सर्वेक्षण नमूना आकार। नमूनाकरण सूत्र - सरल
प्रत्येक पेशे के अपने पसंदीदा प्रश्नों का सेट होता है। बाजार शोधकर्ताओं के लिए सूची में सबसे ऊपर, निश्चित रूप से नमूना आकार का मुद्दा है। यह आमतौर पर इस तरह तैयार किया जाता है:
- हम मास्को के आगंतुकों पर एक अध्ययन का आदेश देना चाहेंगे खरीदारी केन्द्र. हमें किस नमूने की आवश्यकता है?
- हमारे लक्षित दर्शक लगभग 300,000 लोग हैं। प्रतिनिधि बनने के लिए हमें कितने लोगों का साक्षात्कार लेने की आवश्यकता है? और अगर लक्षित दर्शक 3 मिलियन हैं?
- हमें रूस के उत्तरी शहरों के निवासियों के लिए सेंट पीटर्सबर्ग में अपार्टमेंट की बिक्री की क्षमता का आकलन करने की आवश्यकता है। क्या नमूना बनाना है?
नमूना आकार के बारे में मुख्य गलत धारणा
बहुत से लोग मानते हैं कि लक्ष्य समूह जितना बड़ा होगा, नमूना आकार उतना ही बड़ा होना चाहिए। इसलिए, कथित तौर पर, एक छोटे से शहर के निवासियों की राय जानने के लिए, 200-300 लोगों का साक्षात्कार करना पर्याप्त है, लेकिन पूरे रूस पर राय जानने के लिए, यहां तक कि 5,000 भी पर्याप्त नहीं होंगे।
इस बीच, इस स्टीरियोटाइप का वास्तविकता से कोई लेना-देना नहीं है। नमूना आकार लक्ष्य समूह के आकार पर निर्भर नहीं करता है (सांख्यिकी की भाषा में इसे "सामान्य जनसंख्या" कहा जाता है) और दो पूरी तरह से अलग कारकों द्वारा निर्धारित किया जाता है। इस नियम का एकमात्र अपवाद तब है जब आबादीबहुत छोटा, उदाहरण के लिए, 1-2 हजार लोग, लेकिन विपणन अनुसंधान के वास्तविक अभ्यास में ऐसी स्थितियां दुर्लभ हैं।
नमूना आकार को प्रभावित करने वाले दो कारक
सामूहिक सर्वेक्षण का नमूना आकार दो कारकों पर निर्भर करता है:
- डेटा की सटीकता जो आपको आउटपुट पर प्राप्त करने की आवश्यकता है वही "सांख्यिकीय त्रुटि" है। 100 उत्तरदाताओं के नमूने के लिए, यह प्लस या माइनस 10% के भीतर होगा, और 1,000 उत्तरदाताओं के नमूने के लिए, यह प्लस या माइनस 3.1% के भीतर होगा। इस पर और नीचे।
- उपसमूहों की संख्या और आकार जिसमें विश्लेषण में नमूना विभाजित किया जाना चाहिए। उदाहरण के लिए, यदि एक चुनावी अध्ययन किया जा रहा है, तो हम मुख्य रूप से सक्रिय मतदाताओं के मूल में रुचि लेंगे। एक नियम के रूप में, "कोर" का हिस्सा शायद ही कभी कुल आबादी का 20-25% से अधिक हो। इसलिए, नमूना आकार की गणना इस तरह से की जानी चाहिए कि इसके कुल आकार का एक चौथाई एक पूर्ण सांख्यिकीय विश्लेषण की अनुमति देता है।
दो प्रकार की नमूना त्रुटि
कोई भी नमूना अवलोकन (अर्थात, जब हम सभी का एक पंक्ति में साक्षात्कार नहीं करते हैं, लेकिन सामान्य आबादी से एक यादृच्छिक चयन करते हैं) डेटा त्रुटि से जुड़ा होता है। इस त्रुटि को आमतौर पर "नमूनाकरण त्रुटि" के रूप में जाना जाता है। यह दो प्रकार का हो सकता है:
- व्यवस्थित- नमूना डिजाइन त्रुटियों से जुड़े। इसके आकार, दिशा और विस्थापन की मात्रा का अनुमान लगाना बहुत कठिन, प्रायः असंभव होता है। उदाहरण के लिए, यदि उत्तरदाताओं से सीमांत सामाजिक स्तर के प्रतिनिधियों द्वारा प्रश्न पूछे जाते हैं, तो यह जनसंख्या के अधिक संपन्न समूहों के प्रतिनिधियों की ओर से अध्ययन में भाग लेने की इच्छा को प्रभावित करेगा। नतीजतन, इससे व्यवस्थित त्रुटि और डेटा विरूपण का आकलन करना बेहद मुश्किल हो जाएगा।
- यादृच्छिक रूप से- सांख्यिकी के नियमों के संचालन से संबंधित। इसके आकार की गणना सूत्रों द्वारा आसानी से की जाती है गणितीय सांख्यिकीऔर संभाव्यता सिद्धांत। वे आपको विशेषता के विश्वास अंतराल के बारे में उचित निष्कर्ष निकालने की अनुमति देते हैं। उदाहरण के लिए, यदि सांख्यिकीय त्रुटि प्लस या माइनस 10% है, और संकेतक का परिणामी मूल्य 25% निकला, तो विश्वास अंतराल 15% से 35% तक है।

शोधकर्ता का कार्य इस तरह से डेटा एकत्र करना है कि नमूना पूर्वाग्रह को कम किया जा सके। तब सांख्यिकीय त्रुटि को केवल एक यादृच्छिक त्रुटि तक कम करना संभव होगा, जिसकी गणना सूत्रों का उपयोग करके की जा सकती है।
यादृच्छिक नमूनाकरण त्रुटि के आकार की गणना कैसे करें
रैंडम सैंपलिंग त्रुटि न केवल नमूना आकार पर निर्भर करती है, बल्कि विचरण पर भी निर्भर करती है, अर्थात डेटा समरूपता की डिग्री। डेटा जितना अधिक समरूप होगा (अर्थात, प्राप्त मूल्यों का प्रसार, या फैलाव जितना छोटा होगा), नमूनाकरण त्रुटि उतनी ही कम होगी।
यादृच्छिक नमूनाकरण त्रुटि की गणना के लिए एक सूत्र है, लेकिन सुविधा के लिए, हम ऑनलाइन कैलकुलेटर का उपयोग करने की सलाह देते हैं, उदाहरण के लिए, यह एक। यह आपको आसानी से दो प्रकार की गणना करने की अनुमति देता है:
- नमूना आकार और कल्पित विचरण के आधार पर सांख्यिकीय त्रुटि की मात्रा की गणना करें;
- सटीकता की वांछित डिग्री का अनुमान प्राप्त करने के लिए आवश्यक नमूना आकार निर्धारित करें।

विश्वास के एक पैरामीटर के रूप में (कैलकुलेटर में फ़ील्ड में से एक), आमतौर पर 95% के मान का उपयोग किया जाता है। इसका मतलब यह है कि 95% मामलों में, सामान्य आबादी में एक विशेषता का वितरण परिकलित विश्वास अंतराल (यानी, नमूना में विशेषता का मूल्य प्लस या माइनस सांख्यिकीय त्रुटि का आकार) के भीतर गिर जाएगा। कम सामान्यतः उपयोग किया जाने वाला विश्वसनीयता मान 97% या 99% है - जिसका, क्रमशः, इसका अर्थ है कि ऐसी हिट 97% या 99% मामलों में होगी। इस मामले में, नमूने की विश्वसनीयता बढ़ जाती है, लेकिन नमूना आकार बढ़ जाता है।
