توزیع دو جمله ای. توزیع دو جمله ای: تعریف، فرمول، مثال ها
البته هنگام محاسبه تابع توزیع تجمعی باید از رابطه ذکر شده بین توزیع دو جمله ای و بتا استفاده کرد. این روش مطمئناً بهتر از جمع مستقیم است که n> 10 باشد.
در کتاب های درسی کلاسیک آمار، برای به دست آوردن مقادیر توزیع دوجمله ای، اغلب توصیه می شود از فرمول های مبتنی بر قضایای حدی (مانند فرمول مویور-لاپلاس) استفاده شود. لازم به ذکر است که از نقطه نظر محاسباتی صرفارزش این قضایا نزدیک به صفر است، مخصوصاً در حال حاضر که تقریباً روی هر میز یک رایانه قدرتمند وجود دارد. نقطه ضعف اصلی تقریب های فوق دقت کامل ناکافی آنها برای مقادیر n معمولی برای اکثر برنامه ها است. یک نقطه ضعف کمتر، عدم وجود هرگونه توصیه واضح در مورد کاربرد یک یا تقریب دیگر است (در متون استاندارد، فقط فرمول های مجانبی ارائه می شود، آنها با تخمین های دقت همراه نیستند و بنابراین، کاربرد کمی دارند). من می گویم که هر دو فرمول فقط برای n معتبر هستند< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
من در اینجا مشکل یافتن چندک را در نظر نمیگیرم: برای توزیعهای گسسته، بیاهمیت است، و در آن مشکلاتی که چنین توزیعهایی به وجود میآیند، معمولاً موضوعیت ندارد. اگر هنوز چندک مورد نیاز است، توصیه می کنم مشکل را به گونه ای دوباره فرموله کنید که با مقادیر p (معنای مشاهده شده) کار کند. در اینجا یک مثال آورده شده است: هنگام پیاده سازی برخی از الگوریتم های شمارش، در هر مرحله باید بررسی شود فرضیه آماریدر مورد یک متغیر تصادفی دو جمله ای با توجه به رویکرد کلاسیک، در هر مرحله باید آمار معیار را محاسبه کرد و مقدار آن را با مرز مجموعه بحرانی مقایسه کرد. با این حال، از آنجایی که الگوریتم شمارشی است، لازم است مرز مجموعه بحرانی را هر بار از نو تعیین کنیم (در نهایت، اندازه نمونه از مرحله به مرحله تغییر می کند)، که به طور غیرمولد هزینه های زمانی را افزایش می دهد. رویکرد مدرن محاسبه اهمیت مشاهده شده و مقایسه آن با آن را توصیه می کند سطح اطمینان، صرفه جویی در جستجوی چندک.
بنابراین، در کدهای زیر، محاسبه تابع معکوس وجود ندارد، به جای آن، تابع rev_binomialDF آورده شده است که با توجه به تعداد n آزمایش، تعداد m موفقیت در آنها، احتمال p موفقیت در یک آزمایش واحد را محاسبه می کند. مقدار y احتمال به دست آوردن این m موفقیت ها. این از رابطه فوق الذکر بین توزیع دو جمله ای و بتا استفاده می کند.
در واقع، این تابع به شما اجازه می دهد تا مرزهای فواصل اطمینان را بدست آورید. در واقع، فرض کنید در n آزمایش دوجمله ای m موفقیت به دست آوریم. همانطور که می دانید، حاشیه سمت چپ یک دو طرفه است فاصله اطمینانبرای پارامتر p با سطح اطمینان 0 است اگر m = 0، و برای حل معادله است  . به طور مشابه، کران سمت راست 1 است اگر m = n، و for یک راه حل برای معادله است.
. به طور مشابه، کران سمت راست 1 است اگر m = n، و for یک راه حل برای معادله است.  . این بدان معناست که برای یافتن مرز سمت چپ باید معادله را حل کنیم
. این بدان معناست که برای یافتن مرز سمت چپ باید معادله را حل کنیم  ، و برای جستجوی مناسب - معادله
، و برای جستجوی مناسب - معادله  . آنها در توابع binom_leftCI و binom_rightCI حل شدهاند که به ترتیب کرانهای بالایی و پایینی فاصله اطمینان دو طرفه را برمیگردانند.
. آنها در توابع binom_leftCI و binom_rightCI حل شدهاند که به ترتیب کرانهای بالایی و پایینی فاصله اطمینان دو طرفه را برمیگردانند.
من می خواهم توجه داشته باشم که اگر به دقت کاملاً باورنکردنی نیاز نیست، برای n به اندازه کافی بزرگ، می توانید از تقریب زیر استفاده کنید [B.L. ون در واردن، آمار ریاضی. م: IL، 1960، چ. 2، ثانیه 7]:  ، که g مقدار کمی است توزیع نرمال. ارزش این تقریب این است که تقریب های بسیار ساده ای وجود دارد که به شما امکان می دهد چندک های توزیع نرمال را محاسبه کنید (متن مربوط به محاسبه توزیع نرمال و بخش مربوطه را در این مرجع ببینید). در تمرین من (عمدتا برای n> 100)، این تقریب حدود 3-4 رقم را ارائه می دهد که، به عنوان یک قاعده، کاملاً کافی است.
، که g مقدار کمی است توزیع نرمال. ارزش این تقریب این است که تقریب های بسیار ساده ای وجود دارد که به شما امکان می دهد چندک های توزیع نرمال را محاسبه کنید (متن مربوط به محاسبه توزیع نرمال و بخش مربوطه را در این مرجع ببینید). در تمرین من (عمدتا برای n> 100)، این تقریب حدود 3-4 رقم را ارائه می دهد که، به عنوان یک قاعده، کاملاً کافی است.
محاسبات با کدهای زیر به فایلهای betaDF.h، betaDF.cpp (به بخش توزیع بتا مراجعه کنید)، و همچنین logGamma.h، logGamma.cpp (به پیوست A مراجعه کنید) نیاز دارد. همچنین می توانید نمونه ای از استفاده از توابع را مشاهده کنید.
فایل binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double success, double p); /* * اجازه دهید "آزمایش" مشاهدات مستقل * با احتمال "p" موفقیت در هر یک وجود داشته باشد. * احتمال B(موفقیتها| آزمایشات، p) را محاسبه کنید که تعداد * موفقیتها بین 0 و "موفقیتها" (شامل) باشد. */ double rev_binomialDF (آزمایش مضاعف، موفقیت های مضاعف، دو برابر y)؛ /* * بگذارید احتمال y حداقل m موفقیت * در آزمایشات طرح برنولی شناخته شود. تابع احتمال p * موفقیت را در یک آزمایش واحد پیدا می کند. * * رابطه زیر در محاسبات استفاده می شود * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI (آزمایش مضاعف، موفقیت های مضاعف، دو سطح)؛ /* مشاهدات مستقل "آزمایش" باشد * با احتمال "p" موفقیت در هر * و تعداد موفقیت ها "موفقیت" است. * کران سمت چپ فاصله اطمینان دو طرفه * با سطح سطح معنی داری محاسبه می شود. */ double binom_rightCI(n دو برابر، موفقیتهای مضاعف، دو سطح)؛ /* مشاهدات مستقل "آزمایش" باشد * با احتمال "p" موفقیت در هر * و تعداد موفقیت ها "موفقیت" است. * حد راست فاصله اطمینان دو طرفه * با سطح سطح معنی داری محاسبه می شود. */ #endif /* به پایان می رسد #ifndef __BINOMIAL_H__ */ |
فایل binomialDF.cpp
| /************************************************ **** *********/ /* توزیع دو جمله ای */ /**************************** ********************************/ #شامل |
توزیع احتمال متغیرهای تصادفی گسسته. توزیع دو جمله ای. توزیع پواسون توزیع هندسی تابع تولید
6. توزیع احتمال متغیرهای تصادفی گسسته
6.1. توزیع دو جمله ای
بذار تولید بشه nآزمایشات مستقل، که در هر یک از آنها یک رویداد آممکن است ظاهر شود یا نباشد. احتمال پوقوع یک رویداد آدر همه آزمون ها ثابت است و از آزمونی به آزمون دیگر تغییر نمی کند. به عنوان یک متغیر تصادفی X تعداد وقوع رویداد را در نظر بگیرید آدر این تست ها فرمولی برای یافتن احتمال وقوع یک رویداد آصاف کیک بار در nآزمایشات، همانطور که مشخص است، شرح داده شده است فرمول برنولی
توزیع احتمال تعریف شده توسط فرمول برنولی نامیده می شود دو جمله ای .
این قانون "دوجمله ای" نامیده می شود زیرا سمت راست را می توان به عنوان یک اصطلاح رایج در بسط دو جمله ای نیوتن در نظر گرفت.
قانون دوجمله ای را به صورت جدول می نویسیم
|
پ n |
np n –1 q |
|
q n |

