Оценяване на значимостта на регресионното уравнение и неговите параметри. Оценка на статистическата значимост на параметрите на регресионното уравнение
След като регресионното уравнение е конструирано и неговата точност е оценена с помощта на коефициента на детерминация, остава отворен въпроскак е постигната тази точност и съответно може ли да се вярва на това уравнение. Факт е, че регресионното уравнение не е изградено според население, който е неизвестен, но по образец от него. Точките от генералната съвкупност попадат в извадката на случаен принцип, следователно, в съответствие с теорията на вероятността, наред с други случаи е възможно извадка от „широка“ генерална съвкупност да се окаже „тясна“ (фиг. 15) .
Ориз. 15. Възможен вариантточки, попадащи в извадка от генералната съвкупност.
В такъв случай:
а) регресионното уравнение, конструирано за извадката, може да се различава значително от регресионното уравнение за генералната съвкупност, което ще доведе до прогнозни грешки;
б) коефициентът на детерминация и други характеристики на точност ще бъдат необосновано високи и ще подведат относно предсказуемите качества на уравнението.
В ограничаващия случай опцията не може да бъде изключена, когато от генерална популация, която е облак с главна ос, успоредна на хоризонталната ос (няма връзка между променливите), поради случаен подбор, ще бъде получена извадка, чиято главна ос ще бъде наклонена спрямо оста. По този начин опитите да се предскажат следващите стойности на генералната съвкупност въз основа на данни от извадка от нея са изпълнени не само с грешки в оценката на силата и посоката на връзката между зависимите и независимите променливи, но и с опасността от намиране на връзка между променливи там, където всъщност няма такава.
При липса на информация за всички точки в популацията, единственият начин да се намалят грешките в първия случай е да се използва метод за оценка на коефициентите на регресионното уравнение, който гарантира, че те са безпристрастни и ефективни. И вероятността за възникване на втория случай може да бъде значително намалена поради факта, че едно свойство на генерална съвкупност с две независими една от друга променливи е известно a priori - точно тази връзка липсва в нея. Това намаление се постига чрез проверка статистическа значимостполученото регресионно уравнение.
Една от най-често използваните опции за проверка е следната. За полученото регресионно уравнение се определя -статистика - характеристика на точността на регресионното уравнение, което е съотношението на тази част от дисперсията на зависимата променлива, която се обяснява от регресионното уравнение към необяснената (остатъчна) част на дисперсията. Уравнението за определяне на -статистиката в случай на многомерна регресия има формата:

където: - обяснена дисперсия - част от дисперсията на зависимата променлива Y, която се обяснява от регресионното уравнение;
Остатъчната дисперсия е частта от дисперсията на зависимата променлива Y, която не се обяснява с уравнението на регресията, нейното наличие е следствие от действието на случайния компонент;
Брой точки в извадката;
Брой променливи в регресионното уравнение.
Както може да се види от горната формула, дисперсиите се определят като частното от разделянето на съответната сума от квадрати на броя на степените на свобода. Броят на степените на свобода е минимално необходимият брой стойности на зависимата променлива, които са достатъчни за получаване на желаната характеристика на пробата и които могат да варират свободно, като се вземе предвид факта, че за тази проба всички други стойности използвани за изчисляване на желаната характеристика са известни.
За да се получи остатъчната дисперсия, са необходими коефициентите на регресионното уравнение. В случай на сдвоена линейна регресия има два коефициента, следователно, в съответствие с формулата (като ) броят на степените на свобода е равен на . Това означава, че за определяне на остатъчната вариация е достатъчно да се знаят коефициентите на регресионното уравнение и само стойностите на зависимата променлива от извадката. Останалите две стойности могат да бъдат изчислени въз основа на тези данни и следователно не са свободно променливи.
За да се изчисли обяснената дисперсия на стойностите на зависимата променлива, изобщо не се изисква, тъй като може да се изчисли чрез познаване на регресионните коефициенти за независимите променливи и дисперсията на независимата променлива. За да проверите това, достатъчно е да си припомните дадения преди това израз ![]() . Следователно броят на степените на свобода за остатъчната дисперсия е равен на броя на независимите променливи в регресионното уравнение (за сдвоена линейна регресия).
. Следователно броят на степените на свобода за остатъчната дисперсия е равен на броя на независимите променливи в регресионното уравнение (за сдвоена линейна регресия).
В резултат на това -критерият за сдвоеното уравнение на линейна регресия се определя от формулата:
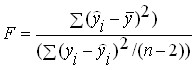 .
.
В теорията на вероятностите е доказано, че -критерият на регресионно уравнение, получено за извадка от обща съвкупност, в която няма връзка между зависимите и независимите променливи, има разпределение на Фишер, което е доста добре проучено. Благодарение на това за всяка стойност на -критерия е възможно да се изчисли вероятността за възникването му и, обратно, да се определи стойността на -критерия, която той не може да надвишава с дадена вероятност.
За изпълнение статистическо тестванезначимостта на регресионното уравнение, формулирана е нулева хипотеза за липсата на връзка между променливите (всички коефициенти за променливите са равни на нула) и е избрано нивото на значимост.
Нивото на значимост е приемливата вероятност за допускане на грешка от тип I – отхвърляне на правилната нулева хипотеза в резултат на тестване. В този случай допускането на грешка от тип I означава разпознаване в извадка, че има връзка между променливите в популацията, когато всъщност няма такава.
Обикновено нивото на значимост се приема за 5% или 1%. Колкото по-високо е нивото на значимост (колкото по-малко), толкова по-високо е нивото на надеждност на теста, равно на , т.е. толкова по-голям е шансът да се избегне грешката да се разпознае в извадката наличието на връзка в общата съвкупност от действително несвързани променливи. Но с нарастването на нивото на значимост се увеличава опасността от извършване на грешка от втори тип - отхвърляне на правилната нулева хипотеза, т.е. да не забележите в извадката действителната връзка между променливите в генералната съвкупност. Следователно, в зависимост от това коя грешка е голяма Отрицателни последици, изберете едно или друго ниво на значимост.
За избраното ниво на значимост разпределението на Фишър определя табличната стойност на вероятността за превишаване, която в мощностна извадка, получена от генералната съвкупност без връзка между променливите, не надвишава нивото на значимост. се сравнява с действителната стойност на критерия за регресионно уравнение.
Ако условието е изпълнено, тогава погрешното откриване на връзка със стойност на критерия, равна или по-голяма в извадка от обща популация с несвързани променливи, ще се случи с вероятност, по-малка от нивото на значимост. В съответствие с правилото „няма много редки събития” стигаме до извода, че връзката между променливите, установени в извадката, съществува и в генералната съвкупност, от която е получена.
Ако се окаже, че регресионното уравнение не е статистически значимо. С други думи, има реална вероятностче извадката е установила връзка между променливи, която не съществува в действителност. Уравнение, което не отговаря на теста за статистическа значимост, се третира по същия начин като лекарство с изтекъл срок на годност.
