विविधता श्रृंखला की परिभाषा भिन्नता और भिन्नता श्रृंखला, विविधता की सीमा
अध्ययन किए गए मूल्यों का समूह यह प्रयोगया परिमाण (वृद्धि या कमी) द्वारा रैंक किए गए पैरामीटर के अवलोकन को भिन्नता श्रृंखला कहा जाता है।
मान लेते हैं कि हमने ऊपरी रक्तचाप की सीमा प्राप्त करने के लिए दस रोगियों के रक्तचाप को मापा: सिस्टोलिक दबाव, यानी केवल एक संख्या।
कल्पना कीजिए कि 10 अवलोकनों में धमनी सिस्टोलिक दबाव की टिप्पणियों (सांख्यिकीय जनसंख्या) की एक श्रृंखला का निम्न रूप है (तालिका 1):
तालिका एक
अवयव भिन्नता श्रृंखलाविकल्प कहलाते हैं। वेरिएंट अध्ययन किए जा रहे गुण के संख्यात्मक मूल्य का प्रतिनिधित्व करते हैं।
प्रेक्षणों के एक सांख्यिकीय समुच्चय से परिवर्तनशील श्रृंखला का निर्माण पूरे समुच्चय की विशेषताओं को समझने की दिशा में केवल पहला कदम है। अगला, अध्ययन किए गए मात्रात्मक विशेषता (रक्त प्रोटीन का औसत स्तर, रोगियों का औसत वजन, संज्ञाहरण की शुरुआत का औसत समय, आदि) का औसत स्तर निर्धारित करना आवश्यक है।
औसत स्तर को मापदंड का उपयोग करके मापा जाता है जिसे औसत कहा जाता है। औसत मूल्य - सामान्यीकरण संख्यात्मक विशेषतागुणात्मक रूप से सजातीय मूल्य, एक विशेषता के अनुसार संपूर्ण सांख्यिकीय आबादी की विशेषता। औसत मान उस सामान्य को व्यक्त करता है जो अवलोकनों के दिए गए सेट में विशेषता की विशेषता है।
सामान्य उपयोग में तीन प्रकार के औसत होते हैं: बहुलक (), माध्यिका () और अंकगणितीय माध्य ()।
कोई परिभाषित करना मध्यम आकारअलग-अलग टिप्पणियों के परिणामों का उपयोग करना आवश्यक है, उन्हें भिन्नता श्रृंखला (तालिका 2) के रूप में लिखना।
फ़ैशन- वह मान जो प्रेक्षणों की श्रृंखला में सबसे अधिक बार आता है। हमारे उदाहरण में, मोड = 120। यदि भिन्नता श्रृंखला में कोई दोहराव वाले मान नहीं हैं, तो वे कहते हैं कि कोई मोड नहीं है। यदि कई मानों को समान संख्या में दोहराया जाता है, तो उनमें से सबसे छोटे को मोड के रूप में लिया जाता है।
मंझला- वितरण को दो समान भागों में विभाजित करने वाला मान, आरोही या अवरोही क्रम में क्रमबद्ध प्रेक्षणों की श्रृंखला का केंद्रीय या माध्य मान। इसलिए, यदि चर श्रृंखला में 5 मान हैं, तो इसकी माध्यिका चर श्रृंखला के तीसरे सदस्य के बराबर है, यदि श्रृंखला में सम संख्यासदस्य हैं, तो माध्यिका इसके दो केंद्रीय प्रेक्षणों का अंकगणितीय माध्य है, अर्थात यदि श्रृंखला में 10 प्रेक्षण हैं, तो माध्यिका 5 और 6 प्रेक्षणों के अंकगणितीय माध्य के बराबर है। हमारे उदाहरण में।
मोड और माध्यिका की एक महत्वपूर्ण विशेषता पर ध्यान दें: उनके मान चरम वेरिएंट के संख्यात्मक मूल्यों से प्रभावित नहीं होते हैं।
अंकगणित औसतसूत्र द्वारा गणना:
-वें प्रेक्षण में प्रेक्षित मान कहाँ है, और प्रेक्षणों की संख्या है। हमारे मामले के लिए।
अंकगणितीय माध्य में तीन गुण होते हैं:
विविधता श्रृंखला में मध्य वाला मध्य स्थान रखता है। सख्ती से सममित पंक्ति में।
औसत एक सामान्यीकरण मूल्य और यादृच्छिक उतार-चढ़ाव है, व्यक्तिगत डेटा में अंतर औसत के पीछे दिखाई नहीं दे रहे हैं। यह उस विशिष्ट को दर्शाता है जो संपूर्ण जनसंख्या की विशेषता है।
माध्य से सभी प्रकारों के विचलन का योग शून्य के बराबर है: . माध्य से भिन्न का विचलन इंगित किया गया है।
भिन्नता श्रृंखला में वेरिएंट और उनकी संबंधित आवृत्तियाँ होती हैं। प्राप्त दस मूल्यों में से, संख्या 120 का सामना 6 बार, 115 - 3 बार, 125 - 1 बार हुआ। आवृत्ति () - जनसंख्या में व्यक्तिगत विकल्पों की पूर्ण संख्या, यह दर्शाता है कि यह कितनी बार होता है इस विकल्पविविधता श्रृंखला में।
भिन्नता श्रृंखला सरल (आवृत्ति = 1) या समूहीकृत छोटा, 3-5 विकल्प प्रत्येक हो सकता है। एक साधारण श्रृंखला का उपयोग कम संख्या में टिप्पणियों (), समूहीकृत - बड़ी संख्या में टिप्पणियों () के साथ किया जाता है।
सांख्यिकीय विश्लेषण में एक विशेष स्थान अध्ययन की गई विशेषता या घटना के औसत स्तर के निर्धारण से संबंधित है। किसी विशेषता का औसत स्तर औसत मानों द्वारा मापा जाता है।
औसत मूल्य अध्ययन किए गए गुण के सामान्य मात्रात्मक स्तर की विशेषता है और यह सांख्यिकीय आबादी की एक समूह संपत्ति है। वह समतल करती है, कमजोर करती है यादृच्छिक विचलनएक दिशा या किसी अन्य में व्यक्तिगत अवलोकन और अध्ययन के तहत विशेषता की मुख्य, विशिष्ट संपत्ति पर प्रकाश डाला गया है।
औसत का व्यापक रूप से उपयोग किया जाता है:
1. जनसंख्या की स्वास्थ्य स्थिति का आकलन करने के लिए: विशेषताएँ शारीरिक विकास(ऊंचाई, वजन, छाती की परिधि, आदि), विभिन्न रोगों की व्यापकता और अवधि की पहचान करना, जनसांख्यिकीय संकेतकों (प्राकृतिक जनसंख्या आंदोलन, औसत जीवन प्रत्याशा, जनसंख्या प्रजनन, औसत जनसंख्या, आदि) का विश्लेषण करना।
2. चिकित्सा संस्थानों, चिकित्सा कर्मियों की गतिविधियों का अध्ययन करना और उनके काम की गुणवत्ता का आकलन करना, योजना बनाना और जनसंख्या की जरूरतों का निर्धारण करना विभिन्न प्रकार केचिकित्सा देखभाल (आवेदन की औसत संख्या या प्रति निवासी प्रति वर्ष दौरे, अस्पताल में रोगी के रहने की औसत अवधि, रोगी की परीक्षा की औसत अवधि, डॉक्टरों, बिस्तरों आदि के साथ औसत प्रावधान)।
3. सैनिटरी और महामारी विज्ञान की स्थिति (कार्यशाला में हवा की औसत धूल, प्रति व्यक्ति औसत क्षेत्र, प्रोटीन, वसा और कार्बोहाइड्रेट आदि की औसत खपत) को चिह्नित करने के लिए।
4. सामाजिक-स्वच्छ, नैदानिक, प्रायोगिक अध्ययनों में एक चयनात्मक अध्ययन के परिणामों की विश्वसनीयता स्थापित करने के लिए, प्रयोगशाला डेटा के प्रसंस्करण में, आदर्श और विकृति विज्ञान में चिकित्सा और शारीरिक मापदंडों का निर्धारण करना।
भिन्नता श्रृंखला के आधार पर औसत मूल्यों की गणना की जाती है। रूपांतर श्रृंखला- यह एक गुणात्मक रूप से सजातीय सांख्यिकीय सेट है, जिसकी अलग-अलग इकाइयाँ अध्ययन की गई विशेषता या घटना के मात्रात्मक अंतर को दर्शाती हैं।
मात्रात्मक भिन्नता दो प्रकार की हो सकती है: असतत (असतत) और निरंतर।
एक विच्छिन्न (असतत) चिह्न केवल एक पूर्णांक के रूप में व्यक्त किया जाता है और इसमें कोई नहीं हो सकता मध्यवर्ती मान(उदाहरण के लिए, विज़िट की संख्या, साइट की जनसंख्या, परिवार में बच्चों की संख्या, अंकों में रोग की गंभीरता आदि)।
एक निरंतर संकेत कुछ सीमाओं के भीतर कुछ मूल्यों पर ले सकता है, जिसमें भिन्नात्मक भी शामिल हैं, और केवल लगभग व्यक्त किया जाता है (उदाहरण के लिए, वजन - वयस्कों के लिए आप खुद को किलोग्राम तक सीमित कर सकते हैं, और नवजात शिशुओं के लिए - ग्राम; ऊंचाई, रक्तचाप, समय एक मरीज को देखने पर खर्च किया, और आदि)।
भिन्नता श्रृंखला में शामिल प्रत्येक व्यक्तिगत विशेषता या घटना के डिजिटल मूल्य को एक संस्करण कहा जाता है और इसे पत्र द्वारा इंगित किया जाता है वी . उदाहरण के लिए, गणितीय साहित्य में अन्य संकेत भी हैं एक्स या वाई
एक परिवर्तनशील श्रृंखला, जहाँ प्रत्येक विकल्प को एक बार इंगित किया जाता है, सरल कहलाती है।इन्हीं पंक्तियों का प्रयोग सर्वाधिक होता है सांख्यिकीय कार्यकंप्यूटर डेटा प्रोसेसिंग के मामले में।
टिप्पणियों की संख्या में वृद्धि के साथ, एक नियम के रूप में, वैरिएंट के दोहराए गए मान हैं। इस मामले में बनाता है समूहीकृत भिन्नता श्रृंखला, जहां दोहराव की संख्या इंगित की गई है (आवृत्ति, पत्र द्वारा चिह्नित " आर »).