اجازه دهید ویژگی های عددی این توزیع را پیدا کنیم.
طبق تعریف انتظارات ریاضیبرای DSW ما داریم
 .
.
اجازه دهید تساوی را بنویسیم که همان بن نیوتن است
 .
.
و آن را با توجه به p متمایز کنید. در نتیجه می گیریم
 .
.
ضرب چپ و سمت راستبر روی پ:
 .
.
با توجه به اینکه پ+ q=1، ما داریم
 (6.2)
(6.2)
بنابراین، انتظارات ریاضی از تعداد وقوع رویدادها درn تست های مستقلبرابر حاصل ضرب تعداد آزمایش استnبر اساس احتمالپوقوع یک رویداد در هر آزمایش.
پراکندگی را با فرمول محاسبه می کنیم
 .
.
برای این ما پیدا می کنیم
 .
.
ابتدا فرمول دوجمله ای نیوتن را دو بار با توجه به آن متمایز می کنیم پ:

و دو طرف معادله را در ضرب کنید پ 2:

در نتیجه،
بنابراین واریانس توزیع دو جمله ای است
 .
(6.3)
.
(6.3)
این نتایج را می توان از استدلال صرفاً کیفی نیز به دست آورد. مجموع X وقوع رویداد A در همه کارآزماییها به تعداد وقوع رویداد در آزمایشهای فردی اضافه میشود. بنابراین، اگر X 1 تعداد وقوع رویداد در آزمایش اول، X 2 در آزمایش دوم و غیره باشد، پس تعداد کلوقوع رویداد A در تمام آزمایشات برابر با X=X 1 +X 2 +…+X است n. با توجه به ویژگی انتظار ریاضی:
هر یک از اصطلاحات سمت راست برابری، انتظار ریاضی تعداد رویدادها در یک آزمون است که برابر با احتمال رخداد است. به این ترتیب،
با توجه به خاصیت پراکندگی:
از آنجا که، و انتظارات ریاضی یک متغیر تصادفی  ، که فقط می تواند دو مقدار یعنی 1 2 با احتمال را بگیرد پو 0 2 با احتمال q، سپس
، که فقط می تواند دو مقدار یعنی 1 2 با احتمال را بگیرد پو 0 2 با احتمال q، سپس  . به این ترتیب،
. به این ترتیب،  در نتیجه می گیریم
در نتیجه می گیریم
با استفاده از مفهوم گشتاورهای اولیه و مرکزی، می توان فرمول هایی برای چولگی و کشیدگی به دست آورد:
 .
(6.4)
.
(6.4)