Ti - такива лекарства не са непременно развалени, но тъй като няма доверие в тяхното качество, те предпочитат да не ги използват. Това правило не предпазва от всички грешки, но ви позволява да избегнете най-сериозните, което също е много важно.
Втората опция за проверка, по-удобна при използване на електронни таблици, е да се сравни вероятността за поява на получената стойност на критерия с нивото на значимост. Ако тази вероятност е под нивото на значимост, тогава уравнението е статистически значимо, в противен случай не е.
След проверка на статистическата значимост на регресионното уравнение като цяло, обикновено е полезно, особено за многовариантни зависимости, да се провери статистическата значимост на получените регресионни коефициенти. Идеологията на проверката е същата като при проверката на уравнението като цяло, но като критерий се използва t-тестът на Student, определен от формулите:
 И
И 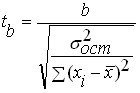
където: , - стойности на критерия на Студент за коефициенти и съответно;
 - остатъчна дисперсия на регресионното уравнение;
- остатъчна дисперсия на регресионното уравнение;
Брой точки в извадката;
Брой променливи в извадката за линейна регресия по двойки.
Получените действителни стойности от теста на Стюдънт се сравняват с табличните стойности ![]() , получен от разпределението на Student. Ако се окаже, че , тогава съответният коефициент е статистически значим, в противен случай не. Вторият вариант за проверка на статистическата значимост на коефициентите е да се определи вероятността за поява на теста на Студент и да се сравни с нивото на значимост.
, получен от разпределението на Student. Ако се окаже, че , тогава съответният коефициент е статистически значим, в противен случай не. Вторият вариант за проверка на статистическата значимост на коефициентите е да се определи вероятността за поява на теста на Студент и да се сравни с нивото на значимост.
За променливи, чиито коефициенти се оказаха статистически незначими, има голяма вероятност тяхното влияние върху зависимата променлива в съвкупността напълно да отсъства. Следователно е необходимо или да се увеличи броят на точките в извадката, тогава може би коефициентът ще стане статистически значим и в същото време стойността му ще се изясни, или да се намерят други като независими променливи, които са по-тясно свързани със зависимите променлива. В този случай точността на прогнозата ще се увеличи и в двата случая.
Като експресен метод за оценка на значимостта на коефициентите на регресионното уравнение можете да използвате следващото правило– ако t-тестът на Student е по-голям от 3, тогава такъв коефициент, като правило, се оказва статистически значим. Като цяло се смята, че за да се получат статистически значими регресионни уравнения, е необходимо условието да бъде изпълнено.
Стандартната грешка при прогнозиране от полученото регресионно уравнение на неизвестна стойност с известна стойност се оценява с помощта на формулата:

По този начин прогноза с вероятност за доверие от 68% може да бъде представена като:
Ако се изисква друг вероятност за доверие, тогава за нивото на значимост е необходимо да се намери тестът на Студент и доверителен интервалза прогноза с ниво на надеждност ще бъде равно на ![]() .
.
Прогноза на многомерни и нелинейни зависимости
Ако прогнозираната стойност зависи от няколко независими променливи, тогава в този случай има многовариантна регресия на формата:
където: - регресионни коефициенти, описващи влиянието на променливите върху прогнозираната стойност.
Методологията за определяне на коефициентите на регресия не се различава от двойната линейна регресия, особено когато се използва електронна таблица, тъй като използва същата функция както за двойна, така и за многовариантна линейна регресия. В този случай е желателно да няма връзки между независимите променливи, т.е. промяната на една променлива не повлия на стойностите на други променливи. Но това изискване не е задължително, важно е да няма функционални линейни зависимости между променливите. Описаните по-горе процедури за проверка на статистическата значимост на полученото регресионно уравнение и неговите индивидуални коефициенти, оценката на точността на прогнозиране остава същата, както в случая на сдвоена линейна регресия. В същото време използването на многовариантни регресии вместо двойни обикновено позволява, при правилен подбор на променливи, значително да се повиши точността на описание на поведението на зависимата променлива и следователно точността на прогнозата.
В допълнение, многовариантните линейни регресионни уравнения позволяват да се опише нелинейната зависимост на прогнозираната стойност от независими променливи. Процедура за отливане Не линейно уравнениедо линейна форма се нарича линеаризация. По-специално, ако тази зависимост се описва с полином със степен, различна от 1, тогава чрез замяна на променливи със степени, различни от единица, с нови променливи от първа степен, получаваме многовариантна линейна регресионна задача вместо нелинейна. Така, например, ако влиянието на независимата променлива е описано с парабола на формата
![]()
тогава заместването ни позволява да трансформираме нелинейния проблем в многомерен линеен от формата
![]()
Нелинейните проблеми, при които възниква нелинейност поради факта, че прогнозираната стойност зависи от произведението на независими променливи, също могат лесно да бъдат трансформирани. За да се вземе предвид такова влияние, е необходимо да се въведе нова променлива, равна на този продукт.
В случаите, когато нелинейността се описва от по-сложни зависимости, линеаризацията е възможна поради координатна трансформация. За целта се изчисляват стойностите ![]() и са построени графики на зависимостта на началните точки в различни комбинации от трансформирани променливи. Тази комбинация от трансформирани координати или трансформирани и нетрансформирани координати, в която зависимостта е най-близка до права линия, предизвиква промяна на променливите, която ще доведе до трансформация на нелинейна зависимост в линейна форма. Например нелинейна зависимост на формата
и са построени графики на зависимостта на началните точки в различни комбинации от трансформирани променливи. Тази комбинация от трансформирани координати или трансформирани и нетрансформирани координати, в която зависимостта е най-близка до права линия, предизвиква промяна на променливите, която ще доведе до трансформация на нелинейна зависимост в линейна форма. Например нелинейна зависимост на формата
се превръща в линейна форма
Получените регресионни коефициенти за трансформираното уравнение остават безпристрастни и ефективни, но тестването на статистическата значимост на уравнението и коефициентите не е възможно
Проверка на валидността на метода най-малки квадрати
Използването на метода на най-малките квадрати гарантира ефективността и безпристрастните оценки на коефициентите на регресионното уравнение при следните условия (условия на Гаус-Марков):
3. стойностите не зависят една от друга
4. стойностите не зависят от независими променливи
Най-лесният начин да проверите дали тези условия са изпълнени е като начертаете остатъците като функция на , след това като функция на независимата променлива(и). Ако точките на тези графики са разположени в коридор, разположен симетрично на оста x и не се виждат модели в местоположението на точките, тогава условията на Гаус-Марков са изпълнени и няма възможност за подобряване на точността на регресията уравнение. Ако това не е така, тогава е възможно значително да се подобри точността на уравнението и за това е необходимо да се обърнете към специализирана литература.
ТЕМА 4. СТАТИСТИЧЕСКИ МЕТОДИ ЗА ИЗУЧАВАНЕ НА ВРЪЗКИ
Регресионно уравнение -Това е аналитично представяне на корелационната зависимост. Уравнението на регресията описва хипотетичната функционална връзка между условната средна стойност на резултантния признак и стойността на признака - фактор (фактори), т.е. основната тенденция на пристрастяване.