रैंक भिन्नता श्रृंखलाआरोही या अवरोही क्रम में व्यवस्थित विकल्प होते हैं। रैंकिंग के साथ सरल और समूहीकृत श्रृंखला दोनों की रचना की जा सकती है।
अंतराल भिन्नता श्रृंखलाबहुत बड़ी संख्या में अवलोकन इकाइयों (1000 से अधिक) के साथ कंप्यूटर का उपयोग किए बिना की गई बाद की गणनाओं को सरल बनाने के लिए बनाया गया है।
निरंतर भिन्नता श्रृंखलाभिन्न मान शामिल होते हैं, जो कोई भी मान हो सकते हैं.
यदि भिन्न श्रृंखला में गुण (विकल्प) के मान अलग-अलग विशिष्ट संख्याओं के रूप में दिए जाते हैं, तो ऐसी श्रृंखला कहलाती है अलग.
सामान्य विशेषताएँभिन्नता श्रृंखला में परिलक्षित गुण के मान औसत मान हैं। उनमें से, सबसे अधिक उपयोग किया जाता है: अंकगणितीय माध्य एम,फ़ैशन एमओऔर मंझला मुझे।इनमें से प्रत्येक विशेषता अद्वितीय है। वे एक दूसरे को प्रतिस्थापित नहीं कर सकते हैं, और केवल समग्र रूप से, पूरी तरह से और संक्षिप्त रूप में, भिन्नता श्रृंखला की विशेषताएं हैं।
फ़ैशन (मो) सबसे अधिक बार होने वाले विकल्पों के मान को नाम दें।
मंझला (मुझे) रेंजेड वेरिएबल सीरीज़ को आधे में विभाजित करने वाले वेरिएंट का मान है (माध्यिका के प्रत्येक तरफ वेरिएंट का आधा हिस्सा है)। दुर्लभ मामलों में, जब एक सममित भिन्नता श्रृंखला होती है, तो बहुलक और माध्य एक दूसरे के बराबर होते हैं और अंकगणितीय माध्य के मान के साथ मेल खाते हैं।
भिन्न मानों की सबसे विशिष्ट विशेषता है अंकगणित औसतमूल्य( एम ). गणितीय साहित्य में, यह निरूपित है .
अंकगणित औसत (एम, ) अध्ययन की गई घटनाओं की एक निश्चित विशेषता की एक सामान्य मात्रात्मक विशेषता है, जो गुणात्मक रूप से सजातीय सांख्यिकीय सेट बनाती है। सरल अंकगणितीय माध्य और भारित माध्य में अंतर स्पष्ट कीजिए। सरल अंकगणितीय माध्य की गणना सभी विकल्पों को जोड़कर और इस भिन्नता श्रृंखला में शामिल विकल्पों की कुल संख्या से विभाजित करके एक सरल भिन्नता श्रृंखला के लिए की जाती है। गणना सूत्र के अनुसार की जाती है:
 ,
,
कहाँ पे: एम - सरल अंकगणितीय माध्य;
Σ वी - राशि विकल्प;
एन- टिप्पणियों की संख्या।
समूहीकृत भिन्नता श्रृंखला में, एक भारित अंकगणितीय माध्य निर्धारित किया जाता है। इसकी गणना का सूत्र:
 ,
,
कहाँ पे: एम - अंकगणितीय भारित औसत;
Σ वीपी - उनकी आवृत्तियों पर एक संस्करण के उत्पादों का योग;
एन- टिप्पणियों की संख्या।
बड़ी संख्या में टिप्पणियों के साथ, मैन्युअल गणना के मामले में, क्षणों की विधि का उपयोग किया जा सकता है।
अंकगणितीय माध्य में निम्नलिखित गुण होते हैं:
माध्य से भिन्न के विचलन का योग ( Σ डी ) शून्य के बराबर है (तालिका 15 देखें);
जब एक ही कारक (भाजक) द्वारा सभी विकल्पों को गुणा (विभाजित) किया जाता है, तो अंकगणितीय माध्य को उसी कारक (विभाजक) से गुणा (विभाजित) किया जाता है;
यदि आप सभी विकल्पों में समान संख्या जोड़ते (घटाते) हैं, तो अंकगणितीय माध्य उसी संख्या से बढ़ता (घटता) है।
अंकगणितीय औसत, स्वयं द्वारा लिया गया, श्रृंखला की परिवर्तनशीलता को ध्यान में रखे बिना, जिससे उनकी गणना की जाती है, भिन्नता श्रृंखला के गुणों को पूरी तरह से प्रतिबिंबित नहीं कर सकती है, खासकर जब अन्य औसत के साथ तुलना आवश्यक हो। मूल्य के करीब का मतलब श्रृंखला से प्राप्त किया जा सकता है बदलती डिग्रियांबिखरना। मात्रात्मक विशेषताओं के संदर्भ में व्यक्तिगत विकल्प एक-दूसरे के जितने करीब होंगे, उतना ही कम होगा बिखराव (उतार-चढ़ाव, परिवर्तनशीलता)श्रृंखला, अधिक विशिष्ट इसका औसत।
मुख्य पैरामीटर जो किसी विशेषता की परिवर्तनशीलता का आकलन करने की अनुमति देते हैं:
· दायरा;
आयाम;
· मानक विचलन;
· भिन्नता का गुणांक।
लगभग, एक विशेषता के उतार-चढ़ाव को भिन्नता श्रृंखला के दायरे और आयाम से आंका जा सकता है। श्रेणी श्रृंखला में अधिकतम (वी अधिकतम) और न्यूनतम (वी मिनट) विकल्प इंगित करती है। आयाम (A m) इन विकल्पों के बीच का अंतर है: A m = V max - V min ।
परिवर्तनशील श्रृंखला के उतार-चढ़ाव का मुख्य, आम तौर पर स्वीकृत उपाय हैं फैलाव (डी ). लेकिन अधिक सुविधाजनक पैरामीटर का सबसे अधिक उपयोग किया जाता है, जिसकी गणना विचरण के आधार पर की जाती है - मानक विचलन ( σ ). यह विचलन मान को ध्यान में रखता है ( डी ) अपने अंकगणितीय माध्य से भिन्नता श्रृंखला के प्रत्येक संस्करण का ( डी = वी - एम ).
