F-тестът на Fisher се използва за оценка на значимостта. Тест на Фишер и частичен тест на Фишер за уравнение на множествена регресия
Критерий на Фишер
Тестът на Фишер се използва за проверка на хипотезата за равенството на дисперсиите на две популации, разпределени в нормален закон. Това е параметричен критерий.
Тестът на Fisher F се нарича коефициент на дисперсия, тъй като се формира като съотношение на две безпристрастни оценки на дисперсиите, които се сравняват.
Нека в резултат на наблюденията се получат две проби. От тях вариациите и  имайки
имайки  И
И  степени на свобода. Ще приемем, че първата проба е взета от популация с дисперсия
степени на свобода. Ще приемем, че първата проба е взета от популация с дисперсия  , а вторият е от генералната съвкупност с дисперсия
, а вторият е от генералната съвкупност с дисперсия  . Излага се нулева хипотеза за равенството на двете дисперсии, т.е. H0:
. Излага се нулева хипотеза за равенството на двете дисперсии, т.е. H0:  или . За да се отхвърли тази хипотеза, е необходимо да се докаже значимостта на разликата при дадено ниво на значимост
или . За да се отхвърли тази хипотеза, е необходимо да се докаже значимостта на разликата при дадено ниво на значимост  .
.
Стойността на критерия се изчислява по формулата:
Очевидно, ако дисперсиите са равни, стойността на критерия ще бъде равна на единица. В други случаи ще бъде по-голямо (по-малко) от едно.
Тестът има разпределение на Фишер  . Тест на Фишер - двустранен тест и нулева хипотеза
. Тест на Фишер - двустранен тест и нулева хипотеза  отхвърлен в полза на алтернатива
отхвърлен в полза на алтернатива  ако . Ето къде
ако . Ето къде  – обемът съответно на първата и втората проба.
– обемът съответно на първата и втората проба.
Системата STATISTICA реализира едностранен тест на Фишер, т.е. максималната дисперсия винаги се приема като качество. В този случай нулевата хипотеза се отхвърля в полза на алтернативата ако.
Пример
Нека поставим задачата да сравним ефективността на обучението на две групи ученици. Нивото на постижения характеризира нивото на управление на процеса на обучение, а дисперсията е качеството на управление на обучението, степента на организация на процеса на обучение. И двата индикатора са независими и общ случайтрябва да се разглеждат заедно. Нивото на академичните постижения (математическо очакване) на всяка група ученици се характеризира със средни аритметични стойности  и , а качеството се характеризира със съответните извадкови дисперсии на оценките: и . При оценката на нивото на текущото представяне се оказа, че то е еднакво и за двамата ученици:
и , а качеството се характеризира със съответните извадкови дисперсии на оценките: и . При оценката на нивото на текущото представяне се оказа, че то е еднакво и за двамата ученици:  = = 4,0. Примерни отклонения:
= = 4,0. Примерни отклонения: 
 И
И  . Числа на степените на свобода, съответстващи на тези оценки:
. Числа на степените на свобода, съответстващи на тези оценки:  И
И  . Оттук, за да установим разликите в ефективността на ученето, можем да използваме стабилността на академичното представяне, т.е. Нека проверим хипотезата.
. Оттук, за да установим разликите в ефективността на ученето, можем да използваме стабилността на академичното представяне, т.е. Нека проверим хипотезата.
Нека изчислим  (трябва да има голямо отклонение в числителя), . Според таблиците ( STATISTICA –
ВероятностРазпределениеКалкулатор)
намираме , което е по-малко от изчисленото, следователно нулевата хипотеза трябва да бъде отхвърлена в полза на алтернативата. Това заключение може да не задоволи изследователя, тъй като той се интересува от истинската стойност на съотношението
(трябва да има голямо отклонение в числителя), . Според таблиците ( STATISTICA –
ВероятностРазпределениеКалкулатор)
намираме , което е по-малко от изчисленото, следователно нулевата хипотеза трябва да бъде отхвърлена в полза на алтернативата. Това заключение може да не задоволи изследователя, тъй като той се интересува от истинската стойност на съотношението  (винаги имаме голямо отклонение в числителя). При проверка на едностранен критерий получаваме, че е по-малко от изчислената по-горе стойност. Така че нулевата хипотеза трябва да бъде отхвърлена в полза на алтернативата.
