Обсяг вибірки опитування. Формула вибірки – проста
Кожна професія має свій набір улюблених питань. Для дослідників ринку цей список очолює, безумовно, питання розмірі вибірки. Зазвичай його формулюють так:
- Ми хотіли б замовити дослідження з відвідувачів московських торгових центрів. Яка нам потрібна вибірка?
- Наша цільова аудиторія – приблизно 300 000 людей. Скільки людей потрібно опитати, щоб було репрезентативно? А якщо цільова аудиторія буде 3 млн?
- Нам необхідно оцінити потенціал продажів квартир у Санкт-Петербурзі мешканцям північних міст Росії. Яку вибірку зробити?
Головна помилка про розмір вибірки
Багато хто впевнений, що чим більший розмір цільової групи, тим більше має бути розмір вибірки. Тому, нібито, щоб дізнатися думку мешканців маленького міста, достатньо опитати чоловік 200-300, ну а для з'ясування думки щодо Росії загалом і 5000 буде мало.
Тим часом цей стереотип не має нічого спільного з реальністю. Розмір вибірки не залежить від чисельності цільової групи (мовою статистики вона називається «генеральною сукупністю») і визначається двома зовсім іншими факторами. Єдиний виняток із цього правила – випадки, коли Генеральна сукупністьдуже маленька, наприклад, 1-2 тисячі осіб, але такі ситуації у реальній практиці маркетингових досліджень трапляються рідко.
Два фактори, від яких залежить розмір вибірки
Розмір вибірки масового опитування залежить від двох факторів:
- Точності даних, які потрібно отримати на виході – це та сама «статистична похибка». Для вибірки у 100 респондентів вона буде у межах плюс-мінус 10%, а для вибірки у 1000 респондентів – у межах плюс-мінус 3,1%. Докладніше про це – нижче.
- Кількості та розміру підгруп, на які потрібно розбивати вибірку під час аналізу. Наприклад, якщо проводиться електоральне дослідження, то переважно нас цікавитиме ядро активних виборців. Зазвичай, частка «ядра» рідко перевищує 20-25% від населення. Тому розмір вибірки потрібно розраховувати так, щоб одна чверть від загального обсягу дозволяла проводити повноцінний статистичний аналіз.
Два різновиди помилки вибірки
Будь-яке вибіркове спостереження (тобто коли ми опитуємо не всіх поспіль, а робимо випадковий відбір із генеральної сукупності) пов'язане з похибкою даних. Цю похибку зазвичай називають помилкою вибірки. Вона може бути двох видів:
- Систематична- Пов'язана з помилками проектування вибірки. Оцінити її розмір, напрямок та ступінь усунення дуже складно, найчастіше – неможливо. Наприклад, якщо питання респондентам задаватимуть представники маргінальних соціальних верств, це вплине на готовність брати участь у дослідженні з боку представників більш забезпечених груп населення. У результаті це призведе до вкрай важко оцінюваної систематичної помилки та спотворення даних.
- Випадкова– пов'язані з дією законів статистики. Її розмір легко розраховується за формулами математичної статистикита теорії ймовірності. Вони дозволяють робити обґрунтовані висновки про довірчий інтервал ознаки. Наприклад, якщо статистична похибка становить плюс-мінус 10%, а отримане значення показника дорівнювало 25%, то довірчий інтервалдорівнює від 15% до 35%.

Завдання дослідника – зібрати дані те щоб мінімізувати систематичну помилку вибірки. Тоді можна буде звести статпохибку лише до випадкової помилки, яку можна розрахувати за формулами.
Як розрахувати розмір випадкової помилки вибірки
Випадкова помилка вибірки залежить тільки від обсягу вибірки, а й від дисперсії, тобто ступеня однорідності даних. Чим однорідніші дані (тобто чим менше розкид отриманих значень, або дисперсія), тим менша помилка вибірки.
Існує формула розрахунку випадкової помилки вибірки, проте для зручності рекомендуємо користуватися онлайн-калькуляторами, наприклад, ось цим. Він дозволяє легко провести два види розрахунку:
- розрахувати величину статистичної похибки на основі розміру вибірки та передбачуваної дисперсії;
- визначити розмір вибірки, необхідний отримання оцінки потрібного ступеня точності.

Як параметр довірчої надійності (одне з полів у калькуляторі) зазвичай використовується значення 95%. Це означає, що у 95% випадків розподіл ознаки у генеральній сукупності потрапить у розрахований довірчий інтервал (тобто саме значення ознаки у вибірці плюс-мінус розмір статистичної похибки). Рідше використовується значення надійності в 97% або 99% - воно, відповідно, означає, що подібне потрапляння відбудеться у 97% або 99% випадків. У разі надійність вибірки підвищується, але збільшується розмір вибірки.