नमूना आकार निर्धारित करने का सबसे कठिन हिस्सा आवश्यक सटीकता और डेटा संग्रह की लागत के बीच व्यापार-बंद है। यह प्रक्रिया इस तथ्य से जटिल है कि नमूना आकार को चार के कारक से बढ़ाने से सटीकता में केवल दो के कारक से वृद्धि होती है (इसी के अनुरूप) वर्गमूलनमूने में वृद्धि के आकार पर)।
मामला: क्षेत्रों के खरीदारों को महानगरीय अचल संपत्ति की बिक्री के लिए बाजार की क्षमता का आकलन करने के लिए नमूना आकार का निर्धारण
नवंबर-दिसंबर 2016 में, हमने रूस के विभिन्न शहरों के निवासियों से मॉस्को और सेंट पीटर्सबर्ग में नई इमारतों में अपार्टमेंट की मांग का अध्ययन किया। अध्ययन में तीन डेटा संग्रह विधियां शामिल थीं: 20 से 60 आयु वर्ग की आबादी का एक सामूहिक प्रतिनिधि सर्वेक्षण (सीएटीआई प्रौद्योगिकी का उपयोग करके आयोजित), साथ ही साथ रीयलटर्स के साथ विशेषज्ञ साक्षात्कार की एक श्रृंखला और संभावित अपार्टमेंट खरीदारों के साथ गहन साक्षात्कार।
अध्ययन में 33 शहरों को शामिल किया गया है, जो सेंट पीटर्सबर्ग और मॉस्को अचल संपत्ति की बढ़ती मांग की विशेषता है। सूत्रों के अनुसार गणना किए गए अध्ययन के नियोजित नमूने में 21,500 उत्तरदाताओं की राशि थी। यह आकार विपणन अनुसंधान में प्रयुक्त "मानक" नमूना आकार से बहुत बड़ा है। इतना बड़ा नमूना आकार क्यों?
बात यह है कि ग्राहक को प्रत्येक शहर के लिए अलग-अलग अनुमानों की आवश्यकता होती है, न कि केवल "पूरे देश के लिए"। वास्तव में, हम 1 नमूने के साथ काम नहीं कर रहे हैं, बल्कि प्रत्येक शहर के लिए 33 अलग-अलग नमूनों के साथ काम कर रहे हैं। सेंट पीटर्सबर्ग या मॉस्को में एक अपार्टमेंट खरीदने में दिलचस्पी रखने वाले लोगों का हिस्सा सर्वेक्षण किए गए शहरों के निवासियों की संख्या के 5% के भीतर विशेषज्ञ रूप से निर्धारित किया गया था।
ग्राहक के लिए शहर के महत्व के आधार पर, एजेंसी के परियोजना प्रबंधक ने स्वीकार्य सांख्यिकीय त्रुटि निर्धारित की, जो अंतिम परिणामों के अनुरूप होनी चाहिए। ऐसा करने के लिए, हमने एमएस एक्सेल में एक विशेष मैक्रो का उपयोग किया, लेकिन ये गणना चयन कैलकुलेटर का उपयोग करके भी की जा सकती है। नतीजतन, अध्ययन के प्रत्येक शहर के लिए नमूना आकार 500 से 1000 उत्तरदाताओं से भिन्न था, जिसने कुल 21,500 लोगों को घोषित किया।
- लक्ष्य समूह की संरचना का निर्धारण करें। क्या आप अलग-अलग उपसमूहों का विश्लेषण करने की योजना बना रहे हैं, या पूरे नमूने पर विश्लेषण पर्याप्त होगा?
- डेटा की वांछित सटीकता निर्धारित करें। उदाहरण के लिए, यदि आपको वर्ष के लिए बाजार हिस्सेदारी की गतिशीलता का अनुमान लगाने की आवश्यकता है, तो शेयर के अनुमानित मूल्य को एक विशेष कैलकुलेटर में बदलें और विभिन्न नमूना आकारों के साथ "खेलें"।
- डेटा संग्रह की लागत (नमूना आकार के सीधे आनुपातिक) और आवश्यक सटीकता के बीच संतुलन खोजें।
जनसंख्या
अवलोकन की वस्तुओं की कुल संख्या (लोगों, घरों, उद्यमों, बस्तियोंआदि), जिसमें विशेषताओं का एक निश्चित समूह (लिंग, आयु, आय, संख्या, कारोबार, आदि) है, जो स्थान और समय में सीमित है। आबादी के उदाहरण:
- मास्को के सभी निवासी (2002 की जनगणना के अनुसार 10.6 मिलियन लोग)
- मस्कोवाइट पुरुष (2002 की जनगणना के अनुसार 4.9 मिलियन लोग)
- कानूनी संस्थाएंरूस (2005 की शुरुआत में 2.2 मिलियन)
- खाद्य उत्पाद बेचने वाले खुदरा आउटलेट (2008 की शुरुआत में 20 हजार), आदि।
नमूना (नमूना जनसंख्या)
पूरी आबादी के बारे में निष्कर्ष निकालने के लिए अध्ययन के लिए चुनी गई आबादी से वस्तुओं का एक हिस्सा। नमूने का अध्ययन करके प्राप्त निष्कर्ष को पूरी आबादी तक विस्तारित करने के लिए, नमूने में प्रतिनिधि होने का गुण होना चाहिए।
नमूना प्रतिनिधित्व
सामान्य जनसंख्या को सही ढंग से प्रतिबिंबित करने के लिए नमूने की संपत्ति। एक ही नमूना विभिन्न आबादी का प्रतिनिधि हो भी सकता है और नहीं भी।
उदाहरण:
- एक नमूना जिसमें पूरी तरह से मस्कोवाइट्स शामिल हैं, जिनके पास एक कार है, मास्को की पूरी आबादी का प्रतिनिधित्व नहीं करता है।
- 100 लोगों तक के रूसी उद्यमों का एक नमूना रूस में सभी उद्यमों का प्रतिनिधित्व नहीं करता है।
- बाजार में खरीदारी करने वाले Muscovites का एक नमूना सभी Muscovites के क्रय व्यवहार का प्रतिनिधित्व नहीं करता है।
साथ ही, ये नमूने (अन्य शर्तों के अधीन) पूरी तरह से मस्कोवाइट कार मालिकों, छोटे और मध्यम आकार के रूसी उद्यमों और बाजारों में खरीदारी करने वाले खरीदारों का प्रतिनिधित्व कर सकते हैं।
यह समझना महत्वपूर्ण है कि नमूना प्रतिनिधित्व और नमूना त्रुटि हैं विभिन्न घटनाएं. त्रुटि के विपरीत प्रतिनिधित्व, नमूना आकार पर निर्भर नहीं करता है।
उदाहरण:
हम सर्वेक्षण किए गए मस्कोवाइट्स-कार मालिकों की संख्या में कितना भी वृद्धि करें, हम इस नमूने के साथ सभी मस्कोवाइट्स का प्रतिनिधित्व नहीं कर पाएंगे।
नमूनाकरण त्रुटि (विश्वास अंतराल)
का उपयोग करके प्राप्त परिणामों की अस्वीकृति चयनात्मक अवलोकनवास्तविक जनसंख्या डेटा से।
नमूना त्रुटि दो प्रकार की होती है: सांख्यिकीय और व्यवस्थित। सांख्यिकीय त्रुटि नमूना आकार पर निर्भर करती है। नमूना आकार जितना बड़ा होगा, उतना ही कम होगा।
उदाहरण:
400 इकाइयों के एक साधारण यादृच्छिक नमूने के लिए, अधिकतम सांख्यिकीय त्रुटि (95% आत्मविश्वास के साथ) 5% है, 600 इकाइयों के नमूने के लिए - 4%, 1100 इकाइयों के नमूने के लिए - 3%।
