تعریف سری تغییرات سری تنوع و تنوع، محدوده تنوع
مجموعه ارزش های مورد مطالعه در این آزمایشیا مشاهده یک پارامتر رتبه بندی شده بر اساس بزرگی (افزایش یا کاهش) سری تغییرات نامیده می شود.
بیایید فرض کنیم که فشار خون ده بیمار را اندازهگیری کردهایم تا آستانه BP بالایی را به دست آوریم: فشار سیستولیک، یعنی. فقط یک عدد
تصور کنید که یک سری از مشاهدات (جمعیت آماری) فشار سیستولیک شریانی در 10 مشاهده به شکل زیر باشد (جدول 1):
میز 1
اجزاء سری تغییراتگزینه نامیده می شوند. واریانت ها ارزش عددی صفت مورد مطالعه را نشان می دهند.
ساخت یک سری متغیر از مجموعه آماری مشاهدات تنها اولین گام برای درک ویژگی های کل مجموعه است. در مرحله بعد، تعیین سطح متوسط صفت کمی مورد مطالعه (میانگین سطح پروتئین خون، میانگین وزن بیماران، میانگین زمان شروع بیهوشی و ...) ضروری است.
سطح متوسط با استفاده از معیارهایی که میانگین نامیده می شود اندازه گیری می شود. مقدار متوسط - تعمیم مشخصه عددیمقادیر کیفی همگن، که با یک عدد کل جامعه آماری را با توجه به یک ویژگی مشخص می کند. مقدار متوسط، کلی را بیان می کند که مشخصه یک صفت در مجموعه ای از مشاهدات معین است.
سه نوع میانگین در استفاده رایج وجود دارد: حالت ()، میانه () و میانگین حسابی ().
برای تعریف هر سایز متوسطلازم است از نتایج مشاهدات فردی استفاده کرد و آنها را در قالب یک سری تغییرات نوشت (جدول 2).
روش- مقداری که بیشتر در یک سری از مشاهدات رخ می دهد. در مثال ما، mode = 120. اگر مقادیر تکراری در سری تغییرات وجود نداشته باشد، آنها می گویند که هیچ حالتی وجود ندارد. اگر چندین مقدار به تعداد یکسان تکرار شوند، کوچکترین آنها به عنوان حالت در نظر گرفته می شود.
میانه- مقداری که توزیع را به دو قسمت مساوی تقسیم می کند، مقدار مرکزی یا میانه یک سری مشاهدات که به ترتیب صعودی یا نزولی مرتب شده اند. بنابراین، اگر 5 مقدار در سری تغییرات وجود داشته باشد، میانه آن برابر است با عضو سوم سری تغییرات، اگر در سری باشد. عدد زوجاعضا، پس میانه میانگین حسابی دو مشاهدات مرکزی آن است، یعنی. اگر 10 مشاهده در سری وجود داشته باشد، میانه برابر است با میانگین حسابی 5 و 6 مشاهده. در مثال ما.
به یک ویژگی مهم حالت و میانه توجه کنید: مقادیر آنها تحت تأثیر مقادیر عددی انواع شدید قرار نمی گیرد.
میانگین حسابیبا فرمول محاسبه می شود:
مقدار مشاهده شده در مشاهده -ام کجاست و تعداد مشاهدات است. برای پرونده ما
میانگین حسابی سه ویژگی دارد:
وسط در سری تغییرات موقعیت وسط را اشغال می کند. در یک ردیف کاملاً متقارن.
میانگین یک مقدار تعمیم دهنده است و نوسانات تصادفی است، تفاوت در داده های فردی پشت میانگین قابل مشاهده نیست. این نشان دهنده ویژگی های معمولی است که مشخصه کل جمعیت است.
مجموع انحرافات همه انواع از میانگین برابر با صفر است: . انحراف متغیر از میانگین نشان داده شده است.
سری تغییرات شامل انواع و فرکانس های مربوط به آنها است. از ده مقدار به دست آمده، عدد 120 6 بار، 115 - 3 بار، 125 - 1 بار مواجه شده است. فرکانس () - تعداد مطلق گزینه های فردی در جمعیت، که نشان می دهد چند بار رخ می دهد این گزینهدر سری تغییرات
سری تغییرات می تواند ساده باشد (فرکانس ها = 1) یا کوتاه شده گروه بندی شده، هر کدام 3-5 گزینه. یک سری ساده با تعداد کمی از مشاهدات ()، گروه بندی شده - با تعداد زیادی مشاهدات () استفاده می شود.
جایگاه ویژه ای در تحلیل های آماری به تعیین سطح متوسط ویژگی یا پدیده مورد مطالعه تعلق دارد. سطح متوسط یک ویژگی با مقادیر متوسط اندازه گیری می شود.
مقدار متوسط سطح کمی کلی صفت مورد مطالعه را مشخص می کند و یک ویژگی گروهی از جامعه آماری است. او سطح، ضعیف می شود انحرافات تصادفیمشاهدات فردی در یک جهت یا جهت دیگر و ویژگی اصلی و معمولی صفت مورد مطالعه را برجسته می کند.
میانگین ها به طور گسترده استفاده می شوند:
1. ارزیابی وضعیت سلامت جمعیت: ویژگی ها رشد فیزیکی(قد، وزن، دور قفسه سینه و ...)، شناسایی شیوع و طول مدت بیماری های مختلف، تجزیه و تحلیل شاخص های جمعیت شناختی (حرکت طبیعی جمعیت، میانگین امید به زندگی، تولید مثل جمعیت، میانگین جمعیت و ...).
2. مطالعه فعالیت موسسات پزشکی، پرسنل پزشکی و ارزیابی کیفیت کار آنها، برنامه ریزی و تعیین نیازهای جمعیت در انواع مختلفمراقبتهای پزشکی (متوسط تعداد درخواستها یا ویزیتها به ازای هر ساکن در سال، میانگین مدت اقامت بیمار در بیمارستان، میانگین مدت معاینه بیمار، متوسط تأمین پزشک، تختها و غیره).
3. مشخص کردن وضعیت بهداشتی و اپیدمیولوژیک (متوسط گرد و غبار هوای کارگاه، میانگین مساحت هر نفر، میانگین مصرف پروتئین، چربی و کربوهیدرات و ...).
4. تعیین پارامترهای پزشکی و فیزیولوژیکی در هنجار و آسیب شناسی، در پردازش داده های آزمایشگاهی، برای ایجاد قابلیت اطمینان نتایج یک مطالعه انتخابی در مطالعات اجتماعی، بهداشتی، بالینی، تجربی.
محاسبه مقادیر متوسط بر اساس سری تغییرات انجام می شود. سری واریاسیون- این یک مجموعه آماری از نظر کیفی همگن است که واحدهای جداگانه آن تفاوت های کمی ویژگی یا پدیده مورد مطالعه را مشخص می کند.