Найскладніше щодо розміру вибірки – пошук компромісу між необхідної точністю і вартістю збору даних. Цей процес ускладнюється тим, що збільшення розміру вибірки вчетверо призводить до збільшення точності лише вдвічі (відповідає квадратного коренявід величини приросту вибірки).
Кейс: визначення розміру вибірки для оцінки потенціалу ринку продажу столичної нерухомості покупцям із регіонів
У листопаді-грудні 2016 року ми провели дослідження попиту на квартири в новобудовах Москви та Санкт-Петербурга з боку мешканців різних міст Росії. Дослідження включало три методи збору даних: масове репрезентативне опитування населення віком від 20 до 60 років (проводилося з використанням технології CATI), а також серію експертних інтерв'ю з ріелторами і глибинних інтерв'ю з потенційними покупцями квартир.
Дослідження охоплювало 33 міста, що відрізняються підвищеним попитом на петербурзьку та московську нерухомість. Планова вибірка дослідження, розрахована за формулами, становила 21500 респондентів. Цей обсяг значно більший за «стандартний» обсяг вибірки, що використовується в маркетингових дослідженнях. З чим пов'язаний такий великий розмір вибірки?
Справа в тому, що клієнту були потрібні оцінки окремо по кожному місту, а не просто «загалом по країні». Практично ми працюємо не з 1 вибіркою, а з 33 окремими вибірками по кожному місту. Частка людей, зацікавлених у купівлі квартири в Санкт-Петербурзі або Москві, була експертно визначена в рамках 5% від числа мешканців опитуваних міст.
Залежно від важливості міста для замовника керівник проекту з боку Агентства визначив допустиму статистичну похибку, в яку повинні вкладатися підсумкові результати. Для цього ми використовували спеціальний макрос у MS Excel, але ці розрахунки також можна виконати за допомогою калькулятора вибірки. В результаті розмір вибірки варіював від 500 до 1000 респондентів по кожному з міст дослідження, що в сумі дало заявлені 21 500 осіб.
- Визначте структуру цільової групи. Чи плануєте ви аналізувати окремі підгрупи чи достатньо буде аналізу щодо вибірки загалом?
- Визначте бажану точність даних. Наприклад, якщо потрібно оцінити динаміку ринкової частки за рік, підставте в спеціальний калькулятор зразкове значення частки і «пограйте» з різними обсягами вибірки.
- Знайдіть баланс між вартістю збору даних (прямо пропорційною обсягу вибірки) і необхідною точністю.
Генеральна сукупність
Сумарна чисельність об'єктів спостереження (люди, домогосподарства, підприємства, населені пунктиі т.д.), що володіють певним набором ознак (стаття, вік, дохід, чисельність, оборот і т.д.), обмежена у просторі та часі. Приклади генеральних сукупностей:
- всі жителі Москви (10,6 млн. осіб за даними перепису 2002 року)
– Чоловіки-Москвичі (4,9 млн. осіб за даними перепису 2002 року)
- Юридичні особиРосії (2,2 млн. початку 2005 року)
- роздрібні торгові точки, які здійснюють продаж продуктів харчування (20 тисяч на початок 2008 року) тощо.
Вибірка (Вибіркова сукупність)
Частина об'єктів з генеральної сукупності, відібраних для вивчення, для того, щоб зробити висновок про всю генеральну сукупність. Для того щоб висновок, отриманий шляхом вивчення вибірки, можна було поширити на всю генеральну сукупність, вибірка повинна мати властивість репрезентативності.
Репрезентативність вибірки
Властивість вибірки коректно відбивати генеральну сукупність. Одна і та ж вибірка може бути репрезентативною та нерепрезентативною для різних генеральних сукупностей.
Приклад:
- Вибірка, що повністю складається з москвичів, які володіють автомобілем, не репрезентує все населення Москви.
- Вибірка із російських підприємств чисельністю до 100 осіб не репрезентує всі підприємства Росії.
- Вибірка з москвичів, які здійснюють покупки на ринку, не репрезентує купівельну поведінку всіх москвичів.
У той же час, зазначені вибірки (при дотриманні інших умов) можуть відмінно репрезентувати москвичів-автовласників, невеликі та середні російські підприємства та покупців, які купують на ринках відповідно.
Важливо розуміти, що репрезентативність вибірки та помилка вибірки – різні явища. Репрезентативність, на відміну від помилки, ніяк не залежить від розміру вибірки.
Приклад:
Як би ми не збільшували кількість опитаних москвичів-автовласників, ми не зможемо репрезентувати цією вибіркою всіх москвичів.
Помилка вибірки (довірчий інтервал)
Відхилення результатів, отриманих за допомогою вибіркового спостереженнявід дійсних даних генеральної сукупності.
Помилка вибірки буває двох видів – статистична та систематична. Статистична помилка залежить від розміру вибірки. Чим більший розмір вибірки, тим вона нижча.
