द्विपद वितरण कानून। द्विपद वितरण
सामान्य के विपरीत और समान वितरणअध्ययनाधीन विषयों के नमूने में एक चर के व्यवहार का वर्णन करते हुए, द्विपद वितरण का उपयोग अन्य उद्देश्यों के लिए किया जाता है। यह एक निश्चित संख्या में स्वतंत्र परीक्षणों में दो परस्पर अनन्य घटनाओं की संभावना की भविष्यवाणी करने का कार्य करता है। द्विपद वितरण का एक उत्कृष्ट उदाहरण एक सिक्के को उछालना है जो एक कठोर सतह पर गिरता है। दो परिणाम (घटनाएं) समान रूप से संभावित हैं: 1) सिक्का "ईगल" गिरता है (संभावना बराबर है आर) या 2) सिक्का "पूंछ" गिरता है (संभावना बराबर है क्यू) यदि कोई तीसरा परिणाम नहीं दिया जाता है, तो पी = क्यू= 0.5 और पी + क्यू= 1. द्विपद बंटन सूत्र का उपयोग करके, उदाहरण के लिए, आप यह निर्धारित कर सकते हैं कि 50 परीक्षणों (सिक्का उछालने की संख्या) में अंतिम सिक्का 25 बार गिरेगा, इसकी क्या प्रायिकता है।
आगे के तर्क के लिए, हम आम तौर पर स्वीकृत संकेतन का परिचय देते हैं:
एन – कुल गणनाअवलोकन;
मैं- हमारे लिए ब्याज की घटनाओं (परिणामों) की संख्या;
एन – मैं- वैकल्पिक घटनाओं की संख्या;
पी- आनुभविक रूप से निर्धारित (कभी-कभी - माना जाता है) हमारे लिए रुचि की घटना की संभावना;
क्यूएक वैकल्पिक घटना की संभावना है;
पीएन ( मैं) हमारे लिए रुचि की घटना की अनुमानित संभावना है मैंटिप्पणियों की एक निश्चित संख्या के लिए एन.
द्विपद वितरण सूत्र:
घटनाओं के समसंभाव्य परिणाम के मामले में ( पी = क्यू) आप सरलीकृत सूत्र का उपयोग कर सकते हैं:
![]() (6.8)
(6.8)
आइए मनोवैज्ञानिक शोध में द्विपद वितरण सूत्रों के उपयोग को दर्शाने वाले तीन उदाहरणों पर विचार करें।
उदाहरण 1
मान लें कि 3 छात्र बढ़ी हुई जटिलता की समस्या को हल कर रहे हैं। उनमें से प्रत्येक के लिए, 2 परिणाम समान रूप से संभावित हैं: (+) - समाधान और (-) - समस्या का समाधान नहीं। कुल मिलाकर, 8 अलग-अलग परिणाम संभव हैं (2 3 = 8)।
संभावना है कि कोई भी छात्र कार्य का सामना नहीं करेगा 1/8 (विकल्प 8) है; 1 छात्र कार्य पूरा करेगा: पी= 3/8 (विकल्प 4, 6, 7); 2 छात्र - पी= 3/8 (विकल्प 2, 3, 5) और 3 विद्यार्थी - पी= 1/8 (विकल्प 1)।
यह संभावना निर्धारित करना आवश्यक है कि 5 में से तीन छात्र सफलतापूर्वक इस कार्य का सामना करेंगे।
समाधान
कुल संभावित परिणाम: 2 5 = 32.
विकल्प 3(+) और 2(-) की कुल संख्या है

