Прогнозування методом експонентного згладжування (ES, exponential smoothing). Прогнозування на основі експонентного згладжування
9 5. Метод експоненційного згладжування. Вибір постійного згладжування
При використанні методу найменших квадратівдля визначення прогнозної тенденції (тренду) заздалегідь припускають, що всі ретроспективні дані (спостереження) мають однакову інформативність. Очевидно, логічніше було б зважити на процес дисконтування вихідної інформації, тобто нерівноцінність цих даних для розробки прогнозу. Це досягається в методі експоненційного згладжування шляхом надання останнім спостереження динамічного ряду (тобто значенням, що безпосередньо передували періоду попередження прогнозу) більш значних «ваг» порівняно з початковими спостереженнями. До переваг методу експоненційного згладжування слід також віднести простоту обчислювальних операцій та гнучкість опису різних динаміків процесу. Найбільше застосування метод знайшов реалізації середньострокових прогнозів .
5.1. Сутність методу експоненційного згладжування
Сутність методу полягає в тому, що динамічний рядзгладжується за допомогою виваженої «ковзної середньої», в якій ваги підпорядковуються експоненційному закону. Іншими словами, чим далі від кінця часового ряду відстає точка, для якої обчислюється зважена середня ковзна, тим менше «участі вона бере» у розробці прогнозу.
Нехай вихідний динамічний ряд складається з рівнів (складових ряду) yt, t = 1, 2, ..., n. Для кожних послідовних рівнів цього ряду
(m динамічному ряду з кроком, що дорівнює одиниці. Якщо m – непарне число, а переважно брати непарне число рівнів, оскільки в цьому випадку розрахункове значення рівня опиниться в центрі інтервалу згладжування і їм легко замінити фактичне значення, то для визначення ковзної середньої можна записати таку формулу: t+ ξ t+ ξ ∑ y i ∑ y i i= t− ξ i= t− ξ 2ξ + 1 де y t - значення ковзної середньої для моменту t (t = 1, 2, ..., n); y i - фактичне значення рівня в момент i; i – порядковий номер рівня інтервалу згладжування. Величина ξ визначається із тривалості інтервалу згладжування. Оскільки m =2 ξ +1 при непарному m , то ξ = m 2 − 1 . Розрахунок ковзної середньої при великій кількості рівнів можна спростити, визначаючи послідовні значення ковзної середньої рекурсивно: y t= y t− 1 + yt + ξ − y t − (ξ + 1 ) 2ξ + 1 Але виходячи з того, що останнім спостереженням необхідно надати більшу «вагу», ковзне середнє потребує іншого тлумачення. Воно у тому, що отримана з допомогою усереднення величина замінює не центральний член інтервалу усереднення, яке останній член. Відповідно до цього останній вираз можна переписати у вигляді Mi = Mi + 1 y i− y i− m Тут ковзна середня, що відноситься до кінця інтервалу, позначена новим символом M i . По суті, Mi рівноy t , зсунутому на кроків вправо, тобто Mi = y t + ξ , де i = t + ξ . Враховуючи, що M i − 1 є оцінкою величини y i − m , вираз (5.1) можна переписати у вигляді y i+ 1 M i − 1 , M i , що визначається виразом (5.1). де M i є оцінкою Якщо обчислення (5.2) повторювати у міру надходження нової інформації і переписати в іншому вигляді, то отримаємо згладжену функцію спостережень: Q i = α y i+ (1 − α ) Q i− 1 , або в еквівалентній формі Q t= α y t+ (1 − α ) Q t− 1 Обчислення, що проводяться за виразом (5.3) з кожним новим спостереженням, називають експоненційним згладжуванням. В останньому виразі для відмінності експоненційного згладжування від ковзного середнього введено позначення Q замість M. Величинаα аналогом m 1 називається постійною згладжування. Значенняα лежать у інтервалі [0, 1]. Якщо α уявити у вигляді ряду α + α(1 − α) + α(1 − α) 2 + α(1 − α) 3 + ... + α(1 − α) n , то неважко помітити, що «ваги» зменшуються за експоненційним законом у часі. Наприклад, для α = 0 , 2 отримаємо 0,2 + 0,16 + 0,128 + 0,102 + 0,082 + … Сума ряду прагне одиниці, а члени суми зменшуються з часом. Величина Q t у виразі (5.3) являє собою експоненційну середню першого порядку, тобто середню, отриману безпосередньо при згладжування даних спостереження (первинне згладжування). Іноді розробки статистичних моделей корисно вдатися до розрахунку експоненційних середніх вищих порядків, тобто середніх, одержуваних шляхом багаторазового експоненційного згладжування. Загальний запис у рекурентній формі експоненційної середньої порядку k має вигляд Q t (k) = α Q t (k - 1) + (1 - α) Q t (- k1). Величина k змінюється в межах 1, 2, …, p, p +1, де – порядок прогнозного полінома (лінійного, квадратичного і так далі). На основі цієї формули для експоненційної середньої першого, другого та третього порядків отримані вирази Q t (1) = α y t + (1 - α) Q t (- 1 1); Q t (2) = α Q t (1) + (1 − α) Q t (− 2 1); Q t (3) = α Q t (2) + (1 - α) Q t (-3 1). 5.2. Визначення параметрів прогнозної моделі методом експоненційного згладжування Вочевидь, що з розробки прогнозних значень з урахуванням динамічного низки методом експоненційного згладжування необхідно обчислити коефіцієнти рівняння тренду через експоненційні середні. Оцінки коефіцієнтів визначаються за фундаментальною теоремою Брауна Меєра, яка зв'язує коефіцієнти прогнозуючого полінома з експоненційними середніми відповідних порядків: (−
1
) aˆ p α (1 − α )∞ −α
)
j (p − 1 + j)! ∑ j p= 0 p! (k− 1) !j = 0 де a p p - оцінки коефіцієнтів полінома ступеняр . Коефіцієнти знаходяться рішенням системи (p + 1) рівнянь сp + 1 невідомими. Так, для лінійної моделі aˆ 0 = 2 Q t (1) - Q t (2); aˆ 1 = 1 − α α (Q t (1 )− Q t (2 )) ; для квадратичної моделі aˆ 0 = 3 (Q t (1 )− Q t (2 )) + Q t (3 ); aˆ 1 =1 − α α [ (6 −5 α ) Q t (1 ) −2 (5 −4 α ) Q t (2 ) +(4 −3 α ) Q t (3 )]; aˆ 2 = (1 − α α ) 2 [ Q t (1 )− 2 Q t (2 )+ Q t (3 )] . Прогноз реалізується за обраним багаточленом відповідно для лінійної моделі ˆyt + τ = aˆ0 + aˆ1 τ; для квадратичної моделі ˆyt + τ = aˆ0 + aˆ1 τ + aˆ 2 2 τ 2 , де - крок прогнозування. Необхідно відзначити, що експоненційні середні Q t (k) можна обчислити тільки за відомого (вибраного) параметра, знаючи початкові умови Q 0 (k). Оцінки початкових умов, зокрема, для лінійної моделі Q (1) = a 1 − α Q(2 ) = a− 2 (1 − α ) a для квадратичної моделі Q (1) = a 1 − α + (1 − α )(2 − α ) a 2(1− α ) (1−α)(3−2α) Q 0(2 ) = a 0− 2α 2 Q (3) = a 3(1− α ) (1 − α )(4 − 3 α ) a де коефіцієнти a 0 і 1 обчислюються методом найменших квадратів. Розмір параметра згладжування α приблизно обчислюється за формулою α ≈ m 2 + 1 , де m - Число спостережень (значень) в інтервалі згладжування. Послідовність обчислення прогнозних значень представлена на Розрахунок коефіцієнтів низки методом найменших квадратів Визначення інтервалу згладжування Обчислення постійного згладжування Обчислення початкових умов Обчислення експоненційних середніх Обчислення оцінок a 0 , a 1 і т.д. Розрахунок прогнозних значень ряду Рис. 5.1. Послідовність обчислення прогнозних значень Як приклад розглянемо процедуру отримання прогнозного значення безвідмовної роботи виробу, що виражається напрацюванням на відмову. Вихідні дані зведені у табл. 5.1. Вибираємо лінійну модель прогнозування у вигляді y t = a 0 + a 1 τ Рішення здійснимо з такими значеннями початкових величин: a 0 0 = 64 2; a 1, 0 = 31, 5; α = 0,305. Таблиця 5.1. Початкові дані Номер спостереження, t Довжина кроку, прогнозування, τ Напрацювання на відмову, y (година) При цих значеннях обчислені «згладжені» коефіцієнти величини y 2 дорівнюватимуть = α Q (1) - Q (2) = 97, 9; [ Q (1 )− Q (2 ) 31,