Приклад:
Для простої випадкової вибірки розміром 400 одиниць максимальна статистична помилка (з 95% довірчою ймовірністю) становить 5%, для вибірки в 600 одиниць – 4%, для вибірки у 1100 одиниць – 3% Зазвичай, коли говорять про помилку вибірки, мають на увазі саме статистичну помилку .
Систематична помилка залежить від різних факторів, що надають постійний вплив на дослідження та зміщують результати дослідження у певний бік.
Приклад:
- Використання будь-яких ймовірнісних вибірок занижує частку людей із високим доходом, які ведуть активний спосіб життя. Відбувається це через те, що таких людей набагато складніше застати в якомусь певному місці (наприклад, вдома).
- Проблема респондентів, які відмовляються відповідати на запитання анкети (частка «відмовників» у Москві, для різних опитувань, коливається від 50% до 80%)
У деяких випадках, коли відомі справжні розподіли, систематичну помилку можна нівелювати запровадженням квот або перезважуванням даних, але в більшості реальних досліджень навіть оцінити її досить проблематично.
Типи вибірок
Вибірки поділяються на два типи:
- імовірнісні
- неймовірні
1. Імовірнісні вибірки
1.1 Випадкова вибірка (простий випадковий вибір)
Така вибірка передбачає однорідність генеральної сукупності, однакову можливість доступності всіх елементів, наявність повного спискувсіх елементів. При відборі елементів зазвичай використовується таблиця випадкових чисел.
1.2 Механічна (систематична) вибірка
Різновид випадкової вибірки, впорядкований за якоюсь ознакою ( алфавітний порядок, номер телефону, дата народження тощо). Перший елемент відбирається випадково, потім з кроком 'n' відбирається кожен 'k'-ий елемент. Розмір генеральної сукупності, у своїй – N=n*k
1.3 Стратифікована (районована)
Застосовується у разі неоднорідності генеральної сукупності. Генеральна сукупність розбивається на групи (страти). У кожній страті відбір здійснюється випадковим чи механічним чином.
1.4 Серійна (гніздова чи кластерна) вибірка
При серійній вибірці одиницями відбору виступають самі об'єкти, а групи (кластери чи гнізда). Групи відбираються випадковим чином. Об'єкти всередині груп обстежуються суцільником.
2. Неймовірні вибірки
Відбір у такій вибірці здійснюється за принципами випадковості, а, по суб'єктивним критеріям – доступності, типовості, рівного представництва тощо.
2.1. Квотна вибірка
Спочатку виділяється деяка кількість груп об'єктів (наприклад, чоловіки віком 20-30 років, 31-45 років і 46-60 років; особи з доходом до 30 тисяч рублів, з доходом від 30 до 60 тисяч рублів та з доходом понад 60 тисяч рублів ) Для кожної групи задається кількість об'єктів, які мають бути обстежені. Кількість об'єктів, які мають потрапити до кожної групи, задається, найчастіше, або пропорційно заздалегідь відомої частки групи в генеральній сукупності, або однаковим для кожної групи. Усередині груп об'єкти відбираються довільно. Квотні вибірки використовують у маркетингових дослідженнях досить часто.
2.2. Метод снігової грудки
Вибірка будується в такий спосіб. У кожного респондента, починаючи з першого, просяться контакти його друзів, колег, знайомих, які б підходили під умови відбору і могли б взяти участь у дослідженні. Отже, крім першого кроку, вибірка формується з участю самих об'єктів дослідження. Метод часто застосовується, коли необхідно знайти та опитати важкодоступні групи респондентів (наприклад, респондентів, які мають високий дохід, респондентів, що належать до однієї професійної групи, респондентів, які мають схожі хобі/захоплення тощо)
2.3 Стихійна вибірка
Опитуються найдоступніші респонденти. Типовими прикладами стихійних вибірок є опитування в газетах/журналах, анкети, віддані респондентам на самозаповнення, більшість інтернет-опитувань. Розмір та склад стихійних вибірок заздалегідь не відомий, і визначається лише одним параметром – активністю респондентів.
2.4 Вибір типових випадків
Відбираються одиниці генеральної сукупності, які мають середнім (типовим) значенням ознаки. При цьому виникає проблема вибору ознаки та визначення її типового значення.
Калькулятор розрахунку помилки та розміру вибірки (для випадкової вибірки)
| Найменування параметру | Значення |
| Тема статті: | Тема 5: Розрахунок вибірки |
| Рубрика (тематична категорія) | Маркетинг |
Найчастіше розміри досліджуваної сукупності великі чи отримання інформації від усієї сукупності дуже важливо витратити занадто багато часу й коштів. У цих випадках формують та досліджують вибіркову сукупність. Але слід пам'ятати, що отримані дані завжди містять у собі помилку, про результати спостереження можна судити лише з певним ступенем достовірності.