(винаги имаме голямо отклонение в числителя). При проверка на едностранен критерий получаваме, че е по-малко от изчислената по-горе стойност. Така че нулевата хипотеза трябва да бъде отхвърлена в полза на алтернативата.
Тест на Fisher в програма STATISTICA в Windows среда
За пример за тестване на хипотеза (критерий на Фишер), ние използваме (създаваме) файл с две променливи (fisher.sta):
Ориз. 1. Таблица с две независими променливи
За да се провери хипотезата е необходимо в основни статистики ( ОсновенСтатистикаиМаси) изберете t-тест за независими променливи. ( t-тест, независим, по променливи).

Ориз. 2. Тестване на параметрични хипотези
След като изберете променливи и натиснете клавиша РезюмеИзчисляват се стойностите на стандартните отклонения и критерия на Фишер. Освен това се определя нивото на значимост стр, при което разликата е незначителна.

Ориз. 3. Резултати от тестване на хипотези (F-тест)
Използвайки ВероятностКалкулатори като зададете стойностите на параметрите, можете да изградите графика на разпределението на Фишер с маркирана изчислена стойност.

Ориз. 4. Област на приемане (отхвърляне) на хипотезата (F-критерий)
Източници.
Тестване на хипотези за връзката между две дисперсии
URL: /tryfonov3/terms3/testdi.htm
Лекция 6. :8080/resources/math/mop/lections/lection_6.htm
F – Критерий на Фишер
URL: /home/portal/applications/Multivariatadvisor/F-Fisher/F-Fisheer.htm
Теория и практика на вероятностните статистически изследвания.
URL: /active/referats/read/doc-3663-1.html
F – Критерий на Фишер
Критерий на Фишерви позволява да сравните дисперсиите на извадката на две независими извадки. За да изчислите F emp, трябва да намерите съотношението на дисперсиите на две проби, така че по-голямата дисперсия да е в числителя, а по-малката - в знаменателя. Формулата за изчисляване на критерия на Фишер е:
където са дисперсиите съответно на първата и втората извадка.
Тъй като според условията на критерия стойността на числителя трябва да бъде по-голяма или равна на стойността на знаменателя, стойността на F emp винаги ще бъде по-голяма или равна на единица.
Броят на степените на свобода също се определя просто:
к 1 =n л - 1 за първата проба (т.е. за пробата, чиято дисперсия е по-голяма) и к 2 = н 2 - 1 за втората проба.
В Приложение 1 критичните стойности на критерия на Фишер се намират чрез стойностите на k 1 (горния ред на таблицата) и k 2 (лявата колона на таблицата).
Ако t em >t crit, тогава нулевата хипотеза се приема, в противен случай се приема алтернативата.
Пример 3.В два трети класа десет ученици бяха изследвани за умствено развитие с помощта на теста TURMSH. Получените средни стойности не се различават значително, но психологът се интересува от въпроса дали има разлики в степента на хомогенност на показателите за умствено развитие между класовете.
Решение. За теста на Фишер е необходимо да се сравнят дисперсиите на резултатите от тестовете в двата класа. Резултатите от теста са представени в таблицата:
Таблица 3.
|
Студентски номера |
Първи клас |
Втори клас |
След като изчислим дисперсиите за променливите X и Y, получаваме:
с х 2 =572.83; с г 2 =174,04
След това, използвайки формула (8) за изчисление, използвайки F критерия на Фишер, намираме:
![]()
Според таблицата от Приложение 1 за критерия F със степени на свобода и в двата случая k = 10 - 1 = 9 намираме F crit = 3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Непараметрични тестове
Сравнявайки на око (в проценти) резултатите преди и след всяко въздействие, изследователят стига до извода, че ако се наблюдават разлики, значи има разлика в сравняваните проби. Този подход е категорично неприемлив, тъй като за проценти е невъзможно да се определи нивото на надеждност в разликите. Процентите, взети сами по себе си, не позволяват да се направят статистически надеждни заключения. За да се докаже ефективността на всяка интервенция, е необходимо да се идентифицира статистически значима тенденция в отклонението (изместването) на индикаторите. За да разреши такива проблеми, изследователят може да използва редица критерии за дискриминация. По-долу ще разгледаме непараметрични тестове: знаков тест и хи-квадрат тест.