Двойна корелационна зависимост се описва от двойно регресионно уравнение, а множествена корелационна зависимост се описва от множествено регресионно уравнение.
Атрибутът на резултата в регресионното уравнение е зависимата променлива (отговор, обяснена променлива), а факторният атрибут е независимата променлива (аргумент, обяснителна променлива).
Най-простият тип регресионно уравнение е уравнението на двойната линейна зависимост:
където y е зависимата променлива (атрибут-резултат); x – независима променлива (фактор на признака); и – параметри на регресионното уравнение; - грешка в оценката.
Различни математически функции могат да се използват като регресионно уравнение. Често срещан практическа употребанамерете уравнения на линейна зависимост, парабола, хипербола, степна функция и др.
По правило анализът започва с оценка на линейната връзка, тъй като резултатите са лесни за смислено интерпретиране. Изборът на типа уравнение на свързване е доста важен етап от анализа. В „предкомпютърната“ ера тази процедура беше свързана с определени трудности и изискваше от анализатора да познава свойствата на математическите функции. Понастоящем, въз основа на специализирани програми, е възможно бързо да се конструират много комуникационни уравнения и въз основа на формални критерии да се избере най-добрият модел (математическата грамотност на анализатора обаче не е загубила своята релевантност).
Въз основа на резултатите от конструирането на корелационното поле може да се изложи хипотеза за вида на корелационната зависимост (виж лекция 6). Въз основа на естеството на местоположението на точките на графиката (координатите на точките съответстват на стойностите на зависимите и независимите променливи) се разкрива тенденция за връзка между характеристиките (показателите). Ако регресионната линия минава през всички точки на корелационното поле, това показва функционална връзка. В практиката на социално-икономическите изследвания такава картина не може да се наблюдава, тъй като има статистическа (корелационна) зависимост. В условията на корелационна зависимост при начертаване на регресионна линия върху точкова диаграма се наблюдава отклонение на точките на корелационното поле от регресионната линия, което демонстрира т. нар. остатъчни или оценъчни грешки (виж Фигура 7.1).
Наличието на грешка в уравнението се дължи на факта, че:
§ не всички фактори, влияещи върху резултата, са взети предвид в уравнението на регресията;
§ формата на връзка може да бъде избрана неправилно - регресионното уравнение;
§ Не всички фактори са включени в уравнението.
Да се състави регресионно уравнение означава да се изчислят стойностите на неговите параметри. Регресионното уравнение се изгражда въз основа на действителните стойности на анализираните характеристики. Изчисляването на параметрите обикновено се извършва с помощта на метод на най-малките квадрати (LSM).
Същността на MNCе, че е възможно да се получат такива стойности на параметрите на уравнението, които минимизират сумата от квадратните отклонения на теоретичните стойности на атрибута на резултата (изчислени въз основа на регресионното уравнение) от действителните му стойности:
 ,
,
 където е действителната стойност на резултатната характеристика i-та единицаинертни материали; - стойността на характеристиката на резултата за i-та единица от съвкупността, получена от регресионното уравнение ().
където е действителната стойност на резултатната характеристика i-та единицаинертни материали; - стойността на характеристиката на резултата за i-та единица от съвкупността, получена от регресионното уравнение ().
По този начин се решава проблемът с екстремума, т.е. е необходимо да се намери при какви стойности на параметрите функцията S достига минимум.
Извършване на диференциране, приравняване на частични производни на нула:




 , (7.3)
, (7.3)
 , (7.4)
, (7.4)
където е средното произведение на стойностите на фактора и резултата; - средна стойност на признака - фактор; - средна стойност на резултатната характеристика; - дисперсия на факторния признак.
Параметърът в регресионното уравнение характеризира наклона на регресионната линия на графиката. Този параметър се нарича регресионен коефициенти неговата стойност характеризира колко единици от неговото измерване атрибутът на резултата ще се промени, когато факторният атрибут се промени с една единица от неговото измерване. Знакът на коефициента на регресия отразява посоката на зависимостта (пряка или обратна) и съвпада със знака на коефициента на корелация (в условия на двойна зависимост).
В контекста на разглеждания пример програмата STATISTICA изчислява параметрите на регресионното уравнение, описващо връзката между нивото на паричните доходи на глава от населението и стойността на брутния регионален продукт на глава от населението в регионите на Русия, вж. Таблица 7.1.
Таблица 7.1 - Изчисляване и оценка на параметрите на уравнението, описващо връзката между нивото на средния паричен доход на глава от населението и стойността на брутния регионален продукт на глава от населението в регионите на Русия, 2013 г.

Колона "B" на таблицата съдържа стойностите на параметрите на сдвоеното регресионно уравнение, следователно можем да напишем: = 13406,89 + 22,82 x. Това уравнение описва тенденцията на връзката между анализираните характеристики. Параметърът е коефициентът на регресия. В този случай той е равен на 22,82 и характеризира следното: с увеличение на БВП на глава от населението с 1 хил. Рубли, средният паричен доход на глава от населението се увеличава средно (както е посочено със знака „+“) с 22,28 рубли.
Параметърът на регресионното уравнение в социално-икономическите изследвания като правило не се интерпретира смислено. Формално той отразява стойността на признака - резултат, при условие че признакът - фактор е равен на нула. Параметърът характеризира местоположението на регресионната линия на графиката, вижте Фигура 7.1.

Фигура 7.1 - Корелационно поле и регресионна линия, отразяващи зависимостта на нивото на паричния доход на глава от населението в регионите на Русия и стойността на GRP на глава от населението
Стойността на параметъра съответства на точката на пресичане на регресионната линия с оста Y, при X=0.
Построяването на регресионно уравнение се придружава от оценка на статистическата значимост на уравнението като цяло и неговите параметри. Необходимостта от такива процедури се дължи на ограниченото количество данни, което може да затрудни действието на закона големи числаи следователно идентифициране на истинската тенденция във връзката между анализираните показатели. В допълнение, всяка изследвана популация може да се разглежда като извадка от общата популация, а характеристиките, получени по време на анализа, като оценка на общите параметри.
Оценяването на статистическата значимост на параметрите и уравнението като цяло е обосновка на възможността за използване на изградения комуникационен модел за вземане на управленски решения и прогнозиране (моделиране).
Статистическа значимост на регресионното уравнениекато цяло се оценява чрез F тест на Фишер, което е съотношението на факторните и остатъчните дисперсии, изчислени за степен на свобода:
Където  - факторна дисперсия на признака - резултат; k – брой степени на свобода на факторната дисперсия (брой фактори в регресионното уравнение); - средна стойност на зависимата променлива; - теоретична (получена от регресионното уравнение) стойност на зависимата променлива за i – та единица от съвкупността;
- факторна дисперсия на признака - резултат; k – брой степени на свобода на факторната дисперсия (брой фактори в регресионното уравнение); - средна стойност на зависимата променлива; - теоретична (получена от регресионното уравнение) стойност на зависимата променлива за i – та единица от съвкупността;  - остатъчна дисперсиязнак - резултат; n е обемът на населението; n-k-1 – брой степени на свобода на остатъчната дисперсия.