Генеральна сукупність- Це безліч всіх одиниць, що є об'єктами дослідження, з яких проводиться відбір.
Вибіркова сукупність- Сукупність відібраних для опитування одиниць.
Способи побудови вибірки:
1. Проста випадкова вибірка – кожен елемент генеральної сукупності має однакову можливість потрапити у вибіркову сукупність. Виготовляється за допомогою генератора випадкових чисел;
2. Систематична - перший елемент вибіркової сукупності відбирається довільно, а потім у вибіркову сукупність включається кожен i-ий елемент;
3. Стратифікована (структурована) - генеральна сукупність ділиться на кілька страт (груп), а потім способом простої випадкової мул систематичної вибірки проводиться відбір у кожній із груп;
4. Кластерна вибірка - генеральна сукупність ділиться на кластери, потім випадковим відбором вибирається кілька кластерів і проводиться дослідження всіх об'єктів обраних кластерів.
Методи відбору:
1. Повторна вибірка- ту чи іншу одиницю, що потрапила у вибірку після реєстрації знову повертають у генеральну сукупність, і вона зберігає рівну можливість з іншими одиницями при повторному відборі знову потрапити у вибірку. Загальна чисельність одиниць генеральної сукупності у процесі вибірки залишається незмінною.
2. Безповторна вибірка – одиниця сукупності, що у вибірку, в генеральну сукупність не повертається й у подальшому відборі не бере участі. Загальна чисельність одиниць генеральної сукупності скорочується у процесі вибірки.
Підходи до визначення розміру вибірки:
1. Довільний – бездоказово приймається, що вибірка має становити 5 – 10 % від генеральної сукупності. Даний підхід є простим у використанні, проте неможливо встановити точність отриманих результатів. За досить великої генеральної сукупності він має бути дуже дорогим.
2. На базі попереднього досвіду – обсяг повинен бути встановлений із раніше проведених досліджень. Підхід має певну логіку за умови, що попередня вибірка визначена правильно.
3. Орієнтація на вартість проведення – у бюджеті маркетингових досліджень передбачаються витрати на проведення обстежень, які не можна перевищувати. Достовірність отриманої інформації не гарантується, може мати місце надмірна вибірка.
4. Статистичні методи– за будь-яких вибіркових досліджень виникають помилки. Для розрахунку обсягу вибірки задаються дві величини:
- Довірчий інтервал (припустима помилка вибірки (∆) – деяка величина, на яку генеральні результати можуть відрізнятися вибіркових результатів. Це допустиме відхилення значень, що спостерігаються від істинних. Розмір цього припущення визначається дослідником з урахуванням вимог до точності інформації.
- Довірча ймовірність - означає ступінь впевненості в тому, що значення елемента, що спостерігається, потрапить в заданий діапазон довірчого інтервалу. Найчастіше використовується 95% довірча ймовірність.
Найчастіше ймовірності при проведенні досліджень:
Вибіркова дисперсія (дисперсія ознаки у вибірковій сукупності):
![]()
N - Число одиниць генеральної сукупності.
При цьому приймається за попереднім обстеженням, або розраховується:
Якщо відомо найбільше та найменше значенняознаки у генеральній сукупності:
![]() ;
;
http://www.quans.ru/research/control/select-calc/
Вибіркова сукупність має бути репрезентативною, тобто забезпечувати пропорційне представництво суттєвих ознак генеральної сукупності у вибірці.
Репрезентативність можна проілюструвати таким прикладом. Припустимо, сукупність - це учні школи (600 чоловік із 20 класів, по 30 чоловік у кожному класі). Предмет вивчення – ставлення до куріння. Вибірка, що складається з 60 учнів старших класів, набагато гірше представляє сукупність, ніж вибірка з тих же 60 осіб, до якої увійдуть по 3 учні з кожного класу. Головною причиноютому - нерівний віковий розподіл у класах. Отже, у першому випадку репрезентативність вибірки низька, а в другому репрезентативність висока (за інших рівних умов).
При використанні методу спостережень слід прагнути подолати синдроми Дракули та Франкенштейна. Перший полягає у прагненні «висмоктати» всю мислиму і немислиму інформацію з непрезентативних спостережень. Другий - у прагненні бездумно використати кількісні характеристики. Шлях до успіху - продумане використання як кількісних, і якісних методів; проведення як великомасштабних обстежень, і спостережень у малих групах.
Головною перешкодою на шляху створення ефективних прогнозів за допомогою методу опитувань є знаменитий парадокс Ла-П'єра, який говорить, що люди не завжди роблять так, як вони кажуть.
Тема 5: Розрахунок вибірки - поняття та види. Класифікація та особливості категорії "Тема 5: Розрахунок вибірки" 2017, 2018.