9 , 1− α за початкових умов 1 − α A 0 , 0 − a 1, 0 = −7
,
6
1 − α = −79
,
4
та експоненційних середніх Q (1 )= α y + (1 − α ) Q (1 ) 25,
2;
Q (2 ) = α Q (1 ) + (1 −α) Q(2) = −47,5. "Згладжена" величина y 2 при цьому обчислюється за формулою Q i (1 ) Q i (2 ) a 0 ,i a 1 ,i ˆyt Таким чином (табл. 5.2), лінійна прогнозна модель має вигляд ˆy t + τ = 224, 5+ 32τ. Обчислимо прогнозні значення для періодів попередження в 2 роки (? = 1), 4 роки (? = 2) і так далі напрацювання на відмову виробу (табл. 5.3). Таблиця 5.3. Прогнозні значенняˆy t Рівняння t + 2 t + 4 t + 6 t + 8 t + 20 регресії (τ = 1) (τ = 2) (τ = 3) (τ = 5) τ =
ˆy t = 224, 5+ 32τ Слід зазначити, що сумарну «вагу» останніх m значень тимчасового ряду можна обчислити за формулою c = 1−(m(−1)m). m+ 1 Так, для двох останніх спостережень ряду (m = 2) величина c = 1 - (2 2 - + 1 1) 2 = 0,667. 5.3. Вибір початкових умов та визначення постійного згладжування Як випливає з виразу Q t= α y t+ (1 − α ) Q t− 1 , при проведенні експоненційного згладжування необхідно знати початкове (попереднє) значення функції, що згладжується. У деяких випадках за початкове значення можна взяти перше спостереження, частіше початкові умови визначаються відповідно до виразів (5.4) та (5.5). У цьому величини a 0 , 0 ,a 1 , 0 і a 2 0 визначаються методом найменших квадратів. Якщо ми не дуже довіряємо вибраному початковому значенню, то, взявши велике значення постійного згладжування через к спостережень, ми доведемо «вага» початкового значення до величини (1 − α ) k<<
α
, и оно будет практически забыто. Наоборот, если мы уверены в правильности выбранного начального значения и неизменности модели в течение определенного отрезка времени в будущем,α
может быть выбрано малым (близким к 0). Таким чином, вибір постійного згладжування (або числа спостережень у середній, що рухається) передбачає прийняття компромісного рішення. Зазвичай, як показує практика, величина постійного згладжування лежить у межах від 0,01 до 0,3. Відомо кілька переходів, що дозволяють знайти наближену оцінку α. Перший випливає з умови рівності ковзної та експоненційної середньої α = m 2 + 1 , де m - Число спостережень в інтервалі згладжування. Інші підходи пов'язуються з точністю прогнозу. Так, можливе визначення α виходячи із співвідношення Мейєра: α ≈ S y , де S y - Середньоквадратична помилка моделі; S 1 - Середньоквадратична помилка вихідного ряду. Однак використання останнього співвідношення утруднено тим, що достовірно визначити S y і S 1 вихідної інформації дуже складно. Часто параметр згладжування, а заразом і коефіцієнти a 0 0 і 0 1 підбирають оптимальними залежно від критерію S 2 = α ∑ ∞ (1 − α ) j [ yij − ˆyij ] 2 → min j = 0 шляхом розв'язання алгебраїчної системи рівнянь, яку одержують, прирівнюючи до нуля похідні ∂ S2 ∂ S2 ∂ S2 ∂ a 0, 0 ∂ a 1, 0 ∂ a 2, 0 Так, для лінійної моделі прогнозування вихідний критерій дорівнює S 2 = α ∑ ∞ (1 − α ) j [ yij − a0 , 0 − a1 , 0 τ ] 2 → min. j = 0 Рішення цієї системи за допомогою ЕОМ не становить жодних складнощів. Для обґрунтованого вибору α також можна використовувати процедуру узагальненого згладжування, яка дозволяє отримати наступні співвідношення, що пов'язують дисперсію прогнозу та параметр згладжування для лінійної моделі: S п 2 ≈[ 1 + α β ] 2 [ 1 +4 β +5 β 2 +2 α (1 +3 β ) τ +2 α 2 τ 3 ] S y 2 для квадратичної моделі S п 2≈ [ 2 α + 3 α 3+ 3 α 2τ ] S y 2, де β =
1
−
α