इसलिए, अपेक्षित परिणाम की संभावना 10/32 »0.31 है।
उदाहरण 3
व्यायाम
10 यादृच्छिक विषयों के समूह में 5 बहिर्मुखी पाए जाने की प्रायिकता ज्ञात कीजिए।
समाधान
1. अंकन दर्ज करें: पी = क्यू = 0,5; एन= 10; मैं = 5; पी 10 (5) = ?
2. हम एक सरलीकृत सूत्र का उपयोग करते हैं (ऊपर देखें):
निष्कर्ष
10 यादृच्छिक विषयों में से 5 बहिर्मुखी पाए जाने की प्रायिकता 0.246 है।
टिप्पणियाँ
1. पर्याप्त के लिए सूत्र द्वारा गणना बड़ी संख्यापरीक्षण काफी श्रमसाध्य हैं, इसलिए इन मामलों में द्विपद वितरण तालिकाओं का उपयोग करने की सिफारिश की जाती है।
2. कुछ मामलों में, मान पीतथा क्यूशुरुआत में सेट किया जा सकता है, लेकिन हमेशा नहीं। एक नियम के रूप में, उनकी गणना प्रारंभिक परीक्षणों (पायलट अध्ययन) के परिणामों के आधार पर की जाती है।
3. इन ग्राफिक छवि(निर्देशांक में पी न(मैं) = एफ(मैं)) द्विपद बंटन हो सकता है कुछ अलग किस्म का: जब पी = क्यूवितरण सममित है और गाऊसी सामान्य वितरण जैसा दिखता है; वितरण विषमता से अधिक है अधिक अंतरसंभावनाओं के बीच पीतथा क्यू.
पॉसों वितरण
पॉसों वितरण द्विपद वितरण का एक विशेष मामला है, जिसका उपयोग तब किया जाता है जब ब्याज की घटनाओं की संभावना बहुत कम होती है। दूसरे शब्दों में, यह वितरण दुर्लभ घटनाओं की संभावना का वर्णन करता है। पॉइसन सूत्र का उपयोग किया जा सकता है पी < 0,01 и क्यू ≥ 0,99.
पॉइसन समीकरण अनुमानित है और निम्न सूत्र द्वारा वर्णित है:
![]() (6.9)
(6.9)
जहां μ उत्पाद है औसत संभावनाघटनाओं और टिप्पणियों की संख्या।
एक उदाहरण के रूप में, निम्नलिखित समस्या को हल करने के लिए एल्गोरिथ्म पर विचार करें।
काम
कई वर्षों तक, रूस में 21 बड़े क्लीनिकों ने शिशुओं में डाउन की बीमारी के लिए नवजात शिशुओं की सामूहिक जांच की (प्रत्येक क्लिनिक में औसतन 1,000 नवजात शिशु थे)। निम्नलिखित डेटा प्राप्त किया गया था:
व्यायाम
1. रोग की औसत संभावना (नवजात शिशुओं की संख्या के संदर्भ में) निर्धारित करें।
2. एक रोग से ग्रस्त नवजात शिशुओं की औसत संख्या ज्ञात कीजिए।
3. इस प्रायिकता का निर्धारण करें कि यादृच्छिक रूप से चुने गए 100 नवजात शिशुओं में डाउन रोग वाले 2 बच्चे होंगे।
समाधान
1. रोग की औसत प्रायिकता ज्ञात कीजिए। ऐसा करने में, हमें निम्नलिखित तर्कों द्वारा निर्देशित होना चाहिए। डाउंस रोग 21 में से केवल 10 क्लीनिकों में दर्ज किया गया था। 11 क्लीनिकों में कोई बीमारी नहीं पाई गई, 6 क्लीनिक में 1 मामला, 2 क्लीनिक में 2 मामले, 1 क्लिनिक में 3 और 1 क्लिनिक में 4 मामले दर्ज किए गए। किसी भी क्लिनिक में 5 केस नहीं मिले। रोग की औसत संभावना को निर्धारित करने के लिए, कुल मामलों की संख्या (6 1 + 2 2 + 1 3 + 1 4 = 17) को नवजात शिशुओं की कुल संख्या (21000) से विभाजित करना आवश्यक है:
![]()
2. एक बीमारी के लिए जिम्मेदार नवजात शिशुओं की संख्या औसत संभावना का पारस्परिक है, यानी पंजीकृत मामलों की संख्या से विभाजित नवजात शिशुओं की कुल संख्या के बराबर:
![]()
3. मूल्यों को प्रतिस्थापित करें पी = 0,00081, एन= 100 और मैं= 2 पॉइसन सूत्र में:
उत्तर
100 बेतरतीब ढंग से चुने गए नवजात शिशुओं में डाउंस रोग वाले 2 शिशु पाए जाने की प्रायिकता 0.003 (0.3%) है।
संबंधित कार्य
कार्य 6.1
व्यायाम
सेंसरिमोटर प्रतिक्रिया के समय समस्या 5.1 के डेटा का उपयोग करके, VR के वितरण की विषमता और कुर्टोसिस की गणना करें।
कार्य 6. 2
बुद्धि के स्तर के लिए 200 स्नातक छात्रों का परीक्षण किया गया ( बुद्धि) परिणामी वितरण को सामान्य करने के बाद बुद्धिमानक विचलन के अनुसार, निम्नलिखित परिणाम प्राप्त हुए:
व्यायाम
कोलमोगोरोव और ची-स्क्वायर परीक्षणों का उपयोग करके, यह निर्धारित करें कि क्या संकेतकों का परिणामी वितरण मेल खाता है बुद्धिसामान्य।
कार्य 6. 3
एक वयस्क विषय (एक 25 वर्षीय व्यक्ति) में, 1 किलोहर्ट्ज़ की निरंतर आवृत्ति और 40 डीबी की तीव्रता के साथ ध्वनि उत्तेजना के जवाब में एक साधारण सेंसरिमोटर प्रतिक्रिया (एसआर) के समय का अध्ययन किया गया था। उत्तेजना को 3-5 सेकंड के अंतराल पर सौ बार प्रस्तुत किया गया था। 100 पुनरावृत्तियों के लिए व्यक्तिगत VR मान निम्नानुसार वितरित किए गए:
व्यायाम
1. वीआर के वितरण का एक आवृत्ति हिस्टोग्राम बनाएं; VR का औसत मान और मानक विचलन का मान निर्धारित करें।
2. विषमता के गुणांक और बीपी के वितरण के कर्टोसिस की गणना करें; प्राप्त मूल्यों के आधार पर जैसातथा भूतपूर्वसामान्य वितरण के साथ इस वितरण के पत्राचार या गैर-अनुपालन के बारे में निष्कर्ष निकालना।
कार्य 6.4
1998 में, 14 लोगों (5 लड़कों और 9 लड़कियों) ने निज़नी टैगिल के स्कूलों से स्वर्ण पदक, 26 लोगों (8 लड़के और 18 लड़कियों) ने रजत पदक के साथ स्नातक किया।
प्रश्न
क्या यह कहना संभव है कि लड़कियों को लड़कों की तुलना में अधिक बार पदक मिलते हैं?
टिप्पणी
लड़कों और लड़कियों की संख्या का अनुपात आबादीसमान समझो।
कार्य 6.5
यह माना जाता है कि विषयों के एक सजातीय समूह में बहिर्मुखी और अंतर्मुखी की संख्या लगभग समान है।
व्यायाम
प्रायिकता ज्ञात कीजिए कि यादृच्छिक रूप से चुने गए 10 विषयों के समूह में, 0, 1, 2, ..., 10 बहिर्मुखी मिलेंगे। किसी दिए गए समूह में 0, 1, 2, ..., 10 बहिर्मुखी खोजने के प्रायिकता बंटन के लिए आलेखीय व्यंजक की रचना कीजिए।
कार्य 6.6
व्यायाम
संभावना की गणना करें पी न(i) द्विपद बंटन फलन पी= 0.3 और क्यू= 0.7 मूल्यों के लिए एन= 5 और मैं= 0, 1, 2, ..., 5. निर्भरता का ग्राफिक व्यंजक बनाइए पी न(मैं) = एफ(मैं) .
कार्य 6.7
पर पिछले साल काआबादी के एक निश्चित हिस्से के बीच, ज्योतिषीय पूर्वानुमानों में विश्वास स्थापित किया गया था। प्रारंभिक सर्वेक्षणों के परिणामों के अनुसार, यह पाया गया कि लगभग 15% जनसंख्या ज्योतिष में विश्वास करती है।
व्यायाम
इस संभावना का निर्धारण करें कि यादृच्छिक रूप से चुने गए 10 उत्तरदाताओं में से 1, 2 या 3 लोग ज्योतिषीय पूर्वानुमानों में विश्वास करते हैं।
कार्य 6.8
काम
42 . पर सामान्य शिक्षा स्कूलकई वर्षों के लिए येकातेरिनबर्ग और स्वेर्दलोवस्क क्षेत्र (कुल छात्रों की संख्या 12260 लोग) अगला नंबरस्कूली बच्चों में मानसिक बीमारी के मामले:
व्यायाम
बता दें कि 1000 स्कूली बच्चों की रैंडम तरीके से जांच की जाती है। गणना कीजिए कि इस हजार स्कूली बच्चों में 1, 2 या 3 मानसिक रूप से बीमार बच्चों की पहचान होने की क्या प्रायिकता है?
खंड 7. अंतर के उपाय
समस्या का निरूपण
मान लीजिए हमारे पास विषयों के दो स्वतंत्र नमूने हैं एक्सतथा पर. स्वतंत्रनमूने तब गिने जाते हैं जब एक ही विषय (विषय) केवल एक नमूने में प्रकट होता है। कार्य इन नमूनों (चर के दो सेट) की तुलना उनके अंतर के लिए एक दूसरे से करना है। स्वाभाविक रूप से, पहले और दूसरे नमूनों में चर के मान कितने भी करीब क्यों न हों, कुछ, भले ही महत्वहीन हों, उनके बीच अंतर का पता लगाया जाएगा। इसी दृष्टि से गणितीय सांख्यिकीहम इस प्रश्न में रुचि रखते हैं कि क्या इन नमूनों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण (सांख्यिकीय रूप से महत्वपूर्ण) हैं या महत्वपूर्ण (यादृच्छिक) नहीं हैं।
नमूनों के बीच अंतर के महत्व के लिए सबसे सामान्य मानदंड अंतर के पैरामीट्रिक उपाय हैं - छात्र की कसौटीतथा फिशर की कसौटी. कुछ मामलों में, गैर-पैरामीट्रिक मानदंड का उपयोग किया जाता है - रोसेनबाम का क्यू परीक्षण, यू-परीक्षण मन्ना व्हिटनी और दूसरे। फिशर कोणीय परिवर्तन φ*, जो आपको एक दूसरे के साथ प्रतिशत (प्रतिशत) के रूप में व्यक्त मूल्यों की तुलना करने की अनुमति देता है। और, अंत में, एक विशेष मामले के रूप में, नमूनों की तुलना करने के लिए, मानदंड का उपयोग किया जा सकता है जो नमूना वितरण के आकार की विशेषता है - मानदंड χ 2 पियर्सनतथा मानदंड - कोलमोगोरोव - स्मिरनोव.
इस विषय को बेहतर ढंग से समझने के लिए, हम इस प्रकार आगे बढ़ेंगे। हम चार अलग-अलग मानदंडों का उपयोग करके चार विधियों के साथ एक ही समस्या का समाधान करेंगे - रोसेनबाम, मान-व्हिटनी, छात्र और फिशर।
काम
प्रतिक्रियाशील चिंता के स्तर के लिए स्पीलबर्गर परीक्षण के अनुसार परीक्षा सत्र के दौरान 30 छात्रों (14 लड़के और 16 लड़कियों) का परीक्षण किया गया। निम्नलिखित परिणाम प्राप्त हुए (तालिका 7.1):
तालिका 7.1
| विषयों | प्रतिक्रियाशील चिंता स्तर | |||||||||||||||
| युवाओं | ||||||||||||||||
| लड़कियाँ |
व्यायाम
यह निर्धारित करने के लिए कि लड़कों और लड़कियों में प्रतिक्रियाशील चिंता के स्तर में अंतर सांख्यिकीय रूप से महत्वपूर्ण हैं या नहीं।
के क्षेत्र में विशेषज्ञता रखने वाले मनोवैज्ञानिक के लिए यह कार्य काफी विशिष्ट लगता है शैक्षणिक मनोविज्ञान: कौन अधिक तीव्रता से परीक्षा के तनाव का अनुभव कर रहा है - लड़के या लड़कियां? यदि नमूनों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण हैं, तो इस पहलू में महत्वपूर्ण लिंग अंतर हैं; यदि अंतर यादृच्छिक (सांख्यिकीय रूप से महत्वपूर्ण नहीं) हैं, तो इस धारणा को त्याग दिया जाना चाहिए।
7. 2. गैर-पैरामीट्रिक परीक्षण क्यूरोसेनबम
क्यू-रोज़ेनबाम की कसौटी दो स्वतंत्र चर के मूल्यों की एक दूसरे पर "अतिरंजित" की तुलना पर आधारित है। साथ ही, प्रत्येक पंक्ति के भीतर विशेषता के वितरण की प्रकृति का विश्लेषण नहीं किया जाता है - इस मामले में, केवल दो रैंक वाली पंक्तियों के गैर-अतिव्यापी वर्गों की चौड़ाई मायने रखती है। चरों की दो क्रमबद्ध श्रृंखलाओं की एक दूसरे से तुलना करते समय, 3 विकल्प संभव हैं:
1. रैंक रैंक एक्सतथा आपओवरलैप का कोई क्षेत्र नहीं है, यानी पहली रैंक वाली श्रृंखला के सभी मान ( एक्स) दूसरी रैंक वाली श्रृंखला के सभी मूल्यों से अधिक है ( आप):
इस मामले में, किसी भी सांख्यिकीय मानदंड द्वारा निर्धारित नमूनों के बीच अंतर निश्चित रूप से महत्वपूर्ण हैं, और रोसेनबाम मानदंड के उपयोग की आवश्यकता नहीं है। हालांकि, व्यवहार में यह विकल्प अत्यंत दुर्लभ है।
2. रैंक की गई पंक्तियाँ एक दूसरे को पूरी तरह से ओवरलैप करती हैं (एक नियम के रूप में, पंक्तियों में से एक दूसरे के अंदर है), कोई गैर-अतिव्यापी क्षेत्र नहीं हैं। इस मामले में, रोसेनबाम मानदंड लागू नहीं होता है।

3. पंक्तियों का एक अतिव्यापी क्षेत्र है, साथ ही दो गैर-अतिव्यापी क्षेत्र ( एन 1तथा एन 2) संदर्भ के विभिन्नक्रमबद्ध श्रृंखला (हम निरूपित करते हैं एक्स- एक पंक्ति बड़े की ओर स्थानांतरित हो गई, आप- कम मूल्यों की दिशा में):