Інтервальне оцінювання ймовірності події. Формули розрахунку чисельності вибірки при власне-випадковому способі відбору.Для визначення ймовірностей цікавих для нас подій ми застосовуємо вибірковий метод: проводимо nнезалежних експериментів, у кожному з яких може статися (або не відбутися) подія А (імовірність рПоява події А в кожному експерименті постійна). Тоді відносна частота p* появи подій Ау серії з nвипробувань приймається як точкової оцінкидля ймовірності pпояви події Ау окремому випробуванні. У цьому величину p* називають вибірковою часткою появи події А, а р - генеральною часткою .
Внаслідок слідства з центральної граничної теореми (теорема Муавра-Лапласа) відносну частоту події при великому обсязі вибірки можна вважати нормально розподіленою з параметрами M(p*)=p
Тому за n>30 довірчий інтервал для генеральної частки можна побудувати, використовуючи формули:

де u кр знаходиться за таблицями функції Лапласа з урахуванням заданої довірчої ймовірностіγ: 2Ф(u кр)=γ.
При малому обсязі вибірки n≤30 гранична помилка ε визначається за таблицею розподілу Стьюдента: ![]() де t кр =t(k; α) та число ступенів свободи k=n-1 ймовірність α=1-γ (двостороння область).
де t кр =t(k; α) та число ступенів свободи k=n-1 ймовірність α=1-γ (двостороння область).
Формули справедливі, якщо відбір проводився випадковим повторним чином (генеральна сукупність нескінченна), інакше необхідно зробити виправлення на безповторність відбору (таблиця).
Середня помилка вибірки для генеральної частки
| Генеральна сукупність | Нескінченна | Кінцева обсягу N |
| Тип відбору | Повторний | Неповторний |
| Середня помилка вибірки |
Формули розрахунку чисельності вибірки при власне-випадковому способі відбору
| Спосіб відбору | Формули визначення чисельності вибірки | ||
| для середньої | для частки | ||
| Повторний | |||
| Неповторний | |||
Завдання про генеральну частку
На запитання «Чи накриває довірчий інтервал задане значення p 0?» - можна відповісти, перевіривши статистичну гіпотезу H 0: p = p 0. При цьому передбачається, що досліди проводяться за схемою випробувань Бернуллі (незалежні, ймовірність pпояви події Апостійна). За вибіркою обсягу nвизначають відносну частоту p* появи події A: де m- кількість появи події Ау серії з nвипробувань. Для перевірки гіпотези H 0 використовується статистика, що має при досить великому обсязі вибірки стандартне нормальний розподіл(Табл. 1).Таблиця 1 – Гіпотези про генеральну частку
Гіпотеза | H 0: p = p 0 | H 0: p 1 = p 2 |
| Припущення | Схема випробувань Бернуллі | Схема випробувань Бернуллі |
| Оцінки за вибіркою |  |
|
| Статистика K |  |  |
| Розподіл статистики K | Стандартне нормальне N(0,1) |
Приклад №1. За допомогою випадкового повторного відбору керівництво фірми провело опитування 900 своїх службовців. Серед опитаних виявилося 270 жінок. Побудуйте довірчий інтервал, що з ймовірністю 0.95 накриває справжню частку жінок у всьому колективі фірми.
Рішення. За умовою вибіркова частка жінок становить (відносна частота жінок серед усіх опитаних). Оскільки відбір є повторним, обсяг вибірки великий (n=900) гранична помилка вибірки визначається за формулою ![]()
Значення u кр знаходимо таблиці функції Лапласа із співвідношення 2Ф(u кр)=γ, тобто. ![]() Функція Лапласа (додаток 1) набуває значення 0.475 при u кр = 1.96. Отже, гранична помилка
Функція Лапласа (додаток 1) набуває значення 0.475 при u кр = 1.96. Отже, гранична помилка ![]() та шуканий довірчий інтервал
та шуканий довірчий інтервал
(p - ε, p + ε) = (0.3 - 0.18; 0.3 + 0.18) = (0.12; 0.48)
Отже, з ймовірністю 0.95 можна гарантувати, частка жінок у всьому колективі фірми перебуває у інтервалі від 0.12 до 0.48.
Приклад №2. Власник автостоянки вважає день «вдалим», якщо автостоянка заповнена більш ніж на 80%. Протягом року було проведено 40 перевірок автостоянки, з яких 24 виявилися «вдалими». З ймовірністю 0.98 знайдіть довірчий інтервал для оцінки справжньої частки "вдалих" днів протягом року.
Рішення. Вибіркова частка «вдалих» днів складає
За таблицею функції Лапласа знайдемо значення u кр за заданої
довірчої ймовірності
Ф(2.23) = 0.49, u кр = 2.33.