;Sy- СКО апроксимації вихідного динамічного ряду. Освоєння нових та аналіз відомих управлінських технологій, які дозволяють підвищити ефективність управління бізнесом, стає особливо актуальним для російських підприємств у час. Один із найпопулярніших інструментів - система бюджетування, яка базується на формуванні бюджету підприємства з подальшим контролем виконання. Бюджет є збалансовані короткострокові комерційні, виробничі, фінансові та господарські плани розвитку організації. Бюджет підприємства містить цільові показники, що розраховуються на підставі прогнозних даних. Найбільш значущим прогнозом при складанні бюджету будь-якого підприємства є прогноз продажів. У попередніх статтях було проведено аналіз адитивної та мультиплікативної моделі та розраховано прогнозний обсяг продажів на наступні періоди. При аналізі часових рядів використовувався метод ковзної середньої, де всі дані незалежно від періоду їх виникнення є рівноправними. Існує інший спосіб, в якому даним приписуються ваги, пізнішим даним надається більша вага, ніж більш раннім. Метод експоненційного згладжування на відміну від методу ковзних середніх ще й може бути використаний для короткострокових прогнозів майбутньої тенденції на один період вперед і автоматично коригує будь-який прогноз у світлі відмінностей між фактичним та спрогнозованим результатом. Саме тому метод має явну перевагу над раніше розглянутим. Назва методу походить з того факту, що при його застосуванні виходять експоненційно зважені ковзні середні по всьому часовому ряду. При експоненційному згладжуванні враховуються всі попередні спостереження - попереднє враховується з максимальною вагою, попереднє йому - з дещо меншою, раніше спостереження впливає на результат з мінімальною статистичною вагою. Алгоритм розрахунку експоненційно згладжених значень у будь-якій точці ряду i заснований на трьох величинах: фактичне значення Ai у цій точці ряду i, Новий прогноз можна записати формулою: Розрахунок експоненційно згладжених значень
При практичному використанні методу експонентного згладжування виникає дві проблеми: вибір коефіцієнта згладжування (W), який значною мірою впливає на результати та визначення початкової умови (Fi). З одного боку, для згладжування випадкових відхилень величину необхідно зменшувати. З іншого боку, збільшення ваги нових вимірів потрібно збільшувати. Хоча, в принципі, W може набувати будь-яких значень з діапазону 0< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка). Вибір коефіцієнта постійного згладжування є суб'єктивним. Аналітики більшості фірм при обробці рядів використовують свої традиційні значення W. Так, за опублікованими даними в аналітичному відділі Kodak, традиційно використовують значення 0,38 а на фірмі Ford Motors - 0,28 або 0,3. Ручний розрахунок експонентного згладжування вимагає вкрай великого обсягу монотонної роботи. На прикладі розрахуємо прогнозний обсяг на 13 квартал, якщо є дані обсягу продажу за останні 12 кварталів, використовуючи метод простого експонентного згладжування. Припустимо, що у перший квартал прогноз продажів становив 3. І нехай коефіцієнт згладжування W =0,8. Заповнимо в таблиці третій стовпець, підставляючи для кожного наступного кварталу значення попереднього за формулою: Для 2 кварталу F2 = 0,8 * 4 (1-0,8) * 3 = 3,8 Аналогічно, розраховується згладжене значення коефіцієнта 0,5 і 0,33. Прогноз обсягу продажу при W = 0.8 на 13 квартал становив 13.3 тыс.руб. Ці дані можна подати у графічній формі: Екстраполяція
- це метод наукового дослідження, який ґрунтується на поширенні минулих та реальних тенденцій, закономірностей, зв'язків на майбутній розвиток об'єкта прогнозування. До методів екстраполяції відносяться