برنج. 6.1
چند ضلعی توزیع دو جمله ای شکل زیر را دارد (شکل 6.1 را ببینید). احتمال P n (ک) ابتدا با افزایش افزایش می یابد ک، می رسد بزرگترین ارزشو سپس شروع به کاهش می کند. توزیع دوجمله ای به جز مورد کج است پ=0.5. توجه داشته باشید که وقتی اعداد بزرگتست ها nتوزیع دوجمله ای بسیار نزدیک به نرمال است. (توجیه این گزاره مربوط به قضیه محلی مویور-لاپلاس است.)عددمتر 0 وقوع یک رویداد نامیده می شودبه احتمال زیاد ، اگر احتمال وقوع رویداد در تعداد معینی بار در این سری آزمایش ها بزرگترین باشد (حداکثر در چند ضلعی توزیع). برای توزیع دوجمله ای
اظهار نظر. این نابرابری را می توان با استفاده از فرمول بازگشتی برای احتمالات دو جمله ای اثبات کرد:
 (6.6)
(6.6)
مثال 6.1.سهم محصولات ممتاز در این شرکت 31 درصد است. میانگین و واریانس، همچنین محتمل ترین تعداد اقلام ممتاز در یک دسته 75 موردی که به طور تصادفی انتخاب شده اند چیست؟
راه حل. از آنجا که پ=0,31, q=0,69, n= 75، پس
M[ ایکس] = np= 750.31 = 23.25; D[ ایکس] = npq = 750,310,69 = 16,04.
برای یافتن محتمل ترین عدد متر 0، یک نابرابری مضاعف می سازیم
از این رو نتیجه می شود که متر 0 = 23.
فصل 7
قوانین خاص توزیع متغیرهای تصادفی
انواع قوانین توزیع متغیرهای تصادفی گسسته
بگذارید گسسته شود مقدار تصادفیمی تواند ارزش ها را بگیرد ایکس 1 , ایکس 2 , …, x n، …. احتمالات این مقادیر را می توان با استفاده از فرمول های مختلفی محاسبه کرد، به عنوان مثال، با استفاده از قضایای اساسی نظریه احتمال، فرمول برنولی یا برخی فرمول های دیگر. برای برخی از این فرمول ها، قانون توزیع نام خاص خود را دارد.
رایج ترین قوانین توزیع یک متغیر تصادفی گسسته عبارتند از قانون توزیع دو جمله ای، هندسی، ابر هندسی، قانون توزیع پواسون.
قانون توزیع دوجمله ای
بذار تولید بشه nکارآزمایی های مستقل، که در هر کدام ممکن است رویدادی رخ دهد یا نباشد ولی. احتمال وقوع این رویداد در هر آزمایش ثابت است، به عدد آزمایشی بستگی ندارد و برابر است با آر=آر(ولی). از این رو احتمال وقوع این رویداد وجود دارد ولیدر هر آزمون نیز ثابت و برابر است q=1–آر. یک متغیر تصادفی را در نظر بگیرید ایکسبرابر با تعداد وقوع رویداد است ولیکه در nتست ها بدیهی است که مقادیر این کمیت برابر است
ایکس 1 = 0 - رویداد ولیکه در nآزمایشات ظاهر نشد؛
ایکس 2 = 1 - رویداد ولیکه در nآزمایشات یک بار ظاهر شد.
ایکس 3 = 2 - رویداد ولیکه در nآزمایشات دو بار ظاهر شد.
…………………………………………………………..
x n +1 = n- رویداد ولیکه در nآزمایش همه چیز ظاهر شد nیک بار.
احتمالات این مقادیر را می توان با استفاده از فرمول برنولی (4.1) محاسبه کرد:
جایی که به=0, 1, 2, …,n .
قانون توزیع دوجمله ای ایکسبرابر با تعداد موفقیت ها در nآزمایشات برنولی، با احتمال موفقیت آر.
بنابراین، یک متغیر تصادفی گسسته دارای توزیع دو جمله ای است (یا بر اساس توزیع می شود قانون دوجمله ای) اگر مقادیر ممکن آن 0، 1، 2، … باشد، n، و احتمالات مربوطه با فرمول (7.1) محاسبه می شود.
توزیع دوجمله ای به دو عدد بستگی دارد مولفه های آرو n.
سری توزیع یک متغیر تصادفی که طبق قانون دوجمله ای توزیع شده است به شکل زیر است:
| ایکس | … | ک | … | n | ||
| آر | | … | … | |
مثال 7.1 . سه گلوله مستقل به سمت هدف شلیک می شود. احتمال زدن هر شلیک 0.4 است. مقدار تصادفی ایکس- تعداد ضربه به هدف. سری توزیع آن را بسازید.
راه حل. مقادیر احتمالی یک متغیر تصادفی ایکسهستند ایکس 1 =0; ایکس 2 =1; ایکس 3 =2; ایکس 4=3. با استفاده از فرمول برنولی احتمالات مربوطه را پیدا کنید. به راحتی می توان نشان داد که کاربرد این فرمول در اینجا کاملاً موجه است. توجه داشته باشید که احتمال اصابت نکردن به هدف با یک شلیک برابر با 1-0.4=0.6 خواهد بود. گرفتن