Вважаючи відбір безповторним (тобто дві перевірки одного дня не проводилося), знайдемо граничну помилку: ![]()
де n = 40, N = 365 (днів). Звідси ![]()
та довірчий інтервал для генеральної частки: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
З ймовірністю 0.98 очікується, що частка «вдалих» днів протягом року перебуває в інтервалі від 0.43 до 0.77.
Приклад №3. Перевіривши 2500 виробів у партії, виявили, що 400 виробів вищого ґатунку, а n-m – ні. Скільки треба перевірити виробів, щоб із впевненістю 95% визначити частку вищого ґатунку з точністю до 0.01?
Рішення шукаємо за формулою визначення чисельності вибірки для повторного відбору.
Ф(t) = γ/2 = 0.95/2 = 0.475 і цьому значенню за таблицею Лапласа відповідає t=1.96
Вибіркова частка w = 0.16; помилка вибірки ε = 0.01
Приклад №4. Партія виробів приймається, якщо ймовірність того, що виріб виявиться таким, що відповідає стандарту, становить не менше 0.97. Серед випадково відібраних 200 виробів партії, що перевіряється, виявилося 193 відповідних стандарту. Чи можна на рівні значення α=0,02 прийняти партію?
Рішення. Сформулюємо основну та альтернативну гіпотези.
H 0: p = p 0 = 0,97 - невідома генеральна частка pдорівнює заданому значенню p 0 = 0,97. Щодо умови - ймовірність того, що деталь з партії, що перевіряється, виявиться відповідною стандарту, дорівнює 0.97; тобто. партію виробів можна прийняти.
H 1: p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Спостережуване значення статистики K(Таблиця) обчислимо при заданих значеннях p 0 =0,97, n=200, m=193
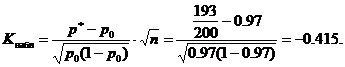
Критичне значення знаходимо за таблицею функції Лапласа з рівності
![]()
За умовою α=0,02 звідси Ф(Ккр)=0,48 і Ккр=2,05. Критична область лівостороння, тобто. є інтервалом (-∞; -K kp) = (-∞; -2,05). Спостережуване значення К набл =-0,415 належить критичної області, отже, цьому рівні значимості немає підстав відхиляти основну гіпотезу. Партію виробів можна прийняти.
Приклад №5. Два заводи виготовляють однотипні деталі. Для оцінки їх якості зроблено вибірки з продукції цих заводів та отримано такі результати. Серед 200 відібраних виробів першого заводу виявилося 20 бракованих, серед 300 виробів другого заводу – 15 бракованих.
На рівні значимості 0.025 з'ясувати, чи є істотна відмінність як деталі, що виготовляються цими заводами.
За умовою α=0,025 звідси Ф(Ккр)=0,4875 і Ккр=2,24. При двосторонній альтернативі область допустимих значень має вигляд (-2,24; 2,24). Спостережуване значення K набл =2,15 потрапляє у цей інтервал, тобто. цьому рівні значимості немає підстав відкидати основну гіпотезу. Заводи виготовляють вироби однакової якості.
Модуль 1.4. РОЗРАХУНОК ОПТИМАЛЬНОЇ ЧИСЛІВОСТІ ВИБІРКИ
Модуль 1.4. РОЗРАХУНОК ОПТИМАЛЬНОЇ ЧИСЛІВОСТІ ВИБІРКИ
Мета вивчення модуля:показати способи розрахунку оптимальної чисельності вибірки щодо громадського здоров'я,
діяльності системи (установ) охорони здоров'я та у клінічній практиці.
Після вивчення теми студент має знати:
Переваги використання вибіркового методу;
Способи формування вибіркової сукупності;
Методи розрахунку оптимальної чисельності вибірки. Студент повинен вміти:
Вибрати спосіб формування вибіркової сукупності відповідно до завдань медико-соціального дослідження;
1.4.1. Блок інформації
Статистичне спостереження можна організувати як суцільне та несуцільне. Суцільне спостереження передбачає обстеження всіх одиниць сукупності, що вивчається, несуцільне - лише її частина. До непоганого спостереження відноситься вибіркове спостереження. Мета вибіркового спостереження у тому, щоб за характеристиками вибіркової сукупності судити про характеристики генеральної сукупності.
Під час проведення медико-соціальних досліджень використовують такі способи формування вибіркової сукупності:
механічний відбір;
Типологічний (стратифікований) відбір;
Серійний відбір;
Багатоступінчастий (скринінговий) відбір;
Когортний метод;
Метод відбору копі-пар.
Формування вибіркової сукупності (вибірки) дозволяє отримати таку сукупність одиниць спостереження, яка за ознаками, що цікавлять дослідника, дає уявлення про генеральну сукупність. Для цього вибірка має бути репрезентативної(представницькою).