метод ковзної середньої, метод експоненційного згладжування, метод найменших квадратів. Метод експоненційного згладжування
найефективніший при створенні середньострокових прогнозів. Він прийнятний під час прогнозування лише на період вперед. Його основні переваги простота процедури обчислень та можливість урахування ваг вихідної інформації. Робоча формула методу експоненційного згладжування: При прогнозуванні даним методом виникає дві труднощі: Від величини α залежить
Як швидко знижується вага впливу попередніх спостережень. Чим більше α, тим менше впливає попередні роки. Якщо значення α близьке до одиниці, це призводить до обліку при прогнозі переважно впливу лише останніх спостережень. Якщо значення близько до нуля, то ваги, якими зважуються рівні часового ряду, зменшуються повільно, тобто. при прогнозі враховуються всі (чи майже всі) попередні спостереження. Таким чином, якщо є впевненість, що початкові умови, на підставі яких розробляється прогноз, є достовірними, слід використовувати невелику величину параметра згладжування (α→0). Коли параметр згладжування малий, то функція, що досліджується, поводиться як середня з великої кількості минулих рівнів. Якщо немає достатньої впевненості в початкових умовах прогнозування, слід використовувати велику величину α, що призведе до обліку при прогнозі в основному впливу останніх спостережень. Точного методу вибору оптимальної величини параметра згладжування α немає. В окремих випадках автор даного методу професор Браун пропонував визначати величину, виходячи з довжини інтервалу згладжування. При цьому α обчислюється за такою формулою: де n - Число спостережень, що входять в інтервал згладжування. Завдання вибору Uo
(експоненційно зваженого середнього початкового) вирішується такими способами: Також можна скористатися експертними оцінками. Зазначимо, що з вивченні економічних часових рядів і прогнозуванні економічних процесів метод експоненційного згладжування який завжди «спрацьовує». Це зумовлено тим, що економічні часові лави бувають надто короткими (15-20 спостережень), і у разі, коли темпи зростання та приросту великі, даний метод не «встигає» відобразити всі зміни. Завдання
. Є дані, що характеризують рівень безробіття у регіоні, % Рішення методом експоненційного згладжування
1) Визначаємо значення параметра згладжування за формулою: де n - Число спостережень, що входять в інтервал згладжування. α = 2/(10+1) = 0,2 2) Визначаємо початкове значення Uo двома способами: 3) Розраховуємо експоненційно зважену середню для кожного періоду, використовуючи формулу де t - період, що передує прогнозному; t+1 – прогнозний період; Ut+1 - прогнозований показник; - параметр згладжування; Уt - фактичне значення досліджуваного показника за період, що передує прогнозному; Ut - експоненційно виважена середня для періоду, що передує прогнозному. Наприклад: Uфев = 2,99 * 0,2 + (1-0,2) * 2,99 = 2,99 (II спосіб) 4) За цією ж формулою обчислюємо прогнозне значення 5) Розраховуємо середню відносну помилку за такою формулою: ε = 209,58/10 = 20,96% (І спосіб) У кожному випадку точність прогнозу
є задовільною, оскільки середня відносна помилка потрапляє в межі 20-50%. Розв'язавши це завдання методами ковзної середньої
і найменших квадратів