व्यवस्थित त्रुटि निर्भर करती है कई कारकजो अध्ययन पर स्थायी प्रभाव डालते हैं और अध्ययन के परिणामों को एक निश्चित दिशा में स्थानांतरित करते हैं।
उदाहरण:
- किसी भी संभाव्यता नमूने का उपयोग सक्रिय जीवन शैली का नेतृत्व करने वाले उच्च आय वाले लोगों के अनुपात को कम करके आंका जाता है। यह इस तथ्य के कारण होता है कि ऐसे लोगों को किसी विशेष स्थान (उदाहरण के लिए, घर पर) में ढूंढना अधिक कठिन होता है।
- प्रश्नावली के सवालों के जवाब देने से इनकार करने वाले उत्तरदाताओं की समस्या (मास्को में "refuseniks" की हिस्सेदारी, विभिन्न सर्वेक्षणों के लिए, 50% से 80% तक होती है)
कुछ मामलों में, जब सही वितरण ज्ञात होते हैं, तो कोटा शुरू करके या डेटा को फिर से भारित करके पूर्वाग्रह को समतल किया जा सकता है, लेकिन अधिकांश वास्तविक अध्ययनों में, इसका अनुमान लगाना भी काफी समस्याग्रस्त हो सकता है।
नमूना प्रकार
नमूने दो प्रकारों में विभाजित हैं:
- संभाव्य
- असंभाव्यता
1. संभाव्यता नमूने
1.1 यादृच्छिक नमूनाकरण (सरल यादृच्छिक चयन)
ऐसा नमूना सामान्य जनसंख्या की एकरूपता, सभी तत्वों की उपलब्धता की समान संभावना, उपस्थिति को मानता है पूरी लिस्टसभी तत्व। तत्वों का चयन करते समय, एक नियम के रूप में, एक तालिका का उपयोग किया जाता है यादृच्छिक संख्या.
1.2 यांत्रिक (व्यवस्थित) नमूनाकरण
एक प्रकार का यादृच्छिक नमूना, जिसे किसी मानदंड के अनुसार क्रमबद्ध किया जाता है ( वर्णमाला क्रम, फोन नंबर, जन्म तिथि, आदि)। पहले तत्व को यादृच्छिक रूप से चुना जाता है, फिर प्रत्येक 'k'th तत्व को 'n' की वृद्धि में चुना जाता है। सामान्य जनसंख्या का आकार, जबकि - N=n*k
1.3 स्तरीकृत (क्षेत्रीय)
इसका उपयोग सामान्य जनसंख्या की विषमता के मामले में किया जाता है। सामान्य जनसंख्या समूहों (स्तर) में विभाजित है। प्रत्येक स्तर में, चयन बेतरतीब ढंग से या यंत्रवत् किया जाता है।
1.4 सीरियल (नेस्टेड या क्लस्टर्ड) सैंपलिंग
सीरियल सैंपलिंग के साथ, चयन की इकाइयाँ स्वयं वस्तु नहीं होती हैं, बल्कि समूह (समूह या घोंसले) होते हैं। समूहों को यादृच्छिक रूप से चुना जाता है। समूहों के भीतर की वस्तुओं का हर जगह सर्वेक्षण किया जाता है।
2. अतुल्य नमूने
इस तरह के नमूने में चयन संयोग के सिद्धांतों के अनुसार नहीं, बल्कि व्यक्तिपरक मानदंडों के अनुसार किया जाता है - पहुंच, विशिष्टता, समान प्रतिनिधित्व, आदि।
2.1. कोटा नमूना
प्रारंभ में, वस्तुओं के समूहों की एक निश्चित संख्या आवंटित की जाती है (उदाहरण के लिए, 20-30 वर्ष, 31-45 वर्ष और 46-60 वर्ष की आयु के पुरुष; 30 से 60 की आय वाले 30 हजार रूबल तक की आय वाले व्यक्ति) हजार रूबल और 60 हजार रूबल से अधिक की आय के साथ) प्रत्येक समूह के लिए सर्वेक्षण की जाने वाली वस्तुओं की संख्या निर्दिष्ट है। प्रत्येक समूह में आने वाली वस्तुओं की संख्या निर्धारित की जाती है, सबसे अधिक बार, या तो सामान्य आबादी में समूह के पहले ज्ञात हिस्से के अनुपात में, या प्रत्येक समूह के लिए समान। समूहों के भीतर, वस्तुओं को यादृच्छिक रूप से चुना जाता है। विपणन अनुसंधान में अक्सर कोटा नमूनों का उपयोग किया जाता है।
2.2. स्नोबॉल विधि
नमूना निम्नानुसार बनाया गया है। प्रत्येक उत्तरदाता, पहले से शुरू करते हुए, अपने दोस्तों, सहकर्मियों, परिचितों से संपर्क करने के लिए कहा जाता है जो चयन की शर्तों में फिट होंगे और अध्ययन में भाग ले सकते हैं। इस प्रकार, पहले चरण के अपवाद के साथ, नमूना स्वयं अध्ययन की वस्तुओं की भागीदारी के साथ बनता है। विधि का उपयोग अक्सर तब किया जाता है जब उत्तरदाताओं के कठिन-से-पहुंच समूहों को ढूंढना और उनका साक्षात्कार करना आवश्यक होता है (उदाहरण के लिए, उच्च आय वाले उत्तरदाता, एक ही पेशेवर समूह से संबंधित उत्तरदाता, उत्तरदाता जिनके कुछ समान शौक / जुनून हैं, आदि। )
2.3 स्वतःस्फूर्त नमूनाकरण
सर्वाधिक सुलभ उत्तरदाताओं का सर्वेक्षण किया जाता है। स्वतःस्फूर्त प्रतिचयन के विशिष्ट उदाहरण हैं समाचार पत्रों/पत्रिकाओं में सर्वेक्षण, उत्तरदाताओं को स्वतः पूर्णता के लिए दिए गए प्रश्नावली, अधिकांश इंटरनेट सर्वेक्षण। सहज नमूनों का आकार और संरचना पहले से ज्ञात नहीं है, और केवल एक पैरामीटर - उत्तरदाताओं की गतिविधि द्वारा निर्धारित किया जाता है।
2.4 विशिष्ट मामलों का नमूना
सामान्य जनसंख्या की इकाइयाँ चुनी जाती हैं जिनमें विशेषता का औसत (विशिष्ट) मान होता है। यह एक विशेषता को चुनने और उसके विशिष्ट मूल्य को निर्धारित करने की समस्या को उठाता है।
त्रुटि और नमूना आकार कैलकुलेटर (यादृच्छिक नमूना)
| मापदण्ड नाम | अर्थ |
| लेख विषय: | विषय 5: नमूना गणना |
| रूब्रिक (विषयगत श्रेणी) | विपणन |
अक्सर, अध्ययनाधीन जनसंख्या का आकार बड़ा होता है, या पूरी आबादी से जानकारी प्राप्त करने के लिए बहुत अधिक समय और धन खर्च करना अत्यंत महत्वपूर्ण होता है। इन मामलों में, एक नमूना बनाया जाता है और जांच की जाती है। लेकिन यह याद रखना चाहिए कि प्राप्त आंकड़ों में हमेशा एक त्रुटि होती है, अवलोकन के परिणामों को केवल एक निश्चित डिग्री के साथ ही आंका जा सकता है।
जनसंख्या- सभी इकाइयों का समुच्चय जो अनुसंधान की वस्तु है, जिससे चयन किया जाता है।
नमूना जनसंख्यासर्वेक्षण के लिए चयनित इकाइयों का समूह है।
नमूनाकरण के तरीके:
1. सरल यादृच्छिक नमूनाकरण - जनसंख्या के प्रत्येक तत्व के नमूने में शामिल होने की समान संभावना है। एक यादृच्छिक संख्या जनरेटर का उपयोग करके उत्पादित;
