95 कॉन्फिडेंस इंटरवल का क्या मतलब है? विश्वास अंतराल
आइए एमएस में निर्माण करें एक्सेल ट्रस्टमामले में वितरण के औसत मूल्य का अनुमान लगाने के लिए अंतराल ज्ञात मूल्यभिन्नताएँ
बेशक चुनाव विश्वास का स्तरपूरी तरह से समस्या के समाधान पर निर्भर करता है। इस प्रकार, हवाई जहाज की विश्वसनीयता में एक हवाई यात्री के विश्वास की डिग्री निस्संदेह एक विद्युत प्रकाश बल्ब की विश्वसनीयता में खरीदार के विश्वास की डिग्री से अधिक होनी चाहिए।
समस्या सूत्रीकरण
चलिए मान लेते हैं कि से जनसंख्या लिया जा चुका है नमूनाआकार एन. यह मान लिया है कि मानक विचलनयह वितरण ज्ञात है। इसके आधार पर यह जरूरी है नमूनेअज्ञात का मूल्यांकन करें वितरण माध्य(μ, ) और संगत रचना कीजिए दोहरा विश्वास अंतराल.
बिंदु लागत
जैसा कि ज्ञात होता है आंकड़े(आइए इसे निरूपित करें एक्स औसत) है माध्य का निष्पक्ष अनुमानयह जनसंख्याऔर इसका वितरण N(μ;σ 2 /n) है।
टिप्पणी: यदि आपको निर्माण करने की आवश्यकता हो तो क्या करें? विश्वास अंतरालवितरण के मामले में क्या नहीं है सामान्य?इस मामले में, बचाव के लिए आता है, जो बताता है कि पर्याप्त बड़े आकार के साथ नमूने n वितरण से नहीं बनना सामान्य, आँकड़ों का नमूना वितरण X औसतइच्छा लगभगअनुरूप सामान्य वितरणपैरामीटर N(μ;σ 2 /n) के साथ।
इसलिए, बिंदु लागत औसत वितरण मूल्यहमारे पास है - यह नमूना माध्य, अर्थात। एक्स औसत. अब चलिए शुरू करते हैं विश्वास अंतराल।
एक विश्वास अंतराल का निर्माण
आमतौर पर, वितरण और उसके मापदंडों को जानकर, हम इस संभावना की गणना कर सकते हैं कि यादृच्छिक चर हमारे द्वारा निर्दिष्ट अंतराल से एक मान लेगा। अब आइए इसके विपरीत करें: उस अंतराल का पता लगाएं जिसमें से यादृच्छिक चर गिरेगा दी गई संभावना. उदाहरण के लिए, गुणों से सामान्य वितरणयह ज्ञात है कि 95% की संभावना के साथ, एक यादृच्छिक चर वितरित किया जाता है सामान्य कानून , लगभग +/- 2 से की सीमा के भीतर आएगा औसत मूल्य(इसके बारे में लेख देखें)। यह अंतराल हमारे लिए एक प्रोटोटाइप के रूप में काम करेगा विश्वास अंतराल.
अब देखते हैं कि क्या हम वितरण जानते हैं , इस अंतराल की गणना करने के लिए? प्रश्न का उत्तर देने के लिए, हमें वितरण के आकार और उसके मापदंडों को इंगित करना होगा।
वितरण का स्वरूप हम जानते हैं - यह है सामान्य वितरण (उसे याद रखो हम बात कर रहे हैंहे नमूने का वितरण आंकड़े एक्स औसत).
पैरामीटर μ हमारे लिए अज्ञात है (इसे केवल इसका उपयोग करके अनुमान लगाने की आवश्यकता है विश्वास अंतराल), लेकिन हमारे पास इसका एक अनुमान है एक्स औसत,के आधार पर गणना की गई नमूने,जिसका उपयोग किया जा सकता है.
दूसरा पैरामीटर - नमूना माध्य का मानक विचलन हम इसे ज्ञात मानेंगे, यह σ/√n के बराबर है।
क्योंकि हम μ नहीं जानते, तो हम अंतराल +/- 2 बनाएंगे मानक विचलनइससे नहीं औसत मूल्य, और इसके ज्ञात अनुमान से एक्स औसत. वे। गणना करते समय विश्वास अंतरालहम ऐसा नहीं मानेंगे एक्स औसत+/- 2 की सीमा के अंतर्गत आता है मानक विचलन 95% की संभावना के साथ μ से, और हम मान लेंगे कि अंतराल +/- 2 है मानक विचलनसे एक्स औसत 95% संभावना के साथ यह μ को कवर करेगा – सामान्य जनसंख्या का औसत,जिससे यह लिया गया था नमूना. ये दोनों कथन समतुल्य हैं, लेकिन दूसरा कथन हमें निर्माण करने की अनुमति देता है विश्वास अंतराल.
इसके अलावा, आइए अंतराल को स्पष्ट करें: एक यादृच्छिक चर वितरित किया गया सामान्य कानून, 95% संभावना के साथ अंतराल +/- 1.960 के भीतर आता है मानक विचलन,नहीं +/- 2 मानक विचलन. इसकी गणना सूत्र का उपयोग करके की जा सकती है =NORM.ST.REV((1+0.95)/2), सेमी। उदाहरण फ़ाइल शीट अंतराल.

अब हम एक संभाव्य कथन तैयार कर सकते हैं जो हमें बनाने में मदद करेगा विश्वास अंतराल:
"संभावना है कि आबादी मतलबसे स्थित है नमूना औसत 1,960 के भीतर" नमूना माध्य के मानक विचलन", 95% के बराबर"।
कथन में उल्लिखित संभाव्यता मान का एक विशेष नाम है , जिससे सम्बंधित हैएक सरल अभिव्यक्ति द्वारा महत्व स्तर α (अल्फा)। विश्वास स्तर =1 -α . हमारे मामले में महत्वपूर्ण स्तर α =1-0,95=0,05 .
अब, इस संभाव्य कथन के आधार पर, हम गणना के लिए एक अभिव्यक्ति लिखते हैं विश्वास अंतराल:

जहां Z α/2 – मानक सामान्य वितरण(यादृच्छिक चर का यह मान जेड, क्या पी(जेड>=जेड α/2 )=α/2).
टिप्पणी: ऊपरी α/2-मात्राचौड़ाई को परिभाषित करता है विश्वास अंतरालवी मानक विचलन नमूना माध्य। ऊपरी α/2-मात्रा मानक सामान्य वितरणहमेशा 0 से अधिक, जो बहुत सुविधाजनक है।
हमारे मामले में, α=0.05 के साथ, ऊपरी α/2-मात्रा 1.960 के बराबर है। अन्य महत्व स्तरों के लिए α (10%; 1%) ऊपरी α/2-मात्रा जेड α/2 सूत्र =NORM.ST.REV(1-α/2) या, यदि ज्ञात हो, का उपयोग करके गणना की जा सकती है विश्वास स्तर, =NORM.ST.OBR((1+विश्वास स्तर)/2).
आमतौर पर निर्माण करते समय माध्य का अनुमान लगाने के लिए आत्मविश्वास अंतरालकेवल उपयोग ऊपरी α/2-मात्रात्मकऔर उपयोग न करें निचला α/2-मात्रात्मक. ऐसा इसलिए संभव है क्योंकि मानक सामान्य वितरण x अक्ष के बारे में सममित रूप से ( इसका वितरण घनत्वके बारे में सममित औसत, यानी 0). इसलिए गणना करने की कोई जरूरत नहीं है निचला α/2-मात्रा(इसे बस α कहा जाता है /2-मात्रात्मक), क्योंकि यह बराबर है ऊपरी α/2-मात्रात्मकऋण चिह्न के साथ.
आइए हम याद करें कि, मान x के वितरण के आकार के बावजूद, संगत यादृच्छिक चर एक्स औसतवितरित लगभग अच्छा N(μ;σ 2 /n) (इसके बारे में लेख देखें)। इसलिए, में सामान्य मामला, के लिए उपरोक्त अभिव्यक्ति विश्वास अंतरालकेवल एक अनुमान है. यदि मान x को वितरित किया जाता है सामान्य कानून N(μ;σ 2 /n), फिर के लिए अभिव्यक्ति विश्वास अंतरालसही है।
MS EXCEL में कॉन्फिडेंस अंतराल गणना
आइए समस्या का समाधान करें.
इनपुट सिग्नल के लिए इलेक्ट्रॉनिक घटक का प्रतिक्रिया समय डिवाइस की एक महत्वपूर्ण विशेषता है। एक इंजीनियर 95% के आत्मविश्वास स्तर पर औसत प्रतिक्रिया समय के लिए एक विश्वास अंतराल का निर्माण करना चाहता है। पिछले अनुभव से, इंजीनियर जानता है कि प्रतिक्रिया समय का मानक विचलन 8 एमएस है। यह ज्ञात है कि प्रतिक्रिया समय का मूल्यांकन करने के लिए, इंजीनियर ने 25 माप किए, औसत मूल्य 78 एमएस था।
समाधान: एक इंजीनियर किसी इलेक्ट्रॉनिक उपकरण का प्रतिक्रिया समय जानना चाहता है, लेकिन वह समझता है कि प्रतिक्रिया समय एक निश्चित मान नहीं है, बल्कि एक यादृच्छिक चर है जिसका अपना वितरण होता है। इसलिए, वह जो सबसे अच्छी उम्मीद कर सकता है वह इस वितरण के मापदंडों और आकार को निर्धारित करना है।
दुर्भाग्य से, समस्या की स्थिति से हम प्रतिक्रिया समय वितरण के आकार को नहीं जानते हैं (ऐसा होना जरूरी नहीं है)। सामान्य). , यह वितरण भी अज्ञात है। वही तो जाना जाता है मानक विचलनσ=8. इसलिए, जबकि हम संभावनाओं की गणना और निर्माण नहीं कर सकते विश्वास अंतराल.