यह मामला रोसेनबाम मानदंड के उपयोग के लिए विशिष्ट है, जिसका उपयोग करते समय निम्नलिखित शर्तों का पालन किया जाना चाहिए:
1. प्रत्येक नमूने का आयतन कम से कम 11 होना चाहिए।
2. नमूना आकार एक दूसरे से महत्वपूर्ण रूप से भिन्न नहीं होना चाहिए।
मापदंड क्यूरोसेनबाम गैर-अतिव्यापी मूल्यों की संख्या से मेल खाता है: क्यू = एन 1 +एन 2 . नमूनों के बीच अंतर की विश्वसनीयता के बारे में निष्कर्ष निकाला जाता है यदि क्यू > क्यूक्रू . उसी समय, मान क्यूकरोड़ विशेष तालिकाओं में हैं (देखें परिशिष्ट, तालिका VIII)।
चलो अपने काम पर लौटते हैं। आइए हम संकेतन का परिचय दें: एक्स- लड़कियों का चयन, आप- लड़कों का चयन। प्रत्येक नमूने के लिए, हम एक क्रमबद्ध श्रृंखला बनाते हैं:
एक्स: 28 30 34 34 35 36 37 39 40 41 42 42 43 44 45 46
आप: 26 28 32 32 33 34 35 38 39 40 41 42 43 44
हम क्रमबद्ध श्रृंखला के गैर-अतिव्यापी क्षेत्रों में मूल्यों की संख्या की गणना करते हैं। एक पंक्ति में एक्समान 45 और 46 गैर-अतिव्यापी हैं, अर्थात। एन 1 = 2; एक पंक्ति में आपकेवल 1 गैर-अतिव्यापी मान 26 यानी। एन 2 = 1. इसलिए, क्यू = एन 1 +एन 2 = 1 + 2 = 3.
तालिका में। आठवीं परिशिष्ट हम पाते हैं कि क्यूक्रू . = 7 (0.95 के महत्व स्तर के लिए) और क्यूकरोड़ = 9 (0.99 के महत्व स्तर के लिए)।
निष्कर्ष
क्यों कि क्यू<क्यूकरोड़, तो रोसेनबाम मानदंड के अनुसार, नमूनों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण नहीं हैं।
टिप्पणी
रोसेनबाम परीक्षण का उपयोग चर के वितरण की प्रकृति की परवाह किए बिना किया जा सकता है, अर्थात, इस मामले में, दोनों नमूनों में वितरण के प्रकार को निर्धारित करने के लिए पियर्सन के 2 और कोलमोगोरोव के परीक्षणों का उपयोग करने की कोई आवश्यकता नहीं है।
7. 3. यू-मान-व्हिटनी परीक्षण
रोसेनबाम मानदंड के विपरीत, यूमान-व्हिटनी परीक्षण दो रैंक वाली पंक्तियों के बीच ओवरलैप ज़ोन का निर्धारण करने पर आधारित है, यानी ओवरलैप ज़ोन जितना छोटा होगा, नमूनों के बीच अंतर उतना ही महत्वपूर्ण होगा। इसके लिए अंतराल पैमानों को रैंक स्केल में बदलने के लिए एक विशेष प्रक्रिया का उपयोग किया जाता है।
आइए गणना एल्गोरिथ्म पर विचार करें यू-पिछले कार्य के उदाहरण पर मानदंड।
तालिका 7.2
| एक्स, वाई | आर xy | आर xy * | आरएक्स | आरआप |
| 26 28 32 32 33 34 35 38 39 40 41 42 43 44 | 2,5 2,5 5,5 5,5 11,5 11,5 16,5 16,5 18,5 18,5 20,5 20,5 25,5 25,5 27,5 27,5 | 2,5 11,5 16,5 18,5 20,5 25,5 27,5 | 1 2,5 5,5 5,5 7 9 11,5 15 16,5 18,5 20,5 23 25,5 27,5 | |
| Σ | 276,5 | 188,5 |
1. हम दो स्वतंत्र नमूनों से एकल रैंक वाली श्रृंखला बनाते हैं। इस स्थिति में, दोनों नमूनों के मान मिश्रित होते हैं, स्तंभ 1 ( एक्स, आप) आगे के काम (कंप्यूटर संस्करण सहित) को सरल बनाने के लिए, विभिन्न नमूनों के मूल्यों को अलग-अलग फोंट (या अलग-अलग रंगों) में चिह्नित किया जाना चाहिए, इस तथ्य को ध्यान में रखते हुए कि भविष्य में हम उन्हें अलग-अलग कॉलम में वितरित करेंगे।
2. मूल्यों के अंतराल पैमाने को एक क्रमसूचक में बदलना (ऐसा करने के लिए, हम सभी मानों को 1 से 30, कॉलम 2 के रैंक नंबरों के साथ फिर से डिज़ाइन करते हैं ( आरएक्सई))।
3. हम संबंधित रैंकों के लिए सुधार पेश करते हैं (वेरिएबल के समान मान समान रैंक द्वारा दर्शाए जाते हैं, बशर्ते कि रैंकों का योग नहीं बदलता है, कॉलम 3 ( आरएक्सई *)। इस स्तर पर, दूसरे और तीसरे कॉलम में रैंकों के योग की गणना करने की सिफारिश की जाती है (यदि सभी सुधार सही ढंग से दर्ज किए गए हैं, तो ये रकम बराबर होनी चाहिए)।
4. हम रैंक संख्याओं को एक विशेष नमूने (कॉलम 4 और 5 (कॉलम 4 और 5) से संबंधित उनके अनुसार फैलाते हैं। आरएक्स और आरवाई))।
5. हम सूत्र के अनुसार गणना करते हैं:
![]() (7.1)
(7.1)
कहाँ पे टी x रैंक राशियों में सबसे बड़ा है ; एनएक्स और एन y , क्रमशः, नमूना आकार। इस मामले में, ध्यान रखें कि यदि टीएक्स< टी y , फिर संकेतन एक्सतथा आपउलट दिया जाना चाहिए।
6. प्राप्त मूल्य की तालिका मूल्य के साथ तुलना करें (अनुलग्नक, तालिका IX देखें)। दो नमूनों के बीच अंतर की विश्वसनीयता के बारे में निष्कर्ष निकाला जाता है यदि यूक्स्प< यूकरोड़। .
हमारे उदाहरण में ![]() यूक्स्प = 83.5 > यू करोड़ = 71.
यूक्स्प = 83.5 > यू करोड़ = 71.
निष्कर्ष
मान-व्हिटनी परीक्षण के अनुसार दो नमूनों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण नहीं हैं।
टिप्पणियाँ
1. मान-व्हिटनी परीक्षण में व्यावहारिक रूप से कोई प्रतिबंध नहीं है; तुलना किए गए नमूनों के न्यूनतम आकार 2 और 5 लोग हैं (परिशिष्ट की तालिका IX देखें)।
2. इसी तरह रोसेनबाम परीक्षण के लिए, मान-व्हिटनी परीक्षण का उपयोग किसी भी नमूने के लिए किया जा सकता है, वितरण की प्रकृति की परवाह किए बिना।
छात्र की कसौटी
रोसेनबाम और मान-व्हिटनी मानदंड के विपरीत, मानदंड टीछात्र विधि पैरामीट्रिक है, अर्थात मुख्य सांख्यिकीय संकेतकों के निर्धारण के आधार पर - प्रत्येक नमूने में औसत मान ( और ) और उनके संस्करण (s 2 x और s 2 y), मानक फ़ार्मुलों का उपयोग करके गणना की जाती है (धारा 5 देखें)।
विद्यार्थी की कसौटी का उपयोग निम्नलिखित शर्तों को दर्शाता है:
1. दोनों नमूनों के मूल्यों के वितरण को कानून का पालन करना चाहिए सामान्य वितरण(खंड 6 देखें)।
2. नमूनों की कुल मात्रा कम से कम 30 (β 1 = 0.95 के लिए) और कम से कम 100 (β 2 = 0.99 के लिए) होनी चाहिए।
3. दो नमूनों की मात्रा एक दूसरे से महत्वपूर्ण रूप से भिन्न नहीं होनी चाहिए (1.5 2 बार से अधिक नहीं)।
छात्र की कसौटी का विचार काफी सरल है। मान लीजिए कि प्रत्येक नमूने में चर के मूल्यों को के अनुसार वितरित किया जाता है सामान्य कानून, यानी हम दो सामान्य वितरणों के साथ काम कर रहे हैं जो एक दूसरे से औसत मूल्यों और भिन्नता में भिन्न होते हैं (क्रमशः और, और, चित्र 7.1 देखें)।

एस एक्सएस आप
चावल। 7.1 दो स्वतंत्र नमूनों के बीच अंतर का अनुमान: और - नमूनों के माध्य मान एक्सतथा आप; एस एक्स और एस वाई - मानक विचलन
यह समझना आसान है कि दो नमूनों के बीच का अंतर जितना अधिक होगा, साधनों के बीच का अंतर उतना ही अधिक होगा और उनके प्रसरण (या मानक विचलन) भी कम होंगे।
स्वतंत्र नमूनों के मामले में, छात्र का गुणांक सूत्र द्वारा निर्धारित किया जाता है:
 (7.2)
(7.2)
कहाँ पे एनएक्स और एन y - क्रमशः, नमूनों की संख्या एक्सतथा आप.
मानक (महत्वपूर्ण) मूल्यों की तालिका में छात्र के गुणांक की गणना के बाद टी(परिशिष्ट, तालिका X देखें) स्वतंत्रता की डिग्री की संख्या के अनुरूप मान ज्ञात करें एन = एनएक्स + एन y - 2, और इसकी तुलना सूत्र द्वारा परिकलित एक से करें। यदि एक टीक्स्प £ टीकरोड़। , तो नमूनों के बीच अंतर की विश्वसनीयता के बारे में परिकल्पना को खारिज कर दिया जाता है, यदि टीक्स्प > टीकरोड़। , तो इसे स्वीकार किया जाता है। दूसरे शब्दों में, नमूने एक दूसरे से महत्वपूर्ण रूप से भिन्न होते हैं यदि सूत्र द्वारा परिकलित विद्यार्थी का गुणांक संगत महत्व स्तर के लिए सारणीबद्ध मान से अधिक हो।
जिस समस्या पर हमने पहले विचार किया था, उसमें औसत मूल्यों और प्रसरणों की गणना देता है निम्नलिखित मान: एक्ससीएफ = 38.5; σ एक्स 2 = 28.40; परसीएफ = 36.2; वाई 2 = 31.72।
यह देखा जा सकता है कि लड़कियों के समूह में चिंता का औसत मूल्य लड़कों के समूह की तुलना में अधिक है। हालांकि, ये अंतर इतने छोटे हैं कि सांख्यिकीय रूप से महत्वपूर्ण होने की संभावना नहीं है। लड़कों में मूल्यों का बिखराव, इसके विपरीत, लड़कियों की तुलना में थोड़ा अधिक है, लेकिन भिन्नताओं के बीच का अंतर भी छोटा है।