سری توزیع به شکل زیر است:
| ایکس | ||||
| آر | 0,216 | 0,432 | 0,288 | 0,064 |
به راحتی می توان بررسی کرد که مجموع همه احتمالات برابر با 1 باشد. خود متغیر تصادفی ایکسطبق قانون دوجمله ای توزیع می شود. ■
بیایید انتظار ریاضی و واریانس یک متغیر تصادفی توزیع شده بر اساس قانون دو جمله ای را پیدا کنیم.
هنگام حل مثال 6.5 نشان داده شد که انتظارات ریاضی تعداد وقوع یک رویداد ولیکه در nتست های مستقل، در صورت احتمال وقوع ولیدر هر آزمون ثابت و مساوی است آر، برابر است n· آر
در این مثال، از یک متغیر تصادفی استفاده شده است که بر اساس قانون دوجمله ای توزیع شده است. بنابراین، حل مثال 6.5 در واقع اثبات قضیه زیر است.
قضیه 7.1.انتظار ریاضی یک متغیر تصادفی گسسته که طبق قانون دوجمله ای توزیع شده است برابر است با حاصل ضرب تعداد آزمایش و احتمال "موفقیت"، یعنی. م(ایکس)=n· آر.
قضیه 7.2.واریانس یک متغیر تصادفی گسسته توزیع شده بر اساس قانون دوجمله ای برابر است با حاصل ضرب تعداد آزمایش بر اساس احتمال "موفقیت" و احتمال "شکست"، یعنی. D(ایکس)=npq.
چولگی و کشیدگی یک متغیر تصادفی توزیع شده بر اساس قانون دوجمله ای با فرمول تعیین می شود.
این فرمول ها را می توان با استفاده از مفهوم گشتاورهای اولیه و مرکزی به دست آورد.
قانون توزیع دوجمله ای زیربنای بسیاری از موقعیت های واقعی است. برای مقادیر بزرگ nتوزیع دو جمله ای را می توان با توزیع های دیگر، به ویژه توزیع پواسون، تقریب زد.
توزیع پواسون
بذار باشه nآزمایشات برنولی، با تعداد آزمایشات nبه اندازه کافی بزرگ قبلاً نشان داده شده بود که در این مورد (اگر علاوه بر این، احتمال آرتحولات ولیبسیار کوچک) برای یافتن احتمال وقوع یک رویداد ولیظاهر شدن تییک بار در تست ها، می توانید از فرمول پواسون (4.9) استفاده کنید. اگر متغیر تصادفی ایکسبه معنی تعداد وقوع رویداد است ولیکه در nآزمایشات برنولی، سپس احتمال آن ایکسمعنا را به خود خواهد گرفت کبا فرمول قابل محاسبه است
 , (7.2)
, (7.2)
جایی که λ = np.
قانون توزیع پواسونتوزیع یک متغیر تصادفی گسسته نامیده می شود ایکس، که مقادیر ممکن برای آن اعداد صحیح غیر منفی و احتمالات هستند p tاین مقادیر با فرمول (7.2) یافت می شوند.
ارزش λ = npتماس گرفت پارامترتوزیع پواسون
یک متغیر تصادفی که بر اساس قانون پواسون توزیع میشود، میتواند تعداد نامتناهی مقدار بگیرد. از آنجایی که برای این توزیع احتمال آروقوع یک رویداد در هر آزمایش کوچک است، سپس این توزیع گاهی اوقات قانون پدیده های نادر نامیده می شود.
سری توزیع یک متغیر تصادفی که بر اساس قانون پواسون توزیع شده است دارای شکل است
| ایکس | … | تی | … | ||||
| آر | … | … |
به راحتی می توان تأیید کرد که مجموع احتمالات ردیف دوم برابر با 1 است. برای انجام این کار، باید به خاطر داشته باشیم که تابع را می توان در یک سری Maclaurin گسترش داد، که برای هر یک همگرا می شود. ایکس. در این مورد داریم
 . (7.3)
. (7.3)
همانطور که اشاره شد، قانون پواسون در برخی موارد محدود کننده جایگزین قانون دوجمله ای می شود. یک مثال یک متغیر تصادفی است ایکسکه مقادیر آن برابر با تعداد خرابی های یک دوره زمانی معین با استفاده مکرر از یک دستگاه فنی است. فرض بر این است که این دستگاه از قابلیت اطمینان بالایی برخوردار است، یعنی. احتمال شکست در یک برنامه بسیار کم است.
علاوه بر چنین موارد محدود کننده، در عمل متغیرهای تصادفی توزیع شده بر اساس قانون پواسون وجود دارد که به توزیع دوجمله ای مربوط نمی شود. به عنوان مثال، توزیع پواسون اغلب برای برخورد با تعداد رویدادهایی که در یک دوره زمانی رخ میدهند (تعداد تماسهای تلفنی در طول یک ساعت، تعداد خودروهایی که در طول روز به کارواش رسیدهاند، تعداد توقف های ماشین در هفته و غیره .). همه این رویدادها باید به اصطلاح جریان رویدادها را تشکیل دهند که یکی از مفاهیم اساسی نظریه است در صف. پارامتر λ میانگین شدت جریان رویدادها را مشخص می کند.