2. व्यवस्थित - नमूना सेट का पहला तत्व यादृच्छिक रूप से चुना जाता है, और फिर प्रत्येक i-th तत्व नमूना सेट में शामिल होता है;
3. स्तरीकृत (संरचित) - सामान्य जनसंख्या को कई स्तरों (समूहों) में विभाजित किया जाता है, और फिर प्रत्येक समूह में सरल यादृच्छिक या व्यवस्थित नमूनाकरण की विधि द्वारा चयन किया जाता है;
4. क्लस्टर नमूनाकरण - सामान्य जनसंख्या को समूहों में विभाजित किया जाता है, फिर यादृच्छिक चयन द्वारा कई समूहों का चयन किया जाता है और चयनित समूहों की सभी वस्तुओं का अध्ययन किया जाता है।
चयन के तरीके:
1. रीसेंपलिंग- एक या दूसरी इकाई जो पंजीकरण के बाद नमूने में गिर गई, उसे फिर से सामान्य आबादी को वापस कर दिया जाता है, और यह अन्य सभी इकाइयों के साथ फिर से चयन होने पर फिर से नमूने में आने का समान अवसर रखता है। नमूनाकरण प्रक्रिया में जनसंख्या इकाइयों की कुल संख्या अपरिवर्तित रहती है।
2. गैर-दोहराव नमूनाकरण - एक जनसंख्या इकाई जो नमूने में शामिल है, सामान्य आबादी को वापस नहीं की जाती है और आगे के चयन में भाग नहीं लेती है। नमूनाकरण प्रक्रिया के दौरान जनसंख्या इकाइयों की कुल संख्या घट जाती है।
नमूना आकार दृष्टिकोण:
1. मनमाना - यह बिना प्रमाण के स्वीकार किया जाता है कि नमूना सामान्य जनसंख्या का 5-10% होना चाहिए। इस दृष्टिकोण का उपयोग करना आसान है, लेकिन प्राप्त परिणामों की सटीकता को स्थापित करना संभव नहीं है। पर्याप्त रूप से बड़ी आबादी के साथ, यह काफी महंगा होना चाहिए।
2. पिछले अनुभव के आधार पर - पिछले अध्ययनों से मात्रा की स्थापना की जानी चाहिए। दृष्टिकोण का एक निश्चित तर्क है, बशर्ते कि पिछले नमूने को सही ढंग से परिभाषित किया गया हो।
3. संचालन की लागत पर अभिविन्यास - विपणन अनुसंधान बजट सर्वेक्षण करने की लागत प्रदान करता है, जिसे पार नहीं किया जा सकता है। प्राप्त जानकारी की विश्वसनीयता की गारंटी नहीं है, और ओवरसैंपलिंग हो सकती है।
4. सांख्यिकीय पद्धतियां- किसी भी नमूने में अनुसंधान त्रुटियाँ होती हैं। नमूना आकार की गणना करने के लिए, दो मान दिए गए हैं:
- विश्वास अंतराल (अनुमेय नमूना त्रुटि (∆) - एक निश्चित राशि जिसके द्वारा सामान्य परिणाम नमूना परिणामों से भिन्न हो सकते हैं। यह सच्चे मूल्यों से देखे गए मूल्यों का अनुमेय विचलन है। इस धारणा का आकार द्वारा निर्धारित किया जाता है सूचना सटीकता के लिए आवश्यकताओं को ध्यान में रखते हुए शोधकर्ता।
- कॉन्फिडेंस प्रायिकता - का अर्थ है कॉन्फिडेंस की डिग्री कि प्रेक्षित तत्व का मान कॉन्फिडेंस इंटरवल की निर्दिष्ट सीमा के भीतर आ जाएगा। सबसे अधिक इस्तेमाल किया जाने वाला 95% आत्मविश्वास का स्तर है।
अनुसंधान में सबसे आम संभावनाएं हैं:
नमूना विचरण (नमूना आबादी में एक विशेषता का विचरण):
![]()
एन सामान्य जनसंख्या में इकाइयों की संख्या है।
इस मामले में, इसे पिछले सर्वेक्षण के अनुसार लिया जाता है, या इसकी गणना की जाती है:
अगर सबसे बड़ा और सबसे छोटा मानसामान्य आबादी में विशेषता:
![]() ;
;
http://www.quans.ru/research/control/select-calc/
नमूना जनसंख्या प्रतिनिधि होना चाहिए, अर्थात नमूने में सामान्य जनसंख्या की आवश्यक विशेषताओं का आनुपातिक प्रतिनिधित्व प्रदान करना चाहिए।
प्रतिनिधित्व को निम्न उदाहरण द्वारा स्पष्ट किया जा सकता है। मान लीजिए जनसंख्या स्कूल के सभी छात्र हैं (20 कक्षाओं के 600 लोग, प्रत्येक कक्षा में 30 लोग)। अध्ययन का विषय धूम्रपान के प्रति दृष्टिकोण है। हाई स्कूल के 60 छात्रों का एक नमूना उन्हीं 60 लोगों के नमूने की तुलना में बहुत खराब जनसंख्या का प्रतिनिधित्व करता है, जिसमें प्रत्येक कक्षा के 3 छात्र शामिल होंगे। मुख्य कारणयह कक्षाओं में एक असमान आयु वितरण है। इसलिए, पहले मामले में, नमूने का प्रतिनिधित्व कम है, और दूसरे मामले में, प्रतिनिधित्व अधिक है (सेटेरिस परिबस)।
अवलोकन की विधि का उपयोग करते समय, किसी को ड्रैकुला और फ्रेंकस्टीन के सिंड्रोम को दूर करने का प्रयास करना चाहिए। पहली गैर-प्रतिनिधि टिप्पणियों से सभी बोधगम्य और अकल्पनीय जानकारी को "चूसने" की इच्छा है। दूसरा बिना सोचे-समझे मात्रात्मक विशेषताओं का उपयोग करने के प्रयास में है। सफलता का मार्ग मात्रात्मक और गुणात्मक दोनों तरीकों का विवेकपूर्ण उपयोग है; छोटे समूहों में बड़े पैमाने पर सर्वेक्षण और अवलोकन दोनों आयोजित करना।
सर्वेक्षण पद्धति का उपयोग करके प्रभावी भविष्यवाणियां करने में मुख्य बाधा प्रसिद्ध ला पियरे विरोधाभास है, जो कहता है कि लोग हमेशा वह नहीं करते जो वे कहते हैं।
विषय 5: नमूना गणना - अवधारणा और प्रकार। "विषय 5: नमूना गणना" 2017, 2018 श्रेणी का वर्गीकरण और विशेषताएं।
घटना की संभावना का अंतराल अनुमान। यादृच्छिक चयन विधि के मामले में नमूनों की संख्या की गणना के लिए सूत्र।हमारे लिए रुचि की घटनाओं की संभावनाओं को निर्धारित करने के लिए, हम नमूनाकरण विधि का उपयोग करते हैं: हम करते हैं एनस्वतंत्र प्रयोग, जिनमें से प्रत्येक घटना में ए हो सकता है (या नहीं हो सकता) (प्रायिकता आरप्रत्येक प्रयोग में घटना ए की घटना स्थिर है)। फिर घटनाओं की घटनाओं की सापेक्ष आवृत्ति p* लेकिनकी एक श्रृंखला में एनपरीक्षण के रूप में स्वीकार किए जाते हैं बिंदु लागतसंभावना के लिए पीकिसी घटना का घटित होना लेकिनएक अलग परीक्षण में। इस स्थिति में, मान p* कहलाता है नमूना शेयर घटना घटना लेकिन, और आर - सामान्य हिस्सा .
