندازه نمونه. در این مورد به خاطر داشته باشید که اگر تیایکس< تی y، سپس نماد ایکسو yباید معکوس شود.
6. مقدار به دست آمده را با مقدار جدولی مقایسه کنید (به پیوست ها، جدول IX مراجعه کنید) نتیجه گیری در مورد پایایی تفاوت های بین دو نمونه در صورتی انجام می شود که Uانقضا< U cr. .
در مثال ما ![]() Uانقضا = 83.5 > U cr. = 71.
Uانقضا = 83.5 > U cr. = 71.
نتیجه
تفاوت بین دو نمونه بر اساس آزمون من ویتنی از نظر آماری معنی دار نیست.
یادداشت
1. آزمون من ویتنی عملا هیچ محدودیتی ندارد. حداقل اندازه نمونه های مقایسه شده 2 و 5 نفر است (جدول IX پیوست را ببینید).
2. مشابه آزمایش روزنبام، آزمون من ویتنی را می توان برای هر نمونه ای، صرف نظر از ماهیت توزیع، استفاده کرد.
معیار دانش آموز
بر خلاف معیارهای روزنبام و من ویتنی، معیار تیروش دانش آموز پارامتریک است، یعنی بر اساس تعیین شاخص های آماری اصلی - مقادیر میانگین در هر نمونه (و) و واریانس آنها (s 2 x و s 2 y) که با استفاده از فرمول های استاندارد محاسبه می شود (به بخش 5 مراجعه کنید).
استفاده از معیار دانشجو مستلزم شرایط زیر است:
1. توزیع مقادیر برای هر دو نمونه باید مطابق با قانون باشد توزیع نرمال(به بخش 6 مراجعه کنید).
2. حجم کل نمونه ها باید حداقل 30 (برای β 1 = 0.95) و حداقل 100 (برای β 2 = 0.99) باشد.
3. حجم دو نمونه نباید تفاوت قابل توجهی با یکدیگر داشته باشد (بیش از 1.5 ÷ 2 برابر).
ایده معیار دانشجویی بسیار ساده است. فرض کنید که مقادیر متغیرها در هر یک از نمونه ها بر اساس توزیع شده است قانون عادی، یعنی با دو توزیع نرمال روبرو هستیم که از نظر مقادیر میانگین و واریانس با یکدیگر متفاوت هستند (به ترتیب و، و، به شکل 7.1 مراجعه کنید).

س ایکسس y
برنج. 7.1. برآورد تفاوت بین دو نمونه مستقل: و - مقادیر میانگین نمونه ها ایکسو y; s x و s y - انحرافات استاندارد
به راحتی می توان درک کرد که تفاوت بین دو نمونه بیشتر، تفاوت بین میانگین ها بیشتر و واریانس (یا انحراف معیار) آنها کوچکتر خواهد بود.
در مورد نمونه های مستقل، ضریب دانشجو با فرمول تعیین می شود:
 (7.2)
(7.2)
جایی که n x و n y - به ترتیب تعداد نمونه ها ایکسو y.
پس از محاسبه ضریب Student در جدول مقادیر استاندارد (بحرانی). تی(به پیوست، جدول X مراجعه کنید) مقدار مربوط به تعداد درجات آزادی را بیابید n = n x + n y - 2 و آن را با فرمول محاسبه شده مقایسه کنید. اگر یک تیانقضا £ تی cr. ، در این صورت فرضیه پایایی تفاوت بین نمونه ها رد می شود تیانقضا > تی cr. ، سپس پذیرفته می شود. به عبارت دیگر، اگر ضریب دانشجویی که با فرمول محاسبه میشود، از مقدار جدولی برای سطح معنیداری متناظر بیشتر باشد، نمونهها با یکدیگر تفاوت معناداری دارند.
در مسئله ای که قبلا در نظر گرفتیم، محاسبه میانگین مقادیر و واریانس ها به دست می آید مقادیر زیر: ایکسرجوع کنید به = 38.5; σ x 2 = 28.40; دررجوع کنید به = 36.2; σ y 2 = 31.72.
مشاهده می شود که میانگین ارزش اضطراب در گروه دختران بیشتر از گروه پسران است. با این حال، این تفاوت ها به قدری کوچک هستند که بعید به نظر می رسد از نظر آماری معنی دار باشند. برعکس، پراکندگی مقادیر در پسران کمی بیشتر از دختران است، اما تفاوت بین واریانس ها نیز کم است.