हालाँकि, इस तथ्य के बावजूद कि हम वितरण को नहीं जानते हैं समय अलग प्रतिक्रिया, हम उसके अनुसार जानते हैं सीपीटी, नमूने का वितरण औसत प्रतिक्रिया समयलगभग है सामान्य(हम मान लेंगे कि शर्तें सीपीटीकिया जाता है, क्योंकि आकार नमूनेकाफी बड़ा (n=25)) .
इसके अतिरिक्त, औसतयह वितरण बराबर है औसत मूल्यएकल प्रतिक्रिया का वितरण, अर्थात μ. ए मानक विचलनइस वितरण की गणना (σ/√n) सूत्र =8/ROOT(25) का उपयोग करके की जा सकती है।
यह भी ज्ञात हुआ कि इंजीनियर को प्राप्त हुआ बिंदु लागतपैरामीटर μ 78 एमएस (एक्स औसत) के बराबर। इसलिए, अब हम संभावनाओं की गणना कर सकते हैं, क्योंकि हम वितरण का स्वरूप जानते हैं ( सामान्य) और इसके पैरामीटर (X avg और σ/√n)।
इंजीनियर जानना चाहता है अपेक्षित मूल्यμ प्रतिक्रिया समय वितरण। जैसा कि ऊपर बताया गया है, यह μ के बराबर है गणितीय अपेक्षाऔसत प्रतिक्रिया समय का नमूना वितरण. अगर हम उपयोग करते हैं सामान्य वितरण N(X avg; σ/√n), तो वांछित μ लगभग 95% की संभावना के साथ +/-2*σ/√n की सीमा में होगा।
महत्वपूर्ण स्तर 1-0.95=0.05 के बराबर है।
अंत में, आइए बाएँ और दाएँ बॉर्डर खोजें विश्वास अंतराल.
बाईं सीमा: =78-NORM.ST.REV(1-0.05/2)*8/रूट(25) =
74,864
दाहिनी सीमा: =78+NORM.ST.INV(1-0.05/2)*8/रूट(25)=81.136
बाईं सीमा: =NORM.REV(0.05/2; 78; 8/रूट(25))
दाहिनी सीमा: =NORM.REV(1-0.05/2; 78; 8/रूट(25))
उत्तर: विश्वास अंतरालपर 95% आत्मविश्वास स्तर और σ=8मिसेके बराबर होती है 78+/-3.136 एमएस.
में सिग्मा शीट पर उदाहरण फ़ाइलज्ञात, गणना और निर्माण के लिए एक प्रपत्र बनाया दोहरा विश्वास अंतरालमनमानी के लिए नमूनेदिए गए σ और के साथ स्तर का महत्व.

कॉन्फिडेंस.नॉर्म() फ़ंक्शन
यदि मान नमूनेके दायरे में हैं बी20:बी79
, ए महत्वपूर्ण स्तर 0.05 के बराबर; फिर MS Excel सूत्र:
=औसत(बी20:बी79)-आत्मविश्वास.मानदंड(0.05;σ; गिनती(बी20:बी79))
बाईं सीमा वापस कर देंगे विश्वास अंतराल.
उसी सीमा की गणना सूत्र का उपयोग करके की जा सकती है:
=औसत(B20:B79)-NORM.ST.REV(1-0.05/2)*σ/रूट(COUNT(B20:B79))
टिप्पणी: CONFIDENCE.NORM() फ़ंक्शन MS EXCEL 2010 में दिखाई दिया। MS EXCEL के पुराने संस्करणों में, TRUST() फ़ंक्शन का उपयोग किया गया था।
लक्ष्य- सांख्यिकीय मापदंडों के आत्मविश्वास अंतराल की गणना के लिए छात्रों को एल्गोरिदम सिखाएं।
डेटा को सांख्यिकीय रूप से संसाधित करते समय, गणना किए गए अंकगणितीय माध्य, भिन्नता के गुणांक, सहसंबंध गुणांक, अंतर मानदंड और अन्य बिंदु आँकड़ों को मात्रात्मक विश्वास सीमाएँ प्राप्त होनी चाहिए, जो विश्वास अंतराल के भीतर छोटी और बड़ी दिशाओं में संकेतक के संभावित उतार-चढ़ाव का संकेत देती हैं।
उदाहरण 3.1
.
बंदरों के रक्त सीरम में कैल्शियम का वितरण, जैसा कि पहले स्थापित किया गया था, निम्नलिखित नमूना संकेतकों द्वारा विशेषता है: = 11.94 मिलीग्राम%;  = 0.127 मिलीग्राम%; एन= 100। सामान्य औसत के लिए विश्वास अंतराल निर्धारित करना आवश्यक है (
= 0.127 मिलीग्राम%; एन= 100। सामान्य औसत के लिए विश्वास अंतराल निर्धारित करना आवश्यक है (  ) पर आत्मविश्वास की संभावनापी
= 0,95.
) पर आत्मविश्वास की संभावनापी
= 0,95.
सामान्य औसत अंतराल में एक निश्चित संभावना के साथ स्थित होता है:
 , कहाँ
, कहाँ  - नमूना अंकगणितीय माध्य; टी- छात्र का परीक्षण;
- नमूना अंकगणितीय माध्य; टी- छात्र का परीक्षण;  – अंकगणित माध्य की त्रुटि.
– अंकगणित माध्य की त्रुटि.
तालिका "छात्र के टी-परीक्षण मान" का उपयोग करके हम मान ज्ञात करते हैं
 0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ क= 100-1 = 99. यह 1.982 के बराबर है। अंकगणित माध्य और सांख्यिकीय त्रुटि के मूल्यों के साथ, हम इसे सूत्र में प्रतिस्थापित करते हैं:
0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ क= 100-1 = 99. यह 1.982 के बराबर है। अंकगणित माध्य और सांख्यिकीय त्रुटि के मूल्यों के साथ, हम इसे सूत्र में प्रतिस्थापित करते हैं:
या 11.69  12,19
12,19
इस प्रकार, 95% की संभावना के साथ, यह कहा जा सकता है कि इस सामान्य वितरण का सामान्य औसत 11.69 और 12.19 मिलीग्राम% के बीच है।
उदाहरण 3.2
. सामान्य विचरण के लिए 95% विश्वास अंतराल की सीमाएं निर्धारित करें (  ) बंदरों के रक्त में कैल्शियम का वितरण, यदि यह ज्ञात हो
) बंदरों के रक्त में कैल्शियम का वितरण, यदि यह ज्ञात हो  = 1.60, पर एन
= 100.
= 1.60, पर एन
= 100.
समस्या को हल करने के लिए आप निम्न सूत्र का उपयोग कर सकते हैं:
कहाँ  - फैलाव की सांख्यिकीय त्रुटि.
- फैलाव की सांख्यिकीय त्रुटि.
हम सूत्र का उपयोग करके नमूना विचरण त्रुटि पाते हैं:  . यह 0.11 के बराबर है. अर्थ टी- 0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ मानदंड क= 100-1 = 99 पिछले उदाहरण से ज्ञात होता है।
. यह 0.11 के बराबर है. अर्थ टी- 0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ मानदंड क= 100-1 = 99 पिछले उदाहरण से ज्ञात होता है।
आइए सूत्र का उपयोग करें और प्राप्त करें:
या 1.38  1,82
1,82
अधिक सटीक रूप से, सामान्य विचरण के विश्वास अंतराल का उपयोग करके निर्माण किया जा सकता है  (ची-स्क्वायर) - पियर्सन परीक्षण। इस मानदंड के लिए महत्वपूर्ण बिंदु एक विशेष तालिका में दिए गए हैं। मानदंड का उपयोग करते समय
(ची-स्क्वायर) - पियर्सन परीक्षण। इस मानदंड के लिए महत्वपूर्ण बिंदु एक विशेष तालिका में दिए गए हैं। मानदंड का उपयोग करते समय  आत्मविश्वास अंतराल के निर्माण के लिए, दो-तरफा महत्व स्तर का उपयोग किया जाता है। निचली सीमा के लिए, महत्व स्तर की गणना सूत्र का उपयोग करके की जाती है
आत्मविश्वास अंतराल के निर्माण के लिए, दो-तरफा महत्व स्तर का उपयोग किया जाता है। निचली सीमा के लिए, महत्व स्तर की गणना सूत्र का उपयोग करके की जाती है  , शीर्ष के लिए -
, शीर्ष के लिए -  . उदाहरण के लिए, आत्मविश्वास के स्तर के लिए
. उदाहरण के लिए, आत्मविश्वास के स्तर के लिए  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. तदनुसार, महत्वपूर्ण मूल्यों के वितरण की तालिका के अनुसार
= 0.990. तदनुसार, महत्वपूर्ण मूल्यों के वितरण की तालिका के अनुसार  , गणना किए गए आत्मविश्वास के स्तर और स्वतंत्रता की डिग्री की संख्या के साथ क= 100 – 1= 99, मान ज्ञात कीजिए
, गणना किए गए आत्मविश्वास के स्तर और स्वतंत्रता की डिग्री की संख्या के साथ क= 100 – 1= 99, मान ज्ञात कीजिए  और
और  . हम पाते हैं
. हम पाते हैं  135.80 के बराबर है, और
135.80 के बराबर है, और  70.06 के बराबर है.
70.06 के बराबर है.