Значимостта на уравнението на множествената регресия като цяло, както и в сдвоената регресия, се оценява с помощта на критерия на Фишер:
 ,
(2.22)
,
(2.22)
Където  – фактор сбор от квадрати за степен на свобода;
– фактор сбор от квадрати за степен на свобода;  – остатъчна сума от квадрати за степен на свобода;
– остатъчна сума от квадрати за степен на свобода;  – коефициент (индекс) на множествена детерминация;
– коефициент (индекс) на множествена детерминация;  – брой параметри за променливи
– брой параметри за променливи  (при линейна регресия съвпада с броя на факторите, включени в модела);
(при линейна регресия съвпада с броя на факторите, включени в модела);  – брой наблюдения.
– брой наблюдения.
Оценява се значимостта не само на уравнението като цяло, но и на фактора, допълнително включен в регресионния модел. Необходимостта от такава оценка се дължи на факта, че не всеки фактор, включен в модела, може значително да увеличи дела на обяснената вариация в резултантния признак. Освен това, ако има няколко фактора в модела, те могат да бъдат въведени в модела в различни последователности. Поради корелацията между факторите, значимостта на един и същи фактор може да бъде различна в зависимост от последователността на въвеждането му в модела. Мярката за оценка на включването на фактор в модела е частната  -критерий, т.е.
-критерий, т.е.  .
.
Частно  -критерият се основава на сравняване на увеличението на факторната дисперсия поради влиянието на допълнително включен фактор с остатъчната дисперсия за една степен на свобода за регресионния модел като цяло. Най-общо за фактора
-критерият се основава на сравняване на увеличението на факторната дисперсия поради влиянието на допълнително включен фактор с остатъчната дисперсия за една степен на свобода за регресионния модел като цяло. Най-общо за фактора  частен
частен  -критерият ще бъде определен като
-критерият ще бъде определен като
 ,
(2.23)
,
(2.23)
Където  – коефициент на множествена детерминация за модел с пълен набор от фактори,
– коефициент на множествена детерминация за модел с пълен набор от фактори,  – същия показател, но без включване на фактора в модела
– същия показател, но без включване на фактора в модела  ,
, – брой наблюдения,
– брой наблюдения,  – брой параметри в модела (без свободен член).
– брой параметри в модела (без свободен член).
Действителната стойност на коефициента  - критерият се сравнява с таблицата на ниво значимост
- критерият се сравнява с таблицата на ниво значимост  и брой степени на свобода: 1 и
и брой степени на свобода: 1 и  . Ако действителната стойност
. Ако действителната стойност  превишава
превишава  , след това допълнителното включване на фактора
, след това допълнителното включване на фактора  в модела е статистически обоснован и коефициентът на чиста регресия
в модела е статистически обоснован и коефициентът на чиста регресия  при фактор
при фактор  статистически значим. Ако действителната стойност
статистически значим. Ако действителната стойност  е по-малка от табличната стойност, тогава допълнително включване на фактора в модела
е по-малка от табличната стойност, тогава допълнително включване на фактора в модела  не увеличава значително дела на обяснената вариация в черта
не увеличава значително дела на обяснената вариация в черта  следователно е неуместно включването му в модела; Коефициентът на регресия за този фактор в този случай е статистически незначим.
следователно е неуместно включването му в модела; Коефициентът на регресия за този фактор в този случай е статистически незначим.
За двуфакторно уравнение частните  - критериите имат формата:
- критериите имат формата:
 ,
, . (2.23a)
. (2.23a)
Използване на лични  -критерий, може да се провери значимостта на всички регресионни коефициенти при допускането, че всеки съответен фактор
-критерий, може да се провери значимостта на всички регресионни коефициенти при допускането, че всеки съответен фактор  въведени в уравнението на множествената регресия последни.