- остатъчна дисперсиязнак - резултат; n е обемът на населението; n-k-1 – брой степени на свобода на остатъчната дисперсия.
Стойността на F теста на Фишер, съгласно формулата, характеризира връзката между фактора и остатъчните дисперсии на зависимата променлива, показвайки по същество колко пъти стойността на обяснената част от вариацията надвишава необяснената част.
F-тестът на Fisher е представен в таблица; входът към таблицата е броят на степените на свобода на фактора и остатъчните дисперсии. Сравняването на изчислената стойност на критерия с табличната (критична) ни позволява да отговорим на въпроса: тази част от вариацията в атрибута резултат, която може да се обясни с факторите, включени в уравнението от този тип, е статистически значима? Ако  , тогава регресионното уравнение се счита за статистически значимо и съответно коефициентът на детерминация е статистически значим. В противен случай (
, тогава регресионното уравнение се счита за статистически значимо и съответно коефициентът на детерминация е статистически значим. В противен случай (  ), уравнението е статистически незначимо, т.е. вариацията на факторите, взети предвид в уравнението, не обяснява статистически значима част от вариацията в атрибута на резултата или уравнението на връзката не е избрано правилно.
), уравнението е статистически незначимо, т.е. вариацията на факторите, взети предвид в уравнението, не обяснява статистически значима част от вариацията в атрибута на резултата или уравнението на връзката не е избрано правилно.
Оценка на статистическата значимост на параметрите на уравнениетоизвършено на осн t-статистика, което се изчислява като съотношението на модула на параметрите на регресионното уравнение към техните стандартни грешки (  ):
):
 , Където
, Където  ; (7.6)
; (7.6)
 , Където
, Където  ; (7.7)
; (7.7)
Където  - стандартни отклонениязнак - фактор и знак - резултат; - коефициент на детерминация.
- стандартни отклонениязнак - фактор и знак - резултат; - коефициент на детерминация.
 В специализирани статистически програми изчисляването на параметрите винаги е придружено от изчисляване на стойностите на техните стандартни (средни квадратни) грешки и t-статистики (вижте таблица 7.1). Изчислената стойност на t-статистиката се сравнява с тази в таблицата; ако обемът на изследваната популация е по-малък от 30 единици (със сигурност малка извадка), трябва да се обърнете към таблицата с t-разпределение на Стюдент; ако обемът на популацията е голям , трябва да използвате таблицата на нормалното разпределение (вероятностен интеграл на Лаплас). Параметърът на уравнението се счита за статистически значим, ако.
В специализирани статистически програми изчисляването на параметрите винаги е придружено от изчисляване на стойностите на техните стандартни (средни квадратни) грешки и t-статистики (вижте таблица 7.1). Изчислената стойност на t-статистиката се сравнява с тази в таблицата; ако обемът на изследваната популация е по-малък от 30 единици (със сигурност малка извадка), трябва да се обърнете към таблицата с t-разпределение на Стюдент; ако обемът на популацията е голям , трябва да използвате таблицата на нормалното разпределение (вероятностен интеграл на Лаплас). Параметърът на уравнението се счита за статистически значим, ако.
Оценката на параметрите въз основа на t-статистиката е по същество тест на нулевата хипотеза, че общите параметри са равни на нула (H 0: =0; H 0: =0;), т.е. че параметрите на регресионното уравнение са статистически незначими. Нивото на значимост на хипотезата обикновено се приема: = 0,05. Ако изчисленото ниво на значимост е по-малко от 0,05, тогава нулевата хипотеза се отхвърля и се приема алтернативната - за статистическата значимост на параметъра.
 Да продължим с примера. В таблица 7.1 колона “B” показва стойностите на параметрите, а колоната Std.Err.ofB показва стойностите на стандартните грешки на параметрите ( ), в колоната t(77 – брой степени на свобода) стойностите на t - статистика се изчисляват, като се вземе предвид броят на степени на свобода. За да се оцени статистическата значимост на параметрите, изчислените стойности на t - статистиката трябва да се сравнят с табличната стойност. Посоченото ниво на значимост (0,05) в таблицата за нормално разпределение съответства на t = 1,96. От 18.02, 10.84, т.е. , трябва да се признае статистическата значимост на получените стойности на параметрите, т.е. тези стойности се формират под въздействието на неслучайни фактори и отразяват тенденцията на връзката между анализираните показатели.
Да продължим с примера. В таблица 7.1 колона “B” показва стойностите на параметрите, а колоната Std.Err.ofB показва стойностите на стандартните грешки на параметрите ( ), в колоната t(77 – брой степени на свобода) стойностите на t - статистика се изчисляват, като се вземе предвид броят на степени на свобода. За да се оцени статистическата значимост на параметрите, изчислените стойности на t - статистиката трябва да се сравнят с табличната стойност. Посоченото ниво на значимост (0,05) в таблицата за нормално разпределение съответства на t = 1,96. От 18.02, 10.84, т.е. , трябва да се признае статистическата значимост на получените стойности на параметрите, т.е. тези стойности се формират под въздействието на неслучайни фактори и отразяват тенденцията на връзката между анализираните показатели.
За да оценим статистическата значимост на уравнението като цяло, нека се обърнем към стойността на F теста на Фишер (вижте таблица 7.1). Изчислената стойност на F-критерия = 117,51, табличната стойност на критерия, базирана на съответния брой степени на свобода (за факторна дисперсия d.f. =1, за остатъчна дисперсия d.f. =77), е равна на 4,00 (вижте приложението .... .). По този начин,  , следователно уравнението на регресията като цяло е статистически значимо. В такава ситуация може да се говори за статистическа значимост на стойността на коефициента на детерминация, т.е. 60% от вариациите в доходите на глава от населението в регионите на Русия могат да се обяснят с вариациите в обема на брутния регионален продукт на глава от населението.
, следователно уравнението на регресията като цяло е статистически значимо. В такава ситуация може да се говори за статистическа значимост на стойността на коефициента на детерминация, т.е. 60% от вариациите в доходите на глава от населението в регионите на Русия могат да се обяснят с вариациите в обема на брутния регионален продукт на глава от населението.
Чрез оценка на статистическата значимост на регресионното уравнение и неговите параметри можем да получим различна комбинация от резултати.
· Уравнението според F-теста е статистически значимо и всички параметри на уравнението според t-статистиката също са статистически значими. Това уравнение може да се използва както за вземане на управленски решения (кои фактори трябва да бъдат повлияни, за да се получи желаният резултат), така и за прогнозиране на поведението на резултатния признак при определени стойности на факторите.
· Според F-теста уравнението е статистически значимо, но параметрите (параметър) на уравнението са незначими. Уравнението може да се използва за вземане на управленски решения (свързани с тези фактори, за които е получено потвърждение за статистическата значимост на тяхното влияние), но уравнението не може да се използва за прогнозиране.