सामान्य विचरण के लिए विश्वास सीमा का उपयोग करना  आइए सूत्रों का उपयोग करें: निचली सीमा के लिए
आइए सूत्रों का उपयोग करें: निचली सीमा के लिए  , ऊपरी सीमा के लिए
, ऊपरी सीमा के लिए  . आइए समस्या डेटा के लिए पाए गए मानों को प्रतिस्थापित करें
. आइए समस्या डेटा के लिए पाए गए मानों को प्रतिस्थापित करें  सूत्रों में:
सूत्रों में:  =
1,17;
=
1,17; = 2.26. इस प्रकार, आत्मविश्वास की संभावना के साथ पी= 0.99 या 99% सामान्य विचरण 1.17 से 2.26 मिलीग्राम% समावेशी सीमा में होगा।
= 2.26. इस प्रकार, आत्मविश्वास की संभावना के साथ पी= 0.99 या 99% सामान्य विचरण 1.17 से 2.26 मिलीग्राम% समावेशी सीमा में होगा।
उदाहरण 3.3 . लिफ्ट में प्राप्त बैच के 1000 गेहूं के बीजों में से 120 बीज एर्गोट से संक्रमित पाए गए। गेहूं के दिए गए बैच में संक्रमित बीजों के सामान्य अनुपात की संभावित सीमाओं को निर्धारित करना आवश्यक है।
सूत्र का उपयोग करके इसके सभी संभावित मूल्यों के लिए सामान्य शेयर की विश्वास सीमा निर्धारित करना उचित है:
 ,
,
कहाँ एन - अवलोकनों की संख्या; एम- समूहों में से एक का पूर्ण आकार; टी- सामान्यीकृत विचलन.
संक्रमित बीजों का नमूना अनुपात है  या 12%. आत्मविश्वास की संभावना के साथ आर= 95% सामान्यीकृत विचलन ( टी-छात्र का परीक्षण क
=
या 12%. आत्मविश्वास की संभावना के साथ आर= 95% सामान्यीकृत विचलन ( टी-छात्र का परीक्षण क
=
 )टी
= 1,960.
)टी
= 1,960.
हम उपलब्ध डेटा को सूत्र में प्रतिस्थापित करते हैं:
अत: विश्वास अंतराल की सीमाएँ बराबर हैं  = 0.122–0.041 = 0.081, या 8.1%;
= 0.122–0.041 = 0.081, या 8.1%;  = 0.122 + 0.041 = 0.163, या 16.3%।
= 0.122 + 0.041 = 0.163, या 16.3%।
इस प्रकार, 95% की विश्वास संभावना के साथ यह कहा जा सकता है कि संक्रमित बीजों का सामान्य अनुपात 8.1 और 16.3% के बीच है।
उदाहरण 3.4 . बंदरों के रक्त सीरम में कैल्शियम (मिलीग्राम%) की भिन्नता को दर्शाने वाला भिन्नता गुणांक 10.6% के बराबर था। नमूने का आकार एन= 100. सामान्य पैरामीटर के लिए 95% विश्वास अंतराल की सीमाओं को निर्धारित करना आवश्यक है सीवी.
भिन्नता के सामान्य गुणांक के लिए विश्वास अंतराल की सीमाएँ सीवी निम्नलिखित सूत्रों द्वारा निर्धारित किए जाते हैं:
 और
और  , कहाँ क
मध्यवर्ती मूल्य की गणना सूत्र द्वारा की जाती है
, कहाँ क
मध्यवर्ती मूल्य की गणना सूत्र द्वारा की जाती है  .
.
यह जानने की संभावना निश्चित रूप से है आर= 95% सामान्यीकृत विचलन (छात्र का परीक्षण)। क
=
 )टी
= 1.960, आइए पहले मान की गणना करें को:
)टी
= 1.960, आइए पहले मान की गणना करें को:
 .
.
 या 9.3%
या 9.3%
 या 12.3%
या 12.3%
इस प्रकार, 95% आत्मविश्वास स्तर के साथ भिन्नता का सामान्य गुणांक 9.3 से 12.3% की सीमा में है। बार-बार नमूनों के साथ, भिन्नता का गुणांक 12.3% से अधिक नहीं होगा और 100 में से 95 मामलों में 9.3% से कम नहीं होगा।
आत्म-नियंत्रण के लिए प्रश्न:

स्वतंत्र समाधान के लिए समस्याएँ.
1. खोल्मोगोरी संकर गायों के स्तनपान के दौरान दूध में वसा का औसत प्रतिशत इस प्रकार था: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. 95% आत्मविश्वास स्तर (20 अंक) पर सामान्य माध्य के लिए विश्वास अंतराल स्थापित करें।
2. 400 संकर राई पौधों पर, पहला फूल बुआई के औसतन 70.5 दिन बाद दिखाई दिया। मानक विचलन 6.9 दिन था। महत्व स्तर पर सामान्य माध्य और विचरण के लिए माध्य और विश्वास अंतराल की त्रुटि निर्धारित करें डब्ल्यू= 0.05 और डब्ल्यू= 0.01 (25 अंक).
3. उद्यान स्ट्रॉबेरी के 502 नमूनों की पत्तियों की लंबाई का अध्ययन करते समय, निम्नलिखित डेटा प्राप्त हुए:
 = 7.86 सेमी; σ = 1.32 सेमी,
= 7.86 सेमी; σ = 1.32 सेमी, 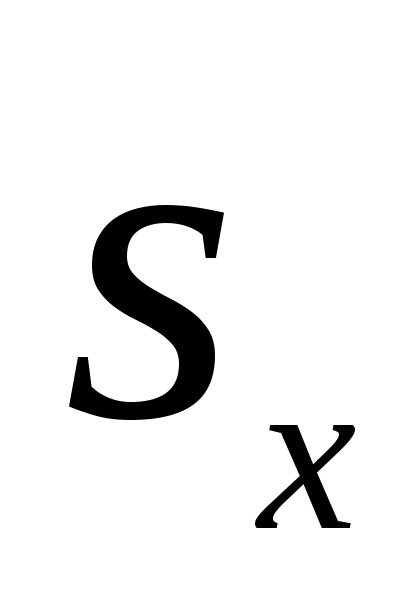 =± 0.06 सेमी. 0.01 के महत्व स्तर के साथ अंकगणितीय जनसंख्या माध्य के लिए आत्मविश्वास अंतराल निर्धारित करें; 0.02; 0.05. (25 अंक).
=± 0.06 सेमी. 0.01 के महत्व स्तर के साथ अंकगणितीय जनसंख्या माध्य के लिए आत्मविश्वास अंतराल निर्धारित करें; 0.02; 0.05. (25 अंक).
4. 150 वयस्क पुरुषों के एक अध्ययन में, औसत ऊंचाई 167 सेमी थी, और σ = 6 सेमी. 0.99 और 0.95 की आत्मविश्वास संभावना के साथ सामान्य माध्य और सामान्य विचरण की सीमाएँ क्या हैं? (25 अंक).
5. बंदरों के रक्त सीरम में कैल्शियम का वितरण निम्नलिखित चयनात्मक संकेतकों द्वारा विशेषता है:
 = 11.94 मिलीग्राम%, σ
= 1,27, एन
= 100. इस वितरण के सामान्य माध्य के लिए 95% विश्वास अंतराल का निर्माण करें। भिन्नता के गुणांक (25 अंक) की गणना करें।
= 11.94 मिलीग्राम%, σ
= 1,27, एन
= 100. इस वितरण के सामान्य माध्य के लिए 95% विश्वास अंतराल का निर्माण करें। भिन्नता के गुणांक (25 अंक) की गणना करें।
6. 37 और 180 दिन की उम्र के अल्बिनो चूहों के रक्त प्लाज्मा में कुल नाइट्रोजन सामग्री का अध्ययन किया गया। परिणाम प्लाज्मा के प्रति 100 सेमी 3 ग्राम में व्यक्त किए जाते हैं। 37 दिन की उम्र में, 9 चूहों में: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. 180 दिन की उम्र में, 8 चूहों में: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. 0.95 (50 अंक) के आत्मविश्वास स्तर पर अंतर के लिए आत्मविश्वास अंतराल निर्धारित करें।
7. बंदरों के रक्त सीरम में कैल्शियम (मिलीग्राम%) के वितरण के सामान्य विचरण के लिए 95% विश्वास अंतराल की सीमाएँ निर्धारित करें, यदि इस वितरण के लिए नमूना आकार n = 100 है, तो नमूना विचरण की सांख्यिकीय त्रुटि एस σ 2 = 1.60 (40 अंक).
8. लंबाई (σ 2 = 40.87 मिमी 2) के साथ 40 गेहूं स्पाइकलेट के वितरण के सामान्य भिन्नता के लिए 95% विश्वास अंतराल की सीमाएं निर्धारित करें। (25 अंक).
9. धूम्रपान को प्रतिरोधी फुफ्फुसीय रोगों का मुख्य कारण माना जाता है। निष्क्रिय धूम्रपान को ऐसा कारक नहीं माना जाता है। वैज्ञानिकों ने निष्क्रिय धूम्रपान की हानिरहितता पर संदेह किया और धूम्रपान न करने वालों, निष्क्रिय और सक्रिय धूम्रपान करने वालों के वायुमार्ग की धैर्य की जांच की। श्वसन पथ की स्थिति को चिह्नित करने के लिए, हमने बाहरी श्वसन समारोह के संकेतकों में से एक लिया - मध्य-निकास की अधिकतम वॉल्यूमेट्रिक प्रवाह दर। इस सूचक में कमी वायुमार्ग में रुकावट का संकेत है। सर्वेक्षण डेटा तालिका में दिखाया गया है।
|
जांच किये गये लोगों की संख्या |
अधिकतम मध्य-निःश्वसन प्रवाह दर, एल/एस |
||
|
मानक विचलन |
|||
|
धूम्रपान न करने वालों |
|||
|
धूम्रपान रहित क्षेत्र में काम करें | |||
|
धुएँ से भरे कमरे में काम करना | |||
|
धूम्रपान |
|||
|
धूम्रपान करने वाले ऐसा नहीं करते बड़ी संख्यासिगरेट | |||
|
सिगरेट पीने वालों की औसत संख्या | |||
|
बड़ी संख्या में सिगरेट पीना | |||
तालिका डेटा का उपयोग करके, प्रत्येक समूह के लिए समग्र माध्य और समग्र भिन्नता के लिए 95% विश्वास अंतराल खोजें। समूहों के बीच क्या अंतर हैं? परिणामों को ग्राफ़िक रूप से प्रस्तुत करें (25 अंक)।
10. यदि नमूना विचरण की सांख्यिकीय त्रुटि है, तो 64 खेतों में पिगलेट की संख्या में सामान्य भिन्नता के लिए 95% और 99% विश्वास अंतराल की सीमाएं निर्धारित करें एस σ 2 = 8.25 (30 अंक).