केंद्रीय सीमा प्रमेय (मोइवर-लाप्लास प्रमेय) के परिणाम के आधार पर, एक बड़े नमूना आकार के साथ एक घटना की सापेक्ष आवृत्ति को सामान्य रूप से मापदंडों के साथ वितरित माना जा सकता है M(p*)=p तथा
इसलिए, n>30 के लिए, सूत्रों का उपयोग करके सामान्य अंश के लिए विश्वास अंतराल बनाया जा सकता है:

जहां u kr दिए गए को ध्यान में रखते हुए, लैपलेस फ़ंक्शन की तालिकाओं से पाया जाता है आत्मविश्वास का स्तर: 2Ф(यू करोड़)=γ.
एक छोटे से नमूना आकार n≤30 के साथ, छात्र वितरण तालिका से सीमांत त्रुटि निर्धारित की जाती है: ![]() जहाँ t cr =t(k; α) और स्वतंत्रता की डिग्री की संख्या k=n-1 प्रायिकता α=1-γ (दो तरफा क्षेत्र)।
जहाँ t cr =t(k; α) और स्वतंत्रता की डिग्री की संख्या k=n-1 प्रायिकता α=1-γ (दो तरफा क्षेत्र)।
सूत्र मान्य हैं यदि चयन को बार-बार यादृच्छिक रूप से किया गया था (सामान्य जनसंख्या अनंत है), अन्यथा गैर-दोहराए जाने वाले चयन (तालिका) के लिए सुधार करना आवश्यक है।
सामान्य अनुपात के लिए औसत नमूनाकरण त्रुटि
| जनसंख्या | अनंत | अंतिम मात्रा एन |
| चयन प्रकार | दोहराया गया | न दोहराई |
| औसत नमूना त्रुटि |
एक उचित यादृच्छिक चयन पद्धति के साथ नमूना आकार की गणना के लिए सूत्र
| चयन विधि | नमूना आकार सूत्र | ||
| बीच के लिए | शेयर के लिए | ||
| दोहराया गया | |||
| न दोहराई | |||
सामान्य हिस्सेदारी के बारे में समस्याएं
प्रश्न के लिए "क्या p 0 का दिया गया मान विश्वास अंतराल को कवर करता है?" - चेक करके उत्तर दिया जा सकता है सांख्यिकीय परिकल्पनाएच 0: पी = पी 0। यह माना जाता है कि प्रयोग बर्नौली परीक्षण योजना (स्वतंत्र, संभाव्यता) के अनुसार किए जाते हैं पीकिसी घटना का घटित होना लेकिनलगातार)। मात्रा के नमूने द्वारा एनघटना ए की घटना की सापेक्ष आवृत्ति पी * निर्धारित करें: जहां एम- घटना की घटनाओं की संख्या लेकिनकी एक श्रृंखला में एनपरीक्षण। परिकल्पना एच 0 का परीक्षण करने के लिए, आंकड़ों का उपयोग किया जाता है, जो पर्याप्त रूप से बड़े नमूना आकार के साथ मानक होते हैं सामान्य वितरण(तालिका एक)।तालिका 1 - सामान्य हिस्से के बारे में परिकल्पना
परिकल्पना | एच0:पी=पी0 | एच 0:पी 1 \u003d पी 2 |
| मान्यताओं | बर्नौली परीक्षण योजना | बर्नौली परीक्षण योजना |
| नमूना अनुमान |  |
|
| आंकड़े क |  |  |
| सांख्यिकी वितरण क | मानक सामान्य एन(0,1) |
उदाहरण 1। रैंडम री-सैंपलिंग का उपयोग करते हुए, कंपनी के प्रबंधन ने अपने 900 कर्मचारियों का एक यादृच्छिक सर्वेक्षण किया। उत्तरदाताओं में 270 महिलाएं थीं। एक विश्वास अंतराल प्लॉट करें, जो 0.95 की संभावना के साथ फर्म की पूरी टीम में महिलाओं के सही अनुपात को कवर करता है।
समाधान। शर्त के अनुसार, महिलाओं का नमूना अनुपात (सभी उत्तरदाताओं के बीच महिलाओं की सापेक्ष आवृत्ति) है। चूंकि चयन दोहराया जाता है और नमूना आकार बड़ा होता है (एन = 900), सीमांत नमूना त्रुटि सूत्र द्वारा निर्धारित की जाती है ![]()
u cr का मान लैपलेस फलन की तालिका से संबंध 2Ф(u cr)=γ से ज्ञात किया जाता है, अर्थात्। ![]() लैपलेस फ़ंक्शन (परिशिष्ट 1) u cr = 1.96 पर 0.475 मान लेता है। इसलिए, सीमांत त्रुटि
लैपलेस फ़ंक्शन (परिशिष्ट 1) u cr = 1.96 पर 0.475 मान लेता है। इसलिए, सीमांत त्रुटि ![]() और वांछित विश्वास अंतराल
और वांछित विश्वास अंतराल
(पी - , पी + ε) = (0.3 - 0.18; 0.3 + 0.18) = (0.12; 0.48)
तो, 0.95 की संभावना के साथ, यह गारंटी दी जा सकती है कि फर्म की पूरी टीम में महिलाओं का अनुपात 0.12 से 0.48 के बीच है।
उदाहरण # 2। कार पार्क का मालिक उस दिन को "भाग्यशाली" मानता है जब कार पार्क 80% से अधिक भरा हो। वर्ष के दौरान, 40 कार पार्क निरीक्षण किए गए, जिनमें से 24 "सफल" रहे। 0.98 की प्रायिकता के साथ, वर्ष के दौरान "भाग्यशाली" दिनों के सही प्रतिशत का अनुमान लगाने के लिए विश्वास अंतराल ज्ञात कीजिए।
समाधान. "अच्छे" दिनों का नमूना अंश है
लैपलेस फलन की तालिका के अनुसार, हम दिए गए के लिए u cr का मान ज्ञात करते हैं
आत्मविश्वास का स्तर
(2.23) = 0.49, यू करोड़ = 2.33।
चयन को गैर-दोहराव मानते हुए (यानी, एक ही दिन में दो जांच नहीं की गई थी), हम पाते हैं सीमांत त्रुटि: ![]()
जहाँ n=40 , N = 365 (दिन)। यहाँ से ![]()
और सामान्य भिन्न के लिए विश्वास अंतराल: (p - , p + ε) = (0.6 - 0.17; 0.6 + 0.17) = (0.43; 0.77)
0.98 की संभावना के साथ, यह उम्मीद की जा सकती है कि वर्ष के दौरान "अच्छे" दिनों का अनुपात 0.43 से 0.77 के बीच हो।
उदाहरण #3। बैच में 2500 वस्तुओं की जाँच के बाद, उन्होंने पाया कि 400 वस्तुएँ उच्चतम श्रेणी की थीं, लेकिन n-m नहीं थीं। 95% निश्चितता के साथ 0.01 की सटीकता के साथ प्रीमियम ग्रेड के हिस्से को निर्धारित करने के लिए आपको कितने उत्पादों की जांच करने की आवश्यकता है?