· Уравнението на F-теста е статистически незначимо. Уравнението не може да се използва. Трябва да се продължи търсенето на значими знаци-фактори или аналитична форма на връзка между аргумент и отговор.
Ако статистическата значимост на уравнението и неговите параметри се потвърди, тогава може да се реализира така наречената точкова прогноза, т.е. Получена е оценка на стойността на резултатната характеристика (y) за определени стойности на фактора (x).
Съвсем очевидно е, че прогнозираната стойност на зависимата променлива, изчислена въз основа на уравнението на връзката, няма да съвпадне с нейната действителна стойност (  ) Графично тази ситуация се потвърждава от факта, че не всички точки на корелационното поле лежат на линията на регресия; само с функционална връзка линията на регресия ще премине през всички точки на диаграмата на разсейване. Наличието на несъответствия между действителните и теоретичните стойности на зависимата променлива се свързва преди всичко със самата същност на корелационната зависимост: в същото време резултатът се влияе от много фактори, от които само част могат да бъдат взети предвид в конкретно комуникационно уравнение. В допълнение, формата на връзката между резултата и фактора (тип регресионно уравнение) може да бъде избрана неправилно. В тази връзка възниква въпросът колко информативно е построеното уравнение на свързване. Два показателя отговарят на този въпрос: коефициентът на определяне (вече обсъден по-горе) и стандартната грешка на оценката.
) Графично тази ситуация се потвърждава от факта, че не всички точки на корелационното поле лежат на линията на регресия; само с функционална връзка линията на регресия ще премине през всички точки на диаграмата на разсейване. Наличието на несъответствия между действителните и теоретичните стойности на зависимата променлива се свързва преди всичко със самата същност на корелационната зависимост: в същото време резултатът се влияе от много фактори, от които само част могат да бъдат взети предвид в конкретно комуникационно уравнение. В допълнение, формата на връзката между резултата и фактора (тип регресионно уравнение) може да бъде избрана неправилно. В тази връзка възниква въпросът колко информативно е построеното уравнение на свързване. Два показателя отговарят на този въпрос: коефициентът на определяне (вече обсъден по-горе) и стандартната грешка на оценката.
Разликата между действителните и теоретичните стойности на зависимата променлива се нарича отклонения или грешки или остатъци. Въз основа на тези стойности се изчислява остатъчната дисперсия. Корен квадратенот остатъчната дисперсия и е средна квадратична (стандартна) грешка при оценка:
 =
=  (7.8)
(7.8)
Стандартната грешка на уравнението се измерва в същите единици като предвидената стойност. Ако грешките в уравнението следват нормално разпределение (за големи количества данни), тогава 95 процента от стойностите трябва да са в рамките на 2S от регресионната линия (въз основа на свойството на нормалното разпределение - правилото на трите сигми) . Стойността на стандартната грешка на оценката се използва при изчисляване на доверителните интервали при прогнозиране на стойността на характеристика - резултат за конкретна единица от съвкупността.
В практическите изследвания често има нужда да се предвиди средната стойност на характеристика - резултат за определена стойност на характеристиката - фактор. В този случай, при изчисляване на доверителния интервал за средната стойност на зависимата променлива ()
стойността се взема предвид средна грешка:
 (7.9)
(7.9)
Използването на различни стойности на грешката се обяснява с факта, че променливостта на нивата на индикатора в определени единици от популацията е много по-висока от променливостта на средната стойност, следователно грешката при прогнозиране на средната стойност е по-малка.
Доверителен интервал за прогнозиране на средната стойност на зависимата променлива:
 , (7.10)
, (7.10)
Където  - пределна грешкаоценки (вижте теория на извадката); t – коефициент на доверие, чиято стойност е в съответната таблица, въз основа на нивото на вероятност (брой степени на свобода), прието от изследователя (вижте теорията на вземането на проби).
- пределна грешкаоценки (вижте теория на извадката); t – коефициент на доверие, чиято стойност е в съответната таблица, въз основа на нивото на вероятност (брой степени на свобода), прието от изследователя (вижте теорията на вземането на проби).
Доверителният интервал за прогнозираната стойност на характеристиката на резултата може също да бъде изчислен, като се вземе предвид корекцията за отклонението (отместването) на регресионната линия. Стойността на корекционния коефициент се определя:
 (7.11)
(7.11)
където е стойността на факторната характеристика, въз основа на която се прогнозира стойността на резултатната характеристика.
 От това следва, че колкото повече стойността се различава от средната стойност на факторния признак, толкова по-голяма стойносткоригиращ фактор, толкова по-голяма е грешката в прогнозата. Като се вземе предвид този коефициент, ще се изчисли доверителният интервал на прогнозата:
От това следва, че колкото повече стойността се различава от средната стойност на факторния признак, толкова по-голяма стойносткоригиращ фактор, толкова по-голяма е грешката в прогнозата. Като се вземе предвид този коефициент, ще се изчисли доверителният интервал на прогнозата:
Точността на прогнозата въз основа на регресионното уравнение може да бъде повлияна от различни причини. На първо място, трябва да се има предвид, че оценката на качеството на уравнението и неговите параметри се извършва въз основа на предположението, че нормална дистрибуцияпроизволни остатъци. Нарушаването на това предположение може да се дължи на наличието на рязко различни стойности в данните, неравномерна вариация или наличие на нелинейна връзка. В този случай качеството на прогнозата намалява. Втората точка, която трябва да запомните, е, че стойностите на факторите, взети предвид при прогнозиране на резултата, не трябва да надхвърлят диапазона на вариация в данните, на които се основава уравнението.
©2015-2019 сайт
Всички права принадлежат на техните автори. Този сайт не претендира за авторство, но предоставя безплатно използване.
Дата на създаване на страницата: 2018-01-08
След оценка на параметрите аИ b, получихме регресионно уравнение, чрез което можем да оценим стойностите гспоред зададени стойности х. Естествено е да се вярва, че изчислените стойности на зависимата променлива няма да съвпадат с действителните стойности, тъй като регресионната линия описва връзката само средно, като цяло. Около него са разпръснати отделни значения. По този начин надеждността на изчислените стойности, получени от регресионното уравнение, до голяма степен се определя от разсейването на наблюдаваните стойности около регресионната линия. На практика, като правило, дисперсията на грешката е неизвестна и се оценява от наблюдения едновременно с параметрите на регресията аИ b. Съвсем логично е да се предположи, че оценката е свързана със сумата от квадратите на регресионните остатъци. Количеството е примерна оценка на дисперсията на смущенията, съдържащи се в теоретичен модел ![]() . Може да се покаже, че за сдвоения регресионен модел
. Може да се покаже, че за сдвоения регресионен модел
където е отклонението на действителната стойност на зависимата променлива от нейната изчислена стойност.
Ако ![]() , тогава за всички наблюдения действителните стойности на зависимата променлива съвпадат с изчислените (теоретични) стойности .
Графично това означава, че теоретичната регресионна линия (линия, построена с помощта на функцията) минава през всички точки на корелационното поле, което е възможно само при строго функционална връзка. Следователно ефективният знак присе дължи изцяло на влиянието на фактора Х.