تغییرات کمی می تواند دو نوع باشد: ناپیوسته (گسسته) و پیوسته.
یک علامت ناپیوسته (گسسته) فقط به صورت یک عدد صحیح بیان می شود و نمی تواند داشته باشد مقادیر میانی(به عنوان مثال تعداد بازدید، جمعیت سایت، تعداد فرزندان خانواده، شدت بیماری در نقاط و ...).
یک علامت پیوسته می تواند هر مقداری را در محدوده های خاصی از جمله کسری به خود بگیرد و فقط تقریباً بیان می شود (به عنوان مثال وزن - برای بزرگسالان می توانید خود را به کیلوگرم محدود کنید و برای نوزادان - گرم؛ قد، فشار خون، زمان. صرف دیدن بیمار و غیره می شود).
مقدار دیجیتالی هر ویژگی یا پدیده منفرد موجود در سری تغییرات، یک نوع نامیده می شود و با حرف نشان داده می شود V . به عنوان مثال، نمادهای دیگری نیز در ادبیات ریاضی وجود دارد ایکس یا y
یک سری متغیر، که در آن هر گزینه یک بار نشان داده می شود، ساده نامیده می شود.این خطوط در اکثر موارد استفاده می شود وظایف آماریدر مورد پردازش داده های کامپیوتری.
با افزایش تعداد مشاهدات، به عنوان یک قاعده، مقادیر تکراری از نوع وجود دارد. در این صورت ایجاد می کند سری تغییرات گروهی، جایی که تعداد تکرارها نشان داده شده است (تکرار، با حرف " آر »).
سری تغییرات رتبه بندی شدهشامل گزینه هایی است که به ترتیب صعودی یا نزولی مرتب شده اند. هر دو سری ساده و گروه بندی شده را می توان با رتبه بندی تشکیل داد.
سری تغییرات فاصلهبه منظور ساده کردن محاسبات بعدی که بدون استفاده از رایانه انجام می شود، با تعداد بسیار زیادی واحد مشاهده (بیش از 1000) ساخته شده اند.
سری تغییرات پیوستهشامل مقادیر متغیر است که می تواند هر مقداری باشد.
اگر در سری تغییرات مقادیر مشخصه (گزینه ها) به صورت اعداد خاص جداگانه داده شود، چنین سری نامیده می شود. گسسته.
خصوصیات عمومیمقادیر صفت منعکس شده در سری تغییرات مقادیر متوسط هستند. در این میان بیشترین کاربرد عبارتند از: میانگین حسابی م،روش موو میانه منهر یک از این ویژگی ها منحصر به فرد است. آنها نمی توانند جایگزین یکدیگر شوند و تنها در مجموع، کاملاً و به صورت مختصر، از ویژگی های سری تغییرات هستند.
روش (مو) مقدار گزینه های رایج را نام ببرید.
میانه (من) مقدار متغیری است که سری تغییرات دامنهدار را به نصف تقسیم میکند (در هر طرف میانه نیمی از متغیر وجود دارد). در موارد نادر، زمانی که یک سری تغییرات متقارن وجود دارد، مد و میانه با یکدیگر برابر هستند و با مقدار میانگین حسابی منطبق هستند.
معمولی ترین مشخصه مقادیر متغیر این است میانگین حسابیارزش( م ). در ادبیات ریاضی به آن اشاره می شود .
میانگین حسابی (م، ) یک مشخصه کمی کلی از یک ویژگی خاص از پدیده های مورد مطالعه است که یک مجموعه آماری از نظر کیفی همگن را تشکیل می دهد. بین میانگین حسابی ساده و میانگین وزنی تمایز قائل شوید. میانگین حسابی ساده برای یک سری متغیر ساده با جمع همه گزینه ها و تقسیم این مجموع بر تعداد کل گزینه های موجود در این سری متغیر محاسبه می شود. محاسبات طبق فرمول انجام می شود:
 ,
,
جایی که: م - میانگین حسابی ساده؛
Σ V - گزینه مقدار؛
n- تعداد مشاهدات
در سری تغییرات گروهی، میانگین حسابی وزنی تعیین می شود. فرمول محاسبه آن:
 ,
,
جایی که: م - میانگین موزون حسابی؛
Σ vp - مجموع محصولات یک نوع در فرکانس آنها.
n- تعداد مشاهدات
با تعداد زیاد مشاهدات در مورد محاسبات دستی می توان از روش گشتاورها استفاده کرد.
میانگین حسابی دارای ویژگی های زیر است:
مجموع انحرافات متغیر از میانگین ( Σ د ) برابر با صفر است (جدول 15 را ببینید).
هنگام ضرب (تقسیم) همه گزینه ها در یک عامل (مقسوم کننده) ، میانگین حسابی در یک عامل (تقسیم کننده) ضرب (تقسیم) می شود.
اگر یک عدد را به همه گزینه ها اضافه کنید (کم کنید)، میانگین حسابی به همان عدد افزایش (کاهش) می یابد.
میانگینهای حسابی، بدون در نظر گرفتن تغییرپذیری سریهایی که از آن محاسبه میشوند، بهخودی خود گرفته میشوند، ممکن است بهطور کامل ویژگیهای سری تغییرات را منعکس نکنند، به خصوص زمانی که مقایسه با میانگینهای دیگر ضروری باشد. میانگین های نزدیک به ارزش را می توان از سری با به دست آورد درجات مختلفپراکندگی هر چه گزینه های فردی از نظر ویژگی های کمی به یکدیگر نزدیکتر باشند، کمتر است پراکندگی (نوسان، تغییرپذیری)سری، میانگین آن معمولی تر است.
پارامترهای اصلی که امکان ارزیابی تغییرپذیری یک صفت را فراهم می کند عبارتند از:
· محدوده؛
دامنه؛
· انحراف معیار؛
· ضریب تغییرات.
به طور تقریبی، نوسانات یک صفت را می توان با دامنه و دامنه سری تغییرات قضاوت کرد. محدوده حداکثر (V max) و حداقل (V min) گزینه های سری را نشان می دهد. دامنه (A m) تفاوت بین این گزینه ها است: A m = V max - V min .
معیار اصلی و عمومی پذیرفته شده برای نوسانات سری تغییرات هستند پراکندگی (D ). اما بیشتر اوقات از پارامتر راحت تر استفاده می شود که بر اساس واریانس محاسبه می شود - انحراف استاندارد ( σ ). این مقدار انحراف را در نظر می گیرد ( د ) هر گونه از سری تغییرات از میانگین حسابی آن ( d=V - M ).