въведени в уравнението на множествената регресия последни.
-Тест на студент за уравнение на множествена регресия.
Частно  -критерий оценява значимостта на чистите регресионни коефициенти. Познавайки величината
-критерий оценява значимостта на чистите регресионни коефициенти. Познавайки величината  , възможно е да се определи
, възможно е да се определи  -критерий за коефициента на регресия при
-критерий за коефициента на регресия при  -m фактор,
-m фактор,  , а именно:
, а именно:
 .
(2.24)
.
(2.24)
Оценяване на значимостта на чистите коефициенти на регресия чрез  -Тестът на Стюдънт може да се извърши без изчисляване на частичното
-Тестът на Стюдънт може да се извърши без изчисляване на частичното  - критерии. В този случай, както при регресията по двойки, за всеки фактор се използва формулата:
- критерии. В този случай, както при регресията по двойки, за всеки фактор се използва формулата:
 ,
(2.25)
,
(2.25)
Където  – чист коефициент на регресия при фактора
– чист коефициент на регресия при фактора  ,
, – средна квадратична (стандартна) грешка на регресионния коефициент
– средна квадратична (стандартна) грешка на регресионния коефициент  .
.
За уравнение на множествена регресия средната квадратична грешка на регресионния коефициент може да се определи по следната формула:
 ,
(2.26)
,
(2.26)
Където 
 ,
, – стандартно отклонение за характеристиката
– стандартно отклонение за характеристиката  ,
, – коефициент на определяне за уравнението на множествената регресия,
– коефициент на определяне за уравнението на множествената регресия,  – коефициент на детерминация за зависимостта на фактора
– коефициент на детерминация за зависимостта на фактора  с всички други фактори в уравнението на множествената регресия;
с всички други фактори в уравнението на множествената регресия;  – брой степени на свобода за остатъчната сума на квадратите на отклоненията.
– брой степени на свобода за остатъчната сума на квадратите на отклоненията.
Както можете да видите, за да използвате тази формула, имате нужда от междуфакторна корелационна матрица и изчисляването на съответните коефициенти на определяне, използвайки я  . И така, за уравнението
. И така, за уравнението  оценка на значимостта на регресионните коефициенти
оценка на значимостта на регресионните коефициенти  ,
, ,
, включва изчисляването на три коефициента на определяне на междуфактори:
включва изчисляването на три коефициента на определяне на междуфактори:  ,
, ,
, .
.
Връзката между показателите на частичния коефициент на корелация, частична  - критерии и
- критерии и  -Тестът на Стюдънт за коефициенти на чиста регресия може да се използва в процедурата за избор на фактор. Елиминирането на факторите при конструиране на регресионно уравнение по метода на елиминиране може практически да се извърши не само чрез частични коефициенти на корелация, изключвайки на всяка стъпка фактора с най-малката незначителна стойност на частичния коефициент на корелация, но и чрез стойности
-Тестът на Стюдънт за коефициенти на чиста регресия може да се използва в процедурата за избор на фактор. Елиминирането на факторите при конструиране на регресионно уравнение по метода на елиминиране може практически да се извърши не само чрез частични коефициенти на корелация, изключвайки на всяка стъпка фактора с най-малката незначителна стойност на частичния коефициент на корелация, но и чрез стойности  И
И  .
Частно
.
Частно  -критерият се използва широко при конструирането на модел, като се използва методът на включване на променливи и методът на поетапната регресия.
-критерият се използва широко при конструирането на модел, като се използва методът на включване на променливи и методът на поетапната регресия.
Функцията FISCHER връща трансформацията на Fisher на аргументите на X. Тази трансформация създава функция, която има нормално, а не изкривено разпределение. Функцията FISCHER се използва за тестване на хипотезата с помощта на коефициента на корелация.
Описание на функцията FISCHER в Excel
Когато работите с тази функция, трябва да зададете стойността на променливата. Струва си да се отбележи веднага, че има някои ситуации, в които тази функция няма да доведе до резултати. Това е възможно, ако променливата:
- не е число. В такава ситуация функцията FISCHER ще върне стойността на грешка #VALUE!;
- има стойност по-малка от -1 или по-голяма от 1. В този случай функцията FISCHER ще върне стойността за грешка #NUM!.