11. यह ज्ञात है कि खरगोशों का औसत वजन 2.1 किलोग्राम होता है। सामान्य माध्य और विचरण के लिए 95% और 99% विश्वास अंतराल की सीमाएं निर्धारित करें एन= 30, σ = 0.56 किग्रा (25 अंक)।
12. बालियों में दाने की मात्रा 100 बालियों के लिए मापी गई ( एक्स), कान की लंबाई ( वाई) और कान में अनाज का द्रव्यमान ( जेड). सामान्य माध्य और विचरण के लिए विश्वास अंतराल खोजें पी 1
= 0,95, पी 2
= 0,99, पी 3
= 0.999 यदि
 = 19, = 6.766 सेमी, = 0.554 ग्राम; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 अंक)।
= 19, = 6.766 सेमी, = 0.554 ग्राम; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 अंक)।
13. शीतकालीन गेहूं की 100 बेतरतीब ढंग से चुनी गई बालियों में स्पाइकलेट्स की संख्या की गणना की गई। नमूना जनसंख्या को निम्नलिखित संकेतकों द्वारा चित्रित किया गया था:
 = 15 स्पाइकलेट और σ = 2.28 पीसी। निर्धारित करें कि औसत परिणाम किस सटीकता से प्राप्त किया गया था (
= 15 स्पाइकलेट और σ = 2.28 पीसी। निर्धारित करें कि औसत परिणाम किस सटीकता से प्राप्त किया गया था (  ) और 95% और 99% महत्व स्तरों (30 अंक) पर सामान्य माध्य और विचरण के लिए एक विश्वास अंतराल का निर्माण करें।
) और 95% और 99% महत्व स्तरों (30 अंक) पर सामान्य माध्य और विचरण के लिए एक विश्वास अंतराल का निर्माण करें।
14. जीवाश्म मोलस्क के गोले पर पसलियों की संख्या ऑर्थम्बोनाइट्स सुलेख:
ह ज्ञात है कि एन = 19, σ = 4.25. महत्व स्तर पर सामान्य माध्य और सामान्य विचरण के लिए विश्वास अंतराल की सीमाएं निर्धारित करें डब्ल्यू = 0.01 (25 अंक).
15. एक व्यावसायिक डेयरी फार्म पर दूध की उपज निर्धारित करने के लिए प्रतिदिन 15 गायों की उत्पादकता निर्धारित की जाती थी। वर्ष के आंकड़ों के अनुसार, प्रत्येक गाय औसतन प्रति दिन निम्नलिखित मात्रा में दूध देती है (एल): 22; 19; 25; 20; 27; 17; तीस; 21; 18; 24; 26; 23; 25; 20; 24. सामान्य विचरण और अंकगणितीय माध्य के लिए विश्वास अंतराल का निर्माण करें। क्या हम उम्मीद कर सकते हैं कि प्रति गाय औसत वार्षिक दूध उपज 10,000 लीटर होगी? (50 अंक).
16. कृषि उद्यम के लिए औसत गेहूं की उपज निर्धारित करने के लिए, 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 और 2 हेक्टेयर के परीक्षण भूखंडों पर कटाई की गई। भूखंडों से उत्पादकता (सी/हेक्टेयर) 39.4 थी; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; क्रमशः 29. सामान्य विचरण और अंकगणितीय माध्य के लिए विश्वास अंतराल का निर्माण करें। क्या हम उम्मीद कर सकते हैं कि औसत कृषि उपज 42 सी/हेक्टेयर होगी? (50 अंक).
मान लीजिए कि हमारे पास कुछ विशेषताओं के सामान्य वितरण के साथ बड़ी संख्या में वस्तुएं हैं (उदाहरण के लिए, एक ही प्रकार की सब्जियों का एक पूरा गोदाम, जिसका आकार और वजन भिन्न होता है)। आप माल के पूरे बैच की औसत विशेषताएँ जानना चाहते हैं, लेकिन आपके पास प्रत्येक सब्जी को मापने और तौलने का न तो समय है और न ही इच्छा। आप समझते हैं कि यह आवश्यक नहीं है. लेकिन मौके पर जांच के लिए कितने टुकड़े ले जाने होंगे?
इस स्थिति के लिए उपयोगी कई सूत्र देने से पहले, आइए कुछ संकेतन को याद करें।
सबसे पहले, अगर हमने सब्जियों के पूरे गोदाम को माप लिया (तत्वों के इस सेट को सामान्य आबादी कहा जाता है), तो हमें पूरे बैच का औसत वजन हमारे लिए उपलब्ध सभी सटीकता के साथ पता चल जाएगा। चलिए इसे औसत कहते हैं एक्स औसत .जी एन . - सामान्य औसत। हम पहले से ही जानते हैं कि यदि इसका माध्य मान और विचलन ज्ञात हो तो क्या पूरी तरह से निर्धारित होता है . सच है, जबकि हम न तो एक्स औसत पीढ़ी हैं और न हीएस हम आम जनता को नहीं जानते. हम केवल एक निश्चित नमूना ले सकते हैं, हमारे लिए आवश्यक मानों को माप सकते हैं और इस नमूने के लिए औसत मान X औसत और मानक विचलन S दोनों की गणना कर सकते हैं।
यह ज्ञात है कि यदि हमारे नमूना जांच में बड़ी संख्या में तत्व होते हैं (आमतौर पर n 30 से अधिक होता है), और उन्हें लिया जाता है वास्तव में यादृच्छिक, फिर एस सामान्य जनसंख्या एस चयन से शायद ही भिन्न होगी..
इसके अलावा, सामान्य वितरण के मामले में हम निम्नलिखित सूत्रों का उपयोग कर सकते हैं:
95% की संभावना के साथ
99% की संभावना के साथ
![]()
में सामान्य रूप से देखेंसंभाव्यता पी (टी) के साथ
टी मान और संभाव्यता मान पी (टी) के बीच संबंध, जिसके साथ हम विश्वास अंतराल जानना चाहते हैं, निम्न तालिका से लिया जा सकता है:
इस प्रकार, हमने यह निर्धारित कर लिया है कि जनसंख्या का औसत मूल्य किस श्रेणी में है (दी गई संभावना के साथ)।
जब तक हमारे पास पर्याप्त बड़ा नमूना न हो, हम यह नहीं कह सकते कि जनसंख्या में s = है एस चयन करें इसके अलावा, इस मामले में नमूने की सामान्य वितरण से निकटता समस्याग्रस्त है। इस मामले में, हम इसके बजाय S सेलेक्ट का भी उपयोग करते हैंसूत्र में है:

लेकिन एक निश्चित संभावना P(t) के लिए t का मान नमूना n में तत्वों की संख्या पर निर्भर करेगा। n जितना बड़ा होगा, परिणामी विश्वास अंतराल सूत्र (1) द्वारा दिए गए मान के उतना ही करीब होगा। इस मामले में t मान किसी अन्य तालिका से लिया गया है ( विद्यार्थी का टी-टेस्ट), जिसे हम नीचे प्रस्तुत कर रहे हैं:
संभाव्यता 0.95 और 0.99 के लिए विद्यार्थी का टी-परीक्षण मान

उदाहरण 3.कंपनी के कर्मचारियों में से 30 लोगों को यादृच्छिक रूप से चुना गया। नमूने के अनुसार, यह पता चला कि औसत वेतन (प्रति माह) औसतन 30 हजार रूबल है वर्ग विचलन 5 हजार रूबल. प्रायिकता 0.99 के साथ निर्धारित करें औसत वेतनकंपनी में।
समाधान:शर्त के अनुसार हमारे पास n = 30, X औसत है। =30000, एस=5000, पी = 0.99. आत्मविश्वास अंतराल खोजने के लिए, हम छात्र के टी परीक्षण के अनुरूप सूत्र का उपयोग करेंगे। n = 30 और P = 0.99 की तालिका से हम t = 2.756 पाते हैं, इसलिए,
वे। वांछित ट्रस्टीअंतराल 27484< Х ср.ген
< 32516.
