कम से कम वर्गों की विधि की अनुमति देता है। रैखिक जोड़ीदार प्रतिगमन विश्लेषण
- ट्यूटोरियल
परिचय
मैं एक कंप्यूटर प्रोग्रामर हूं. मैंने अपने करियर में सबसे बड़ी छलांग तब लगाई जब मैंने कहना सीखा: "मुझे कुछ भी समझ में नहीं आता!"अब मुझे विज्ञान के प्रकाश को यह बताने में कोई शर्म नहीं है कि वह मुझे व्याख्यान दे रहा है, कि मुझे समझ नहीं आ रहा है कि यह प्रकाशमान मुझसे क्या बात कर रहा है। और यह बहुत कठिन है। हाँ, यह स्वीकार करना कठिन और शर्मनाक है कि आप नहीं जानते। कौन यह स्वीकार करना पसंद करता है कि वह किसी चीज़ की मूल बातें नहीं जानता है। अपने पेशे के आधार पर, मुझे बड़ी संख्या में प्रस्तुतियों और व्याख्यानों में भाग लेना पड़ता है, जहाँ, मैं स्वीकार करता हूँ, अधिकांश मामलों में मुझे नींद आती है, क्योंकि मुझे कुछ भी समझ में नहीं आता है। और मुझे समझ नहीं आता क्योंकि विज्ञान की वर्तमान स्थिति की बहुत बड़ी समस्या गणित में निहित है। यह मानता है कि सभी छात्र गणित के बिल्कुल सभी क्षेत्रों से परिचित हैं (जो बेतुका है)। यह स्वीकार करना कि आप नहीं जानते कि डेरिवेटिव क्या है (कि यह थोड़ी देर बाद है) शर्म की बात है।
लेकिन मैंने यह कहना सीख लिया है कि मुझे नहीं पता कि गुणा क्या है। हां, मुझे नहीं पता कि लाई अलजेब्रा के ऊपर सबलजेब्रा क्या होता है। हां, मुझे नहीं पता कि आपको जीवन में क्यों चाहिए द्विघातीय समीकरण. वैसे, अगर आप सुनिश्चित हैं कि आप जानते हैं, तो हमारे पास बात करने के लिए कुछ है! गणित ट्रिक्स की एक श्रृंखला है। गणितज्ञ जनता को भ्रमित करने और डराने की कोशिश करते हैं; जहां कोई भ्रम नहीं है, कोई प्रतिष्ठा नहीं है, कोई अधिकार नहीं है। हां, संभव सबसे अमूर्त भाषा में बोलना प्रतिष्ठित है, जो अपने आप में पूरी बकवास है।
क्या आप जानते हैं कि व्युत्पन्न क्या है? सबसे अधिक संभावना है कि आप मुझे अंतर संबंध की सीमा के बारे में बताएंगे। सेंट पीटर्सबर्ग स्टेट यूनिवर्सिटी में गणित के पहले वर्ष में, विक्टर पेट्रोविच खाविन मी परिभाषितबिंदु पर समारोह के टेलर श्रृंखला की पहली अवधि के गुणांक के रूप में व्युत्पन्न (यह डेरिवेटिव के बिना टेलर श्रृंखला निर्धारित करने के लिए एक अलग जिम्नास्टिक था)। मैं इस परिभाषा पर लंबे समय तक हँसा, जब तक कि मैं अंत में समझ नहीं पाया कि यह किस बारे में है। व्युत्पन्न केवल एक उपाय से ज्यादा कुछ नहीं है कि हम जिस फ़ंक्शन को अलग कर रहे हैं वह फ़ंक्शन y=x, y=x^2, y=x^3 के समान है।
मुझे अब छात्रों को व्याख्यान देने का सम्मान मिला है डरअंक शास्त्र। यदि आप गणित से डरते हैं - हम रास्ते में हैं। जैसे ही आप किसी पाठ को पढ़ने की कोशिश करते हैं और आपको लगता है कि यह बहुत जटिल है, तो जान लें कि यह खराब तरीके से लिखा गया है। मेरा तर्क है कि गणित का एक भी क्षेत्र ऐसा नहीं है जिसके बारे में सटीकता खोए बिना "उंगलियों पर" नहीं बोला जा सकता है।
निकट भविष्य के लिए चुनौती: मैंने अपने छात्रों को यह समझने का निर्देश दिया कि रैखिक-द्विघात नियंत्रक क्या होता है। शरमाओ मत, अपने जीवन के तीन मिनट बर्बाद करो, लिंक का पालन करो। अगर आपको कुछ समझ नहीं आ रहा है तो हम रास्ते में हैं। मुझे (पेशेवर गणितज्ञ-प्रोग्रामर) भी कुछ समझ नहीं आया। और मैं आपको विश्वास दिलाता हूं, इसे "उंगलियों पर" हल किया जा सकता है। फिलहाल मुझे नहीं पता कि यह क्या है, लेकिन मैं आपको विश्वास दिलाता हूं कि हम इसका पता लगाने में सक्षम होंगे।
इसलिए, पहला व्याख्यान जो मैं अपने छात्रों को देने जा रहा हूं, जब वे मेरे पास भागते हुए आते हैं, इस शब्द के साथ कि रैखिक-द्विघात नियंत्रक एक भयानक बग है जिसे आप अपने जीवन में कभी भी मास्टर नहीं करेंगे तरीकों कम से कम वर्गों . क्या आप तय कर सकते हैं? रेखीय समीकरण? यदि आप यह पाठ पढ़ रहे हैं, तो शायद नहीं।
तो, दो बिंदु (x0, y0), (x1, y1), उदाहरण के लिए, (1,1) और (3,2) दिए गए हैं, कार्य इन दो बिंदुओं से गुजरने वाली सीधी रेखा के समीकरण को ढूंढना है:
चित्रण

इस सीधी रेखा में निम्न जैसा समीकरण होना चाहिए:
यहाँ अल्फा और बीटा हमारे लिए अज्ञात हैं, लेकिन इस रेखा के दो बिंदु ज्ञात हैं:
आप इस समीकरण को मैट्रिक्स रूप में लिख सकते हैं:
यहाँ आपको करना चाहिए गीतात्मक विषयांतर: मैट्रिक्स क्या है? एक मैट्रिक्स और कुछ नहीं बल्कि एक द्वि-आयामी सरणी है। यह डाटा को स्टोर करने का एक तरीका है, इसमें और कोई वैल्यू नहीं देनी चाहिए। यह हम पर निर्भर करता है कि किसी निश्चित मैट्रिक्स की ठीक-ठीक व्याख्या कैसे की जाए। समय-समय पर, मैं इसे एक रेखीय मानचित्रण के रूप में, समय-समय पर द्विघात रूप में, और कभी-कभी केवल वैक्टर के एक सेट के रूप में व्याख्या करूँगा। यह सब संदर्भ में स्पष्ट किया जाएगा।
आइए विशिष्ट मैट्रिसेस को उनके प्रतीकात्मक प्रतिनिधित्व से बदलें:
तब (अल्फा, बीटा) आसानी से पाया जा सकता है:
अधिक विशेष रूप से हमारे पिछले डेटा के लिए:
जो बिंदुओं (1,1) और (3,2) से गुजरने वाली सीधी रेखा के निम्नलिखित समीकरण की ओर ले जाता है:
ठीक है, यहाँ सब कुछ स्पष्ट है। और एक सीधी रेखा का समीकरण ज्ञात करते हैं जिससे होकर गुजरती है तीनअंक: (x0,y0), (x1,y1) और (x2,y2):
ओह-ओह-ओह, लेकिन हमारे पास दो अज्ञात के लिए तीन समीकरण हैं! मानक गणितज्ञ कहेंगे कि कोई हल नहीं है। प्रोग्रामर क्या कहेगा? और वह पहले समीकरणों की पिछली प्रणाली को निम्नलिखित रूप में फिर से लिखेंगे:
हमारे मामले में वैक्टर मैं, जे, बीत्रि-आयामी, इसलिए, (में सामान्य मामला) इस प्रणाली का कोई समाधान नहीं है। कोई भी सदिश (alpha\*i + beta\*j) सदिशों (i, j) द्वारा फैलाए गए समतल में स्थित है। यदि b इस तल से संबंधित नहीं है, तो कोई हल नहीं है (समीकरण में समानता प्राप्त नहीं की जा सकती)। क्या करें? आइए एक समझौता देखें। द्वारा निरूपित करते हैं ई (अल्फा, बीटा)कैसे वास्तव में हमने समानता हासिल नहीं की:
और हम इस त्रुटि को कम करने का प्रयास करेंगे:
चौक क्यों?
हम न केवल मानदंड के न्यूनतम के लिए देख रहे हैं, बल्कि मानक के न्यूनतम वर्ग के लिए भी देख रहे हैं। क्यों? न्यूनतम बिंदु स्वयं मेल खाता है, और वर्ग एक सहज कार्य (तर्कों का एक द्विघात कार्य (अल्फा, बीटा)) देता है, जबकि केवल लंबाई एक शंकु के रूप में एक कार्य देती है, जो न्यूनतम बिंदु पर गैर-विभेदी है। ब्र. वर्ग अधिक सुविधाजनक है।
जाहिर है, वेक्टर होने पर त्रुटि कम हो जाती है इवैक्टर द्वारा फैलाए गए विमान के लिए ऑर्थोगोनल मैंतथा जे.
चित्रण