نتیجه
تیانقضا = 1.14< تی cr. = 2.05 (β 1 = 0.95). تفاوت بین دو نمونه مقایسه شده از نظر آماری معنی دار نیست. این نتیجه گیری کاملاً با نتیجه به دست آمده با استفاده از معیارهای روزنبام و من ویتنی مطابقت دارد.
روش دیگر برای تعیین تفاوت بین دو نمونه با استفاده از آزمون تی دانشجویی محاسبه فاصله اطمینان انحرافات استاندارد است. فاصله اطمینان، میانگین انحراف مربع (استاندارد) تقسیم بر جذر حجم نمونه و ضرب در مقدار استاندارد ضریب دانشجو برای n– 1 درجه آزادی (به ترتیب و ).
توجه داشته باشید
ارزش = m xریشه میانگین مربعات خطا نامیده می شود (به بخش 5 مراجعه کنید). بنابراین، فاصله اطمینان خطای استاندارد ضرب در ضریب دانشجو برای یک حجم نمونه معین است، که در آن تعداد درجات آزادی ν = n- 1، و برای سطح داده شدهاهمیت
دو نمونه که مستقل از یکدیگر هستند به طور قابل توجهی متفاوت در نظر گرفته می شوند اگر فاصله اطمینانزیرا این نمونه ها با یکدیگر همپوشانی ندارند. در مورد ما، برای نمونه اول 2.84 ± 38.5 و برای نمونه دوم 36.2 ± 3.38 داریم.
بنابراین، تغییرات تصادفی x iدر محدوده 35.66 ¸ 41.34 قرار دارد و تغییرات y من- در محدوده 32.82 ¸ 39.58. بر این اساس می توان بیان کرد که تفاوت بین نمونه ها ایکسو yاز نظر آماری غیر قابل اعتماد (محدوده تغییرات با یکدیگر همپوشانی دارند). در این مورد، باید در نظر داشت که عرض منطقه همپوشانی در این مورد مهم نیست (تنها واقعیت همپوشانی فواصل اطمینان مهم است).
روش دانشآموز برای نمونههای وابسته (مثلاً برای مقایسه نتایج بهدستآمده از آزمایشهای مکرر روی نمونههای مشابه) به ندرت استفاده میشود، زیرا روشهای آموزندهتر دیگری برای این اهداف وجود دارد. ترفندهای آماری(به بخش 10 مراجعه کنید). اما برای این منظور به عنوان تقریب اول می توانید از فرمول Student به شکل زیر استفاده کنید:
 (7.3)
(7.3)
نتیجه به دست آمده با مقدار جدول برای مقایسه می شود n– 1 درجه آزادی، که در آن n- تعداد جفت مقادیر ایکسو y. نتایج مقایسه دقیقاً به همان روشی که در مورد محاسبه تفاوت بین دو نمونه مستقل تفسیر می شود.
معیار فیشر
معیار فیشر ( اف) بر اساس همان اصل آزمون t Student است، یعنی شامل محاسبه مقادیر میانگین و واریانس در نمونه های مقایسه شده است. اغلب در مقایسه نمونه هایی که از نظر اندازه نابرابر (از نظر اندازه متفاوت) هستند با یکدیگر استفاده می شود. آزمون فیشر تا حدودی سختگیرانهتر از آزمون دانشجو است و بنابراین در مواردی که در مورد پایایی تفاوتها تردید وجود دارد (مثلاً اگر طبق آزمون دانشجو، تفاوتها در صفر معنیدار باشند و در اهمیت اول معنیدار نباشند، ارجحتر است. مرحله).
فرمول فیشر به این صورت است:
 (7.4)
(7.4)
کجا و  (7.5, 7.6)
(7.5, 7.6)
در مشکل ما d2= 5.29; σz 2 = 29.94.
مقادیر موجود در فرمول را جایگزین کنید: ![]()
روی میز. XI برنامه های کاربردی، متوجه می شویم که برای سطح معنی داری β 1 = 0.95 و ν = n x + n y - 2 = 28 مقدار بحرانی 4.20 است.
نتیجه
اف = 1,32 < F cr.= 4.20. تفاوت بین نمونه ها از نظر آماری معنی دار نیست.
توجه داشته باشید
هنگام استفاده از آزمون فیشر، همان شرایطی که برای آزمون دانشجویی وجود دارد باید رعایت شود (به بخش 7.4 مراجعه کنید). با این وجود، تفاوت در تعداد نمونه ها بیش از دو برابر مجاز است.
بنابراین، هنگام حل همان مشکل با چهار روش های مختلفبا استفاده از دو معیار ناپارامتریک و دو معیار پارامتریک، به این نتیجه صریح رسیدیم که تفاوتهای گروه دختران و پسران از نظر سطح اضطراب واکنشی قابل اعتماد نیستند (یعنی در محدوده تغییرات تصادفی قرار دارند. ). با این حال، ممکن است مواردی وجود داشته باشد که نتیجه گیری بدون ابهام ممکن نباشد: برخی از معیارها تفاوت های قابل اعتماد و برخی دیگر - تفاوت های غیرقابل اعتماد را ارائه می دهند. در این موارد اولویت با معیارهای پارامتریک (به شرط کافی بودن حجم نمونه و توزیع نرمال مقادیر مورد مطالعه) است.
7. 6. معیار j* - تبدیل زاویه ای فیشر
معیار j*Fisher برای مقایسه دو نمونه با توجه به فراوانی وقوع اثر مورد علاقه محقق طراحی شده است. اهمیت تفاوت بین درصدهای دو نمونه را که اثر علاقه در آنها ثبت شده است، ارزیابی می کند. مقایسه درصدها در همان نمونه نیز مجاز است.
ماهیت تبدیل زاویه ای فیشر، تبدیل درصدها به زوایای مرکزی است که بر حسب رادیان اندازه گیری می شوند. درصد بزرگتر با زاویه بزرگتر مطابقت دارد j، و یک سهم کوچکتر - یک زاویه کوچکتر، اما رابطه در اینجا غیر خطی است:
![]()
جایی که آر- درصد، بیان شده در کسری از واحد.
با افزایش اختلاف بین زوایای j 1 و j 2 و افزایش تعداد نمونه ها، مقدار معیار افزایش می یابد.
معیار فیشر با فرمول زیر محاسبه می شود:
| |
که در آن j 1 زاویه مربوط به درصد بزرگتر است. j 2 - زاویه مربوط به درصد کمتر. n 1 و n 2- به ترتیب حجم نمونه اول و دوم.
مقدار محاسبه شده توسط فرمول با مقدار استاندارد مقایسه می شود (j* st = 1.64 برای b 1 = 0.95 و j* st = 2.31 برای b 2 = 0.99. تفاوت بین دو نمونه از نظر آماری معنی دار در نظر گرفته می شود اگر j*> j* st برای سطح معینی از اهمیت.
مثال
ما علاقه مندیم که آیا دو گروه از دانش آموزان از نظر موفقیت در انجام یک کار نسبتاً پیچیده با یکدیگر تفاوت دارند یا خیر. در گروه اول 20 نفره، 12 دانش آموز با آن کنار آمدند، در گروه دوم - 10 نفر از 25 نفر.
راه حل
1. نماد را وارد کنید: n 1 = 20, n 2 = 25.
2. محاسبه درصد آر 1 و آر 2: آر 1 = 12 / 20 = 0,6 (60%), آر 2 = 10 / 25 = 0,4 (40%).
3. در جدول. XII برنامه های کاربردی، مقادیر φ را مربوط به درصدها می یابیم: j 1 = 1.772، j 2 = 1.369.
| |
از اینجا:
نتیجه
تفاوت بین گروه ها از نظر آماری معنی دار نیست زیرا j*< j* ст для 1-го и тем более для 2-го уровня значимости.
7.7. با استفاده از آزمون χ2 پیرسون و آزمون λ کولموگروف
توزیع احتمال متغیرهای تصادفی گسسته. توزیع دو جمله ای. توزیع پواسون توزیع هندسی تابع تولید
6. توزیع احتمال متغیرهای تصادفی گسسته
6.1. توزیع دو جمله ای
بذار تولید بشه nآزمایشات مستقل، که در هر یک از آنها یک رویداد آممکن است ظاهر شود یا نباشد. احتمال پوقوع یک رویداد آدر همه آزمون ها ثابت است و از آزمونی به آزمون دیگر تغییر نمی کند. به عنوان یک متغیر تصادفی X تعداد وقوع رویداد را در نظر بگیرید آدر این تست ها فرمولی برای یافتن احتمال وقوع یک رویداد آصاف کیک بار در nآزمایشات، همانطور که مشخص است، شرح داده شده است فرمول برنولی
توزیع احتمال تعریف شده توسط فرمول برنولی نامیده می شود دو جمله ای .
این قانون "دوجمله ای" نامیده می شود زیرا سمت راست را می توان به عنوان یک اصطلاح رایج در بسط دو جمله ای نیوتن در نظر گرفت.
قانون دوجمله ای را به صورت جدول می نویسیم
|
پ n |
np n –1 q |
|
q n |