Репрезентативність вибірки- відповідність показників, одержуваних у результаті вибіркового спостереження, аналогічним показником генеральної сукупності.
Під час проведення вибіркового дослідження не можна отримати абсолютно точні дані, як із суцільному спостереженні.
Зумовлено це тим, що спостереженню піддається не вся сукупність, лише її частина. Тому під час проведення вибіркового дослідження неминуча деяка похибка (помилки). Помилки, властиві вибірковому дослідженню, називають помилками вибірки.
Помилка вибірки -розбіжність між характеристиками вибіркової та генеральної сукупностей. Як правило, вона виникає в результаті порушення методологічних принципів відбору одиниць спостереження при формуванні вибіркової сукупності та викликана об'єктивною відмінністю цілого (генеральної сукупності) та його частини (вибірки).
Найбільша з можливих помилок вибірки Δ називається граничною помилкою вибірки,яка розраховується за формулою:
де S 2 - оцінка дисперсії σ 2 , що обчислюється за вибіркою х 1 х 2, х n.
Середньою помилкою вибірки(μ) називають різницю між середніми вибірковою та генеральною сукупностями, яка за модулем не перевищує σ.
Тоді коефіцієнт довіри tхарактеризує її кратність. У разі коли генеральна сукупність має кінцевий обсяг N,у середню помилку вибірки μ вводять поправочний коефіцієнт

На формулах розрахунку граничної помилки вибірки заснований спосіб визначення чисельності вибірки, що забезпечує задану оцінку точність. З формули для граничної помилки:

слід:

У разі генеральної сукупності кінцевого обсягу Nаналогічно можна знайти:

отже,

Довірчий коефіцієнт tзнаходиться з таблиці квантилей нормального розподілу при заданій надійності. При стандартних значеннях надійності γ = 0,95 та γ = 0,99 відповідні довірчі коефіцієнти tдорівнюють t 0,95 = 1,96; t 0,99 = 2,58. Наведемо ще два значення, що часто використовуються: t 0,9544 = 2; t 0,9973 = 3. Якщо замість σ у формулі фігурує S,виявляється, що tзалежить не тільки від γ, а й від n.У цьому випадку коефіцієнт tзнаходять із таблиці квантилей розподілу Стьюдента. При досить великих nвипливає, що S≈ σ та відповідні коефіцієнти tпри однаковій надійності малорозрізні.
При оцінці ймовірності рпо відносній частоті з формули:

слід:

Аналогічно для генеральної сукупності кінцевого обсягу Nотримуємо:

отже,

Отже, задавши бажану точність, тобто. вказавши граничну помилку Δ, достатній обсяг вибірки n, що забезпечує цю точність, можна знайти за наведеними формулами. При n,великих знайденого значення, точність збільшується, оскільки гранична помилка Δ зменшується (див. формули, що зв'язують nта Δ).
1.4.2. Завдання для самостійної роботи
1.Вивчити матеріали відповідного розділу підручника, модуля, рекомендованої літератури.
2.Відповісти на контрольні питання.
3. Розібрати завдання-еталон.
4.Відповісти на запитання тестового завдання модуля.
5. Розв'язати задачі.
1.4.3. Контрольні питання
1.У чому перевага вибіркового методу дослідження?
2. Дайте визначення репрезентативності вибірки.
3.Дайте визначення помилки вибірки.
4.Назвіть способи формування вибіркової сукупності.
5.Дайте визначення граничної помилки вибірки. Наведіть формули розрахунку.
6.Дайте визначення середньої помилки вибірки. Наведіть формули розрахунку.
1.4.4. Завдання-еталон
Початкові дані
1. При вивченні середньої тривалості перебування хворих у стаціонарі одержано такі дані: М = 20 днів, σ = 1,63 дня, μ = 0,16 дня.
2. Під час вивчення однорічної летальності в онкологічному диспансері отримано показник 67,9%.
Завдання
1)для отримання достовірних результатів щодо середньої тривалості перебування хворих у стаціонарі при заданому довірчому коефіцієнті t Y= 3 (надійність γ = 0,9973) та граничній помилці Δ = 0,5 дня;
2) для отримання достовірних результатів щодо однорічної летальності в онкологічному диспансері при заданому довірчому коефіцієнті t Y= 2 (надійність γ = 0,9544) та граничної помилки Δ = 0,05.
Рішення
1. Розрахунок необхідного обсягу вибірки вивчення середньої тривалості перебування хворих на стаціонарі:
2. Розрахунок необхідного обсягу вибірки для вивчення однорічної летальності в онкологічному диспансері:
Висновок
1.Для отримання показника середньої тривалості перебування хворих у стаціонарі із заданою точністю 0,5 дня необхідний обсяг вибірки має становити 96 хворих.