हम फिर से चयन के लिए नमूने के आकार को निर्धारित करने के लिए सूत्र के अनुसार समाधान की तलाश कर रहे हैं।
Ф(t) = γ/2 = 0.95/2 = 0.475 और लाप्लास तालिका के अनुसार यह मान t=1.96 से मेल खाता है
नमूना अंश w = 0.16; नमूना त्रुटि ε = 0.01
उदाहरण # 4। उत्पादों का एक बैच स्वीकार किया जाता है यदि उत्पाद के मानक को पूरा करने की संभावना कम से कम 0.97 है। परीक्षण किए गए लॉट के बेतरतीब ढंग से चुने गए 200 उत्पादों में से 193 उत्पाद मानक के अनुरूप पाए गए। क्या बैच को महत्व स्तर α=0.02 पर स्वीकार करना संभव है?
समाधान. हम मुख्य और वैकल्पिक परिकल्पना तैयार करते हैं।
एच 0: पी \u003d पी 0 \u003d 0.97 - अज्ञात सामान्य शेयर पीनिर्दिष्ट मान के बराबर पी 0 = 0.97। स्थिति के संबंध में - संभावना है कि परीक्षण किए गए लॉट से हिस्सा मानक के अनुसार होगा 0.97 है; वे। उत्पादों के बैच को स्वीकार किया जा सकता है।
एच1:पी<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
मनाया गया आँकड़ा मूल्य क(तालिका) दिए गए मानों के लिए गणना करें पी 0 = 0.97, एन = 200, एम = 193
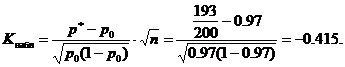
महत्वपूर्ण मान समानता से लाप्लास फ़ंक्शन की तालिका से पाया जाता है
![]()
शर्त के अनुसार α=0.02, इसलिए F(Kcr)=0.48 और Kcr=2.05। महत्वपूर्ण क्षेत्र बाएं हाथ का है, अर्थात। अंतराल है (-∞;-K kp)= (-∞;-2.05)। देखा गया मान कोब्स = -0.415 महत्वपूर्ण क्षेत्र से संबंधित नहीं है, इसलिए, इस स्तर के महत्व पर, मुख्य परिकल्पना को अस्वीकार करने का कोई कारण नहीं है। उत्पादों का एक बैच स्वीकार किया जा सकता है।
उदाहरण संख्या 5. दो कारखाने एक ही प्रकार के पुर्जों का उत्पादन करते हैं। उनकी गुणवत्ता का आकलन करने के लिए इन कारखानों के उत्पादों से नमूने लिए गए और निम्नलिखित परिणाम प्राप्त हुए। पहली फैक्ट्री के 200 चयनित उत्पादों में से 20 खराब थे और दूसरी फैक्ट्री के 300 उत्पादों में से 15 खराब थे।
0.025 के महत्व स्तर पर, पता करें कि क्या इन कारखानों द्वारा निर्मित पुर्जों की गुणवत्ता में कोई महत्वपूर्ण अंतर है।
शर्त के अनुसार α=0.025, इसलिए F(Kcr)=0.4875 और Kcr=2.24। दो तरफा विकल्प के साथ, स्वीकार्य मूल्यों के क्षेत्र का रूप है (-2.24; 2.24)। प्रेक्षित मान कोब्स =2.15 इस अंतराल के भीतर आता है, अर्थात। महत्व के इस स्तर पर, मुख्य परिकल्पना को अस्वीकार करने का कोई कारण नहीं है। कारखाने समान गुणवत्ता के उत्पाद तैयार करते हैं।
मॉड्यूल 1.4. इष्टतम नमूना आकार की गणना
मॉड्यूल 1.4. इष्टतम नमूना आकार की गणना
मॉड्यूल का अध्ययन करने का उद्देश्य:सार्वजनिक स्वास्थ्य अध्ययनों में इष्टतम नमूना आकार की गणना करने का तरीका दिखाएं,
स्वास्थ्य देखभाल प्रणाली (संस्थानों) की गतिविधियों और नैदानिक अभ्यास में।
विषय का अध्ययन करने के बाद, छात्र को चाहिए जानना:
नमूनाकरण विधि का उपयोग करने के लाभ;
नमूना जनसंख्या बनाने के तरीके;
इष्टतम नमूना आकार की गणना के लिए तरीके। छात्र चाहिए करने में सक्षम हो:
चिकित्सा और सामाजिक अनुसंधान के उद्देश्यों के अनुसार एक नमूना आबादी बनाने की एक विधि चुनें;
1.4.1. सूचना खंड
सांख्यिकीय अवलोकन को निरंतर और गैर-निरंतर के रूप में व्यवस्थित किया जा सकता है। निरंतर अवलोकन में अध्ययन की गई आबादी की सभी इकाइयों की जांच शामिल है, गैर-निरंतर - इसका केवल एक हिस्सा। चयनात्मक अवलोकन गैर-निरंतर अवलोकन को संदर्भित करता है। नमूना अवलोकन का उद्देश्य नमूना जनसंख्या की विशेषताओं द्वारा सामान्य जनसंख्या की विशेषताओं का न्याय करना है।
चिकित्सा और सामाजिक अनुसंधान करते समय, नमूना बनाने के निम्नलिखित तरीकों का उपयोग किया जाता है:
यांत्रिक चयन;
टाइपोलॉजिकल (स्तरीकृत) चयन;
धारावाहिक चयन;
मल्टीस्टेज (स्क्रीनिंग) चयन;
कोहोर्ट विधि;
कॉपी-जोड़ी चयन विधि।
नमूना जनसंख्या (नमूना) के गठन से अवलोकन की इकाइयों का एक ऐसा सेट प्राप्त करना संभव हो जाता है, जो शोधकर्ता की रुचि की विशेषताओं के अनुसार, सामान्य जनसंख्या का एक विचार देता है। इसके लिए नमूना होना चाहिए प्रतिनिधि(प्रतिनिधि)।
नमूना प्रतिनिधित्व- सामान्य जनसंख्या के समान संकेतक के साथ चयनात्मक अवलोकन के परिणामस्वरूप प्राप्त विशेषताओं का अनुपालन।
चयनात्मक अध्ययन करते समय, निरंतर अवलोकन के साथ, बिल्कुल सटीक डेटा प्राप्त करना असंभव है।
यह इस तथ्य के कारण है कि पूरी आबादी अवलोकन के अधीन नहीं है, बल्कि इसका केवल एक हिस्सा है। इसलिए, चयनात्मक अध्ययन करते समय, कुछ त्रुटि (त्रुटियाँ) अपरिहार्य हैं। नमूनाकरण अनुसंधान में निहित त्रुटियों को नमूनाकरण त्रुटियाँ कहा जाता है।