اجازه دهید ویژگی های عددی این توزیع را پیدا کنیم.
طبق تعریف انتظارات ریاضیبرای DSW ما داریم
 .
.
اجازه دهید تساوی را بنویسیم که همان بن نیوتن است
 .
.
و آن را با توجه به p متمایز کنید. در نتیجه می گیریم
 .
.
ضرب چپ و سمت راستبر روی پ:
 .
.
با توجه به اینکه پ+ q=1، ما داریم
 (6.2)
(6.2)
بنابراین، انتظارات ریاضی از تعداد وقوع رویدادها درnآزمایشهای مستقل برابر است با حاصل ضرب تعداد آزمایشهاnبر اساس احتمالپوقوع یک رویداد در هر آزمایش.
پراکندگی را با فرمول محاسبه می کنیم
 .
.
برای این ما پیدا می کنیم
 .
.
ابتدا فرمول دوجمله ای نیوتن را دو بار با توجه به آن متمایز می کنیم پ:

و دو طرف معادله را در ضرب کنید پ 2:

در نتیجه،
بنابراین واریانس توزیع دو جمله ای است
 .
(6.3)
.
(6.3)
این نتایج را می توان از استدلال صرفاً کیفی نیز به دست آورد. مجموع X وقوع رویداد A در همه کارآزماییها به تعداد وقوع رویداد در آزمایشهای فردی اضافه میشود. بنابراین، اگر X 1 تعداد وقوع رویداد در آزمایش اول، X 2 در آزمایش دوم و غیره باشد، تعداد کل وقوع رویداد A در همه آزمایشها X=X 1 +X 2 +…+ است. ایکس n. با توجه به ویژگی انتظار ریاضی:
هر یک از اصطلاحات سمت راست برابری، انتظار ریاضی تعداد رویدادها در یک آزمون است که برابر با احتمال رخداد است. به این ترتیب،
با توجه به خاصیت پراکندگی:
از آنجا که، و انتظارات ریاضی یک متغیر تصادفی  ، که فقط می تواند دو مقدار یعنی 1 2 با احتمال را بگیرد پو 0 2 با احتمال q، سپس
، که فقط می تواند دو مقدار یعنی 1 2 با احتمال را بگیرد پو 0 2 با احتمال q، سپس  . به این ترتیب،
. به این ترتیب،  در نتیجه می گیریم
در نتیجه می گیریم
با استفاده از مفهوم گشتاورهای اولیه و مرکزی، می توان فرمول هایی برای چولگی و کشیدگی به دست آورد:
 .
(6.4)
.
(6.4)