در این یادداشت و چند یادداشت بعدی، مدلهای ریاضی رویدادهای تصادفی را در نظر خواهیم گرفت. مدل ریاضی- این هست بیان ریاضی، نشان دهنده یک متغیر تصادفی است. برای متغیرهای تصادفی گسسته، این عبارت ریاضی به عنوان تابع توزیع شناخته می شود.
اگر مشکل به شما اجازه می دهد که به صراحت یک عبارت ریاضی را که نشان دهنده یک متغیر تصادفی است بنویسید، می توانید احتمال دقیق هر یک از مقادیر آن را محاسبه کنید. در این حالت می توانید تمام مقادیر تابع توزیع را محاسبه و فهرست کنید. در کاربردهای تجاری، جامعهشناسی و پزشکی، توزیعهای مختلفی از متغیرهای تصادفی وجود دارد. یکی از مفیدترین توزیع ها دوجمله ای است.
توزیع دو جمله ایبرای مدلسازی موقعیتهایی که با ویژگیهای زیر مشخص میشوند استفاده میشود.
- نمونه از تعداد ثابتی از عناصر تشکیل شده است nنشان دهنده نتیجه یک آزمایش
- هر عنصر نمونه متعلق به یکی از دو دسته متقابل منحصر به فرد است که کل فضای نمونه را پوشش می دهد. معمولاً به این دو دسته موفقیت و شکست می گویند.
- احتمال موفقیت آرثابت است بنابراین، احتمال شکست است 1 - ص.
- نتیجه (یعنی موفقیت یا شکست) هر آزمایشی مستقل از نتیجه آزمایش دیگری است. برای اطمینان از استقلال نتایج، موارد نمونه معمولاً با استفاده از دو روش مختلف به دست میآیند. هر عنصر از نمونه به طور تصادفی از یک نامتناهی استخراج می شود جمعیتبدون بازگشت یا از یک جمعیت محدود با بازگشت.
دانلود یادداشت در قالب یا فرمت، نمونه ها در قالب
توزیع دو جمله ای برای تخمین تعداد موفقیت ها در یک نمونه متشکل از استفاده می شود nمشاهدات بیایید سفارش را به عنوان مثال در نظر بگیریم. مشتریان شرکت ساکسون می توانند از فرم الکترونیکی تعاملی برای ثبت سفارش و ارسال آن به شرکت استفاده کنند. سپس سیستم اطلاعاتی بررسی می کند که آیا اشتباهی در سفارشات وجود دارد و همچنین اطلاعات ناقص یا نادرست وجود دارد. هر سفارش مشکوک علامت گذاری شده و در گزارش استثنای روزانه گنجانده شده است. داده های جمع آوری شده توسط شرکت نشان می دهد که احتمال خطا در سفارشات 0.1 است. شرکت مایل است بداند که احتمال یافتن تعداد معینی از سفارشات اشتباه در یک نمونه مشخص چقدر است. به عنوان مثال، فرض کنید مشتریان چهار را تکمیل کرده اند فرم های الکترونیکی. احتمال اینکه همه سفارشات بدون خطا باشد چقدر است؟ چگونه این احتمال را محاسبه کنیم؟ منظور از موفقیت، خطا در پر کردن فرم است و سایر نتایج را به عنوان شکست در نظر می گیریم. به یاد داشته باشید که ما به تعداد سفارشات اشتباه در یک نمونه معین علاقه مند هستیم.
چه نتایجی را می توانیم مشاهده کنیم؟ اگر نمونه از چهار دستور تشکیل شده باشد، ممکن است یک، دو، سه یا هر چهار مرتبه اشتباه باشد، علاوه بر این، ممکن است همه آنها به درستی پر شده باشند. آیا متغیر تصادفی که تعداد فرم های اشتباه تکمیل شده را توصیف می کند می تواند مقدار دیگری داشته باشد؟ این امکان پذیر نیست زیرا تعداد فرم های نادرست تکمیل شده نمی تواند از حجم نمونه بیشتر شود nیا منفی باشد بنابراین، یک متغیر تصادفی که از قانون توزیع دوجمله ای تبعیت می کند، مقادیری از 0 تا را می گیرد n.
فرض کنید در یک نمونه از چهار مرتبه، نتایج زیر مشاهده می شود:
احتمال یافتن سه ترتیب اشتباه در نمونه چهار مرتبه و به ترتیب مشخص شده چقدر است؟ از آنجایی که مطالعات اولیه نشان داده است که احتمال خطا در تکمیل فرم 0.10 است، احتمال نتایج فوق به صورت زیر محاسبه می شود:
از آنجایی که پیامدها مستقل از یکدیگر هستند، احتمال دنباله نتایج نشان داده شده برابر است با: p*p*(1–p)*p = 0.1*0.1*0.9*0.1 = 0.0009. اگر لازم است تعداد انتخاب ها را محاسبه کنید ایکس nعناصر، باید از فرمول ترکیبی (1) استفاده کنید:

کجا n! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - فاکتوریل عدد n، و 0! = 1 و 1! = 1 طبق تعریف
این عبارت اغلب به عنوان . بنابراین، اگر n = 4 و X = 3 باشد، تعداد دنباله های متشکل از سه عنصر، استخراج شده از نمونه اندازه 4، با فرمول زیر تعیین می شود:
بنابراین، احتمال یافتن سه ترتیب اشتباه به صورت زیر محاسبه می شود:
(تعداد دنباله های ممکن) *
(احتمال یک دنباله خاص) = 4 * 0.0009 = 0.0036
به همین ترتیب، میتوانیم احتمال اشتباه بودن یک یا دو مرتبه از بین چهار مرتبه و همچنین احتمال اشتباه بودن یا درست بودن همه دستورات را محاسبه کنیم. با این حال، با افزایش حجم نمونه nتعیین احتمال یک توالی خاص از نتایج دشوارتر می شود. در این مورد، مناسب را اعمال کنید مدل ریاضیتوزیع دوجمله ای تعداد انتخاب ها را توصیف می کند ایکساشیاء از نمونه حاوی nعناصر.
توزیع دو جمله ای

جایی که P(X)- احتمال ایکسموفقیت برای یک حجم نمونه معین nو احتمال موفقیت آر, ایکس = 0, 1, … n.
به این واقعیت توجه کنید که فرمول (2) رسمی سازی نتیجه گیری های شهودی است. مقدار تصادفی ایکس، با رعایت توزیع دو جمله ای، می تواند هر عدد صحیحی را در محدوده 0 تا داشته باشد n. کار کنید آرایکس(1 - p)n – ایکساحتمال یک دنباله خاص متشکل از ایکسموفقیت در نمونه، که اندازه آن برابر است n. مقدار تعداد ترکیبات ممکن را تعیین می کند ایکسموفقیت در nتست ها بنابراین، برای تعداد معینی از آزمایشات nو احتمال موفقیت آراحتمال یک دنباله متشکل از ایکسموفقیت برابر است با
P(X) = (تعداد دنباله های ممکن) * (احتمال یک دنباله خاص) = 
مثال هایی را در نظر بگیرید که کاربرد فرمول (2) را نشان می دهد.
1. فرض کنید احتمال پرکردن اشتباه فرم 0.1 باشد. احتمال اشتباه بودن سه فرم از چهار فرم تکمیل شده چقدر است؟ با استفاده از فرمول (2) به دست می آوریم که احتمال یافتن سه مرتبه اشتباه در یک نمونه چهار مرتبه برابر است با
2. احتمال عدم تکمیل فرم را 0.1 فرض کنید. احتمال اشتباه بودن حداقل سه فرم از چهار فرم تکمیل شده چقدر است؟ همانطور که در مثال قبل نشان داده شد، احتمال اشتباه بودن سه فرم از چهار فرم تکمیل شده 0.0036 است. برای محاسبه احتمال اشتباه تکمیل شدن حداقل سه فرم از چهار فرم تکمیل شده، باید احتمال اشتباه بودن سه فرم از بین چهار فرم تکمیل شده و احتمال اشتباه بودن همه چهار فرم تکمیل شده را اضافه کنید. احتمال رخداد دوم است
بنابراین، احتمال اینکه از بین چهار فرم تکمیل شده حداقل سه مورد اشتباه باشد برابر است
P(X > 3) = P(X = 3) + P(X = 4) = 0.0036 + 0.0001 = 0.0037
3. احتمال عدم تکمیل فرم را 0.1 فرض کنید. احتمال اشتباه بودن کمتر از سه فرم از چهار فرم تکمیل شده چقدر است؟ احتمال این رویداد
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
با استفاده از فرمول (2) هر یک از این احتمالات را محاسبه می کنیم:

بنابراین، P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
احتمال P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. سپس P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
با افزایش حجم نمونه nمحاسبات مشابه آنچه در مثال 3 انجام شد دشوار می شود. برای جلوگیری از این عوارض، بسیاری از احتمالات دوجمله ای پیش از زمان جدول بندی شده اند. برخی از این احتمالات در شکل نشان داده شده است. 1. مثلاً برای بدست آوردن این احتمال که ایکس= 2 در n= 4 و پ= 0.1، باید عددی را که در تقاطع خط قرار دارد از جدول استخراج کنید ایکس= 2 و ستون آر = 0,1.

برنج. 1. احتمال دو جمله ای در n = 4, ایکس= 2 و آر = 0,1
توزیع دو جمله ای را می توان با استفاده از توابع اکسل=BINOM.DIST() (شکل 2)، که دارای 4 پارامتر است: تعداد موفقیت ها - ایکس، تعداد آزمایشات (یا حجم نمونه) - n، احتمال موفقیت است آر، پارامتر انتگرال، که مقادیر TRUE را می گیرد (در این حالت، احتمال محاسبه می شود حداقل ایکسرویدادها) یا FALSE (در این مورد، احتمال دقیقا ایکسمناسبت ها).

برنج. 2. پارامترهای تابع =BINOM.DIST()
برای سه مثال بالا، محاسبات در شکل نشان داده شده است. 3 (به فایل اکسل نیز مراجعه کنید). هر ستون شامل یک فرمول است. اعداد پاسخ نمونه های عدد مربوطه را نشان می دهند).

برنج. 3. محاسبه توزیع دو جمله ای در اکسل برای n= 4 و پ = 0,1
ویژگی های توزیع دو جمله ای
توزیع دو جمله ای به پارامترها بستگی دارد nو آر. توزیع دو جمله ای می تواند متقارن یا نامتقارن باشد. اگر p = 0.05، توزیع دوجمله ای بدون توجه به مقدار پارامتر متقارن است n. با این حال، اگر p ≠ 0.05، توزیع کج می شود. هر چه مقدار پارامتر نزدیکتر باشد آربه 0.05 و اندازه نمونه بزرگتر است n، عدم تقارن توزیع ضعیف تر است. بنابراین، توزیع تعداد فرم های نادرست تکمیل شده به سمت راست منتقل می شود، زیرا پ= 0.1 (شکل 4).