از آنجایی که انحراف متغیر از میانگین می تواند مثبت و منفی باشد، پس از جمع آوری مقدار "0" (S d=0). برای جلوگیری از این، مقادیر انحراف ( د) به توان دوم افزایش یافته و میانگین می شوند. بنابراین، واریانس سری تغییرات، مجذور میانگین انحراف متغیر از میانگین حسابی است و با فرمول محاسبه می شود:
 .
.
این مهم ترین مشخصه تغییرپذیری است و برای محاسبه بسیاری از آزمون های آماری استفاده می شود.
از آنجایی که واریانس به عنوان مربع انحرافات بیان می شود، نمی توان از مقدار آن در مقایسه با میانگین حسابی استفاده کرد. برای این اهداف از آن استفاده می شود انحراف معیار، که با علامت "سیگما" نشان داده می شود ( σ ). میانگین انحراف همه انواع سری تغییرات از میانگین حسابی را در واحدهای مشابه خود میانگین مشخص می کند، بنابراین می توان آنها را با هم استفاده کرد.
انحراف استاندارد با فرمول تعیین می شود:

این فرمول برای تعداد مشاهدات ( n ) بزرگتر از 30 است. با عدد کوچکتر n مقدار انحراف استاندارد دارای خطای مرتبط با بایاس ریاضی ( n - 1). در این رابطه، با در نظر گرفتن چنین سوگیری در فرمول محاسبه انحراف استاندارد، می توان نتیجه دقیق تری به دست آورد:
انحراف معیار (س ) تخمینی از انحراف معیار متغیر تصادفی است ایکسدر مورد او انتظارات ریاضیبر اساس یک برآورد بی طرفانه از واریانس آن.
برای ارزش ها n > 30 انحراف معیار ( σ ) و انحراف معیار ( س ) همینطور خواهد بود ( σ=s ). بنابراین، در بیشتر کتابچه های کاربردی، این معیارها دارای معانی متفاوتی هستند.در یک برنامه محاسبه اکسلانحراف استاندارد را می توان با =STDEV (محدوده) انجام داد. و برای محاسبه انحراف معیار، باید یک فرمول مناسب ایجاد کنید.
ریشه میانگین مربع یا انحراف استاندارد به شما امکان می دهد تعیین کنید که مقادیر یک ویژگی چقدر می تواند با مقدار میانگین متفاوت باشد. فرض کنید دو شهر با میانگین دمای روزانه یکسان وجود دارد دوره تابستان. یکی از این شهرها در ساحل و دیگری در قاره قرار دارد. مشخص است که در شهرهای واقع در ساحل، تفاوت دمای روز کمتر از شهرهای واقع در داخل است. بنابراین انحراف معیار دمای روز در نزدیکی شهر ساحلی کمتر از شهر دوم خواهد بود. در عمل، این بدان معنی است که میانگین دمای هوای هر روز خاص در یک شهر واقع در این قاره بیشتر از میانگین دمای یک شهر در ساحل متفاوت است. علاوه بر این، انحراف استاندارد امکان برآورد انحرافات احتمالی دما از میانگین را با سطح احتمال مورد نیاز فراهم می کند.
بر اساس تئوری احتمال، در پدیده هایی که از قانون توزیع نرمال پیروی می کنند، بین مقادیر میانگین حسابی، انحراف معیار و گزینه ها رابطه سختی وجود دارد. قانون سه سیگما). به عنوان مثال، 68.3٪ از مقادیر یک ویژگی متغیر در M ± 1 است σ 95.5٪ - در محدوده M ± 2 σ و 99.7٪ - در M ± 3 σ .
مقدار انحراف معیار قضاوت در مورد ماهیت همگنی سری تغییرات و گروه مورد مطالعه را ممکن می سازد. اگر مقدار انحراف معیار کوچک باشد، این نشان دهنده همگنی به اندازه کافی بالای پدیده مورد مطالعه است. میانگین حسابی در این مورد باید کاملاً مشخصه این سری متغیر شناخته شود. با این حال، یک سیگمای بسیار کوچک باعث میشود که فرد به انتخاب مصنوعی مشاهدات فکر کند. با یک سیگما بسیار بزرگ، میانگین حسابی سری تغییرات را به میزان کمتری مشخص میکند که نشاندهنده تنوع قابلتوجه صفت یا پدیده مورد مطالعه یا ناهمگونی گروه مورد مطالعه است. با این حال، مقایسه مقدار انحراف معیار فقط برای علائمی با همان ابعاد امکان پذیر است. در واقع، اگر تنوع وزن نوزادان و بزرگسالان را مقایسه کنیم، همیشه مقادیر سیگما در بزرگسالان بالاتر خواهد بود.
مقایسه تنوع ویژگی های ابعاد مختلف می تواند با استفاده از ضریب تغییر. تنوع را به صورت درصدی از میانگین بیان می کند که امکان مقایسه صفات مختلف را فراهم می کند. ضریب تغییرات در ادبیات پزشکیمشخص شده با " از جانب "، و در ریاضیات" v» و با فرمول محاسبه می شود:
 .
.
مقادیر ضریب تغییرات کمتر از 10٪ نشان دهنده یک پراکندگی کوچک است، از 10 تا 20٪ - حدود متوسط، بیش از 20٪ - در مورد یک پراکندگی قوی در اطراف میانگین حسابی.
میانگین حسابی معمولاً از روی داده ها محاسبه می شود چارچوب نمونه. با مطالعات مکرر تحت تأثیر پدیده های تصادفی، میانگین حسابی ممکن است تغییر کند. این به دلیل این واقعیت است که به عنوان یک قاعده، تنها بخشی از واحدهای مشاهده ممکن، یعنی یک جامعه نمونه، بررسی می شود. اطلاعات مربوط به تمام واحدهای ممکن که نمایانگر پدیده مورد مطالعه هستند را می توان با مطالعه کل به دست آورد جمعیت، که همیشه امکان پذیر نیست. در عین حال، به منظور تعمیم داده های تجربی، مقدار میانگین در جمعیت عمومی مورد توجه است. بنابراین برای تدوین یک نتیجه کلی در مورد پدیده مورد مطالعه، نتایج به دست آمده بر اساس جامعه نمونه باید با روش های آماری به جامعه عمومی منتقل شود.
برای تعیین میزان تطابق بین مطالعه نمونه و جامعه عمومی، لازم است میزان خطای که به طور اجتناب ناپذیری به وجود می آید، برآورد شود. مشاهده انتخابی. چنین خطایی نامیده می شود خطای نمایندگی” یا “میانگین خطای میانگین حسابی”. در واقع تفاوت بین میانگین های بدست آمده از نمونه است مشاهده آماری، و مقادیر مشابهی که در مطالعه مستمر یک شی به دست می آیند، به عنوان مثال. هنگام مطالعه جمعیت عمومی از آنجایی که میانگین نمونه یک متغیر تصادفی است، چنین پیش بینی با سطح احتمال قابل قبولی برای محقق انجام می شود. در تحقیقات پزشکی حداقل 95 درصد است.