दूसरे शब्दों में: हम एक ऐसी रेखा की तलाश कर रहे हैं, जिसमें इस रेखा के सभी बिंदुओं से दूरियों की वर्ग लंबाई का योग न्यूनतम हो:
अद्यतन: यहां मेरे पास एक जंब है, लाइन की दूरी लंबवत रूप से मापी जानी चाहिए, न कि ऑर्थोग्राफ़िक प्रोजेक्शन। टिप्पणीकार सही है।
चित्रण

पूरी तरह से अलग शब्दों में (सावधानीपूर्वक, खराब औपचारिक रूप से, लेकिन यह उंगलियों पर स्पष्ट होना चाहिए): हम सभी बिंदुओं के बीच सभी संभव रेखाएं लेते हैं और सभी के बीच औसत रेखा की तलाश करते हैं:
चित्रण

उंगलियों पर एक और स्पष्टीकरण: हम सभी डेटा बिंदुओं (यहां हमारे पास तीन हैं) और जिस रेखा की हम तलाश कर रहे हैं, और संतुलन की स्थिति की रेखा के बीच एक वसंत संलग्न करते हैं, वही है जो हम खोज रहे हैं।
द्विघात रूप न्यूनतम
तो, वेक्टर दिया बीऔर मैट्रिक्स के कॉलम-वैक्टर द्वारा फैला हुआ विमान ए(इस मामले में (x0,x1,x2) और (1,1,1)), हम एक वेक्टर की तलाश कर रहे हैं इन्यूनतम वर्ग लंबाई के साथ। जाहिर है, न्यूनतम केवल वेक्टर के लिए ही प्राप्त किया जा सकता है इ, मैट्रिक्स के कॉलम-वैक्टर द्वारा फैलाए गए विमान के लिए ऑर्थोगोनल ए:दूसरे शब्दों में, हम एक सदिश x=(alpha, beta) की तलाश कर रहे हैं जैसे कि:
मैं आपको याद दिलाता हूं कि यह सदिश x=(alpha, beta) न्यूनतम है द्विघात फंक्शन||ई(अल्फा, बीटा)||^2:
यहां यह याद रखना उपयोगी है कि मैट्रिक्स की व्याख्या द्विघात रूप के साथ-साथ की जा सकती है, उदाहरण के लिए, पहचान मैट्रिक्स ((1,0),(0,1)) की व्याख्या x^2 + y के एक फ़ंक्शन के रूप में की जा सकती है ^2:
द्विघात रूप

यह सब जिम्नास्टिक रैखिक प्रतिगमन के रूप में जाना जाता है।
डिरिचलेट सीमा शर्त के साथ लाप्लास समीकरण
अब सबसे सरल वास्तविक समस्या: एक निश्चित त्रिकोणीय सतह है, इसे चिकना करना आवश्यक है। उदाहरण के लिए, मेरे चेहरे का मॉडल लोड करें:
मूल प्रतिबद्धता उपलब्ध है। बाहरी निर्भरता को कम करने के लिए, मैंने अपने सॉफ़्टवेयर रेंडरर का कोड लिया, जो पहले से ही हैबे पर था। समाधान के लिए रैखिक प्रणालीमैं ओपनएनएल का उपयोग करता हूं, यह एक महान सॉल्वर है, लेकिन इसे स्थापित करना वास्तव में कठिन है: आपको अपने प्रोजेक्ट फ़ोल्डर में दो फाइलों (.h+.c) की प्रतिलिपि बनाने की आवश्यकता है। सभी चौरसाई निम्नलिखित कोड द्वारा किया जाता है:
के लिए (इंट डी = 0; डी<3; d++) {
nlNewContext();
nlSolverParameteri(NL_NB_VARIABLES, verts.size());
nlSolverParameteri(NL_LEAST_SQUARES, NL_TRUE);
nlBegin(NL_SYSTEM);
nlBegin(NL_MATRIX);
for (int i=0; i<(int)verts.size(); i++) {
nlBegin(NL_ROW);
nlCoefficient(i, 1);
nlRightHandSide(verts[i][d]);
nlEnd(NL_ROW);
}
for (unsigned int i=0; i
X, Y और Z निर्देशांक वियोज्य हैं, मैं उन्हें अलग से चिकना करता हूं। यही है, मैं रैखिक समीकरणों की तीन प्रणालियों को हल करता हूं, जिनमें से प्रत्येक में मेरे मॉडल में वर्टिकल की संख्या के समान चर हैं। मैट्रिक्स ए की पहली एन पंक्तियों में प्रति पंक्ति केवल एक 1 है, और वेक्टर बी की पहली एन पंक्तियों में मूल मॉडल निर्देशांक हैं। यही है, मैं नई शीर्ष स्थिति और पुरानी शीर्ष स्थिति के बीच स्प्रिंग-टाई करता हूं - नए को पुराने से बहुत दूर नहीं होना चाहिए।
मैट्रिक्स A की सभी बाद की पंक्तियों (faces.size()*3 = ग्रिड में सभी त्रिकोणों के किनारों की संख्या) में 1 की एक घटना और -1 की एक घटना होती है, जबकि वेक्टर b में शून्य घटक विपरीत होते हैं। इसका मतलब है कि मैंने हमारे त्रिकोणीय जाल के प्रत्येक किनारे पर एक स्प्रिंग लगाया है: सभी किनारे अपने शुरुआती और अंत बिंदु के समान शीर्ष प्राप्त करने का प्रयास करते हैं।
एक बार फिर: सभी शीर्ष चर हैं, और वे अपनी मूल स्थिति से दूर विचलित नहीं हो सकते, लेकिन साथ ही वे एक दूसरे के समान बनने का प्रयास करते हैं।
यहाँ परिणाम है:

सब कुछ ठीक हो जाएगा, मॉडल वास्तव में चिकना है, लेकिन यह अपने मूल किनारे से दूर चला गया। आइए कोड को थोड़ा बदलें:
के लिए (int मैं = 0; मैं<(int)verts.size(); i++) { float scale = border[i] ? 1000: 1; nlBegin(NL_ROW); nlCoefficient(i, scale); nlRightHandSide(scale*verts[i][d]); nlEnd(NL_ROW); }
हमारे मैट्रिक्स ए में, किनारे पर मौजूद शीर्षों के लिए, मैं श्रेणी v_i = verts[i][d] से कोई पंक्ति नहीं जोड़ता, लेकिन 1000*v_i = 1000*verts[i][d]। यह क्या बदलता है? और यह त्रुटि के हमारे द्विघात रूप को बदल देता है। अब किनारे पर ऊपर से एक भी विचलन पहले की तरह एक इकाई नहीं, बल्कि 1000 * 1000 इकाइयों का खर्च आएगा। यही है, हमने चरम शिखर पर एक मजबूत वसंत लटका दिया, समाधान दूसरों को अधिक मजबूती से फैलाना पसंद करता है। यहाँ परिणाम है:

आइए शीर्षों के बीच के झरनों की शक्ति को दोगुना करें:
एनएल गुणांक (चेहरा [जे], 2); एनएल गुणांक (चेहरा [(जे + 1)% 3], -2);
यह तार्किक है कि सतह चिकनी हो गई है:

और अब सौ गुना ज्यादा मजबूत:

यह क्या है? कल्पना कीजिए कि हमने तार के छल्ले को साबुन के पानी में डुबाया है। नतीजतन, परिणामी साबुन फिल्म कम से कम वक्रता रखने की कोशिश करेगी, उसी सीमा को छूती है - हमारे तार की अंगूठी। सीमा तय करने और अंदर चिकनी सतह मांगने से हमें यही मिला। बधाई हो, हमने डिरिचलेट सीमा स्थितियों के साथ लाप्लास समीकरण को अभी हल किया है। ठीक लगता है? लेकिन वास्तव में, हल करने के लिए रैखिक समीकरणों की सिर्फ एक प्रणाली।
पोइसन समीकरण
चलो एक और अच्छा नाम है।मान लें कि मेरे पास ऐसी छवि है:

सब अच्छे हैं, पर मुझे कुर्सी अच्छी नहीं लगती।
मैंने चित्र को आधा काट दिया: 