चूंकि माध्य से भिन्न का विचलन धनात्मक और ऋणात्मक हो सकता है, जब अभिव्यक्त किया जाता है तो वे "0" (S) मान देते हैं डी = 0). इससे बचने के लिए, विचलन मान ( डी) को दूसरी शक्ति तक बढ़ाया जाता है और औसत किया जाता है। इस प्रकार, परिवर्तनशील श्रृंखला का विचरण अंकगणितीय माध्य से भिन्न के विचलन का औसत वर्ग है और इसकी गणना सूत्र द्वारा की जाती है:
 .
.
यह परिवर्तनशीलता की सबसे महत्वपूर्ण विशेषता है और इसका उपयोग कई सांख्यिकीय परीक्षणों की गणना के लिए किया जाता है।
क्योंकि विचरण को विचलन के वर्ग के रूप में व्यक्त किया जाता है, इसका मान अंकगणितीय माध्य की तुलना में उपयोग नहीं किया जा सकता है। इन उद्देश्यों के लिए इसका उपयोग किया जाता है मानक विचलन, जिसे "सिग्मा" चिह्न द्वारा दर्शाया जाता है ( σ ). यह समान इकाइयों में अंकगणित माध्य से भिन्नता श्रृंखला के सभी प्रकारों के औसत विचलन को दर्शाता है, इसलिए उन्हें एक साथ उपयोग किया जा सकता है।
मानक विचलन सूत्र द्वारा निर्धारित किया जाता है:

यह सूत्र टिप्पणियों की संख्या के लिए लागू होता है ( एन ) 30 से अधिक है। छोटी संख्या के साथ एन मानक विचलन के मान में गणितीय पूर्वाग्रह से जुड़ी त्रुटि होगी ( एन - एक)। इस संबंध में, मानक विचलन की गणना के सूत्र में इस तरह के पूर्वाग्रह को ध्यान में रखकर अधिक सटीक परिणाम प्राप्त किया जा सकता है:
मानक विचलन (एस ) यादृच्छिक चर के मानक विचलन का अनुमान है एक्सउसके बारे में गणितीय अपेक्षाइसके विचरण के निष्पक्ष अनुमान के आधार पर।
मूल्यों के लिए एन > 30 मानक विचलन ( σ ) और मानक विचलन ( एस ) एक ही हो जाएगा ( σ=s ). इसलिए, अधिकांश व्यावहारिक नियमावली में, इन मानदंडों को अलग-अलग अर्थों के रूप में माना जाता है।एक कार्यक्रम में एक्सेल गणनामानक विचलन =STDEV(श्रेणी) के साथ किया जा सकता है। और मानक विचलन की गणना करने के लिए, आपको एक उपयुक्त सूत्र बनाने की आवश्यकता है।
मूल माध्य वर्ग या मानक विचलन आपको यह निर्धारित करने की अनुमति देता है कि किसी विशेषता का मान माध्य मान से कितना भिन्न हो सकता है। मान लीजिए कि दो शहरों में औसत दैनिक तापमान समान है गर्मी की अवधि. इनमें से एक शहर तट पर और दूसरा महाद्वीप पर स्थित है। यह ज्ञात है कि तट पर स्थित शहरों में, अंतर्देशीय स्थित शहरों की तुलना में दिन के तापमान में अंतर कम होता है। इसलिए, तटीय शहर के पास दिन के तापमान का मानक विचलन दूसरे शहर की तुलना में कम होगा। व्यवहार में, इसका मतलब है कि महाद्वीप पर स्थित एक शहर में प्रत्येक विशेष दिन का औसत हवा का तापमान तट पर एक शहर की तुलना में औसत से अधिक भिन्न होगा। इसके अलावा, मानक विचलन संभावना के आवश्यक स्तर के साथ औसत से संभावित तापमान विचलन का अनुमान लगाना संभव बनाता है।
संभाव्यता के सिद्धांत के अनुसार, सामान्य वितरण कानून का पालन करने वाली घटनाओं में, अंकगणितीय माध्य, मानक विचलन और विकल्पों के मूल्यों के बीच एक सख्त संबंध होता है ( तीन सिग्मा नियम). उदाहरण के लिए, एक चर विशेषता के 68.3% मान M ± 1 के भीतर हैं σ , 95.5% - एम ± 2 के भीतर σ और 99.7% - एम ± 3 के भीतर σ .
मानक विचलन का मूल्य विविधता श्रृंखला और अध्ययन के तहत समूह की एकरूपता की प्रकृति का न्याय करना संभव बनाता है। यदि मानक विचलन का मान छोटा है, तो यह अध्ययन के तहत घटना की पर्याप्त उच्च एकरूपता को इंगित करता है। इस मामले में अंकगणितीय माध्य को इस परिवर्तनशील श्रृंखला की काफी विशेषता के रूप में पहचाना जाना चाहिए। हालांकि, एक बहुत छोटा सिग्मा प्रेक्षणों के एक कृत्रिम चयन के बारे में सोचता है। एक बहुत बड़े सिग्मा के साथ, अंकगणित माध्य भिन्नता श्रृंखला को कुछ हद तक दर्शाता है, जो अध्ययन किए गए गुण या घटना या अध्ययन समूह की विषमता की एक महत्वपूर्ण परिवर्तनशीलता को इंगित करता है। हालांकि, मानक विचलन के मूल्य की तुलना केवल समान आयाम के संकेतों के लिए ही संभव है। दरअसल, अगर हम नवजात शिशुओं और वयस्कों के वजन की विविधता की तुलना करते हैं, तो हम हमेशा वयस्कों में उच्च सिग्मा मान प्राप्त करेंगे।
विभिन्न आयामों की विशेषताओं की परिवर्तनशीलता की तुलना का उपयोग करके किया जा सकता है गुणांक का परिवर्तन. यह विविधता को माध्य के प्रतिशत के रूप में व्यक्त करता है, जो विभिन्न लक्षणों की तुलना करने की अनुमति देता है। में भिन्नता का गुणांक चिकित्सा साहित्यसे चिह्नित " से ", और गणितीय में" वि» और सूत्र द्वारा गणना:
 .
.