خطای بازنمایی نباید با خطاهای ثبت یا خطاهای توجه (اشتباه چاپی، محاسبات اشتباه، چاپ اشتباه، و غیره) اشتباه گرفته شود، که باید با روش و ابزار مناسب مورد استفاده در آزمایش به حداقل برسد.
بزرگی خطای بازنمایی هم به حجم نمونه و هم به متغیر بودن صفت بستگی دارد. چگونه تعداد بیشترمشاهدات، هر چه نمونه به جامعه عمومی نزدیکتر باشد و خطا کمتر باشد. هرچه ویژگی متغیرتر باشد، خطای آماری بیشتر است.
در عمل، از فرمول زیر برای تعیین خطای نمایندگی در سری های متغیر استفاده می شود:
 ,
,
جایی که: متر - خطای نمایندگی؛
σ - انحراف معیار؛
nتعداد مشاهدات در نمونه است.
از فرمول می توان فهمید که اندازه خطای متوسطبا انحراف معیار، یعنی تغییرپذیری صفت مورد مطالعه، نسبت مستقیم دارد و با جذر تعداد مشاهدات نسبت معکوس دارد.
هنگام انجام تجزیه و تحلیل آماری بر اساس محاسبه مقادیر نسبی، ساخت یک سری تغییرات اجباری نیست. در این مورد، تعیین میانگین خطا برای شاخص های نسبی را می توان با استفاده از یک فرمول ساده انجام داد:
 ,
,
جایی که: آر- ارزش شاخص نسبی، به صورت درصد، ppm و غیره بیان می شود.
q- متقابل P و به صورت (1-P)، (100-P)، (1000-P) و غیره بیان می شود، بسته به مبنایی که شاخص برای آن محاسبه می شود.
nتعداد مشاهدات در نمونه است.
با این حال، فرمول مشخص شده برای محاسبه خطای نمایندگی برای مقادیر نسبی تنها زمانی قابل اعمال است که مقدار نشانگر کمتر از پایه آن باشد. در تعدادی از موارد محاسبه شاخص های فشرده، این شرط برقرار نیست و می توان شاخص را به صورت عددی بیش از 100% یا 1000% o بیان کرد. در چنین شرایطی، یک سری تغییرات ساخته شده و خطای نمایندگی با استفاده از فرمول مقادیر میانگین بر اساس انحراف استاندارد محاسبه میشود.
پیش بینی مقدار میانگین حسابی در جمعیت عمومی با نشان دادن دو مقدار - حداقل و حداکثر انجام می شود. این مقادیر شدید انحرافات احتمالی، که در آن مقدار متوسط مطلوب جمعیت عمومی می تواند در نوسان باشد، نامیده می شود. مرزهای اعتماد به نفس».
فرضیه های نظریه احتمال ثابت کردند که با توزیع نرمال یک ویژگی با احتمال 99.7٪، مقادیر شدید انحرافات میانگین نخواهد بود. ارزش بیشترسه برابر خطای نمایندگی ( م ± 3 متر ) در 95.5٪ - نه بیشتر از مقدار خطای میانگین دو برابر شده مقدار متوسط ( م ± 2 متر ) در 68.3٪ - نه بیشتر از مقدار یک خطای متوسط ( م ± 1 متر ) (شکل 9).

| پ٪ |
برنج. 9. چگالی احتمال توزیع نرمال.
توجه داشته باشید که عبارت فوق فقط برای ویژگی هایی صادق است که از قانون توزیع طبیعی گاوسی پیروی می کند.
بیشتر مطالعات تجربی، از جمله مطالعات در زمینه پزشکی، با اندازهگیریهایی همراه هستند که نتایج آن میتواند تقریباً هر مقدار را در یک بازه زمانی معین بگیرد، بنابراین، به عنوان یک قاعده، آنها با مدلی از متغیرهای تصادفی پیوسته توصیف میشوند. در این راستا اکثر روش های آماری توزیع های پیوسته را در نظر می گیرند. یکی از این توزیع ها که نقش اساسی در آمار ریاضی، است توزیع نرمال یا گاوسی.
این به دلایل مختلفی است.
1. اول از همه، بسیاری از مشاهدات تجربی را می توان با موفقیت با استفاده از توزیع نرمال توصیف کرد. فوراً باید توجه داشت که هیچ توزیعی از داده های تجربی وجود ندارد که دقیقاً نرمال باشد، زیرا یک متغیر تصادفی توزیع شده نرمال در محدوده ای از تا قرار دارد که هرگز در عمل رخ نمی دهد. با این حال، توزیع نرمال اغلب یک تقریب خوب است.
این که آیا اندازه گیری وزن، قد و سایر پارامترهای فیزیولوژیکی بدن انسان انجام می شود - همه جا نتایج تحت تأثیر بسیار زیاد است. عدد بزرگعوامل تصادفی (علل طبیعی و خطاهای اندازه گیری). و قاعدتاً تأثیر هر یک از این عوامل ناچیز است. تجربه نشان می دهد که نتایج در چنین مواردی تقریباً به طور معمول توزیع می شود.
2. بسیاری از توزیع های مرتبط با یک نمونه تصادفی، با افزایش حجم دومی، نرمال می شوند.
3. توزیع نرمال به عنوان یک توصیف تقریبی دیگر مناسب است توزیع های پیوسته(مثلاً نامتقارن).
4. توزیع نرمال دارای تعدادی ویژگی ریاضی مطلوب است که تا حد زیادی استفاده گسترده آن را در آمار تضمین می کند.
در عین حال، باید توجه داشت که در داده های پزشکی توزیع های تجربی زیادی وجود دارد که با مدل توزیع نرمال قابل توصیف نیستند. برای انجام این کار، آمار روش هایی را توسعه داده است که معمولاً «ناپارامتریک» نامیده می شود.
انتخاب روش آماری، که برای پردازش داده های یک آزمایش خاص مناسب است، باید بسته به اینکه داده های به دست آمده متعلق به قانون توزیع نرمال هستند، ساخته شود. آزمایش فرضیه برای تبعیت یک علامت به قانون توزیع نرمال با استفاده از هیستوگرام توزیع فرکانس (گراف)، و همچنین تعدادی از معیارهای آماری انجام می شود. از جمله:
معیار عدم تقارن ( ب );
معیارهای بررسی کشیدگی ( g );
معیار شاپیرو-ویلکز ( دبلیو ) .
تجزیه و تحلیل ماهیت توزیع داده ها (به آن آزمون نرمال بودن توزیع نیز گفته می شود) برای هر پارامتر انجام می شود. برای قضاوت مطمئن در مورد انطباق توزیع پارامتر با قانون عادی، تعداد کافی واحد مشاهده (حداقل 30 مقدار) مورد نیاز است.