Уравнението, което се използва за математическо описание на функцията FISCHER е:
Z"=1/2*ln(1+x)/(1-x)
Нека да разгледаме използването на тази функция, използвайки 3 конкретни примера.
Оценка на връзката между печалба и разходи с помощта на функцията FISHER
Пример 1. Използвайки данни за дейността на търговските организации, е необходимо да се направи оценка на връзката между печалбата Y (милиона рубли) и разходите X (милиона рубли), използвани за разработване на продукта (показано в таблица 1).
Таблица 1 – Изходни данни:
| № | х | Y |
| 1 | 210 000 000,00 рубли | 95 000 000,00 рубли |
| 2 | 1 068 000 000,00 рубли | 76 000 000,00 рубли |
| 3 | 1 005 000 000,00 рубли | 78 000 000,00 рубли |
| 4 | 610 000 000,00 рубли | 89 000 000,00 рубли |
| 5 | 768 000 000,00 рубли | 77 000 000,00 рубли |
| 6 | 799 000 000,00 рубли | 85 000 000,00 рубли |
Схемата за решаване на такива проблеми е следната:
- Изчислява се коефициентът на линейна корелация r xy;
- Значимостта на коефициента на линейна корелация се проверява на базата на t-критерия на Стюдънт. В този случай се излага и тества хипотеза, че коефициентът на корелация е равен на нула. T-статистиката се използва за проверка на тази хипотеза. Ако хипотезата се потвърди, t-статистиката има разпределение на Стюдънт. Ако изчислената стойност t p > t cr, тогава хипотезата се отхвърля, което показва значимостта на коефициента на линейна корелация и следователно статистическата значимост на връзката между X и Y;
- Определя се интервална оценка за статистически значим линеен корелационен коефициент.
- Интервална оценка за коефициента на линейна корелация се определя въз основа на обратната z-трансформация на Fisher;
- Изчислява се стандартната грешка на коефициента на линейна корелация.
Резултатите от решаването на този проблем с функциите, използвани в Excel, са показани на фигура 1.

Фигура 1 – Пример за изчисления.
| Не. | Име на индикатора | Формула за изчисление |
| 1 | Коефициент на корелация | =КОРЕЛ(B2:B7;C2:C7) |
| 2 | Изчислена стойност на t-теста tp | =ABS(C8)/SQRT(1-POWER(C8,2))*SQRT(6-2) |
| 3 | Таблични стойности на t-теста trh | =ОТКРИВАНЕ НА ПРОУЧВАНЕ(0,05;4) |
| 4 | Таблични стойности на стандартно нормално разпределение zy | =NORMSINV((0,95+1)/2) |
| 5 | Стойност на трансформация на Fisher z | =FISHER(C8) |
| 6 | Лява оценка на интервала за z | =C12-C11*ROOT(1/(6-3)) |
| 7 | Дясна интервална оценка за z | =C12+C11*ROOT(1/(6-3)) |
| 8 | Лява оценка на интервала за rxy | =FISHEROBR(C13) |
| 9 | Оценка на десния интервал за rxy | =FISHEROBR(C14) |
| 10 | Стандартно отклонение за rxy | =ROOT((1-C8^2)/4) |
По този начин, с вероятност от 0,95, коефициентът на линейна корелация е в диапазона от (–0,386) до (–0,990) със стандартна грешка от 0,205.
Проверка на статистическата значимост на регресията с помощта на функцията FASTER
Пример 2. Проверете статистическата значимост на уравнението на множествената регресия с помощта на F теста на Фишер и направете заключения.
За да проверим значимостта на уравнението като цяло, излагаме хипотезата H 0 за статистическата незначимост на коефициента на детерминация и противоположната хипотеза H 1 за статистическата значимост на коефициента на детерминация:
H 1: R 2 ≠ 0.
Нека проверим хипотезите с помощта на F теста на Фишер. Индикаторите са показани в таблица 2.