और मैं अपने हाथों से एक कुर्सी उठाऊंगा: 
फिर मैं तस्वीर के बाईं ओर मुखौटा में सफेद सब कुछ खींचूंगा, और साथ ही मैं पूरी तस्वीर में कहूंगा कि दो पड़ोसी पिक्सेल के बीच का अंतर दो पड़ोसी पिक्सेल के बीच के अंतर के बराबर होना चाहिए सही छवि:
के लिए (int मैं = 0; मैं यहाँ परिणाम है: कोड और चित्र उपलब्ध हैं प्रयोगात्मक डेटा का अनुमान एक विश्लेषणात्मक फ़ंक्शन के साथ प्रयोगात्मक रूप से प्राप्त डेटा के प्रतिस्थापन के आधार पर एक विधि है जो प्रारंभिक मानों (प्रयोग या प्रयोग के दौरान प्राप्त डेटा) के साथ नोडल बिंदुओं पर सबसे निकट से गुजरता है या मेल खाता है। विश्लेषणात्मक कार्य को परिभाषित करने के वर्तमान में दो तरीके हैं: एक एन-डिग्री प्रक्षेप बहुपद का निर्माण करके जो गुजरता है सीधे सभी बिंदुओं के माध्यम सेडेटा की दी गई सरणी। इस मामले में, सन्निकट फलन को इस प्रकार दर्शाया जाता है: लैग्रेंज रूप में एक प्रक्षेप बहुपद या न्यूटन रूप में एक प्रक्षेप बहुपद। पास होने वाले एन-डिग्री अनुमानित बहुपद का निर्माण करके बिंदुओं के करीबदिए गए डेटा सरणी से। इस प्रकार, सन्निकटन कार्य प्रयोग के दौरान होने वाले सभी यादृच्छिक शोर (या त्रुटियों) को सुचारू करता है: प्रयोग के दौरान मापा गया मान यादृच्छिक कारकों पर निर्भर करता है जो अपने स्वयं के यादृच्छिक कानूनों (माप या उपकरण त्रुटियों, अशुद्धि या प्रयोगात्मक) के अनुसार उतार-चढ़ाव करते हैं। त्रुटियां)। इस स्थिति में, सन्निकट फलन न्यूनतम वर्ग विधि द्वारा निर्धारित किया जाता है। कम से कम वर्ग विधि(अंग्रेजी साहित्य में ऑर्डिनरी लीस्ट स्क्वेयर, ओएलएस) एक गणितीय विधि है जो अनुमानित फलन की परिभाषा पर आधारित है, जो प्रयोगात्मक डेटा के दिए गए सरणी से बिंदुओं के निकटतम निकटता में बनाया गया है। प्रारंभिक और अनुमानित कार्यों की निकटता एफ (एक्स) एक संख्यात्मक माप द्वारा निर्धारित की जाती है, अर्थात्: अनुमानित वक्र एफ (एक्स) से प्रयोगात्मक डेटा के वर्ग विचलन का योग सबसे छोटा होना चाहिए। न्यूनतम वर्ग विधि द्वारा निर्मित फिटिंग कर्व सबसे कम वर्ग विधि का उपयोग किया जाता है: समीकरणों की अतिनिर्धारित प्रणालियों को हल करने के लिए जब समीकरणों की संख्या अज्ञात की संख्या से अधिक हो जाती है; समीकरणों के साधारण (अतिनिर्धारित नहीं) अरेखीय प्रणालियों के मामले में समाधान खोजने के लिए; कुछ अनुमानित फ़ंक्शन द्वारा अनुमानित बिंदु मानों के लिए। कम से कम वर्ग विधि द्वारा सन्निकट फलन प्रायोगिक डेटा के दिए गए सरणी से परिकलित सन्निकट फलन के वर्ग विचलन के न्यूनतम योग की स्थिति से निर्धारित होता है। न्यूनतम वर्ग विधि का यह मानदंड निम्नलिखित व्यंजक के रूप में लिखा गया है: नोडल बिंदुओं पर परिकलित सन्निकटन फ़ंक्शन का मान , नोडल बिंदुओं पर प्रयोगात्मक डेटा की निर्दिष्ट सरणी। द्विघात मानदंड में कई "अच्छे" गुण होते हैं, जैसे कि भिन्नता, बहुपद सन्निकटन कार्यों के साथ सन्निकटन समस्या का एक अनूठा समाधान प्रदान करता है। समस्या की स्थितियों के आधार पर, सन्निकटन फलन डिग्री m का एक बहुपद है अनुमानित फ़ंक्शन की डिग्री नोडल बिंदुओं की संख्या पर निर्भर नहीं करती है, लेकिन इसका आयाम हमेशा प्रायोगिक डेटा के दिए गए सरणी के आयाम (अंकों की संख्या) से कम होना चाहिए। ∙ यदि अनुमानित फ़ंक्शन की डिग्री एम = 1 है, तो हम टेबल फ़ंक्शन को सीधी रेखा (रैखिक प्रतिगमन) के साथ अनुमानित करते हैं। ∙ यदि सन्निकट फलन की डिग्री m=2 है, तो हम द्विघात परवलय (द्विघात सन्निकटन) के साथ तालिका फलन का सन्निकटन करते हैं। ∙ यदि सन्निकट फलन की डिग्री m=3 है, तो हम घन परवलय (घन सन्निकटन) के साथ तालिका फलन का सन्निकटन करते हैं। सामान्य स्थिति में, जब दिए गए सारणीबद्ध मानों के लिए डिग्री एम के अनुमानित बहुपद का निर्माण करना आवश्यक होता है, तो सभी नोडल बिंदुओं पर न्यूनतम विचलन के न्यूनतम योग की स्थिति को निम्नलिखित रूप में फिर से लिखा जाता है: निर्दिष्ट तालिका मानों की संख्या। एक न्यूनतम फ़ंक्शन के अस्तित्व के लिए एक आवश्यक शर्त अज्ञात चर के संबंध में इसके आंशिक डेरिवेटिव के शून्य की समानता है आइए समीकरणों की परिणामी रैखिक प्रणाली को रूपांतरित करें: कोष्ठक खोलें और मुक्त पदों को अभिव्यक्ति के दाईं ओर ले जाएं। परिणामस्वरूप, रैखिक बीजगणितीय व्यंजकों की परिणामी प्रणाली निम्नलिखित रूप में लिखी जाएगी: रैखिक बीजगणितीय व्यंजकों की इस प्रणाली को आव्यूह के रूप में फिर से लिखा जा सकता है: परिणामस्वरूप, आयाम m + 1 के रैखिक समीकरणों की एक प्रणाली प्राप्त हुई, जिसमें m + 1 अज्ञात शामिल हैं। रैखिक बीजगणितीय समीकरणों (उदाहरण के लिए, गॉस विधि) को हल करने के लिए किसी भी विधि का उपयोग करके इस प्रणाली को हल किया जा सकता है। समाधान के परिणामस्वरूप, अनुमानित फ़ंक्शन के अज्ञात पैरामीटर पाए जाएंगे जो मूल डेटा से अनुमानित फ़ंक्शन के चुकता विचलन का न्यूनतम योग प्रदान करते हैं, अर्थात सर्वोत्तम संभव द्विघात सन्निकटन। यह याद रखना चाहिए कि यदि प्रारंभिक डेटा का एक भी मान बदलता है, तो सभी गुणांक अपने मूल्यों को बदल देंगे, क्योंकि वे पूरी तरह से प्रारंभिक डेटा द्वारा निर्धारित होते हैं। रैखिक निर्भरता द्वारा प्रारंभिक डेटा का अनुमान (रेखीय प्रतिगमन) एक उदाहरण के रूप में, सन्निकट फलन के निर्धारण की विधि पर विचार करें, जो एक रैखिक संबंध के रूप में दी गई है। कम से कम वर्ग विधि के अनुसार, विचलन के न्यूनतम योग के लिए शर्त को इस प्रकार लिखा जाता है: तालिका के नोडल बिंदुओं के निर्देशांक; सन्निकट फलन के अज्ञात गुणांक, जो एक रैखिक संबंध के रूप में दिए गए हैं। एक न्यूनतम फ़ंक्शन के अस्तित्व के लिए एक आवश्यक शर्त अज्ञात चर के संबंध में इसके आंशिक डेरिवेटिव के शून्य की समानता है। परिणामस्वरूप, हम समीकरणों की निम्नलिखित प्रणाली प्राप्त करते हैं: आइए समीकरणों की परिणामी रेखीय प्रणाली को रूपांतरित करें। हम रैखिक समीकरणों की परिणामी प्रणाली को हल करते हैं। विश्लेषणात्मक रूप में अनुमानित कार्य के गुणांक निम्नानुसार निर्धारित किए जाते हैं (क्रैमर की विधि): ये गुणांक दिए गए सारणीबद्ध मानों (प्रायोगिक डेटा) से अनुमानित फ़ंक्शन के वर्गों के योग को कम करने के मानदंड के अनुसार एक रैखिक सन्निकटन फ़ंक्शन का निर्माण प्रदान करते हैं। कम से कम वर्गों की विधि को लागू करने के लिए एल्गोरिथम 1. प्रारंभिक डेटा: मापन एन की संख्या के साथ प्रयोगात्मक डेटा की एक सरणी को देखते हुए अनुमानित बहुपद (एम) की डिग्री दी गई है 2. गणना एल्गोरिथ्म: 2.1। आयाम के साथ समीकरणों की एक प्रणाली के निर्माण के लिए गुणांक निर्धारित किए जाते हैं समीकरणों की प्रणाली के गुणांक (समीकरण के बाईं ओर) रैखिक समीकरणों की प्रणाली के मुक्त सदस्य (समीकरण के दाईं ओर) 2.2। आयाम के साथ रैखिक समीकरणों की एक प्रणाली का गठन। 