2.Для отримання показника однорічної летальності з гарантованою точністю Δ = 0,05 необхідний обсяг вибірки має становити 352 хворих.
1.4.5. Тестові завдання
Виберіть лише одну правильну відповідь.1. Яка сукупність називається генеральною?
1)достовірні дані, необхідних дослідження;
2) окремі одиниці сукупності, що відрізняються один від одного в силу різних випадкових причин;
3) необмежену кількість одиниць спостереження;
4) безліч статистичних елементів;
5) безліч якісно однорідних одиниць спостереження, об'єднаних за однією або групою ознак.
2. Частина одиниць спостереження генеральної сукупності, що піддається вибірковому дослідженню, називають:
1) частковою сукупністю;
2)випадковою сукупністю;
3) вибірковою сукупністю;
4) загальною сукупністю;
5) фрагментарною сукупністю.
3. Назвіть найважливішу умову об'єднання одиниць спостереження у вибіркову сукупність:
1) репрезентативність;
2) однорідність;
3) різноманітність;
4) конгруентність;
5)випадковість.
4. Які помилки виникають внаслідок того, що вибіркова сукупність не відтворює точності характеристики генеральної сукупності?
1)помилки вибірки;
2)помилки реєстрації;
3)ненавмисні помилки;
4) логічні помилки;
5) систематичні помилки.
5. Можливе розбіжність характеристик вибіркової та генеральної сукупностей вимірюють:
1) середнім квадратичним відхиленням;
2) дисперсією;
3) помилкою вибірки;
4) кореляцією;
5) помилкою реєстрації.
6. Чим забезпечується репрезентативність вибірки?
1)випадковим відбором;
2) помилкою вибірки;
3) граничною помилкою;
4) середнім квадратичним відхиленням;
5) випадковою помилкою.
7. Що таке серійний відбір?
1) відбір копі-пар одиниць спостереження;
2) відбір одиниць спостережень за допомогою генератора випадкових чисел;
3) відбір цілих груп одиниць спостереження;
4) багатоступінчастий відбір одиниць спостереження;
5) типологічний відбір одиниць спостереження.
8. Вкажіть формулу для обчислення граничної помилки вибірки:

9. У яких випадках використається когортний метод?
1) для вивчення захворюваності населення;
2) аналізу причинно-наслідкових зв'язків захворюваності та факторів ризику;
3) розробки цільових медико-соціальних програм;
4) вивчення статистичної сукупності щодо однорідних груп осіб, об'єднаних настанням певної демографічної події;
5) аналізу соціальної ефективності діяльності системи охорони здоров'я.
10. Необхідний обсяг вибірки, що забезпечує задану точність, визначається за такою формулою:

1.4.6. Завдання для самостійного вирішення
Завдання 1
Початкові дані
1.При попередньому вивченні середнього зростання школярів отримані такі дані: М = 132 см, σ = 3,18 см, μ = 0,13 см.
2.При попередньому вивченні захворюваності міського населення отримано показник 980 0/00.
Завдання
Визначити необхідний обсяг вибірки:
1)для отримання достовірних результатів щодо середнього зростання школярів при коефіцієнті довіри t = 3 та граничній помилці Δ = 0,5 см;
2)для отримання достовірних результатів при поглибленому вивченні захворюваності міського населення за коефіцієнта довіри t
Завдання 2
Початкові дані
1.При попередньому вивченні середньої частоти серцевих скорочень (ЧСС) у підлітків після фізичного навантаження отримані такі дані: М = 110 за хвилину, σ = 10,0 за хвилину, μ = 4,0 за хвилину.
2.При вивченні частоти народження осіб, які мають надмірну масу тіла, отримано показник 528,4 0 / 00 .
Завдання
Визначити необхідний обсяг вибірки:
1)для отримання достовірних результатів щодо середньої ЧСС у підлітків після фізичного навантаження при коефіцієнті довіри t = 3 та граничній помилці Δ = 0,5 за хвилину;
2) для отримання достовірних результатів при вивченні частоти народження осіб, які мають надмірну масу тіла, при коефіцієнті довіри t = 2 та граничній помилці Δ = 2.
Завдання 3
Початкові дані
1. При попередньому вивченні середньої тривалості тимчасової непрацездатності хворих, які проходили амбулаторне лікування з приводу хвороб органів дихання, було отримано такі дані: М = 12 днів, σ = 2,15 дні, μ = 0,2 дні.
2. При попередньому вивченні частота порушення зору осіб, які тривалий час працюють за комп'ютером, відзначена значенням
257, 0 / 00 . Завдання
Визначити необхідний обсяг вибірки:
1)для отримання достовірних результатів щодо середньої тривалості тимчасової непрацездатності хворих, які проходили амбулаторне лікування щодо хвороб органів дихання, при коефіцієнті довіри t = 3 та граничній помилці Δ = 0,5 дня;