तो, 0.99 की संभावना के साथ हम कह सकते हैं कि अंतराल (27484; 32516) में कंपनी में औसत वेतन शामिल है।
हम आशा करते हैं कि आप इस विधि का उपयोग करेंगे और यह आवश्यक नहीं है कि हर बार आपके पास एक टेबल हो। एक्सेल में गणनाएँ स्वचालित रूप से की जा सकती हैं। एक्सेल फ़ाइल में रहते हुए, शीर्ष मेनू में एफएक्स बटन पर क्लिक करें। फिर, फ़ंक्शंस के बीच "सांख्यिकीय" प्रकार का चयन करें, और विंडो में प्रस्तावित सूची से - स्टूडेंट डिस्कवर। फिर, प्रॉम्प्ट पर, कर्सर को "संभावना" फ़ील्ड में रखकर, उलटा संभावना का मान दर्ज करें (यानी हमारे मामले में, 0.95 की संभावना के बजाय, आपको 0.05 की संभावना टाइप करने की आवश्यकता है)। जाहिरा तौर पर, स्प्रेडशीट इस तरह से डिज़ाइन की गई है कि परिणाम इस सवाल का जवाब देता है कि हमारे गलत होने की कितनी संभावना है। इसी प्रकार, स्वतंत्रता की डिग्री फ़ील्ड में, अपने नमूने के लिए एक मान (n-1) दर्ज करें।
आवृत्तियों और भिन्नों के लिए विश्वास अंतराल
© 2008
राष्ट्रीय सार्वजनिक स्वास्थ्य संस्थान, ओस्लो, नॉर्वे
लेख में वाल्ड, विल्सन, क्लॉपर - पियर्सन विधियों का उपयोग करके, कोणीय परिवर्तन का उपयोग करके और एग्रेस्टी - कूल सुधार के साथ वाल्ड विधि का उपयोग करके आवृत्तियों और अनुपातों के लिए आत्मविश्वास अंतराल की गणना का वर्णन और चर्चा की गई है। प्रस्तुत सामग्री देती है सामान्य जानकारीआवृत्तियों और अनुपातों के लिए आत्मविश्वास अंतराल की गणना करने के तरीकों के बारे में और इसका उद्देश्य जर्नल पाठकों में न केवल अपने स्वयं के शोध के परिणामों को प्रस्तुत करते समय आत्मविश्वास अंतराल का उपयोग करने में रुचि जगाना है, बल्कि भविष्य के प्रकाशनों पर काम शुरू करने से पहले विशेष साहित्य पढ़ने में भी रुचि जगाना है।
कीवर्ड : आत्मविश्वास अंतराल, आवृत्ति, अनुपात
पिछले प्रकाशन में गुणात्मक डेटा के विवरण का संक्षेप में उल्लेख किया गया था और बताया गया था कि यह अंतराल अनुमानजनसंख्या में अध्ययन की जा रही विशेषता की घटना की आवृत्ति का वर्णन करने के लिए एक बिंदु से बेहतर है। दरअसल, चूंकि अनुसंधान नमूना डेटा का उपयोग करके आयोजित किया जाता है, इसलिए जनसंख्या पर परिणामों के प्रक्षेपण में नमूनाकरण अशुद्धता का एक तत्व शामिल होना चाहिए। कॉन्फिडेंस इंटरवल अनुमानित पैरामीटर की सटीकता का एक माप है। यह दिलचस्प है कि डॉक्टरों के लिए बुनियादी आंकड़ों पर कुछ किताबें आवृत्तियों के लिए विश्वास अंतराल के विषय को पूरी तरह से नजरअंदाज कर देती हैं। इस लेख में हम आवृत्तियों के लिए आत्मविश्वास अंतराल की गणना करने के कई तरीकों पर गौर करेंगे, जिसमें गैर-दोहराव और प्रतिनिधित्वशीलता जैसी नमूना विशेषताओं के साथ-साथ एक दूसरे से टिप्पणियों की स्वतंत्रता भी शामिल होगी। इस लेख में आवृत्ति का मतलब नहीं है पूर्ण संख्या, यह दर्शाता है कि समुच्चय में कोई विशेष मान कितनी बार आता है, और सापेक्ष मान, जो अध्ययन प्रतिभागियों के अनुपात को निर्धारित करता है जिनमें अध्ययन की गई विशेषता होती है।
बायोमेडिकल अनुसंधान में, 95% आत्मविश्वास अंतराल का सबसे अधिक उपयोग किया जाता है। यह विश्वास अंतराल वह क्षेत्र है जिसके भीतर 95% समय वास्तविक अनुपात गिरता है। दूसरे शब्दों में, हम 95% विश्वसनीयता के साथ कह सकते हैं कि जनसंख्या में किसी लक्षण के घटित होने की आवृत्ति का सही मूल्य 95% विश्वास अंतराल के भीतर होगा।
चिकित्सा शोधकर्ताओं के लिए अधिकांश सांख्यिकी मैनुअल रिपोर्ट करते हैं कि आवृत्ति त्रुटि की गणना सूत्र का उपयोग करके की जाती है
जहाँ p नमूने में विशेषता के घटित होने की आवृत्ति है (मान 0 से 1 तक)। अधिकांश घरेलू में वैज्ञानिक लेखनमूने (पी) में विशेषता की घटना की आवृत्ति को दर्शाया गया है, साथ ही इसकी त्रुटि को पी ± एस के रूप में दर्शाया गया है। हालाँकि, जनसंख्या में किसी विशेषता की घटना की आवृत्ति के लिए 95% विश्वास अंतराल प्रस्तुत करना अधिक उपयुक्त है, जिसमें मान शामिल होंगे
 |
 पहले।
पहले।
कुछ मैनुअल अनुशंसा करते हैं कि छोटे नमूनों के लिए, एन - 1 डिग्री की स्वतंत्रता के लिए 1.96 के मान को टी के मान से बदलें, जहां एन नमूने में अवलोकनों की संख्या है। टी मान टी-वितरण के लिए तालिकाओं से पाया जाता है, जो लगभग सभी सांख्यिकी पाठ्यपुस्तकों में उपलब्ध है। वाल्ड विधि के लिए टी वितरण का उपयोग नीचे चर्चा की गई अन्य विधियों की तुलना में दृश्यमान लाभ प्रदान नहीं करता है, और इसलिए कुछ लेखकों द्वारा इसकी अनुशंसा नहीं की जाती है।
आवृत्तियों या अनुपातों के लिए विश्वास अंतराल की गणना के लिए ऊपर प्रस्तुत विधि को अब्राहम वाल्ड (1902-1950) के सम्मान में वाल्ड नाम दिया गया है, क्योंकि इसका व्यापक उपयोग 1939 में वाल्ड और वोल्फोविट्ज़ के प्रकाशन के बाद शुरू हुआ था। हालाँकि, यह विधि स्वयं पियरे साइमन लाप्लास (1749-1827) द्वारा 1812 में प्रस्तावित की गई थी।
वाल्ड विधि बहुत लोकप्रिय है, लेकिन इसका अनुप्रयोग महत्वपूर्ण समस्याओं से जुड़ा है। यह विधि छोटे नमूना आकारों के लिए अनुशंसित नहीं है, साथ ही ऐसे मामलों में जहां किसी विशेषता की घटना की आवृत्ति 0 या 1 (0% या 100%) हो जाती है और 0 और 1 की आवृत्तियों के लिए यह असंभव है। इसके अलावा, सामान्य वितरण का सन्निकटन, जिसका उपयोग त्रुटि की गणना करते समय किया जाता है, उन मामलों में "काम नहीं करता" जहां n·p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
चूंकि नया वेरिएबल सामान्य रूप से वितरित किया जाता है, वेरिएबल φ के लिए 95% विश्वास अंतराल की निचली और ऊपरी सीमाएं φ-1.96 और φ+1.96left"> होंगी


छोटे नमूनों के लिए 1.96 के बजाय, स्वतंत्रता की एन-1 डिग्री के लिए टी मान को प्रतिस्थापित करने की सिफारिश की जाती है। यह विधिनहीं देता नकारात्मक मानऔर वाल्ड विधि की तुलना में आवृत्तियों के लिए विश्वास अंतराल के अधिक सटीक अनुमान की अनुमति देता है। इसके अलावा, इसका वर्णन कई घरेलू संदर्भ पुस्तकों में भी किया गया है चिकित्सा आँकड़ेहालाँकि, इससे चिकित्सा अनुसंधान में इसका व्यापक उपयोग नहीं हुआ। कोणीय परिवर्तन का उपयोग करके आत्मविश्वास अंतराल की गणना 0 या 1 के करीब आने वाली आवृत्तियों के लिए अनुशंसित नहीं है।
यह वह जगह है जहां चिकित्सा शोधकर्ताओं के लिए सांख्यिकी की मूल बातें पर अधिकांश पुस्तकों में आत्मविश्वास अंतराल का आकलन करने के तरीकों का वर्णन आमतौर पर समाप्त होता है, और यह समस्या न केवल घरेलू के लिए, बल्कि इसके लिए भी विशिष्ट है। विदेशी साहित्य. दोनों विधियाँ केंद्रीय सीमा प्रमेय पर आधारित हैं, जिसका तात्पर्य एक बड़े नमूने से है।