निष्कर्ष
टीक्स्प = 1.14< टीकरोड़। = 2.05 (β 1 = 0.95)। दो तुलनात्मक नमूनों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण नहीं हैं। यह निष्कर्ष रोसेनबाम और मान-व्हिटनी मानदंड का उपयोग करके प्राप्त किए गए निष्कर्ष के अनुरूप है।
छात्र के टी-टेस्ट का उपयोग करके दो नमूनों के बीच अंतर को निर्धारित करने का एक अन्य तरीका मानक विचलन के आत्मविश्वास अंतराल की गणना करना है। विश्वास अंतराल माध्य वर्ग (मानक) विचलन है जिसे नमूना आकार के वर्गमूल से विभाजित किया जाता है और इसके लिए छात्र के गुणांक के मानक मान से गुणा किया जाता है। एन- स्वतंत्रता की 1 डिग्री (क्रमशः, और)।
टिप्पणी
मूल्य = एम एक्समूल माध्य वर्ग त्रुटि कहलाती है (भाग 5 देखें)। इसलिए, कॉन्फिडेंस इंटरवल एक मानक त्रुटि है जिसे किसी दिए गए सैंपल साइज के लिए छात्र के गुणांक से गुणा किया जाता है, जहां स्वतंत्रता की डिग्री की संख्या = एन- 1, और के लिए दिया गया स्तरमहत्व।
दो नमूने जो एक दूसरे से स्वतंत्र हैं, उन्हें काफी भिन्न माना जाता है यदि विश्वास अंतरालक्योंकि ये नमूने एक दूसरे से ओवरलैप नहीं होते हैं। हमारे मामले में, हमारे पास पहले नमूने के लिए 38.5 ± 2.84 और दूसरे के लिए 36.2 ± 3.38 है।
इसलिए, यादृच्छिक विविधताएं एक्स मैं 35.66 41.34, और विविधताओं की सीमा में हैं यी- 32.82 39.58 की सीमा में। इसके आधार पर यह कहा जा सकता है कि नमूनों के बीच का अंतर एक्सतथा आपसांख्यिकीय रूप से अविश्वसनीय (विविधताओं की श्रेणियां एक दूसरे के साथ ओवरलैप होती हैं)। इस मामले में, यह ध्यान में रखा जाना चाहिए कि इस मामले में ओवरलैप क्षेत्र की चौड़ाई कोई फर्क नहीं पड़ता (केवल अतिव्यापी आत्मविश्वास अंतराल का तथ्य महत्वपूर्ण है)।
आश्रित नमूनों के लिए छात्र की विधि (उदाहरण के लिए, विषयों के एक ही नमूने पर बार-बार परीक्षण से प्राप्त परिणामों की तुलना करने के लिए) का उपयोग शायद ही कभी किया जाता है, क्योंकि इन उद्देश्यों के लिए अन्य, अधिक जानकारीपूर्ण तरीके हैं। सांख्यिकीय तरकीबें(धारा 10 देखें)। हालाँकि, इस उद्देश्य के लिए, पहले सन्निकटन के रूप में, आप निम्न प्रपत्र के विद्यार्थी सूत्र का उपयोग कर सकते हैं:
 (7.3)
(7.3)
प्राप्त परिणाम की तुलना तालिका मान के साथ की जाती है एन- स्वतंत्रता की 1 डिग्री, जहां एन- मूल्यों के जोड़े की संख्या एक्सतथा आप. तुलना के परिणामों की व्याख्या ठीक उसी तरह की जाती है जैसे दो स्वतंत्र नमूनों के बीच अंतर की गणना के मामले में की जाती है।
फिशर की कसौटी
फिशर मानदंड ( एफ) छात्र के टी-टेस्ट के समान सिद्धांत पर आधारित है, अर्थात, इसमें तुलना किए गए नमूनों में माध्य मानों और भिन्नताओं की गणना शामिल है। इसका उपयोग अक्सर उन नमूनों की तुलना करते समय किया जाता है जो एक दूसरे के साथ असमान आकार (आकार में भिन्न) होते हैं। फिशर का परीक्षण छात्र के परीक्षण की तुलना में कुछ अधिक कठोर है, और इसलिए उन मामलों में अधिक बेहतर है जहां मतभेदों की विश्वसनीयता के बारे में संदेह है (उदाहरण के लिए, यदि, छात्र के परीक्षण के अनुसार, अंतर शून्य पर महत्वपूर्ण हैं और पहले महत्व पर महत्वपूर्ण नहीं हैं स्तर)।
फिशर का सूत्र इस तरह दिखता है:
 (7.4)
(7.4)
और कहां  (7.5, 7.6)
(7.5, 7.6)
हमारी समस्या में d2= 5.29; z 2 = 29.94।
सूत्र में मान रखें: ![]()
तालिका में। XI अनुप्रयोगों में, हम पाते हैं कि महत्व स्तर β 1 = 0.95 और ν = . के लिए एनएक्स + एन y - 2 = 28 क्रांतिक मान 4.20 है।
निष्कर्ष
एफ = 1,32 < एफ करोड़।= 4.20. नमूनों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण नहीं हैं।
टिप्पणी
फिशर परीक्षण का उपयोग करते समय, छात्र के परीक्षण के समान शर्तों को पूरा किया जाना चाहिए (देखें उपधारा 7.4)। फिर भी, नमूनों की संख्या में दो गुना से अधिक के अंतर की अनुमति है।
इस प्रकार, चार के साथ एक ही समस्या को हल करते समय विभिन्न तरीकेदो गैर-पैरामीट्रिक और दो पैरामीट्रिक मानदंडों का उपयोग करके, हम एक स्पष्ट निष्कर्ष पर पहुंचे कि प्रतिक्रियाशील चिंता के स्तर के संदर्भ में लड़कियों के समूह और लड़कों के समूह के बीच अंतर अविश्वसनीय हैं (यानी, वे यादृच्छिक भिन्नताओं की सीमा के भीतर हैं ) हालांकि, ऐसे मामले भी हो सकते हैं जहां एक स्पष्ट निष्कर्ष निकालना संभव नहीं है: कुछ मानदंड विश्वसनीय हैं, अन्य - अविश्वसनीय अंतर। इन मामलों में, पैरामीट्रिक मानदंड (नमूना आकार की पर्याप्तता और अध्ययन के तहत मूल्यों के सामान्य वितरण के अधीन) को प्राथमिकता दी जाती है।
7. 6. मानदंड j* - फिशर का कोणीय परिवर्तन
जे*फिशर मानदंड को शोधकर्ता के लिए ब्याज के प्रभाव की घटना की आवृत्ति के अनुसार दो नमूनों की तुलना करने के लिए डिज़ाइन किया गया है। यह दो नमूनों के प्रतिशत के बीच अंतर के महत्व का मूल्यांकन करता है जिसमें ब्याज का प्रभाव दर्ज किया जाता है। एक ही नमूने के भीतर प्रतिशत की तुलना की भी अनुमति है।
फिशर कोणीय परिवर्तन का सार प्रतिशत का केंद्रीय कोणों में रूपांतरण है, जिसे रेडियन में मापा जाता है। एक बड़ा प्रतिशत एक बड़े कोण के अनुरूप होगा जे, और एक छोटा हिस्सा - एक छोटा कोण, लेकिन यहां संबंध गैर-रैखिक है:
![]()
कहाँ पे आर- प्रतिशत, एक इकाई के अंशों में व्यक्त।
कोण j 1 और j 2 के बीच विसंगति में वृद्धि और नमूनों की संख्या में वृद्धि के साथ, मानदंड का मूल्य बढ़ जाता है।
फिशर मानदंड की गणना निम्न सूत्र द्वारा की जाती है:
| |
जहां j 1 बड़े प्रतिशत के अनुरूप कोण है; j 2 - छोटे प्रतिशत के अनुरूप कोण; एन 1 और एन 2 - क्रमशः, पहले और दूसरे नमूनों की मात्रा।
सूत्र द्वारा परिकलित मान की तुलना मानक मान (j* st = 1.64 b 1 = 0.95 के लिए और j* st = 2.31 b 2 = 0.99 के लिए की जाती है। दो नमूनों के बीच अंतर को सांख्यिकीय रूप से महत्वपूर्ण माना जाता है यदि j*> j* महत्व के दिए गए स्तर के लिए सेंट।
उदाहरण
हम इस बात में रुचि रखते हैं कि क्या छात्रों के दो समूह एक जटिल कार्य को पूरा करने की सफलता के संदर्भ में एक दूसरे से भिन्न हैं। 20 लोगों के पहले समूह में, 12 छात्रों ने इसका मुकाबला किया, दूसरे में - 25 में से 10 लोग।
समाधान
1. अंकन दर्ज करें: एन 1 = 20, एन 2 = 25.
2. प्रतिशत की गणना करें आर 1 और आर 2: आर 1 = 12 / 20 = 0,6 (60%), आर 2 = 10 / 25 = 0,4 (40%).
3. तालिका में। बारहवीं आवेदन, हम प्रतिशत के अनुरूप φ के मान पाते हैं: जे 1 = 1.772, जे 2 = 1.369।
| |
यहाँ से:
निष्कर्ष
समूहों के बीच अंतर सांख्यिकीय रूप से महत्वपूर्ण नहीं हैं क्योंकि j*< j* ст для 1-го и тем более для 2-го уровня значимости.
7.7. पियर्सन के 2 परीक्षण और कोलमोगोरोव के परीक्षण . का उपयोग करना
असतत यादृच्छिक चर के संभाव्यता वितरण। द्विपद वितरण। पॉसों वितरण। ज्यामितीय वितरण। जनरेटिंग फंक्शन।
6. असतत यादृच्छिक चर का प्रायिकता वितरण
6.1. द्विपद वितरण
इसे उत्पादित होने दें एनस्वतंत्र परीक्षण, जिनमें से प्रत्येक में एक घटना एप्रकट हो सकता है या नहीं भी हो सकता है। संभावना पीकिसी घटना का घटित होना एसभी परीक्षणों में स्थिर है और परीक्षण से परीक्षण में नहीं बदलता है। एक यादृच्छिक चर X के रूप में घटना की घटनाओं की संख्या पर विचार करें एइन परीक्षणों में। किसी घटना के घटित होने की प्रायिकता ज्ञात करने का सूत्र एचिकना कएक बार एनपरीक्षण, जैसा कि ज्ञात है, वर्णित है बर्नौली सूत्र
बर्नौली सूत्र द्वारा परिभाषित प्रायिकता बंटन कहलाता है द्विपद .
इस नियम को "द्विपद" कहा जाता है क्योंकि न्यूटन के द्विपद के विस्तार में दाहिनी ओर को एक सामान्य शब्द माना जा सकता है
हम द्विपद नियम को तालिका के रूप में लिखते हैं
|
पी एन |
एनपी एन –1 क्यू |
|
क्यू एन |