10% से कम भिन्नता के गुणांक के मान छोटे बिखरने का संकेत देते हैं, 10 से 20% तक - औसत के बारे में, 20% से अधिक - अंकगणितीय माध्य के आसपास एक मजबूत बिखरने के बारे में।
अंकगणितीय माध्य की गणना आमतौर पर डेटा से की जाती है नमूना चयन ढांचा. यादृच्छिक घटना के प्रभाव में बार-बार अध्ययन के साथ, अंकगणितीय माध्य बदल सकता है। यह इस तथ्य के कारण है कि, एक नियम के रूप में, अवलोकन की संभावित इकाइयों का केवल एक हिस्सा, यानी एक नमूना आबादी की जांच की जाती है। अध्ययन के तहत घटना का प्रतिनिधित्व करने वाली सभी संभावित इकाइयों के बारे में जानकारी संपूर्ण अध्ययन करके प्राप्त की जा सकती है आबादी, जो हमेशा संभव नहीं होता। इसी समय, प्रायोगिक डेटा को सामान्य बनाने के लिए, सामान्य आबादी में औसत का मूल्य रुचि का है। इसलिए, अध्ययन के तहत घटना के बारे में एक सामान्य निष्कर्ष तैयार करने के लिए, नमूना जनसंख्या के आधार पर प्राप्त परिणामों को सांख्यिकीय विधियों द्वारा सामान्य जनसंख्या में स्थानांतरित किया जाना चाहिए।
नमूना अध्ययन और सामान्य आबादी के बीच समझौते की डिग्री निर्धारित करने के लिए, त्रुटि की मात्रा का अनुमान लगाना आवश्यक है जो अनिवार्य रूप से उत्पन्न होती है जब चयनात्मक अवलोकन. ऐसी त्रुटि कहलाती है प्रतिनिधित्व त्रुटि"या" अंकगणितीय माध्य की औसत त्रुटि "। यह वास्तव में नमूने से प्राप्त औसत के बीच का अंतर है सांख्यिकीय अवलोकन, और समान मूल्य जो एक ही वस्तु के निरंतर अध्ययन में प्राप्त होंगे, अर्थात। सामान्य आबादी का अध्ययन करते समय। चूंकि नमूना माध्य एक यादृच्छिक चर है, इस तरह का पूर्वानुमान शोधकर्ता के लिए स्वीकार्य स्तर की संभाव्यता के साथ बनाया जाता है। चिकित्सा अनुसंधान में, यह कम से कम 95% है।
प्रतिनिधित्व त्रुटि को पंजीकरण त्रुटियों या ध्यान त्रुटियों (गलत छाप, गलत गणना, गलत प्रिंट, आदि) के साथ भ्रमित नहीं होना चाहिए, जिसे प्रयोग में उपयोग की जाने वाली पर्याप्त पद्धति और उपकरणों द्वारा कम किया जाना चाहिए।
अभ्यावेदन की त्रुटि का परिमाण नमूना आकार और विशेषता की परिवर्तनशीलता दोनों पर निर्भर करता है। कैसे अधिक संख्याअवलोकन, नमूना सामान्य आबादी के जितना करीब होगा और त्रुटि उतनी ही कम होगी। सुविधा जितनी अधिक परिवर्तनशील होगी, सांख्यिकीय त्रुटि उतनी ही अधिक होगी।
व्यवहार में, परिवर्तनशील श्रृंखला में प्रतिनिधित्व त्रुटि को निर्धारित करने के लिए निम्न सूत्र का उपयोग किया जाता है:
 ,
,
कहाँ पे: एम - प्रतिनिधित्व त्रुटि;
σ - मानक विचलन;
एननमूने में टिप्पणियों की संख्या है।
यह सूत्र से देखा जा सकता है कि आकार औसत त्रुटिमानक विचलन के सीधे आनुपातिक है, अर्थात, अध्ययन के तहत विशेषता की परिवर्तनशीलता, और टिप्पणियों की संख्या के वर्गमूल के व्युत्क्रमानुपाती।
सापेक्ष मूल्यों की गणना के आधार पर सांख्यिकीय विश्लेषण करते समय, भिन्नता श्रृंखला का निर्माण अनिवार्य नहीं है। इस मामले में, सापेक्ष संकेतकों के लिए औसत त्रुटि का निर्धारण सरलीकृत सूत्र का उपयोग करके किया जा सकता है:
 ,
,
कहाँ पे: आर- मूल्य सापेक्ष संकेतक, प्रतिशत, पीपीएम, आदि के रूप में व्यक्त किया गया;
क्यू- पी का व्युत्क्रम और (1-पी), (100-पी), (1000-पी), आदि के रूप में व्यक्त किया जाता है, जिसके आधार पर सूचक की गणना की जाती है;
एननमूने में टिप्पणियों की संख्या है।
हालाँकि, सापेक्ष मूल्यों के लिए प्रतिनिधित्व त्रुटि की गणना के लिए संकेतित सूत्र केवल तभी लागू किया जा सकता है जब संकेतक का मान उसके आधार से कम हो। गहन संकेतकों की गणना के कई मामलों में, यह स्थिति पूरी नहीं होती है, और सूचक को 100% या 1000%o से अधिक की संख्या के रूप में व्यक्त किया जा सकता है। ऐसी स्थिति में, एक भिन्नता श्रृंखला का निर्माण किया जाता है और मानक विचलन के आधार पर औसत मूल्यों के सूत्र का उपयोग करके प्रतिनिधित्व त्रुटि की गणना की जाती है।
सामान्य आबादी में अंकगणितीय माध्य के मूल्य का पूर्वानुमान दो मूल्यों के संकेत के साथ किया जाता है - न्यूनतम और अधिकतम। संभावित विचलन के ये चरम मूल्य, जिसके भीतर सामान्य आबादी के वांछित औसत मूल्य में उतार-चढ़ाव हो सकता है, "कहा जाता है" आत्मविश्वास की सीमाएँ».
संभाव्यता सिद्धांत के अभिधारणाओं ने सिद्ध किया कि 99.7% की संभावना के साथ एक सुविधा के सामान्य वितरण के साथ, माध्य के विचलन के चरम मान नहीं होंगे अधिक मूल्यप्रतिनिधित्व की त्रुटि को तिगुना करें ( एम ± 3 एम ); 95.5% में - औसत मूल्य की दोगुनी औसत त्रुटि के मूल्य से अधिक नहीं ( एम ± 2 एम ); 68.3% में - एक औसत त्रुटि के मान से अधिक नहीं ( एम ± 1 एम ) (चित्र 9)।

| पी% |
चावल। 9. संभाव्यता घनत्व सामान्य वितरण.
ध्यान दें कि उपरोक्त कथन केवल उस विशेषता के लिए सत्य है जो सामान्य गॉसियन वितरण कानून का पालन करता है।
अधिकांश प्रयोगात्मक अध्ययन, जिनमें चिकित्सा के क्षेत्र में शामिल हैं, माप से जुड़े हैं, जिसके परिणाम किसी दिए गए अंतराल में लगभग कोई भी मान ले सकते हैं, इसलिए, एक नियम के रूप में, उन्हें निरंतर यादृच्छिक चर के मॉडल द्वारा वर्णित किया जाता है। इस संबंध में, अधिकांश सांख्यिकीय विधियां निरंतर वितरण पर विचार करती हैं। इनमें से एक वितरण, जिसमें एक मौलिक भूमिका है गणितीय सांख्यिकी, है सामान्य, या गॉसियन, वितरण.
यह कई कारणों से है।
1. सबसे पहले, सामान्य वितरण का उपयोग करके कई प्रायोगिक अवलोकनों का सफलतापूर्वक वर्णन किया जा सकता है। यह तुरंत ध्यान दिया जाना चाहिए कि अनुभवजन्य डेटा का कोई वितरण नहीं है जो बिल्कुल सामान्य होगा, क्योंकि सामान्य रूप से वितरित यादृच्छिक चर से सीमा में है, जो अभ्यास में कभी नहीं होता है। हालांकि, सामान्य वितरण अक्सर एक अच्छा सन्निकटन होता है।
क्या वजन, ऊंचाई और मानव शरीर के अन्य शारीरिक मापदंडों का मापन किया जाता है - हर जगह परिणाम बहुत प्रभावित होते हैं बड़ी संख्यायादृच्छिक कारक (प्राकृतिक कारण और माप त्रुटियां)। और, एक नियम के रूप में, इनमें से प्रत्येक कारक का प्रभाव नगण्य है। अनुभव बताता है कि ऐसे मामलों में परिणाम लगभग सामान्य रूप से वितरित किए जाएंगे।
2. बाद वाले की मात्रा में वृद्धि के साथ यादृच्छिक नमूने से जुड़े कई वितरण सामान्य हो जाते हैं।
3. सामान्य वितरण अन्य के अनुमानित विवरण के रूप में उपयुक्त है निरंतर वितरण(उदाहरण के लिए, असममित)।
4. सामान्य वितरण में कई अनुकूल गणितीय गुण होते हैं, जो बड़े पैमाने पर आँकड़ों में इसके व्यापक उपयोग को सुनिश्चित करते हैं।
इसी समय, यह ध्यान दिया जाना चाहिए कि चिकित्सा डेटा में कई प्रायोगिक वितरण हैं जिन्हें सामान्य वितरण मॉडल द्वारा वर्णित नहीं किया जा सकता है। ऐसा करने के लिए, आँकड़ों ने ऐसे तरीके विकसित किए हैं जिन्हें आमतौर पर "नॉनपैमेट्रिक" कहा जाता है।
पसंद सांख्यिकीय विधि, जो किसी विशेष प्रयोग के डेटा को संसाधित करने के लिए उपयुक्त है, इस आधार पर बनाया जाना चाहिए कि प्राप्त डेटा सामान्य वितरण कानून से संबंधित है या नहीं। सामान्य वितरण कानून के संकेत के अधीनता के लिए परिकल्पना परीक्षण आवृत्ति वितरण (ग्राफ) के हिस्टोग्राम के साथ-साथ कई सांख्यिकीय मानदंडों का उपयोग करके किया जाता है। उनमें से:
विषमता मानदंड ( बी );
कर्टोसिस की जाँच के लिए मानदंड ( जी );
शापिरो-विल्क्स कसौटी ( डब्ल्यू ) .