उपरोक्त विधियों का उपयोग करके आत्मविश्वास अंतराल का अनुमान लगाने की कमियों को ध्यान में रखते हुए, क्लॉपर और पियर्सन ने 1934 में तथाकथित सटीक आत्मविश्वास अंतराल की गणना के लिए एक विधि प्रस्तावित की, जिसे ध्यान में रखते हुए द्विपद वितरणजिस विशेषता का अध्ययन किया जा रहा है। यह विधि कई ऑनलाइन कैलकुलेटर में उपलब्ध है, लेकिन इस तरह से प्राप्त विश्वास अंतराल ज्यादातर मामलों में बहुत व्यापक है। साथ ही, इस पद्धति को उन मामलों में उपयोग के लिए अनुशंसित किया जाता है जहां रूढ़िवादी मूल्यांकन आवश्यक है। जैसे-जैसे नमूना आकार घटता जाता है, विधि की रूढ़िवादिता की डिग्री बढ़ती जाती है, विशेषकर जब एन< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
कई सांख्यिकीविदों के अनुसार, आवृत्तियों के लिए आत्मविश्वास अंतराल का सबसे इष्टतम मूल्यांकन विल्सन विधि द्वारा किया जाता है, जिसे 1927 में प्रस्तावित किया गया था, लेकिन व्यावहारिक रूप से घरेलू बायोमेडिकल अनुसंधान में इसका उपयोग नहीं किया जाता है। यह विधि न केवल बहुत छोटी और बहुत बड़ी दोनों आवृत्तियों के लिए विश्वास अंतराल का अनुमान लगाने की अनुमति देती है, बल्कि कम संख्या में अवलोकनों के लिए भी लागू होती है। सामान्य तौर पर, विल्सन के सूत्र के अनुसार आत्मविश्वास अंतराल का रूप होता है
 |
 |
जहां 95% विश्वास अंतराल की गणना करते समय 1.96 मान लिया जाता है, एन अवलोकनों की संख्या है, और पी नमूने में विशेषता की घटना की आवृत्ति है। यह विधि ऑनलाइन कैलकुलेटर में उपलब्ध है, इसलिए इसका उपयोग समस्याग्रस्त नहीं है। और एन पी के लिए इस पद्धति का उपयोग करने की अनुशंसा नहीं करते हैं< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
विल्सन विधि के अलावा, एग्रेस्टी-कोल सुधार के साथ वाल्ड विधि भी आवृत्तियों के लिए विश्वास अंतराल का एक इष्टतम अनुमान प्रदान करने वाली मानी जाती है। एग्रेस्टी-कोल सुधार एक नमूने (पी) में एक विशेषता की घटना की आवृत्ति के वाल्ड सूत्र में पी` द्वारा प्रतिस्थापन है, जिसकी गणना करते समय अंश में 2 जोड़ा जाता है और हर में 4 जोड़ा जाता है, अर्थात, पी` = (एक्स + 2) / (एन + 4), जहां एक्स अध्ययन प्रतिभागियों की संख्या है जिनके पास अध्ययन की जा रही विशेषता है, और एन नमूना आकार है। यह संशोधन विल्सन के फार्मूले के समान परिणाम उत्पन्न करता है, सिवाय इसके कि जब घटना की आवृत्ति 0% या 100% तक पहुंचती है और नमूना छोटा होता है। आवृत्तियों के लिए विश्वास अंतराल की गणना के लिए उपरोक्त तरीकों के अलावा, छोटे नमूनों के लिए वाल्ड और विल्सन दोनों तरीकों के लिए निरंतरता सुधार प्रस्तावित किए गए हैं, लेकिन अध्ययनों से पता चला है कि उनका उपयोग अनुचित है।
आइए दो उदाहरणों का उपयोग करके आत्मविश्वास अंतराल की गणना के लिए उपरोक्त विधियों के अनुप्रयोग पर विचार करें। पहले मामले में, हम 1,000 बेतरतीब ढंग से चुने गए अध्ययन प्रतिभागियों के एक बड़े नमूने का अध्ययन करते हैं, जिनमें से 450 में अध्ययन के तहत विशेषता है (यह एक जोखिम कारक, परिणाम या कोई अन्य विशेषता हो सकती है), जो 0.45 या 45 की आवृत्ति का प्रतिनिधित्व करती है। %. दूसरे मामले में, अध्ययन एक छोटे नमूने का उपयोग करके किया जाता है, मान लीजिए, केवल 20 लोग, और केवल 1 अध्ययन प्रतिभागी (5%) के पास अध्ययन किया जा रहा गुण है। विश्वास अंतरालवाल्ड विधि के अनुसार, एग्रेस्टी-कोल सुधार के साथ वाल्ड विधि के अनुसार, विल्सन विधि के अनुसार जेफ सोरो (http://www. /wald. htm) द्वारा विकसित एक ऑनलाइन कैलकुलेटर का उपयोग करके गणना की गई थी। विल्सन के निरंतरता-संशोधित आत्मविश्वास अंतराल की गणना वासर स्टैट्स द्वारा प्रदान किए गए कैलकुलेटर का उपयोग करके की गई: सांख्यिकीय गणना के लिए वेब साइट (http://faculty.vassar.edu/lowry/prop1.html)। कोणीय फिशर परिवर्तन गणना क्रमशः 19 और 999 डिग्री स्वतंत्रता के लिए महत्वपूर्ण टी मान का उपयोग करके मैन्युअल रूप से की गई थी। दोनों उदाहरणों के लिए गणना परिणाम तालिका में प्रस्तुत किए गए हैं।
आत्मविश्वास अंतराल की गणना छह से की जाती है विभिन्न तरीकेपाठ में वर्णित दो उदाहरणों के लिए
कॉन्फिडेंस अंतराल गणना विधि |
पी=0.0500, या 5% | X=450, N=1000, P=0.4500, या 45% के लिए 95% CI |
–0,0455–0,2541 | ||
एग्रेस्टी-कोल सुधार के साथ वाल्ड | <,0001–0,2541 | |
विल्सन निरंतरता सुधार के साथ | ||
क्लॉपर-पियर्सन "सटीक विधि" | ||
कोणीय परिवर्तन | <0,0001–0,1967 |
जैसा कि तालिका से देखा जा सकता है, पहले उदाहरण के लिए "आम तौर पर स्वीकृत" वाल्ड पद्धति का उपयोग करके गणना किया गया विश्वास अंतराल नकारात्मक क्षेत्र में प्रवेश करता है, जो आवृत्तियों के मामले में नहीं हो सकता है। दुर्भाग्य से, रूसी साहित्य में ऐसी घटनाएं असामान्य नहीं हैं। आवृत्ति और उसकी त्रुटि के संदर्भ में डेटा प्रस्तुत करने का पारंपरिक तरीका आंशिक रूप से इस समस्या को छुपाता है। उदाहरण के लिए, यदि किसी लक्षण की घटना की आवृत्ति (प्रतिशत में) 2.1 ± 1.4 के रूप में प्रस्तुत की जाती है, तो यह 2.1% (95% सीआई: -0.7; 4.9) के रूप में "आंख के लिए आक्रामक" नहीं है, हालांकि और इसका मतलब है एक ही बात। एग्रेस्टी-कोल सुधार और कोणीय परिवर्तन का उपयोग करके गणना के साथ वाल्ड विधि शून्य की ओर निचली सीमा प्रदान करती है। विल्सन की निरंतरता-सही विधि और "सटीक विधि" विल्सन की विधि की तुलना में व्यापक आत्मविश्वास अंतराल उत्पन्न करती है। दूसरे उदाहरण के लिए, सभी विधियाँ लगभग समान आत्मविश्वास अंतराल देती हैं (अंतर केवल हज़ारवें हिस्से में दिखाई देता है), जो आश्चर्य की बात नहीं है, क्योंकि इस उदाहरण में घटना की आवृत्ति 50% से बहुत अलग नहीं है, और नमूना आकार है काफी बड़ी।
इस समस्या में रुचि रखने वाले पाठकों के लिए, हम आर. जी. न्यूकॉम्ब और ब्राउन, कै और दासगुप्ता के कार्यों की सिफारिश कर सकते हैं, जो क्रमशः आत्मविश्वास अंतराल की गणना के लिए 7 और 10 अलग-अलग तरीकों का उपयोग करने के फायदे और नुकसान प्रदान करते हैं। घरेलू मैनुअल के बीच, हम पुस्तक की अनुशंसा करते हैं और, जो सिद्धांत के विस्तृत विवरण के अलावा, वाल्ड और विल्सन के तरीकों को प्रस्तुत करता है, साथ ही द्विपद आवृत्ति वितरण को ध्यान में रखते हुए आत्मविश्वास अंतराल की गणना करने की एक विधि भी प्रस्तुत करता है। मुफ़्त ऑनलाइन कैलकुलेटर (http://www. /wald. htm और http://faculty. vassar. edu/lowry/prop1.html) के अलावा, आवृत्तियों के लिए आत्मविश्वास अंतराल (और न केवल!) का उपयोग करके गणना की जा सकती है सीआईए प्रोग्राम (कॉन्फिडेंस इंटरवल एनालिसिस), जिसे http://www से डाउनलोड किया जा सकता है। माध्यमिक विद्यालय। soton. एसी। यूके/सीआईए/ .