برای توزیع نرمال، معیار چولگی و کشیدگی مقدار 0 را می گیرد. اگر توزیع به سمت راست منتقل شود. ب > 0 (عدم تقارن مثبت)، با ب < 0 - график распределения смещен влево (отрицательная асимметрия). Критерий асимметрии проверяет форму кривой распределения. В случае قانون عادی g =0. در g > 0 منحنی توزیع واضح تر است اگر g < 0 пик более сглаженный, чем функция нормального распределения.
برای تست نرمال بودن با استفاده از آزمون Shapiro-Wilks، باید مقدار این معیار را با استفاده از جداول آماری در سطح معناداری مورد نیاز و بسته به تعداد واحدهای مشاهده (درجات آزادی) یافت. پیوست 1. فرضیه نرمال بودن برای مقادیر کوچک این معیار، به عنوان یک قاعده، رد می شود. w <0,8.
بیایید مقادیر مختلف نمونه را فراخوانی کنیم گزینه هایک سری مقادیر و نشان دهنده: ایکس 1 , ایکس 2، …. اول از همه، بیایید بسازیم محدودهگزینه ها، یعنی آنها را به ترتیب صعودی یا نزولی مرتب کنید. برای هر گزینه، وزن خود نشان داده شده است، یعنی. عددی که سهم این گزینه در کل جمعیت را مشخص می کند. فرکانس ها یا فرکانس ها به عنوان وزن عمل می کنند.
فرکانس n من گزینه x iعددی نامیده می شود که نشان می دهد این گزینه چند بار در جامعه نمونه در نظر گرفته شده رخ می دهد.
فرکانس یا فرکانس نسبی w i گزینه x iعددی برابر با نسبت فرکانس یک واریانت به مجموع فرکانس های همه انواع نامیده می شود. بسامد نشان می دهد که چه بخشی از واحدهای جامعه نمونه دارای یک نوع معین است.
دنباله گزینه ها با وزن متناظر آنها (فرکانس یا فرکانس) که به ترتیب صعودی (یا نزولی) نوشته می شود، نامیده می شود. سری های متغیر.
سری های متغیر گسسته و بازه ای هستند.
برای یک سری تغییرات گسسته، مقادیر نقطهای مشخصه مشخص میشود، برای سری بازهای، مقادیر ویژگیها به صورت فواصل مشخص میشوند. سری تغییرات می تواند توزیع فرکانس ها یا فرکانس های نسبی (فرکانس ها) را بسته به مقدار مشخص شده برای هر گزینه - فرکانس یا فرکانس نشان دهد.
سری تغییرات گسسته توزیع فرکانسبه نظر می رسد:
فرکانس ها با فرمول i = 1, 2, … متر.
w 1 +w 2 + … + w m = 1.
مثال 4.1. برای مجموعه ای معین از اعداد
4, 6, 6, 3, 4, 9, 6, 4, 6, 6
ساخت سری های متغیر گسسته از توزیع های فرکانس و فرکانس.
تصمیم گیری . حجم جمعیت است n= 10. سری توزیع فرکانس گسسته دارای فرم است
سریال های فاصله ای شکل مشابهی از ضبط دارند.
سری تغییرات فاصله توزیع فرکانسبه صورت نوشته شده است:
مجموع همه فرکانس ها برابر است با تعداد کل مشاهدات، یعنی. حجم کل: n = n 1 +n 2 + … + nمتر
سری تغییرات بازه ای توزیع فرکانس های نسبی (فرکانس ها)به نظر می رسد:
فرکانس با فرمول i = 1, 2, … متر.
مجموع همه فرکانس ها برابر با یک است: w 1 +w 2 + … + w m = 1.
اغلب در عمل از سری های فاصله ای استفاده می شود. اگر دادههای نمونه آماری زیادی وجود داشته باشد و مقادیر آنها به مقدار دلخواه کمی با یکدیگر متفاوت باشد، آنگاه سریهای گسسته برای این دادهها برای تحقیقات بیشتر دستوپاگیر و ناخوشایند خواهد بود. در این مورد، از گروه بندی داده ها استفاده می شود، یعنی. بازه ای که شامل تمام مقادیر ویژگی است به چندین بازه جزئی تقسیم می شود و با محاسبه فرکانس برای هر بازه، یک سری بازه به دست می آید. اجازه دهید طرح ساخت یک سری بازه ای را با جزئیات بیشتر بنویسیم، با فرض اینکه طول بازه های جزئی یکسان باشد.
2.2 ساخت یک سری فاصله
برای ساخت یک سری فاصله، شما نیاز دارید:
تعداد فواصل را تعیین کنید؛
طول فواصل را تعیین کنید؛
محل فواصل روی محور را تعیین کنید.
برای تعیین تعداد فواصل ک یک فرمول استرجز وجود دارد که طبق آن
 ,
,
جایی که n- حجم کل.
به عنوان مثال، اگر 100 مقدار مشخصه (نوع) وجود دارد، توصیه می شود برای ساخت یک سری بازه، تعداد بازه ها را برابر با فواصل در نظر بگیرید.
با این حال، اغلب در عمل تعداد بازهها توسط خود محقق انتخاب میشود، با توجه به اینکه این تعداد نباید خیلی زیاد باشد، به طوری که مجموعهها دست و پا گیر نباشد، بلکه خیلی کم نیز نباشد تا برخی از ویژگیهای آن از بین نرود. توزیع
طول فاصله ساعت با فرمول زیر تعیین می شود:
 ,
,
جایی که ایکسحداکثر و ایکس min به ترتیب بزرگترین و کوچکترین مقادیر گزینه ها است.
ارزش  تماس گرفت در مقیاس بزرگردیف
تماس گرفت در مقیاس بزرگردیف
برای ساختن خود فواصل، به روش های مختلفی پیش می روند. یکی از ساده ترین راه ها به شرح زیر است. مقدار به عنوان شروع اولین بازه در نظر گرفته می شود  . سپس بقیه مرزهای فواصل با فرمول پیدا می شوند. بدیهی است که پایان آخرین فاصله آ m+1 باید شرایط را برآورده کند
. سپس بقیه مرزهای فواصل با فرمول پیدا می شوند. بدیهی است که پایان آخرین فاصله آ m+1 باید شرایط را برآورده کند
پس از یافتن تمام مرزهای بازه ها، فرکانس (یا فرکانس) این بازه ها تعیین می شود. برای حل این مشکل، آنها تمام گزینه ها را بررسی می کنند و تعداد گزینه هایی را که در یک بازه زمانی خاص قرار می گیرند تعیین می کنند. ما ساخت کامل یک سری بازه ای را با استفاده از یک مثال در نظر خواهیم گرفت.