प्रत्येक पैरामीटर के लिए डेटा के वितरण की प्रकृति का विश्लेषण (इसे वितरण की सामान्यता के लिए एक परीक्षण भी कहा जाता है) किया जाता है। सामान्य कानून के साथ पैरामीटर वितरण के अनुपालन का आत्मविश्वास से न्याय करने के लिए, पर्याप्त रूप से बड़ी संख्या में अवलोकन इकाइयों (कम से कम 30 मान) की आवश्यकता होती है।
एक सामान्य वितरण के लिए, तिरछापन और कुर्तोसिस मानदंड 0 का मान लेते हैं। यदि वितरण को दाईं ओर स्थानांतरित किया जाता है बी > 0 (सकारात्मक विषमता), के साथ बी < 0 - график распределения смещен влево (отрицательная асимметрия). Критерий асимметрии проверяет форму кривой распределения. В случае सामान्य कानून जी = 0। पर जी > 0 वितरण वक्र तेज है यदि जी < 0 пик более сглаженный, чем функция нормального распределения.
शापिरो-विल्क्स परीक्षण का उपयोग करके सामान्यता के लिए परीक्षण करने के लिए, आवश्यक स्तर पर महत्व के स्तर पर सांख्यिकीय तालिकाओं का उपयोग करके और अवलोकन की इकाइयों की संख्या (स्वतंत्रता की डिग्री) के आधार पर इस मानदंड के मूल्य का पता लगाना आवश्यक है। परिशिष्ट 1। इस मानदंड के छोटे मूल्यों के लिए, एक नियम के रूप में, सामान्यता की परिकल्पना को खारिज कर दिया गया है डब्ल्यू <0,8.
आइए विभिन्न नमूना मूल्यों को कॉल करें विकल्पमूल्यों की एक श्रृंखला और निरूपित करें: एक्स 1 , एक्स 2,…। सबसे पहले तो बनाते हैं लेकरविकल्प, अर्थात्। उन्हें आरोही या अवरोही क्रम में व्यवस्थित करें। प्रत्येक विकल्प के लिए, अपना स्वयं का वजन इंगित किया गया है, अर्थात। एक संख्या जो कुल जनसंख्या में इस विकल्प के योगदान को दर्शाती है। फ़्रीक्वेंसी या फ़्रीक्वेंसी वज़न के रूप में कार्य करती हैं।
आवृत्ति एन मैं विकल्प एक्स मैंमाना नमूना आबादी में यह विकल्प कितनी बार होता है यह दिखाने के लिए एक संख्या कहा जाता है।
आवृत्ति या सापेक्ष आवृत्ति मैं विकल्प एक्स मैंसभी वेरिएंट की आवृत्तियों के योग के लिए एक संस्करण की आवृत्ति के अनुपात के बराबर संख्या कहलाती है। आवृत्ति दर्शाती है कि नमूना जनसंख्या की इकाइयों के किस हिस्से में एक दिया गया संस्करण है।
आरोही (या अवरोही) क्रम में लिखे गए उनके संबंधित वजन (आवृत्ति या आवृत्तियों) के साथ विकल्पों का क्रम कहलाता है परिवर्तनशील श्रृंखला.
परिवर्तनशील श्रृंखला असतत और अंतराल हैं।
असतत परिवर्तनशील श्रृंखला के लिए, विशेषता के बिंदु मान निर्दिष्ट किए जाते हैं, अंतराल श्रृंखला के लिए, विशेषता मान अंतराल के रूप में निर्दिष्ट किए जाते हैं। विविधता श्रृंखला आवृत्तियों या सापेक्ष आवृत्तियों (आवृत्तियों) के वितरण को दिखा सकती है, यह इस बात पर निर्भर करता है कि प्रत्येक विकल्प - आवृत्ति या आवृत्ति के लिए क्या मूल्य इंगित किया गया है।
आवृत्ति वितरण की असतत भिन्नता श्रृंखलाकी तरह लगता है:
आवृत्ति सूत्र द्वारा पाई जाती है, i = 1, 2, ..., एम.
डब्ल्यू 1 +डब्ल्यू 2 + … + डब्ल्यूएम = 1।
उदाहरण 4.1. संख्याओं के दिए गए सेट के लिए
4, 6, 6, 3, 4, 9, 6, 4, 6, 6
बारंबारता और बारंबारता वितरण की असतत परिवर्तनशील श्रृंखला का निर्माण।
समाधान . जनसंख्या का आयतन है एन= 10। असतत आवृत्ति वितरण श्रृंखला का रूप है
अंतराल श्रृंखला में रिकॉर्डिंग का एक समान रूप होता है।
आवृत्ति वितरण की अंतराल भिन्नता श्रृंखलाके रूप में लिखा है:
सभी बारंबारताओं का योग प्रेक्षणों की कुल संख्या के बराबर होता है, अर्थात कुल मात्रा: एन = एन 1 +एन 2 + … + एनएम ।
सापेक्ष आवृत्तियों (आवृत्तियों) के वितरण की अंतराल भिन्नता श्रृंखलाकी तरह लगता है:
आवृत्ति सूत्र द्वारा पाई जाती है, i = 1, 2, ..., एम.
सभी आवृत्तियों का योग एक के बराबर है: डब्ल्यू 1 +डब्ल्यू 2 + … + डब्ल्यूएम = 1।
अक्सर व्यवहार में, अंतराल श्रृंखला का उपयोग किया जाता है। यदि बहुत सारे सांख्यिकीय नमूना डेटा हैं और उनके मूल्य एक दूसरे से मनमाने ढंग से छोटी राशि से भिन्न हैं, तो इन आंकड़ों के लिए असतत श्रृंखला आगे के शोध के लिए काफी बोझिल और असुविधाजनक होगी। इस मामले में, डेटा ग्रुपिंग का उपयोग किया जाता है, अर्थात। विशेषता के सभी मूल्यों वाले अंतराल को कई आंशिक अंतरालों में विभाजित किया जाता है और, प्रत्येक अंतराल के लिए आवृत्ति की गणना करके, एक अंतराल श्रृंखला प्राप्त की जाती है। यह मानते हुए कि आंशिक अंतराल की लंबाई समान होगी, आइए हम एक अंतराल श्रृंखला के निर्माण की योजना को और अधिक विस्तार से लिखें।
2.2 एक अंतराल श्रृंखला का निर्माण
अंतराल श्रृंखला बनाने के लिए, आपको चाहिए:
अंतराल की संख्या निर्धारित करें;
अंतराल की लंबाई निर्धारित करें;
अक्ष पर अंतराल का स्थान निर्धारित करें।
निर्धारण के लिए अंतराल की संख्या क एक स्टर्ज फॉर्मूला है, जिसके अनुसार
 ,
,
कहाँ पे एन- समग्रता का आयतन।
उदाहरण के लिए, यदि 100 विशेषता मान (वैरिएंट) हैं, तो अंतराल श्रृंखला के निर्माण के लिए अंतराल के बराबर अंतराल की संख्या लेने की सिफारिश की जाती है।
हालाँकि, बहुत बार व्यवहार में अंतरालों की संख्या स्वयं शोधकर्ता द्वारा चुनी जाती है, यह देखते हुए कि यह संख्या बहुत बड़ी नहीं होनी चाहिए, ताकि श्रृंखला बोझिल न हो, लेकिन बहुत छोटी भी न हो, ताकि कुछ गुण खो न जाएँ वितरण।
अंतराल की लंबाई एच निम्नलिखित सूत्र द्वारा निर्धारित किया जाता है:
 ,
,
कहाँ पे एक्सअधिकतम और एक्स min क्रमशः विकल्पों का सबसे बड़ा और सबसे छोटा मान है।
मूल्य  बुलाया बड़े पैमाने परपंक्ति।
बुलाया बड़े पैमाने परपंक्ति।
स्वयं अंतरालों का निर्माण करने के लिए, वे विभिन्न तरीकों से आगे बढ़ते हैं। सबसे आसान तरीकों में से एक इस प्रकार है। मान को पहले अंतराल की शुरुआत के रूप में लिया जाता है  . फिर अंतराल की शेष सीमाएं सूत्र द्वारा पाई जाती हैं। जाहिर है, आखिरी अंतराल का अंत एकएम+1 को शर्त पूरी करनी होगी
. फिर अंतराल की शेष सीमाएं सूत्र द्वारा पाई जाती हैं। जाहिर है, आखिरी अंतराल का अंत एकएम+1 को शर्त पूरी करनी होगी
अंतरालों की सभी सीमाएँ मिल जाने के बाद, इन अंतरालों की बारंबारताएँ (या बारंबारताएँ) निर्धारित की जाती हैं। इस समस्या को हल करने के लिए, वे सभी विकल्पों को देखते हैं और एक विशेष अंतराल में आने वाले विकल्पों की संख्या निर्धारित करते हैं। हम एक उदाहरण का उपयोग करके एक अंतराल श्रृंखला के पूर्ण निर्माण पर विचार करेंगे।
उदाहरण 4.2. आरोही क्रम में लिखे गए निम्नलिखित आँकड़ों के लिए, 5 के बराबर अंतरालों की संख्या के साथ एक अंतराल श्रृंखला बनाएँ:
11, 12, 12, 14, 14, 15, 21, 21, 22, 23, 25, 38, 38, 39, 42, 42, 44, 45, 50, 50, 55, 56, 58, 60, 62, 63, 65, 68, 68, 68, 70, 75, 78, 78, 78, 78, 80, 80, 86, 88, 90, 91, 91, 91, 91, 91, 93, 93, 95, 96.