, тогава за всички наблюдения действителните стойности на зависимата променлива съвпадат с изчислените (теоретични) стойности .
Графично това означава, че теоретичната регресионна линия (линия, построена с помощта на функцията) минава през всички точки на корелационното поле, което е възможно само при строго функционална връзка. Следователно ефективният знак присе дължи изцяло на влиянието на фактора Х.
Обикновено на практика има известно разсейване на точките на корелационното поле спрямо теоретичната регресионна линия, т.е. отклонения на емпиричните данни от теоретичните. Това разсейване се дължи както на влиянието на фактора х, т.е. регресия гот х, (такава вариация се нарича обяснена, тъй като се обяснява с уравнението на регресията), и от действието на други причини (необяснима вариация, случайна). Големината на тези отклонения е основата за изчисляване на качествените показатели на уравнението.
Съгласно основния принцип на дисперсионния анализ общата сума на квадратите на отклоненията на зависимата променлива гот средната стойност може да се разложи на два компонента: обяснен с регресионното уравнение и необяснен:
 ,
,
къде са стойностите г, изчислено по уравнението.
Нека намерим съотношението на сбора на квадратите на отклоненията, обяснени от регресионното уравнение, към общия сбор на квадратите:
 , където
, където
 . (7.6)
. (7.6)
Съотношението на частта от дисперсията, обяснена от регресионното уравнение към обща дисперсияефективната характеристика се нарича коефициент на детерминация. Стойността не може да надвишава единица и тази максимална стойност ще бъде постигната само при , т.е. когато всяко отклонение е нула и следователно всички точки на диаграмата на разсейване лежат точно на права линия.
Коефициентът на детерминация характеризира дела на дисперсията, обяснена с регресия в общата дисперсия на зависимата променлива . Съответно, стойността характеризира дела на вариация (дисперсия) y,необяснени от уравнението на регресията и следователно причинени от влиянието на други фактори, които не са взети предвид в модела. Колкото по-близо до единството, толкова по-високо е качеството на модела.
При сдвоена линейна регресия коефициентът на детерминация равно на квадратдвойки линеен коефициенткорелации: .
Коренът на този коефициент на определяне е коефициентът (индекс) множествена корелация, или теоретично корелационна връзка.
За да разберете дали стойността на коефициента на детерминация, получена при оценяване на регресията, наистина отразява истинската връзка между гИ хпроверете значимостта на построеното уравнение като цяло и отделни параметри. Тестването на значимостта на регресионно уравнение ви позволява да разберете дали регресионното уравнение е подходящо за практическа употреба, като например прогнозиране, или не.
В същото време се излага основната хипотеза за незначимостта на уравнението като цяло, което формално се свежда до хипотезата, че параметрите на регресията са равни на нула или, което е същото, че коефициентът на детерминация е равен до нула: . Алтернативна хипотеза за значимостта на уравнението е хипотезата, че регресионните параметри не са равни на нула или че коефициентът на детерминация не е равен на нула: .
За да тествате значимостта на регресионния модел, използвайте Ф-Критерият на Фишер, изчислен като съотношението на сумата от квадрати (за една независима променлива) към остатъчната сума от квадрати (за една степен на свобода):
 , (7.7)
, (7.7)
Където к– брой независими променливи.
След разделяне на числителя и знаменателя на отношението (7.7) на обща сумаквадратни отклонения на зависимата променлива, Ф-критерият може да бъде еквивалентно изразен въз основа на коефициента:
 .
.
Ако нулевата хипотеза е вярна, тогава дисперсията, обяснена от уравнението на регресията, и необяснимата (остатъчна) дисперсия не се различават една от друга.
Прогнозна стойност Ф-критерият се сравнява с критичната стойност, която зависи от броя на независимите променливи к, и от броя на степените на свобода (n-k-1). Таблица (критична) стойност Ф-критерият е максималната стойност на съотношението на дисперсии, която може да възникне, ако те се разминават произволно за дадено ниво на вероятност на нулевата хипотеза. Ако изчислената стойност Ф-критерий е по-голям от табличния при дадено ниво на значимост, тогава се отхвърля нулевата хипотеза за липса на връзка и се прави извод за значимостта на тази връзка, т.е. моделът се счита за значим.
За сдвоен регресионен модел
 .
.
При линейната регресия обикновено се оценява значимостта не само на уравнението като цяло, но и на неговите отделни коефициенти. За да направите това, се определя стандартната грешка на всеки параметър. Стандартните грешки на регресионните коефициенти на параметрите се определят по формулите:
 , (7.8)
, (7.8)
 (7.9)
(7.9)
Стандартните грешки на регресионните коефициенти или стандартните отклонения, изчислени с помощта на формули (7.8,7.9), като правило, са дадени в резултатите от изчисляването на регресионния модел в статистически пакети.
Въз основа на средните квадратични грешки на регресионните коефициенти, значимостта на тези коефициенти се проверява с помощта на обичайната схема за тестване на статистически хипотези.
Основната хипотеза е, че „истинският” регресионен коефициент се различава незначително от нула. Алтернативна хипотеза в този случай е противоположната хипотеза, т.е. че „истинският“ регресионен параметър не е равен на нула. Тази хипотеза се тества с помощта на T-статистика, която има T-Разпределение на студентите:
След това изчислените стойности T-статистиката се сравнява с критични стойности T-статистически данни, определени от таблиците за разпределение на Student. Критичната стойност се определя в зависимост от нивото на значимост α и броя на степените на свобода, който е равен на (n-k-1), n -брой наблюдения, к- брой независими променливи. В случай на линейна регресия по двойки, броят на степените на свобода е (П- 2). Критичната стойност може да се изчисли и на компютър с помощта на вградената функция STUDARCOVER в пакета Excel.
Ако изчислената стойност T-статистиката е повече от критична, тогава основната хипотеза се отхвърля и се смята, че с вероятност (1-α)„истинският” регресионен коефициент е значително различен от нула, което е статистическо потвърждение за съществуването на линейна зависимост на съответните променливи.
Ако изчислената стойност T-статистиката е по-малко от критична, тогава няма причина да се отхвърли основната хипотеза, т.е. „истинският“ коефициент на регресия не се различава значително от нула на ниво на значимост α . В този случай факторът, съответстващ на този коефициент, трябва да бъде изключен от модела.
Значимостта на регресионния коефициент може да се установи чрез конструиране на доверителен интервал. Доверителен интервал за регресионните параметри аИ bопределени, както следва:
![]() ,
,
![]() ,
,
където се определя от таблицата за разпределение на Student за нивото на значимост α и брой степени на свобода (П- 2) за сдвоена регресия.
Тъй като регресионните коефициенти в иконометричните изследвания имат ясна икономическа интерпретация, доверителните интервали не трябва да съдържат нула. Истинската стойност на коефициента на регресия не може да съдържа едновременно положителни и отрицателни стойности, включително нула, в противен случай получаваме противоречиви резултати при икономическо тълкуване на коефициентите, което не може да бъде така. Следователно коефициентът е значим, ако полученият доверителен интервал не покрива нула.