مثال 4.2. برای آمارهای زیر که به ترتیب صعودی نوشته شده اند، یک سری بازه ای با تعداد بازه ها برابر با 5 بسازید:
11, 12, 12, 14, 14, 15, 21, 21, 22, 23, 25, 38, 38, 39, 42, 42, 44, 45, 50, 50, 55, 56, 58, 60, 62, 63, 65, 68, 68, 68, 70, 75, 78, 78, 78, 78, 80, 80, 86, 88, 90, 91, 91, 91, 91, 91, 93, 93, 95, 96.
تصمیم گیری جمع n= 50 مقدار متغیر.
تعداد فواصل در شرایط مشکل مشخص می شود، یعنی. ک=5.
طول فواصل است  .
.
بیایید مرزهای فواصل را مشخص کنیم:
آ 1 = 11 − 8,5 = 2,5; آ 2 = 2,5 + 17 = 19,5; آ 3 = 19,5 + 17 = 36,5;
آ 4 = 36,5 + 17 = 53,5; آ 5 = 53,5 + 17 = 70,5; آ 6 = 70,5 + 17 = 87,5;
آ 7 = 87,5 +17 = 104,5.
برای تعیین فراوانی فواصل، تعداد گزینه هایی که در این بازه قرار می گیرند را می شماریم. به عنوان مثال گزینه های 11، 12، 12، 14، 14، 15 در فاصله اول از 2.5 تا 19.5 قرار می گیرند، تعداد آنها 6 است، بنابراین، فراوانی فاصله اول است. n 1=6. فرکانس بازه اول است  . انواع 21، 21، 22، 23، 25 که تعداد آنها 5 است، در بازه دوم از 19.5 تا 36.5 قرار می گیرند.بنابراین فراوانی بازه دوم برابر است با n 2 = 5 و فرکانس
. انواع 21، 21، 22، 23، 25 که تعداد آنها 5 است، در بازه دوم از 19.5 تا 36.5 قرار می گیرند.بنابراین فراوانی بازه دوم برابر است با n 2 = 5 و فرکانس  . با یافتن فرکانس ها و فرکانس های مشابه برای همه بازه ها، سری بازه های زیر را به دست می آوریم.
. با یافتن فرکانس ها و فرکانس های مشابه برای همه بازه ها، سری بازه های زیر را به دست می آوریم.
سری بازه ای توزیع فرکانس به شکل زیر است:
مجموع فرکانس ها 6+5+9+11+8+11=50 است.
سری بازه ای توزیع فرکانس به شکل زیر است:
مجموع فرکانس ها 0.12+0.1+0.18+0.22+0.16+0.22=1 است. ■
هنگام ساخت سری های بازه ای، بسته به شرایط خاص مسئله مورد بررسی، می توان قوانین دیگری را اعمال کرد، یعنی
1. سری تغییرات فاصله ممکن است از فواصل جزئی با طول های مختلف تشکیل شده باشد. طول نابرابر فواصل این امکان را فراهم می کند که ویژگی های یک جامعه آماری با توزیع نابرابر یک ویژگی را مشخص کنیم. به عنوان مثال، اگر مرزهای فواصل تعداد ساکنان شهرها را تعیین می کند، در این مسئله توصیه می شود از فواصل نامساوی استفاده شود. بدیهی است برای شهرهای کوچک اختلاف کمی در تعداد ساکنان نیز مهم است و برای شهرهای بزرگ اختلاف ده ها و صدها نفری قابل توجه نیست. سریهای بازهای با طولهای نابرابر بازههای جزئی عمدتاً در تئوری عمومی آمار مورد مطالعه قرار میگیرند و بررسی آنها از حوصله این راهنما خارج است.
2. در آمار ریاضی گاهی سری های بازه ای در نظر گرفته می شود که برای آن ها مرز سمت چپ بازه اول –∞ و مرز سمت راست آخرین بازه +∞ در نظر گرفته می شود. این به منظور نزدیکتر کردن توزیع آماری به توزیع نظری انجام می شود.
3. هنگام ساخت سری های بازه ای، ممکن است معلوم شود که مقدار برخی از انواع دقیقاً با مرز بازه منطبق است. بهترین کار در این مورد به شرح زیر است. اگر فقط یک چنین تصادفی وجود داشته باشد، در نظر بگیرید که نوع مورد بررسی با فرکانس آن در فاصله نزدیکتر به وسط سری بازه قرار می گیرد، اگر چندین گونه از این قبیل وجود داشته باشد، هر کدام از آنها به فواصل زمانی اختصاص داده می شوند. سمت راست این نوع، یا همه به سمت چپ.
4. پس از تعیین تعداد فواصل و طول آنها می توان محل قرارگیری فواصل را به روش دیگری انجام داد. میانگین حسابی تمام مقادیر در نظر گرفته شده گزینه ها را پیدا کنید ایکسرجوع کنید به و اولین بازه را طوری بسازید که این میانگین نمونه در داخل یک بازه باشد. بنابراین، ما فاصله از ایکسرجوع کنید به - 0.5 ساعتقبل از ایکسمیانگین + 0.5 ساعت. سپس چپ و راست با اضافه کردن طول بازه، بازه های باقی مانده را می سازیم تا ایکسدقیقه و ایکس max به ترتیب در بازه های اول و آخر قرار نمی گیرد.
5. سری های فاصله ای با تعداد بازه های زیاد به راحتی به صورت عمودی نوشته می شوند، یعنی. فواصل را نه در خط اول، بلکه در ستون اول، و فرکانس ها (یا فرکانس ها) را در ستون دوم ثبت کنید.
داده های نمونه را می توان به عنوان مقادیر برخی از متغیرهای تصادفی در نظر گرفت ایکس. یک متغیر تصادفی قانون توزیع خاص خود را دارد. از نظریه احتمال مشخص شده است که قانون توزیع یک متغیر تصادفی گسسته را می توان به عنوان یک سری توزیع و برای یک پیوسته با استفاده از تابع چگالی توزیع مشخص کرد. با این حال، یک قانون توزیع جهانی وجود دارد که برای متغیرهای تصادفی گسسته و پیوسته صادق است. این قانون توزیع به عنوان تابع توزیع داده شده است اف(ایکس) = پ(ایکس<ایکس). برای داده های نمونه، می توانید یک آنالوگ از تابع توزیع - تابع توزیع تجربی را مشخص کنید.
اطلاعات مشابه
سری واریاسیونمجموعه ای از مقادیر عددی یک ویژگی است.
ویژگی های اصلی سری تغییرات: v - نوع، p - فراوانی وقوع آن.
انواع سری های واریاسیون:
با توجه به فراوانی وقوع انواع: ساده - نوع یک بار رخ می دهد، وزن دار - نوع دو یا چند بار رخ می دهد.
گزینه ها بر اساس مکان: رتبه بندی شده - گزینه ها به ترتیب نزولی و صعودی مرتب شده اند، بدون رتبه - گزینه ها بدون ترتیب خاصی نوشته می شوند.