Таблица 2 - Изходни данни
За целта използваме функцията в Excel:
ПО-БЪРЗО (α;p;n-p-1)
- α е вероятността, свързана с дадено разпределение;
- p и n са съответно числителят и знаменателят на степените на свобода.
Като знаем, че α = 0,05, p = 2 и n = 53, получаваме следната стойност за F crit (вижте Фигура 2).
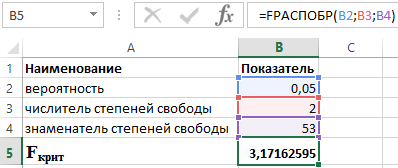
Фигура 2 – Пример за изчисления.
Така можем да кажем, че F изчислено > F критично. В резултат на това се приема хипотезата H 1 за статистическата значимост на коефициента на детерминация.
Изчисляване на стойността на индикатора за корелация в Excel
Пример 3. Използване на данни от 23 предприятия за: X е цената на продукт А, хиляди рубли; Y е печалбата на търговско предприятие, милиони рубли, тяхната зависимост се изучава. Регресионният модел беше оценен както следва: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Какъв корелационен показател може да се определи от тези данни? Изчислете стойността на корелационния индикатор и, като използвате критерия на Фишер, направете заключение за качеството на регресионния модел.
Нека определим F crit от израза:
F изчислено = R 2 /23*(1-R 2)
където R е коефициентът на определяне, равен на 0,67.
Така изчислената стойност F calc = 46.
За да определим F crit, ние използваме разпределението на Fisher (виж Фигура 3).

Фигура 3 – Пример за изчисления.
По този начин получената оценка на регресионното уравнение е надеждна.
За да сравните две нормално разпределени популации, които нямат разлики в извадковите средни стойности, но има разлика в дисперсиите, използвайте Тест на Фишер. Действителният критерий се изчислява по формулата:
където числителят е по-голямата стойност на дисперсията на извадката, а знаменателят е по-малката. За да заключите надеждността на разликите между пробите, използвайте ОСНОВНИЯТ ПРИНЦИП
тестване на статистически хипотези. Критични точки за 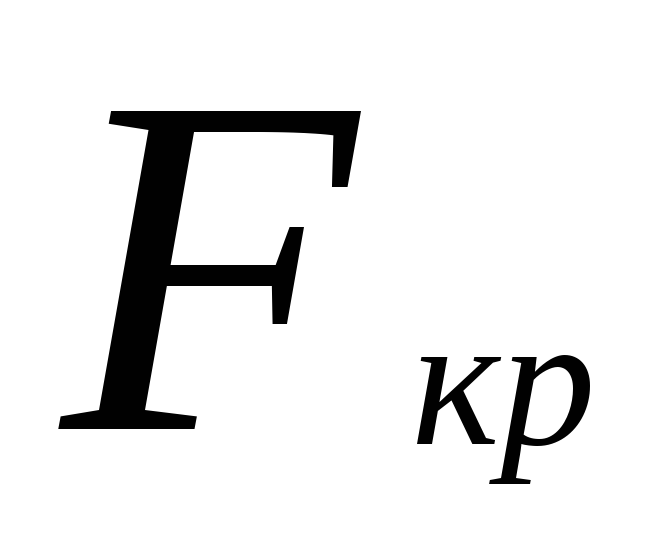 се съдържат в таблицата. Нулевата хипотеза се отхвърля, ако действителната стойност
се съдържат в таблицата. Нулевата хипотеза се отхвърля, ако действителната стойност 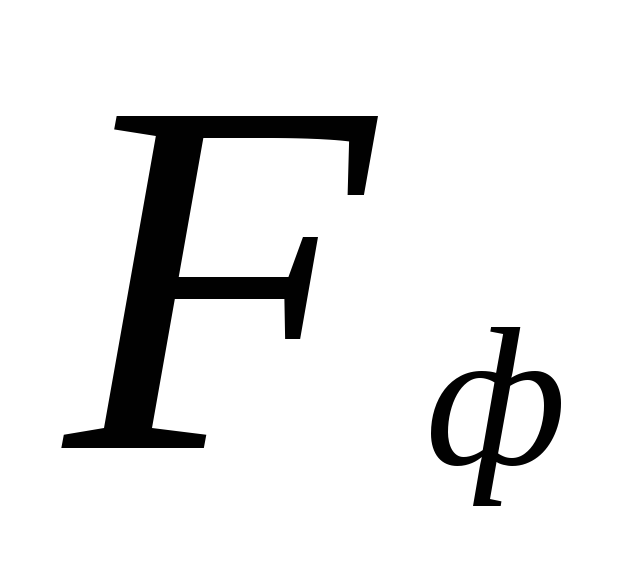 ще надвишава или е равна на критичната (стандартна) стойност
ще надвишава или е равна на критичната (стандартна) стойност  тази стойност за приетото ниво на значимост
и брой степени на свобода к
1
=
н
голям
-1
;
к
2
=
н
по-малък
-1
.