अगला लेख गुणात्मक डेटा की तुलना करने के एकतरफा तरीकों पर गौर करेगा।
ग्रन्थसूची
बनर्जी ए.स्पष्ट भाषा में चिकित्सा आँकड़े: एक परिचयात्मक पाठ्यक्रम / ए. बनर्जी। - एम.: प्रैक्टिकल मेडिसिन, 2007. - 287 पी. चिकित्सा आँकड़े /। - एम.: चिकित्सा सूचना एजेंसी, 2007. - 475 पी. ग्लैंज़ एस.चिकित्सा और जैविक सांख्यिकी / एस. ग्लान्ज़। - एम.: प्रकृति, 1998। डेटा प्रकार, वितरण परीक्षण और वर्णनात्मक आँकड़े // मानव पारिस्थितिकी - 2008। - नंबर 1. - पी. 52-58। झिझिन के.एस.. चिकित्सा आँकड़े: पाठ्यपुस्तक /। - रोस्तोव एन/डी: फीनिक्स, 2007। - 160 पी। अनुप्रयुक्त चिकित्सा आँकड़े / , . - सेंट पीटर्सबर्ग। : फोलियट, 2003.-428 पी. लैकिन जी.एफ. बॉयोमीट्रिक्स/. - एम.: हायर स्कूल, 1990. - 350 पी. चिकित्सक वी. ए. चिकित्सा में गणितीय आँकड़े / , . - एम.: वित्त और सांख्यिकी, 2007. - 798 पी. नैदानिक अनुसंधान में गणितीय आँकड़े / , . - एम.: जियोटार-मेड, 2001. - 256 पी. जंकेरोव वी. और. चिकित्सा अनुसंधान डेटा का चिकित्सा और सांख्यिकीय प्रसंस्करण / , . - सेंट पीटर्सबर्ग। : वीमेडए, 2002. - 266 पी. एग्रेस्टी ए.द्विपद अनुपातों के अंतराल अनुमान के लिए अनुमानित सटीक से बेहतर है / ए. एग्रेस्टी, बी. कूल // अमेरिकी सांख्यिकीविद्। - 1998. - एन 52. - पी. 119-126। ऑल्टमैन डी.विश्वास के साथ आँकड़े // डी. ऑल्टमैन, डी. मशीन, टी. ब्रायंट, एम.जे. गार्डनर। - लंदन: बीएमजे बुक्स, 2000. - 240 पी। ब्राउन एल.डी.द्विपद अनुपात के लिए अंतराल अनुमान / एल. डी. ब्राउन, टी. टी. कै, ए. दासगुप्ता // सांख्यिकीय विज्ञान। - 2001. - एन 2. - पी. 101-133. क्लॉपर सी.जे.द्विपद / सी.जे. क्लॉपर, ई.एस. पियर्सन // बायोमेट्रिका के मामले में सचित्र आत्मविश्वास या प्रत्ययी सीमाओं का उपयोग। - 1934. - एन 26. - पी. 404-413। गार्सिया-पेरेज़ एम. ए. द्विपद पैरामीटर के लिए विश्वास अंतराल पर / एम. ए. गार्सिया-पेरेज़ // गुणवत्ता और मात्रा। - 2005. - एन 39. - पी. 467-481. मोटुलस्की एच.सहज जैवसांख्यिकी // एच. मोटुलस्की। - ऑक्सफ़ोर्ड: ऑक्सफ़ोर्ड यूनिवर्सिटी प्रेस, 1995. - 386 पी। न्यूकॉम्ब आर.जी.एकल अनुपात के लिए दो तरफा आत्मविश्वास अंतराल: सात तरीकों की तुलना / आर. जी. न्यूकॉम्ब // चिकित्सा में सांख्यिकी। - 1998. - एन. 17. - पी. 857-872. सोरो जे.द्विपद आत्मविश्वास अंतराल का उपयोग करके छोटे नमूनों से पूर्णता दर का अनुमान लगाना: तुलना और सिफारिशें / जे. सोरो, जे. आर. लुईस // मानव कारकों और एर्गोनॉमिक्स सोसायटी की वार्षिक बैठक की कार्यवाही। - ऑरलैंडो, FL, 2005. वाल्ड ए.निरंतर वितरण कार्यों के लिए विश्वास सीमाएँ // ए. वाल्ड, जे. वोल्फोवित्ज़ // गणितीय सांख्यिकी के इतिहास। - 1939. - एन 10. - पी. 105-118. विल्सन ई.बी. संभावित अनुमान, उत्तराधिकार का नियम, और सांख्यिकीय अनुमान / ई.बी. विल्सन // जर्नल ऑफ़ अमेरिकन स्टैटिस्टिकल एसोसिएशन। - 1927. - एन 22. - पी. 209-212।अनुपात के लिए विश्वास अंतराल
एक। एम. ग्रजीबोव्स्की
राष्ट्रीय सार्वजनिक स्वास्थ्य संस्थान, ओस्लो, नॉर्वे
लेख द्विपद अनुपातों के लिए आत्मविश्वास अंतराल की गणना के लिए कई तरीके प्रस्तुत करता है, अर्थात्, वाल्ड, विल्सन, आर्क्साइन, एग्रेस्टी-कूल और सटीक क्लॉपर-पियर्सन विधियां। यह पेपर द्विपद अनुपात के आत्मविश्वास अंतराल अनुमान की समस्या का केवल एक सामान्य परिचय देता है और इसका उद्देश्य न केवल पाठकों को अपने स्वयं के अनुभवजन्य अनुसंधान के परिणाम प्रस्तुत करते समय आत्मविश्वास अंतराल का उपयोग करने के लिए प्रोत्साहित करना है, बल्कि उन्हें सांख्यिकी पुस्तकों से परामर्श करने के लिए प्रोत्साहित करना भी है। स्वयं के डेटा का विश्लेषण करने और पांडुलिपियाँ तैयार करने से पहले।
मुख्य शब्द: आत्मविश्वास अंतराल, अनुपात
संपर्क जानकारी:
– वरिष्ठ सलाहकार, राष्ट्रीय सार्वजनिक स्वास्थ्य संस्थान, ओस्लो, नॉर्वे
इस लेख से आप सीखेंगे:
क्या हुआ है विश्वास अंतराल?
क्या बात है 3 सिग्मा नियम?
आप इस ज्ञान को व्यवहार में कैसे लागू कर सकते हैं?
आजकल, उत्पादों, बिक्री दिशाओं, कर्मचारियों, गतिविधि के क्षेत्रों आदि के एक बड़े वर्गीकरण से जुड़ी जानकारी की अधिकता के कारण, मुख्य बात को उजागर करना कठिन हो सकता है, जो, सबसे पहले, ध्यान देने और प्रबंधित करने के प्रयास करने लायक है। परिभाषा विश्वास अंतरालऔर इसकी सीमाओं से परे जाकर वास्तविक मूल्यों का विश्लेषण - एक तकनीक जो आपको स्थितियों को उजागर करने में मदद मिलेगी, बदलते रुझानों को प्रभावित करना।आप सकारात्मक कारकों को विकसित करने और नकारात्मक कारकों के प्रभाव को कम करने में सक्षम होंगे। इस तकनीक का इस्तेमाल कई जानी-मानी वैश्विक कंपनियों में किया जाता है।
तथाकथित हैं " अलर्ट", कौन प्रबंधकों को सूचित करेंकि अगला मान एक निश्चित दिशा में है परे चला गया विश्वास अंतराल. इसका अर्थ क्या है? यह एक संकेत है कि कोई असामान्य घटना घटी है, जो इस दिशा में मौजूदा रुझान को बदल सकती है। यह एक संकेत हैउस के लिए पता लगाने के लिएस्थिति में और समझें कि किस चीज़ ने इसे प्रभावित किया।
उदाहरण के लिए, कई स्थितियों पर विचार करें. हमने 2011 के लिए 100 उत्पाद वस्तुओं के लिए महीने और मार्च में वास्तविक बिक्री की पूर्वानुमान सीमा के साथ बिक्री पूर्वानुमान की गणना की:
- "सूरजमुखी तेल" के लिए उन्होंने पूर्वानुमान की ऊपरी सीमा तोड़ दी और विश्वास अंतराल में नहीं आए।
- "सूखा खमीर" के लिए हमने पूर्वानुमान की निचली सीमा पार कर ली है।
- "दलिया दलिया" ऊपरी सीमा को तोड़ चुका है।
अन्य उत्पादों के लिए, वास्तविक बिक्री दी गई पूर्वानुमान सीमा के भीतर थी। वे। उनकी बिक्री उम्मीदों के अनुरूप थी। इसलिए, हमने 3 उत्पादों की पहचान की जो सीमाओं से परे चले गए और यह पता लगाना शुरू किया कि किस चीज़ ने उन्हें सीमाओं से परे जाने के लिए प्रभावित किया:
- सूरजमुखी तेल के लिए, हमने एक नए वितरण नेटवर्क में प्रवेश किया, जिससे हमें अतिरिक्त बिक्री की मात्रा मिली, जिसके कारण हम ऊपरी सीमा से आगे निकल गए। इस उत्पाद के लिए, इस नेटवर्क के बिक्री पूर्वानुमान को ध्यान में रखते हुए, वर्ष के अंत तक पूर्वानुमान की पुनर्गणना करना उचित है।
- "ड्राई यीस्ट" के लिए कार सीमा शुल्क में फंस गई, और 5 दिनों के भीतर कमी हो गई, जिससे बिक्री में गिरावट आई और निचली सीमा से अधिक हो गई। यह पता लगाना सार्थक हो सकता है कि इसका कारण क्या है और इस स्थिति को दोबारा न दोहराने का प्रयास करें।
- ओटमील दलिया के लिए एक बिक्री प्रोत्साहन कार्यक्रम शुरू किया गया, जिससे बिक्री में उल्लेखनीय वृद्धि हुई और कंपनी पूर्वानुमान से आगे निकल गई।
हमने तीन कारकों की पहचान की है जो पूर्वानुमान सीमा से आगे जाने को प्रभावित करते हैं। जीवन में उनमें से बहुत कुछ हो सकते हैं। पूर्वानुमान और योजना की सटीकता बढ़ाने के लिए, ऐसे कारक जो इस तथ्य की ओर ले जाते हैं कि वास्तविक बिक्री पूर्वानुमान से आगे जा सकती है, उनके लिए अलग से पूर्वानुमान और योजनाएँ बनाना और उजागर करना उचित है। और फिर मुख्य बिक्री पूर्वानुमान पर उनके प्रभाव पर विचार करें। आप नियमित रूप से इन कारकों के प्रभाव का आकलन भी कर सकते हैं और स्थिति को बेहतरी के लिए बदल सकते हैं। नकारात्मक कारकों के प्रभाव को कम करके और सकारात्मक कारकों के प्रभाव को बढ़ाकर.
एक विश्वास अंतराल के साथ हम यह कर सकते हैं:
- दिशानिर्देश चुनें, जो ध्यान देने योग्य हैं, क्योंकि इन दिशाओं में ऐसी घटनाएँ घटी हैं जो प्रभावित कर सकती हैं प्रवृत्ति में परिवर्तन.
- कारकों को पहचानें, जो वास्तव में स्थिति में बदलाव को प्रभावित करते हैं।
- स्वीकार करना सूचित निर्णय(उदाहरण के लिए, खरीदारी, योजना आदि के बारे में)।
अब आइए देखें कि कॉन्फिडेंस इंटरवल क्या है और एक उदाहरण का उपयोग करके एक्सेल में इसकी गणना कैसे करें।
कॉन्फिडेंस इंटरवल क्या है?