با گروه بندی گزینه در گروه ها: گروه بندی شده - گزینه ها در گروه ها ترکیب می شوند، گروه بندی نشده - گزینه ها گروه بندی نمی شوند.
با گزینه های مقدار: پیوسته - گزینه ها به صورت یک عدد صحیح و یک عدد کسری، گسسته - گزینه ها به صورت عدد صحیح بیان می شوند، مختلط - گزینه ها با یک مقدار نسبی یا متوسط نشان داده می شوند.
یک سری متغیر برای محاسبه مقادیر میانگین جمع آوری و ترسیم می شود.
فرم نشانه گذاری سری تغییرات:
8. مقادیر متوسط، انواع، روش محاسبه، کاربرد در مراقبت های بهداشتی
مقادیر متوسط- ویژگی کلی تعمیم دهنده ویژگی های کمی. کاربرد میانگین ها:
1. تشریح سازماندهی کار موسسات پزشکی و ارزیابی فعالیت های آنها:
الف) در پلی کلینیک: شاخص های حجم کار پزشکان، میانگین تعداد ویزیت ها، میانگین تعداد ساکنان در منطقه؛
ب) در بیمارستان: میانگین تعداد روزهای تخت در سال. میانگین مدت اقامت در بیمارستان؛
ج) در مرکز بهداشت، اپیدمیولوژی و بهداشت عمومی: میانگین مساحت (یا ظرفیت مکعب) برای هر نفر، میانگین استانداردهای تغذیه ای (پروتئین ها، چربی ها، کربوهیدرات ها، ویتامین ها، نمک های معدنی، کالری)، هنجارها و استانداردهای بهداشتی و غیره. ;
2. برای توصیف رشد فیزیکی (ویژگی های اصلی آنتروپومتریک مورفولوژیکی و عملکردی).
3. تعیین پارامترهای پزشکی و فیزیولوژیکی بدن در شرایط طبیعی و پاتولوژیک در مطالعات بالینی و تجربی.
4. در تحقیقات علمی خاص.
تفاوت بین مقادیر متوسط و شاخص ها:
1. ضرایب یک ویژگی جایگزین را مشخص می کند که فقط در بخشی از تیم آماری رخ می دهد، که ممکن است اتفاق بیفتد یا نباشد.
مقادیر متوسط علائم ذاتی در همه اعضای تیم را پوشش می دهد، اما به درجات مختلف (وزن، قد، روزهای درمان در بیمارستان).
2. برای اندازه گیری ویژگی های کیفی از ضرایب استفاده می شود. مقادیر متوسط برای صفات کمی متفاوت است.
انواع میانگین ها:
میانگین حسابی، ویژگی های آن - انحراف معیار و خطای متوسط
حالت و میانه مد (Mo)- مربوط به ارزش صفتی است که اغلب در این جمعیت یافت می شود. میانه (من)- مقدار صفت که مقدار متوسط را در این جمعیت اشغال می کند. این سری را با توجه به تعداد مشاهدات به 2 قسمت مساوی تقسیم می کند. مقدار میانگین حسابی (M)- بر خلاف حالت و میانه، بر تمام مشاهدات انجام شده متکی است، بنابراین یک مشخصه مهم برای کل توزیع است.
انواع دیگر میانگین ها که در مطالعات خاص مورد استفاده قرار می گیرند: ریشه میانگین مربع، مکعب، هارمونیک، هندسی، پیش رونده.
میانگین حسابیمیانگین سطح جامعه آماری را مشخص می کند.
برای یک سریال ساده که در آن
∑v – گزینه جمع،
n تعداد مشاهدات است.
 برای یک سریال وزن دار، که در آن
برای یک سریال وزن دار، که در آن
∑vr مجموع حاصل از هر گزینه و فراوانی وقوع آن است
n تعداد مشاهدات است.
انحراف معیارمیانگین حسابی یا سیگما (σ) تنوع ویژگی را مشخص می کند
 - برای یک ردیف ساده
- برای یک ردیف ساده
Σd 2 - مجموع مجذورات تفاوت بین میانگین حسابی و هر گزینه (d = │M-V│)
n تعداد مشاهدات است
 - برای سریال های وزن دار
- برای سریال های وزن دار
∑d 2 p مجموع حاصل ضرب مجذور اختلاف میانگین حسابی و هر گزینه و فراوانی وقوع آن است.
n تعداد مشاهدات است.
درجه تنوع را می توان با مقدار ضریب تغییرات قضاوت کرد  . بیش از 20٪ - تنوع قوی، 10-20٪ - تنوع متوسط، کمتر از 10٪ - تنوع ضعیف.
. بیش از 20٪ - تنوع قوی، 10-20٪ - تنوع متوسط، کمتر از 10٪ - تنوع ضعیف.
اگر یک سیگما (M ± 1σ) به میانگین حسابی اضافه و از آن کم شود، در آن صورت با توزیع نرمال، حداقل 68.3 درصد از همه واریانت ها (مشاهدات) در این محدوده قرار خواهند گرفت که هنجار پدیده مورد مطالعه در نظر گرفته می شود. . اگر k 2 ± 2σ باشد، 95.5٪ از تمام مشاهدات در این حدود خواهد بود، و اگر k M ± 3σ، آنگاه 99.7٪ از تمام مشاهدات در این محدوده خواهد بود. بنابراین، انحراف معیار، انحراف معیار است که امکان پیشبینی احتمال وقوع چنین مقداری از صفت مورد مطالعه را که در محدودههای مشخص شده است، میدهد.
میانگین خطای میانگین حسابییا خطای نمایندگی برای سریال های ساده و وزن دار و بر اساس قانون لحظه ها:
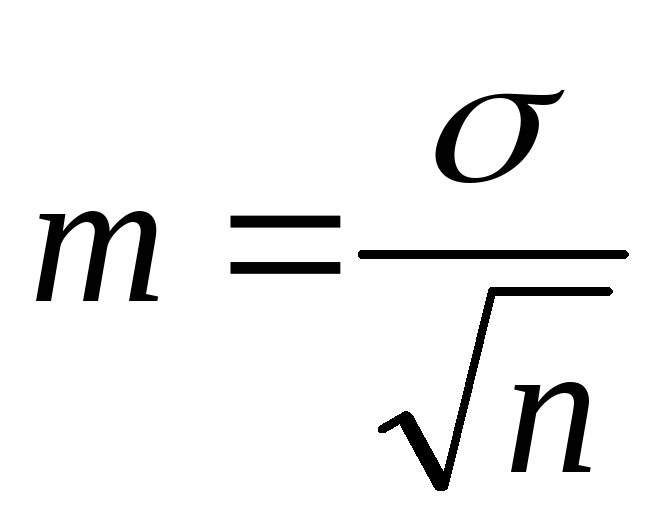 .