समाधान। कुल एन=50 वैरिएंट मान।
समस्या की स्थिति में अंतराल की संख्या निर्दिष्ट है, अर्थात क=5.
अंतराल की लंबाई है  .
.
आइए अंतराल की सीमाओं को परिभाषित करें:
एक 1 = 11 − 8,5 = 2,5; एक 2 = 2,5 + 17 = 19,5; एक 3 = 19,5 + 17 = 36,5;
एक 4 = 36,5 + 17 = 53,5; एक 5 = 53,5 + 17 = 70,5; एक 6 = 70,5 + 17 = 87,5;
एक 7 = 87,5 +17 = 104,5.
अंतराल की आवृत्ति निर्धारित करने के लिए, हम इस अंतराल में आने वाले विकल्पों की संख्या की गणना करते हैं। उदाहरण के लिए, विकल्प 11, 12, 12, 14, 14, 15 पहले अंतराल में 2.5 से 19.5 तक आते हैं। उनकी संख्या 6 है, इसलिए, पहले अंतराल की आवृत्ति है एन 1=6। पहले अंतराल की आवृत्ति है  . वेरिएंट 21, 21, 22, 23, 25, जिनकी संख्या 5 है, दूसरे अंतराल में 19.5 से 36.5 तक आते हैं। इसलिए, दूसरे अंतराल की आवृत्ति है एन 2 = 5, और आवृत्ति
. वेरिएंट 21, 21, 22, 23, 25, जिनकी संख्या 5 है, दूसरे अंतराल में 19.5 से 36.5 तक आते हैं। इसलिए, दूसरे अंतराल की आवृत्ति है एन 2 = 5, और आवृत्ति  . सभी अंतरालों के लिए समान रूप से बारंबारताएँ और बारंबारताएँ प्राप्त करने के बाद, हम निम्नलिखित अंतराल श्रृंखला प्राप्त करते हैं।
. सभी अंतरालों के लिए समान रूप से बारंबारताएँ और बारंबारताएँ प्राप्त करने के बाद, हम निम्नलिखित अंतराल श्रृंखला प्राप्त करते हैं।
आवृत्ति वितरण की अंतराल श्रृंखला का रूप है:
आवृत्तियों का योग 6+5+9+11+8+11=50 है।
आवृत्ति वितरण की अंतराल श्रृंखला का रूप है:
आवृत्तियों का योग 0.12+0.1+0.18+0.22+0.16+0.22=1 है। ■
अंतराल श्रृंखला का निर्माण करते समय, विचाराधीन समस्या की विशिष्ट स्थितियों के आधार पर, अन्य नियम लागू किए जा सकते हैं, अर्थात्
1. अंतराल भिन्नता श्रृंखला में विभिन्न लंबाई के आंशिक अंतराल शामिल हो सकते हैं। अंतराल की असमान लंबाई एक विशेषता के असमान वितरण के साथ एक सांख्यिकीय आबादी के गुणों को अलग करना संभव बनाती है। उदाहरण के लिए, यदि अंतराल की सीमाएं शहरों में निवासियों की संख्या निर्धारित करती हैं, तो इस समस्या में उन अंतरालों का उपयोग करने की सलाह दी जाती है जो लंबाई में असमान हैं। जाहिर है, छोटे शहरों के लिए, निवासियों की संख्या में एक छोटा सा अंतर भी महत्वपूर्ण है, और बड़े शहरों के लिए, दसियों और सैकड़ों निवासियों का अंतर महत्वपूर्ण नहीं है। आंशिक अंतराल की असमान लंबाई वाली अंतराल श्रृंखला का मुख्य रूप से सांख्यिकी के सामान्य सिद्धांत में अध्ययन किया जाता है और उनका विचार इस मैनुअल के दायरे से बाहर है।
2. गणितीय आँकड़ों में, अंतराल श्रृंखला को कभी-कभी माना जाता है, जिसके लिए पहले अंतराल की बाईं सीमा को -∞ माना जाता है, और अंतिम अंतराल की दाईं सीमा +∞ है। यह सांख्यिकीय वितरण को सैद्धांतिक के करीब लाने के लिए किया जाता है।
3. अंतराल श्रृंखला का निर्माण करते समय, यह पता चल सकता है कि कुछ भिन्नता का मान अंतराल सीमा के साथ बिल्कुल मेल खाता है। इस मामले में करने के लिए सबसे अच्छी बात इस प्रकार है। यदि ऐसा केवल एक संयोग है, तो विचार करें कि इसकी आवृत्ति के साथ विचाराधीन संस्करण अंतराल श्रृंखला के मध्य में स्थित अंतराल में गिर गया, यदि ऐसे कई संस्करण हैं, तो या तो उन सभी को अंतराल को सौंपा गया है इन प्रकारों के दाईं ओर, या सभी बाईं ओर।
4. अंतरालों की संख्या और उनकी लंबाई निर्धारित करने के बाद, अंतरालों का स्थान दूसरे तरीके से किया जा सकता है। विकल्पों के सभी माने गए मानों का अंकगणितीय माध्य ज्ञात कीजिए एक्ससीएफ और पहले अंतराल का निर्माण इस तरह से करें कि यह नमूना माध्य कुछ अंतराल के भीतर हो। इस प्रकार, हम से अंतराल प्राप्त करते हैं एक्ससीएफ - 0.5 एचइससे पहले एक्सऔसत + 0.5 एच. फिर बाएँ और दाएँ, अंतराल की लंबाई जोड़कर, हम शेष अंतराल का निर्माण करते हैं एक्समिनट और एक्स max क्रमशः पहले और अंतिम अंतराल में नहीं आएगा।
5. बड़ी संख्या में अंतराल वाली अंतराल श्रृंखला को आसानी से लंबवत रूप से लिखा जाता है, अर्थात। रिकॉर्ड अंतराल पहली पंक्ति में नहीं, बल्कि पहले कॉलम में, और दूसरे कॉलम में फ़्रीक्वेंसी (या फ़्रीक्वेंसी)।
नमूना डेटा को कुछ यादृच्छिक चर के मान के रूप में माना जा सकता है एक्स. एक यादृच्छिक चर का अपना वितरण नियम होता है। संभाव्यता सिद्धांत से यह ज्ञात है कि असतत यादृच्छिक चर के वितरण के नियम को वितरण श्रृंखला के रूप में निर्दिष्ट किया जा सकता है, और वितरण घनत्व फ़ंक्शन का उपयोग करके निरंतर एक के लिए। हालाँकि, एक सार्वभौमिक वितरण कानून है जो असतत और निरंतर यादृच्छिक चर दोनों के लिए है। यह वितरण नियम वितरण फलन के रूप में दिया गया है एफ(एक्स) = पी(एक्स<एक्स). नमूना डेटा के लिए, आप वितरण फ़ंक्शन - अनुभवजन्य वितरण फ़ंक्शन का एक एनालॉग निर्दिष्ट कर सकते हैं।
समान जानकारी।
रूपांतर श्रृंखलाएक सुविधा के संख्यात्मक मूल्यों की एक श्रृंखला है।
भिन्नता श्रृंखला की मुख्य विशेषताएं: वी - संस्करण, पी - इसकी घटना की आवृत्ति।
विविधता श्रृंखला के प्रकार:
वेरिएंट की आवृत्ति के अनुसार: सरल - वेरिएंट एक बार होता है, भारित - वेरिएंट दो या अधिक बार होता है;
स्थान के आधार पर विकल्प: रैंक - विकल्पों को अवरोही और आरोही क्रम में व्यवस्थित किया जाता है, बिना क्रम के - विकल्प किसी विशेष क्रम में नहीं लिखे जाते हैं;
समूहों में विकल्प को समूहीकृत करके: समूहीकृत - विकल्पों को समूहों में संयोजित किया जाता है, असमूहीकृत - विकल्पों को समूहीकृत नहीं किया जाता है;
मूल्य विकल्पों द्वारा: निरंतर - विकल्प एक पूर्णांक और एक भिन्नात्मक संख्या के रूप में व्यक्त किए जाते हैं, असतत - विकल्प एक पूर्णांक के रूप में व्यक्त किए जाते हैं, जटिल - विकल्प एक सापेक्ष या औसत मूल्य द्वारा दर्शाए जाते हैं।
औसत मूल्यों की गणना करने के लिए एक परिवर्तनशील श्रृंखला संकलित और तैयार की जाती है।
भिन्न श्रृंखला संकेतन प्रपत्र:
8. औसत मूल्य, प्रकार, गणना पद्धति, स्वास्थ्य देखभाल में आवेदन
औसत मान- मात्रात्मक विशेषताओं की कुल सामान्यीकरण विशेषता। औसत का आवेदन:
1. चिकित्सा संस्थानों के काम के संगठन की विशेषता और उनकी गतिविधियों का मूल्यांकन करने के लिए:
क) पॉलीक्लिनिक में: डॉक्टरों के कार्यभार के संकेतक, यात्राओं की औसत संख्या, क्षेत्र में निवासियों की औसत संख्या;
बी) एक अस्पताल में: प्रति वर्ष बिस्तर के दिनों की औसत संख्या; अस्पताल में रहने की औसत अवधि;
ग) स्वच्छता, महामारी विज्ञान और सार्वजनिक स्वास्थ्य के केंद्र में: प्रति व्यक्ति औसत क्षेत्र (या घन क्षमता), औसत पोषण मानक (प्रोटीन, वसा, कार्बोहाइड्रेट, विटामिन, खनिज लवण, कैलोरी), स्वच्छता मानदंड और मानक, आदि। ;
2. शारीरिक विकास (रूपात्मक और कार्यात्मक की मुख्य मानवशास्त्रीय विशेषताएं) को चिह्नित करने के लिए;
3. नैदानिक और प्रयोगात्मक अध्ययनों में सामान्य और रोग संबंधी स्थितियों में शरीर के चिकित्सा और शारीरिक मापदंडों का निर्धारण करना।
4. विशेष वैज्ञानिक अनुसंधान में।
औसत मूल्यों और संकेतकों के बीच का अंतर:
1. गुणांक एक वैकल्पिक विशेषता का वर्णन करते हैं जो केवल सांख्यिकीय टीम के कुछ भाग में होती है, जो घटित हो भी सकती है और नहीं भी।
औसत मूल्य टीम के सभी सदस्यों में निहित संकेतों को कवर करते हैं, लेकिन अलग-अलग डिग्री (वजन, ऊंचाई, अस्पताल में उपचार के दिन) तक।
2. गुणात्मक विशेषताओं को मापने के लिए गुणांक का उपयोग किया जाता है। औसत मूल्य अलग-अलग मात्रात्मक लक्षणों के लिए हैं।
औसत के प्रकार:
अंकगणित माध्य, इसकी विशेषताएं - मानक विचलन और औसत त्रुटि
मोड और माध्यिका। फैशन (मो)- उस विशेषता के मूल्य से मेल खाती है जो इस आबादी में सबसे अधिक पाई जाती है। माध्यिका (मी)- विशेषता का मूल्य, जो इस जनसंख्या में औसत मूल्य रखता है। यह प्रेक्षणों की संख्या के अनुसार श्रृंखला को 2 बराबर भागों में विभाजित करता है। अंकगणितीय औसत मूल्य (एम)- मोड और माध्यिका के विपरीत, यह किए गए सभी अवलोकनों पर निर्भर करता है, इसलिए यह संपूर्ण वितरण के लिए एक महत्वपूर्ण विशेषता है।
अन्य प्रकार के औसत जो विशेष अध्ययन में उपयोग किए जाते हैं: मूल माध्य वर्ग, घन, हार्मोनिक, ज्यामितीय, प्रगतिशील।
अंकगणित औसतसांख्यिकीय आबादी के औसत स्तर की विशेषता है।
एक साधारण श्रृंखला के लिए जहां
∑v – योग विकल्प,
n प्रेक्षणों की संख्या है।
 एक भारित श्रृंखला के लिए, जहाँ
एक भारित श्रृंखला के लिए, जहाँ
∑vr प्रत्येक विकल्प के गुणनफल और उसके घटित होने की आवृत्ति का योग है
n प्रेक्षणों की संख्या है।
मानक विचलनअंकगणित माध्य या सिग्मा (σ) सुविधा की विविधता को दर्शाता है
 - एक साधारण पंक्ति के लिए
- एक साधारण पंक्ति के लिए
Σd 2 - अंकगणितीय माध्य और प्रत्येक विकल्प के बीच अंतर के वर्गों का योग (d = │M-V│)
n प्रेक्षणों की संख्या है
 - भारित श्रृंखला के लिए
- भारित श्रृंखला के लिए
∑d 2 p अंकगणितीय माध्य और प्रत्येक विकल्प और इसकी आवृत्ति की आवृत्ति के बीच अंतर के वर्गों के उत्पादों का योग है,
n प्रेक्षणों की संख्या है।
विविधता की डिग्री को भिन्नता के गुणांक के मूल्य से आंका जा सकता है  . 20% से अधिक - मजबूत विविधता, 10-20% - मध्यम विविधता, 10% से कम - कमजोर विविधता।
. 20% से अधिक - मजबूत विविधता, 10-20% - मध्यम विविधता, 10% से कम - कमजोर विविधता।
यदि एक सिग्मा (M ± 1σ) को अंकगणितीय माध्य में जोड़ा और घटाया जाता है, तो एक सामान्य वितरण के साथ, सभी वेरिएंट (टिप्पणियों) का कम से कम 68.3% इन सीमाओं के भीतर होगा, जिसे अध्ययन के तहत घटना के लिए आदर्श माना जाता है . यदि k 2 ± 2σ, तो सभी अवलोकनों का 95.5% इन सीमाओं के भीतर होगा, और यदि k M ± 3σ, तो सभी अवलोकनों का 99.7% इन सीमाओं के भीतर होगा। इस प्रकार, मानक विचलन मानक विचलन है, जो अध्ययन के तहत विशेषता के ऐसे मूल्य की घटना की संभावना की भविष्यवाणी करना संभव बनाता है, जो निर्दिष्ट सीमा के भीतर है।
अंकगणितीय माध्य की औसत त्रुटिया प्रतिनिधित्व त्रुटि। सरल, भारित श्रृंखला के लिए और क्षणों के नियम द्वारा:
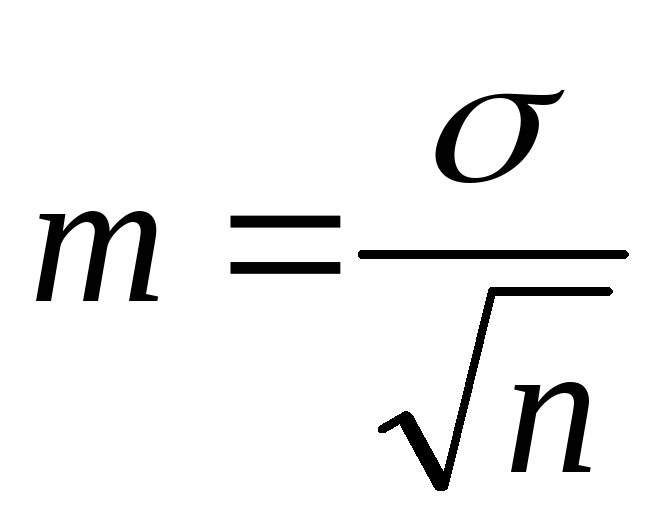 .
.