आइए हम इस वितरण की संख्यात्मक विशेषताओं को खोजें।
परिभाषा से गणितीय अपेक्षा DSW के लिए हमारे पास है
 .
.
आइए हम समानता लिखते हैं, जो न्यूटन बिन है
 .
.
और पी के संबंध में इसे अलग करें। परिणामस्वरूप, हमें प्राप्त होता है
 .
.
बाईं ओर गुणा करें और दाईं ओरपर पी:
 .
.
मान लें कि पी+ क्यू= 1, हमारे पास है
 (6.2)
(6.2)
इसलिए, घटनाओं की घटनाओं की संख्या की गणितीय अपेक्षाएनस्वतंत्र परीक्षण परीक्षणों की संख्या के उत्पाद के बराबर हैएनसंभावना परपीप्रत्येक परीक्षण में एक घटना की घटना.
हम सूत्र द्वारा फैलाव की गणना करते हैं
 .
.
इसके लिए हम पाते हैं
 .
.
सबसे पहले, हम न्यूटन के द्विपद सूत्र में दो बार अंतर करते हैं पी:

और समीकरण के दोनों पक्षों को से गुणा करें पी 2:

फलस्वरूप,
अतः द्विपद बंटन का प्रसरण है
 .
(6.3)
.
(6.3)
ये परिणाम विशुद्ध रूप से गुणात्मक तर्क से भी प्राप्त किए जा सकते हैं। सभी परीक्षणों में घटना ए की कुल एक्स घटनाओं को व्यक्तिगत परीक्षणों में घटना की घटनाओं की संख्या में जोड़ा जाता है। इसलिए, यदि एक्स 1 पहले परीक्षण में घटना की घटनाओं की संख्या है, एक्स 2 - दूसरे में, आदि, तो सभी परीक्षणों में घटना ए की घटनाओं की कुल संख्या एक्स \u003d एक्स 1 + एक्स 2 + है ... + एक्स एन. गणितीय अपेक्षा की संपत्ति के अनुसार:
समानता के दायीं ओर प्रत्येक पद एक परीक्षण में घटनाओं की संख्या की गणितीय अपेक्षा है, जो घटना की संभावना के बराबर है। इस तरह,
फैलाव संपत्ति के अनुसार:
चूँकि , और एक यादृच्छिक चर की गणितीय अपेक्षा  , जो केवल दो मान ले सकता है, अर्थात् 1 2 प्रायिकता के साथ पीऔर 0 2 प्रायिकता के साथ क्यू, फिर
, जो केवल दो मान ले सकता है, अर्थात् 1 2 प्रायिकता के साथ पीऔर 0 2 प्रायिकता के साथ क्यू, फिर  . इस तरह,
. इस तरह,  परिणामस्वरूप, हमें प्राप्त होता है
परिणामस्वरूप, हमें प्राप्त होता है
प्रारंभिक और केंद्रीय क्षणों की अवधारणा का उपयोग करते हुए, कोई व्यक्ति तिरछापन और कर्टोसिस के लिए सूत्र प्राप्त कर सकता है:
 .
(6.4)
.
(6.4)

चावल। 6.1
द्विपद बंटन के बहुभुज का निम्न रूप होता है (देखिए आकृति 6.1)। प्रायिकता पी एन (क) पहले बढ़ने के साथ बढ़ता है क, पहुँचती है सबसे बड़ा मूल्यऔर फिर घटने लगती है। मामले को छोड़कर द्विपद वितरण विषम है पी=0.5. ध्यान दें कि बड़ी संख्या में परीक्षणों के लिए एनद्विपद वितरण सामान्य के बहुत करीब है। (इस प्रस्ताव का औचित्य स्थानीय मोइवर-लाप्लास प्रमेय से संबंधित है।)संख्याएम 0 किसी घटना के घटित होने को कहते हैंसबसे अधिक संभावना , यदि परीक्षणों की इस श्रृंखला में दी गई संख्या में घटना की संभावना सबसे बड़ी है (वितरण बहुभुज में अधिकतम). द्विपद वितरण के लिए
टिप्पणी। द्विपद संभावनाओं के लिए आवर्तक सूत्र का उपयोग करके इस असमानता को सिद्ध किया जा सकता है:
 (6.6)
(6.6)
उदाहरण 6.1.इस उद्यम में प्रीमियम उत्पादों की हिस्सेदारी 31% है। 75 मदों के यादृच्छिक रूप से चयनित बैच में माध्य और विचरण, प्रीमियम मदों की सर्वाधिक संभावित संख्या क्या है?
समाधान। क्यों कि पी=0,31, क्यू=0,69, एन=75, तब
एम[ एक्स] = एनपी= 750.31 = 23.25; डी[ एक्स] = एनपीक्यू = 750,310,69 = 16,04.
सबसे संभावित संख्या खोजने के लिए एम 0 , हम एक दोहरी असमानता की रचना करते हैं
इसलिए यह इस प्रकार है कि एम 0 = 23.
द्विपद बंटन एक अत्यंत महत्वपूर्ण प्रायिकता बंटनों में से एक है, जो कि विवेकपूर्ण रूप से बदलते यादृच्छिक चर के लिए है। द्विपद बंटन किसी संख्या का प्रायिकता बंटन है एमप्रतिस्पर्धा लेकिनमें एनपरस्पर स्वतंत्र अवलोकन. अक्सर एक घटना लेकिनअवलोकन की "सफलता" और विपरीत घटना - "विफलता" कहा जाता है, लेकिन यह पदनाम बहुत सशर्त है।
द्विपद वितरण की शर्तें:
- कुल में किया गया एनपरीक्षण जिसमें घटना लेकिनहो भी सकता है और नहीं भी;
- प्रतिस्पर्धा लेकिनप्रत्येक परीक्षण में समान संभावना के साथ हो सकता है पी;
- परीक्षण परस्पर स्वतंत्र हैं।
संभावना है कि in एनपरीक्षण घटना लेकिनबिल्कुल एमबर्नौली सूत्र का उपयोग करके समय की गणना की जा सकती है:
![]()
![]() ,
,
कहाँ पे पी- होने वाली घटना की संभावना लेकिन;
क्यू = 1 - पीविपरीत घटना के घटित होने की प्रायिकता है।
आइए इसका पता लगाते हैं क्यों द्विपद वितरण ऊपर वर्णित तरीके से बर्नौली सूत्र से संबंधित है . घटना - सफलताओं की संख्या एनपरीक्षणों को कई विकल्पों में विभाजित किया जाता है, जिनमें से प्रत्येक में सफलता प्राप्त की जाती है एमपरीक्षण, और विफलता - में एन - एमपरीक्षण। इनमें से किसी एक विकल्प पर विचार करें - बी1 . प्रायिकताओं के योग के नियम के अनुसार, हम विपरीत घटनाओं की प्रायिकताओं को गुणा करते हैं:
![]() ,
,
और अगर हम निरूपित करते हैं क्यू = 1 - पी, फिर
![]() .
.
इसी प्रायिकता के पास कोई अन्य विकल्प होगा जिसमें एमसफलता और एन - एमविफलताएं ऐसे विकल्पों की संख्या उन तरीकों की संख्या के बराबर है जिनसे यह संभव है एनपरीक्षण प्राप्त करें एमसफलता।
सभी की संभावनाओं का योग एमघटना संख्या लेकिन(संख्या 0 से . तक एन) एक के बराबर है:
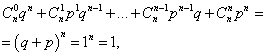
जहाँ प्रत्येक पद न्यूटन द्विपद का एक पद है। इसलिए, माना गया वितरण द्विपद बंटन कहलाता है।
व्यवहार में, अक्सर "अधिकतम" संभावनाओं की गणना करना आवश्यक होता है एममें सफलता एनपरीक्षण" या "कम से कम एममें सफलता एनपरीक्षण"। इसके लिए, निम्नलिखित सूत्रों का उपयोग किया जाता है।
अभिन्न कार्य, अर्थात् संभावना एफ(एम) में है कि एनअवलोकन घटना लेकिनअब नहीं आएगा एमएक बार, सूत्र का उपयोग करके गणना की जा सकती है:
इसकी बारी में संभावना एफ(≥एम) में है कि एनअवलोकन घटना लेकिनकम से कम आओ एमएक बार, सूत्र द्वारा गणना की जाती है:
कभी-कभी प्रायिकता की गणना करना अधिक सुविधाजनक होता है कि in एनअवलोकन घटना लेकिनअब नहीं आएगा एमबार, विपरीत घटना की संभावना के माध्यम से:
![]() .
.
किस सूत्र का उपयोग करना है यह इस बात पर निर्भर करता है कि उनमें से किसमें कम शब्द हैं।
द्विपद वितरण की विशेषताओं की गणना निम्नलिखित सूत्रों का उपयोग करके की जाती है: .
अपेक्षित मूल्य: ।
फैलाव:।
मानक विचलन: ।
एमएस एक्सेल में द्विपद वितरण और गणना
द्विपद वितरण संभावना पीएन ( एम) और अभिन्न कार्य का मूल्य एफ(एम) की गणना MS Excel फ़ंक्शन BINOM.DIST का उपयोग करके की जा सकती है। संबंधित गणना के लिए विंडो नीचे दिखाई गई है (विस्तार करने के लिए बाईं माउस बटन पर क्लिक करें)।