2.3। डिग्री एम के अनुमानित बहुपद के अज्ञात गुणांक निर्धारित करने के लिए रैखिक समीकरणों की एक प्रणाली का समाधान। 2.4 सभी नोडल बिंदुओं पर प्रारंभिक मूल्यों से अनुमानित बहुपद के वर्ग विचलन के योग का निर्धारण वर्गित विचलनों के योग का पाया गया मान न्यूनतम संभव है। अन्य कार्यों के साथ सन्निकटन यह ध्यान दिया जाना चाहिए कि कम से कम वर्ग विधि के अनुसार प्रारंभिक डेटा का अनुमान लगाते समय, लॉगरिदमिक फ़ंक्शन, एक्सपोनेंशियल फ़ंक्शन और पावर फ़ंक्शन को कभी-कभी अनुमानित फ़ंक्शन के रूप में उपयोग किया जाता है। लॉग सन्निकटन मामले पर विचार करें जब सन्निकटन फ़ंक्शन फॉर्म के लॉगरिदमिक फ़ंक्शन द्वारा दिया जाता है: इसके कई अनुप्रयोग हैं, क्योंकि यह अन्य सरल कार्यों द्वारा दिए गए फ़ंक्शन के अनुमानित प्रतिनिधित्व की अनुमति देता है। एलएसएम अवलोकनों को संसाधित करने में बेहद उपयोगी हो सकता है, और यह यादृच्छिक त्रुटियों वाले अन्य के मापन के परिणामों से कुछ मात्राओं का अनुमान लगाने के लिए सक्रिय रूप से उपयोग किया जाता है। इस लेख में, आप सीखेंगे कि एक्सेल में कम से कम वर्गों की गणना कैसे करें। मान लीजिए कि दो संकेतक X और Y हैं। इसके अलावा, Y X पर निर्भर करता है। चूंकि प्रतिगमन विश्लेषण के दृष्टिकोण से OLS हमारे लिए रुचि रखता है (एक्सेल में, इसके तरीकों को अंतर्निहित कार्यों का उपयोग करके लागू किया जाता है), हमें तुरंत आगे बढ़ना चाहिए एक विशिष्ट समस्या पर विचार करने के लिए। तो, X को एक किराने की दुकान का विक्रय क्षेत्र होने दें, जिसे वर्ग मीटर में मापा जाता है, और Y वार्षिक कारोबार हो, जिसे लाखों रूबल में परिभाषित किया गया हो। यह अनुमान लगाना आवश्यक है कि स्टोर में एक या दूसरे रिटेल स्पेस होने पर टर्नओवर (Y) क्या होगा। जाहिर है, फ़ंक्शन वाई = एफ (एक्स) बढ़ रहा है, क्योंकि हायपरमार्केट स्टॉल से ज्यादा सामान बेचता है। मान लें कि हमारे पास एन स्टोर्स के डेटा के साथ एक टेबल बनाया गया है। गणितीय आँकड़ों के अनुसार, यदि कम से कम 5-6 वस्तुओं के डेटा की जाँच की जाए तो परिणाम कमोबेश सही होंगे। साथ ही, "विषम" परिणामों का उपयोग नहीं किया जा सकता है। विशेष रूप से, एक संभ्रांत छोटे बुटीक का टर्नओवर "मास्मार्केट" वर्ग के बड़े आउटलेट्स के टर्नओवर से कई गुना अधिक हो सकता है। तालिका डेटा को कार्तीय तल पर बिंदु M 1 (x 1, y 1), ... M n (x n, y n) के रूप में प्रदर्शित किया जा सकता है। अब समस्या का समाधान एक अनुमानित फ़ंक्शन y = f (x) के चयन के लिए कम हो जाएगा, जिसका एक ग्राफ जितना संभव हो सके बिंदु M 1, M 2, .. M n के पास से गुजरता है। बेशक, आप एक उच्च डिग्री बहुपद का उपयोग कर सकते हैं, लेकिन यह विकल्प न केवल लागू करना मुश्किल है, बल्कि गलत भी है, क्योंकि यह उस मुख्य प्रवृत्ति को प्रतिबिंबित नहीं करेगा जिसका पता लगाने की आवश्यकता है। सबसे उचित समाधान एक सीधी रेखा y = ax + b की खोज करना है, जो प्रायोगिक डेटा का सबसे अच्छा अनुमान लगाता है, और अधिक सटीक रूप से, गुणांक - a और b। किसी भी अनुमान के लिए, इसकी सटीकता का आकलन विशेष महत्व रखता है। बिंदु x i के लिए कार्यात्मक और प्रायोगिक मानों के बीच e i अंतर (विचलन) को निरूपित करें, अर्थात e i = y i - f (x i)। जाहिर है, सन्निकटन की सटीकता का आकलन करने के लिए, आप विचलन के योग का उपयोग कर सकते हैं, अर्थात, Y पर X की निर्भरता के अनुमानित प्रतिनिधित्व के लिए एक सीधी रेखा का चयन करते समय, वरीयता उसी को दी जानी चाहिए जिसका सबसे छोटा मूल्य हो योग ई मैं विचाराधीन सभी बिंदुओं पर। हालांकि, सब कुछ इतना सरल नहीं है, क्योंकि सकारात्मक विचलन के साथ-साथ व्यावहारिक रूप से नकारात्मक भी होंगे। आप विचलन मॉड्यूल या उनके वर्गों का उपयोग करके समस्या का समाधान कर सकते हैं। बाद की विधि सबसे व्यापक रूप से उपयोग की जाती है। इसका उपयोग कई क्षेत्रों में किया जाता है, जिसमें प्रतिगमन विश्लेषण भी शामिल है (एक्सेल में, इसका कार्यान्वयन दो अंतर्निहित कार्यों का उपयोग करके किया जाता है), और यह लंबे समय से प्रभावी साबित हुआ है। एक्सेल में, जैसा कि आप जानते हैं, एक अंतर्निहित ऑटोसम फ़ंक्शन है जो आपको चयनित सीमा में स्थित सभी मानों के मूल्यों की गणना करने की अनुमति देता है। इस प्रकार, कुछ भी हमें अभिव्यक्ति के मूल्य की गणना करने से नहीं रोकेगा (ई 1 2 + ई 2 2 + ई 3 2 + ... ई एन 2)। गणितीय संकेतन में, ऐसा दिखता है: चूंकि निर्णय शुरू में एक सीधी रेखा का उपयोग करके अनुमानित किया गया था, हमारे पास: इस प्रकार, एक सीधी रेखा खोजने का कार्य जो एक्स और वाई के बीच एक विशिष्ट संबंध का सबसे अच्छा वर्णन करता है, दो चर के न्यूनतम फ़ंक्शन की गणना करने के लिए: इसके लिए नए चर ए और बी के संबंध में शून्य आंशिक डेरिवेटिव के बराबर होने की आवश्यकता है, और फॉर्म के 2 अज्ञात के साथ दो समीकरणों वाली एक प्रारंभिक प्रणाली को हल करना: सरल परिवर्तनों के बाद, 2 से विभाजित करने और योगों में हेरफेर करने सहित, हम प्राप्त करते हैं: इसे हल करते हुए, उदाहरण के लिए, क्रैमर की विधि द्वारा, हम निश्चित गुणांक a * और b * के साथ एक स्थिर बिंदु प्राप्त करते हैं। यह