औसत मूल्यों की गणना करने के लिए, यह आवश्यक है: सामग्री की एकरूपता, पर्याप्त संख्या में अवलोकन। यदि प्रेक्षणों की संख्या 30 से कम है, तो σ और m की गणना के सूत्र में n-1 का उपयोग किया जाता है।
औसत त्रुटि के आकार द्वारा प्राप्त परिणाम का मूल्यांकन करते समय, एक विश्वास गुणांक का उपयोग किया जाता है, जो एक सही उत्तर की संभावना निर्धारित करना संभव बनाता है, अर्थात यह इंगित करता है कि परिणामी नमूना त्रुटि वास्तविक त्रुटि से अधिक नहीं होगी निरंतर अवलोकन के परिणामस्वरूप बनाया गया। नतीजतन, विश्वास की संभावना में वृद्धि के साथ, विश्वास अंतराल की चौड़ाई बढ़ जाती है, जो बदले में, निर्णय के विश्वास को बढ़ाता है, प्राप्त परिणाम का समर्थन करता है।
(एक परिवर्तनशील श्रृंखला की परिभाषा; एक परिवर्तनशील श्रृंखला के घटक; एक परिवर्तनशील श्रृंखला के तीन रूप; एक अंतराल श्रृंखला के निर्माण की समीचीनता; निष्कर्ष जो निर्मित श्रृंखला से निकाले जा सकते हैं)
एक परिवर्तनशील श्रृंखला गैर-घटते क्रम में व्यवस्थित नमूने के सभी तत्वों का एक क्रम है। वही तत्व दोहराए जाते हैं
परिवर्तनशील - ये मात्रात्मक आधार पर निर्मित श्रृंखलाएँ हैं।
परिवर्तनशील वितरण श्रृंखला में दो तत्व होते हैं: वेरिएंट और फ़्रीक्वेंसी:
वेरिएंट वितरण की विविधता श्रृंखला में एक मात्रात्मक विशेषता के संख्यात्मक मान हैं। वे सकारात्मक या नकारात्मक, निरपेक्ष या सापेक्ष हो सकते हैं। इसलिए, जब उद्यमों को आर्थिक गतिविधि के परिणामों के अनुसार समूहीकृत किया जाता है, तो विकल्प सकारात्मक होते हैं - यह लाभ है, और नकारात्मक संख्या - यह एक नुकसान है।
फ़्रीक्वेंसी अलग-अलग वेरिएंट या विविधता श्रृंखला के प्रत्येक समूह की संख्या है, अर्थात। ये संख्याएँ दर्शाती हैं कि वितरण श्रृंखला में कुछ विकल्प कितनी बार आते हैं। सभी आवृत्तियों के योग को जनसंख्या का आयतन कहा जाता है और यह संपूर्ण जनसंख्या के तत्वों की संख्या से निर्धारित होता है।
आवृत्तियाँ सापेक्ष मान (इकाइयों या प्रतिशत के अंश) के रूप में व्यक्त की जाने वाली आवृत्तियाँ हैं। आवृत्तियों का योग एक या 100% के बराबर है। बारंबारताओं द्वारा बारंबारताओं के प्रतिस्थापन से विभिन्न संख्याओं के अवलोकनों के साथ परिवर्तनशील श्रृंखला की तुलना करना संभव हो जाता है।
विविधता श्रृंखला के तीन रूप हैं:रैंक श्रृंखला, असतत श्रृंखला और अंतराल श्रृंखला।
एक रैंक श्रृंखला अध्ययन के तहत विशेषता के आरोही या अवरोही क्रम में जनसंख्या की व्यक्तिगत इकाइयों का वितरण है। रैंकिंग से मात्रात्मक डेटा को समूहों में विभाजित करना आसान हो जाता है, किसी विशेषता के सबसे छोटे और सबसे बड़े मूल्यों का तुरंत पता लगा लेता है, उन मूल्यों को उजागर करता है जो सबसे अधिक बार दोहराए जाते हैं।
भिन्नता श्रृंखला के अन्य रूप अध्ययन के तहत विशेषता के मूल्यों में भिन्नता की प्रकृति के अनुसार संकलित समूह सारणी हैं। भिन्नता की प्रकृति से, असतत (असतत) और निरंतर संकेत प्रतिष्ठित हैं।
एक असतत श्रृंखला एक ऐसी परिवर्तनशील श्रृंखला है, जिसका निर्माण एक असंतुलित परिवर्तन (असतत संकेत) वाले संकेतों पर आधारित है। उत्तरार्द्ध में टैरिफ श्रेणी, परिवार में बच्चों की संख्या, उद्यम में कर्मचारियों की संख्या आदि शामिल हैं। ये चिन्ह निश्चित मानों की सीमित संख्या ही ले सकते हैं।
असतत परिवर्तनशील श्रृंखला एक तालिका है जिसमें दो स्तंभ होते हैं। पहला कॉलम विशेषता के विशिष्ट मूल्य को इंगित करता है, और दूसरा - विशेषता के विशिष्ट मूल्य के साथ जनसंख्या इकाइयों की संख्या।
यदि किसी चिन्ह में निरंतर परिवर्तन होता है (आय की मात्रा, कार्य अनुभव, किसी उद्यम की अचल संपत्तियों की लागत, आदि, जो कुछ सीमाओं के भीतर कोई भी मूल्य ले सकता है), तो इस चिन्ह के लिए एक अंतराल भिन्नता श्रृंखला बनाई जानी चाहिए।
यहां ग्रुप टेबल में भी दो कॉलम हैं। पहला अंतराल "से - से" (विकल्प) में सुविधा के मूल्य को इंगित करता है, दूसरा - अंतराल (आवृत्ति) में शामिल इकाइयों की संख्या।
फ़्रिक्वेंसी (पुनरावृत्ति आवृत्ति) - विशेषता मानों के किसी विशेष संस्करण की पुनरावृत्ति की संख्या, निरूपित फाई , और अध्ययन की गई आबादी के आयतन के बराबर आवृत्तियों का योग, निरूपित
जहाँ k विशेषता मान विकल्पों की संख्या है
बहुत बार, तालिका को एक स्तंभ के साथ पूरक किया जाता है जिसमें संचित आवृत्तियों S की गणना की जाती है, जो यह दर्शाता है कि जनसंख्या की कितनी इकाइयाँ इस मान से अधिक नहीं हैं।
असतत भिन्नता वितरण श्रृंखला एक ऐसी श्रृंखला है जिसमें समूहों को एक विशेषता के अनुसार बनाया जाता है जो अलग-अलग भिन्न होता है और केवल पूर्णांक मान लेता है।
वितरण की अंतराल भिन्नता श्रृंखला एक श्रृंखला है जिसमें समूहीकरण विशेषता, जो समूहीकरण का आधार बनाती है, एक निश्चित अंतराल में कोई भी मान ले सकती है, जिसमें भिन्नात्मक भी शामिल हैं।
एक अंतराल परिवर्तनशील श्रृंखला एक यादृच्छिक चर के मूल्यों की भिन्नता के अंतराल का एक क्रमबद्ध सेट है जिसमें उनमें से प्रत्येक में गिरने वाली मात्रा के मूल्यों की संगत आवृत्तियों या आवृत्तियों के साथ होता है।
एक अंतराल वितरण श्रृंखला का निर्माण करना समीचीन है, सबसे पहले, एक विशेषता की निरंतर भिन्नता के साथ, और यह भी कि अगर एक असतत भिन्नता एक विस्तृत श्रृंखला में प्रकट होती है, अर्थात। असतत सुविधा के लिए विकल्पों की संख्या काफी बड़ी है।
इस श्रृंखला से पहले ही कई निष्कर्ष निकाले जा सकते हैं। उदाहरण के लिए, एक भिन्नता श्रृंखला (माध्यिका) का औसत तत्व माप के सबसे संभावित परिणाम का अनुमान हो सकता है। परिवर्तनशील श्रृंखला का पहला और अंतिम तत्व (यानी, नमूने का न्यूनतम और अधिकतम तत्व) नमूने के तत्वों का प्रसार दर्शाता है। कभी-कभी, यदि पहला या अंतिम तत्व शेष नमूने से बहुत भिन्न होता है, तो उन्हें माप परिणामों से बाहर रखा जाता है, यह देखते हुए कि ये मान किसी प्रकार की सकल विफलता के परिणामस्वरूप प्राप्त किए गए थे, उदाहरण के लिए, प्रौद्योगिकी।