कॉन्फिडेंस अंतराल पूर्वानुमान सीमाएँ (ऊपरी और निचली) है, जिसके भीतर दी गई प्रायिकता (सिग्मा) के साथवास्तविक मान दिखाई देंगे.
वे। हम पूर्वानुमान की गणना करते हैं - यह हमारा मुख्य दिशानिर्देश है, लेकिन हम समझते हैं कि वास्तविक मान हमारे पूर्वानुमान के 100% बराबर होने की संभावना नहीं है। और सवाल उठता है, किन सीमाओं के भीतरवास्तविक मूल्य गिर सकते हैं, यदि वर्तमान प्रवृत्ति जारी रहती है? और यह प्रश्न हमें उत्तर देने में मदद करेगा आत्मविश्वास अंतराल गणना, अर्थात। - पूर्वानुमान की ऊपरी और निचली सीमाएँ।
दी गई संभाव्यता सिग्मा क्या है?
गणना करते समयआत्मविश्वास अंतराल हम कर सकते हैं संभाव्यता निर्धारित करें एचआईटीएसवास्तविक मूल्य दी गई पूर्वानुमान सीमा के भीतर. इसे कैसे करना है? ऐसा करने के लिए, हम सिग्मा का मान निर्धारित करते हैं और, यदि सिग्मा इसके बराबर है:
3 सिग्मा- फिर, विश्वास अंतराल में आने वाले अगले वास्तविक मूल्य की संभावना 99.7%, या 300 से 1 होगी, या सीमाओं से परे जाने की 0.3% संभावना है।
2 सिग्मा- तो, सीमाओं के भीतर अगले मान के गिरने की संभावना ≈ 95.5% है, यानी। संभावना लगभग 20 से 1 है, या ओवरबोर्ड जाने की 4.5% संभावना है।
1 सिग्मा- तो संभावना ≈ 68.3% है, यानी। संभावनाएँ लगभग 2 से 1 हैं, या 31.7% संभावना है कि अगला मान विश्वास अंतराल से बाहर हो जाएगा।
हमने तैयार किया 3 सिग्मा नियम,जो ऐसा कहता है हिट संभावनाएक और यादृच्छिक मान विश्वास अंतराल मेंकिसी दिए गए मान के साथ थ्री सिग्मा 99.7% है.
महान रूसी गणितज्ञ चेबीशेव ने प्रमेय सिद्ध किया कि तीन सिग्मा के दिए गए मान के साथ पूर्वानुमान सीमा से आगे जाने की 10% संभावना है। वे। 3-सिग्मा विश्वास अंतराल के भीतर आने की संभावना कम से कम 90% होगी, जबकि पूर्वानुमान और उसकी सीमाओं की "आंख से" गणना करने का प्रयास बहुत अधिक महत्वपूर्ण त्रुटियों से भरा है।
एक्सेल में स्वयं कॉन्फिडेंस अंतराल की गणना कैसे करें?
आइए एक उदाहरण का उपयोग करके एक्सेल में विश्वास अंतराल (यानी, पूर्वानुमान की ऊपरी और निचली सीमाएं) की गणना देखें। हमारे पास एक समय श्रृंखला है - 5 वर्षों के लिए महीने के हिसाब से बिक्री। संलग्न फाइल देख।
पूर्वानुमान सीमा की गणना करने के लिए, हम गणना करते हैं:
- बिक्री पूर्वानुमान().
- सिग्मा - मानक विचलनवास्तविक मूल्यों से पूर्वानुमान मॉडल।
- तीन सिग्मा.
- विश्वास अंतराल।
1. बिक्री पूर्वानुमान.
=(आरसी[-14] (समय श्रृंखला डेटा)- आरसी[-1] (मॉडल मान))^2(वर्ग)

3. प्रत्येक माह के लिए, आइए चरण 8 Sum((Xi-Ximod)^2) से विचलन मानों का योग करें, अर्थात। आइए प्रत्येक वर्ष के लिए जनवरी, फरवरी... का सारांश निकालें।
ऐसा करने के लिए, सूत्र =SUMIF() का उपयोग करें
SUMIF (चक्र के अंदर अवधि संख्याओं के साथ सरणी (1 से 12 तक के महीनों के लिए); चक्र में अवधि संख्या से लिंक; स्रोत डेटा और अवधि मानों के बीच अंतर के वर्गों के साथ एक सरणी से लिंक)

4. चक्र में 1 से 12 तक प्रत्येक अवधि के लिए मानक विचलन की गणना करें (चरण 10) संलग्न फाइल में).
ऐसा करने के लिए, हम चरण 9 में गणना किए गए मान से मूल निकालते हैं और इस चक्र में अवधियों की संख्या से विभाजित करते हैं माइनस 1 = SQRT((Sum(Xi-Ximod)^2/(n-1))
आइए Excel =ROOT(R8) में सूत्रों का उपयोग करें ((Sum(Xi-Ximod)^2 से लिंक)/(COUNTIF($O$8:$O$67 (चक्र संख्या के साथ सरणी से लिंक); O8 (एक विशिष्ट चक्र संख्या से लिंक करें जिसे हम सरणी में गिनते हैं))-1))
एक्सेल सूत्र का उपयोग करना = COUNTIFहम संख्या n गिनते हैं

पूर्वानुमान मॉडल से वास्तविक डेटा के मानक विचलन की गणना करने के बाद, हमने प्रत्येक माह के लिए सिग्मा मान प्राप्त किया - चरण 10 संलग्न फाइल में ।
3. आइए 3 सिग्मा की गणना करें।
चरण 11 पर हम सिग्मा की संख्या निर्धारित करते हैं - हमारे उदाहरण में "3" (चरण 11 संलग्न फाइल में):

अभ्यास के लिए भी सुविधाजनक सिग्मा मान:
1.64 सिग्मा - सीमा पार करने की 10% संभावना (10 में 1 मौका);
1.96 सिग्मा - सीमा से परे जाने की 5% संभावना (20 में 1 मौका);
2.6 सिग्मा - सीमा पार करने की 1% संभावना (100 में 1 संभावना)।
5) तीन सिग्मा की गणना, इसके लिए हम प्रत्येक माह के लिए "सिग्मा" मान को "3" से गुणा करते हैं।

3. विश्वास अंतराल निर्धारित करें.
- ऊपरी पूर्वानुमान सीमा- वृद्धि और मौसमी + (प्लस) 3 सिग्मा को ध्यान में रखते हुए बिक्री पूर्वानुमान;
- कम पूर्वानुमान सीमा- वृद्धि और मौसमी को ध्यान में रखते हुए बिक्री का पूर्वानुमान - (माइनस) 3 सिग्मा;
लंबी अवधि के लिए विश्वास अंतराल की गणना की सुविधा के लिए (संलग्न फ़ाइल देखें), हम एक्सेल सूत्र का उपयोग करेंगे =Y8+VLOOKUP(W8,$U$8:$V$19,2,0), कहाँ
Y8- बिक्री पूर्वानुमान;
W8- उस महीने की संख्या जिसके लिए हम 3-सिग्मा मान लेंगे;
वे। ऊपरी पूर्वानुमान सीमा= "बिक्री पूर्वानुमान" + "3 सिग्मा" (उदाहरण में, VLOOKUP(माह संख्या; 3 सिग्मा मानों वाली तालिका; कॉलम जिसमें से हम संबंधित पंक्ति में माह संख्या के बराबर सिग्मा मान निकालते हैं; 0))।

कम पूर्वानुमान सीमा= "बिक्री पूर्वानुमान" शून्य से "3 सिग्मा"।
इसलिए, हमने एक्सेल में कॉन्फिडेंस इंटरवल की गणना की।
अब हमारे पास एक पूर्वानुमान और सीमाओं के साथ एक सीमा है जिसके भीतर वास्तविक मान किसी दिए गए सिग्मा संभावना के साथ गिरेंगे।
इस लेख में, हमने देखा कि सिग्मा और थ्री-सिग्मा नियम क्या हैं, आत्मविश्वास अंतराल कैसे निर्धारित करें, और आप इस तकनीक का अभ्यास में उपयोग क्यों कर सकते हैं।
हम आपके सटीक पूर्वानुमान और सफलता की कामना करते हैं!
कैसे Forecast4AC PRO आपकी मदद कर सकता हैविश्वास अंतराल की गणना करते समय?:
Forecast4AC PRO स्वचालित रूप से एक साथ 1000 से अधिक समय श्रृंखला के लिए पूर्वानुमान की ऊपरी या निचली सीमा की गणना करेगा;
एक कीस्ट्रोक के साथ चार्ट पर पूर्वानुमान, प्रवृत्ति और वास्तविक बिक्री की तुलना में पूर्वानुमान की सीमाओं का विश्लेषण करने की क्षमता;
Forcast4AC PRO प्रोग्राम में सिग्मा मान को 1 से 3 तक सेट करना संभव है।
हमसे जुड़ें!
निःशुल्क पूर्वानुमान और व्यवसाय विश्लेषण ऐप्स डाउनलोड करें:

- नोवो पूर्वानुमान लाइट- स्वचालित पूर्वानुमान गणनावी एक्सेल.
- 4एनालिटिक्स - एबीसी-एक्सवाईजेड विश्लेषणऔर उत्सर्जन विश्लेषण एक्सेल.
- क्लिक सेंसडेस्कटॉप और QlikViewव्यक्तिगत संस्करण - डेटा विश्लेषण और विज़ुअलाइज़ेशन के लिए बीआई सिस्टम।
सशुल्क समाधानों की क्षमताओं का परीक्षण करें:
- नोवो फोरकास्ट प्रो- बड़े डेटा सेट के लिए एक्सेल में पूर्वानुमान।