, зробимо висновки Наскільки Forecast NOW! краще моделі Експонентне згладжування (ES)ви можете побачити на графіці нижче. По осі X – номер товару, по осі Y – відсоткове поліпшення якості прогнозу. Опис моделі, детальне дослідження, результати експериментів читайте нижче. Прогнозування методом експоненційного згладжування є одним із найпростіших способів прогнозування. Прогноз може бути отриманий лише на період вперед. Якщо прогнозування ведеться у межах днів, то тільки на один день вперед, якщо тижнів, то на один тиждень. Для порівняння, прогнозування проводилося на тиждень вперед протягом 8 тижнів. Що таке експоненційне згладжування? Нехай ряд Зпредставляє вихідний ряд продажів для прогнозування З 1)-продажі в перший тиждень, З(2) у другій тощо. Рисунок 1. Продаж по тижнях, ряд З
Аналогічно, ряд Sє експоненційно згладженим рядом продажів. Коефіцієнт знаходиться від нуля до одиниці. Виходить він так, тут t - момент часу (день, тиждень) S(t+1) = S(t) + α *(С(t) - S(t)) Великі значення константи згладжування α прискорюють відгук прогнозу на стрибок процесу, що спостерігається, але можуть призвести до непередбачуваних викидів, тому що згладжування буде майже відсутній. Перший раз після початку спостережень, маючи лише один результат спостережень С (1)
, коли прогнозу S (1)
немає і формулою (1) скористатися ще неможливо, як прогноз S (2)
слід взяти С (1)
. Формула легко може бути переписана в іншому вигляді: S (t+1) = (1 -α )*
S (t) +α *
З (t).
Таким чином, зі збільшенням константи згладжування частка останніх продажів збільшується, а частка згладжених попередніх зменшується. Константа вибирається дослідним шляхом. Зазвичай будується кілька прогнозів щодо різних констант і вибирається найбільш оптимальна константа з погляду обраного критерію. Критерієм може бути точність прогнозування на попередні періоди. У своєму дослідженні ми розглянули моделі експоненційного згладжування, в яких приймає значення (0.2, 0.4, 0.6, 0.8). Для порівняння з алгоритмом прогнозування Forecast NOW! для кожного товару будувалися прогнози при кожному α, вибирався найточніший прогноз. Насправді ж ситуація була б набагато складніша, користувачу не знаючи наперед точності прогнозу потрібно визначитися з коефіцієнтом α, від якого дуже сильно залежить якість прогнозу. Ось таке замкнене коло. Наочно Рисунок 2. α =0.2 , ступінь експоненційного згладжування висока, реальні продажі враховуються слабо Рисунок 3. α =0.4 , ступінь експоненційного згладжування середня, реальні продажі враховуються в середньому Можна бачити як зі збільшенням константи α згладжений ряд все сильніше відповідає реальним продажам, і якщо там є викиди або аномалії, ми отримаємо вкрай неточний прогноз. Рисунок 4. α =0.6 , ступінь експоненційного згладжування низька, реальні продажі враховуються значно Можемо бачити, що при α=0.8 ряд майже точно повторює вихідний, а значить прогноз прагне до правила «буде продано стільки ж, скільки і вчора» Тут зовсім не можна орієнтуватися на помилку наближення до вихідних даних. Можна досягти ідеальної відповідності, але отримати неприйнятний прогноз. Рисунок 5. α =0.8 , ступінь експоненційного згладжування вкрай низька, реальні продажі враховуються сильно Тепер давайте подивимося на прогнози, які виходять із використанням різних значень α. Як можна бачити з малюнка 6 і 7, що більший коефіцієнт згладжування, то точніше повторює реальні продажі із запізненням на один крок, прогноз. Таке запізнення може виявитися критичним, тому не можна просто вибирати максимальне значення α. Інакше вийде ситуація, коли ми говоримо, що буде продано рівно стільки, скільки було продано минулого періоду. Малюнок 6. Прогноз методу експонентного згладжування при α=0.2 Малюнок 7. Прогноз методу експонентного згладжування при α=0.6 Давайте подивимося, що виходить за α = 1.0. Нагадаємо, S - прогнозовані (згладжені) продажі, C - реальні продажі. S (t+1) = (1 -α )*
S (t) +α *
З (t).