नमूनाकरण त्रुटि -नमूने और सामान्य जनसंख्या की विशेषताओं के बीच विसंगति। एक नियम के रूप में, यह एक नमूना आबादी के गठन के दौरान अवलोकन इकाइयों के चयन के लिए कार्यप्रणाली के सिद्धांतों के उल्लंघन के परिणामस्वरूप उत्पन्न होता है और पूरे (सामान्य आबादी) और उसके हिस्से (नमूना) के बीच एक उद्देश्य अंतर के कारण होता है।
सबसे बड़ी संभावित नमूना त्रुटि को कहा जाता है सीमांत नमूना त्रुटि,जिसकी गणना सूत्र द्वारा की जाती है:
कहाँ पे एस 2 - विचरण का अनुमान σ 2 नमूना x 1 x 2 , x n से परिकलित किया गया है।
माध्य नमूना त्रुटि(μ) नमूने के माध्य और सामान्य जनसंख्या के बीच का अंतर है, जो मापांक में से अधिक नहीं है।
फिर कॉन्फिडेंस फैक्टर टीइसकी बहुलता को दर्शाता है। मामले में जब सामान्य जनसंख्या की एक सीमित मात्रा होती है एन,माध्य नमूना त्रुटि μ . में एक सुधार कारक पेश किया जाता है

सीमांत नमूना त्रुटि की गणना के लिए सूत्रों का उपयोग नमूने के आकार को निर्धारित करने के लिए किया जाता है जो अनुमान की निर्दिष्ट सटीकता प्रदान करता है। सीमांत त्रुटि के सूत्र से:

इस प्रकार है:

परिमित आकार की जनसंख्या के मामले में एनइसी तरह पाया जा सकता है:

फलस्वरूप,

आत्मविश्वास कारक टीदी गई विश्वसनीयता के साथ सामान्य वितरण की मात्राओं की तालिका से पाया जाता है। मानक विश्वसनीयता मूल्यों के साथ γ = 0.95 और γ = 0.99, संबंधित आत्मविश्वास कारक टीटी के बराबर 0.95 = 1.96; टी 0.99 = 2.58। यहाँ दो और सामान्य रूप से उपयोग किए जाने वाले मान हैं: t 0.9544 = 2; t 0.9973 = 3. यदि के बजाय सूत्र में शामिल है एस,परिणाम यह निकला टीन केवल पर निर्भर करता है, बल्कि . पर भी निर्भर करता है एन।इस मामले में, गुणांक टीछात्र वितरण की मात्राओं की तालिका से पाए जाते हैं। पर्याप्त रूप से बड़े . के लिए एनउसका अनुसरण करता है एस≈ σ और संबंधित गुणांक टीसमान विश्वसनीयता के साथ अप्रभेद्य हैं।
संभावना का आकलन करते समय आरसापेक्ष आवृत्ति सूत्र से:

इस प्रकार है:

इसी प्रकार परिमित आयतन की सामान्य जनसंख्या के लिए एनहम पाते हैं:

फलस्वरूप,

इस प्रकार, वांछित सटीकता निर्धारित करके, अर्थात। सीमांत त्रुटि निर्दिष्ट करते हुए, उपरोक्त सूत्रों का उपयोग करके यह सटीकता सुनिश्चित करने के लिए पर्याप्त नमूना आकार n पाया जा सकता है। पर एन,पाया मूल्य से अधिक, सटीकता बढ़ जाती है, क्योंकि सीमांत त्रुटि घट जाती है (सूत्र संबंधित देखें एनऔर )।
1.4.2. स्वतंत्र कार्य के लिए कार्य
1. पाठ्यपुस्तक, मॉड्यूल, अनुशंसित साहित्य के संबंधित अध्याय की सामग्री का अध्ययन करें।
2. सुरक्षा प्रश्नों के उत्तर दें।
3. कार्य-मानक को पार्स करें।
4. मॉड्यूल के परीक्षण कार्य के प्रश्नों के उत्तर दें।
5. समस्याओं का समाधान करें।
1.4.3. परीक्षण प्रश्न
1. चयनात्मक अनुसंधान पद्धति का क्या लाभ है?
2. नमूने की प्रतिनिधित्वशीलता को परिभाषित करें।
3. नमूना त्रुटि को परिभाषित करें।
4. प्रतिदर्श समष्टि बनाने की विधियों के नाम लिखिए।
5. सीमांत प्रतिचयन त्रुटि को परिभाषित कीजिए। गणना सूत्र दें।
6. माध्य प्रतिचयन त्रुटि को परिभाषित कीजिए। गणना सूत्र दें।
1.4.4. संदर्भ कार्य
प्रारंभिक आंकड़े
1. अस्पताल में मरीजों के रहने की औसत अवधि का अध्ययन करते समय, निम्नलिखित आंकड़े प्राप्त हुए: एम = 20 दिन, = 1.63 दिन, μ = 0.16 दिन।
2. ऑन्कोलॉजिकल डिस्पेंसरी में एक साल की मृत्यु दर का अध्ययन करते समय, 67.9% का संकेतक प्राप्त किया गया था।
व्यायाम
1) किसी दिए गए आत्मविश्वास गुणांक के साथ अस्पताल में रोगियों के रहने की औसत अवधि का अध्ययन करते समय विश्वसनीय परिणाम प्राप्त करने के लिए स्व-परीक्षा= 3 (विश्वसनीयता = 0.9973) और सीमांत त्रुटि = 0.5 दिन;
2) एक ऑन्कोलॉजिकल डिस्पेंसरी में दिए गए आत्मविश्वास गुणांक के साथ एक साल की मृत्यु दर के अध्ययन में विश्वसनीय परिणाम प्राप्त करने के लिए स्व-परीक्षा= 2 (विश्वसनीयता = 0.9544) और सीमांत त्रुटि = 0.05।
समाधान
1. अस्पताल में मरीजों के ठहरने की औसत अवधि का अध्ययन करने के लिए आवश्यक नमूना आकार की गणना:
2. एक ऑन्कोलॉजिकल डिस्पेंसरी में एक साल की मृत्यु दर के अध्ययन के लिए आवश्यक नमूना आकार की गणना:
निष्कर्ष
1. दी गई 0.5 दिनों की सटीकता के साथ अस्पताल में मरीजों के ठहरने की औसत लंबाई का एक संकेतक प्राप्त करने के लिए, आवश्यक नमूना आकार 96 रोगियों का होना चाहिए।
2. = 0.05 की गारंटीकृत सटीकता के साथ एक वर्ष की मृत्यु दर प्राप्त करने के लिए, आवश्यक नमूना आकार 352 रोगियों का होना चाहिए।
1.4.5. परीक्षण कार्य
केवल एक सही उत्तर चुनें।1. किस जनसंख्या को सामान्य कहा जाता है?