न्यूनतम है, यानी यह अनुमान लगाने के लिए कि एक निश्चित क्षेत्र के लिए स्टोर का टर्नओवर क्या होगा, सीधी रेखा y = a * x + b * उपयुक्त है, जो प्रश्न में उदाहरण के लिए एक प्रतिगमन मॉडल है। बेशक, यह आपको सटीक परिणाम खोजने की अनुमति नहीं देगा, लेकिन इससे आपको यह अंदाजा लगाने में मदद मिलेगी कि क्या किसी विशेष क्षेत्र के लिए क्रेडिट पर स्टोर खरीदना बंद हो जाएगा। एक्सेल में कम से कम वर्गों के मान की गणना के लिए एक फ़ंक्शन है। इसका निम्न रूप है: TREND (ज्ञात Y मान; ज्ञात X मान; नए X मान; स्थिर)। आइए एक्सेल में ओएलएस की गणना के लिए सूत्र को हमारी तालिका में लागू करें। ऐसा करने के लिए, उस सेल में जिसमें एक्सेल में कम से कम वर्ग विधि का उपयोग करके गणना का परिणाम प्रदर्शित किया जाना चाहिए, "=" चिन्ह दर्ज करें और "ट्रेंड" फ़ंक्शन का चयन करें। खुलने वाली विंडो में, हाइलाइट करते हुए उपयुक्त फ़ील्ड भरें: इसके अलावा, सूत्र में एक तार्किक चर "कॉन्स्ट" है। यदि आप इसके अनुरूप क्षेत्र में 1 दर्ज करते हैं, तो इसका मतलब यह होगा कि बी \u003d 0 मानकर गणना की जानी चाहिए। यदि आपको एक से अधिक x मान के लिए पूर्वानुमान जानने की आवश्यकता है, तो सूत्र दर्ज करने के बाद, आपको "एंटर" नहीं दबाना चाहिए, लेकिन आपको संयोजन "Shift" + "Control" + "Enter" ("Enter") टाइप करना होगा ) कीबोर्ड पर। प्रतिगमन विश्लेषण डमी के लिए भी सुलभ हो सकता है। अज्ञात चरों की एक सरणी के मान की भविष्यवाणी करने के लिए एक्सेल फॉर्मूला - "ट्रेंड" - का उपयोग उन लोगों द्वारा भी किया जा सकता है जिन्होंने कभी कम से कम वर्ग विधि के बारे में नहीं सुना है। इसके काम की कुछ विशेषताओं को जानना ही काफी है। विशेष रूप से: यह कई कार्यों का उपयोग करके कार्यान्वित किया जाता है। उनमें से एक को "भविष्यवाणी" कहा जाता है। यह TREND के समान है, अर्थात यह कम से कम वर्ग विधि का उपयोग करके गणना का परिणाम देता है। हालाँकि, केवल एक X के लिए, जिसके लिए Y का मान अज्ञात है। अब आप डमी के लिए एक्सेल फ़ार्मुलों को जानते हैं जो आपको एक रेखीय प्रवृत्ति के अनुसार एक संकेतक के भविष्य के मूल्य के मूल्य की भविष्यवाणी करने की अनुमति देता है। जो विज्ञान और अभ्यास के विभिन्न क्षेत्रों में सबसे व्यापक अनुप्रयोग पाता है। यह भौतिकी, रसायन विज्ञान, जीव विज्ञान, अर्थशास्त्र, समाजशास्त्र, मनोविज्ञान आदि हो सकता है। भाग्य की इच्छा से, मुझे अक्सर अर्थव्यवस्था से निपटना पड़ता है, और इसलिए आज मैं आपके लिए एक अद्भुत देश नामक टिकट की व्यवस्था करूंगा अर्थमिति=) … आप ऐसा कैसे नहीं चाहते हैं ?! यह वहां बहुत अच्छा है - आपको बस फैसला करना है! …लेकिन आप निश्चित रूप से यह सीखना चाहते हैं कि समस्याओं को कैसे हल किया जाए कम से कम वर्गों. और विशेष रूप से मेहनती पाठक उन्हें न केवल सटीक रूप से, बल्कि बहुत तेजी से हल करना सीखेंगे ;-) लेकिन पहले समस्या का सामान्य कथन+ संबंधित उदाहरण: कुछ विषय क्षेत्र में संकेतकों का अध्ययन किया जाए जिनकी मात्रात्मक अभिव्यक्ति है। इसी समय, यह मानने का हर कारण है कि सूचक संकेतक पर निर्भर करता है। यह धारणा वैज्ञानिक परिकल्पना और प्राथमिक सामान्य ज्ञान पर आधारित दोनों हो सकती है। हालांकि, विज्ञान को एक तरफ छोड़ दें, और अधिक स्वादिष्ट क्षेत्रों का पता लगाएं - अर्थात्, किराना स्टोर। द्वारा निरूपित करें: – किराने की दुकान का खुदरा स्थान, वर्गमीटर, यह बिल्कुल स्पष्ट है कि स्टोर का क्षेत्रफल जितना बड़ा होगा, ज्यादातर मामलों में उसका कारोबार उतना ही अधिक होगा। मान लीजिए कि अवलोकन / प्रयोग / गणना / एक नखरे के साथ नृत्य करने के बाद, हमारे पास संख्यात्मक डेटा है: सारणीबद्ध डेटा को बिंदुओं के रूप में भी लिखा जा सकता है और हमारे लिए सामान्य तरीके से दर्शाया जा सकता है। कार्तीय प्रणाली . आइए एक महत्वपूर्ण प्रश्न का उत्तर दें: गुणात्मक अध्ययन के लिए कितने अंक आवश्यक हैं? जितना बड़ा उतना अच्छा। न्यूनतम स्वीकार्य सेट में 5-6 अंक होते हैं। इसके अलावा, डेटा की थोड़ी मात्रा के साथ, नमूने में "असामान्य" परिणाम शामिल नहीं किए जाने चाहिए। इसलिए, उदाहरण के लिए, एक छोटा संभ्रांत स्टोर "उनके सहयोगियों" से अधिक परिमाण के आदेशों में मदद कर सकता है, जिससे सामान्य पैटर्न को विकृत किया जा सकता है जिसे खोजने की आवश्यकता है! यदि यह काफी सरल है, तो हमें एक फ़ंक्शन चुनने की आवश्यकता है, अनुसूचीजो जितना संभव हो बिंदुओं के करीब से गुजरता है इस प्रकार, वांछित कार्य पर्याप्त रूप से सरल होना चाहिए और साथ ही निर्भरता को पर्याप्त रूप से प्रतिबिंबित करना चाहिए। जैसा कि आप अनुमान लगा सकते हैं, ऐसे कार्यों को खोजने के तरीकों में से एक को कहा जाता है कम से कम वर्गों. पहले, आइए इसके सार का सामान्य तरीके से विश्लेषण करें। कुछ फ़ंक्शन को प्रायोगिक डेटा का अनुमान लगाने दें: विभिन्न कार्यों के साथ प्रायोगिक बिंदुओं का अनुमान लगाकर, हम के विभिन्न मान प्राप्त करेंगे, और यह स्पष्ट है कि जहां यह योग छोटा है, वह कार्य अधिक सटीक है। ऐसी विधि मौजूद है और इसे कहा जाता है कम से कम मापांक विधि. हालाँकि, व्यवहार में यह बहुत अधिक व्यापक हो गया है। न्यूनतम वर्ग विधि, जिसमें संभावित नकारात्मक मूल्यों को मापांक से नहीं, बल्कि विचलन को चुकता करके समाप्त किया जाता है: और अब हम दूसरे महत्वपूर्ण बिंदु पर लौटते हैं: जैसा कि ऊपर उल्लेख किया गया है, चयनित फ़ंक्शन काफी सरल होना चाहिए - लेकिन ऐसे कई कार्य भी हैं: रैखिक
, अतिपरवलिक, घातीय, लघुगणक, द्विघात