برنج. 6.1
چند ضلعی توزیع دو جمله ای شکل زیر را دارد (شکل 6.1 را ببینید). احتمال P n (ک) ابتدا با افزایش افزایش می یابد ک، می رسد بزرگترین ارزشو سپس شروع به کاهش می کند. توزیع دوجمله ای به جز مورد کج است پ=0.5. توجه داشته باشید که برای تعداد زیادی تست nتوزیع دوجمله ای بسیار نزدیک به نرمال است. (توجیه این گزاره مربوط به قضیه محلی مویور-لاپلاس است.)عددمتر 0 وقوع یک رویداد نامیده می شودبه احتمال زیاد ، اگر احتمال وقوع رویداد در تعداد معینی بار در این سری آزمایش ها بزرگترین باشد (حداکثر در چند ضلعی توزیع). برای توزیع دوجمله ای
اظهار نظر. این نابرابری را می توان با استفاده از فرمول بازگشتی برای احتمالات دو جمله ای اثبات کرد:
 (6.6)
(6.6)
مثال 6.1.سهم محصولات ممتاز در این شرکت 31 درصد است. میانگین و واریانس، همچنین محتمل ترین تعداد اقلام ممتاز در یک دسته 75 موردی که به طور تصادفی انتخاب شده اند چیست؟
راه حل. از آنجا که پ=0,31, q=0,69, n= 75، پس
M[ ایکس] = np= 750.31 = 23.25; D[ ایکس] = npq = 750,310,69 = 16,04.
برای یافتن محتمل ترین عدد متر 0، یک نابرابری مضاعف می سازیم
از این رو نتیجه می شود که متر 0 = 23.
توزیع دو جمله ای یکی از مهم ترین توزیع های احتمال برای یک متغیر تصادفی گسسته در حال تغییر است. توزیع دو جمله ای توزیع احتمال یک عدد است متررویداد ولیکه در nمشاهدات مستقل متقابل. اغلب یک رویداد ولیبه نام "موفقیت" مشاهده، و رویداد مخالف - "شکست"، اما این نامگذاری بسیار مشروط است.
شرایط توزیع دو جمله ای:
- در مجموع انجام شد nآزمایشاتی که در آن رویداد ولیممکن است رخ دهد یا نباشد؛
- رویداد ولیدر هر یک از آزمایشات می تواند با احتمال یکسان رخ دهد پ;
- آزمون ها متقابل مستقل هستند.
احتمال اینکه در nرویداد آزمایشی ولیدقیقا متربار را می توان با استفاده از فرمول برنولی محاسبه کرد:
![]()
![]() ,
,
جایی که پ- احتمال وقوع رویداد ولی;
q = 1 - پاحتمال وقوع رویداد مخالف است.
بیایید آن را بفهمیم چرا توزیع دوجمله ای با فرمول برنولی به روشی که در بالا توضیح داده شد مرتبط است . رویداد - تعداد موفقیت ها در nآزمون ها به تعدادی گزینه تقسیم می شوند که در هر کدام از آنها موفقیت حاصل می شود مترآزمایشات، و شکست - در n - مترتست ها یکی از این گزینه ها را در نظر بگیرید - ب1 . طبق قانون جمع احتمالات، احتمالات وقایع متضاد را ضرب می کنیم:
![]() ,
,
و اگر اشاره کنیم q = 1 - پ، سپس
![]() .
.
همین احتمال هر گزینه دیگری در آن خواهد داشت مترموفقیت و n - مترشکست ها تعداد چنین گزینه هایی برابر است با تعداد راه هایی که از طریق آنها امکان پذیر است nتست گرفتن مترموفقیت
مجموع احتمالات همه مترشماره رویداد ولی(اعداد از 0 تا n) برابر با یک است:
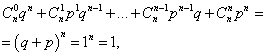
که در آن هر جمله یک جمله از دوجمله ای نیوتن است. بنابراین توزیع در نظر گرفته شده را توزیع دو جمله ای می نامند.
در عمل، اغلب لازم است که احتمالات را حداکثر "حداکثر محاسبه کنیم مترموفقیت در nتست ها» یا «حداقل مترموفقیت در nبرای این کار از فرمول های زیر استفاده می شود.
تابع انتگرال یعنی احتمال اف(متر) که در nرویداد مشاهده ولیدیگر نخواهد آمد متریک باررا می توان با استفاده از فرمول محاسبه کرد:
در نوبتش احتمال اف(≥متر) که در nرویداد مشاهده ولیبیا حداقل متریک بار، با فرمول محاسبه می شود:
گاهی اوقات محاسبه احتمال اینکه در nرویداد مشاهده ولیدیگر نخواهد آمد متربارها، از طریق احتمال رویداد مخالف:
![]() .
.
اینکه کدام یک از فرمول ها استفاده شود بستگی به این دارد که کدام یک از آنها عبارت های کمتری داشته باشد.
مشخصات توزیع دو جمله ای با استفاده از فرمول های زیر محاسبه می شود .
ارزش مورد انتظار: .
پراکندگی: .
انحراف معیار: .
توزیع دو جمله ای و محاسبات در MS Excel
احتمال توزیع دو جمله ای پ n ( متر) و مقدار تابع انتگرال اف(متر) را می توان با استفاده از تابع MS Excel BINOM.DIST محاسبه کرد. پنجره محاسبه مربوطه در زیر نشان داده شده است (برای بزرگنمایی روی دکمه سمت چپ ماوس کلیک کنید).

MS Excel از شما می خواهد که داده های زیر را وارد کنید:
- تعداد موفقیت ها؛
- تعداد تست ها؛
- احتمال موفقیت؛
- انتگرال - مقدار منطقی: 0 - اگر نیاز به محاسبه احتمال دارید پ n ( متر) و 1 - در صورت احتمال اف(متر).
مثال 1مدیر این شرکت اطلاعاتی را در مورد تعداد دوربین های فروخته شده در 100 روز گذشته خلاصه کرد. جدول اطلاعات را خلاصه می کند و احتمال فروش روز را محاسبه می کند تعداد معیندوربین ها
اگر 13 دوربین یا بیشتر فروخته شود روز با سود به پایان می رسد. احتمال اینکه روز با سود انجام شود:
![]()
احتمال اینکه روز بدون سود کار شود:

اجازه دهید احتمال اینکه روز با سود کار می شود ثابت و برابر با 0.61 باشد و تعداد دوربین های فروخته شده در روز به روز بستگی ندارد. سپس میتوانید از توزیع دوجملهای استفاده کنید، جایی که رویداد ولی- روز با سود کار می شود، - بدون سود.
احتمال اینکه از 6 روز همه با سود کار شود:
![]() .
.
ما همان نتیجه را با استفاده از تابع MS Excel BINOM.DIST بدست می آوریم (مقدار انتگرال 0 است):
پ 6 (6 ) = BINOM.DIST(6; 6; 0.61; 0) = 0.052.
احتمال اینکه از 6 روز 4 روز یا بیشتر با سود کار شود:
جایی که ![]() ,
,
![]() ,
,
با استفاده از تابع MS Excel BINOM.DIST، این احتمال را محاسبه می کنیم که از 6 روز بیش از 3 روز با سود کامل نمی شود (مقدار مقدار انتگرال 1 است):
پ 6 (≤3 ) = BINOM.DIST(3، 6، 0.61، 1) = 0.435.
احتمال اینکه از 6 روز همه با ضرر کار شود:
![]() ,
,
ما همان شاخص را با استفاده از تابع MS Excel BINOM.DIST محاسبه می کنیم:
پ 6 (0 ) = BINOM.DIST(0; 6; 0.61; 0) = 0.0035.
خودتان مشکل را حل کنید و سپس راه حل را ببینید
مثال 2یک کوزه شامل 2 توپ سفید و 3 توپ سیاه است. یک توپ از کوزه بیرون آورده می شود، رنگ آن تنظیم می شود و دوباره قرار می گیرد. تلاش 5 بار تکرار می شود. تعداد ظاهر توپ های سفید - گسسته مقدار تصادفی ایکس، طبق قانون دوجمله ای توزیع می شود. قانون توزیع یک متغیر تصادفی را بنویسید. حالت، انتظارات ریاضی و واریانس را تعیین کنید.
ما با هم به حل مشکلات ادامه می دهیم
مثال 3از پیک به اشیاء رفت n= 5 پیک. هر پیک با احتمال پ= 0.3 برای شیء بدون توجه به موارد دیگر دیر است. متغیر تصادفی گسسته ایکس- تعداد پیک های دیررس یک سری توزیع از این متغیر تصادفی بسازید. انتظارات ریاضی، واریانس، انحراف معیار آن را بیابید. این احتمال را پیدا کنید که حداقل دو پیک برای اشیا تاخیر داشته باشند.
توزیع دو جمله ای را در نظر بگیرید، انتظارات ریاضی، واریانس، حالت آن را محاسبه کنید. با استفاده از تابع MS EXCEL (BINOM.DIST)، تابع توزیع و نمودارهای چگالی احتمال را رسم خواهیم کرد. اجازه دهید پارامتر توزیع p، انتظارات ریاضی توزیع و انحراف معیار را تخمین بزنیم. همچنین توزیع برنولی را در نظر بگیرید.
تعریف. بگذار آنها برگزار شود nآزمونهایی که در هر یک از آنها فقط 2 رویداد میتواند رخ دهد: رویداد "موفقیت" با احتمال پ یا رویداد "شکست" با احتمال q =1-p (به اصطلاح طرح برنولی،برنولیآزمایش های).
احتمال بدست آوردن دقیقا ایکس موفقیت در اینها n تست ها برابر است با:
تعداد موفقیت در نمونه ایکس یک متغیر تصادفی است که دارد توزیع دو جمله ای(انگلیسی) دو جمله ایتوزیع) پو n– پارامترهای این توزیع هستند.
به خاطر داشته باشید که برای درخواست طرح های برنولیو به همین ترتیب توزیع دو جمله ای،شرایط زیر باید رعایت شود:
- هر آزمایش باید دقیقاً دو نتیجه داشته باشد که به طور مشروط «موفقیت» و «شکست» نامیده می شود.
- نتیجه هر آزمون نباید به نتایج آزمون های قبلی (استقلال آزمون) بستگی داشته باشد.
- میزان موفقیت پ باید برای تمام تست ها ثابت باشد.
توزیع دو جمله ای در MS EXCEL
در MS EXCEL، از نسخه 2010، برای توزیع دو جمله اییک تابع BINOM.DIST() وجود دارد، عنوان انگلیسی- BINOM.DIST()، که به شما امکان می دهد احتمال دقیق بودن نمونه را محاسبه کنید ایکس"موفقیت ها" (یعنی تابع چگالی احتمال p(x)، فرمول بالا را ببینید)، and تابع توزیع انتگرال(احتمالی که نمونه خواهد داشت ایکسیا کمتر "موفقیت"، از جمله 0).
قبل از MS EXCEL 2010، EXCEL دارای تابع BINOMDIST() بود که به شما امکان محاسبه را نیز می دهد. تابع توزیعو چگالی احتمالی p(x). BINOMDIST () در MS EXCEL 2010 برای سازگاری باقی مانده است.
فایل مثال حاوی نمودارها است چگالی توزیع احتمالو .

توزیع دو جمله ایتعیین را دارد ب(n; پ) .
توجه داشته باشید: برای ساخت تابع توزیع انتگرالنوع نمودار تناسب کامل برنامه، برای چگالی توزیع – هیستوگرام با گروه بندی. برای اطلاعات بیشتر در مورد نمودار ساختمان، مقاله انواع اصلی نمودارها را مطالعه کنید.
توجه داشته باشید: برای راحتی نوشتن فرمول ها در فایل نمونه، نام پارامترها ایجاد شده است توزیع دو جمله ای: n و p.

فایل مثال، محاسبات احتمالات مختلف را با استفاده از توابع MS EXCEL نشان می دهد:

همانطور که در تصویر بالا مشاهده می شود، فرض می شود که:
- جامعه نامتناهی که نمونه از آن ساخته شده است شامل 10٪ (یا 0.1) عناصر خوب (پارامتر) است. پ، آرگومان تابع سوم =BINOM.DIST())
- برای محاسبه این احتمال که در یک نمونه 10 عنصری (پارامتر n، آرگومان دوم تابع) دقیقاً 5 عنصر معتبر وجود خواهد داشت (آگومان اول)، باید فرمول را بنویسید: =BINOM.DIST(5، 10، 0.1، FALSE)
- آخرین، چهارمین عنصر تنظیم شده = FALSE، i.e. مقدار تابع برگردانده می شود چگالی توزیع.
اگر مقدار آرگومان چهارم = TRUE باشد، تابع BINOM.DIST() مقدار را برمی گرداند. تابع توزیع انتگرالیا به سادگی تابع توزیع. در این صورت می توانید احتمال اینکه تعداد اقلام خوب نمونه از یک محدوده معین مثلاً 2 یا کمتر (شامل 0) باشد را محاسبه کنید.
برای این کار باید فرمول زیر را بنویسید:
= BINOM.DIST(2, 10, 0.1, TRUE)
توجه داشته باشید: برای مقدار غیرصحیح x، . به عنوان مثال، فرمول های زیر همان مقدار را برمی گرداند:
=BINOM.DIST( 2
; ده 0.1; درست است، واقعی)
=BINOM.DIST( 2,9
; ده 0.1; درست است، واقعی)
توجه داشته باشید: در فایل نمونه چگالی احتمالیو تابع توزیعهمچنین با استفاده از تعریف و تابع COMBIN() محاسبه می شود.
شاخص های توزیع
AT فایل نمونه در برگه مثالفرمول هایی برای محاسبه برخی از شاخص های توزیع وجود دارد:
- =n*p;
- (انحراف استاندارد مربع) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
ما فرمول را استخراج می کنیم انتظارات ریاضی توزیع دو جمله ایاستفاده كردن طرح برنولی.
طبق تعریف، یک متغیر تصادفی X در طرح برنولی(متغیر تصادفی برنولی) دارد تابع توزیع:

این توزیع نامیده می شود توزیع برنولی.
توجه داشته باشید: توزیع برنولی- مورد خاص توزیع دو جمله ایبا پارامتر n=1.
بیایید 3 آرایه از 100 عدد با احتمال موفقیت متفاوت تولید کنیم: 0.1; 0.5 و 0.9. برای انجام این کار، در پنجره نسل اعداد تصادفی پارامترهای زیر را برای هر احتمال p تنظیم کنید:
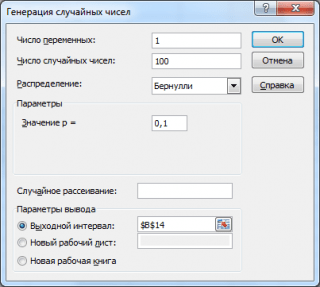
توجه داشته باشید: اگر گزینه را تنظیم کنید پراکندگی تصادفی (دانه تصادفی، سپس می توانید مجموعه تصادفی خاصی از اعداد تولید شده را انتخاب کنید. به عنوان مثال، با تنظیم این گزینه = 25، می توانید مجموعه های یکسانی از اعداد تصادفی را در رایانه های مختلف تولید کنید (البته اگر سایر پارامترهای توزیع یکسان باشند). مقدار گزینه می تواند مقادیر صحیح را از 1 تا 32767 بگیرد. نام گزینه پراکندگی تصادفیمی تواند گیج شود. بهتر است به این صورت ترجمه شود تعداد را با اعداد تصادفی تنظیم کنید.
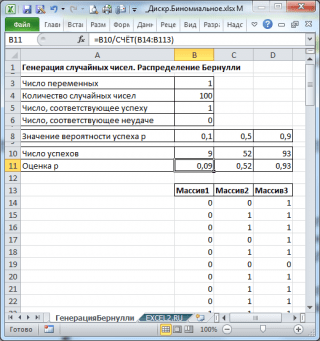
در نتیجه 3 ستون 100 عددی خواهیم داشت که بر اساس آنها مثلاً می توان احتمال موفقیت را تخمین زد. پطبق فرمول: تعداد موفقیت/100(سانتی متر. برگه فایل نمونه تولید برنولی).
توجه داشته باشید: برای توزیع های برنولیبا p=0.5، می توانید از فرمول =RANDBETWEEN(0;1) استفاده کنید که مربوط به .
تولید اعداد تصادفی توزیع دو جمله ای
فرض کنید 7 مورد معیوب در نمونه وجود دارد. این به این معنی است که "بسیار محتمل" است که نسبت محصولات معیوب تغییر کرده است. پکه از ویژگی های فرآیند تولید ماست. اگرچه این وضعیت "بسیار محتمل" است، اما این احتمال وجود دارد (خطر آلفا، خطای نوع 1، "هشدار نادرست") که پبدون تغییر باقی ماند و افزایش تعداد محصولات معیوب به دلیل نمونه گیری تصادفی بود.
همانطور که در شکل زیر مشاهده می شود، 7 تعداد محصولات معیوب قابل قبول برای فرآیندی با 0.21=p در همان مقدار است. آلفا. این نشان می دهد که وقتی از آستانه اقلام معیوب در یک نمونه فراتر رفت، پ"احتمالا" افزایش یافته است. عبارت "به احتمال زیاد" به این معنی است که تنها 10٪ احتمال (100٪ - 90٪) وجود دارد که انحراف درصد محصولات معیوب بالاتر از آستانه فقط به دلایل تصادفی باشد.