1) अध्ययन के लिए आवश्यक विश्वसनीय डेटा;
2) जनसंख्या की व्यक्तिगत इकाइयाँ, जो विभिन्न यादृच्छिक कारणों से एक दूसरे से भिन्न होती हैं;
3) अवलोकन इकाइयों की असीमित संख्या;
4) सांख्यिकीय तत्वों का एक सेट;
5) अवलोकन की गुणात्मक रूप से सजातीय इकाइयों का एक सेट, एक या सुविधाओं के समूह द्वारा एकजुट।
2. सामान्य जनसंख्या की प्रेक्षण इकाइयों का वह भाग जो चयनात्मक अनुसंधान के अधीन होता है, कहलाता है :
1) एक आंशिक सेट;
2) यादृच्छिक संग्रह;
3) नमूना सेट;
4) कुल जनसंख्या;
5) खंडित समुच्चय।
3. एक नमूना सेट में अवलोकन इकाइयों के संयोजन के लिए सबसे महत्वपूर्ण शर्त क्या है:
1) प्रतिनिधित्व;
2) एकरूपता;
3) विविधता;
4) एकरूपता;
5) मौका।
4. क्या त्रुटियाँ उत्पन्न होती हैं क्योंकि नमूना सामान्य जनसंख्या की विशेषताओं को सटीक रूप से पुन: पेश नहीं करता है?
1) नमूना त्रुटियाँ;
2) पंजीकरण त्रुटियां;
3) अनजाने में हुई त्रुटियां;
4) तार्किक त्रुटियां;
5) व्यवस्थित त्रुटियां।
5. नमूने की विशेषताओं और सामान्य जनसंख्या के बीच संभावित विसंगति को किसके द्वारा मापा जाता है:
1) मानक विचलन;
2) फैलाव;
3) नमूना त्रुटि;
4) सहसंबंध;
5) पंजीकरण त्रुटि।
6. नमूने की प्रतिनिधित्वशीलता कैसे सुनिश्चित की जाती है?
1) यादृच्छिक चयन;
2) नमूना त्रुटि;
3) सीमांत त्रुटि;
4) मानक विचलन;
5) यादृच्छिक त्रुटि।
7. धारावाहिक चयन क्या है?
1) अवलोकन की इकाइयों की प्रतिलिपि-जोड़े का चयन;
2) यादृच्छिक संख्या जनरेटर का उपयोग करके अवलोकनों की इकाइयों का चयन;
3) अवलोकन की इकाइयों के पूरे समूहों का चयन;
4) अवलोकन की इकाइयों का बहुस्तरीय चयन;
5) अवलोकन की इकाइयों का टाइपोलॉजिकल चयन।
8. सीमांत नमूना त्रुटि की गणना के लिए सूत्र निर्दिष्ट करें:

9. कोहोर्ट विधि का उपयोग कब किया जाता है?
1) जनसंख्या की घटनाओं का अध्ययन करने के लिए;
2) रुग्णता और जोखिम कारकों के कारण और प्रभाव संबंधों का विश्लेषण;
3) लक्षित चिकित्सा और सामाजिक कार्यक्रमों का विकास;
4) एक निश्चित जनसांख्यिकीय घटना की शुरुआत से एकजुट लोगों के अपेक्षाकृत सजातीय समूहों की सांख्यिकीय आबादी का अध्ययन;
5) स्वास्थ्य देखभाल प्रणाली की सामाजिक दक्षता का विश्लेषण।
10. आवश्यक नमूना आकार, जो दी गई सटीकता प्रदान करता है, सूत्र द्वारा निर्धारित किया जाता है:

1.4.6. स्वतंत्र समाधान के लिए कार्य
कार्य 1
प्रारंभिक आंकड़े
1. स्कूली बच्चों की औसत ऊंचाई के प्रारंभिक अध्ययन में, निम्नलिखित डेटा प्राप्त किया गया था: एम = 132 सेमी, σ = 3.18 सेमी, μ = 0.13 सेमी।
2. शहरी आबादी की रुग्णता के प्रारंभिक अध्ययन में, 980 0/00 का एक संकेतक प्राप्त किया गया था।
व्यायाम
आवश्यक नमूना आकार निर्धारित करें:
1) आत्मविश्वास गुणांक वाले स्कूली बच्चों की औसत ऊंचाई का अध्ययन करते समय विश्वसनीय परिणाम प्राप्त करने के लिए टी = 3 और सीमांत त्रुटि = 0.5 सेमी;
2) एक आत्मविश्वास गुणांक के साथ शहरी आबादी की रुग्णता के गहन अध्ययन में विश्वसनीय परिणाम प्राप्त करने के लिए टी
टास्क 2
प्रारंभिक आंकड़े
1. शारीरिक गतिविधि के बाद किशोरों में औसत हृदय गति (एचआर) के प्रारंभिक अध्ययन में, निम्नलिखित डेटा प्राप्त किया गया: एम = 110 प्रति मिनट, = 10.0 प्रति मिनट, μ = 4.0 प्रति मिनट।
2. अधिक वजन वाले व्यक्तियों की आवृत्ति का अध्ययन करते समय, 528.4 0/00 का संकेतक प्राप्त किया गया था।
व्यायाम
आवश्यक नमूना आकार निर्धारित करें:
1) आत्मविश्वास गुणांक के साथ शारीरिक गतिविधि के बाद किशोरों में औसत हृदय गति का अध्ययन करते समय विश्वसनीय परिणाम प्राप्त करने के लिए टी = 3 और सीमांत त्रुटि = 0.5 प्रति मिनट;
2) अधिक वजन वाले व्यक्तियों की घटना की आवृत्ति का अध्ययन करते समय विश्वसनीय परिणाम प्राप्त करने के लिए, एक आत्मविश्वास गुणांक के साथ टी = 2 और सीमांत त्रुटि Δ = 2।
टास्क 3
प्रारंभिक आंकड़े
1. श्वसन रोगों के लिए आउट पेशेंट उपचार से गुजर रहे रोगियों की अस्थायी विकलांगता की औसत अवधि के प्रारंभिक अध्ययन में, निम्नलिखित डेटा प्राप्त किया गया: एम = 12 दिन, σ = 2.15 दिन, μ = 0.2 दिन।
2. प्रारंभिक अध्ययन में, लंबे समय तक कंप्यूटर पर काम करने वाले व्यक्तियों में दृश्य हानि की आवृत्ति को मान द्वारा चिह्नित किया जाता है
257, 0 / 00 . व्यायाम
आवश्यक नमूना आकार निर्धारित करें:
1) श्वसन रोगों के लिए आउट पेशेंट उपचार से गुजर रहे रोगियों की अस्थायी विकलांगता की औसत अवधि के अध्ययन में विश्वसनीय परिणाम प्राप्त करने के लिए, आत्मविश्वास गुणांक के साथ टी = 3 और सीमांत त्रुटि = 0.5 दिन;