एमएस एक्सेल के लिए आपको निम्नलिखित डेटा दर्ज करने की आवश्यकता है:
- सफलताओं की संख्या;
- परीक्षणों की संख्या;
- सफलता की संभावना;
- अभिन्न - तार्किक मूल्य: 0 - यदि आपको संभाव्यता की गणना करने की आवश्यकता है पीएन ( एम) और 1 - यदि प्रायिकता एफ(एम).
उदाहरण 1कंपनी के प्रबंधक ने पिछले 100 दिनों में बेचे गए कैमरों की संख्या के बारे में जानकारी संक्षेप में दी। तालिका जानकारी को सारांशित करती है और संभावनाओं की गणना करती है कि दिन बेचा जाएगा निश्चित संख्याकैमरे।
13 या अधिक कैमरे बेचे जाने पर दिन का अंत लाभ के साथ होता है। संभावना है कि दिन एक लाभ के साथ काम किया जाएगा:
![]()
संभावना है कि दिन बिना लाभ के काम करेगा:

मान लें कि दिन के लाभ के साथ काम करने की संभावना स्थिर और 0.61 के बराबर है, और प्रति दिन बेचे जाने वाले कैमरों की संख्या दिन पर निर्भर नहीं करती है। तब आप द्विपद बंटन का उपयोग कर सकते हैं, जहां घटना लेकिन- दिन लाभ के साथ काम करेगा, - बिना लाभ के।
संभावना है कि 6 दिनों में से सभी को लाभ के साथ काम किया जाएगा:
![]() .
.
हमें MS Excel फ़ंक्शन BINOM.DIST का उपयोग करके समान परिणाम मिलता है (अभिन्न मान का मान 0 है):
पी 6 (6 ) = बिनोम.डिस्ट (6; 6; 0.61; 0) = 0.052।
संभावना है कि 6 दिनों में से 4 या अधिक दिनों में लाभ के साथ काम किया जाएगा:
कहाँ पे ![]() ,
,
![]() ,
,
एमएस एक्सेल फ़ंक्शन BINOM.DIST का उपयोग करके, हम इस संभावना की गणना करते हैं कि 6 दिनों में से 3 दिनों से अधिक लाभ के साथ पूरा नहीं होगा (अभिन्न मूल्य का मान 1 है):
पी 6 (≤3 ) = बिनोम.डिस्ट (3, 6, 0.61, 1) = 0.435।
संभावना है कि 6 दिनों में से सभी को नुकसान के साथ काम किया जाएगा:
![]() ,
,
हम एमएस एक्सेल फ़ंक्शन BINOM.DIST का उपयोग करके समान संकेतक की गणना करते हैं:
पी 6 (0 ) = बिनोम.डिस्ट (0; 6; 0.61; 0) = 0.0035।
समस्या को स्वयं हल करें और फिर समाधान देखें
उदाहरण 2एक कलश में 2 सफेद गेंदें और 3 काली गेंदें हैं। कलश से एक गेंद निकाली जाती है, रंग सेट किया जाता है और वापस रख दिया जाता है। प्रयास 5 बार दोहराया जाता है। सफेद गेंदों की उपस्थिति की संख्या - असतत यादृच्छिक मूल्य एक्स, द्विपद नियम के अनुसार वितरित। एक यादृच्छिक चर के वितरण के नियम की रचना करें। बहुलक, गणितीय अपेक्षा और प्रसरण का निर्धारण करें।
हम एक साथ समस्याओं को हल करना जारी रखते हैं
उदाहरण 3वस्तुओं के लिए कूरियर सेवा से चला गया एन= 5 कूरियर। एक संभावना के साथ प्रत्येक कूरियर पी= 0.3 दूसरों की परवाह किए बिना वस्तु के लिए देर हो चुकी है। असतत यादृच्छिक चर एक्स- देर से कोरियर की संख्या। इस यादृच्छिक चर की एक वितरण श्रृंखला की रचना कीजिए। इसकी गणितीय अपेक्षा, प्रसरण, मानक विचलन ज्ञात कीजिए। वस्तुओं के लिए कम से कम दो कोरियर देर से आने की प्रायिकता ज्ञात कीजिए।
द्विपद वितरण पर विचार करें, इसकी गणितीय अपेक्षा, विचरण, बहुलक की गणना करें। MS EXCEL फ़ंक्शन BINOM.DIST () का उपयोग करके, हम वितरण फ़ंक्शन और संभाव्यता घनत्व ग्राफ़ प्लॉट करेंगे। आइए हम वितरण पैरामीटर p, वितरण की गणितीय अपेक्षा और मानक विचलन का अनुमान लगाएं। बर्नौली वितरण पर भी विचार करें।
परिभाषा. उन्हें आयोजित होने दें एनपरीक्षण, जिनमें से प्रत्येक में केवल 2 घटनाएं हो सकती हैं: घटना "सफलता" एक संभावना के साथ पी या घटना "विफलता" संभावना के साथ क्यू = 1-पी (तथाकथित बरनौली योजना,Bernoulliपरीक्षणों).
ठीक-ठीक आने की प्रायिकता एक्स इनमें सफलता एन परीक्षण के बराबर है:
नमूने में सफलताओं की संख्या एक्स एक यादृच्छिक चर है जिसमें द्विपद वितरण(अंग्रेज़ी) द्विपदवितरण) पीतथा एन– इस वितरण के पैरामीटर हैं।
याद रखें कि आवेदन करने के लिए बर्नौली योजनाएंऔर तदनुसार द्विपद वितरण,निम्नलिखित शर्तों को पूरा किया जाना चाहिए:
- प्रत्येक परीक्षण के ठीक दो परिणाम होने चाहिए, जिन्हें सशर्त रूप से "सफलता" और "विफलता" कहा जाता है।
- प्रत्येक परीक्षण का परिणाम पिछले परीक्षणों (परीक्षण स्वतंत्रता) के परिणामों पर निर्भर नहीं होना चाहिए।
- सफलता दर पी सभी परीक्षणों के लिए स्थिर होना चाहिए।
एमएस एक्सेल में द्विपद वितरण
MS EXCEL में, संस्करण 2010 से शुरू, के लिए द्विपद वितरणएक फ़ंक्शन है BINOM.DIST() , अंग्रेजी नाम- BINOM.DIST (), जो आपको इस संभावना की गणना करने की अनुमति देता है कि नमूना बिल्कुल होगा एक्स"सफलताएं" (यानी। संभाव्यता घनत्व कार्य p(x), ऊपर सूत्र देखें), और अभिन्न वितरण समारोह(संभावना है कि नमूना होगा एक्सया कम "सफलताएं", 0 सहित)।
MS EXCEL 2010 से पहले, EXCEL में BINOMDIST () फ़ंक्शन था, जो आपको गणना करने की भी अनुमति देता है वितरण समारोहतथा संभावित गहराईपी (एक्स)। अनुकूलता के लिए BINOMDIST () को MS EXCEL 2010 में छोड़ दिया गया है।
उदाहरण फ़ाइल में ग्राफ़ हैं संभाव्यता वितरण घनत्वतथा .

द्विपद वितरणपदनाम है बी(एन; पी) .
टिप्पणी: भवन निर्माण के लिए अभिन्न वितरण समारोहसही फिट चार्ट प्रकार अनुसूची, के लिये वितरण घनत्व – समूहन के साथ हिस्टोग्राम. चार्ट बनाने के बारे में अधिक जानकारी के लिए आलेख मुख्य प्रकार के चार्ट पढ़ें।
टिप्पणी: उदाहरण फ़ाइल में सूत्र लिखने की सुविधा के लिए, मापदंडों के लिए नाम बनाए गए हैं द्विपद वितरण: एन और पी।

उदाहरण फ़ाइल MS EXCEL फ़ंक्शंस का उपयोग करके विभिन्न संभाव्यता गणनाएँ दिखाती है:

जैसा कि ऊपर की तस्वीर में देखा गया है, यह माना जाता है कि:
- जिस अनंत जनसंख्या से नमूना बनाया गया है उसमें 10% (या 0.1) अच्छे तत्व (पैरामीटर .) हैं पी, तीसरा फ़ंक्शन तर्क =BINOM.DIST() )
- प्रायिकता की गणना करने के लिए कि 10 तत्वों के नमूने में (पैरामीटर .) एन, फ़ंक्शन का दूसरा तर्क) ठीक 5 मान्य तत्व होंगे (पहला तर्क), आपको सूत्र लिखने की आवश्यकता है: =BINOM.DIST(5, 10, 0.1, FALSE)
- अंतिम, चौथा तत्व सेट है = FALSE, यानी। फ़ंक्शन मान लौटाया जाता है वितरण घनत्व.
यदि चौथे तर्क का मान = TRUE है, तो BINOM.DIST() फ़ंक्शन मान लौटाता है अभिन्न वितरण समारोहया केवल वितरण समारोह. इस मामले में, आप इस संभावना की गणना कर सकते हैं कि नमूने में अच्छी वस्तुओं की संख्या एक निश्चित सीमा से होगी, उदाहरण के लिए, 2 या उससे कम (0 सहित)।
ऐसा करने के लिए, आपको सूत्र लिखना होगा:
= BINOM.DIST(2, 10, 0.1, TRUE)
टिप्पणी: x के गैर-पूर्णांक मान के लिए, . उदाहरण के लिए, निम्न सूत्र समान मान लौटाएंगे:
= बिनोम। जिला ( 2
; दस; 0.1; सच)
= बिनोम। जिला ( 2,9
; दस; 0.1; सच)
टिप्पणी: उदाहरण फ़ाइल में संभावित गहराईतथा वितरण समारोहपरिभाषा और COMBIN () फ़ंक्शन का उपयोग करके भी गणना की जाती है।
वितरण संकेतक
पर शीट पर उदाहरण फ़ाइल उदाहरणकुछ वितरण संकेतकों की गणना के लिए सूत्र हैं:
- = एन * पी;
- (वर्ग मानक विचलन) = n*p*(1-p);
- = (एन+1)*पी;
- =(1-2*p)*रूट(n*p*(1-p)).
हम सूत्र प्राप्त करते हैं गणितीय अपेक्षा द्विपद वितरणका उपयोग करते हुए बर्नौली योजना.
परिभाषा के अनुसार, एक यादृच्छिक चर X in बर्नौली योजना(बर्नौली यादृच्छिक चर) है वितरण समारोह:

इस वितरण को कहा जाता है बर्नौली वितरण.
टिप्पणी: बर्नौली वितरण- विशेष मामला द्विपद वितरणपैरामीटर एन = 1 के साथ।
आइए सफलता की विभिन्न संभावनाओं के साथ 100 संख्याओं के 3 सरणियाँ उत्पन्न करें: 0.1; 0.5 और 0.9। ऐसा करने के लिए, विंडो में पीढ़ी यादृच्छिक संख्या प्रत्येक प्रायिकता p के लिए निम्नलिखित पैरामीटर सेट करें:
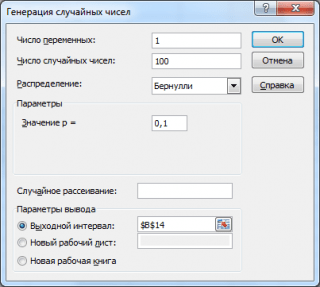
टिप्पणी: यदि आप विकल्प सेट करते हैं यादृच्छिक बिखराव (यादृच्छिक बीज), तो आप जेनरेट की गई संख्याओं का एक निश्चित यादृच्छिक सेट चुन सकते हैं। उदाहरण के लिए, यह विकल्प = 25 सेट करके, आप विभिन्न कंप्यूटरों पर यादृच्छिक संख्याओं के समान सेट उत्पन्न कर सकते हैं (यदि, निश्चित रूप से, अन्य वितरण पैरामीटर समान हैं)। विकल्प मान 1 से 32,767 तक पूर्णांक मान ले सकता है। विकल्प का नाम यादृच्छिक बिखरावभ्रमित कर सकते हैं। इसका अनुवाद करना बेहतर होगा यादृच्छिक संख्याओं के साथ संख्या सेट करें.
नतीजतन, हमारे पास 100 नंबरों के 3 कॉलम होंगे, जिनके आधार पर, उदाहरण के लिए, हम सफलता की संभावना का अनुमान लगा सकते हैं पीसूत्र के अनुसार: सफलताओं की संख्या/100(सेमी। उदाहरण फ़ाइल शीट बर्नौली उत्पन्न करना).
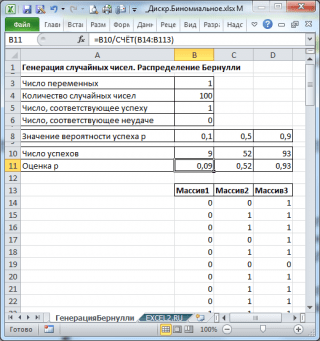
टिप्पणी: के लिये बर्नौली वितरण p=0.5 के साथ, आप सूत्र =RANDBETWEEN(0;1) का उपयोग कर सकते हैं, जो .
यादृच्छिक संख्या पीढ़ी। द्विपद वितरण
मान लीजिए नमूने में 7 दोषपूर्ण वस्तुएँ हैं। इसका मतलब है कि यह "बहुत संभावना है" कि दोषपूर्ण उत्पादों का अनुपात बदल गया है। पी, जो हमारी उत्पादन प्रक्रिया की एक विशेषता है। हालांकि यह स्थिति "बहुत संभावना" है, एक संभावना है (अल्फा जोखिम, टाइप 1 त्रुटि, "गलत अलार्म") कि पीअपरिवर्तित रहा, और दोषपूर्ण उत्पादों की बढ़ती संख्या यादृच्छिक नमूने के कारण थी।
जैसा कि नीचे दिए गए चित्र में देखा जा सकता है, 7 दोषपूर्ण उत्पादों की संख्या है जो समान मूल्य पर p = 0.21 के साथ एक प्रक्रिया के लिए स्वीकार्य है। अल्फा. यह दर्शाता है कि जब किसी नमूने में दोषपूर्ण वस्तुओं की सीमा पार हो जाती है, पी"शायद" बढ़ गया। वाक्यांश "संभावना" का अर्थ है कि केवल 10% संभावना (100% -90%) है कि दहलीज से ऊपर दोषपूर्ण उत्पादों के प्रतिशत का विचलन केवल यादृच्छिक कारणों से होता है।

इस प्रकार, नमूने में दोषपूर्ण उत्पादों की दहलीज से अधिक संख्या एक संकेत के रूप में काम कर सकती है कि प्रक्रिया परेशान हो गई है और बी का उत्पादन शुरू हो गया है के बारे मेंदोषपूर्ण उत्पादों का उच्च प्रतिशत।
टिप्पणी: MS EXCEL 2010 से पहले, EXCEL का एक फंक्शन CRITBINOM() था, जो BINOM.INV() के बराबर है। CRITBINOM () को संगतता के लिए MS EXCEL 2010 और उच्चतर में छोड़ दिया गया है।
द्विपद वितरण का अन्य वितरणों से संबंध
यदि पैरामीटर एन द्विपद वितरणअनंत की ओर जाता है और पी 0 पर जाता है, तो इस मामले में द्विपद वितरणअनुमानित किया जा सकता है।
सन्निकटन होने पर स्थितियां बनाना संभव है पॉसों वितरणअच्छा काम करता है:
- पी<0,1 (कम पीऔर अधिक एन, अधिक सटीक सन्निकटन);
- पी>0,9 (उस पर विचार करना क्यू=1- पी, इस मामले में गणना का उपयोग करके किया जाना चाहिए क्यू(एक एक्सके साथ प्रतिस्थापित करने की आवश्यकता है एन- एक्स) इसलिए, कम क्यूऔर अधिक एन, अधिक सटीक सन्निकटन)।
0.1 . पर<=p<=0,9 и n*p>10 द्विपद वितरणअनुमानित किया जा सकता है।
इसकी बारी में, द्विपद वितरणजनसंख्या का आकार N होने पर एक अच्छे सन्निकटन के रूप में कार्य कर सकता है हाइपरज्यामितीय वितरणनमूना आकार n से बहुत बड़ा (यानी, N>>n या n/N<<1).
आप लेख में उपरोक्त वितरणों के संबंध के बारे में अधिक पढ़ सकते हैं। सन्निकटन के उदाहरण भी वहाँ दिए गए हैं, और शर्तों को समझाया गया है कि यह कब संभव है और किस सटीकता के साथ।
सलाह: आप लेख में एमएस एक्सेल के अन्य वितरणों के बारे में पढ़ सकते हैं।
इसमें और अगले कुछ नोट्स में, हम यादृच्छिक घटनाओं के गणितीय मॉडल पर विचार करेंगे। गणित का मॉडलएक गणितीय व्यंजक है जो एक यादृच्छिक चर का प्रतिनिधित्व करता है। असतत यादृच्छिक चर के लिए, इस गणितीय अभिव्यक्ति को वितरण फ़ंक्शन के रूप में जाना जाता है।
यदि समस्या आपको एक यादृच्छिक चर का प्रतिनिधित्व करने वाले गणितीय अभिव्यक्ति को स्पष्ट रूप से लिखने की अनुमति देती है, तो आप इसके किसी भी मान की सटीक संभावना की गणना कर सकते हैं। इस मामले में, आप वितरण फ़ंक्शन के सभी मानों की गणना और सूची कर सकते हैं। व्यवसाय, समाजशास्त्रीय और चिकित्सा अनुप्रयोगों में, यादृच्छिक चर के विभिन्न वितरण होते हैं। सबसे उपयोगी वितरणों में से एक द्विपद है।
द्विपद वितरणनिम्नलिखित विशेषताओं की विशेषता वाली स्थितियों को मॉडल करने के लिए उपयोग किया जाता है।
- नमूने में निश्चित संख्या में तत्व होते हैं एनकिसी परीक्षण के परिणाम का प्रतिनिधित्व करना।
- प्रत्येक नमूना तत्व दो परस्पर अनन्य श्रेणियों में से एक से संबंधित है जो संपूर्ण नमूना स्थान को कवर करता है। आमतौर पर, इन दो श्रेणियों को सफलता और विफलता कहा जाता है।
- सफलता की संभावना आरस्थिर है। इसलिए, विफलता की संभावना है 1 - पी.
- किसी भी परीक्षण का परिणाम (अर्थात सफलता या विफलता) दूसरे परीक्षण के परिणाम से स्वतंत्र होता है। परिणामों की स्वतंत्रता सुनिश्चित करने के लिए, नमूना आइटम आमतौर पर दो अलग-अलग तरीकों का उपयोग करके प्राप्त किए जाते हैं। प्रत्येक नमूना तत्व यादृच्छिक रूप से एक अनंत आबादी से प्रतिस्थापन के बिना या प्रतिस्थापन के साथ एक सीमित आबादी से खींचा जाता है।
नोट या प्रारूप में डाउनलोड करें, प्रारूप में उदाहरण
द्विपद बंटन का प्रयोग एक नमूने में सफलताओं की संख्या का अनुमान लगाने के लिए किया जाता है जिसमें एनअवलोकन। आइए एक उदाहरण के रूप में आदेश दें। सैक्सन कंपनी के ग्राहक ऑर्डर देने और कंपनी को भेजने के लिए एक इंटरैक्टिव इलेक्ट्रॉनिक फॉर्म का उपयोग कर सकते हैं। फिर सूचना प्रणाली जाँच करती है कि क्या आदेशों में कोई त्रुटि है, साथ ही अधूरी या गलत जानकारी है। संदेह में किसी भी आदेश को चिह्नित किया जाता है और दैनिक अपवाद रिपोर्ट में शामिल किया जाता है। कंपनी द्वारा एकत्र किया गया डेटा इंगित करता है कि ऑर्डर में त्रुटियों की संभावना 0.1 है। कंपनी यह जानना चाहेगी कि दिए गए नमूने में एक निश्चित संख्या में गलत ऑर्डर मिलने की प्रायिकता क्या है। उदाहरण के लिए, मान लीजिए कि ग्राहकों ने चार इलेक्ट्रॉनिक फॉर्म भरे हैं। इसकी क्या प्रायिकता है कि सभी आर्डर त्रुटिरहित होंगे? इस संभावना की गणना कैसे करें? सफलता से हमारा तात्पर्य फ़ॉर्म भरते समय एक त्रुटि से है, और हम अन्य सभी परिणामों को विफलता मानेंगे। याद रखें कि हम दिए गए नमूने में गलत आदेशों की संख्या में रुचि रखते हैं।
हम क्या परिणाम देख सकते हैं? यदि नमूने में चार आदेश हैं, तो एक, दो, तीन या सभी चार गलत हो सकते हैं, इसके अलावा, वे सभी सही ढंग से भरे जा सकते हैं। क्या गलत तरीके से भरे गए फॉर्मों की संख्या का वर्णन करने वाला यादृच्छिक चर किसी अन्य मूल्य पर ले सकता है? यह संभव नहीं है क्योंकि गलत तरीके से भरे गए फॉर्मों की संख्या नमूना आकार से अधिक नहीं हो सकती है एनया नकारात्मक हो। इस प्रकार, द्विपद वितरण नियम का पालन करने वाला एक यादृच्छिक चर 0 से . तक मान लेता है एन.
मान लीजिए कि चार आदेशों के नमूने में निम्नलिखित परिणाम देखे गए हैं:
चार ऑर्डर के नमूने में और निर्दिष्ट क्रम में तीन गलत ऑर्डर मिलने की प्रायिकता क्या है? चूंकि प्रारंभिक अध्ययनों से पता चला है कि फॉर्म को पूरा करने में त्रुटि की संभावना 0.10 है, उपरोक्त परिणामों की संभावनाओं की गणना निम्नानुसार की जाती है:
चूंकि परिणाम एक दूसरे से स्वतंत्र होते हैं, इसलिए परिणामों के संकेतित अनुक्रम की प्रायिकता बराबर होती है: p*p*(1-p)*p = 0.1*0.1*0.9*0.1 = 0.0009। यदि विकल्पों की संख्या की गणना करना आवश्यक है एक्स एनतत्वों, आपको संयोजन सूत्र (1) का उपयोग करना चाहिए:

जहां एन! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - संख्या का भाज्य एन, और 0! = 1 और 1! = 1 परिभाषा के अनुसार।
इस अभिव्यक्ति को अक्सर कहा जाता है। इस प्रकार, यदि n = 4 और X = 3, आकार 4 के नमूने से निकाले गए तीन तत्वों से युक्त अनुक्रमों की संख्या निम्न सूत्र द्वारा निर्धारित की जाती है:
इसलिए, तीन गलत ऑर्डर मिलने की संभावना की गणना निम्नानुसार की जाती है:
(संभावित अनुक्रमों की संख्या) *
(किसी विशेष क्रम की प्रायिकता) = 4 * 0.0009 = 0.0036
इसी तरह, हम इस संभावना की गणना कर सकते हैं कि चार आदेशों में से एक या दो गलत हैं, साथ ही संभावना है कि सभी आदेश गलत हैं या सभी सही हैं। हालाँकि, जैसे-जैसे नमूना आकार बढ़ता है एनपरिणामों के किसी विशेष अनुक्रम की प्रायिकता निर्धारित करना अधिक कठिन हो जाता है। इस मामले में, एक उपयुक्त गणितीय मॉडल लागू किया जाना चाहिए जो विकल्पों की संख्या के द्विपद वितरण का वर्णन करता है एक्सएक नमूने से वस्तुएँ जिसमें एनतत्व
द्विपद वितरण

कहाँ पे पी (एक्स)- संभावना एक्सकिसी दिए गए नमूना आकार के लिए सफलता एनऔर सफलता की संभावना आर, एक्स = 0, 1, … एन.
इस तथ्य पर ध्यान दें कि सूत्र (2) सहज निष्कर्षों का औपचारिककरण है। यादृच्छिक मूल्य एक्स, द्विपद बंटन का पालन करते हुए, 0 से तक की सीमा में कोई भी पूर्णांक मान ले सकता है एन. काम आरएक्स(1 - पी)एन – एक्सएक विशेष अनुक्रम की संभावना है जिसमें एक्सनमूने में सफलता, जिसका आकार बराबर है एन. मान से मिलकर संभव संयोजनों की संख्या निर्धारित करता है एक्समें सफलता एनपरीक्षण। इसलिए, दिए गए परीक्षणों की संख्या के लिए एनऔर सफलता की संभावना आरसे मिलकर बने अनुक्रम की प्रायिकता एक्ससफलता के बराबर है
P(X) = (संभावित अनुक्रमों की संख्या) * (किसी विशेष अनुक्रम की प्रायिकता) = 
सूत्र (2) के अनुप्रयोग को दर्शाने वाले उदाहरणों पर विचार करें।
1. मान लेते हैं कि गलत फॉर्म भरने की प्रायिकता 0.1 है। इसकी क्या प्रायिकता है कि भरे गए चार में से तीन फॉर्म गलत होंगे? सूत्र (2) का उपयोग करके, हम प्राप्त करते हैं कि चार आदेशों के नमूने में तीन गलत आदेशों को खोजने की संभावना बराबर है
2. मान लें कि फॉर्म को गलत तरीके से भरने की प्रायिकता 0.1 है। इसकी क्या प्रायिकता है कि भरे गए चार में से कम से कम तीन फॉर्म गलत होंगे? जैसा कि पिछले उदाहरण में दिखाया गया है, चार भरे हुए फॉर्मों में से तीन के गलत होने की प्रायिकता 0.0036 है। इस संभावना की गणना करने के लिए कि चार भरे हुए फॉर्मों में से कम से कम तीन गलत तरीके से भरे जाएंगे, आपको इस संभावना को जोड़ना होगा कि चार भरे हुए फॉर्मों में से तीन गलत होंगे, और संभावना है कि चार पूर्ण फॉर्मों में से सभी गलत होंगे। दूसरी घटना की संभावना है
इस प्रकार, चार पूर्ण रूपों में से कम से कम तीन के गलत होने की प्रायिकता बराबर है
पी (एक्स> 3) = पी (एक्स = 3) + पी (एक्स = 4) = 0.0036 + 0.0001 = 0.0037
3. मान लें कि फॉर्म को गलत तरीके से भरने की संभावना 0.1 है। इसकी क्या प्रायिकता है कि भरे गए चार में से तीन से कम फॉर्म गलत होंगे? इस घटना की संभावना
पी(एक्स< 3) = P(X = 0) + P(X = 1) + P(X = 2)
सूत्र (2) का उपयोग करके, हम इनमें से प्रत्येक संभावना की गणना करते हैं:

इसलिए, पी(एक्स< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
प्रायिकता P(X .)< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. तब P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
जैसे-जैसे नमूना आकार बढ़ता है एनउदाहरण 3 में की गई गणनाओं के समान गणना कठिन हो जाती है। इन जटिलताओं से बचने के लिए, कई द्विपद संभावनाओं को समय से पहले सारणीबद्ध किया जाता है। इनमें से कुछ संभावनाओं को अंजीर में दिखाया गया है। 1. उदाहरण के लिए, प्रायिकता प्राप्त करने के लिए कि एक्स= 2 पर एन= 4 और पी= 0.1, आपको तालिका से रेखा के प्रतिच्छेदन की संख्या निकालनी चाहिए एक्स= 2 और कॉलम आर = 0,1.

चावल। 1. द्विपद प्रायिकता पर एन = 4, एक्स= 2 और आर = 0,1
द्विपद वितरण की गणना का उपयोग करके की जा सकती है एक्सेल फ़ंक्शन=BINOM.DIST() (चित्र 2), जिसमें 4 पैरामीटर हैं: सफलताओं की संख्या - एक्स, परीक्षणों की संख्या (या नमूना आकार) - एन, सफलता की संभावना है आर, पैरामीटर अभिन्न, जो मान लेता है TRUE (इस मामले में, संभावना की गणना की जाती है कम से कम एक्सघटनाएँ) या FALSE (इस मामले में, की प्रायिकता बिल्कुल एक्सआयोजन)।

चावल। 2. फ़ंक्शन पैरामीटर = बिनोम.डिस्ट ()
उपरोक्त तीन उदाहरणों के लिए, गणना अंजीर में दिखाई गई है। 3 (एक्सेल फ़ाइल भी देखें)। प्रत्येक कॉलम में एक सूत्र होता है। संख्याएँ संबंधित संख्या के उदाहरणों के उत्तर दिखाती हैं)।

चावल। 3. गणना द्विपद वितरणएक्सेल में एन= 4 और पी = 0,1
द्विपद वितरण के गुण
द्विपद वितरण मापदंडों पर निर्भर करता है एनतथा आर. द्विपद बंटन सममित या असममित हो सकता है। यदि पी = 0.05, द्विपद वितरण सममित है, पैरामीटर मान की परवाह किए बिना एन. हालांकि, अगर पी 0.05, वितरण विषम हो जाता है। पैरामीटर मान जितना करीब होगा आर 0.05 और बड़ा नमूना आकार एन, कमजोर वितरण की विषमता है। इस प्रकार, गलत तरीके से भरे गए फॉर्मों की संख्या का वितरण दाईं ओर स्थानांतरित कर दिया गया है, क्योंकि पी= 0.1 (चित्र 4)।

चावल। 4. द्विपद बंटन का आयत चित्र एन= 4 और पी = 0,1
द्विपद बंटन की गणितीय अपेक्षानमूना आकार के उत्पाद के बराबर है एनसफलता की संभावना पर आर:
(3) एम = ई (एक्स) =एनपी
औसतन, चार आदेशों के नमूने में परीक्षणों की पर्याप्त लंबी श्रृंखला के साथ, p \u003d E (X) \u003d 4 x 0.1 \u003d 0.4 गलत तरीके से भरे गए फॉर्म हो सकते हैं।
द्विपद वितरण मानक विचलन
उदाहरण के लिए, मानक विचलनलेखांकन में गलत तरीके से भरे गए फॉर्मों की संख्या सूचना प्रणालीबराबर:
लेविन एट अल पुस्तक से सामग्री प्रबंधकों के लिए सांख्यिकी का उपयोग किया जाता है। - एम .: विलियम्स, 2004. - पी। 307–313