بنابراین، فراتر رفتن از آستانه تعداد محصولات معیوب در نمونه ممکن است به عنوان سیگنالی باشد که فرآیند به هم ریخته و شروع به تولید b در بارهدرصد بالاتر محصولات معیوب
توجه داشته باشید: قبل از MS EXCEL 2010، EXCEL یک تابع CRITBINOM() داشت که معادل BINOM.INV() است. CRITBINOM() در MS EXCEL 2010 و بالاتر برای سازگاری باقی مانده است.
رابطه توزیع دو جمله ای با سایر توزیع ها
اگر پارامتر n توزیع دو جمله ایبه بی نهایت تمایل دارد و پبه 0 تمایل دارد، سپس در این مورد توزیع دو جمله ایمی توان تقریب زد.
ممکن است برای فرمول شرایط زمانی که تقریب توزیع پواسونخوب کار می کند:
- پ<0,1 (کمتر پو بیشتر n، هر چه تقریب دقیق تر باشد)
- پ>0,9 (با توجه به اینکه q=1- پ، محاسبات در این مورد باید با استفاده از q(آ ایکسنیاز به تعویض دارد n- ایکس). بنابراین، کمتر qو بیشتر n، هر چه تقریب دقیق تر باشد).
در 0.1<=p<=0,9 и n*p>10 توزیع دو جمله ایمی توان تقریب زد.
در نوبتش، توزیع دو جمله ایزمانی که اندازه جمعیت N باشد می تواند به عنوان یک تقریب خوب عمل کند توزیع فرا هندسیبسیار بزرگتر از اندازه نمونه n (یعنی N>>n یا n/N<<1).
در مورد رابطه توزیع های فوق می توانید در مقاله بیشتر بخوانید. نمونه هایی از تقریب هم در آنجا آورده شده و شرایط در چه زمانی امکان پذیر است و با چه دقتی توضیح داده شده است.
مشاوره: می توانید در مورد سایر توزیع های MS EXCEL در مقاله بخوانید.
در این یادداشت و چند یادداشت بعدی، مدلهای ریاضی رویدادهای تصادفی را در نظر خواهیم گرفت. مدل ریاضییک عبارت ریاضی است که یک متغیر تصادفی را نشان می دهد. برای متغیرهای تصادفی گسسته، این عبارت ریاضی به عنوان تابع توزیع شناخته می شود.
اگر مشکل به شما اجازه می دهد که به صراحت یک عبارت ریاضی را که نشان دهنده یک متغیر تصادفی است بنویسید، می توانید احتمال دقیق هر یک از مقادیر آن را محاسبه کنید. در این حالت می توانید تمام مقادیر تابع توزیع را محاسبه و فهرست کنید. در کاربردهای تجاری، جامعهشناسی و پزشکی، توزیعهای مختلفی از متغیرهای تصادفی وجود دارد. یکی از مفیدترین توزیع ها دوجمله ای است.
توزیع دو جمله ایبرای مدلسازی موقعیتهایی که با ویژگیهای زیر مشخص میشوند استفاده میشود.
- نمونه از تعداد ثابتی از عناصر تشکیل شده است nنشان دهنده نتیجه یک آزمایش
- هر عنصر نمونه متعلق به یکی از دو دسته متقابل منحصر به فرد است که کل فضای نمونه را پوشش می دهد. معمولاً به این دو دسته موفقیت و شکست می گویند.
- احتمال موفقیت آرثابت است بنابراین، احتمال شکست است 1 - ص.
- نتیجه (یعنی موفقیت یا شکست) هر آزمایشی مستقل از نتیجه آزمایش دیگری است. برای اطمینان از استقلال نتایج، موارد نمونه معمولاً با استفاده از دو روش مختلف به دست میآیند. هر عنصر نمونه به طور تصادفی از یک جمعیت نامتناهی بدون جایگزینی یا از یک جمعیت محدود با جایگزینی استخراج می شود.
دانلود یادداشت در قالب یا فرمت، نمونه ها در قالب
توزیع دو جمله ای برای تخمین تعداد موفقیت ها در یک نمونه متشکل از استفاده می شود nمشاهدات بیایید سفارش را به عنوان مثال در نظر بگیریم. مشتریان شرکت ساکسون می توانند از فرم الکترونیکی تعاملی برای ثبت سفارش و ارسال آن به شرکت استفاده کنند. سپس سیستم اطلاعاتی بررسی می کند که آیا اشتباهی در سفارشات وجود دارد و همچنین اطلاعات ناقص یا نادرست وجود دارد. هر سفارش مشکوک علامت گذاری شده و در گزارش استثنای روزانه گنجانده شده است. داده های جمع آوری شده توسط شرکت نشان می دهد که احتمال خطا در سفارشات 0.1 است. شرکت مایل است بداند که احتمال یافتن تعداد معینی از سفارشات اشتباه در یک نمونه مشخص چقدر است. به عنوان مثال، فرض کنید مشتریان چهار فرم الکترونیکی را تکمیل کرده اند. احتمال اینکه همه سفارشات بدون خطا باشد چقدر است؟ چگونه این احتمال را محاسبه کنیم؟ منظور از موفقیت، خطا در پر کردن فرم است و سایر نتایج را به عنوان شکست در نظر می گیریم. به یاد داشته باشید که ما به تعداد سفارشات اشتباه در یک نمونه معین علاقه مند هستیم.
چه نتایجی را می توانیم مشاهده کنیم؟ اگر نمونه از چهار دستور تشکیل شده باشد، ممکن است یک، دو، سه یا هر چهار مرتبه اشتباه باشد، علاوه بر این، ممکن است همه آنها به درستی پر شده باشند. آیا متغیر تصادفی که تعداد فرم های اشتباه تکمیل شده را توصیف می کند می تواند مقدار دیگری داشته باشد؟ این امکان پذیر نیست زیرا تعداد فرم های نادرست تکمیل شده نمی تواند از حجم نمونه بیشتر شود nیا منفی باشد بنابراین، یک متغیر تصادفی که از قانون توزیع دوجمله ای تبعیت می کند، مقادیری از 0 تا را می گیرد n.
فرض کنید در یک نمونه از چهار مرتبه، نتایج زیر مشاهده می شود:
احتمال یافتن سه ترتیب اشتباه در نمونه چهار مرتبه و به ترتیب مشخص شده چقدر است؟ از آنجایی که مطالعات اولیه نشان داده است که احتمال خطا در تکمیل فرم 0.10 است، احتمال نتایج فوق به صورت زیر محاسبه می شود:
از آنجایی که پیامدها مستقل از یکدیگر هستند، احتمال دنباله نتایج نشان داده شده برابر است با: p*p*(1–p)*p = 0.1*0.1*0.9*0.1 = 0.0009. اگر لازم است تعداد انتخاب ها را محاسبه کنید ایکس nعناصر، باید از فرمول ترکیبی (1) استفاده کنید:

کجا n! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - فاکتوریل عدد n، و 0! = 1 و 1! = 1 طبق تعریف
این عبارت اغلب به عنوان . بنابراین، اگر n = 4 و X = 3 باشد، تعداد دنباله های متشکل از سه عنصر استخراج شده از نمونه ای با اندازه 4 با فرمول زیر به دست می آید:
بنابراین، احتمال یافتن سه ترتیب اشتباه به صورت زیر محاسبه می شود:
(تعداد دنباله های ممکن) *
(احتمال یک دنباله خاص) = 4 * 0.0009 = 0.0036
به همین ترتیب، میتوانیم احتمال اشتباه بودن یا درست بودن همه سفارشها را از بین چهار مرتبه محاسبه کنیم. با این حال، با افزایش حجم نمونه nتعیین احتمال یک توالی خاص از نتایج دشوارتر می شود. در این مورد، یک مدل ریاضی مناسب باید اعمال شود که توزیع دو جمله ای تعداد انتخاب ها را توصیف می کند. ایکساشیاء از نمونه حاوی nعناصر.
توزیع دو جمله ای