आदि। और, ज़ाहिर है, यहाँ मैं तुरंत "गतिविधि के क्षेत्र को कम करना" चाहूंगा। अनुसंधान के लिए किस श्रेणी के कार्यों का चयन करना है? आदिम लेकिन प्रभावी तकनीक: - अंक निकालने का सबसे आसान तरीका यदि बिंदु स्थित हैं, उदाहरण के लिए, साथ अतिशयोक्ति, तो यह स्पष्ट है कि रैखिक कार्य एक खराब सन्निकटन देगा। इस मामले में, हम हाइपरबोला समीकरण के लिए सबसे "अनुकूल" गुणांकों की तलाश कर रहे हैं अब गौर कीजिए कि दोनों ही मामलों में हम बात कर रहे हैं दो चर के कार्य, जिनके तर्क हैं खोजे गए निर्भरता विकल्प: और संक्षेप में, हमें एक मानक समस्या को हल करने की आवश्यकता है - खोजने के लिए न्यूनतम दो चर का एक समारोह. हमारे उदाहरण को याद करें: मान लीजिए कि "दुकान" बिंदु एक सीधी रेखा में स्थित हैं और उपस्थिति पर विश्वास करने का हर कारण है रैखिक निर्भरताव्यापार क्षेत्र से कारोबार। आइए एसयूसीएच गुणांक "ए" और "बी" खोजें ताकि चुकता विचलन का योग हो यदि आप इस जानकारी का उपयोग निबंध या टर्म पेपर के लिए करना चाहते हैं, तो मैं स्रोतों की सूची में लिंक के लिए बहुत आभारी रहूंगा, आपको ऐसी विस्तृत गणना कहीं नहीं मिलेगी: आइए एक मानक प्रणाली बनाएं: हम प्रत्येक समीकरण को एक "दो" से कम करते हैं और इसके अलावा, योगों को "अलग" करते हैं: टिप्पणी
: स्वतंत्र रूप से विश्लेषण करें कि क्यों "ए" और "बी" को योग आइकन से बाहर किया जा सकता है। वैसे, औपचारिक रूप से यह योग के साथ किया जा सकता है आइए सिस्टम को "लागू" रूप में फिर से लिखें: क्या हम बिंदुओं के निर्देशांक जानते हैं? हम जानते है। रकम समारोह विचाराधीन समस्या का बड़ा व्यावहारिक महत्व है। हमारे उदाहरण के साथ स्थिति में, समीकरण मैं "वास्तविक" संख्याओं के साथ सिर्फ एक समस्या का विश्लेषण करूंगा, क्योंकि इसमें कोई कठिनाई नहीं है - सभी गणनाएं ग्रेड 7-8 में स्कूल के पाठ्यक्रम के स्तर पर हैं। 95 प्रतिशत मामलों में, आपको केवल एक रैखिक कार्य खोजने के लिए कहा जाएगा, लेकिन लेख के अंत में मैं दिखाऊंगा कि इष्टतम हाइपरबोला, एक्सपोनेंट और कुछ अन्य कार्यों के लिए समीकरणों को ढूंढना अब मुश्किल नहीं है। वास्तव में, यह वादा किए गए उपहारों को वितरित करने के लिए बना हुआ है - ताकि आप सीखें कि ऐसे उदाहरणों को न केवल सटीक रूप से, बल्कि जल्दी से कैसे हल किया जाए। हम ध्यान से मानक का अध्ययन करते हैं: एक कार्य दो संकेतकों के बीच संबंध का अध्ययन करने के परिणामस्वरूप, संख्याओं के निम्नलिखित जोड़े प्राप्त हुए: ध्यान दें कि "x" मान प्राकृतिक मूल्य हैं, और इसका एक विशिष्ट सार्थक अर्थ है, जिसके बारे में मैं थोड़ी देर बाद बात करूंगा; लेकिन वे, निश्चित रूप से, भिन्नात्मक हो सकते हैं। इसके अलावा, किसी विशेष कार्य की सामग्री के आधार पर, "X" और "G" दोनों मान पूर्ण या आंशिक रूप से नकारात्मक हो सकते हैं। खैर, हमें एक "फेसलेस" टास्क दिया गया है, और हम इसे शुरू करते हैं समाधान: हम सिस्टम के समाधान के रूप में इष्टतम फ़ंक्शन के गुणांक पाते हैं: अधिक संक्षिप्त अंकन के प्रयोजनों के लिए, "काउंटर" चर को छोड़ा जा सकता है, क्योंकि यह पहले से ही स्पष्ट है कि योग 1 से . सारणीबद्ध रूप में आवश्यक राशियों की गणना करना अधिक सुविधाजनक है:
इस प्रकार, हम निम्नलिखित प्राप्त करते हैं व्यवस्था: यहां आप दूसरे समीकरण को 3 और से गुणा कर सकते हैं प्रथम समीकरण के पद में से दूसरे पद को पद के अनुसार घटाना. लेकिन यह भाग्य है - व्यवहार में, सिस्टम अक्सर उपहार में नहीं होते हैं, और ऐसे मामलों में यह बचाता है क्रैमर की विधि: चेक करते हैं। मैं समझता हूं कि मैं नहीं करना चाहता, लेकिन गलतियों को क्यों छोड़ें जहां आप उन्हें बिल्कुल याद नहीं कर सकते? सिस्टम के प्रत्येक समीकरण के बाईं ओर पाए गए समाधान को प्रतिस्थापित करें: इस प्रकार, वांछित अनुमानित कार्य: - से सभी रैखिक कार्यप्रायोगिक डेटा इसके द्वारा सबसे अच्छा अनुमानित है। भिन्न सीधा
अपने क्षेत्र पर स्टोर के टर्नओवर की निर्भरता, मिली निर्भरता है उल्टा
(सिद्धांत "अधिक - कम"), और यह तथ्य तुरंत नकारात्मक द्वारा प्रकट किया जाता है कोणीय गुणांक. समारोह सन्निकट फलन को आलेखित करने के लिए, हमें इसके दो मान मिलते हैं: और आरेखण निष्पादित करें: वर्ग विचलन के योग की गणना करें आइए एक तालिका में गणनाओं को संक्षेप में प्रस्तुत करें:
आइए दोहराते हैं: परिणाम का अर्थ क्या है?से सभी रैखिक कार्यसमारोह आइए वर्ग विचलन का संगत योग ज्ञात करें - उन्हें अलग करने के लिए, मैं उन्हें "एप्सिलॉन" अक्षर से निरूपित करूँगा। तकनीक बिल्कुल वही है: निष्कर्ष: , इसलिए एक्सपोनेंशियल फ़ंक्शन सीधी रेखा से भी बदतर प्रायोगिक बिंदुओं का अनुमान लगाता है लेकिन यहाँ यह ध्यान दिया जाना चाहिए कि "बदतर" है अभी मतलब नहीं है, गलत क्या है। अब मैंने इस एक्सपोनेंशियल फंक्शन का एक ग्राफ बनाया - और यह पॉइंट्स के करीब से भी गुजरता है यह समाधान को पूरा करता है, और मैं तर्क के प्राकृतिक मूल्यों के प्रश्न पर लौटता हूं। विभिन्न अध्ययनों में, एक नियम के रूप में, आर्थिक या समाजशास्त्रीय, महीनों, वर्षों या अन्य समान समय अंतरालों को प्राकृतिक "X" के साथ गिना जाता है। उदाहरण के लिए, ऐसी समस्या पर विचार करें। सुविधाओं के बीच स्टोकेस्टिक संबंधों का अध्ययन करने के तरीकों में से एक प्रतिगमन विश्लेषण है। पैरामीटर आकलन के लिए सबसे अधिक उपयोग किया जाता है कम से कम वर्ग विधि (एलएसएम)।
न्यूनतम वर्ग विधि द्वारा रैखिक युग्म समीकरण के प्राचलों के आकलन की समस्यानिम्नलिखित में शामिल हैं: पैरामीटर के ऐसे अनुमान प्राप्त करने के लिए, जिस पर प्रभावी सुविधा के वास्तविक मूल्यों के चुकता विचलन का योग - y i परिकलित मानों से - न्यूनतम है। सार को चित्रित करें ग्राफिक रूप से कम से कम वर्गों की शास्त्रीय विधि. ऐसा करने के लिए, हम एक आयताकार समन्वय प्रणाली में अवलोकन संबंधी डेटा (x i , y i , i=1;n) के अनुसार एक डॉट प्लॉट बनाएंगे (ऐसे डॉट प्लॉट को सहसंबंध क्षेत्र कहा जाता है)। आइए एक सीधी रेखा खोजने की कोशिश करें जो सहसंबंध क्षेत्र के बिंदुओं के सबसे करीब हो। कम से कम वर्ग विधि के अनुसार, रेखा को चुना जाता है ताकि सहसंबंध क्षेत्र के बिंदुओं और इस रेखा के बीच वर्गाकार ऊर्ध्वाधर दूरियों का योग न्यूनतम हो। सुविधाओं के बीच संबंधों की जकड़न का आकलन
रैखिक जोड़ी सहसंबंध - r x, y के गुणांक का उपयोग करके किया जाता है। इसकी गणना सूत्र का उपयोग करके की जा सकती है: तालिका एक