Пример 7.4.Според пример 7.1:
а) Изградете сдвоен линеен регресионен модел на зависимостта на печалбата от продажбите от продажната цена, като използвате софтуер за обработка на данни.
б) Оценете значимостта на регресионното уравнение като цяло, като използвате Ф-Критерий на Фишер при а=0,05.
в) Оценете значимостта на използването на коефициентите на регресионния модел T-Тест на студента при а=0,05И а=0,1.
За регресионен анализизползваме стандартен офис програма EXCEL. Ще изградим регресионен модел с помощта на инструмента REGRESSION на настройките на ANALYSIS PACKAGE (фиг. 7.5), който се стартира, както следва:
ServiceData AnalysisREGRESSIONOK.

Фиг.7.5. Използване на инструмента REGRESSION
В диалоговия прозорец РЕГРЕСИЯ, в полето Интервал на въвеждане Y, трябва да въведете адреса на диапазона от клетки, съдържащи зависимата променлива. В полето Интервал на въвеждане X трябва да въведете адресите на един или повече диапазони, съдържащи стойностите на независими променливи.Квадратчето за отметка Етикети в първия ред е активирано, ако са избрани и заглавките на колоните. На фиг. 7.6. показва екранната форма за изчисляване на регресионен модел с помощта на инструмента REGRESSION.

Ориз. 7.6. Изграждане на регресионен модел по двойки с помощта на
Инструмент за РЕГРЕСИЯ
В резултат на инструмента REGRESSION се генерира следният протокол за регресионен анализ (фиг. 7.7).

Ориз. 7.7. Протокол за регресионен анализ
Уравнението за зависимостта на печалбата от продажбите от продажната цена има формата:
Ще оценим значението на регресионното уравнение, използвайки Ф-Тест на Фишер. Значение Ф-Взимаме критерия на Фишер от таблицата " Дисперсионен анализ» EXCEL протокол (фиг. 7.7.). Прогнозна стойност Ф-критерии 53.372. Таблица стойност Ф-критерий на ниво на значимост а=0,05и брой степени на свобода ![]() е 4,964. защото
е 4,964. защото ![]() , тогава уравнението се счита за значимо.
, тогава уравнението се счита за значимо.
Изчислени стойности T t-тестовете на Стюдънт за коефициентите на регресионното уравнение са показани в таблицата с резултатите (фиг. 7.7). Таблица стойност T-Тест на ученика на ниво на значимост а=0,05и 10 степени на свобода е 2,228. За коефициента на регресия а, следователно коефициентът анезначителен. За коефициента на регресия b, следователно, коефициентът bзначително
Оценка на значимостта на параметрите на регресионното уравнение
Значимостта на параметрите на уравнението на линейната регресия се оценява с помощта на теста на Стюдънт:
Ако Tкалк. > T cr, тогава основната хипотеза се приема ( H o), показваща статистическата значимост на регресионните параметри;
Ако Tкалк.< T cr, тогава се приема алтернативната хипотеза ( H 1), което показва статистическата незначимост на регресионните параметри.
Където m a , m b– стандартни грешки на параметрите аИ б:
 (2.19)
(2.19)
 (2.20)
(2.20)
Критичната (таблична) стойност на критерия се намира с помощта на статистически таблици на разпределението на Стюдънт (Приложение Б) или с помощта на таблици Excel(раздел на съветника за функцията „Статистически“):
T cr = STUDARSOBR( а=1-Р; k=n-2), (2.21)
Където k=n-2също представлява броя на степените на свобода .
Оценката на статистическата значимост може да се приложи и към коефициента на линейна корелация
Където г-н– стандартна грешка при определяне на стойностите на коефициента на корелация r yx
 (2.23)
(2.23)
По-долу има опции за задачи за практически и лабораторна работапо темите от втори раздел.
Въпроси за самопроверка за раздел 2
1. Посочете основните компоненти на иконометричния модел и тяхната същност.
2. Основното съдържание на етапите на иконометричното изследване.
3. Същността на подходите за определяне на параметрите на линейната регресия.
4. Същността и особеностите на използването на метода на най-малките квадрати при определяне на параметрите на регресионното уравнение.
5. Какви показатели се използват за оценка на близостта на връзката между изследваните фактори?
6. Същност на линейния коефициент на корелация.
7. Същност на коефициента на детерминация.
8. Същността и основните характеристики на процедурите за оценка на адекватността (статистическата значимост) на регресионните модели.
9. Оценка на адекватността на линейните регресионни модели чрез коефициента на апроксимация.
10. Същността на подхода за оценка на адекватността на регресионните модели с помощта на критерия на Фишер. Определяне на стойности на емпирични и критични критерии.
11. Същността на понятието „вариантен анализ” във връзка с иконометричните изследвания.
12. Същността и основните характеристики на процедурата за оценка на значимостта на параметрите на уравнение на линейна регресия.
13. Характеристики на използването на разпределението на Стюдънт при оценка на значимостта на параметрите на уравнение на линейна регресия.
14. Каква е задачата за прогнозиране на единични стойности на изследваното социално-икономическо явление?
1. Конструиране на корелационно поле и формулиране на предположение за формата на уравнението за връзката на изследваните фактори;
2. Запишете основните уравнения на метода на най-малките квадрати, направете необходимите трансформации, съставете таблица за междинни изчисления и определете параметрите на уравнението на линейната регресия;
3. Проверете правилността на изчисленията, като използвате стандартни процедури и функции на електронни таблици на Excel.
4. Анализирайте резултатите, формулирайте изводи и препоръки.
1. Изчисляване на стойността на коефициента на линейна корелация;
2. Изграждане на дисперсионна таблица за анализ;
3. Оценка на коефициента на детерминация;
4. Проверете коректността на изчисленията с помощта на стандартни процедури и функции на електронни таблици на Excel.
5. Анализирайте резултатите, формулирайте изводи и препоръки.
4. Поведение обща класацияадекватност на избраното регресионно уравнение;
1. Оценка на адекватността на уравнението въз основа на стойностите на коефициента на приближение;
2. Оценка на адекватността на уравнението въз основа на стойностите на коефициента на детерминация;
3. Оценка на адекватността на уравнението с помощта на критерия на Фишер;
4. Извършване на обща оценка на адекватността на параметрите на регресионното уравнение;
5. Проверете коректността на изчисленията с помощта на стандартни процедури и функции на електронни таблици на Excel.
6. Анализирайте резултатите, формулирайте изводи и препоръки.
1. Използване на стандартни процедури на Excel Spreadsheet Functions Wizard (от раздели „Математически” и „Статистически”);
2. Подготовка на данни и особености на използване на функцията LINEST;
3. Подготовка на данни и характеристики на използването на функцията „ПРЕДВИЖДАНЕ“.