جایی که P(X)- احتمال ایکسموفقیت برای یک حجم نمونه معین nو احتمال موفقیت آر, ایکس = 0, 1, … n.
به این واقعیت توجه کنید که فرمول (2) رسمی سازی نتیجه گیری های شهودی است. مقدار تصادفی ایکس، با رعایت توزیع دو جمله ای، می تواند هر عدد صحیحی را در محدوده 0 تا داشته باشد n. کار کنید آرایکس(1 - p)n – ایکساحتمال یک دنباله خاص متشکل از ایکسموفقیت در نمونه، که اندازه آن برابر است n. مقدار تعداد ترکیبات ممکن را تعیین می کند ایکسموفقیت در nتست ها بنابراین، برای تعداد معینی از آزمایشات nو احتمال موفقیت آراحتمال یک دنباله متشکل از ایکسموفقیت برابر است با
P(X) = (تعداد دنباله های ممکن) * (احتمال یک دنباله خاص) = 
مثال هایی را در نظر بگیرید که کاربرد فرمول (2) را نشان می دهد.
1. فرض کنید احتمال پرکردن اشتباه فرم 0.1 باشد. احتمال اشتباه بودن سه فرم از چهار فرم تکمیل شده چقدر است؟ با استفاده از فرمول (2) به دست می آوریم که احتمال یافتن سه مرتبه اشتباه در یک نمونه چهار مرتبه برابر است با
2. احتمال عدم تکمیل فرم را 0.1 فرض کنید. احتمال اشتباه بودن حداقل سه فرم از چهار فرم تکمیل شده چقدر است؟ همانطور که در مثال قبل نشان داده شد، احتمال اشتباه بودن سه فرم از چهار فرم تکمیل شده 0.0036 است. برای محاسبه احتمال اشتباه تکمیل شدن حداقل سه فرم از چهار فرم تکمیل شده، باید احتمال اشتباه بودن سه فرم از بین چهار فرم تکمیل شده و احتمال اشتباه بودن همه چهار فرم تکمیل شده را اضافه کنید. احتمال رخداد دوم است
بنابراین، احتمال اینکه از بین چهار فرم تکمیل شده حداقل سه مورد اشتباه باشد برابر است
P(X > 3) = P(X = 3) + P(X = 4) = 0.0036 + 0.0001 = 0.0037
3. احتمال عدم تکمیل فرم را 0.1 فرض کنید. احتمال اشتباه بودن کمتر از سه فرم از چهار فرم تکمیل شده چقدر است؟ احتمال این رویداد
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
با استفاده از فرمول (2) هر یک از این احتمالات را محاسبه می کنیم:

بنابراین، P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
احتمال P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. سپس P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
با افزایش حجم نمونه nمحاسبات مشابه آنچه در مثال 3 انجام شد دشوار می شود. برای جلوگیری از این عوارض، بسیاری از احتمالات دوجمله ای پیش از زمان جدول بندی شده اند. برخی از این احتمالات در شکل نشان داده شده است. 1. مثلاً برای بدست آوردن این احتمال که ایکس= 2 در n= 4 و پ= 0.1، باید عددی را که در تقاطع خط قرار دارد از جدول استخراج کنید ایکس= 2 و ستون آر = 0,1.

برنج. 1. احتمال دو جمله ای در n = 4, ایکس= 2 و آر = 0,1
توزیع دو جمله ای را می توان با استفاده از توابع اکسل=BINOM.DIST() (شکل 2)، که دارای 4 پارامتر است: تعداد موفقیت ها - ایکس، تعداد آزمایشات (یا حجم نمونه) - n، احتمال موفقیت است آر، پارامتر انتگرال، که مقادیر TRUE را می گیرد (در این حالت، احتمال محاسبه می شود حداقل ایکسرویدادها) یا FALSE (در این مورد، احتمال دقیقا ایکسمناسبت ها).

برنج. 2. پارامترهای تابع =BINOM.DIST()
برای سه مثال بالا، محاسبات در شکل نشان داده شده است. 3 (به فایل اکسل نیز مراجعه کنید). هر ستون شامل یک فرمول است. اعداد پاسخ نمونه های عدد مربوطه را نشان می دهند).

برنج. 3. محاسبه توزیع دو جمله ایدر اکسل برای n= 4 و پ = 0,1
ویژگی های توزیع دو جمله ای
توزیع دو جمله ای به پارامترها بستگی دارد nو آر. توزیع دو جمله ای می تواند متقارن یا نامتقارن باشد. اگر p = 0.05، توزیع دوجمله ای بدون توجه به مقدار پارامتر متقارن است n. با این حال، اگر p ≠ 0.05، توزیع کج می شود. هر چه مقدار پارامتر نزدیکتر باشد آربه 0.05 و اندازه نمونه بزرگتر است n، عدم تقارن توزیع ضعیف تر است. بنابراین، توزیع تعداد فرم های نادرست تکمیل شده به سمت راست منتقل می شود، زیرا پ= 0.1 (شکل 4).

برنج. 4. هیستوگرام توزیع دوجمله ای برای n= 4 و پ = 0,1
انتظارات ریاضی از توزیع دوجمله ایبرابر حاصلضرب حجم نمونه است nدر مورد احتمال موفقیت آر:
(3) M = E(X) =np
به طور متوسط، با یک سری آزمایش به اندازه کافی طولانی در یک نمونه از چهار سفارش، ممکن است p \u003d E (X) \u003d 4 x 0.1 \u003d 0.4 فرم های نادرست تکمیل شده وجود داشته باشد.
انحراف استاندارد توزیع دو جمله ای
مثلا، انحراف معیارتعداد فرم های نادرست تکمیل شده در حسابداری سیستم اطلاعاتبرابر است با:
از مطالب کتاب لوین و همکاران آمار برای مدیران استفاده شده است. - م.: ویلیامز، 2004. - ص. 307-313