S (t+1) =З (t).
Продаж у t+1 день згідно з прогнозом дорівнює продажам у попередній день. Тому до вибору константи треба підходити з розумом. Тепер розглянемо цей метод прогнозування порівняно з Forecast NOW! Порівняння велося на 256 товарах, які мають різні продажі, з сезонністю короткострокової та довгострокової, з «поганими» продажами та дефіцитом, акціями та іншими викидами. Для кожного товару був побудований прогноз моделі експоненційного згладжування, для різних α, вибирався кращий і порівнювався з прогнозом моделі Forecast NOW! У таблиці нижче ви бачите значення помилки прогнозу кожного товару. Помилка тут вважалася як RMSE. Це корінь із середньоквадратичного відхилення прогнозу від реальності. Грубо кажучи, показує, скільки одиниць товару ми відхилилися в прогнозі. Поліпшення показує, на скільки відсотків прогноз Forecast NOW! краще, якщо цифра позитивна і гірше, якщо негативна. На малюнку 8 по осі X відкладено товари, по осі Y зазначено, наскільки прогноз Forecast NOW! краще, ніж прогнозування шляхом експоненційного згладжування. Як можна бачити із цього графіка, точність прогнозування Forecast NOW! майже завжди вдвічі вищий і майже ніколи не гірший. Насправді це означає, що використання Forecast NOW! дозволить вдвічі скоротити запаси чи знизити дефіцит.


к.е.н., директор з науки та розвитку ЗАТ "КІС"
Метод експоненційного згладжування
прогноз у точці ряду Fi
деякий наперед заданий коефіцієнт згладжування W, постійний по всьому ряду.
Для 3 кварталу F3 = 0,8 * 6 (1-0,8) * 3,8 = 5,6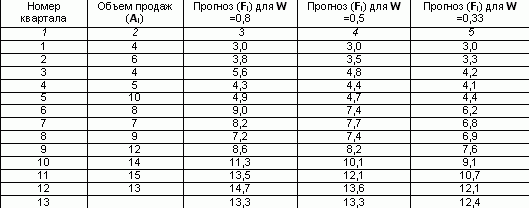
Розрахунок прогнозу обсягу продажу

Експонентне згладжування
Приклад застосування методу експонентного згладжування для розробки прогнозу
І спосіб (середня арифметична) Uo = (2,99 + 2,66 + 2,63 + 2,56 + 2,40 + 2,22 + 1,97 + 1,72 + 1,56 + 1,42)/ 10 = 22,13/10 = 2,21
II метод (приймаємо перше значення основи прогнозу) Uo = 2,99
Uфев = 2,99 * 0,2 + (1-0,2) * 2,21 = 2,37 (І спосіб)
Uмарт = 2,66 * 0,2 + (1-0,2) * 2,37 = 2,43 (І спосіб) і т.д.
Uмарт = 2,66 * 0,2 + (1-0,2) * 2,99 = 2,92 (II спосіб)
Uапр = 2,63 * 0,2 + (1-0,2) * 2,92 = 2,86 (II спосіб) і т.д.
Uноябрь = 1,42 * 0,2 + (1-0,2) * 2,08 = 1,95 (І спосіб)
Uноябрь = 1,42 * 0,2 + (1-0,2) * 2,18 = 2,03 (ІІ спосіб)
Результати заносимо до таблиці.
ε = 255,63/10 = 25,56% (ІІ спосіб)Опис моделі





Приклади прогнозів


Порівняння з Forecast NOW!