тази стойност за приетото ниво на значимост
и брой степени на свобода к
1
=
н
голям
-1
;
к
2
=
н
по-малък
-1
.
Пример: при изследване на ефекта на определено лекарство върху скоростта на покълване на семената се установи, че в опитната партида семена и контролата средната скорост на кълняемост е една и съща, но има разлика във отклоненията. 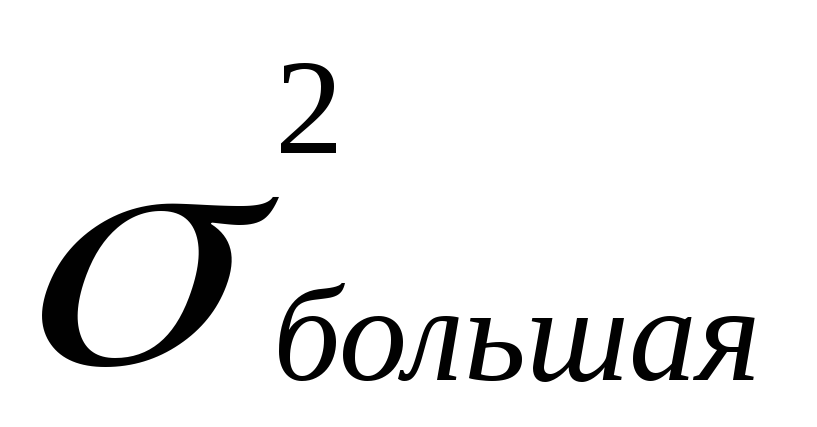 =1250,
=1250, =417. Размерите на извадката са еднакви и равни на 20.
=417. Размерите на извадката са еднакви и равни на 20. 
 =2,12. Следователно нулевата хипотеза се отхвърля.
=2,12. Следователно нулевата хипотеза се отхвърля.
Корелационна зависимост. Коефициент на корелация и неговите свойства. Регресионни уравнения.
ЗАДАЧАкорелационният анализ се свежда до:
Установяване посоката и формата на връзка между характеристиките;
Измерване на неговата плътност.
Функционален Недвусмислена връзка между променливите величини се нарича, когато определена стойност на една (независима) променлива х , наречен аргумент, съответства на определена стойност на друга (зависима) променлива при , наречена функция. ( Пример: зависимост на скоростта на химичната реакция от температурата; зависимост на силата на привличане от масите на привличащите се тела и разстоянието между тях).
Корелация е връзка между променливи, които са статистически по природа, когато определена стойност на една характеристика (разглеждана като независима променлива) съответства на цяла поредица от числови стойности на друга характеристика. ( Пример: връзка между реколтата и валежите; между ръст и тегло и др.).
Корелационно поле представлява набор от точки, чиито координати са равни на експериментално получени двойки променливи стойности х И при .
По вида на корелационното поле може да се прецени наличието или отсъствието на връзка и нейния тип.




Връзката се нарича положителен , ако когато една променлива се увеличава, друга променлива се увеличава.
Връзката се нарича отрицателен , ако когато една променлива нараства, друга променлива намалява.