![]()
![]() - डिग्री एम के अनुमानित बहुपद के अज्ञात गुणांक;
- डिग्री एम के अनुमानित बहुपद के अज्ञात गुणांक;![]() . परिणामस्वरूप, हम समीकरणों की निम्नलिखित प्रणाली प्राप्त करते हैं:
. परिणामस्वरूप, हम समीकरणों की निम्नलिखित प्रणाली प्राप्त करते हैं:






![]()
![]() - समीकरणों की प्रणाली के वर्ग मैट्रिक्स के स्तंभ संख्या का सूचकांक
- समीकरणों की प्रणाली के वर्ग मैट्रिक्स के स्तंभ संख्या का सूचकांक
![]() - समीकरणों की प्रणाली के वर्ग मैट्रिक्स की पंक्ति संख्या का सूचकांक
- समीकरणों की प्रणाली के वर्ग मैट्रिक्स की पंक्ति संख्या का सूचकांक

एक विशिष्ट उदाहरण पर समस्या का विवरण
भविष्यवाणी के लिए प्रयुक्त प्रारंभिक डेटा की शुद्धता के बारे में कुछ शब्द
विधि का सार
सटीकता स्कोर
कम से कम वर्ग विधि





एक्सेल में कम से कम वर्ग विधि कैसे लागू करें
कुछ सुविधाएं

पूर्वानुमान समारोह
- एक किराने की दुकान का वार्षिक कारोबार, मिलियन रूबल।
किराने की दुकानों के साथ, मुझे लगता है कि सब कुछ स्पष्ट है: - यह पहली दुकान का क्षेत्र है, - इसका वार्षिक कारोबार, - दूसरी दुकान का क्षेत्र, - इसका वार्षिक कारोबार, आदि। वैसे, वर्गीकृत सामग्रियों तक पहुंच होना बिल्कुल भी आवश्यक नहीं है - टर्नओवर का उपयोग करके काफी सटीक मूल्यांकन प्राप्त किया जा सकता है गणितीय सांख्यिकी. हालांकि, विचलित न हों, वाणिज्यिक जासूसी का कोर्स पहले ही भुगतान किया जा चुका है =)![]() . ऐसा कार्य कहा जाता है अनुमान करने वाले
(सन्निकटन - सन्निकटन)या सैद्धांतिक समारोह
. सामान्यतया, यहाँ तुरंत एक स्पष्ट "ढोंग" दिखाई देता है - उच्च डिग्री का एक बहुपद, जिसका ग्राफ सभी बिंदुओं से होकर गुजरता है। लेकिन यह विकल्प जटिल है, और अक्सर गलत है। (क्योंकि चार्ट हर समय "हवा" करेगा और मुख्य प्रवृत्ति को खराब रूप से प्रतिबिंबित करेगा).
. ऐसा कार्य कहा जाता है अनुमान करने वाले
(सन्निकटन - सन्निकटन)या सैद्धांतिक समारोह
. सामान्यतया, यहाँ तुरंत एक स्पष्ट "ढोंग" दिखाई देता है - उच्च डिग्री का एक बहुपद, जिसका ग्राफ सभी बिंदुओं से होकर गुजरता है। लेकिन यह विकल्प जटिल है, और अक्सर गलत है। (क्योंकि चार्ट हर समय "हवा" करेगा और मुख्य प्रवृत्ति को खराब रूप से प्रतिबिंबित करेगा).
इस सन्निकटन की सटीकता का मूल्यांकन कैसे करें? आइए प्रायोगिक और कार्यात्मक मूल्यों के बीच अंतर (विचलन) की भी गणना करें (हम ड्राइंग का अध्ययन करते हैं). दिमाग में आने वाला पहला विचार यह अनुमान लगाना है कि राशि कितनी बड़ी है, लेकिन समस्या यह है कि अंतर नकारात्मक हो सकते हैं। (उदाहरण के लिए, ![]() )
और इस तरह के योग के परिणामस्वरूप होने वाले विचलन एक दूसरे को रद्द कर देंगे। इसलिए, सन्निकटन की सटीकता के अनुमान के रूप में, यह खुद को राशि लेने का सुझाव देता है मॉड्यूलविचलन:
)
और इस तरह के योग के परिणामस्वरूप होने वाले विचलन एक दूसरे को रद्द कर देंगे। इसलिए, सन्निकटन की सटीकता के अनुमान के रूप में, यह खुद को राशि लेने का सुझाव देता है मॉड्यूलविचलन:![]() या मुड़े हुए रूप में: (अचानक, कौन नहीं जानता: योग आइकन है, और एक सहायक चर- "काउंटर" है, जो 1 से मान लेता है).
या मुड़े हुए रूप में: (अचानक, कौन नहीं जानता: योग आइकन है, और एक सहायक चर- "काउंटर" है, जो 1 से मान लेता है).![]() , जिसके बाद इस तरह के फ़ंक्शन के चयन के प्रयासों को निर्देशित किया जाता है कि चुकता विचलन का योग
, जिसके बाद इस तरह के फ़ंक्शन के चयन के प्रयासों को निर्देशित किया जाता है कि चुकता विचलन का योग ![]() जितना संभव हो उतना छोटा था। दरअसल, इसलिए विधि का नाम।
जितना संभव हो उतना छोटा था। दरअसल, इसलिए विधि का नाम।![]() ड्राइंग पर और उनके स्थान का विश्लेषण करें। यदि वे एक सीधी रेखा में होते हैं, तो आपको देखना चाहिए सीधी रेखा समीकरण
ड्राइंग पर और उनके स्थान का विश्लेषण करें। यदि वे एक सीधी रेखा में होते हैं, तो आपको देखना चाहिए सीधी रेखा समीकरण ![]() इष्टतम मूल्यों के साथ और। दूसरे शब्दों में, कार्य SUCH गुणांकों को खोजना है - ताकि चुकता विचलन का योग सबसे छोटा हो।
इष्टतम मूल्यों के साथ और। दूसरे शब्दों में, कार्य SUCH गुणांकों को खोजना है - ताकि चुकता विचलन का योग सबसे छोटा हो।![]() - वे जो वर्गों का न्यूनतम योग देते हैं
- वे जो वर्गों का न्यूनतम योग देते हैं  .
.
![]() सबसे छोटा था। सब कुछ हमेशा की तरह - पहले पहले क्रम का आंशिक डेरिवेटिव. के अनुसार रैखिकता नियमआप सम आइकन के ठीक नीचे अंतर कर सकते हैं:
सबसे छोटा था। सब कुछ हमेशा की तरह - पहले पहले क्रम का आंशिक डेरिवेटिव. के अनुसार रैखिकता नियमआप सम आइकन के ठीक नीचे अंतर कर सकते हैं: 



![]()

जिसके बाद हमारी समस्या को हल करने के लिए एल्गोरिथम तैयार होना शुरू होता है:![]() क्या हम ढूंढ सकते हैं? सरलता। हम सबसे सरल रचना करते हैं दो अज्ञात के साथ दो रेखीय समीकरणों की प्रणाली("ए" और "बेह")। हम सिस्टम को हल करते हैं, उदाहरण के लिए, क्रैमर की विधि, जिसके परिणामस्वरूप एक स्थिर बिंदु होता है। चेकिंग एक चरम सीमा के लिए पर्याप्त स्थिति, हम सत्यापित कर सकते हैं कि इस बिंदु पर फ़ंक्शन
क्या हम ढूंढ सकते हैं? सरलता। हम सबसे सरल रचना करते हैं दो अज्ञात के साथ दो रेखीय समीकरणों की प्रणाली("ए" और "बेह")। हम सिस्टम को हल करते हैं, उदाहरण के लिए, क्रैमर की विधि, जिसके परिणामस्वरूप एक स्थिर बिंदु होता है। चेकिंग एक चरम सीमा के लिए पर्याप्त स्थिति, हम सत्यापित कर सकते हैं कि इस बिंदु पर फ़ंक्शन ![]() ठीक पहुँचता है न्यूनतम. सत्यापन अतिरिक्त गणनाओं से जुड़ा है और इसलिए हम इसे पर्दे के पीछे छोड़ देंगे। (यदि आवश्यक हो, लापता फ्रेम देखा जा सकता है). हम अंतिम निष्कर्ष निकालते हैं:
ठीक पहुँचता है न्यूनतम. सत्यापन अतिरिक्त गणनाओं से जुड़ा है और इसलिए हम इसे पर्दे के पीछे छोड़ देंगे। (यदि आवश्यक हो, लापता फ्रेम देखा जा सकता है). हम अंतिम निष्कर्ष निकालते हैं:![]() सबसे अच्छा तरीका (कम से कम किसी अन्य रैखिक कार्य की तुलना में)प्रायोगिक बिंदुओं को करीब लाता है
सबसे अच्छा तरीका (कम से कम किसी अन्य रैखिक कार्य की तुलना में)प्रायोगिक बिंदुओं को करीब लाता है ![]() . मोटे तौर पर, इसका ग्राफ इन बिंदुओं के जितना करीब हो सके गुजरता है। परंपरा में अर्थमितिपरिणामी सन्निकटन फलन भी कहलाता है जोड़ी समीकरण रेखीय प्रतिगमन
.
. मोटे तौर पर, इसका ग्राफ इन बिंदुओं के जितना करीब हो सके गुजरता है। परंपरा में अर्थमितिपरिणामी सन्निकटन फलन भी कहलाता है जोड़ी समीकरण रेखीय प्रतिगमन
.![]() आपको भविष्यवाणी करने की अनुमति देता है कि किस प्रकार का कारोबार ("यिग")बिक्री क्षेत्र के एक या दूसरे मूल्य के साथ स्टोर पर होगा ("x" का एक या दूसरा अर्थ). हां, परिणामी पूर्वानुमान केवल एक पूर्वानुमान होगा, लेकिन कई मामलों में यह काफी सटीक निकलेगा।
आपको भविष्यवाणी करने की अनुमति देता है कि किस प्रकार का कारोबार ("यिग")बिक्री क्षेत्र के एक या दूसरे मूल्य के साथ स्टोर पर होगा ("x" का एक या दूसरा अर्थ). हां, परिणामी पूर्वानुमान केवल एक पूर्वानुमान होगा, लेकिन कई मामलों में यह काफी सटीक निकलेगा।
कम से कम वर्ग विधि का उपयोग करते हुए, उस रैखिक फलन का पता लगाएं जो अनुभवजन्य का सबसे अच्छा सन्निकटन करता है (अनुभव)जानकारी। एक आरेखण बनाएं, जिस पर, एक कार्तीय आयताकार समन्वय प्रणाली में, प्रायोगिक बिंदुओं को प्लॉट करें और सन्निकट फलन का एक ग्राफ बनाएं ![]() . अनुभवजन्य और सैद्धांतिक मूल्यों के बीच वर्ग विचलन का योग ज्ञात कीजिए। पता करें कि क्या फ़ंक्शन बेहतर है (न्यूनतम वर्ग विधि के संदर्भ में)अनुमानित प्रायोगिक बिंदु।
. अनुभवजन्य और सैद्धांतिक मूल्यों के बीच वर्ग विचलन का योग ज्ञात कीजिए। पता करें कि क्या फ़ंक्शन बेहतर है (न्यूनतम वर्ग विधि के संदर्भ में)अनुमानित प्रायोगिक बिंदु।