1. Използване на стандартни процедури на пакета за анализ на данни от електронни таблици на Excel;
2. Подготовка на данни и особености на прилагане на процедурата „РЕГРЕСИЯ”;
3. Интерпретация и синтез на данни от таблици за регресионен анализ;
4. Интерпретация и синтез на данни от дисперсионния анализ на таблицата;
5. Интерпретация и обобщение на данни от таблицата за оценка на значимостта на параметрите на регресионното уравнение;
Когато изпълнявате лабораторна работа въз основа на една от опциите, трябва да изпълните следните конкретни задачи:
1. Изберете формата на уравнението за връзката на изследваните фактори;
2. Определяне на параметрите на регресионното уравнение;
3. Оценка на тясната връзка на изследваните фактори;
4. Оценка на адекватността на избраното регресионно уравнение;
5. Оценете статистическата значимост на параметрите на регресионното уравнение.
6. Проверете правилността на изчисленията, като използвате стандартни процедури и функции на електронни таблици на Excel.
7. Анализирайте резултатите, формулирайте изводи и препоръки.
Задачи за практическа и лабораторна работа по темата „Парна баня“ линейна регресияи корелация в иконометричните изследвания.“
| Опция 1 | Вариант 2 | Вариант 3 | Вариант 4 | Вариант 5 | |||||
| х | г | х | г | х | г | х | г | х | г |
| Вариант 6 | Вариант 7 | Вариант 8 | Вариант 9 | Вариант 10 | |||||
| х | г | х | г | х | г | х | г | х | г |
За оценка на значимостта и значимостта на коефициента на корелация се използва t-тестът на Student.
Средната грешка на коефициента на корелация се намира по формулата:
н  и въз основа на грешката се изчислява t-критерият:
и въз основа на грешката се изчислява t-критерият:
Изчислената стойност на t-теста се сравнява с табличната стойност, намерена в таблицата за разпределение на Стюдънт при ниво на значимост 0,05 или 0,01 и брой степени на свобода n-1. Ако изчислената стойност на t-теста е по-голяма от стойността в таблицата, тогава коефициентът на корелация се счита за значим.
В случай на криволинейна връзка, F-тестът се използва за оценка на значимостта на корелационната връзка и регресионното уравнение. Изчислява се по формулата:

или 
където η е съотношението на корелация; n – брой наблюдения; m – брой параметри в регресионното уравнение.
Изчислената F стойност се сравнява с табличната за приетото ниво на значимост α (0,05 или 0,01) и броя на степените на свобода k 1 =m-1 и k 2 =n-m. Ако изчислената стойност на F надвишава табличната, връзката се счита за значима.
Значимостта на регресионния коефициент се установява с помощта на t-теста на Student, който се изчислява по формулата:

където σ 2 и i е дисперсията на регресионния коефициент.
Изчислява се по формулата:

където k е броят на факторните характеристики в регресионното уравнение.
Коефициентът на регресия се счита за значим, ако t a 1 ≥t cr. t cr се намира в таблицата на критичните точки на разпределението на Стюдънт при приетото ниво на значимост и броя на степените на свобода k=n-1.
4.3 Корелационен и регресионен анализ в Excel
Нека проведем корелационен и регресионен анализ на връзката между добива и разходите за труд на 1 центнер зърно. За да направите това, отворете лист на Excel и въведете стойностите на факторната характеристика в клетки A1: A30 – добива на зърнени култури, в клетки B1:B30, стойността на получената характеристика е цената на труда за 1 центнер зърно. В менюто Инструменти изберете опцията Анализ на данни. Щраквайки с левия бутон върху този елемент, ще отворим инструмента за регресия. Щракнете върху бутона OK и диалоговият прозорец Regression се появява на екрана. В полето Интервал на въвеждане Y въведете стойностите на резултантната характеристика (маркиране на клетки B1: B30), в полето Интервал на въвеждане X въведете стойностите на факторната характеристика (маркиране на клетки A1: A30). Маркирайте нивото на вероятност от 95% и изберете Нов работен лист. Кликнете върху бутона OK. На работния лист се появява таблицата „ЗАКЛЮЧЕНИЕ НА РЕЗУЛТАТИТЕ“, която показва резултатите от изчисляването на параметрите на регресионното уравнение, коефициента на корелация и други показатели, които ви позволяват да определите значимостта на корелационния коефициент и параметрите на регресионното уравнение.
|
ЗАКЛЮЧВАНЕ НА РЕЗУЛТАТИТЕ | ||||||||
|
Регресионна статистика | ||||||||
|
множествено число R | ||||||||
|
R-квадрат | ||||||||
|
Нормализиран R-квадрат | ||||||||
|
Стандартна грешка | ||||||||
|
Наблюдения | ||||||||
|
Дисперсионен анализ | ||||||||
|
Значение F | ||||||||
|
Регресия | ||||||||
|
Коефициенти |
Стандартна грешка |
t-статистика |
P-стойност |
Долни 95% |
Топ 95% |
Най-ниски 95,0% |
Топ 95,0% |
|
|
Y-пресечка | ||||||||
|
Променлива X 1 | ||||||||
В тази таблица „Множество R“ е коефициентът на корелация, „R-квадрат“ е коефициентът на определяне. “Коефициенти: Y-пресечна” - свободен член на регресионното уравнение 2.836242; “Променлива X1” – регресионен коефициент -0.06654. Има и стойности на F-тест на Fisher 74.9876, t-тест на Student 14.18042, „Стандартна грешка 0.112121“, които са необходими за оценка на значимостта на корелационния коефициент, параметрите на регресионното уравнение и цялото уравнение.
Въз основа на данните в таблицата ще изградим регресионно уравнение: y x = 2.836-0.067x. Коефициентът на регресия a 1 = -0,067 означава, че при увеличаване на добива на зърно с 1 ц/ха разходите за труд за 1 ц зърно намаляват с 0,067 човекочаса.
Коефициентът на корелация е r=0,85>0,7, следователно връзката между изследваните характеристики в тази популация е тясна. Коефициентът на детерминация r 2 =0,73 показва, че 73% от изменението на ефективния признак (разходите на труд за 1 ц зърно) се дължи на действието на факторния признак (добив на зърно).
На масата критични точкиразпределението на Fisher - Snedekor намираме критичната стойност на F-теста при ниво на значимост 0,05 и броя на степените на свобода до 1 =m-1=2-1=1 и k 2 =n-m=30-2= 28, то е равно на 4,21. Тъй като изчислената стойност на критерия е по-голяма от табличната (F=74.9896>4.21), регресионното уравнение се счита за значимо.
За да оценим значимостта на коефициента на корелация, нека изчислим t-теста на Student:
IN  В таблицата на критичните точки на разпределението на Стюдънт намираме критичната стойност на t-теста при ниво на значимост 0,05 и броя на степените на свобода n-1=30-1=29, той е равен на 2,0452. Тъй като изчислената стойност е по-голяма от стойността в таблицата, коефициентът на корелация е значителен.
В таблицата на критичните точки на разпределението на Стюдънт намираме критичната стойност на t-теста при ниво на значимост 0,05 и броя на степените на свобода n-1=30-1=29, той е равен на 2,0452. Тъй като изчислената стойност е по-голяма от стойността в таблицата, коефициентът на корелация е значителен.