Връзката се нарича линеен
, ако може да се представи аналитично като 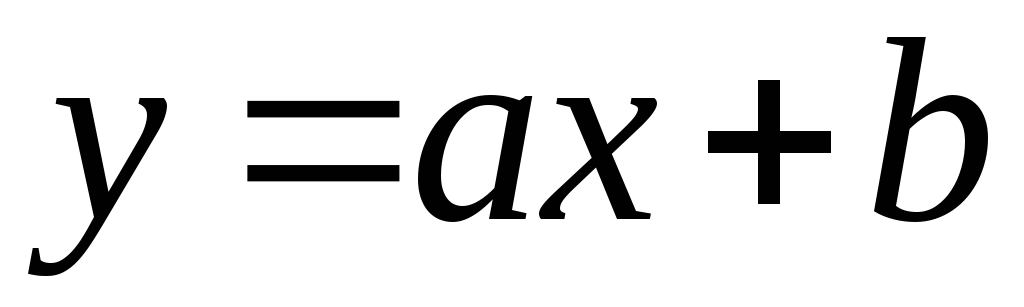 .
.
Индикатор за близостта на връзката е коефициент на корелация . Емпиричният коефициент на корелация се дава от:

Коефициентът на корелация варира от -1 преди 1 и характеризира степента на близост между количествата х И г . Ако:

Корелацията между характеристиките може да бъде описана по различни начини. По-специално, всяка форма на връзка може да бъде изразена чрез уравнение от общата форма 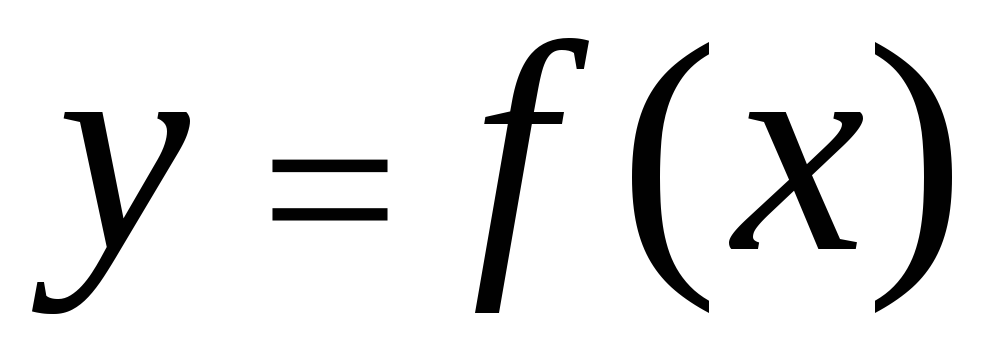 . Уравнение на формата
. Уравнение на формата 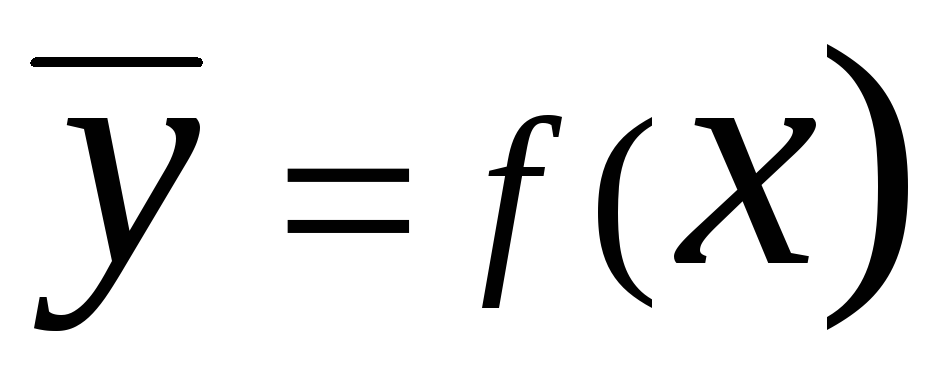 И
И  са наречени регресия
. Уравнение на предната регресия при
На х
в общия случай може да се запише във формата
са наречени регресия
. Уравнение на предната регресия при
На х
в общия случай може да се запише във формата

Уравнение на предната регресия х На при като цяло изглежда

Най-вероятните стойности на коефициента АИ V, сИ дможе да се изчисли, например, като се използва методът на най-малките квадрати.