गणना एक माइक्रोकैलकुलेटर पर की जा सकती है, लेकिन एक्सेल का उपयोग करना बेहतर है - दोनों तेज और त्रुटियों के बिना; एक छोटा वीडियो देखें:![]()
, इसलिए सिस्टम के पास एक अनूठा समाधान है।
संबंधित समीकरणों के सही हिस्से प्राप्त होते हैं, जिसका अर्थ है कि सिस्टम सही तरीके से हल किया गया है।![]() हमें सूचित करता है कि एक निश्चित संकेतक में 1 इकाई की वृद्धि के साथ, आश्रित संकेतक का मूल्य घट जाता है औसत 0.65 इकाइयों द्वारा। जैसा कि वे कहते हैं, एक प्रकार का अनाज की कीमत जितनी अधिक होगी, उतनी ही कम बिकेगी।
हमें सूचित करता है कि एक निश्चित संकेतक में 1 इकाई की वृद्धि के साथ, आश्रित संकेतक का मूल्य घट जाता है औसत 0.65 इकाइयों द्वारा। जैसा कि वे कहते हैं, एक प्रकार का अनाज की कीमत जितनी अधिक होगी, उतनी ही कम बिकेगी।
निर्मित रेखा कहलाती है प्रवृत्ति रेखा
(अर्थात, एक रेखीय प्रवृत्ति रेखा, यानी सामान्य स्थिति में, एक प्रवृत्ति जरूरी नहीं कि एक सीधी रेखा हो). हर कोई "प्रवृत्ति में होना" अभिव्यक्ति से परिचित है, और मुझे लगता है कि इस शब्द को अतिरिक्त टिप्पणियों की आवश्यकता नहीं है।![]() अनुभवजन्य और सैद्धांतिक मूल्यों के बीच। ज्यामितीय रूप से, यह "क्रिमसन" खंडों की लंबाई के वर्गों का योग है (जिनमें से दो इतने छोटे हैं कि आप उन्हें देख भी नहीं सकते).
अनुभवजन्य और सैद्धांतिक मूल्यों के बीच। ज्यामितीय रूप से, यह "क्रिमसन" खंडों की लंबाई के वर्गों का योग है (जिनमें से दो इतने छोटे हैं कि आप उन्हें देख भी नहीं सकते).
उन्हें फिर से मैन्युअल रूप से किया जा सकता है, बस अगर मैं पहले बिंदु के लिए एक उदाहरण दूंगा: ![]()
लेकिन पहले से ज्ञात तरीके से करना अधिक कुशल है:![]() प्रतिपादक सबसे छोटा है, अर्थात यह अपने परिवार में सबसे अच्छा सन्निकटन है। और यहाँ, वैसे, समस्या का अंतिम प्रश्न आकस्मिक नहीं है: क्या होगा यदि प्रस्तावित घातीय कार्य
प्रतिपादक सबसे छोटा है, अर्थात यह अपने परिवार में सबसे अच्छा सन्निकटन है। और यहाँ, वैसे, समस्या का अंतिम प्रश्न आकस्मिक नहीं है: क्या होगा यदि प्रस्तावित घातीय कार्य ![]() क्या प्रायोगिक बिंदुओं का अनुमान लगाना बेहतर होगा?
क्या प्रायोगिक बिंदुओं का अनुमान लगाना बेहतर होगा?
और फिर से 1 बिंदु के लिए प्रत्येक अग्नि गणना के लिए: 
एक्सेल में, हम मानक फ़ंक्शन का उपयोग करते हैं ऍक्स्प (वाक्यविन्यास एक्सेल सहायता में पाया जा सकता है).![]() .
.![]() - इतना कि बिना विश्लेषणात्मक अध्ययन के यह कहना मुश्किल है कि कौन सा कार्य अधिक सटीक है।
- इतना कि बिना विश्लेषणात्मक अध्ययन के यह कहना मुश्किल है कि कौन सा कार्य अधिक सटीक है।
प्रतिगमन विश्लेषण एक प्रतिगमन समीकरण की व्युत्पत्ति है, जिसका उपयोग एक यादृच्छिक चर (फीचर-परिणाम) के औसत मूल्य को खोजने के लिए किया जाता है, यदि अन्य (या अन्य) चर (फीचर-फैक्टर) का मान ज्ञात हो। इसमें निम्नलिखित चरण शामिल हैं:
अक्सर, सुविधाओं के सांख्यिकीय संबंध का वर्णन करने के लिए एक रेखीय रूप का उपयोग किया जाता है। एक रेखीय संबंध पर ध्यान इसके मापदंडों की एक स्पष्ट आर्थिक व्याख्या द्वारा समझाया गया है, चर की भिन्नता से सीमित है, और इस तथ्य से कि ज्यादातर मामलों में, रिश्ते के गैर-रैखिक रूपों को परिवर्तित किया जाता है (लघुगणक या चर बदलते हुए) गणना करने के लिए एक रेखीय रूप में।
एक रैखिक जोड़ी संबंध के मामले में, समाश्रयण समीकरण का रूप होगा: y i =a+b·x i +u i । इस समीकरण ए और बी के पैरामीटर सांख्यिकीय अवलोकन x और y के डेटा से अनुमानित हैं। इस तरह के मूल्यांकन का परिणाम समीकरण है: , जहां , - पैरामीटर ए और बी का अनुमान - प्रतिगमन समीकरण (गणना मूल्य) द्वारा प्राप्त प्रभावी विशेषता (चर) का मूल्य।
कम से कम वर्ग विधि प्रतिगमन समीकरण के मापदंडों का सबसे अच्छा (निरंतर, कुशल और निष्पक्ष) अनुमान देती है। लेकिन केवल अगर यादृच्छिक शब्द (यू) और स्वतंत्र चर (एक्स) के बारे में कुछ मान्यताओं को पूरा किया जाता है (ओएलएस मान्यताओं को देखें)।
औपचारिक रूप से ओएलएस मानदंडइस प्रकार लिखा जा सकता है:  .
.कम से कम वर्ग विधियों का वर्गीकरण

इस समस्या का गणितीय अंकन:  .
.
y i और x i =1...n के मान हमें ज्ञात हैं, ये अवलोकन संबंधी डेटा हैं। समारोह एस में वे स्थिरांक हैं। इस फ़ंक्शन में चर पैरामीटर के आवश्यक अनुमान हैं - , . 2 चरों के एक फ़ंक्शन का न्यूनतम पता लगाने के लिए, प्रत्येक पैरामीटर के संबंध में इस फ़ंक्शन के आंशिक डेरिवेटिव की गणना करना और उन्हें शून्य के बराबर करना आवश्यक है, अर्थात 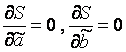 .
.
नतीजतन, हम 2 सामान्य रैखिक समीकरणों की एक प्रणाली प्राप्त करते हैं: 
इस प्रणाली को हल करते हुए, हमें आवश्यक पैरामीटर अनुमान मिलते हैं: 
प्रतिगमन समीकरण के मापदंडों की गणना की शुद्धता की जाँच योगों की तुलना करके की जा सकती है (गणनाओं के पूर्ण होने के कारण कुछ विसंगति संभव है)।
पैरामीटर अनुमानों की गणना करने के लिए, आप तालिका 1 बना सकते हैं।
प्रतिगमन गुणांक b का चिह्न संबंध की दिशा को इंगित करता है (यदि b> 0, संबंध प्रत्यक्ष है, यदि b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
औपचारिक रूप से, पैरामीटर का मान x के लिए y का औसत मान शून्य के बराबर है। यदि साइन-फैक्टर के पास शून्य मान नहीं है और नहीं हो सकता है, तो पैरामीटर की उपरोक्त व्याख्या का कोई मतलब नहीं है। . इसके अलावा, रैखिक जोड़ी सहसंबंध के गुणांक को प्रतिगमन गुणांक बी के संदर्भ में निर्धारित किया जा सकता है:
. इसके अलावा, रैखिक जोड़ी सहसंबंध के गुणांक को प्रतिगमन गुणांक बी के संदर्भ में निर्धारित किया जा सकता है:  .
.
जोड़ी सहसंबंध के रैखिक गुणांक के स्वीकार्य मूल्यों की सीमा -1 से +1 तक है। सहसंबंध गुणांक का चिह्न संबंध की दिशा को दर्शाता है। यदि आर एक्स, वाई > 0, तो कनेक्शन प्रत्यक्ष है; अगर आर एक्स, वाई<0, то связь обратная.
यदि यह गुणांक मापांक में एकता के करीब है, तो सुविधाओं के बीच के संबंध को काफी निकट रैखिक के रूप में व्याख्या किया जा सकता है। यदि इसका मापांक एक ê r x , y ê =1 के बराबर है, तो सुविधाओं के बीच संबंध कार्यात्मक रैखिक है। यदि विशेषताएं x और y रैखिक रूप से स्वतंत्र हैं, तो r x,y 0 के करीब है।
तालिका 1 का उपयोग आर एक्स, वाई की गणना के लिए भी किया जा सकता है।
प्राप्त प्रतिगमन समीकरण की गुणवत्ता का आकलन करने के लिए, निर्धारण के सैद्धांतिक गुणांक की गणना की जाती है - R 2 yx: एन अवलोकन एक्स मैं यी एक्स आई ∙ वाई आई
1
एक्स 1 वाई 1 एक्स 1 वाई 1
2
x2 y2 एक्स 2 वाई 2
...
एन एक्स एन Y n एक्स एन वाई एन
स्तंभ योग ∑x ∑य ∑x वाई
अर्थ
![]()
![]()
 ,
,
जहाँ d 2 प्रतिगमन समीकरण द्वारा समझाया गया प्रसरण y है;
ई 2 - अवशिष्ट (प्रतिगमन समीकरण द्वारा अस्पष्टीकृत) विचरण y ;
एस 2 वाई - कुल (कुल) भिन्नता वाई।
दृढ़ संकल्प का गुणांक परिणामी विशेषता y की भिन्नता (फैलाव) के हिस्से की विशेषता है, जो कुल भिन्नता (फैलाव) y में प्रतिगमन (और, परिणामस्वरूप, कारक x) द्वारा समझाया गया है। निर्धारण का गुणांक R 2 yx 0 से 1 तक मान लेता है। तदनुसार, मान 1-R 2 yx मॉडल और विनिर्देश त्रुटियों में ध्यान में नहीं रखे गए अन्य कारकों के प्रभाव के कारण विचरण y के अनुपात को दर्शाता है।
युग्मित रेखीय समाश्रयण के साथ R 2 yx =r 2 yx ।