برنج. 4. هیستوگرام توزیع دوجمله ای برای n= 4 و پ = 0,1
انتظارات ریاضی از توزیع دوجمله ایبرابر حاصلضرب حجم نمونه است nدر مورد احتمال موفقیت آر:
(3) M = E(X) =np
به طور متوسط، با یک سری آزمایش به اندازه کافی طولانی در یک نمونه از چهار سفارش، ممکن است p \u003d E (X) \u003d 4 x 0.1 \u003d 0.4 فرم های نادرست تکمیل شده وجود داشته باشد.
انحراف استاندارد توزیع دو جمله ای
به عنوان مثال، انحراف معیار تعداد فرم های نادرست تکمیل شده در حسابداری سیستم اطلاعاتبرابر است با:
از مطالب کتاب لوین و همکاران آمار برای مدیران استفاده شده است. - م.: ویلیامز، 2004. - ص. 307-313
توزیع دو جمله ای را در نظر بگیرید، انتظارات ریاضی، واریانس، حالت آن را محاسبه کنید. با استفاده از تابع MS EXCEL (BINOM.DIST)، تابع توزیع و نمودارهای چگالی احتمال را رسم خواهیم کرد. اجازه دهید پارامتر توزیع p، انتظارات ریاضی توزیع، و را تخمین بزنیم انحراف معیار. همچنین توزیع برنولی را در نظر بگیرید.
تعریف. بگذار آنها برگزار شود nآزمونهایی که در هر یک از آنها فقط 2 رویداد میتواند رخ دهد: رویداد "موفقیت" با احتمال پ یا رویداد "شکست" با احتمال q =1-p (به اصطلاح طرح برنولی،برنولیآزمایش های).
احتمال بدست آوردن دقیقا ایکس موفقیت در اینها n تست ها برابر است با:
تعداد موفقیت در نمونه ایکس یک متغیر تصادفی است که دارد توزیع دو جمله ای(انگلیسی) دو جمله ایتوزیع) پو n– پارامترهای این توزیع هستند.
به خاطر داشته باشید که برای درخواست طرح های برنولیو به همین ترتیب توزیع دو جمله ای،شرایط زیر باید رعایت شود:
- هر آزمایش باید دقیقاً دو نتیجه داشته باشد که به طور مشروط «موفقیت» و «شکست» نامیده می شود.
- نتیجه هر آزمون نباید به نتایج آزمون های قبلی (استقلال آزمون) بستگی داشته باشد.
- میزان موفقیت پ باید برای تمام تست ها ثابت باشد.
توزیع دو جمله ای در MS EXCEL
در MS EXCEL، از نسخه 2010، برای توزیع دو جمله اییک تابع BINOM.DIST() وجود دارد، نام انگلیسی- BINOM.DIST()، که به شما امکان می دهد احتمال دقیق بودن نمونه را محاسبه کنید ایکس"موفقیت ها" (یعنی تابع چگالی احتمال p(x)، فرمول بالا را ببینید)، and تابع توزیع انتگرال(احتمالی که نمونه خواهد داشت ایکسیا کمتر "موفقیت"، از جمله 0).
قبل از MS EXCEL 2010، EXCEL دارای تابع BINOMDIST() بود که به شما امکان محاسبه را نیز می دهد. تابع توزیعو چگالی احتمالی p(x). BINOMDIST () در MS EXCEL 2010 برای سازگاری باقی مانده است.
فایل مثال حاوی نمودارها است چگالی توزیع احتمالو .

توزیع دو جمله ایتعیین را دارد ب(n; پ) .
توجه داشته باشید: برای ساخت تابع توزیع انتگرالنوع نمودار تناسب کامل برنامه، برای چگالی توزیع – هیستوگرام با گروه بندی. برای اطلاعات بیشتر در مورد نمودار ساختمان، مقاله انواع اصلی نمودارها را مطالعه کنید.
توجه داشته باشید: برای راحتی نوشتن فرمول ها در فایل نمونه، نام پارامترها ایجاد شده است توزیع دو جمله ای: n و p.

فایل مثال، محاسبات احتمالات مختلف را با استفاده از توابع MS EXCEL نشان می دهد:
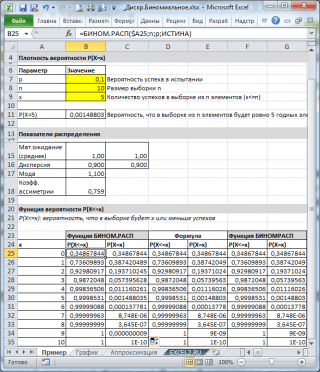
همانطور که در تصویر بالا مشاهده می شود، فرض می شود که:
- جامعه نامتناهی که نمونه از آن ساخته شده است شامل 10٪ (یا 0.1) عناصر خوب (پارامتر) است. پ، آرگومان تابع سوم =BINOM.DIST())
- برای محاسبه این احتمال که در یک نمونه 10 عنصری (پارامتر n، آرگومان دوم تابع) دقیقاً 5 عنصر معتبر وجود خواهد داشت (آگومان اول)، باید فرمول را بنویسید: =BINOM.DIST(5، 10، 0.1، FALSE)
- آخرین، چهارمین عنصر تنظیم شده = FALSE، i.e. مقدار تابع برگردانده می شود چگالی توزیع.
اگر مقدار آرگومان چهارم = TRUE باشد، تابع BINOM.DIST() مقدار را برمی گرداند. تابع توزیع انتگرالیا به سادگی تابع توزیع. در این صورت می توانید احتمال اینکه تعداد اقلام خوب در نمونه از محدوده خاصی مثلاً 2 یا کمتر (شامل 0) باشد را محاسبه کنید.
برای این کار باید فرمول زیر را بنویسید:
= BINOM.DIST(2, 10, 0.1, TRUE)
توجه داشته باشید: برای مقدار غیرصحیح x، . به عنوان مثال، فرمول های زیر همان مقدار را برمی گرداند:
=BINOM.DIST( 2
; ده 0.1; درست است، واقعی)
=BINOM.DIST( 2,9
; ده 0.1; درست است، واقعی)
توجه داشته باشید: در فایل نمونه چگالی احتمالیو تابع توزیعهمچنین با استفاده از تعریف و تابع COMBIN() محاسبه می شود.
شاخص های توزیع
AT فایل نمونه در برگه مثالفرمول هایی برای محاسبه برخی از شاخص های توزیع وجود دارد:
- =n*p;
- (انحراف استاندارد مربع) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
ما فرمول را استخراج می کنیم انتظارات ریاضی توزیع دو جمله ایاستفاده كردن طرح برنولی.
طبق تعریف، یک متغیر تصادفی X در طرح برنولی(متغیر تصادفی برنولی) دارد تابع توزیع:

این توزیع نامیده می شود توزیع برنولی.
توجه داشته باشید: توزیع برنولی- مورد خاص توزیع دو جمله ایبا پارامتر n=1.
بیایید 3 آرایه از 100 عدد با احتمال موفقیت متفاوت تولید کنیم: 0.1; 0.5 و 0.9. برای انجام این کار، در پنجره نسل اعداد تصادفی پارامترهای زیر را برای هر احتمال p تنظیم کنید:

توجه داشته باشید: اگر گزینه را تنظیم کنید پراکندگی تصادفی (دانه تصادفی، سپس می توانید مجموعه تصادفی خاصی از اعداد تولید شده را انتخاب کنید. به عنوان مثال، با تنظیم این گزینه = 25، می توانید مجموعه های یکسانی از اعداد تصادفی را در رایانه های مختلف تولید کنید (البته اگر سایر پارامترهای توزیع یکسان باشند). مقدار گزینه می تواند مقادیر صحیح را از 1 تا 32767 بگیرد. نام گزینه پراکندگی تصادفیمی تواند گیج شود. بهتر است به این صورت ترجمه شود تعداد را با اعداد تصادفی تنظیم کنید.
در نتیجه 3 ستون 100 عددی خواهیم داشت که بر اساس آنها مثلاً می توان احتمال موفقیت را تخمین زد. پطبق فرمول: تعداد موفقیت/100(سانتی متر. برگه فایل نمونه تولید برنولی).

توجه داشته باشید: برای توزیع های برنولیبا p=0.5، می توانید از فرمول =RANDBETWEEN(0;1) استفاده کنید که مربوط به .
تولید اعداد تصادفی توزیع دو جمله ای
فرض کنید 7 مورد معیوب در نمونه وجود دارد. این به این معنی است که "بسیار محتمل" است که نسبت محصولات معیوب تغییر کرده است. پکه از ویژگی های فرآیند تولید ماست. اگرچه این وضعیت "بسیار محتمل" است، اما این احتمال وجود دارد (خطر آلفا، خطای نوع 1، "هشدار نادرست") که پبدون تغییر باقی ماند و افزایش تعداد محصولات معیوب به دلیل نمونه گیری تصادفی بود.
همانطور که در شکل زیر مشاهده می کنید، 7 تعداد محصولات معیوب است که برای فرآیندی با 0.21=p با همان مقدار قابل قبول است. آلفا. این نشان می دهد که وقتی از آستانه اقلام معیوب در یک نمونه فراتر رفت، پ"احتمالا" افزایش یافته است. عبارت "احتمالا" به این معنی است که تنها 10٪ احتمال (100٪ - 90٪) وجود دارد که انحراف درصد محصولات معیوب بالاتر از آستانه فقط به دلایل تصادفی باشد.

بنابراین، فراتر رفتن از آستانه تعداد محصولات معیوب در نمونه ممکن است به عنوان سیگنالی باشد که فرآیند به هم ریخته و شروع به تولید b در بارهدرصد بالاتر محصولات معیوب
توجه داشته باشید: قبل از MS EXCEL 2010، EXCEL یک تابع CRITBINOM() داشت که معادل BINOM.INV() است. CRITBINOM() در MS EXCEL 2010 و بالاتر برای سازگاری باقی مانده است.
رابطه توزیع دو جمله ای با سایر توزیع ها
اگر پارامتر n توزیع دو جمله ایبه بی نهایت تمایل دارد و پبه 0 تمایل دارد، سپس در این مورد توزیع دو جمله ایمی توان تقریب زد.
ممکن است برای فرمول شرایط زمانی که تقریب توزیع پواسونخوب کار می کند:
- پ<0,1 (کمتر پو بیشتر n، هر چه تقریب دقیق تر باشد)
- پ>0,9 (با توجه به اینکه q=1- پ، محاسبات در این مورد باید با استفاده از q(آ ایکسنیاز به تعویض دارد n- ایکس). بنابراین، کمتر qو بیشتر n، هر چه تقریب دقیق تر باشد).
در 0.1<=p<=0,9 и n*p>10 توزیع دو جمله ایمی توان تقریب زد.
در نوبتش، توزیع دو جمله ایزمانی که اندازه جمعیت N باشد می تواند به عنوان یک تقریب خوب عمل کند توزیع فرا هندسیبسیار بزرگتر از اندازه نمونه n (یعنی N>>n یا n/N<<1).
در مورد رابطه توزیع های فوق می توانید در مقاله بیشتر بخوانید. نمونه هایی از تقریب هم در آنجا آورده شده و شرایط در چه زمانی امکان پذیر است و با چه دقتی توضیح داده شده است.
مشاوره: می توانید در مورد سایر توزیع های MS EXCEL در مقاله بخوانید.