.
برای محاسبه مقادیر متوسط، لازم است: همگن بودن مواد، تعداد کافی مشاهدات. اگر تعداد مشاهدات کمتر از 30 باشد، در فرمول های محاسبه σ و m از n-1 استفاده می شود.
هنگام ارزیابی نتیجه به دست آمده با اندازه خطای متوسط، از ضریب اطمینان استفاده می شود که امکان تعیین احتمال پاسخ صحیح را ممکن می کند، یعنی نشان می دهد که خطای نمونه حاصل از خطای واقعی بیشتر نخواهد بود. در نتیجه مشاهده مداوم ساخته شده است. در نتیجه، با افزایش احتمال اطمینان، عرض فاصله اطمینان افزایش مییابد که به نوبه خود، اطمینان قضاوت، حمایت از نتیجه بهدستآمده را افزایش میدهد.
(تعریف یک سری متغیر؛ اجزای یک سری متغیر؛ سه شکل از یک سری متغیر؛ مصلحت ساختن یک سری بازه ای؛ نتایجی که می توان از سری ساخته شده به دست آورد)
سری تغییرات دنباله ای از تمام عناصر یک نمونه است که به ترتیب غیر کاهشی مرتب شده اند. همان عناصر تکرار می شود
متغیر - اینها سری هایی هستند که بر اساس کمی ساخته شده اند.
سری های توزیع متغیر از دو عنصر تشکیل شده است: انواع و فرکانس ها:
واریانت ها مقادیر عددی یک صفت کمی در سری تغییرات توزیع هستند. آنها می توانند مثبت یا منفی، مطلق یا نسبی باشند. بنابراین، هنگام گروه بندی شرکت ها بر اساس نتایج فعالیت اقتصادی، گزینه ها مثبت هستند - این سود است و اعداد منفی - این ضرر است.
فرکانس ها تعداد انواع مختلف یا هر گروه از سری تغییرات هستند، یعنی. اینها اعدادی هستند که نشان می دهند چند وقت یکبار گزینه های خاص در یک سری توزیع رخ می دهند. مجموع همه فرکانس ها حجم جمعیت نامیده می شود و با تعداد عناصر کل جمعیت تعیین می شود.
فرکانس ها فرکانس هایی هستند که به صورت مقادیر نسبی بیان می شوند (کسری از واحدها یا درصد). مجموع فرکانس ها برابر با یک یا 100 درصد است. جایگزینی فرکانس ها با فرکانس ها امکان مقایسه سری های متغیر با تعداد مشاهدات مختلف را فراهم می کند.
سه شکل از سری تغییرات وجود دارد:سری های رتبه بندی شده، سری های گسسته و سری های بازه ای.
سری رتبه بندی شده توزیع واحدهای فردی جمعیت به ترتیب صعودی یا نزولی صفت مورد مطالعه است. رتبه بندی تقسیم داده های کمی را به گروه ها آسان می کند، بلافاصله کوچکترین و بزرگترین مقادیر یک ویژگی را شناسایی می کند، مقادیری را که اغلب تکرار می شوند برجسته می کند.
اشکال دیگر سری تغییرات جداول گروهی هستند که با توجه به ماهیت تغییرات در مقادیر صفت مورد مطالعه گردآوری شدهاند. با ماهیت تنوع، علائم گسسته (ناپیوسته) و پیوسته متمایز می شوند.
سری گسسته چنین سری متغیری است که ساخت آن بر اساس نشانه هایی با تغییر ناپیوسته (نشانه های گسسته) است. مورد دوم شامل دسته تعرفه، تعداد فرزندان خانواده، تعداد کارکنان شرکت و غیره است. این علائم فقط می توانند تعداد محدودی از مقادیر مشخص را بگیرند.
یک سری تغییرات گسسته جدولی است که از دو ستون تشکیل شده است. ستون اول مقدار خاص ویژگی را نشان می دهد، و دوم - تعداد واحدهای جمعیت با مقدار خاصی از ویژگی.
اگر علامتی دارای تغییر مداوم باشد (میزان درآمد، تجربه کاری، هزینه دارایی های ثابت یک شرکت و غیره که می تواند هر مقداری را در محدوده خاصی داشته باشد)، باید یک سری تغییرات بازه ای برای این علامت ساخته شود.
جدول گروه در اینجا نیز دارای دو ستون است. اولی مقدار ویژگی را در بازه "از - به" (گزینه ها) نشان می دهد، دوم - تعداد واحدهای موجود در بازه (فرکانس).
فرکانس (تکرار تکرار) - تعداد تکرارهای یک نوع خاص از مقادیر مشخصه، نشان داده شده با fi، و مجموع فرکانس ها برابر با حجم جامعه مورد مطالعه، نشان داده شده است.
جایی که k تعداد گزینه های مقدار ویژگی است
اغلب، جدول با ستونی تکمیل می شود که در آن فرکانس های انباشته S محاسبه می شود، که نشان می دهد چند واحد از جمعیت دارای ارزش ویژگی هستند که بیشتر از این مقدار نیست.
یک سری توزیع متغیر گسسته سریای است که در آن گروهها بر اساس ویژگیای تشکیل میشوند که به طور گسسته متفاوت است و فقط مقادیر صحیح را میگیرد.
سری تغییرات بازهای توزیع مجموعهای است که در آن صفت گروهبندی، که اساس گروهبندی را تشکیل میدهد، میتواند هر مقداری را در یک بازه مشخص، از جمله مقادیر کسری، بگیرد.
یک سری تغییرات بازه ای مجموعه مرتب شده ای از فواصل تغییرات مقادیر یک متغیر تصادفی با فرکانس های مربوطه یا فرکانس مقادیر کمیت است که در هر یک از آنها قرار می گیرد.
ساخت یک سری توزیع بازهای، اول از همه، با تغییرات پیوسته از یک صفت، و همچنین اگر یک تغییر گسسته در یک محدوده وسیع ظاهر شود، مصلحت است. تعداد گزینه ها برای یک ویژگی گسسته بسیار زیاد است.
در حال حاضر می توان چندین نتیجه از این مجموعه گرفت. برای مثال، عنصر متوسط یک سری تغییرات (میانگین) می تواند تخمینی از محتمل ترین نتیجه یک اندازه گیری باشد. اولین و آخرین عنصر سری تغییرات (یعنی حداقل و حداکثر عنصر نمونه) پراکندگی عناصر نمونه را نشان می دهد. گاهی اوقات، اگر اولین یا آخرین عنصر بسیار متفاوت از بقیه نمونه باشد، با توجه به اینکه این مقادیر در نتیجه نوعی شکست فاحش، به عنوان مثال، فناوری به دست آمده اند، از نتایج اندازه گیری حذف می شوند.
